1. Introduction
Decision trees have been widely used for their good learning capabilities and ease of understanding. In some real world issues, instances may be ill-known for some factors such as randomness, data incompleteness and even expert’s indefinite subjective opinions; however, traditional decision trees can only handle certain samples with precise data. The incompletely observed instances are usually ignored or replaced by a precise one, despite the fact that they may contain useful information [
1], which may cause a loss of accuracy.
There have been many attempts to build trees from incomplete data in the past several decades. The probability trees [
2,
3] were suggested based on probability theory, which is usually intuitively the first tool to modeling uncertainty in practice; however, it has been proven that probability cannot always be adequate for representing data uncertainty [
4,
5] (often termed epistemic uncertainty). To overcome this drawback, various approaches have been proposed, including: fuzzy decision trees [
6,
7], the possibilistic decision trees [
8] and the uncertain decision trees [
9,
10]. Besides the aforementioned methods, a more general framework, called the belief function theory [
11,
12] (also evidential theory or Dempster–Shafer theory), has been proven to have the ability to model all kinds of knowledge. The process of embedding belief functions within decision tree techniques has already been extensively investigated [
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25] in recent years. Particularly, among these methods, several trees [
17,
18,
19] estimate parameters by maximizing evidential likelihood function using the
algorithm [
26,
27], which is also the basis of part of the trees to be proposed in this paper.
However, the existing methods on incomplete data do not take continuous attributes into full consideration. These proposals deal with uncertain data modeled by the belief function and build trees by extending the traditional decision tree method. The imitation and transformation decides to use existing methods to handle continuous attribute values by discretization, which brings about an issue of losing the detail of the training data. For example, the information gain ratio, the attribute selecting measurement in C4.5, was transformed to adapt the evidential labels of the training set in the Belief C4.5 trees [
19], in which the continuous-valued attribute is divided into four intervals of equal width before learning. This issue leads to the purpose of this paper: to learn from uncertain data with continuous attribute values without pretreatment.
To realize this purpose, we firstly, for each attribute, fit the training data to a Gaussian mixture model (GMM), which consists of normal distribution models one-by-one corresponding to class labels, by adopting the
algorithm. This step, which significantly differs from other decision trees, confirms the ability to deal with ill-known labels and original attribute values (either discrete or continuous). On the basis of these GMM models, we generate the basic belief assignment (BBA) and calculate belief entropy [
28]. The attribute with minimal average entropy, which distinguishes classes from each others most, will be selected as the splitting attribute. The following decision tree induction steps are designed accordingly and logically. To our knowledge, this paper is the first to introduce GMM models and belief entropy to decision trees with evidential data.
Another part of our proposal is adopting the ensemble method for our belief entropy trees. Inspired by the idea of building bagging trees based on random sampling [
29], we further choose a more efficient and popular technique—random forest [
30]. Under the belief function framework, the basic trees will output either precise or mass (modeled by BBA) label predictions, while traditional random forest can only combine precise labels. Thus, a new method to summarize the basic tree predictions is proposed to combine mass labels directly, instead of voting on precise labels. This combined mass keeps the uncertain information of data as much as possible, which helps to generate a more reasonable prediction. The new combination method is discussed and compared to the traditional majority voting method later.
We note that we have proposed our early work in a shorter conference paper [
31]. Compared with our initial conference paper, we have fixed the attribute selection and splitting strategy of a single tree and introduced ensemble learning to our tree method in this paper.
Section 2 recalls some basic knowledge about decision trees, belief function theory, the
algorithm and belief entropy.
Section 3 details the induction procedure of belief entropy methods and proposes three different instance prediction techniques. In
Section 4, we introduce how to expend the single belief entropy tree to random forests and discuss the different predicting combination strategies. In
Section 5, we detail experiments that were carried out on some classical UCI machine learning data sets to compare the classification accuracies of proposed trees and random forests. Finally, conclusions are summarized in
Section 6.
2. Settings and Basic Definitions
The purpose of a classification method is to build a model that maps an attribute vector
, which contains D attributes, to an output class
taking its value among K classes. Each attribute discretely has finite values or continuously takes value within an interval. The learning of classification is based on a complete training set of precise data which contains
N instances, denoted as
However, the imperfect knowledge about the inputs (feature vector) and the outputs (classification labels) exists widely in practical applications. Traditionally and regularly, the imperfect knowledge is modeled by probability theory, which is considered to be questionable in a variety of scenarios. Hence, we model uncertainty by belief function in this paper. Typically, we consider that attribute values are precise and can be either continuous or discrete, while only the output labels are uncertain.
2.1. Decision Trees
Decision trees [
32] are regarded as one of the most effective and efficient machine learning methods and widely adopted for solving classification and regression problems in practice. The success, to a great extent, relays on the easily understandable structure, for both humans and computers. Generally, a decision tree is induced top-down from a training set
T, which recursively repeats the steps below:
Select an attribute, through a designed selection method, to generate a partition of a training set;
Split the current training set to several subsets and put them into child node;
Generate a leaf node and determine the prediction label for a child node when a stop criterion is satisfied.
Differing in the attribute selection methods, several decision tree algorithms have been proposed, such as ID3 [
32], C4.5 [
33] and CART [
34]. Among these trees, the ID3 and C4.5 choose entropy as an information measure to compute and evaluate the quality of a node split by a given attribute.
The core of ID3 is information gain. Given training data
T and an attribute
A with
modalities, the information gain will be:
where
and
where
is the proportion of instances in
T that are of class
,
and
are the cardinalities of the instance sets belonging to a parent node and to the child node
i.
The limitation of information gain is that attributes with largest values will be most promoted [
33], which leads to the
in the C4.5 algorithm. It is given as:
where
The attribute with the largest gain ratio will be selected for splitting.
We can easily find the the Equation (
2) is actually the Shannon Entropy. Yet in this paper, concerning the feature of evidential data described by the framework of belief function, the attribute selection method is newly designed based on belief entropy [
28] instead of Shannon entropy.
2.2. Random Forest
To improve the classification accuracy and generalization ability of machine learning, the ensemble model method is introduced to the learning procedure. One important branch of ensemble method is called
, which concurrently builds multiple basic models learning from different training sets, which are generated from original data by bootstrap sampling. On the basis of bagging decision trees, random forest (RF) [
30] not only chooses the training instance randomly but also introduces randomness into attributes selection. To be specific, traditional decision trees select the best splitting attribute among all
D attributes; random forest generates a random attribute subset then chooses the best one within this subset to split the tree node. The size
of this subset is adjustable and generally set as
.
A detailed description of the mathematical formulation of RF model is found in [
30]. The RF model consists of a union of multiple basic trees, where each tree learns from bootstrap samples and selects attribute from a small subset of all attributes. There some advantages of RF: (a) better prediction performance, (b) resistance to overfitting, (c) low correlation of individual trees, (d) low bias and low variance and (e) small computational overhead.
Some existing works have explored the ensemble method on belief decision trees, such as bagging [
29]. In this paper, we apply the random forest technique to the proposed belief entropy trees and discuss the different prediction determining strategies.
2.3. Belief Function Theory
Let the finite set
denote the frame of discernment containing
k possible exclusive values that a variable can take. When considering the output
y, the imperfect knowledge about value of
y can be modeled by mass function
, such that
, and
which is also called a basic belief assignment (BBA). The subset
A is called a focal set where
, and the
can be interpreted as the support degree of the evidence towards the case that true value is in set
A.
There are some typical mass functions need to be attended:
mass: mass function such that , which means total ignorance;
mass: for all focal set A, the cardinality . In this case, the mass degenerates to a probability distribution;
mass: for some A. In this case, the mass is equivalent to the set A.
One-to-one related to the mass function
, the
and
are defined as:
which, respectively, indicate the minimum and maximum belief degree of evidence towards set
B. Typically, the function
such that
for all
is called
associated to
.
For two mass function
and
induced by evidences independently, they can be combined by the
[
12]⊕ defined as:
for all
, and
, where
is called the
between
and
. Obviously, Dempster’s rule is commutative and associative according to the definition.
In the decision making situation, we need to determine the most reasonable hypothesis from a mass. Different decision-making strategies with belief functions [
35,
36] have been researched. Among these methods, in the transferable belief model (TBM),
[
37] was proposed to make decision from a BBA:
where
is the cardinality of
A.
When we model uncertain labels of evidential data with mass functions, the training set becomes
2.4. Evidential Likelihood
Consider a discrete random vector
Y taking values in
with a probability mass function
assumed to be associated with a parameter
. After a realization
y of
Y has been perfectly observed, the likelihood function of
is defined as
such that
When the observations are uncertain, it is impossible to evaluate parameter
from a likelihood function. In this situation, a new statistical tool [
38] called evidential likelihood was proposed to perform parameter estimation. Assume that
y is not precisely observed, but is known surely that
for some
. Given such
, the likelihood function will be extended to
Furthermore, the observation of instance
y could be not only
, but also
, which is modeled by mass function
. Thus the evidential likelihood function [
27] can be defined as
where the
is the contour function related to
and the
can be remarked as
. According to the statement of Denoeux [
27], the value
equals to the conflict between parametric model
and the uncertain observation
, which means minimizing
is actually a procedure of estimating the best parameter
to fit the parametric model to observation as closely as much.
Equation (
14) also indicates that
can be remarked as the expectation of
such that
Assume that
is a sample set containing n cognitively independent [
12] and i.i.d. uncertain observations, in which the
is model by
. In the situation the Equation (
15) is written as a product of
n terms:
2.5. EM Algorithm
Though an extension of likelihood function, the maximum likelihood estimation of evidential likelihood can not directly be computed by the broadly applied EM algorithm [
39]. The
algorithms [
27] introduced by Denoeux allow us to maximize the evidential likelihood iteratively, which is composed of two steps (similar to EM algorithm):
- 1.
The
E-step require firstly a probability mass function
, in which the former part means the probability mass function of
Y under the parameter
estimated from last iteration and the latter part indicates contour function
. The expression is:
Then calculate the expectation of log likelihood
of complete data with respect to
,
- 2.
The M-step is to maximize with respect to , obtaining a new estimation that ensures .
The two steps repeat until , where is a set threshold.
2.6. Belief Entropy
Inspired by Shannon entropy [
40], which can measure uncertainty contained by a probability distribution, a type of belief entropy called Deng entropy is proposed by Deng [
28] to handle situation where the traditional probability theory is limited. When the uncertain information is described by the basic belief assignment instead of the probability distribution, Shannon entropy cannot work. Deng entropy is defined on the belief function frame, which makes it able to measure uncertain information described by the BBA efficiently.
Let
A be the focal set of belief function, and
be the cardinality of
A. Deng entropy
E is defined as:
We can easily learn from the definition that if the mass function is
, which means
for all
A, Deng entropy degenerates to Shannon entropy such that
The greater the cardinality of the focal set is, the bigger the corresponding Deng entropy is, so that the evidence imprecisely refers to more single elements. Thus, significant Deng entropy indicates huge uncertainty. Powered by this feature, we calculate the average Deng entropy of BBAs to select the best attribute leading to the least uncertainty. The details are shown in the next section.
3. Design of Belief Entropy Trees
Up to now, various decision tree methods have been proposed to deal with evidential data, but many of them consider categorical attributes and transform the continuous attribute values into discrete categories. Some recent works fit the continuous attributes with same class labels into normal distributions [
41] and generate BBA from the normal distributions to select the best splitting attribute by calculating belief entropy [
42]; however, this method divides samples into each set of certain classes, which can only handle the precise class labels. Our goal is to develop a belief decision tree method learns from data set with continuous and precise attribute values but incomplete class labels directly and efficiently.
This section explains our method in detail, specifically focusing on the procedure of attribute selection. Corresponding splitting strategy, stopping criterion and the leaf structure are also well-designed to accomplish the whole belief entropy decision tree.
3.1. The Novel Method to Select Attribute
The learning procedure of decision trees is generally to decide the split attribute and to decide how to split on this attribute on each node; our method also proceeds in this manner. As a novel decision tree, the most characteristic and core part of our method is the attribution selection, which includes three steps: firstly, for each attribute, fit the values to normal distributions corresponding to each class label, in another words, fit attribute values into K×D normal distribution models, where K is the class number and D is the attributes number of instances; secondly, for every instance, generate D BBAs from each attribute according to the normal distribution-based models; finally, calculate belief entropy from BBAs for each attribute. The attribute with minimum belief entropy will be selected to split.
3.1.1. Parameter Estimation on Data with Continuous Attributes
Powered by the idea of extracting BBAs from normal distribution-modeled attribute values [
41], we try to operate similarly on data with ill-known class labels. In the situation that each instance exactly belongs to one class, the d-th attribute values set
is divided into K subsets
corresponding to each class. It is easy to fit each subset to the normal distribution by calculating means and standard deviations.
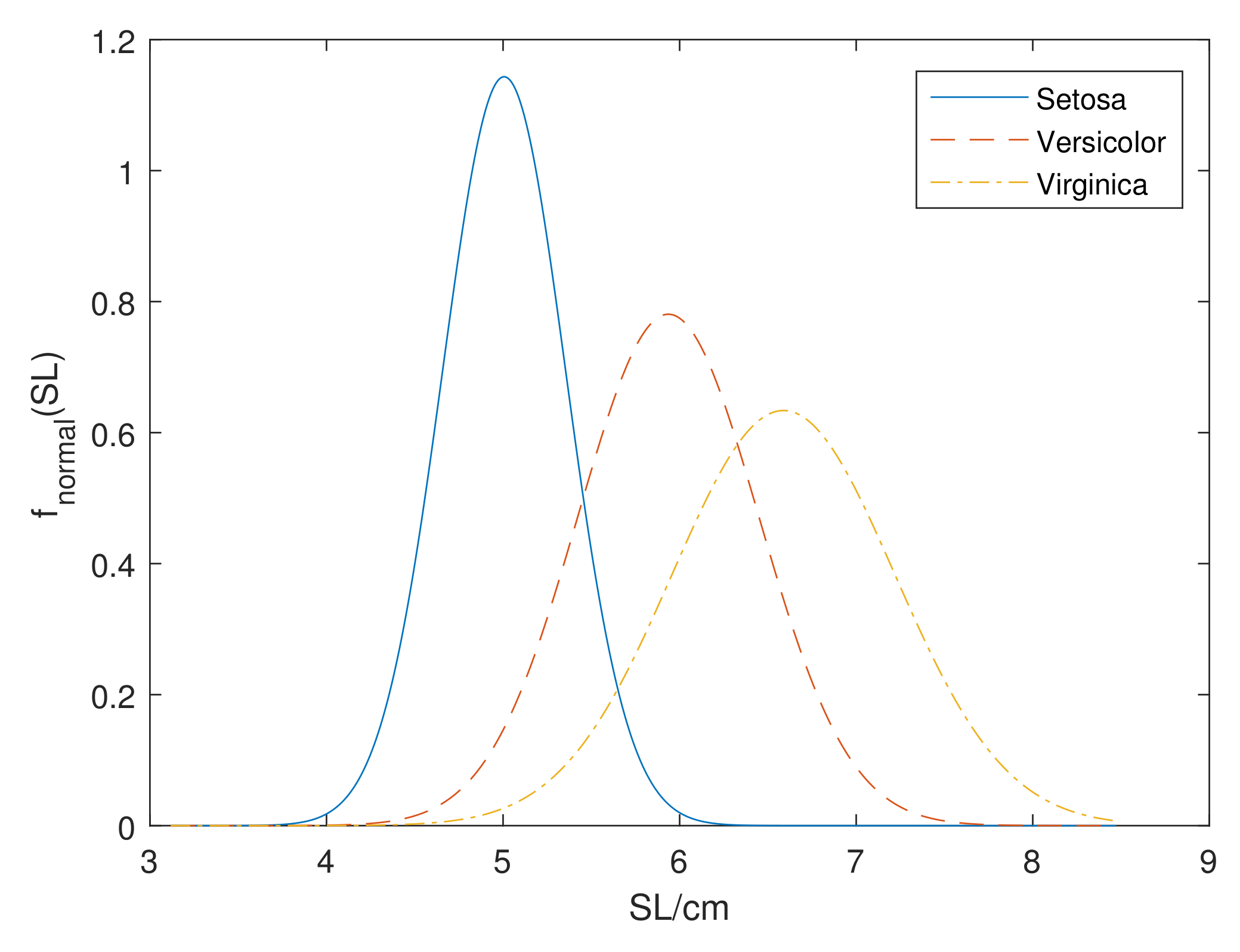
Example 1. Consider the Iris data set [43], a classical machine learning data set, which contains 150 training instances of three classes: ‘Setosa’, ‘Versicolor’, ‘Virginica’, with four attributes: sepal length(SL), sepal width(SW), petal length(PL) and petal width(PW). For the values of attribute SL in the class of Setosa, we can directly calculate the mean value as and standard deviation as . Similarly, we can obtain normal distribution parameters of class of Versicolor and Virginica. Figure 1 shows the normal distribution model of Iris data set for the SL attribute in three classes. However, when the labels of training set are ill-known, some instances can not be allocated to a certain class assertively. The evidential likelihood and
algorithm introduced in
Section 2 make it possible to generate an estimation of model parameters. Because the
algorithm uses only contour functions, the label of n-th instance will be represented by plausibility
instead of mass function
.
For the purpose of comparing attributes, we split the whole training data into D attribute–label pairs and handle D parameter estimation problems. Consider the
d-th attribute value vector
, we assume the conditional distribution of
when given
is normal with mean
and standard deviation
:
Actually the assumption is to build a one-dimensional
[
44]. Similar to the application of
algorithm in
[
45], the following discuss is practically to adopt
algorithm to estimate parameters in GMM.
Let
be the marginal probability when
, and
the parameter vector to be estimated. The complete-data likelihood is
where the
is normal distribution probability density,
and
is a binary indicator variable, such that
if
and
if
.
when expended to evidential data, where we use contour function to describe the labels, the evidential likelihood is drew from Equation (
16) that,
According to the
algorithm, we compute the expectation of complete-data log likelihood
with respect to the combined mass probability function
To simplify the equation, we denote
Finally, we obtain the to-be-maximized function
in the E-step.
The formal of
is similar to the function computed in the EM algorithm on the GMM [
44]. Because of the similarity, we imitate it and learn that the optimal parameter maximizing
can be iteratively computed by
Finally when
is satisfied for some
, stop the iteration and remark
as
, which is the estimation of parameters in the GMM extracted from d-th attribute. Repeat this procedure for every attributes of the training set,
normal distribution
will be generated.
The Algorithm 1 shows the procedure of parameter estimation and there is Example 2 to help understand it.
| Algorithm 1 Parameter estimation of GMMs. |
Input: evidential training set , iteration stop threshold Output: estimated normal distribution parameter matrix - 1:
for each attribute do - 2:
initialize parameters as ; - 3:
Initialize loop variable. - 4:
for q do - 5:
update the estimation of parameters by Equations ( 28) and ( 29). - 6:
if then - 7:
break; {End the loop if evidential likelihood increment is less than threshold.} - 8:
end if - 9:
; - 10:
end for - 11:
adopt as estimated normal distribution parameters under attribute ; - 12:
end for
|
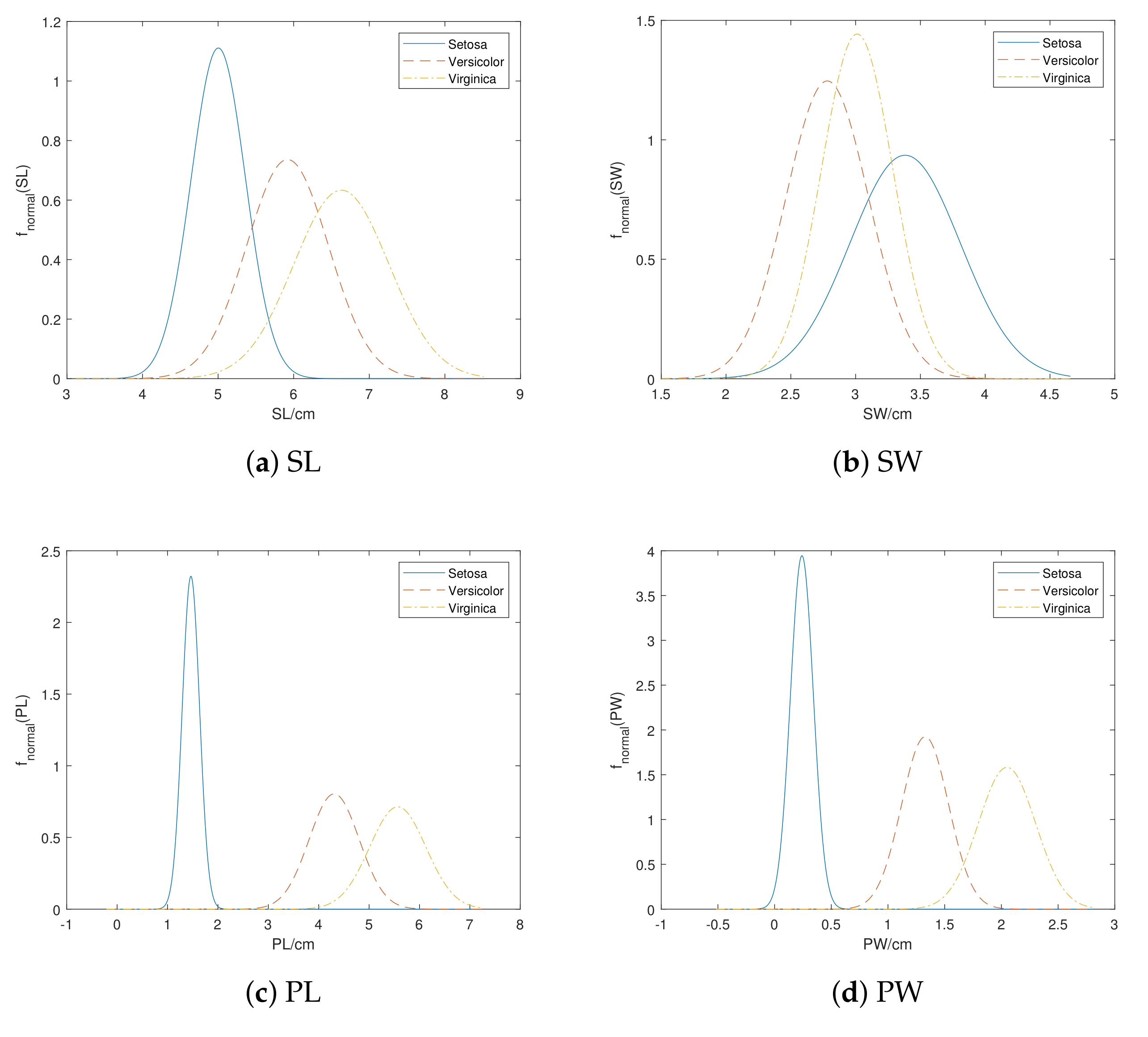
Example 2. Consider the Iris data set mentioned in Example 1. To simulate the situation that labels of training set are not completely observed, we manually introduce uncertainty to the Iris data. In this example, we set that each instance has an equivalent chance (25%) to be , , or completely observed (the detail of transformation is discussed in Section 5). Table 1 shows the attribute values and labels described by plausibility of some instances in evidential Iris data. Table 2 shows the mean and standard deviation pairs calculated by algorithm. Figure 2 shows curves of these models. 3.1.2. BBA Determination
This step is to generate D BBAs corresponding to each attribute for every instance in the training set.
Choose an instance with attribute vector from the data set, calculate the intersection of and the K normal distribution functions , i.e., we obtain K normally distributed probability density function (PDF) values for the attribute and instance , denoted as .
Due to the property that the probability of a value x sampling from a normal distribution is proportional to the PDF , we can infer, for the attribute d, the probability that instance belongs to each class is proportional to . From this opinion of statistical analysis, the rule to assign normal PDFs to some sets was proposed to build BBAs.
Firstly, normalize the
with different class
k such that
Then rank
in decreasing order
, whose corresponding class is denoted as
. Assign
to the class set by the following rule:
If , then . By this rule, we obtain a nested BBA of under the select attribute , which we denote as .
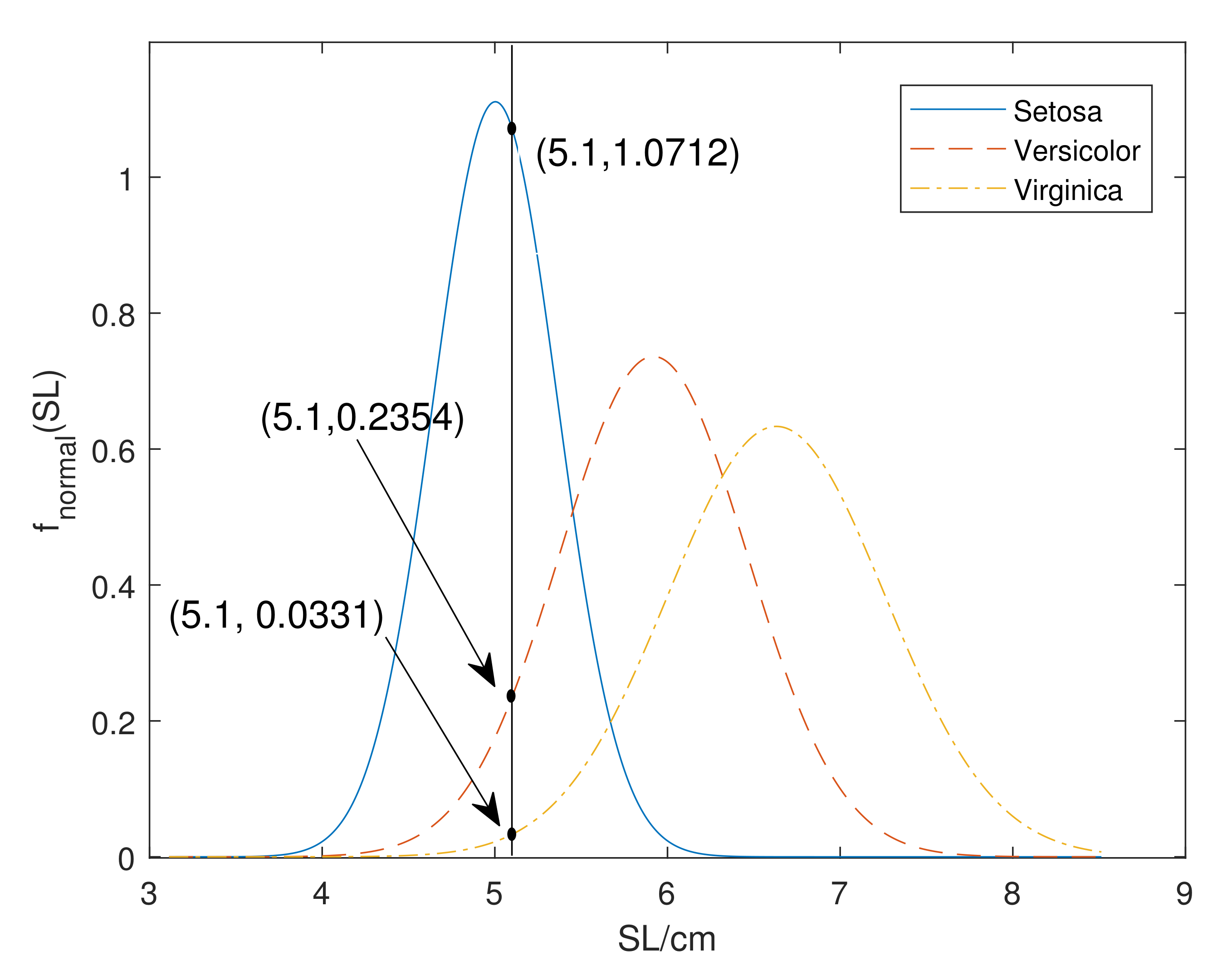
Example 3. Consider the first instance of the evidential Iris data set showed in Table 1, whose attributes are:For attribute SL, the intersections of and three normal distributions are shown in Figure 3 such that The reader can see in the figure that this instance is closest to class ‘Setosa’, then to the ‘Versicolor’ and ‘Virginica’. Thus, we generate BBA from intersection values, which is intuitive. The BBA is assigned as:Similarly, we build BBAs for the rest of the attributes—shown in Table 3. 3.1.3. Calculation of Belief Entropy
The last step to determine splitting attribute is to calculate the average Deng entropy
of all instances for each attribute. As mentioned in
Section 2.6, Deng entropy measures the uncertain degree contained by BBA, which means the less
, the more certainty the BBAs contain, and the more separate the division of classes is. Consequently, we choose the attribute
that minimizes the average Deng entropy such that
to be the best splitting attribute to proceed the tree building.
Example 4. Continue the Examples 2 and 3. Calculate Deng entropy of BBAs of selected instance shown in Table 3:Similarly proceed same calculation to all instances so that average Deng entropy for attributes are calculated thatAccording to this result, attribute PW will be chosen to generate child nodes. Comparing the Deng entropy with the curves in Figure 2, we can intuitively learn that PW has the most distinctive curves for each class, yet curves in SW overlap each other a lot, which conforms to the size of the average Deng entropy above, where PW is the lowest and SW is the highest. As a matter of fact, Examples 1–4 in this chapter can be orderly combined as a whole calculating example, which shows the procedure of the proposed attribute selecting method.
3.2. Splitting Strategy
The splitting strategy is redesigned according to the selected attribute
to fit the proposed attribute selection method. Branches will be associated to each class, that is to say, each node to be edged will have K branches. For an instance
, consider the generated BBAs, the class corresponding to the maximum mass value will be the branch that this instance shall be put into. To put it simply, when splitting the tree under attribute
, the instance
will be assigned into the
-
child node, where the
satisfies
The Algorithm 2 summarizes the procedure of selecting attribute and splitting. It should be mentioned that, though the child nodes are associated to each class, this splitting strategy does not mean to determine the affiliation of instances directly and arbitrarily in this step.
| Algorithm 2 Attribute selection and splitting. |
Input: evidential training set , possible splitting attribute Output: selected attribute , instance sets in child nodes , - 1:
compute the normal distribution parameters for each and by algorithm; - 2:
for each attribute do - 3:
for each instance do - 4:
generate BBA from normal distributions ; - 5:
; {Calculate Deng entropy for all generated BBAs} - 6:
end for - 7:
; {Calculate average Deng entropy for each attribute} - 8:
end for - 9:
split on attribute ; {The attribute with minimum average entropy is selected}
|
3.3. Stopping Criterion and Prediction Decision
After designing the attribute selection and partitioning strategy, we split each decision node to several child nodes. This procedure repeats iteratively until one of the stop criterion is met:
No more attributes for selection;
The number of instances in the nodes falls below a set threshold;
The labels of instances are all precise and fall into the same class;
When the tree building stops at a leaf node L, a class label should be determined to predict the instances that fall into this node. We design two different prediction methods such that:
The first one is to generate the prediction label from the original training labels of instances contained by this node, which is a similar treatment to traditional decision trees such as C4.5 tree method. Denoting the instances in the leaf node by
and the corresponding evidential training labels by
, the leaf node will be labeled by
, where
which means the class label with maximal plausibility summation will represent this node. This tree predicts from the original labels of training set, which is called
-
for short in this paper.
The first method described above in fact abandons the generated BBAs during the tree build procedure, which will be adopted to generating predicted instance label in the second method. Firstly, the splitting attributes list, which lead instance
to the leaf node from top to down, are denoted by
, and the BBAs generated accordingly are denoted by
. Then combine these BBAs by Dempster rule, such that
, to predict the training instance. On this basis, we continue to combine generated BBAs of all instances in a leaf node such that
, where the once again combined BBA
will be the mass prediction label for the whole leaf node. To obtain a precise label for another choice, the last step is making decision on BBA by choosing the class label with maximal pignistic probability computed by Equation (
11). We call this tree a
-
in this paper.
The Algorithm 3 summarizes the induction of belief entropy trees introduced in this section.
| Algorithm 3 Induction of belief entropy trees (BE-tree). |
Input: evidential training set , classifier type Output: belief entropy tree - 1:
construct a root node containing all instances ; - 2:
if stopping criterion is met then - 3:
if then - 4:
output precise prediction generated from original plausibility label for the whole node; - 5:
else if
then - 6:
combine BBAs generates during each splitting for each instance; - 7:
combine BBAs of all instances in previous node generated in step 6 that ; - 8:
output as a mass prediction for the whole leaf node; - 9:
output as a precise prediction for the whole leaf node; - 10:
end if - 11:
return =root node; - 12:
else - 13:
apply Algorithm 2 to select splitting attribute ; - 14:
induce each subset based on ; - 15:
for all do - 16:
-; {Recursively build the tree on the new child node} - 17:
attach to the corresponding ; - 18:
end for - 19:
end if
|
3.4. An Alternative Method for Predicting New Instance
Two types of belief entropy trees, the OBE tree and the LBE tree, have been described in detail in the last section. Similar to traditional decision trees, a new instance will be classified in a top-down way: starting at the root node and following branches by considering its generated BBA under splitting attribute until reaching a leaf node. The prediction of leaf node will be given to this new instance.
However, differing from the idea of collecting the numerous ‘opinions’ of instances, another method to predict a new instance is considered after a tree has been built. In
Section 3.1.2, we introduced how to generate each training instance’s BBA corresponding to attributes. In the same way, we can generate
corresponding to an attributes list
, which orderly splits and leads the new instance to a leaf node. Then, we combine these BBAs such that
to predict the new testing instance. It is easy to find that this method performs the same way as the front part of label prediction in LBE trees, yet stops when obtaining a mass prediction from the testing instance’s own attribution values instead of the leaf node it belongs to, which also means testing instances in a same leaf node normally have different mass prediction under this design. For the sake of narrative, a tree predicting in this way is called
-
in this paper.
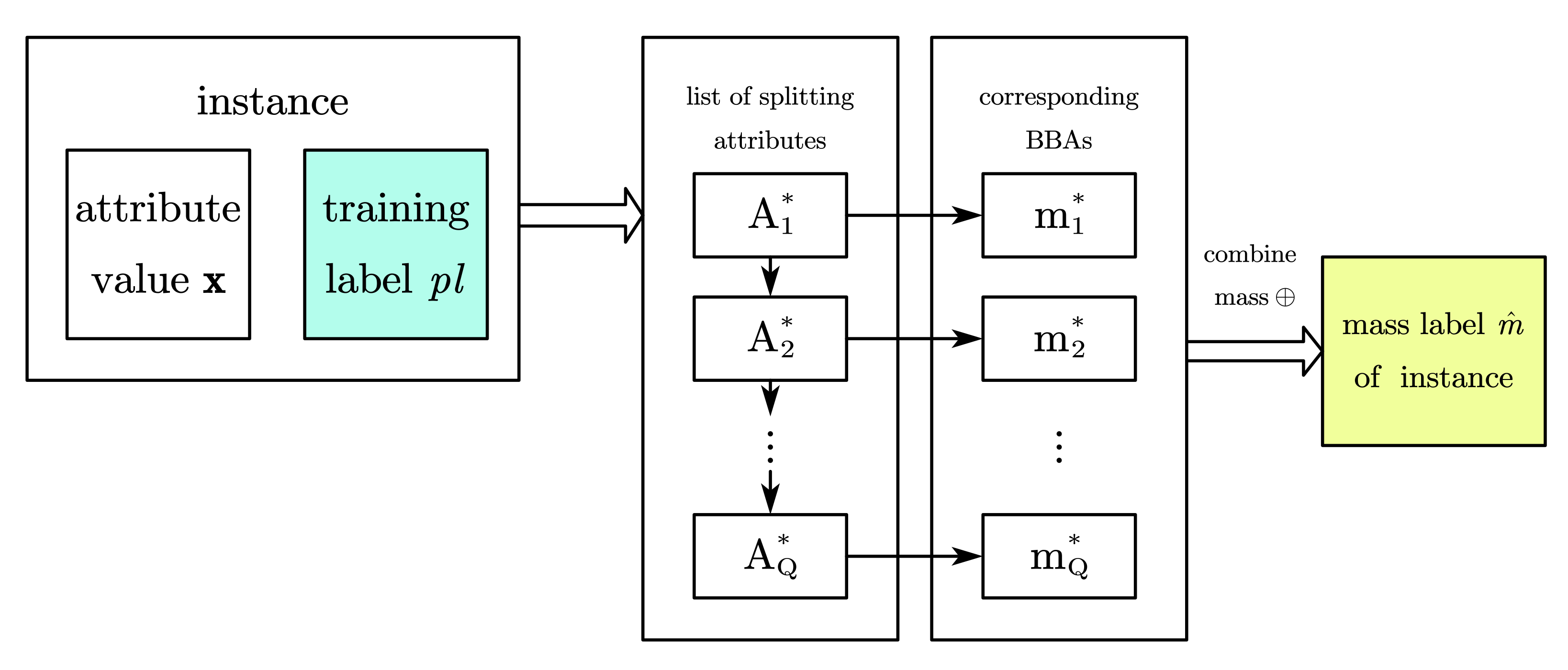
Figure 4 and
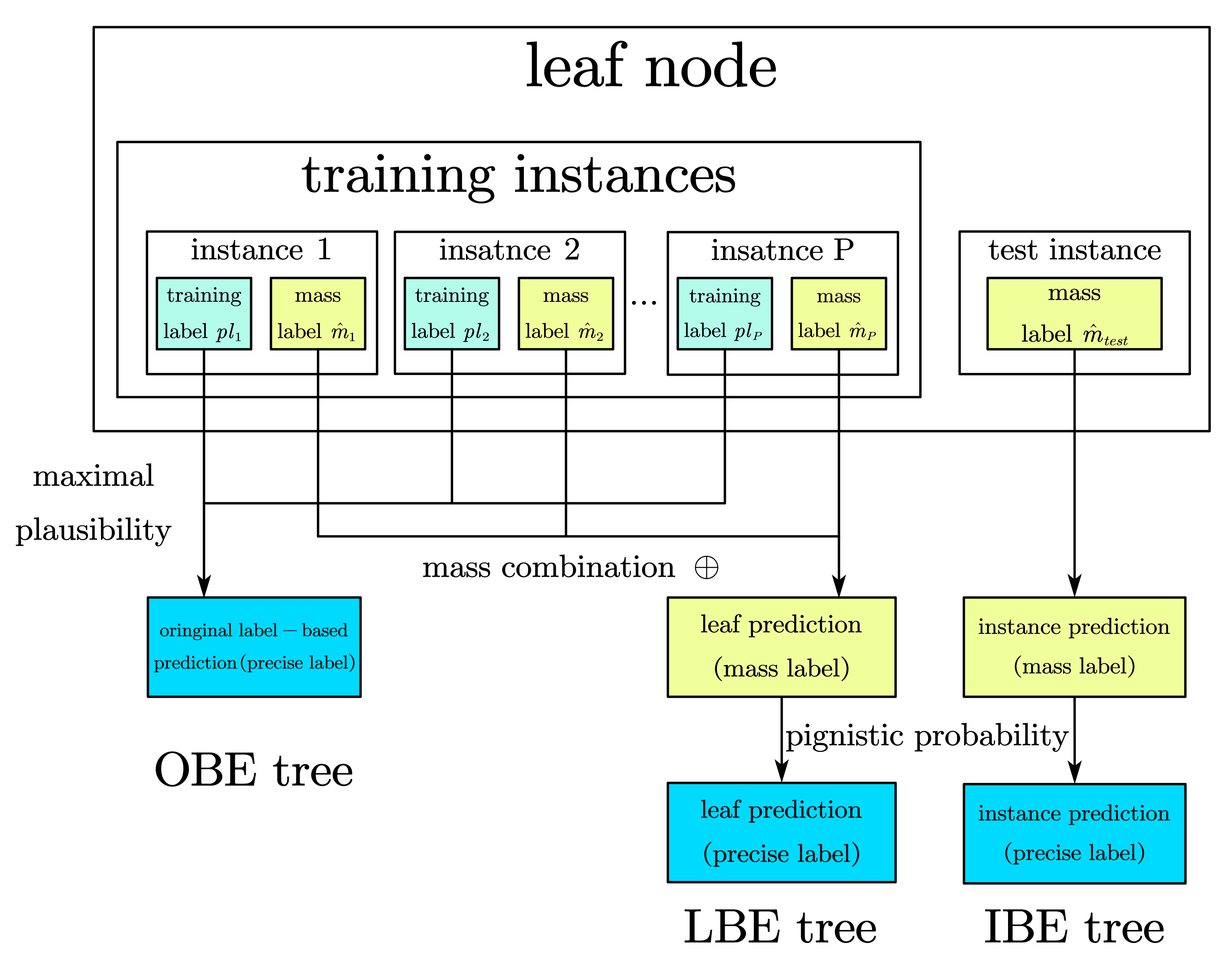
Figure 5 show the procedure of making prediction on leaf node, where
Figure 4 is the generation of mass prediction
for each instance, in whether training set or testing set;
Figure 5 details the different prediction making in the proposed three belief entropy trees.
4. Belief Entropy Random Forest
We have introduced the induction of belief entropy trees in the previous section, which is regarded as the basic classifier of random forest ensemble method in the following discussion.
The generalization ability of random forest draws from not only the perturbation of sampling, but also the perturbation of attributes selecting. Specific to the proposed belief entropy random forest, for each basic tree, we firstly performs bootstrap sampling on the original training set, which means randomly sampling with replacement for N times on the set T where . Secondly, when training on this resampling set, for each to-be-split node, the best splitting attribute will be chosen from a subset of the set of all available attributes , where . If , the basic tree splits totally, the same as the belief entropy tree; while means randomly selecting an attribute to split all the time.
Repeat the first and second steps above S times then a ‘forest’ containing variable basic trees will be constructed, where the repeat time S is called forest size. When making a prediction of a new instance on this forest, S primary predictions will be independently generated by S basic trees and finally summarized to one result. It should be mentioned that the OBE tree output precise label directly for testing instances while the LBE trees and IBE trees can provide mass labels described by BBAs or precise labels. This feature inspires two different strategies for making predictions in the last step: the majority voting for precise labels and belief combination of mass labels.
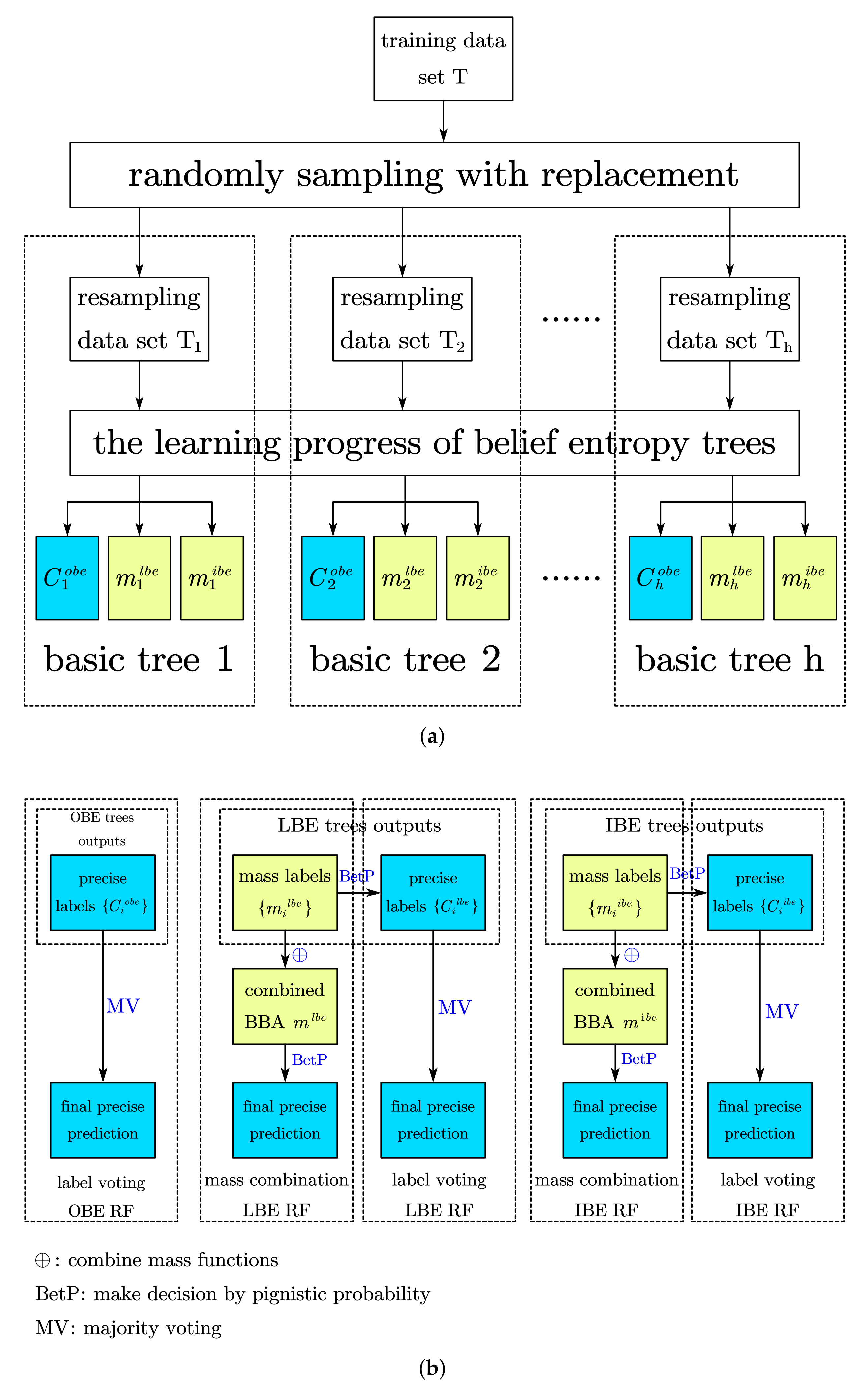
Algorithm 4 shows the procedure of building the complete evidential random forests based on belief entropy trees. Selecting different ensemble prediction strategies and base tree types, we build five random forest lists below:
label-voting Random Forest-, which performs majority voting on precise outputs of OBE trees;
label-voting Random Forest-, which performs majority voting on precise outputs of LBE trees;
mass-combination Random Forest-, which combines BBAs generated by LBE trees and makes decision;
label-voting Random Forest-, which performs majority voting on precise outputs of IBE trees;
mass-combination Random Forest-, which combines BBAs generated by IBE trees and makes decision;
| Algorithm 4 Building procedure of evidential random forests. |
Input: evidential training set , new instance , base classifier number h, base classifier type , base classifier output mode O Output: predicted label - 1:
for
do - 2:
; {The resampling procedure of each base tree.} - 3:
if then - 4:
;
- 5:
else if
then - 6:
; - 7.
else if
then - 8:
; - 9:
end if - 10:
end for - 11:
for
do - 12:
; {Generate predict labels of each base tree.} - 13:
end for - 14:
if
then - 15:
; {Generate prediction from precise labels.}
- 16:
else if
then - 17:
; {Generate prediction from mass labels.} - 18:
end if
|
Figure 6 shows the procedure of constructing the forests, in which the
Figure 6a shows generation of basic trees in a random forest, and
Figure 6b shows different procedure of combining the final prediction in five forests, which will lead to a different classification performance. We will evaluate them in the next section.
5. Experiments
In this section, we detail experiments to evaluate the performance of the proposed decision tree method. The experiment settings and results are detailed below.
5.1. Experiment Settings
As there are no widely accepted evidential data sets to measure the proposed method, it is necessary to generate a data set with ill-known labels from machine learning databases taken from the UCI repository [
46]. We selected several data sets, including: Iris, Wine, Balance scale, Breast cancer, Sonar and Ionosphere.
Denote the true label of a instance by , and give its uncertain observation . Due to the characters of belief function, we can simulate several situations from precise data:
- •
a observation is such that , and ;
- •
a observation is such that ;
- •
an observation is such that if or , and otherwise, where is a set of randomly selected labels;
- •
an observation is such that , and , where are sampled independently from uniform distribution .
To observe the performance on evidential training data sets with different ill-known types and incomplete degrees, we set three variables, vacuousness level , imprecision level and uncertainty level , to adjust the generation procedure, where .
Example 2 shows the transformed Iris data set and listed part of instances in
Table 1. In this example, labels of no.53 and no.54 instance are vacuous; labels of no.1 and no.2 instance are imprecise; labels of no.4 and no.52 instance are uncertain.
To improve the reliability and reduce the stochasticity, we performed 5-fold cross-validation on each data set and repeat ten times to compute an average classification accuracy for all experiments. Different tree induction techniques will be compared:
We set the maximal size of the leaf node as to avoid overfitting in the belief entropy trees. In the random forests, the forest size was set as 50, and the size of the attributes subset was set as .
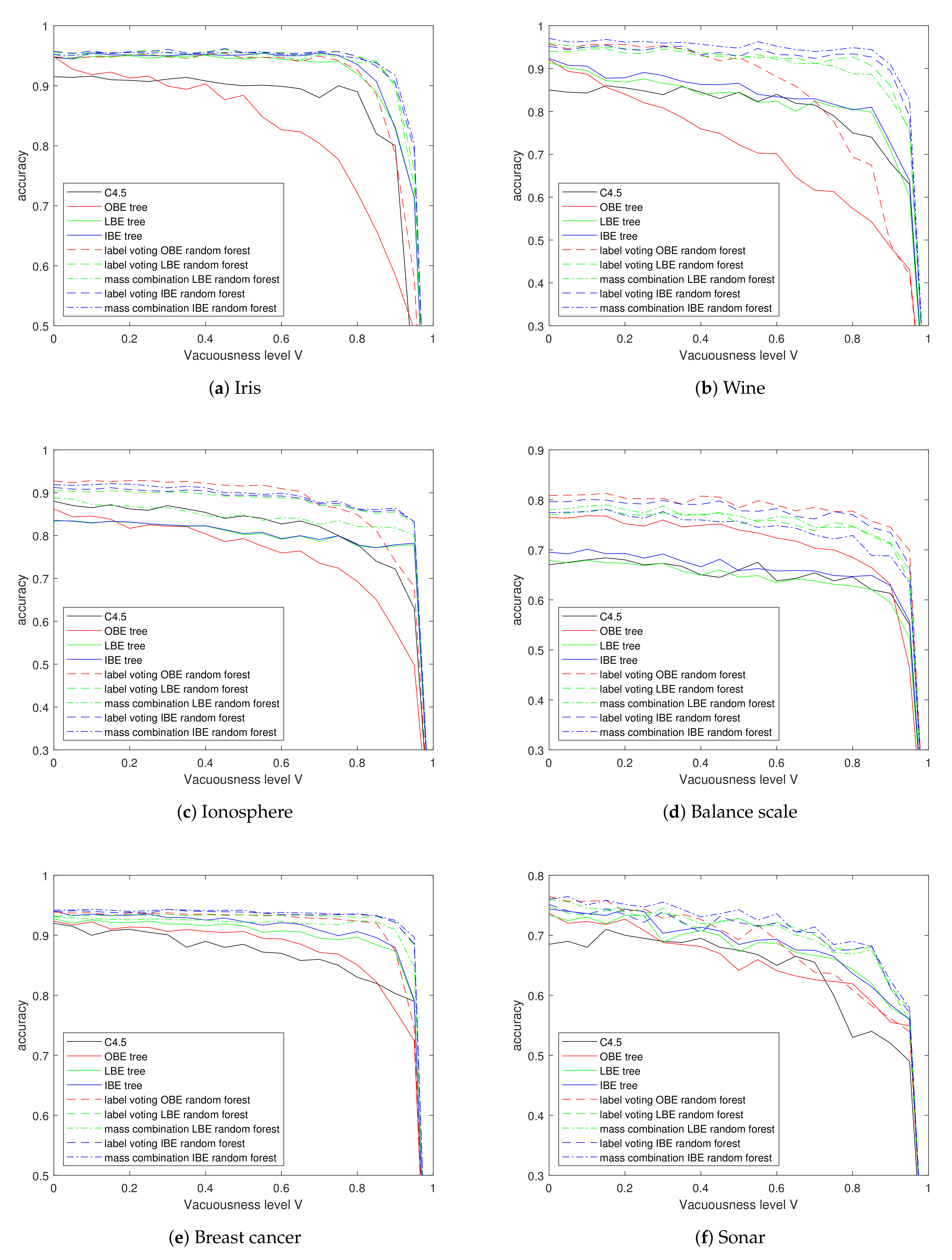
5.2. Experiments on Vacuous Data
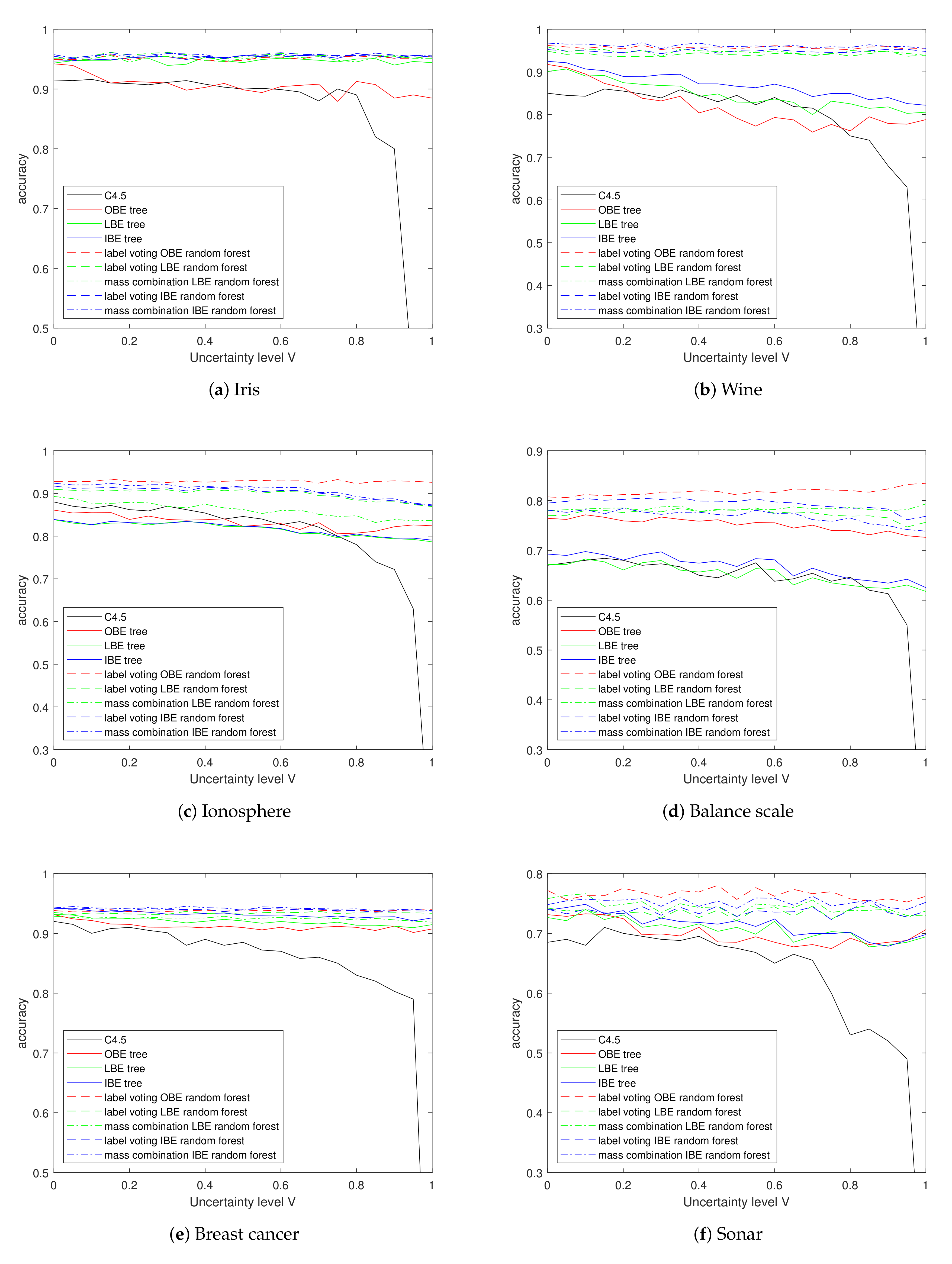
Assuming part of the instances in the training set are totally unobserved while others are completely observed, we performed experiments with different vacuousness levels
while
. Generating the training sets and learning on them, the results are shown in
Figure 7.
Firstly, we observe the figure as a whole. Obviously, whatever the tree induction method is, it is impossible to learn from data sets whose instances are all vacuous. Thus, the accuracy of all trees decreases gradually as
V increases, yet drops sharply when the
V approaches nearly to 1. On the contrary, almost all curves keep steady or decrease slightly before the vacuousness level reaches 80%, except for the OBE trees.
Table 4 shows the accuracy results when V equals 90%.
Considering the basic belief entropy trees firstly, the LBE trees and IBE trees perform, most of the time, at least as well as the traditional C4.5 decision trees, and better than the traditional decision trees for some time, especially when encountering high vacuousness level V; however, the OBE preforms elusively on different data sets: it has the lowest classification accuracy in Iris, Wine and Ionosphere data set; however, it achieves better results in the Balance scale. It is possible that if all samples in a leaf node are vacuous, the direct combination of all the training labels stays vacuous, which led to the shortage of OBE tree.
It can be observed that the belief entropy random forests perform well overall for their improvement in classification accuracy compared to the corresponding basic tree and the slower accuracy decent rate as V increases. Among these forests, the ones based on IBE and making prediction by mass combination performs better than others in nearly all data sets except the Balance scale.
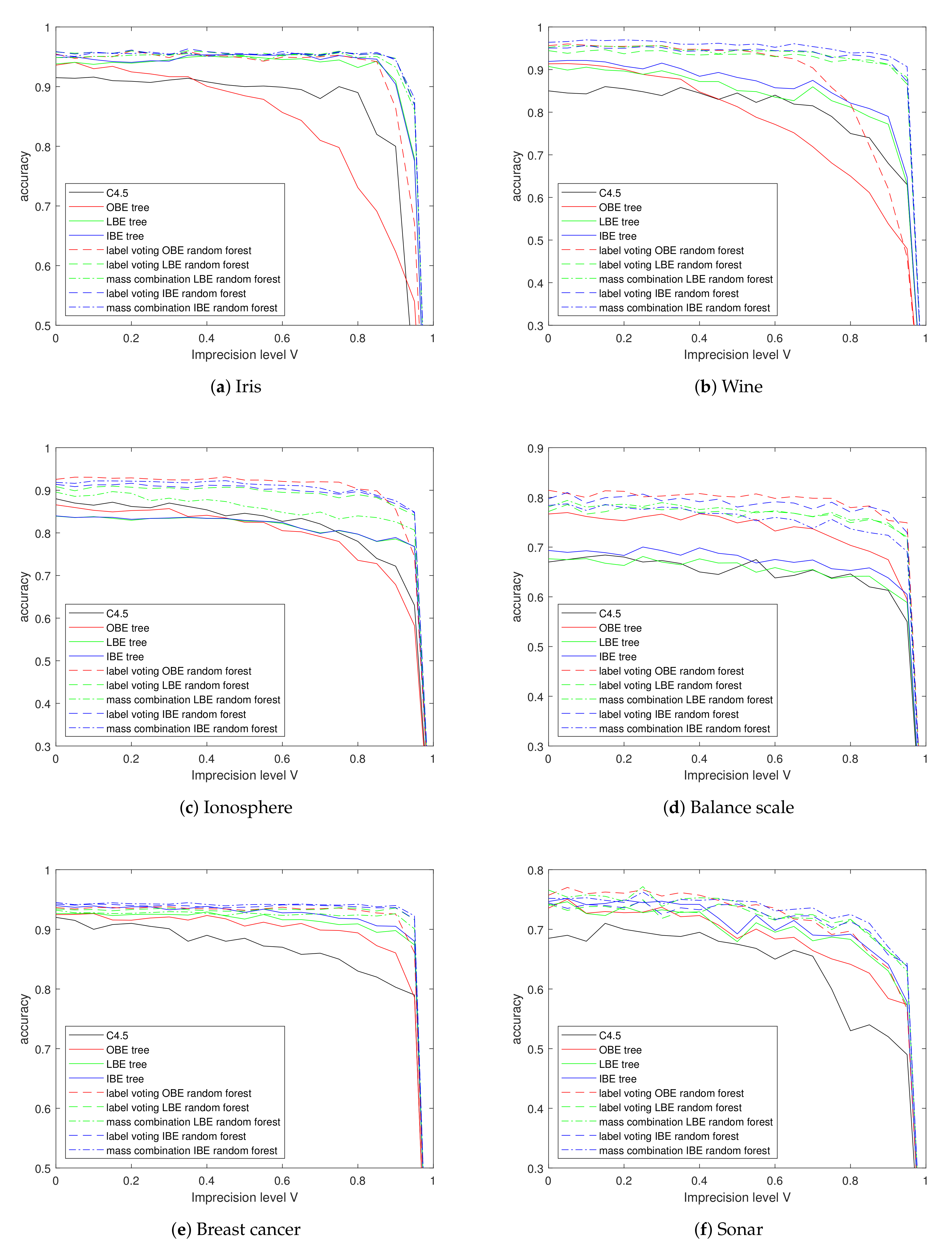
5.3. Experiments on Imprecise Data
The second situation is that some data are imprecisely observed, i.e., the observation is a set value, while the true value lies in this set (called superset labels [
47] in some works). As mentioned before, imprecision level
I controls the percentage of imprecise observations.
For the instance to be imprecise, we randomly generate a number
for each class
except the true one. Plausibility of labels with
will be set to 1. When the
, a training set becomes totally imprecise, which is, in practice, the same situation as total vacuousness; while
, instances are in a middle state of transition from precise to vacuous, which indicates a piece of similarity between the vacuous training set and the imprecise training set, i.e., we can tell that the imprecise sample contains more information than the totally vacuous ones. As a result, we can see in
Figure 8, that curves of accuracy with changing I are similar to those in experiments with vacuousness in
Figure 7, yet more smooth and full.
According to the
Table 5, the proposed methods keep pretty good classification results under high-level imprecise observations. OBE still keeps the shortage in almost all data sets while LBE and IBE achieve similar performance.
M-
keeps its advantage in most situations, especially in the Iris and Breast Cancer data; the classification accuracy is almost equal to the results on the total precise training set. The balance scale is a particular case to be discussed later.
5.4. Experiments on Uncertain Data
Another type of ill-known label is the uncertain one, which is measured by a plausibility distribution, with the true label having the highest chance among all class labels. To evaluate the performance of the proposed trees and forests in a more general situation with uncertainty, we set and . For instance, to be transformed into an uncertain one, we assign a value 1 to the plausibility of the true label and random values averagely sampled from to other labels.
Despite the inability to handle total vacuousness and imprecision, the belief entropy trees have the ability to learn from totally uncertain training data sets. The horizontal curves in
Figure 9 indicate all methods proposed in this paper keep stable performance with changing uncertainty level
U. On the whole, we can learn from the figure that LBE and IBE perform equally well and better than OBE as a single tree in most data sets, except in the Balance scale.
Considering the forests, for the good attribute normality of Iris, Wine and Breast cancer data, classification accuracies of the five forests on these data sets have similar performance according to
Table 6, leading to a heavy overlap of curves in figure. Among these trees, the OBE trees achieve the most significant improvement by building random forest; this improvement helps OBE-RF to surpass other forests in the Ionosphere, Sonar and Balance scale data sets. Particularly, in the Balance scale, the accuracy of OBE-RF even increases slightly as the
U decreases, which can be partially explained by the fact that uncertain instances are more informative then absolutely precise instances.
5.5. Summary
By carrying out experiments on training sets with different types and degrees of incomplete observation, we can conclude that the LBE trees and IBE trees, along with four types of random forests based on them, generally possess excellent learning ability on data with ill-known labels. Among the RFs, the ensemble of the IBE tree, L-IBE-RF and M-IBE RF achieve the highest classification accuracy in most situations except on samples with high uncertainty levels, especially on the Balance scale data set. We think there are two reasons: (a) compared to vacuous and imprecise samples, the learning labels of uncertain samples are more information rich, while the OBE use the learning labels to predict directly; (b) the attribute values of Ionosphere, Balance, and Sonar data sets contain less normality than others—the balance scale are totally not normal. We can conclude that the ensemble OBE RF requests less normality of the data set.
The results of experiments indicate that the application of the belief function tool to the prediction of trees and combination of forests is efficient and reasonable; yet there are also some drawbacks. Firstly, the introduction of the belief function and mass combination obviously increases the time cost of learning. The sensitivity to the normality of data makes the proposed trees and RFs unable to handle, to the greatest extent, all situations with one particular structure.
6. Conclusions
In this paper, a new classification tree method based on belief entropy is proposed to cope with uncertain data. This method directly models continuous attribute values of training data by algorithm, and selects a splitting attribute via a new tool–belief entropy. Differing from the traditional decision trees, we redesign the splitting and prediction, making them fit the feature of uncertain labels described by the belief function. Finally, random forests with different combination strategies were constructed on the basis of the proposed tree method to seek higher accuracy and stronger generalization ability.
As the experimental results show, the proposed belief entropy trees are robust to different sorts of uncertainty. They perform closely to traditional decision trees on precise data and keep good results on data with ill-known labels. Meanwhile, the belief entropy random forests, which improve significantly when compared to the basic belief function trees, achieve excellent and stable performance even in the situation with high-level uncertainty. It is proved that the proposed trees and random forests have a potentially broad field of application. In future research, some further improvements will be investigated, such as more reasonable BBA combination methods for the incapacity of Dempster’s rule to handle huge mass conflict, and a boosting ensemble method based on the belief entropy trees.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}