
Thresholding Approach for Low-Rank Correlation Matrix Based on MM Algorithm


Abstract
:1. Background
2. Method
2.1. Adaptive Thresholding for Sparse and Low-Rank Correlation Matrix Estimation
2.1.1. Optimization Problem of Low-Rank Correlation Matrices
2.1.2. Estimation of Low-Rank Correlation Matrices Based on MM Algorithm
| Algorithm 1 Algorithm for estimating the low-rank correlation matrix |
| Input:, and small constant |
| Output: |
| Initialisation: Set satisfying for all j and set |
| 1: while do |
| 2: for to p |
| 3: Calculate |
| 4: Calculate to be the largest eigenvalue of |
| 5: Update based on Equation (8). |
| 6: End for |
| 7: |
| 8: End while |
| 9: return with the constraint for all j |
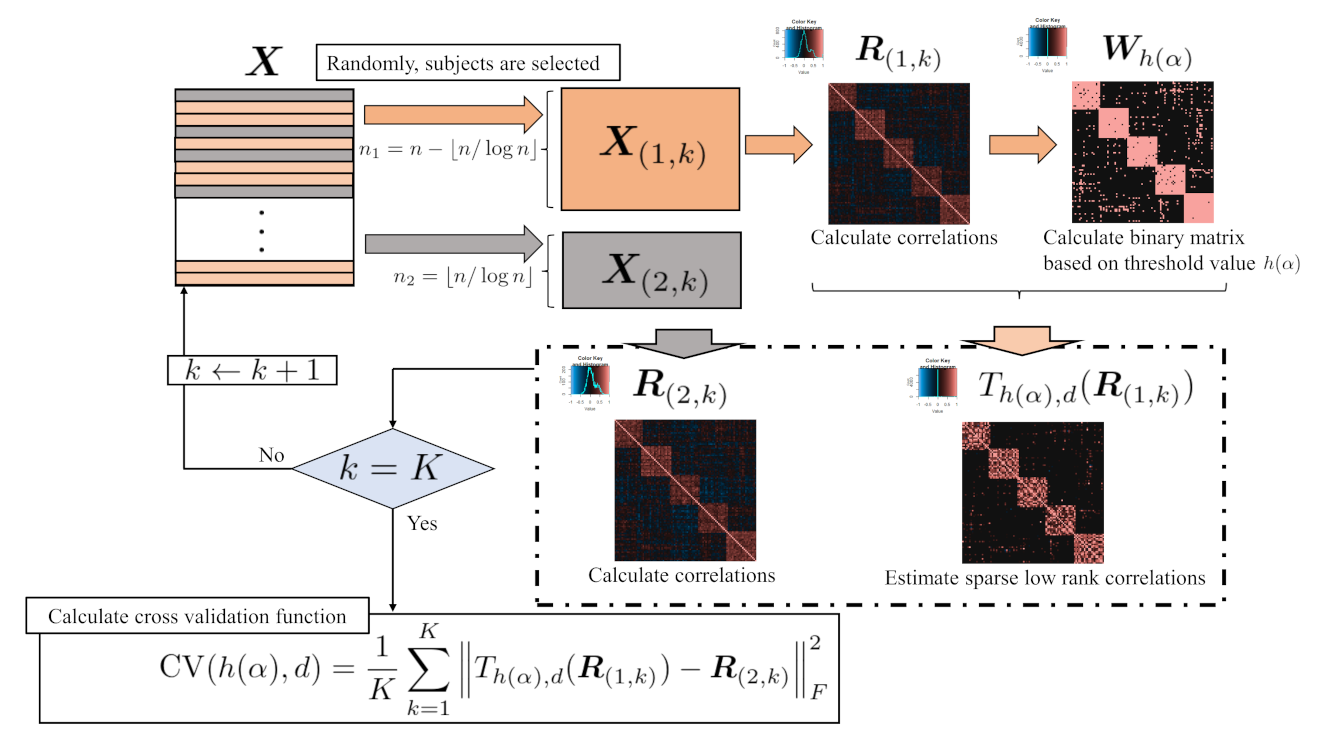
2.1.3. Proposed Algorithm of Cross-Validation to Determine Hard Thresholds
| Algorithm 2 Algorithm of Cross-validation for tuning proportional thresholds |
| Input: candidates of threshold values , and |
| Output: |
| Initialisation: Set with the length of |
| 1: For to |
| 2: For to K |
| 3: Split into and |
| 4: Calculate both and |
| 5: Calculate from corresponding and . |
| 6: Given and , Algorithm 1 is applied to estimate , |
| 7: End For |
| 8: calculate |
| 9: |
| 10: End For |
| 11: |
| 12: return |
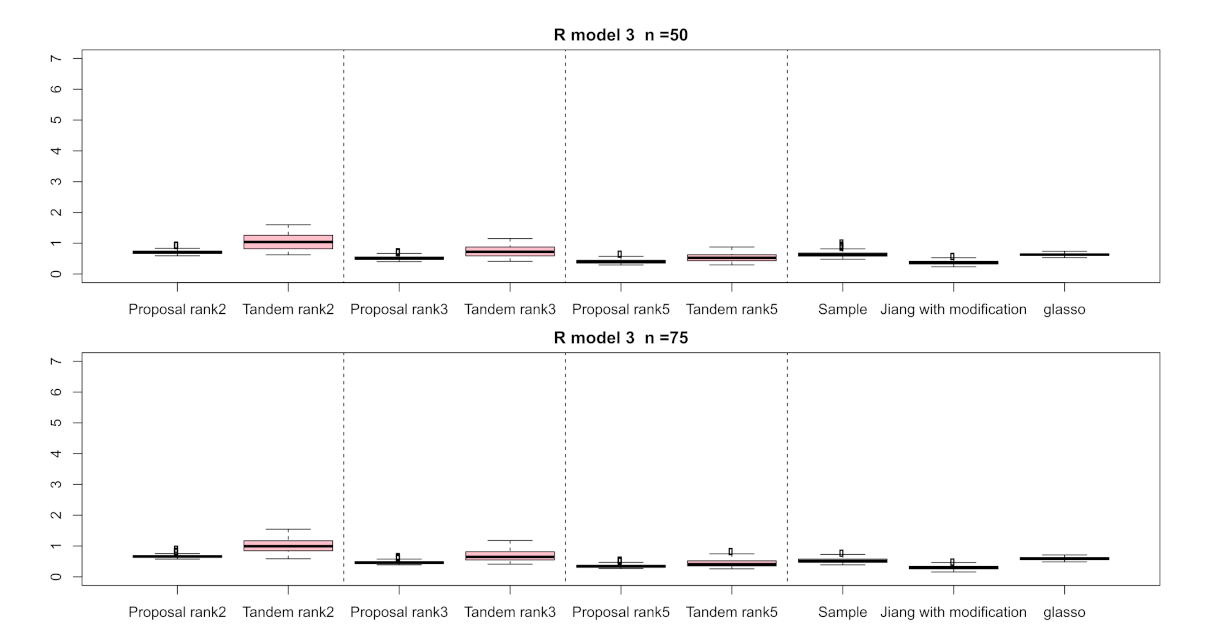
2.2. Numerical Simulation and Real Example
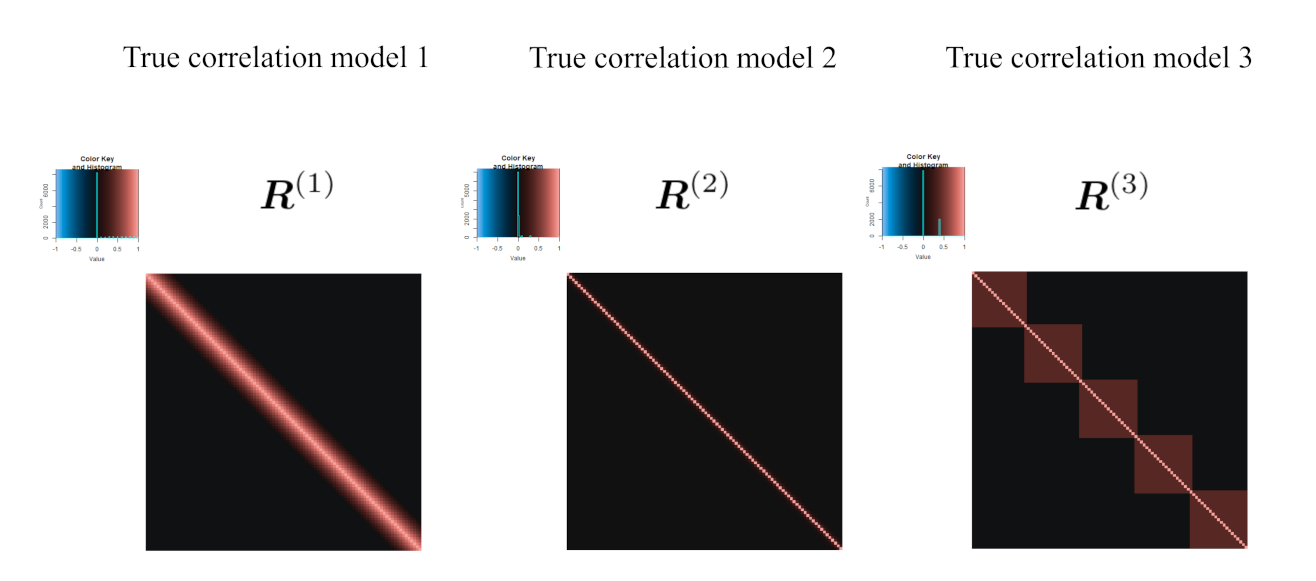
2.2.1. Simulation Design of Numerical Simulation
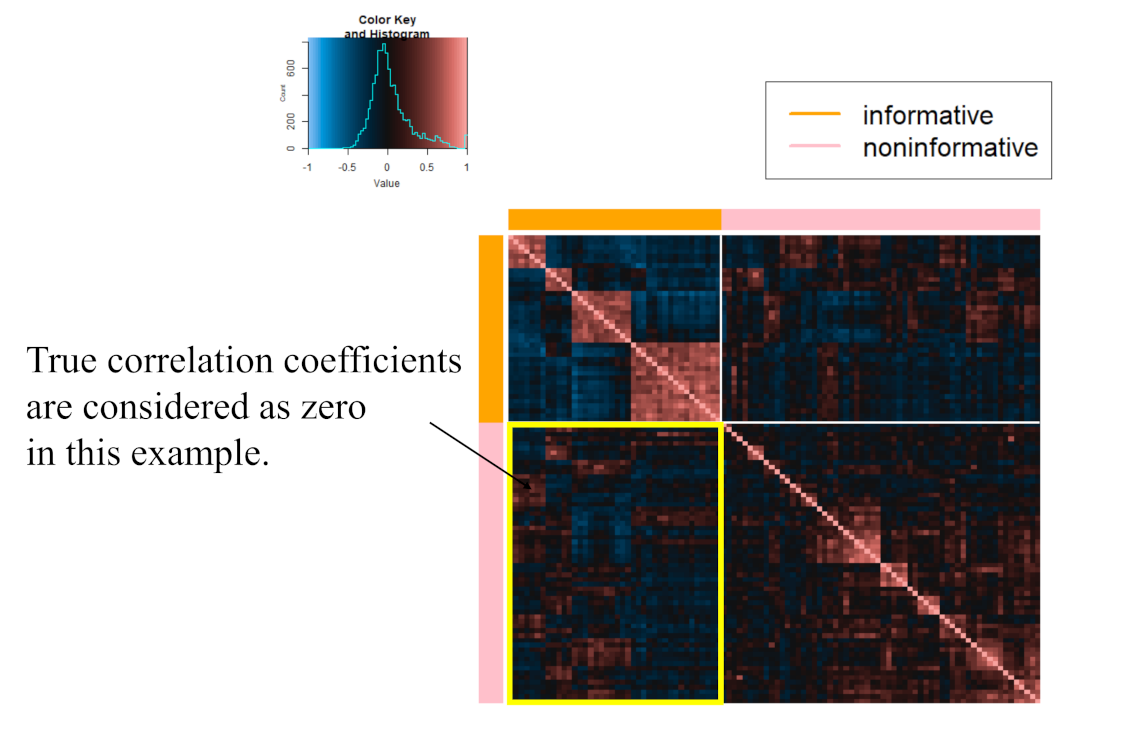
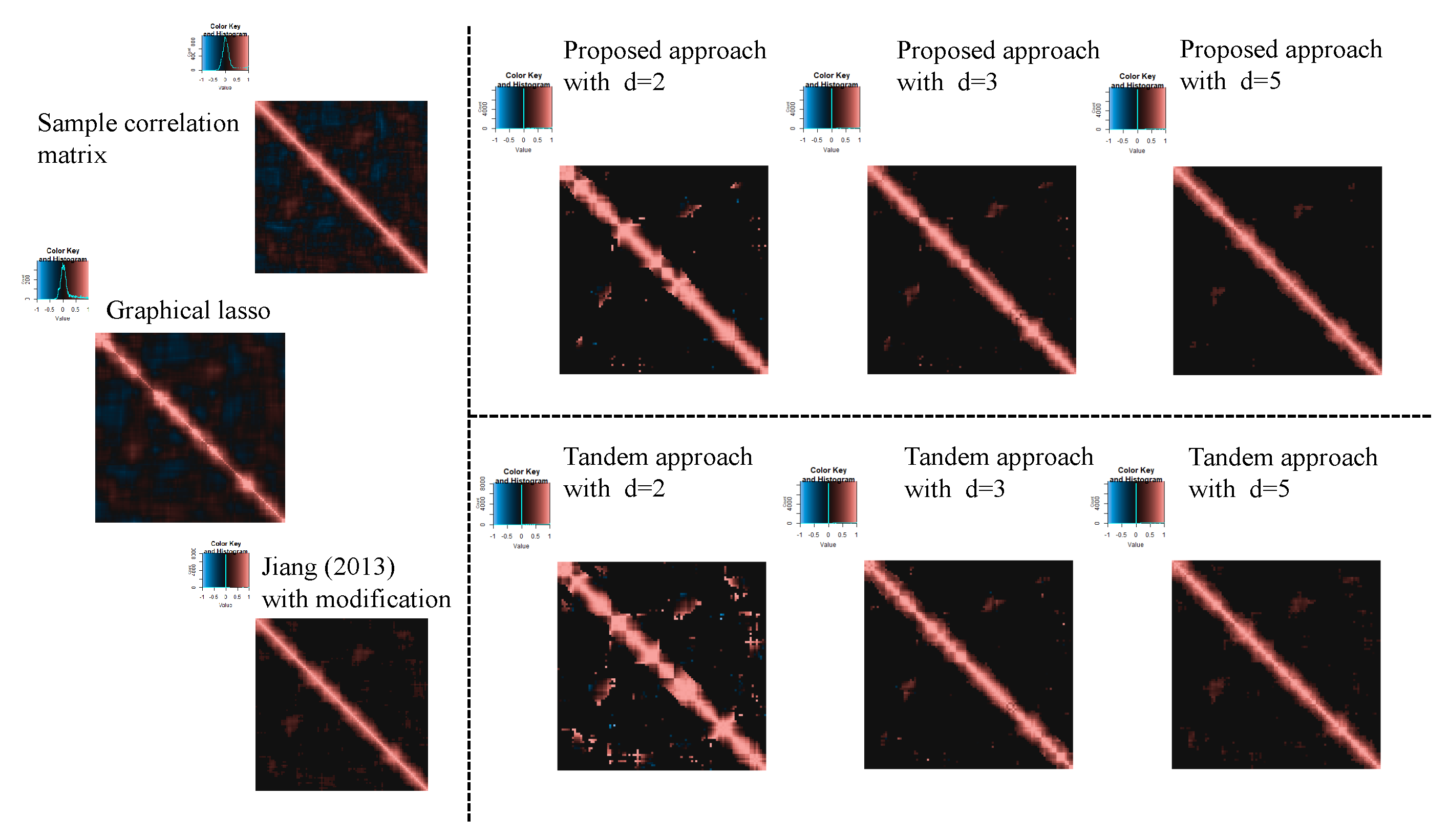
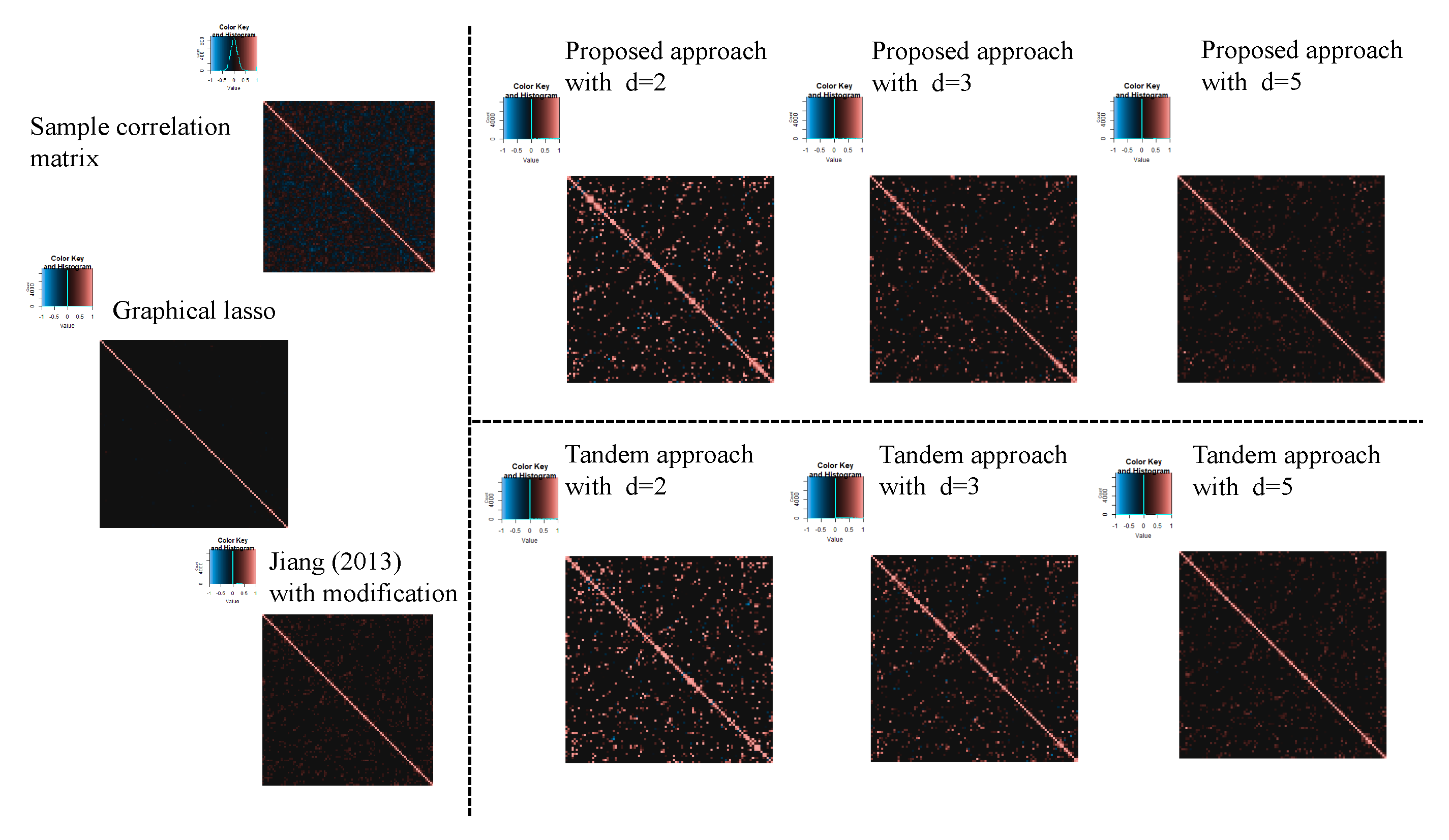
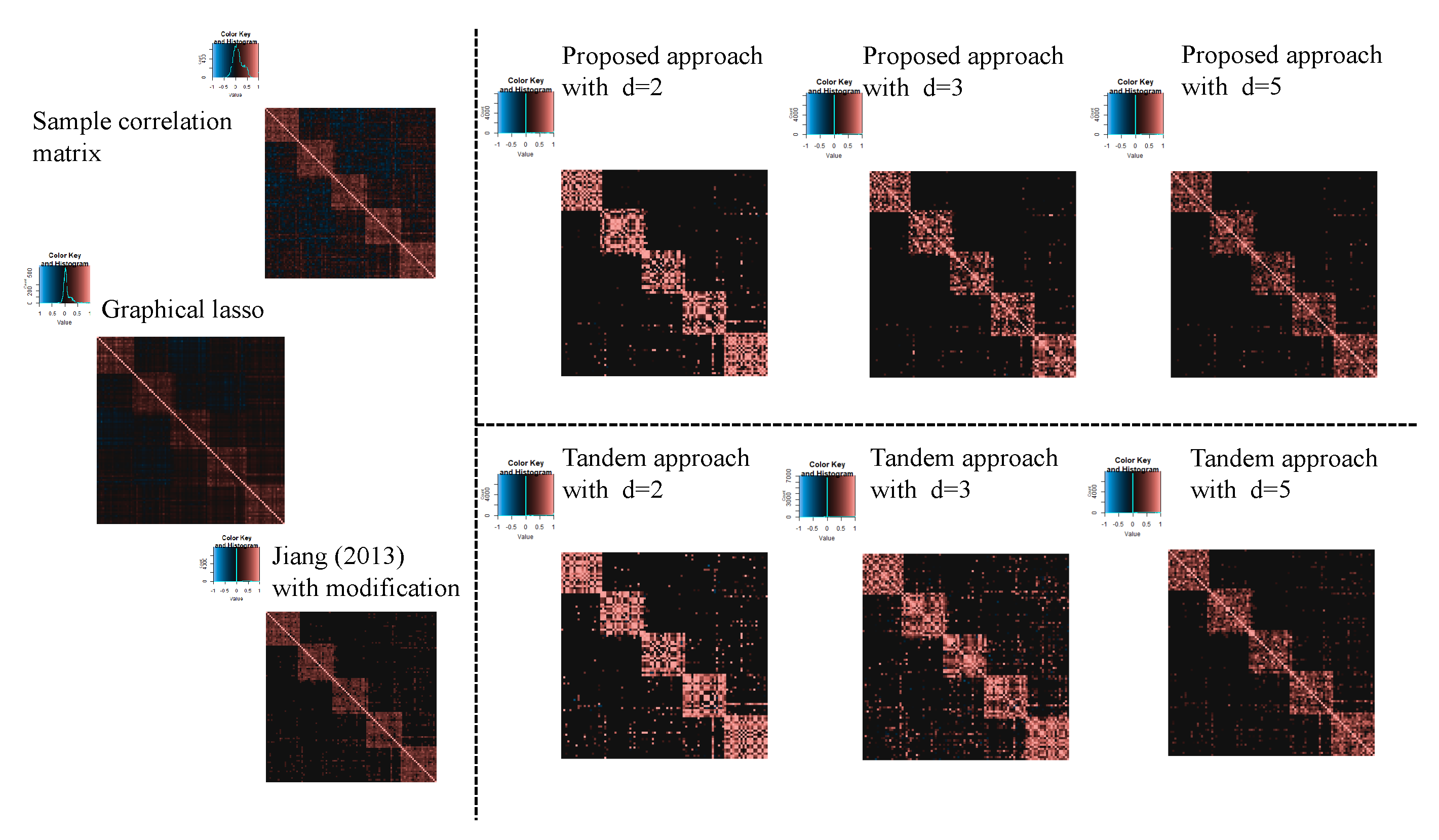
2.2.2. Application of Microarray Gene Expression Dataset
3. Results
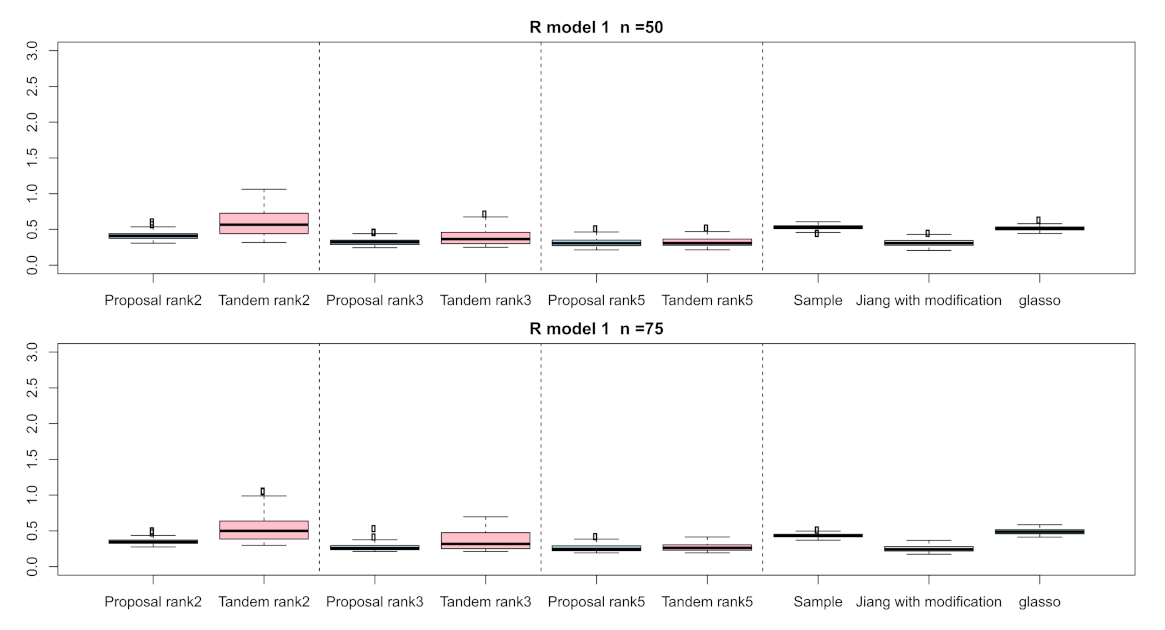
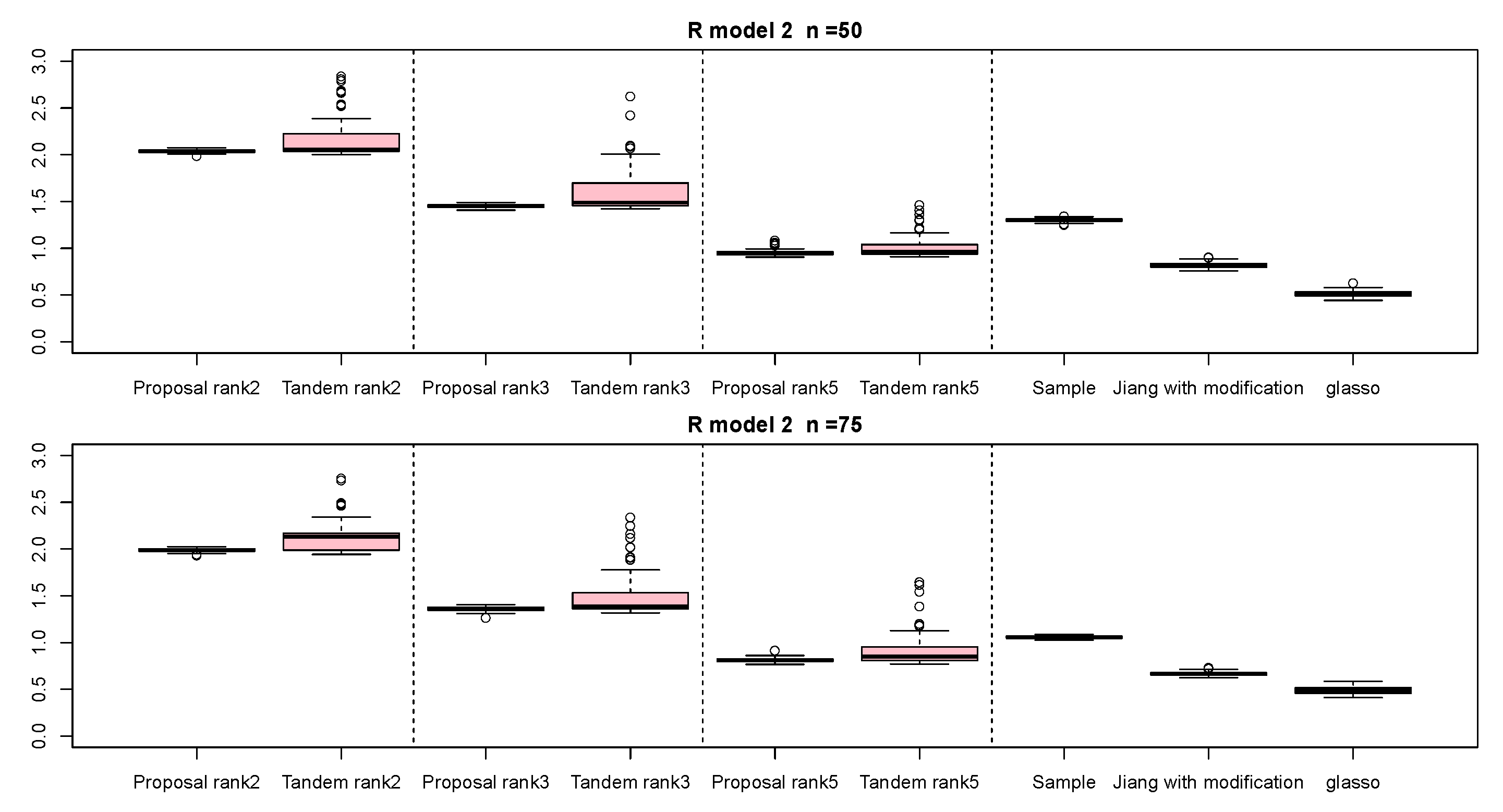
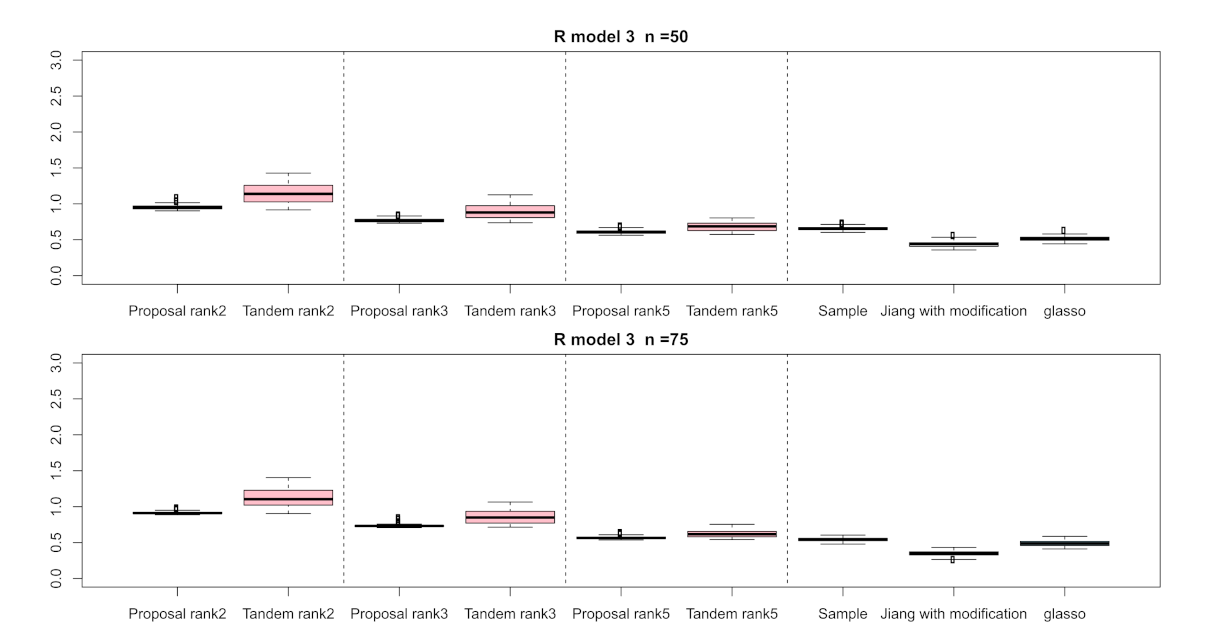
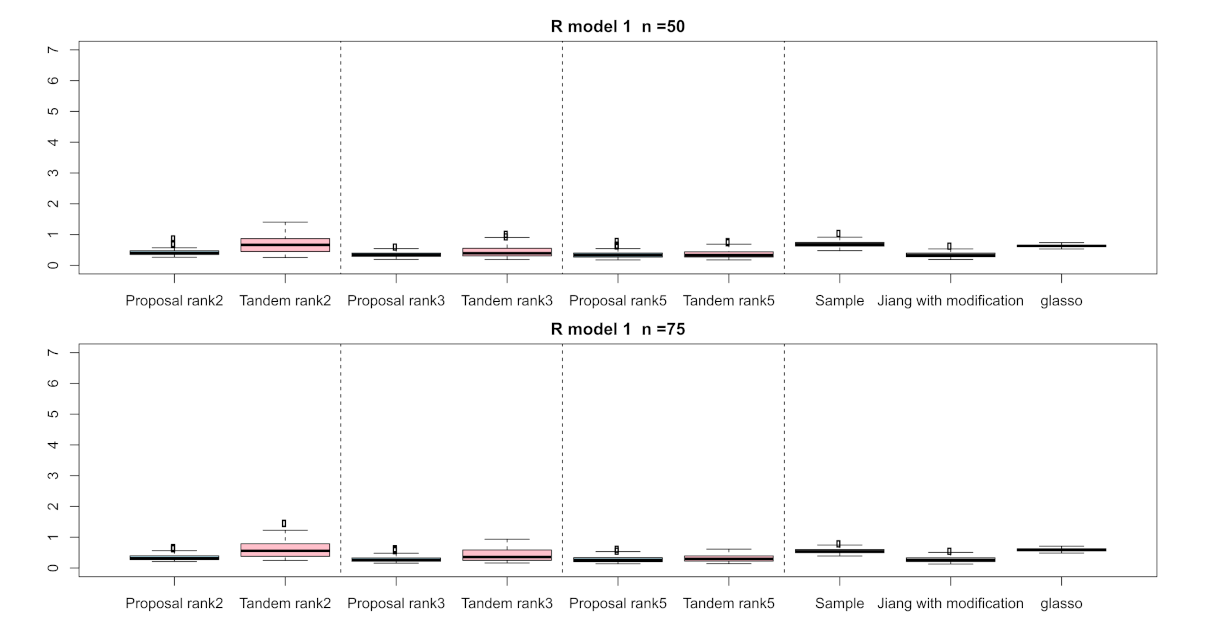
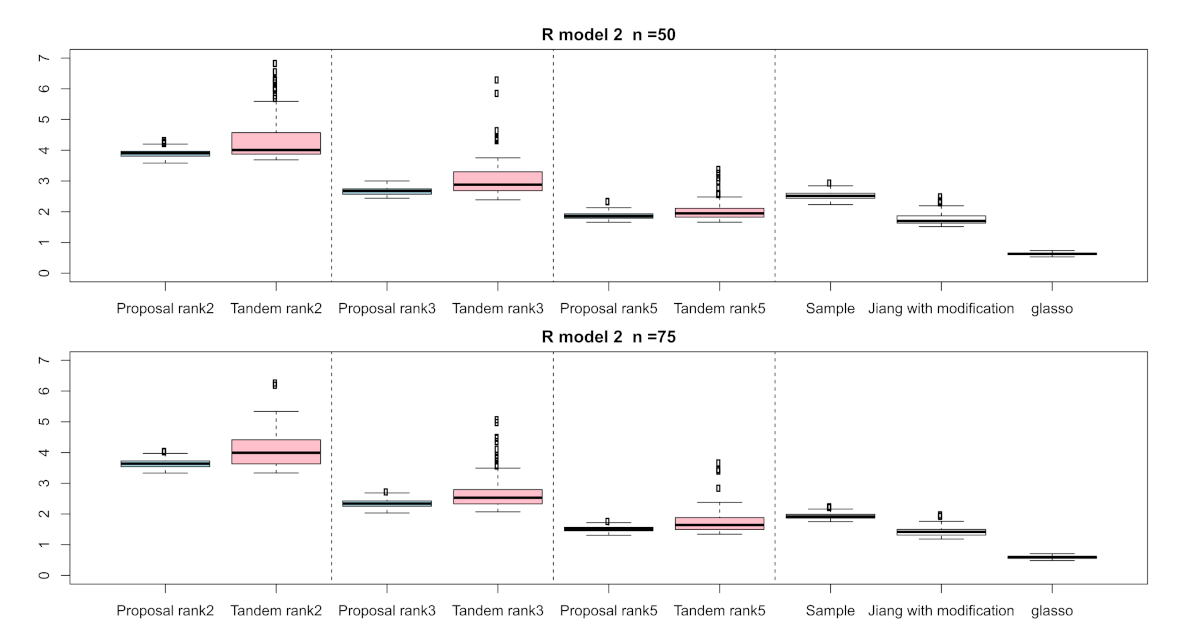
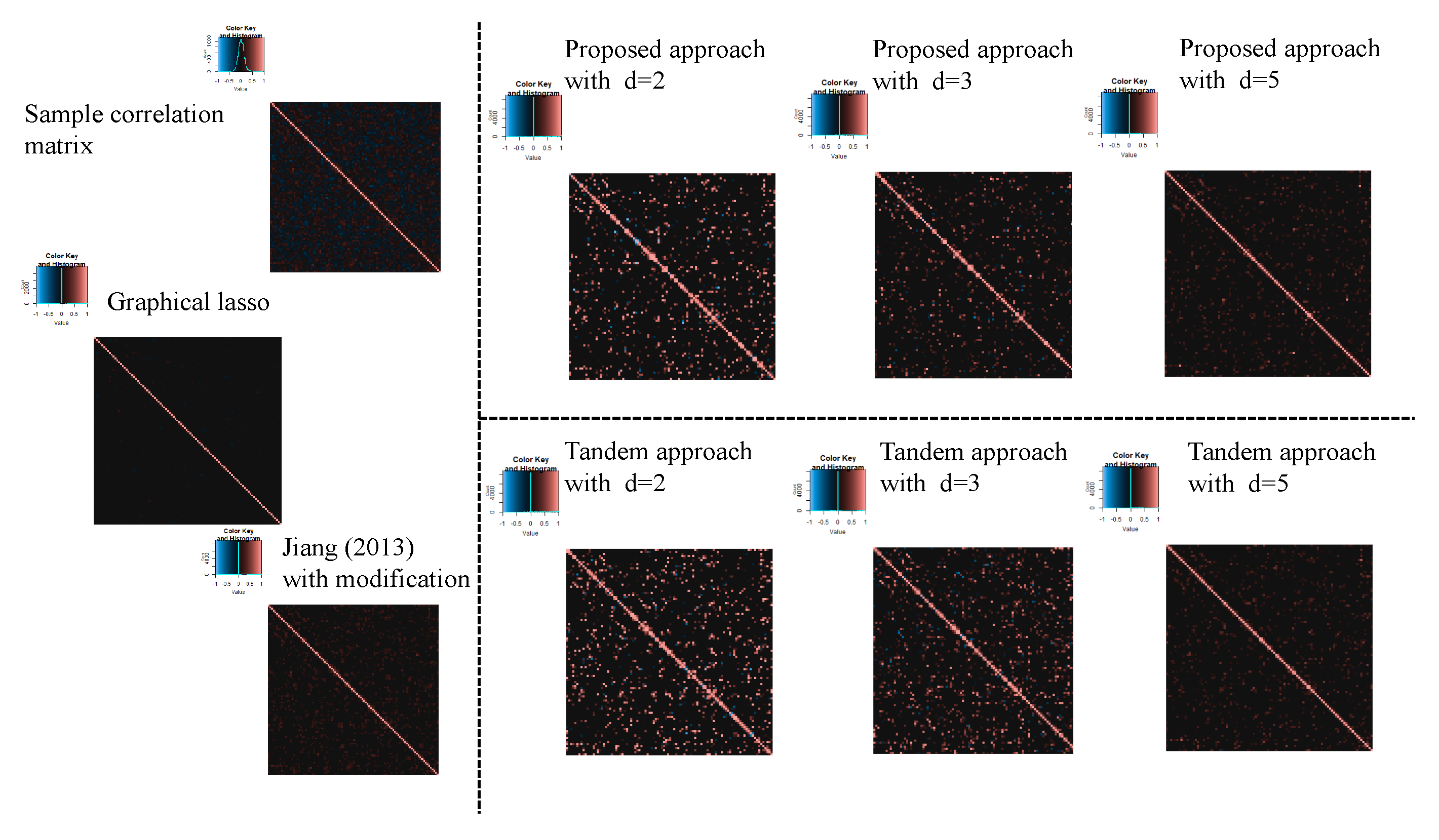
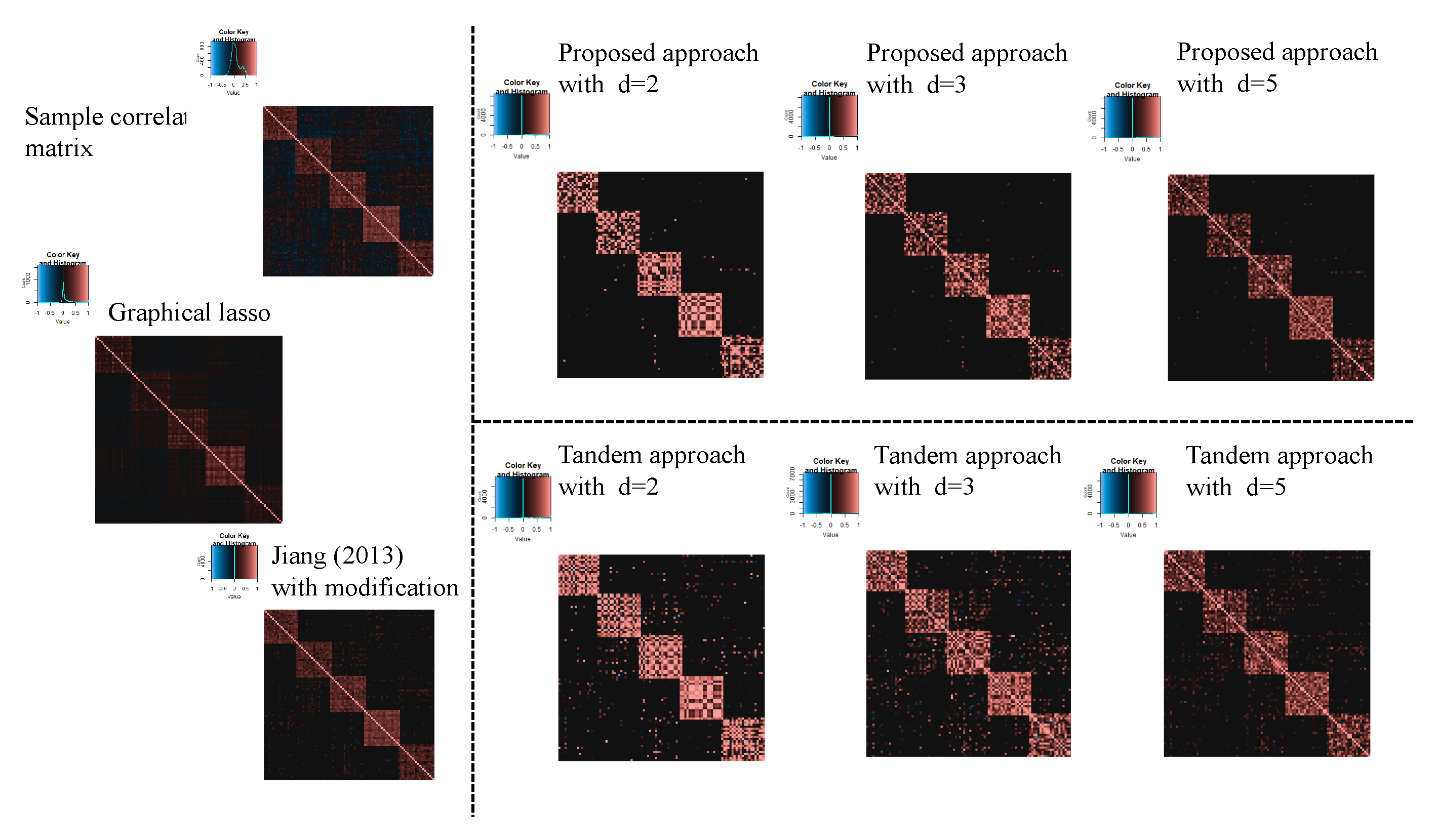
3.1. Simulation Result
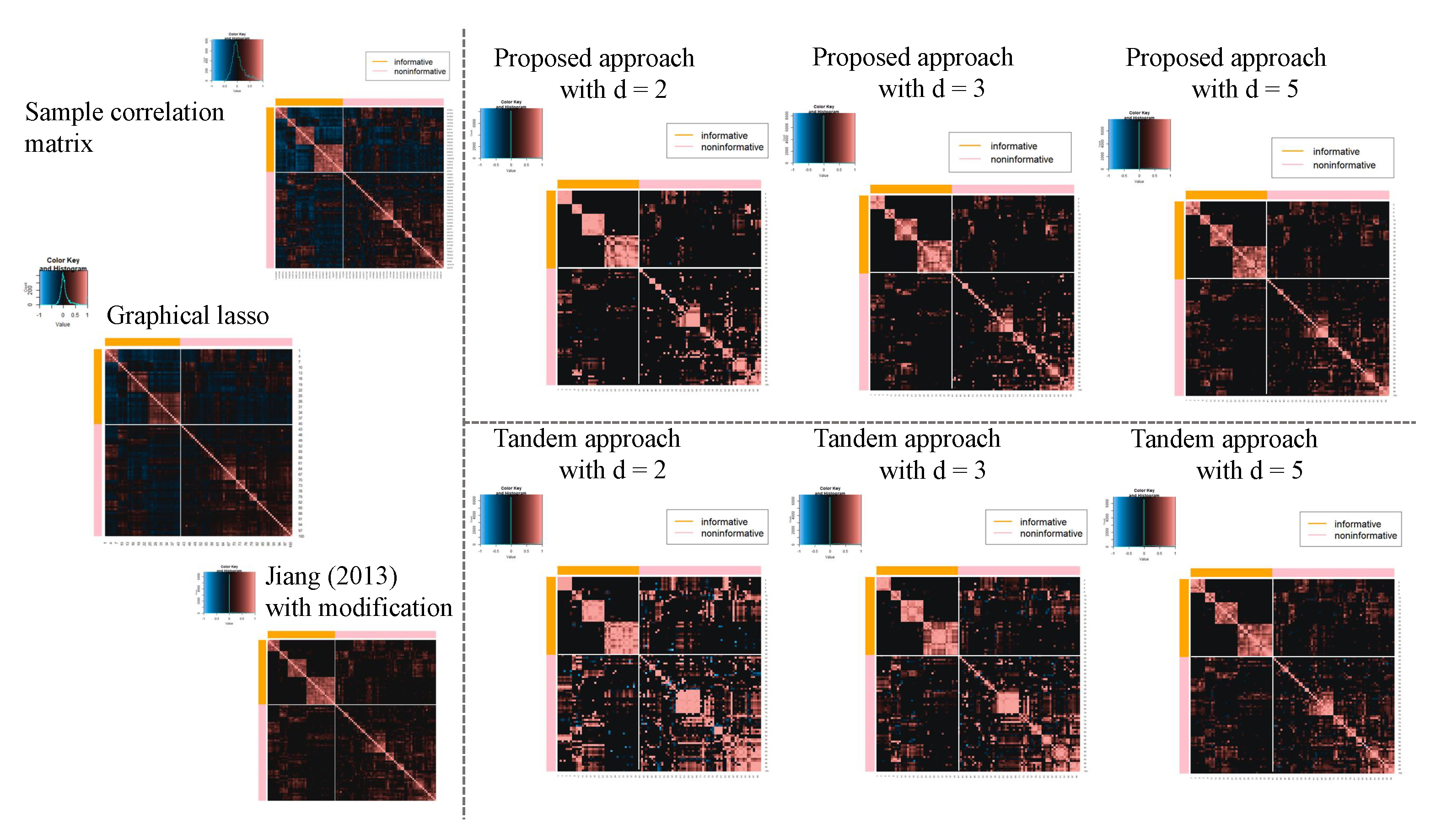
3.2. Result of Application of Microarray Gene Expression Dataset
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MM | Majorize-minimization |
| DOAJ | Directory of open access journals |
| TLA | Three letter acronym |
| LD | Linear dichroism |
| FPR | False Positive Rate |
| TPR | True Positive Rate |
| F-norm | Frobenius norm |
| S-norm | Spectral norm |
| SRBCT | Small round blue cell tumours of childhood |
| NB | Neuroblastoma |
| RMS | Rhabdomyosarcoma |
| BL | Burkitt lymphoma, a subset of non-Hodgkin lymphoma |
| EWS | Ewing family of tumours |
References
- Wilkinson, L.; Friendly, M. The history of the cluster heat map. Am. Stat. 2009, 36, 179–184. [Google Scholar] [CrossRef] [Green Version]
- Ten Berge, J. Least Squares Optimization in Multivariate Analysis; DSWO Press: Leiden, The Netherlands, 1993. [Google Scholar]
- Pietersz, R.; Groenen, P. Rank reduction of correlation matrices by majorization. Quant Financ. 2004, 4, 649–662. [Google Scholar] [CrossRef] [Green Version]
- Simon, D.; Abell, J. A majorization algorithm for constrained approximation. Linear Algebra Its Appl. 2010, 432, 1152–1164. [Google Scholar] [CrossRef] [Green Version]
- Grubisic, I.; Pietersz, R. Efficient rank reduction of correlation matrices. Linear Algebra Its Appl. 2007, 422, 629–653. [Google Scholar] [CrossRef] [Green Version]
- Duan, X.; Bai, J.; Li, J.; Peng, J. On the low rank solution of the q-weighted nearest correlation matrix problem. Numer. Linear Algebra Appl. 2016, 23, 340–355. [Google Scholar] [CrossRef]
- Ding, C.; He, X. k-means clustering via principle component analysis. In Proceedings of the International Conference on Machine Learning (ICML), Banff, AB, Canada, 4–8 July 2004. [Google Scholar]
- Eckart, C.; Young, G. The approximation of one matrix by another of lower rank. Psychometrika 1936, 1, 211–218. [Google Scholar] [CrossRef]
- Engel, J.; Buydens, L.; Blanchet, L. An overview of large-dimensional covariance and precision matrix estimators with applications in chemometrics. J. Chemom. 2017, 31, e2880. [Google Scholar] [CrossRef]
- Lam, C. High-dimensional covariance matrix estimation. Wiley Interdiscip. Rev. Comput. Stat. 2020, 12, e1485. [Google Scholar] [CrossRef]
- Bien, J.; Tibshirani, R. Sparse estimation of a covariance matrix. Biometrika 2011, 99, 807–820. [Google Scholar] [CrossRef] [Green Version]
- Rothman, A. Positive definite estimators of large covariance matrices. Biometrika 2012, 99, 733–740. [Google Scholar] [CrossRef]
- Xue, L.; Ma, S.; Zou, H. Positive definite L1 penalized estimation of large covariance matrices. J. Am. Stat. Assoc. 2012, 107, 1480–1491. [Google Scholar] [CrossRef] [Green Version]
- Cai, T.; Liu, W.; Luo, X. A constrained ℓ1 minimization approach to sparse precision matrix estimation. J. Am. Stat. Assoc. 2011, 106, 594–607. [Google Scholar] [CrossRef] [Green Version]
- D’aspremont, A.; Banerjee, O.; Ghaoui, L. First-order methods for sparse covariance selection. SIAM J. Matrix Anal. Appl. 2008, 30, 56–66. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.; Hastie, T.; Tibshirani, R. Sparse inverse covariance estimation with the graphical lasso. Biostatistics 2008, 9, 432–441. [Google Scholar] [CrossRef] [Green Version]
- Rothman, A.; Bickel, P.; Levina, E.; Zhu, J. Sparse permutation invariant covariance estimation. Electron. J. Stat. 2008, 2, 495–515. [Google Scholar] [CrossRef]
- Yuan, M.; Lin, Y. Model selection and estimation in Gaussian graphical model. Biometrika 2007, 94, 19–35. [Google Scholar] [CrossRef] [Green Version]
- Cui, Y.; Leng, C.; Sun, D. Sparse estimation of high-dimensional correlation matrices. Comput. Stat. Data Anal. 2016, 93, 390–403. [Google Scholar] [CrossRef]
- Bickel, P.; Levina, E. Covariance regularization by thresholding. Ann. Stat. 2008, 36, 2577–2604. [Google Scholar] [CrossRef]
- Cai, T.; Liu, W. Adaptive thresholding for sparse covariance matrix estimation. J. Am. Stat. Assoc. 2011, 106, 594–607. [Google Scholar] [CrossRef] [Green Version]
- Bickel, P.; Levina, E. Regularized estimation of large covariance matrices. Ann. Stat. 2008, 36, 199–227. [Google Scholar] [CrossRef]
- El Karoui, N. Operator norm consistent estimation of large-dimensional sparse covariance matrices. Ann. Stat. 2008, 36, 2717–2756. [Google Scholar] [CrossRef]
- Jiang, B. Covariance selection by thresholding the sample correlation matrix. Stat. Probab. Lett. 2013, 83, 2492–2498. [Google Scholar] [CrossRef]
- Rothman, A.; Levina, E.; Zhu, J. Generalized thresholding of large covariance matrices. J. Am. Stat. Assoc. 2009, 104, 177–186. [Google Scholar] [CrossRef]
- Lam, C.; Fan, J. Sparsistency and rates of convergence in large covariance matrices estimation. Ann. Stat. 2009, 37, 4254–4278. [Google Scholar] [CrossRef]
- Liu, H.; Wang, L.; Zhao, T. Sparse covariance matrix estimation with eigenvalue constraints. J. Comput. Graph. Stat. 2014, 37, 439–459. [Google Scholar] [CrossRef] [Green Version]
- Zhou, S.; Xiu, N.; Luo, Z.; Kong, L. Sparse and low-rank covariance matrix estimation. J. Oper. Res. Soc. China 2015, 3, 231–250. [Google Scholar] [CrossRef]
- Savalle, P.; Richard, E.; Vayatis, N. Estimation of simultaneously sparse and low rank matrices. In Proceedings of the International Conference on Machine Learning (ICML), Edinburgh, UK, 26 June–1 July 2012. [Google Scholar]
- Pourahmadi, M. Joint mean-covariance models with applications to longitudinal data: Unconstrained parameterisation. Biometrika 1999, 86, 677–690. [Google Scholar] [CrossRef]
- Chang, C.; Tsay, R. Estimation of covariance matrix via the sparse Cholesky factor with lasso. J. Stat. Plan. Inference 2010, 86, 677–690. [Google Scholar] [CrossRef]
- Kang, X.; Wang, M. Ensemble sparse estimation of covariance structure for exploring genetic desease data. Comput. Stat. Data Anal. 2021, 159, 107220. [Google Scholar] [CrossRef]
- Li, C.; Yang, M.; Wang, M.; Kang, H.; Kang, X. A Cholesky-based sparse covariance estimation with an application to genes data. J. Biopharm. Stat. 2021, 31, 603–616. [Google Scholar] [CrossRef]
- Yang, W.; Kang, X. An improved banded estimation for large covariance matrix. Commun.-Stat.-Theory Methods 2021. [Google Scholar] [CrossRef]
- Kang, X.; Deng, X. On variable ordination of Cholesky-based estimation for a sparse covariance matrix. Can. J. Stat. 2021, 49, 283–310. [Google Scholar] [CrossRef]
- Niu, L.; Liu, X.; Zhao, J. Robust estimator of the correlation matrix with sparse Kronecker structure for a high-dimensional matrix-variate. J. Multivar. Anal. 2020, 177, 104598. [Google Scholar] [CrossRef]
- Knol, D.; Ten Berge, J. Least-squares approximation of an improper correlation matrix by a proper one. Psychometrika 2012, 54, 53–61. [Google Scholar] [CrossRef]
- Hunter, D.; Lange, K. A tutorial on MM algorithm. Am. Stat. 2004, 58, 30–37. [Google Scholar] [CrossRef]
- van den Heuvel, M.; de Lange, S.; Zalesky, A.; Seguin, C.; Thomas Yeo, B.; Schmidt, R. Proportional thresholding in resting-state fMRI functional connectivity networks and consequences for patient-control connectome studies: Issues and recommendations. NeuroImage 2017, 152, 437–449. [Google Scholar] [CrossRef]
- Khan, J.; Wei, J.S.; Ringner, M.; Saal, L.H.; Ladanyi, M.; Westermann, F.; Berthold, F.; Schwab, M.; Antonescu, C.R.; Meltzer, P.S.; et al. Classification and diagnostic prediction of cancers using gene expression profiling and artificial neural networks. Nat. Med. 2001, 7, 673–679. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Sparse inverse covariance estimation with the lasso. arXiv 2007, arXiv:0708.3517. [Google Scholar]
- Galloway, M. CVglasso: Lasso Penalized Precision Matrix Estimation; R package version 1.0.; 2018. Available online: https://cran.r-project.org/web/packages/CVglasso/index.html (accessed on 17 April 2022).
- Culhane, A.; Thioulouse, J.; Perriere, G.; Higgins, D. MADE4: An R package for multivariate analysis of gene expression data. Bioinformatics 2005, 21, 2789–2790. [Google Scholar] [CrossRef] [Green Version]
- Candes, E.; Tao, T. The power of convex relaxation: Near-optimal matrix completion. IEEE Trans. Inf. Theory 2010, 56, 2053–2080. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Setting Name | Levels | Description |
|---|---|---|
| Setting 1: The number of subjects | 2 | |
| Setting 2: Rank | 3 | |
| Setting 3: True correlation model | 3 | Equations (14)–(16) |
| Setting 4: Methods | 5 | proposed approach, tandem approach, sample correlation, Jiang (2013) with modification, and graphical lasso |
| Methods | d | FPR | TPR | Sparsity | |
|---|---|---|---|---|---|
| Sample correlation matrix | − | − | − | ||
| Jiang (2013) with modifications | |||||
| Graphical lasso | |||||
| Tandem | 2 | ||||
| Proposal | |||||
| Tandem | 3 | ||||
| Proposal | |||||
| Tandem | 5 | ||||
| Proposal | |||||
| Sample correlation matrix | − | − | − | ||
| Jiang (2013) with modifications | |||||
| Graphical lasso | |||||
| Tandem | 2 | 0.80 | |||
| Proposal | 0.85 | ||||
| Tandem | 3 | 0.79 | |||
| Proposal | 0.84 | ||||
| Tandem | 5 | 0.79 | |||
| Proposal | 0.81 |
| Methods | d | FPR | TPR | Sparsity | |
|---|---|---|---|---|---|
| Sample correlation matrix | − | − | − | ||
| Jiang (2013) with modifications | − | ||||
| Graphical lasso | − | ||||
| Tandem | 2 | − | 0.84 | ||
| Proposal | − | 0.86 | |||
| Tandem | 3 | − | 0.83 | ||
| Proposal | − | 0.86 | |||
| Tandem | 5 | − | 0.84 | ||
| Proposal | − | 0.85 | |||
| Sample correlation matrix | − | − | − | ||
| Jiang (2013) with modifications | − | ||||
| Graphical lasso | − | ||||
| Tandem | 2 | − | 0.84 | ||
| Proposal | − | 0.86 | |||
| Tandem | 3 | − | 0.83 | ||
| Proposal | − | 0.86 | |||
| Tandem | 5 | − | 0.83 | ||
| Proposal | − | 0.85 |
| Methods | d | FPR | TPR | Sparsity | |
|---|---|---|---|---|---|
| Sample correlation matrix | − | − | − | ||
| Jiang (2013) with modifications | |||||
| Graphical lasso | |||||
| Tandem | 2 | 0.74 | |||
| Proposal | 0.81 | ||||
| Tandem | 3 | 0.74 | |||
| Proposal | 0.81 | ||||
| Tandem | 5 | 0.73 | |||
| Proposal | 0.80 | ||||
| Sample correlation matrix | − | − | − | ||
| Jiang (2013) with modifications | |||||
| Graphical lasso | |||||
| Tandem | 2 | 0.73 | |||
| Proposal | 0.81 | ||||
| Tandem | 3 | 0.74 | |||
| Proposal | 0.81 | ||||
| Tandem | 5 | 0.74 | |||
| Proposal | 0.80 |
| Method | d | FPR | Within Class Sparsity |
|---|---|---|---|
| Proposal | 2 | 0.128 | 0.757 |
| Proposal | 3 | 0.748 | |
| Proposal | 5 | 0.687 | |
| Tandem | − | 0.578 | |
| Jiang (2013) with modifications | − | 0.578 | |
| Graphical lasso | − | 0.000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tanioka, K.; Furotani, Y.; Hiwa, S. Thresholding Approach for Low-Rank Correlation Matrix Based on MM Algorithm. Entropy 2022, 24, 579. https://doi.org/10.3390/e24050579
Tanioka K, Furotani Y, Hiwa S. Thresholding Approach for Low-Rank Correlation Matrix Based on MM Algorithm. Entropy. 2022; 24(5):579. https://doi.org/10.3390/e24050579
Chicago/Turabian StyleTanioka, Kensuke, Yuki Furotani, and Satoru Hiwa. 2022. "Thresholding Approach for Low-Rank Correlation Matrix Based on MM Algorithm" Entropy 24, no. 5: 579. https://doi.org/10.3390/e24050579