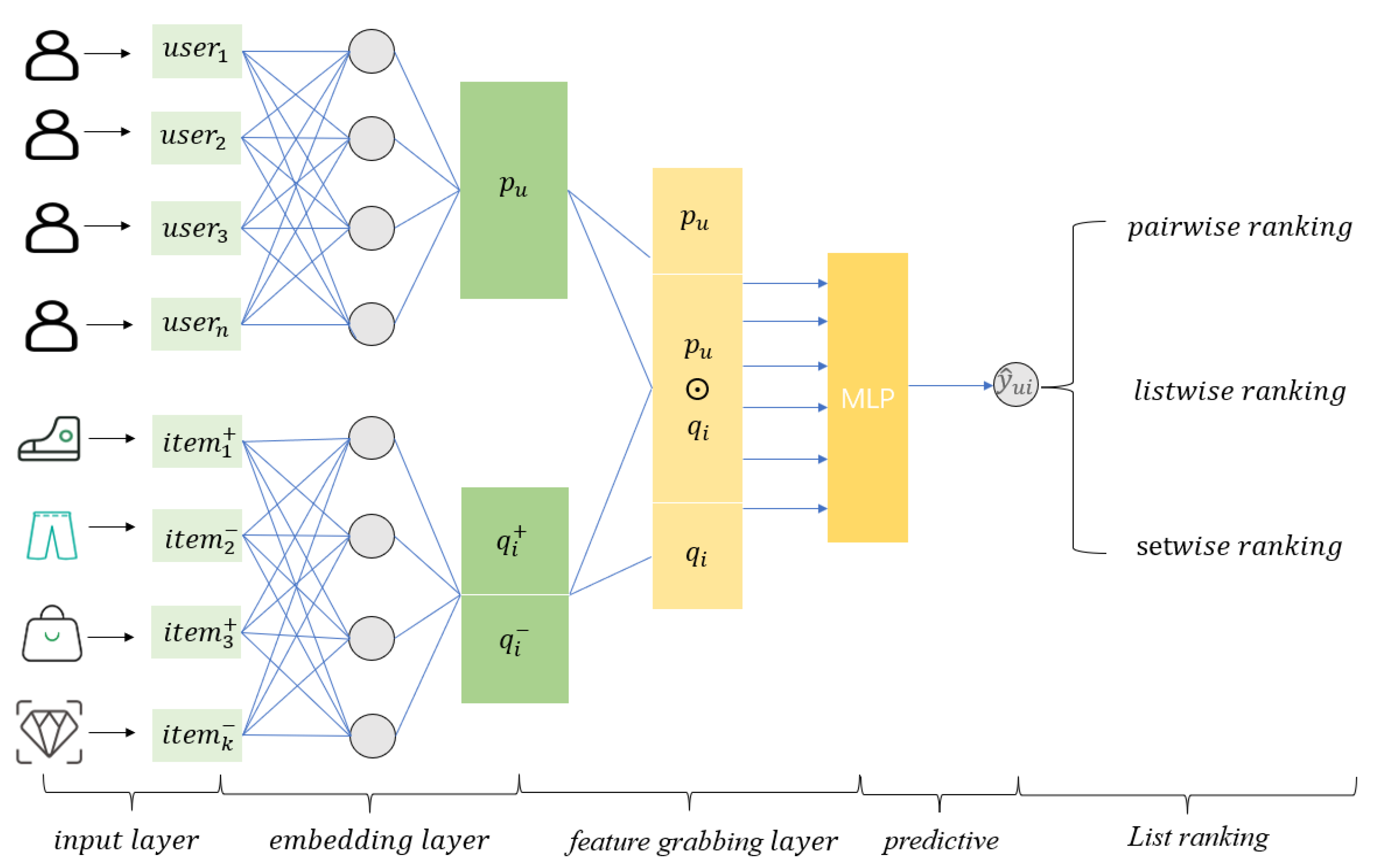
In this section, we introduce the dataset, the experimental evaluation index and the algorithm to compare with our experiment. Our experiment aims to answer four key questions
4.1. Datasets, Evaluation Metrics and Compared Models
As shown in
Table 1, we evaluated our model on several public datasets, including MovieLens—100 k, MovieLens—1 M, and Yahoo. We randomly selected 80% of the scores for training the data for each dataset.
In addition, we used two popular accuracy metrics, the HR@N and the NDCG@N (N denotes that the RBLF generate the number of the top-n items).
The larger the value of HR and NDCG, the better the model’s performance. The HR@N score is defined as:
where #users are the total users whose items in the test set appear.
NDCG@N is defined as follows:
indicates whether the item ranked i is preferred by the user.
indicates that the user likes the product;
indicates that the user does not like the product; b is the free parameter, which is generally set to 2; N is the number of the top-n items from RBLF. DCG was normalized to obtain NDCG.
We used the compared methods as shown below:
The ItemKNN model considers the evaluation bias after the calculation is completed and obtains the k most similar items.
BPR [
34] is a widely used Bayesian-sorting algorithm.
ListRank-MF [
26] uses a learning-sorting algorithm and matrix factorization to improve performance while maintaining low complexity.
Neural cooperative filtering (NCF) [
14] directly uses a combination of the DNN and matrix factorization, thereby alleviating the problem of DNN overfitting and ignoring low-rank information.
The DeepCF [
13] model is the deep matrix decomposition model (DMF) and gives its own solution to NCF’s problem. It uses matching learning, which combines the advantages of the two methods, and effectively avoids the shortcomings of the two methods.
The DeepRank [
32] model is built on natural language processing capabilities and is currently one of the best sorting algorithms.
4.2. Performance Evaluation (RQ1)
The model is compared with the benchmark in
Table 2. The best marks are highlighted in bold.
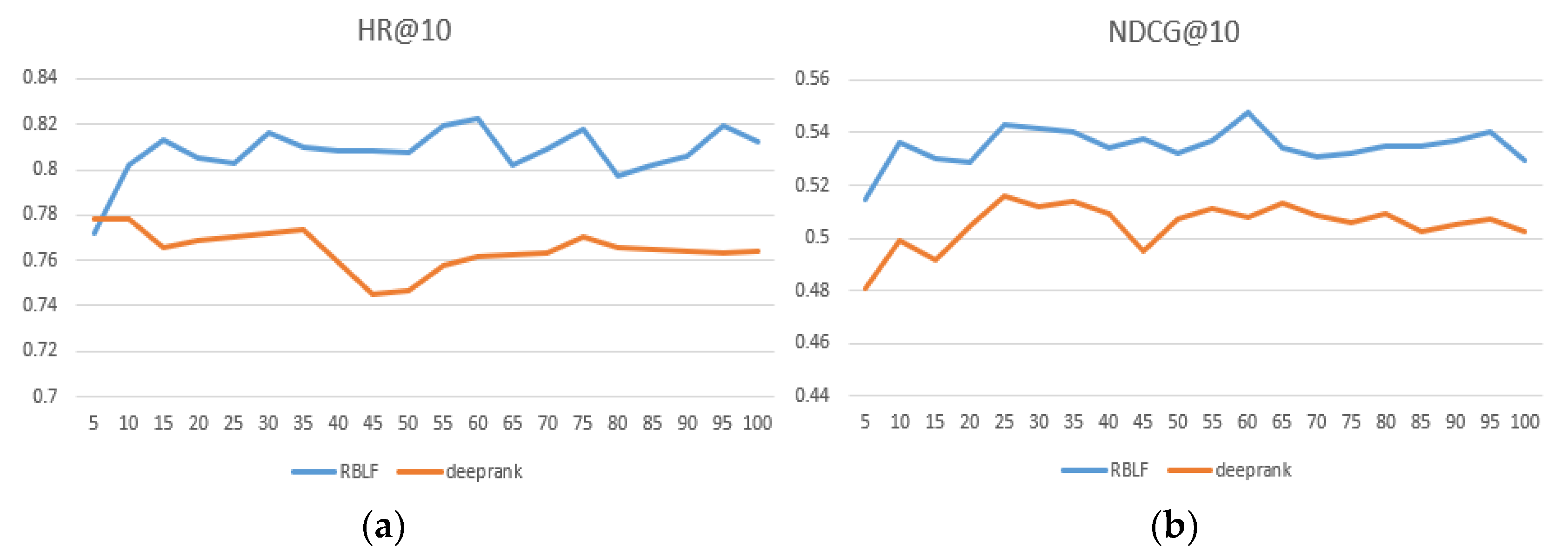
We compared the performance of RBLF and the adaptability of the model when facing different datasets in
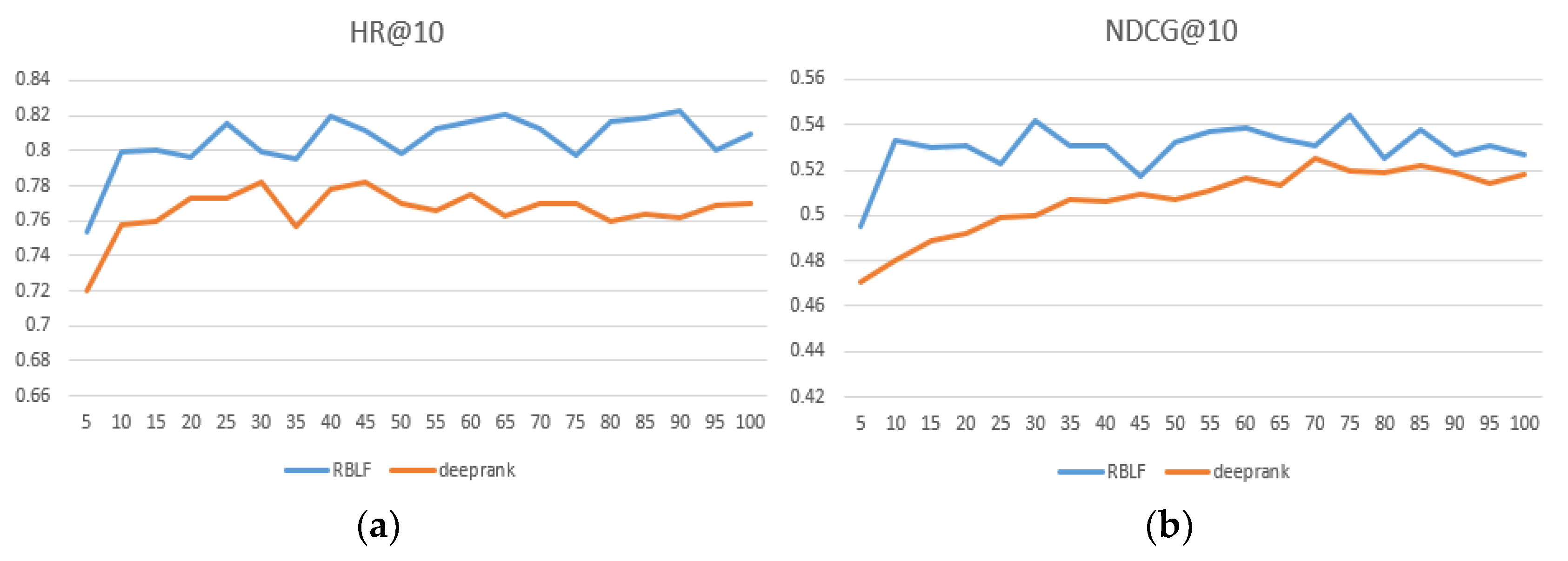
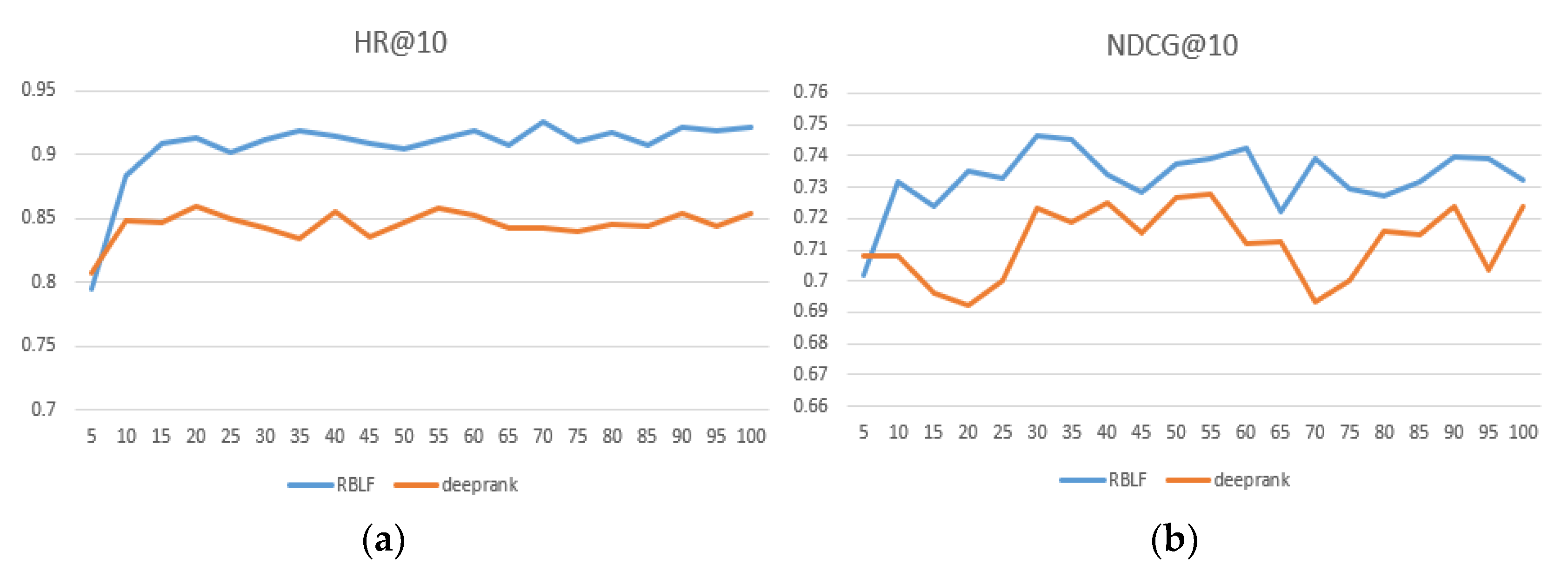
Table 2 and the best performing numbers are in bold. At the same time, we intuitively compared the DeepRank model, which is the closest to our model and records results within each epoch at 100. As seen in
Figure 4,
Figure 5 and
Figure 6, the x-axis represents the epoch and the y-axis represents the results.
As seen in
Table 2, our proposed method achieves excellent ranking performance and has considerable advantages on each dataset. We believe that it is precisely because our model better simulates the user’s preferences that the performance is ahead of the performance of the comparison algorithm. In addition, RBLF consistently outperforms the DeepRank model on the three datasets and increases by 6.3%, 7.1%, and 4.5%, respectively. (According to the paper and our experimental data, the specific values of the hyperparameters when DeepRank achieves the best performance are: the length of the list K = 15, the user and item dimension sizes of embedding
, and the depth of MLP L = 4.)
Figure 4,
Figure 5 and
Figure 6 show that the RBLF and DeepRank epoch are between 0–100, including the values of HR@10 and NDCG@10. In the figure, we can see more clearly that the performance of RBLF is better at each epoch, and at the same time, it avoids DeepRank due to the problem of mid-term performance degradation.
On the sparsest dataset Yahoo! Movie, RBLF is also superior to other methods, indicating that the idea of combining RBLF in our model simulates the invisible preferences of users, ensuring high performance and high flexibility of the model. Since BPR and ListRank-MF are simply linear interactions, they perform relatively poorly on all datasets, although they also model invisible preferences. The DeepRank model uses the MLP model, which omits some low-rank information and some simple user characteristics in the user–item matrix. As a result, although their performance is high, they are still inferior to RBLF. Although the NCF model uses MLP and MF, our model is a cascade fusion, which allows the model to better integrate these two algorithms, and thus, our model performance is even better. The DeepCF method is concerned with the point-by-point method and ignores the paired ranking information. Our model captures the user’s characteristics from the user’s paired item. This result in our model is more powerful than theirs in predicting the performance of personalized rankings.
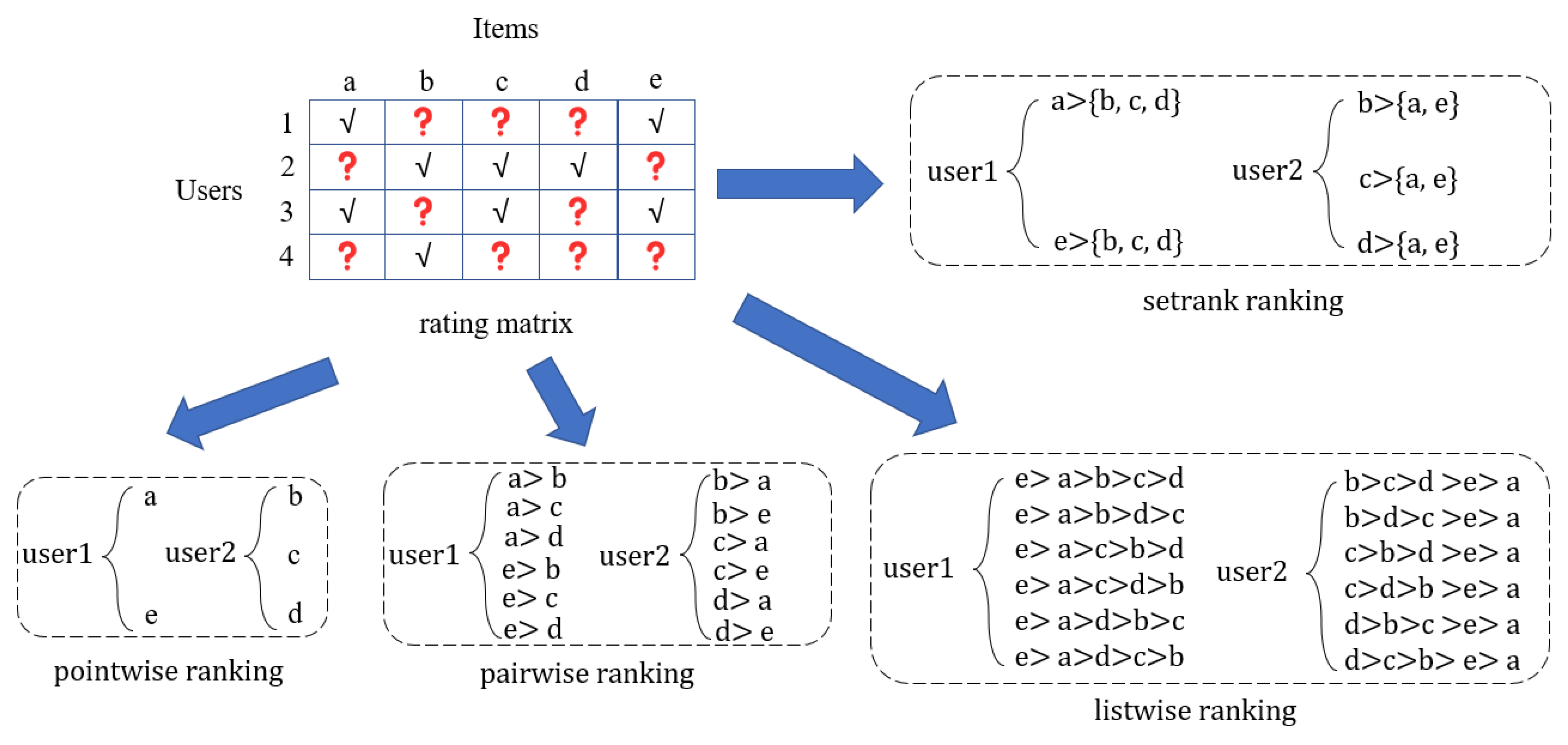
4.4. Different List Ranking Methods (RQ3)
The results for different list ranking methods are shown in
Table 4. Deep-setrank outperforms the pairwise ranking and listwise ranking on the two datasets and increases by 10% and 1.8%, respectively.
The reason Deep-setrank performance is substantially better than pairwise ranking is that pairwise methods typically model the preference structure in implicit feedback based on an item pair consisting of a positive feedback item and an unobserved item. This approach is prone to the problem of inconsistent independence in assumptions and implementation. Pairwise ranking attempts to maximize the probability of pairwise comparisons between positive and unobserved simples. This work requires the strict assumption that two items have independent pairwise preferences as the basis for constructing the loss function. Therefore, the independence between preference pairs cannot be guaranteed, which affects the optimization results of the pairwise loss function. Only the order of the two documents is considered, and the position of the documents in the search list is not, resulting in a less-than-optimal final ranking.
The reason Deep-setrank outperforms listwise ranking is that the list method is implemented by defining a probabilistic relationship between the preference sizes on the list of items. For the list method, items with the same rating value cannot be handled efficiently, especially because there is no explicit graded rating in the implicit feedback but 0/1 rating, which can lead to a large number of items with the same rating. In contrast, Deep-setrank does not sort the set of unobserved items or the set of positive sample items internally but only ensures that each positive sample is larger than the set of unobserved samples. Therefore, Deep-setrank models the implicit feedback data more realistically than listwise ranking.
4.5. Different Hyperparameters of the Model (RQ4)
The effect of the length of the list is shown in
Table 5. First, as the list length K increases, the model performance increases. After K = 5, the performance is not significantly improved. After K = 10, the performance of the model begins to decrease as K increases. This is because our model is more complex, and the meaningless increase in the length of the list affects the final performance. At the same time, the longer list length inevitably leads to a substantial increase in the running time. Therefore, we finally take K as 5, the optimal parameter after combining time and performance.
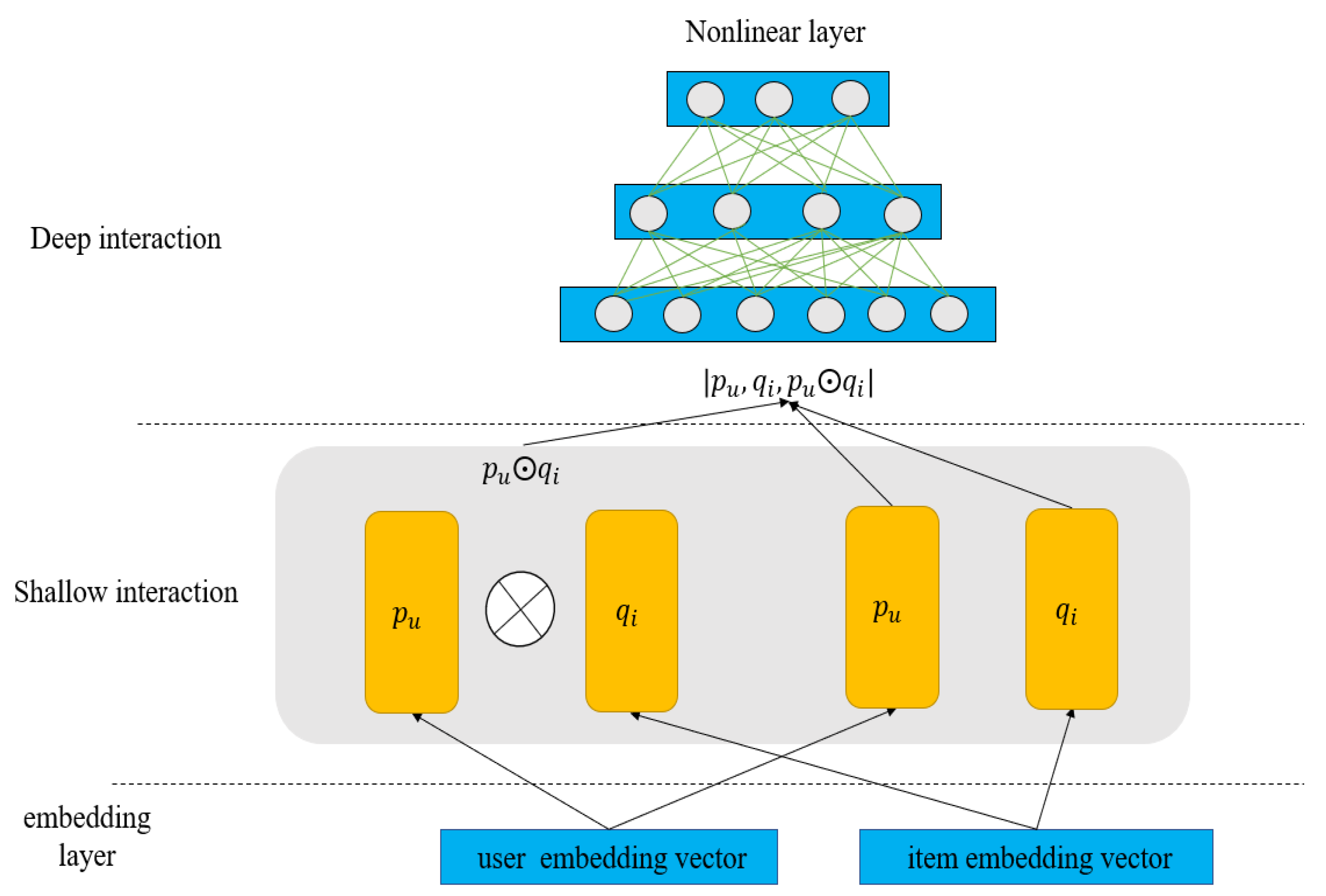
The embedding size is important for the representation of the project. We conducted experiments to determine the impact of embeddings of different dimensional sizes on the performance of the model. We set the user and item embedding dimension size
, e
, and the results are shown in
Table 6.
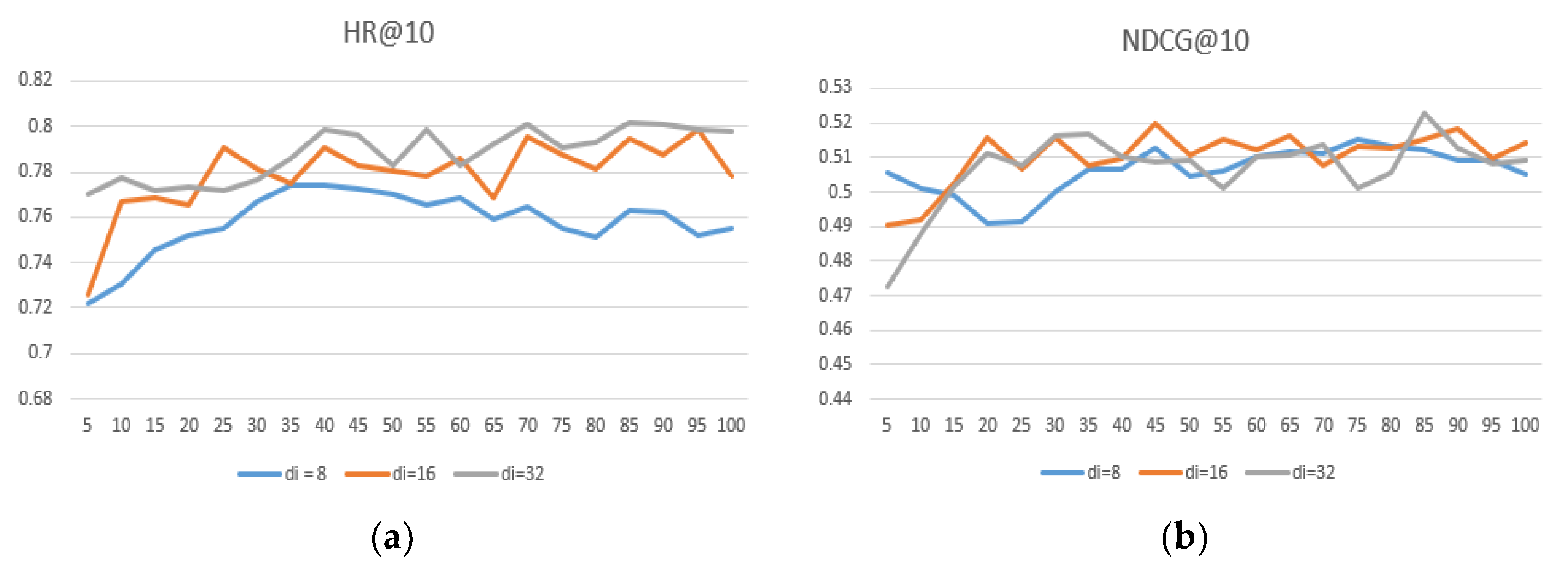
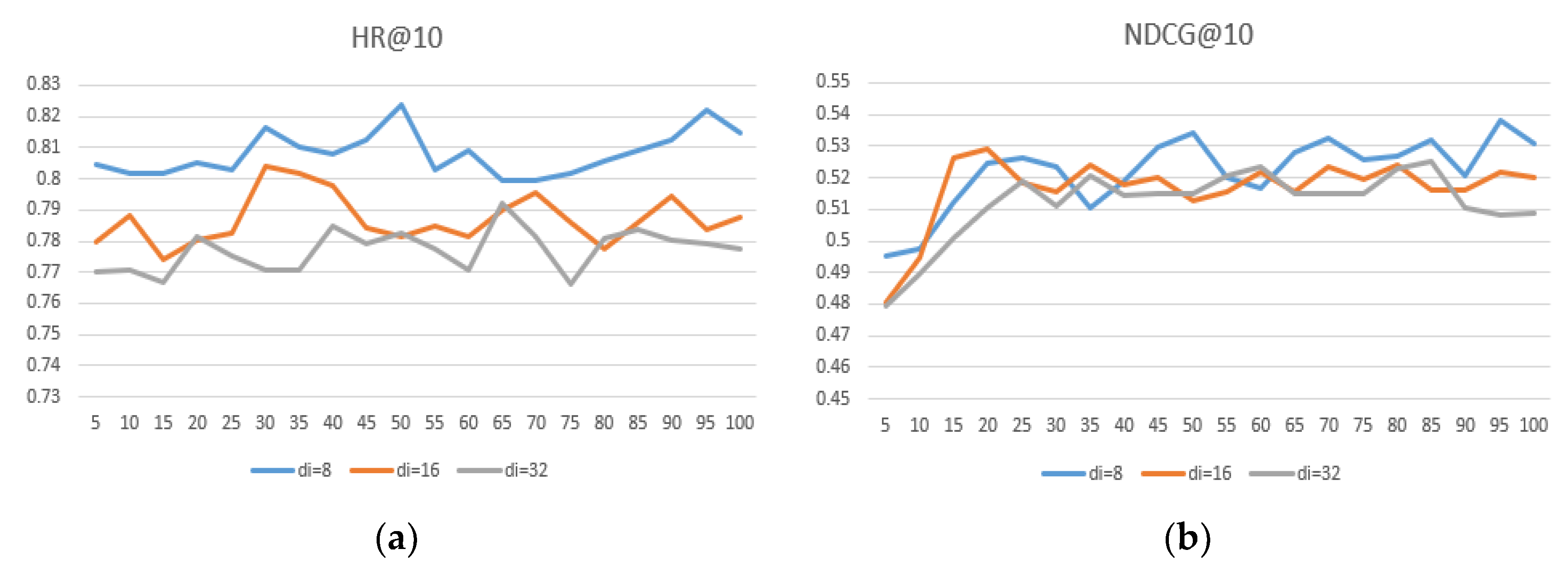
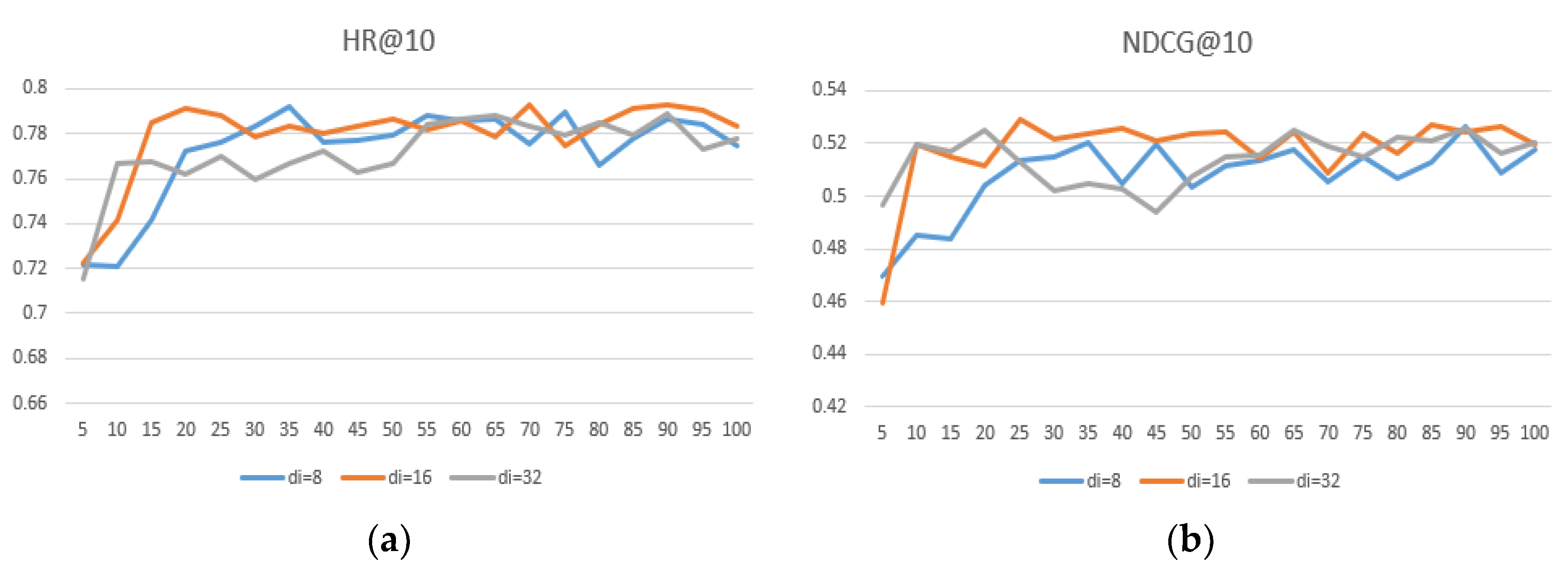
Figure 7,
Figure 8 and
Figure 9 show that the user embedding remains unchanged in MovieLens—100 K and the impact of changing the size of the item embedding, where the x-axis represents the epoch and the y-axis represents the results.
After conducting many experiments, we can conclude the following: First, when the user–item embedding dimensions are different, the performance is better than that of the user and the item with the same embedding dimension. Second, if you want to achieve better results, neither user embedding nor item embedding can take 32 because excessive dimensions.
Third, the dimension of user embedding is preferably smaller than the dimension of item embedding. Finally, we conclude that when = 8 and = 16, the model’s performance can reach its highest and performs much better on different datasets, proving that the generalization ability is well.
In the new experiment, we set the size of MLP to [8], [16,8], [32,16,8], [64,32,16,8] and [128,64,32,16,8], and the results are shown in
Table 7.
In the beginning, as the number of layers of MLP increases, the performance of the model also improves because the deep neural network is similar to the structure of the shallow neural network when the number of layers is too small, and the model does not have sufficient fitting capabilities. Therefore, as L increases, the fitting ability of the deep neural network also increases, which drives the improvement of the model’s performance. After L = 4, the performance decreases instead because the model adds a shallow interaction-grabbing layer, limiting the MLP model’s depth.
In this section, we compare the performance and time cost of three list ranking methods.
Table 8 shows the training time of the three models on the MovieLens—100 K and Movielens—1 M datasets.
The time cost of the pairwise-ranking model is far superior to that of those models, although the performance of pairwise-ranking is the worst. As for listwise-ranking and deep-setrank, they take about the same amount of time, but the performance of deep-setrank is better than the listwise-ranking. Thus, we suggest that if you care about the time cost, you should choose pairwise-ranking, and if you prefer higher performance, you should choose deep-setrank.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}