1. Introduction
Objective affective analysis has always been in the area of psychology over the course of the twentieth century. It is mainly in the form of psychologists determining treatment options based on patients’ self-reported emotional states. However, since the beginning of the 21st century, with the rise of artificial intelligence, emotional research has broken into the field of computer science and information technology with the new name of “Affective Computing” [
1], attempting to provide “Emotional Intelligence”, the almost universally acknowledged gap between artificial intelligence and real machine intelligence [
1,
2,
3,
4]. Meanwhile, researchers from the fields of ethology, behaviorists, anthropology, etc., have also explored different aspects of this with various research purposes. Hence, in recent decades, effective research has been naturally interdisciplinary, pulling together knowledge from neurobiology, psychology, evolutionary biology, computer science, and beyond. Note that in this piece, “emotion” and “affection” are utilized to represent the same notion, but both are strictly distinguished from terms like “mood”, “feelings”, “attitude”, “personality”, etc.
Human emotions can be expressed through both verbal cues and nonverbal cues. The majority of pilot studies in the community used verbal expressions, particularly those derived from audio, images, and videos. Since affection is a highly personal property, emotions may be inhibited and elaborately cloaked in subjective verbal reports that vary from subtle hints to explicit declarations. Besides, language itself introduces ambiguity. However, nonverbal cues are spontaneous physiological changes in the process of experiencing waves of emotions, such as facial expressions, tone of voice, overt actions, slips of the tongue, and physiological voltage fluctuations (e.g., electroencephalogram (EEG), galvanic skin Response (GSR), electromyography (EMG), respiration, and temperature) from peripheral/central nervous systems more recently. It was reported in [
5] that the Japanese would disguise negative facial responses with smiles in the presence of a scientist. By contrast, spontaneous expression of physiological fluctuations is less likely to be spurious. Consequently, the research community has started to focus its attention on modalities of genuinely physiological or the fusion of multiple modalities, including video, speech, and physiological recordings. To stay current with academic trends, in this article, we choose to stay focused on the pure physiological fluctuations elicited by experiencing various emotions captured by sensors on the body (EGG).
The central purpose of affective analysis is emotion recognition or emotion detection. Literature in this area can be divided into two categories, i.e., traditional machine-learning algorithms (can process raw data, with less accuracy) that depend on the most discriminating features extracted and selected by labor-intensive intervention and deep-learning algorithms that can work well on raw data.
Traditional machine-learning models such as support vector machine (SVM), decision trees, k-nearest neighbors (KNN), logistic regression, linear discriminant analysis, and dynamic time warping (DTW) have been utilized on various data in many applications. They are usually combined with manual feature engineering to extract the optimal robust feature set. Besides, a discrete hidden Markov model (HMM) was utilized in [
6] as the classifier, and a hierarchical binary decision tree approach was proposed in [
7], both of which were efforts in speech signals-based emotion recognition. Databases for the analysis of spontaneous emotions include MAHNOB-HCI [
8] and DEAP [
9]. Data in MAHNOB-HCI and DEAP ware both recorded with the Valence-Arousal-Dominance model. Most references used DEAP as their dataset. One study [
10] used the Gaussian Process Latent Variable Model (GP-LVM) and applied SVM as its classifier on the dataset DEAP. The results showed that the accuracy of third-class classification was around 88/90% by considering emotions: VA.
In representation learning, deep generative-learning models like Deep Belief Network (DBN), Autoencoder (AE), and Variational Automatic Encoder (VAE) are employed to extract the hidden, abstract, and complex non-linear patterns of raw data, replacing or eliminating the hand-crafted steps. In addition, deep discriminative architectures such as Deep Neural Network (DNN) and Convolutional Neural Network (CNN) can also be regarded as feature extractors that learn hierarchical representations. For instance, CNN is believed to be capable of capturing spatial features (e.g., local dependencies) and invariant features in data. Another study [
11] conducted the experiment on the dataset DEAP, and used DNN and CNN as classifiers, splitting the 8094 datapoints into ten batches, and gained a relatively high accuracy by considering emotions: VA. Long Short-Term Memory Network (LSTM), the building block of recurrent neural networks, can be used to exploit the temporal dynamics in time-series data.
Meanwhile, some papers had their own datasets. For example, N. Murali Krishna et al. tested six mentally impaired subjects using an eight-channel EEG signal to collect audio-visual stimuli. The features were extracted by cepstral coefficients with a novel generalized mixture distribution model. By considering four emotions: happy, sad, neutral, and boredom, the average resulting accuracy was about 89% [
12]. H. Becker et al. also started their own dataset, HR-EEG, which included 257-channel EEG data. They considered various feature extractors, and used ANN as their model. Finally, they compared the influence of nine features and the accuracy of the experiment was medium [
13].
We compare the emotion estimation methods we mentioned above in
Table 1. We can see that although the accuracy of our method is not the highest, we have the highest number of features, and thus, the most comprehensive list for feature importance (occurrence frequency). Besides, we innovatively used SDA as a feature extractor and compared the proposed SDA with other networks with a best-performance assessment.
In this paper, we aim to construct a deep-learning algorithm with an SDA architecture including unsupervised pretraining and supervised fine-tuning using backpropagation of error derivatives that can process raw data with a relatively higher accuracy. We are motivated by the need to develop an efficient deep architecture to extract more powerful and robust representations automatically, to guide the learning of supervised learning algorithms. The top issue in emotion detection is the size of databases. More powerful representations are expected to be built with a larger scale of unsupervised learning. In the presence of labeled data and an abundance of unlabeled data, semi-supervised learning is more practical. In detail, the principal contributions of this paper are as follows:
We propose a semi-supervised deep-learning architecture to extract the underlying representations of pure physiological emotion data without any manual intervention. The experimental results indicate that the Stacked Denoising Autoencoder (SDA) ranks over the other three deep networks. To the best of our knowledge, ours is the first to utilize the stacked denoising autoencoder algorithm as the feature extractor and, in a true sense, to directly take the raw data as input for a model.
By looking back at the historical roots and the development of the emotion-recognition field, we implement most of the recommended well-designed features and perform a comprehensive comparative analysis of diverse existing methodologies and features on the same benchmarking database, thus proving that features from the wavelet transform are the most efficient.
The fusion of two different physiological modalities is performed on a data-level, feature-level, and decision-level. The results demonstrate that the two modalities operate simultaneously, instead of “EEG first, and periphery second”, as much of the literature claims.
Cross-subject and single-subject accuracy show a significant gap, which echoes the conclusions of previous studies in psychobiology (emotions are individualized). This gap can be reduced as the amount of data grows. To our knowledge, ours is the first to investigate the difference in performance between cross-subject and single-subject recognition.
The remainder of this paper is organized as follows. The derivation and selection of discriminating features are discussed in
Section 2.
Section 3 presents the premier well-performed recognizers in the literature. The experiment setup and result anlysis are presented in
Section 4. Finally,
Section 5 concludes this paper and discusses future work.
Notation
Throughout this paper, the following notation is used: The EEG trace or the periphery physiological signal within a certain epoch is expressed as a function of time , and is the number of the time-samples in . The time derivative of is denoted as .
2. Material
As mentioned above, the benchmarking dataset, DEAP [
9], is selected to compare the performances of different representations and algorithms. The physiological data in DEAP is adjusted differently to adapt to various algorithms, including a naive way of augmenting the limited samples to take advantage of deep-learning models and reducing the dimensionality by extracting the artificially designed features and the Principal Component Analysis.
2.1. The DEAP Dataset
Mathematically modeling emotion to represent affection’s latent structure is the first step in emotion-related research. Among the more popular theoretical frameworks for measuring emotion are the discrete model [
5,
14] and the dimensional theory. A comprehensive analysis of dimensional and discrete conceptual views on emotions has been completed by Eddie Harmon Jones et al. in their review [
9], in which both models were believed to have much to offer in attempting to understand the psychology of emotions. From more recent literature, an obvious preference for a dimensional model exists in building physiological emotion databases, and it is indeed quite widespread today, gaining increasing acceptance. For example, the dataset MAHNOB-HCI [
8] was recorded using the Valence-Arousal-Dominance (VAD) model; dataset DEAP [
9] was also recoded along the scale of VAD. As a result, we also used the well-known VAD affection model to conduct the experiments.
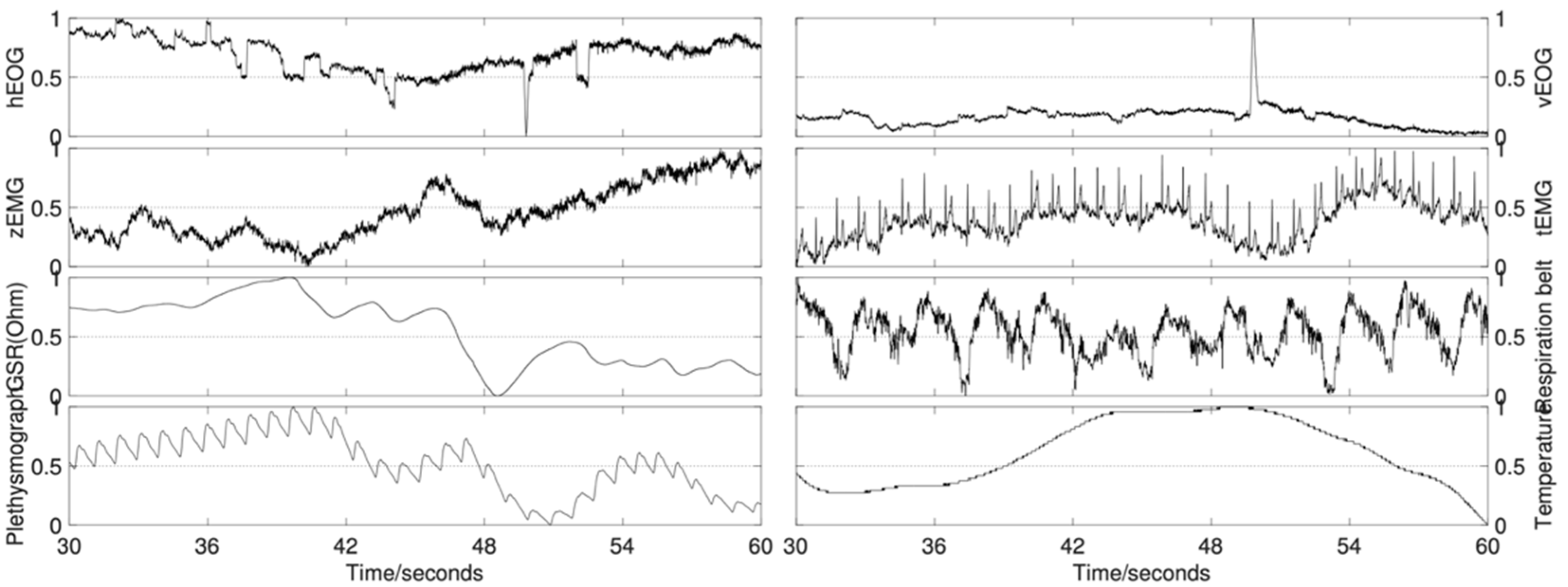
The DEAP was a multimodal dataset for the analysis of human affective states. It contained the recordings of the EEG traces and 13 other periphery physiological signals of 32 subjects (half male) watching 40 one-minute music clips. Specifically, for one subject, there are 40 clips/trials. For one trial, 40 channels captured the physiological voltage fluctuations from where 45 electrodes were placed, resulting in 8064 time samples in a 60 s video time and a 3 s baseline with a 128 Hz sampling frequency for each channel considering that the inner affective states change slowly. We only use the data in the last 30 s because we need dimensionality reduction. The threshold of splitting a dimension of the affectioned model is simply set as 4.5, right in the middle of the range (0, 9), and thus obtaining the ground truth labels for the three basic recognition tasks (arousal, valence, and dominance).
For the detailed placement of 45 electrodes, refer to [
9] or their website. The 13 periphery signals are combined into eight channels for the five channels of horizontal electrooculogram (EOG), vertical EOG, zygomaticus major electromyography (EMG), trapezius EMG, and GSR derived from the difference between two electrodes. Normalized values of the eight periphery channels are illustrated in
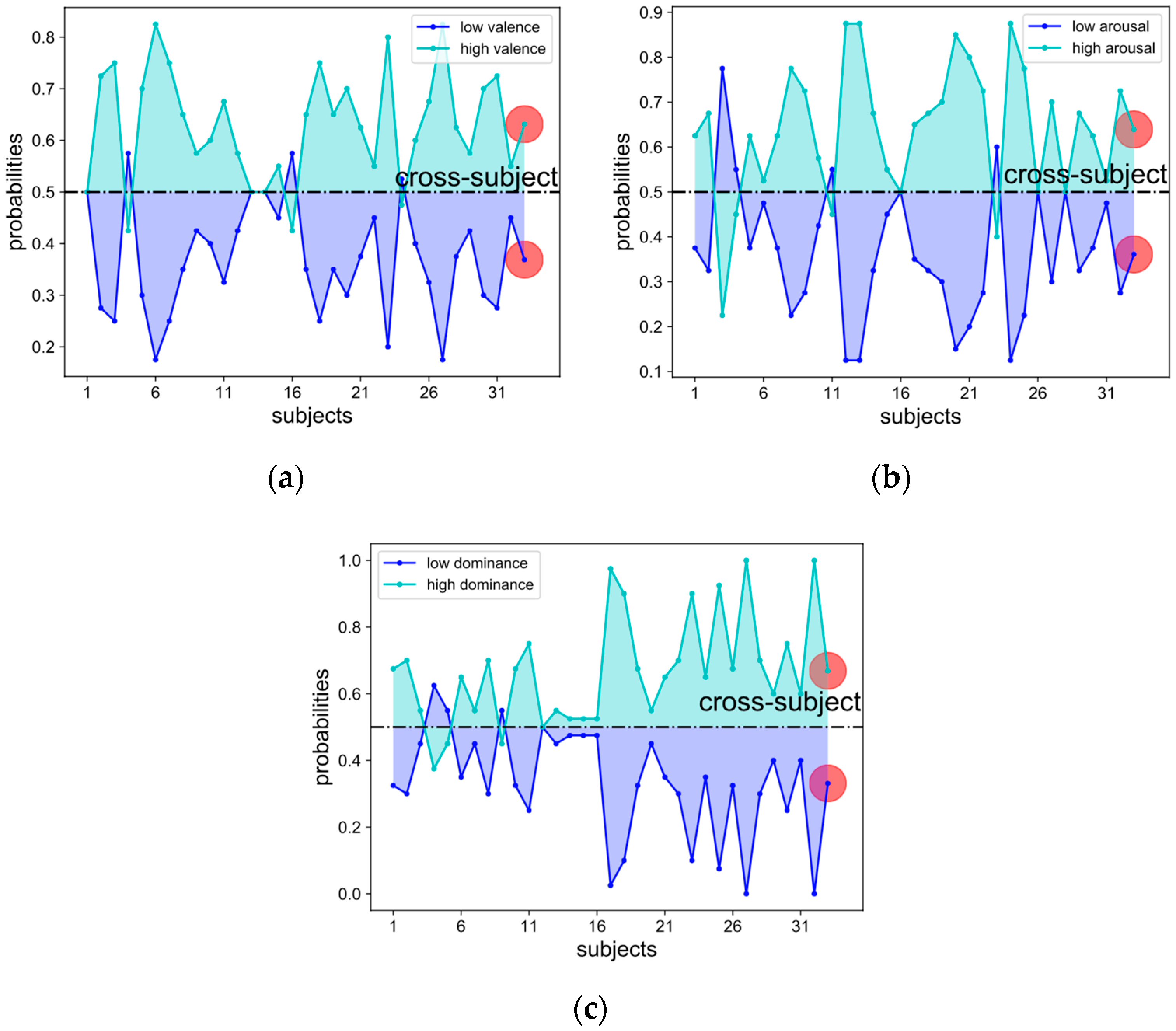
Figure 1. Prior probabilities of 32 single-subject recognition tasks and the cross-subject recognition (marked by the red dot) on all three scales of the dimensional effect model are illustrated in
Figure 2.
2.2. Augmenting the Raw Data
Existing emotional databases share the same weakness: insufficient size. In this regard, datasets of visual and vocal modalities are no exception. For cross-subject emotion recognition, DEAP holds at most 1280 pieces of multimodal physiological data and corresponding subjective ratings on five dimensions of valence, arousal, dominance, liking, and familiarity, ranging from 0 to 9 continuously. The number 1280 is too few to fully exploit the power of deep-learning algorithms. In addition, even without considering the insufficient data volume, directly concatenating the overall 40 channels would result in a vector with 153,600 components (3840 × 40), where the three-second baseline is removed, and only the second half of the data is employed. As a result, 1280 pieces of input vectors of a length of 153,600 would lead to a shallow but wide network to avoid preventing overfitting. Therefore, some deep-learning pioneers in physiological emotion detection have tried to obtain smaller and more acceptable compressed representations from raw data.
However, deep-learning is desirable and valuable because it requires input of the original data rather than the extracted or compressed representations in addition to pre-processing (such as patching the missing values and normalization to eliminate magnitude differences). Ingeniously, we propose to consider signals captured from each channel as a separate piece of data. This is so that all channels of the same trial take the same subject evaluation scores accordingly. This simple augmentation will arrive at 40,960 pieces of data for EEG signals, 10,240 for periphery signals, 51,200 for data-level fusion, and 3840 components for each piece under the same conditions as above. The augmented raw data were normalized along the channel and then fed into our SDA network for feature extraction and classification.
2.3. Human-Designed Features
Pattern recognition algorithms are typically a combination of various features and learning algorithms. Generally, the pre-processed raw data were hard to process directly due to its large volume and the inabilities of classifiers to extract discriminative information from the data. Feature engineering is an essential way of taking advantage of prior knowledge and human ingenuity to compensate for the weakness of current learning models. Therefore, we must resort to features that characterize the most crucial information in raw signals. In emotion recognition, frequently utilized human-designed features can be classified into three categories: statistics derived from the time domain; the frequency domain; and the time–frequency domain. As illustrated in
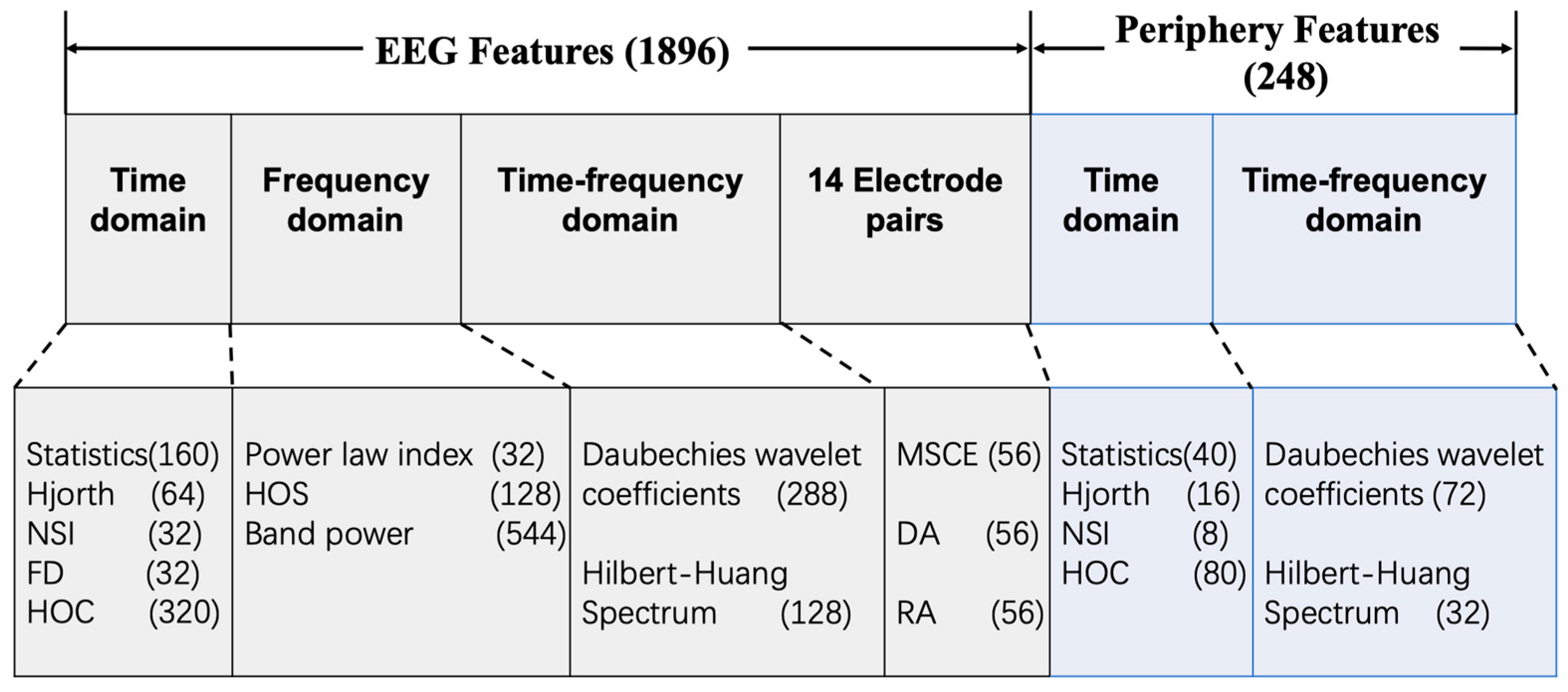
Figure 3 and
Table 2 a total of 1896 EEG features and 248 periphery features were extracted.
2.3.1. Time Domain
The most common quantization terms are calculated entirely in the time domain, such as power reflecting the energy of the signal, the average over the whole-time interval representing the approximation with the lowest resolution in discrete wavelet transform, the variance that characterizes the degree of deviation, and difference (the approximate derivative of the discrete-time series). The power, mean, standard deviation, normalized 1st difference, and normalized 2nd difference of the 40 channels of one trial are computed.
The Hjorth parameter can be expressed as the activity, mobility, and complexity of a feature. The activity is the variance that can be fully expressed as the square of the standard deviation, so it will not be implemented afterward [
15].
The NSI proposed in [
16] measures the complexity of the time series and can capture the non-stationary degree of the signals. The temporal variations of the amplitude of EEG signals are involved, irregular, turbulent, and non-periodic, yet they exhibit long-range correlations over most time scales, indicating the presence of self-invariant and self-similar structures. NSI is easy to implement. It is sufficient to divide the time sequence to be analyzed into several segments, then calculate the local averages of sections, and finally compute the variance of the local averages.
Another indicator for describing the complexity or chaos of EEG signals is the FD, whose stable and precise values are generally derived through the Higuchi algorithm [
17]. Fractal dimension-based features build on evidence that EEG signals can be regarded as a fractal curve, each part of which can be seen as a reduced-scale image of the whole. The calculation procedure is as follows.
First, consider a finite set of time-series observations sampled at a regular interval
:
Second, construct a new time sequence,
, from the above-given signal:
where [⋅] denotes the Gauss notation for the floor function;
k denotes the time interval;
m = 1, 2, ⋯,
k is the initial time point of each subsequence; both
k and
m are integers.
Next, the length of each sub-curve
is defined as:
The term
is a normalization factor. The sum term represents the sum of the absolute values of the forward difference to the
set.
Then, the length of the time series or the curve for the time interval , , is defined as the mean over k sets of . Last, if there is , then the EEG curve is fractal with the dimension . Note that the FD has not been utilized on periphery physiological channels.
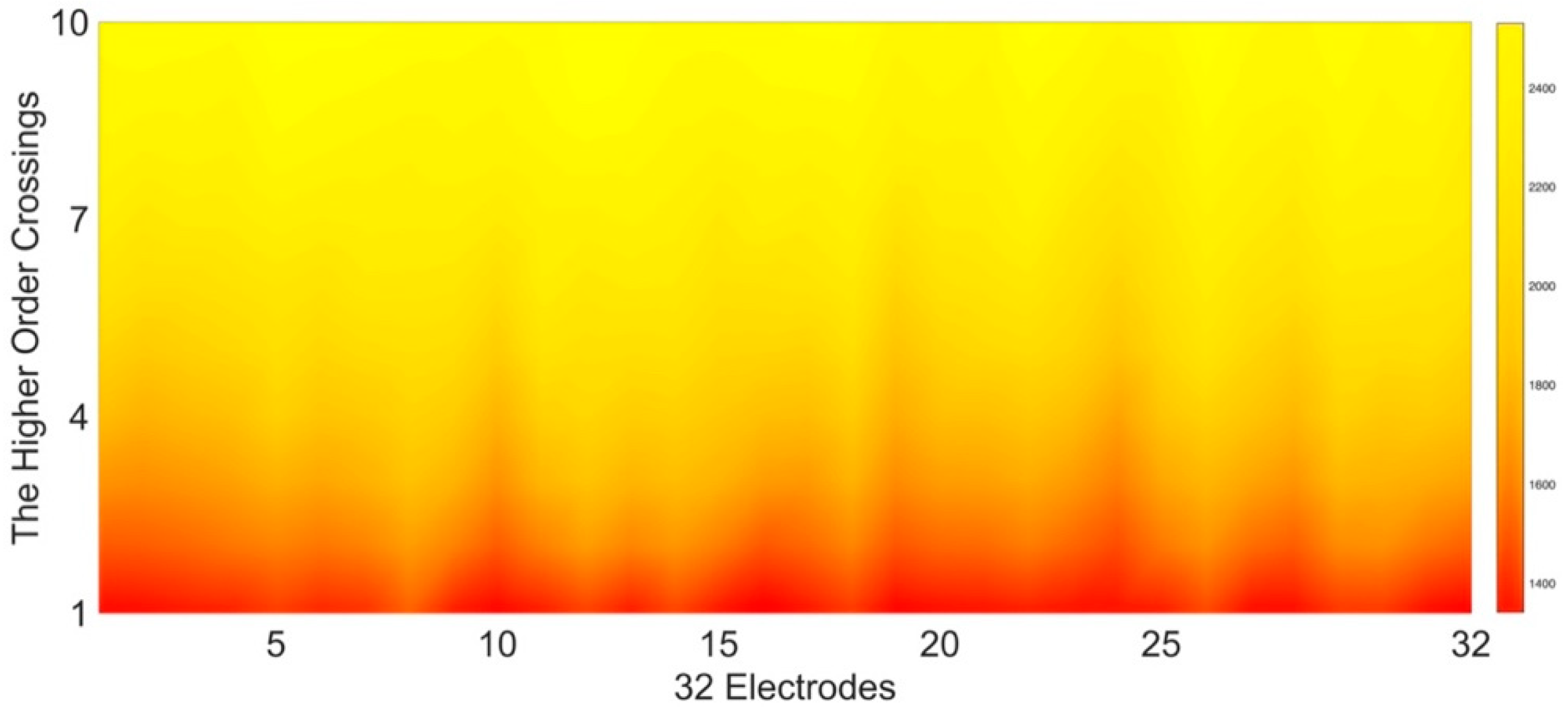
Higher-order statistics are found to be more effective. The zero-crossings count of a finitely long real-valued zero-mean series can account for the oscillating attitude around the zero levels, the values of which will consequently vary if a filter is applied to the time series. Naturally, a specific sequence of filters applied to a time series will result in specific zero-crossings counts, which are the so-called HOC-based features that can be viewed as a measure of oscillation pattern in the manner that the stronger the oscillation, the higher the zero-crossing rate, and vice versa. Herein, enlightened by [
18], we apply a sequence of high-pass filters based on the backward difference operator to the zero-mean time series
where
is then iteratively applied backward to the difference operator, and
is the order. The resulting
features, i.e.,
, consist of the zero-crossings count of the filtered time series
. As shown in
Figure 4, the values of ten HOC features of the 32 EEG channels are presented in a heat map, and the lighter the color, the larger the value. As the order increases, the zero-crossing count decreases. Higher-order crossings can also apply to the periphery signals.
2.3.2. Frequency Domain
Signal processing has always relied on power spectral density (PSD) analysis as a conventional instrument for analyzing time series. In particular, when the power spectrum follows the power-law
, where
denotes the power spectrum density and f in hertz, then the exponent
can also be considered as the index for characterizing the irregularity of signals. It is formally defined as the Fourier Transform (FT) of the autocorrelation sequence (the Wiener–Khintchine theorem, which assumes the stationarity of stochastic signals):
where
is the autocorrelation sequence. Since
in this article is definitely real-valued, and its autocorrelation is summable (a sufficient but necessary condition for the power spectrum), the power spectrum exists and is real-valued, nonnegative, and symmetrical.
To estimate the PSDs of power signals that do not satisfy the generalized stationary assumption, we may use Welch’s averaged, modified periodogram [
19]. First, chop a length N signal into length
L overlapping segments of equal length
M, i.e.,
N =
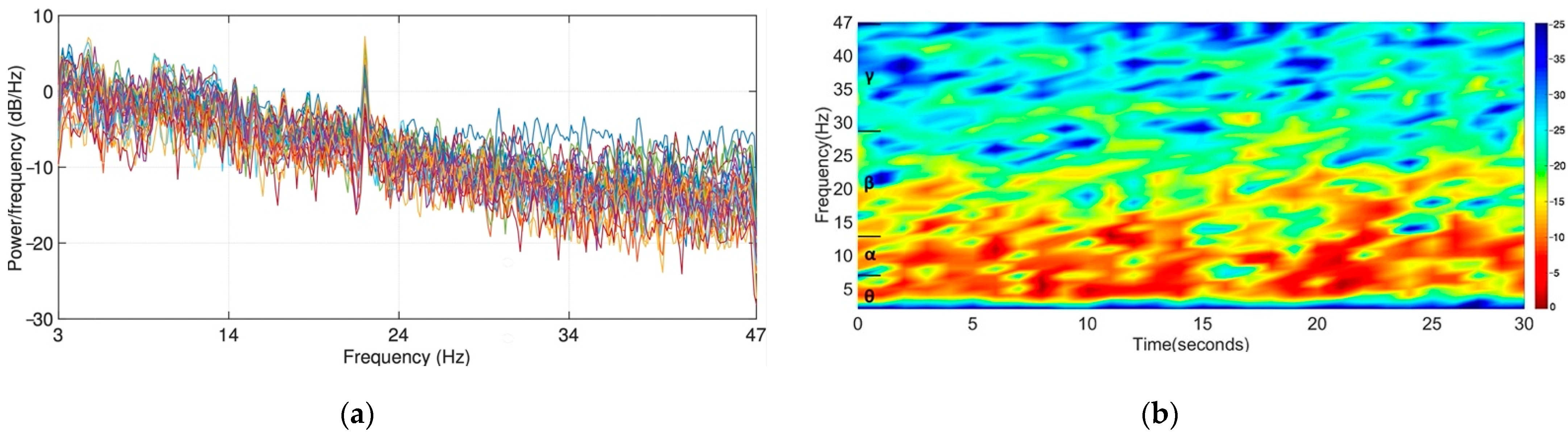
L ∗ M; then window each slice and apply Fourier transform to determine the frequency components at that slice; finally, let the power spectrum of the entire signal by the average overall pieces of data. Herein, an 853-point FFT with a 426-point (half of the window) overlapped Hamming window function w was adopted to generate the PSDs. An example of the power spectral density of EEG signals is illustrated in
Figure 5a. The power spectral density curves show a mild trend of the long tail.
Power in four major frequency bands:
are the most popular features in EEG-based emotion recognition. Short-Time Fourier Transform is more commonly used to calculate the approximate average power of each band because it is more robust to noise than Fourier Transform, and
Figure 5b shows the spectrum of an EEG channel in 30 s at 347 Hz. As one can see, the energy is mainly concentrated in
and
bands in this case. Here, we adopt the Hamming window with length of 1000 ms with no overlap. The final computed features comprise the logarithm of the average, the logarithm, of the maximum and minimum power of each band, the power variance across all frequency bands, and the average power ratio of
over
.
Spectrogram, the most basic method, relies on conventional Fourier spectral analysis, which assumes piecewise stationarity of the data. The typical implementation of the spectrogram is the Short-Time Fourier Transform (STFT), with which a time–frequency distribution can be obtained by successively sliding the window along the time axis and performing the Fast Fourier Transform on each time window. The uncertainty principle in the field of time and frequency analysis demonstrates that increased time resolution reduces frequency resolution and vice versa. STFT suffers from inaccurate time–frequency positioning due to this conflicting phenomenon. Therefore, it will only serve to compute the band power as described above and will not be further discussed.
The higher-order spectral analysis is a non-linear signal processing framework, building on the fact that much more information can be obtained from an autocorrelation or power spectrum in a stochastic non-Gaussian signal. Higher-order spectra defined in terms of a signal’s higher-order moments or cumulants contain this additional information. The higher-order spectral analysis assumes that the processes or signals of interest are zero means, just as higher-order crossings in the time domain because higher-order cumulants are invariant to mean shifts. Higher-order spectra include polyspectra, such as the bispectrum, bicoherence, trispectrum, etc. Here, we have only analyzed the bispectrum for simplicity. For an in-depth discussion of the definitions of “polyspectrum” and “cumulant” and their properties as well as implementation issues, the reader is encouraged to consult the Higher-Order Spectral-Analysis Toolbox [
20].
Bispectrum serves to extract the phase information and characterize the properties of non-linear mechanisms such as quadratic and cubic patterns [
21]. The features of the bispectrum were derived for the quantification of emotions in [
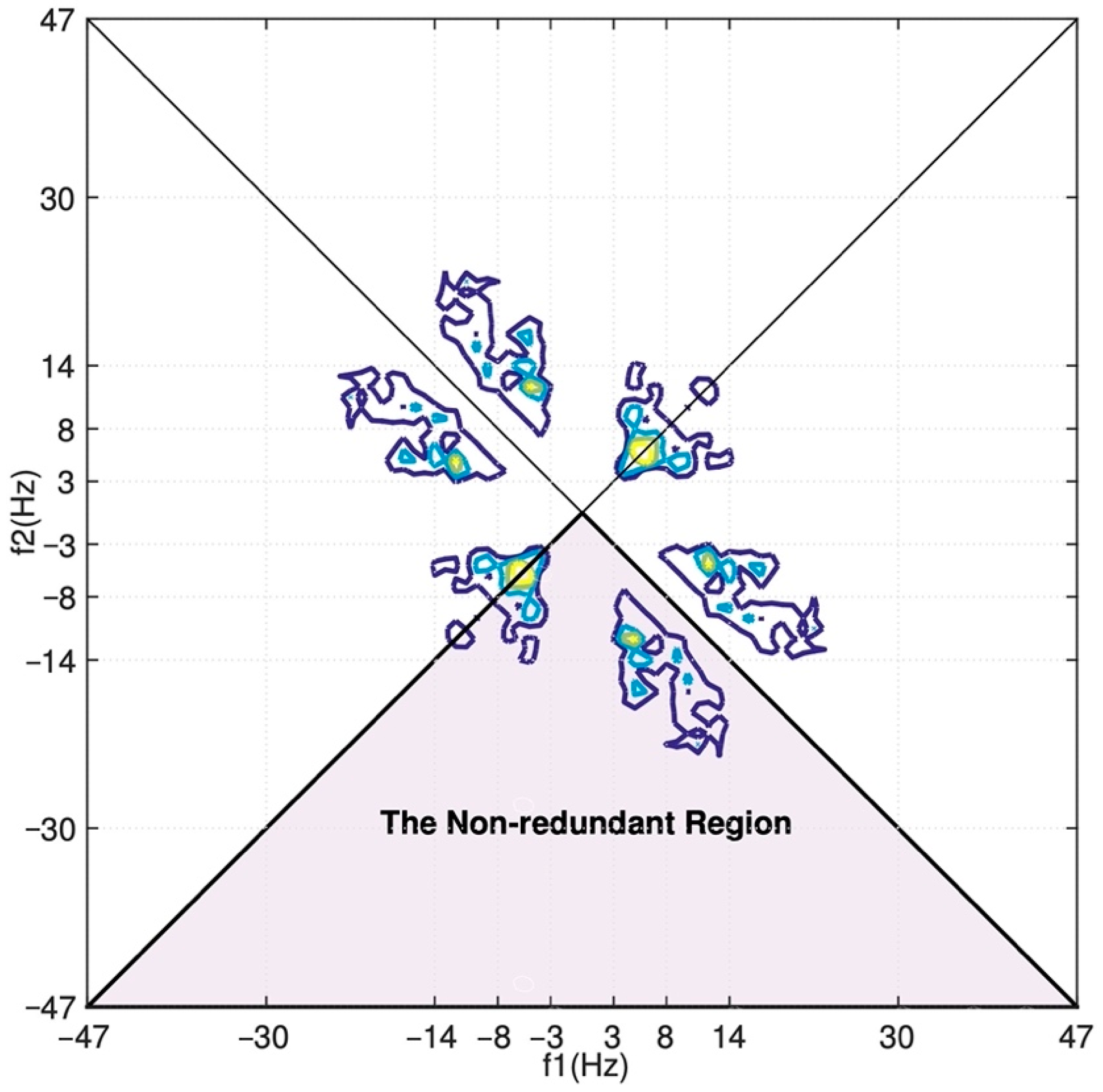
2]. The bispectrum is defined as the Fourier Transform of the third-order cumulant sequence:
Note that the bispectrum is a function of two frequencies. Herein, the 128 × 128 bispectra are estimated by firstly segmenting the signal into 30 nonoverlapping 128-sample slices (only the second half’s recordings are used), next applying lag-domain windows to the computed cumulants in the nonredundant region, and finally computing a two-dimensional 128-point FFT of the windowed cumulants with shifting and rotating for proper orientation.
Due to the vast volume (128 × 128 = 16,384) of the computed bispectrum, we turn to derive the four features proposed in [
2] from the bispectrum data:
- 1.
Normalized bispectral entropy
where Ω is the non-redundant or principal region, as illustrated in
Figure 6. For a specific definition of the non-redundant region, the reader is referred to [
20,
21,
22].
- 2.
Normalized bispectral squared entropy
- 3.
Mean-magnitude of bispectrum
where
L is the number of points within Ω.
- 4.
First order spectral moment
where
N denotes the total number of elements in the bispectrum matrix.
The quantities mentioned above are all computed based on the recordings of one single electrode (except for the average power ratio of
over
). Yet, researchers have found that some electrodes in different scalp regions have a joint reaction while experiencing different affective states [
1]. MSCE features describe the correspondence of two signals coming from different channels
and
at corresponding frequency, taking values between 0 and 1 [
15]. The MSCE is given in Equation (21):
where
is the MSCE of
;
indicates how well
corresponds to
at each frequency;
is the cross-power spectral density;
and
denote the power spectral density of
and
, respectively.
According to neuroscientific findings concerning hemispheric asymmetry and its relationship to emotion [
23], features based on the combination of symmetrical pairs of electrodes have garnered attention. They are typically classified as differential asymmetry and rational asymmetry between the electrode pairs symmetrically distributed on the cerebral cortex in the international 10–20 system. The former one usually refers to the average power difference of electrode pairs on the left/right hemisphere of the scalp:
, and the latter refers to the ratio of the pairs:
.
2.3.3. Time–Frequency Domain
It is not new to decompose a signal into its harmonic components. As early as 1677, Newton had carried out the spectral decomposition of light. The Fourier Transform led to modern signal analysis based on transform domain decomposition. The below three methods are designed to modify the global representation of Fourier analysis, but they have all failed in one way or another. In time–frequency analysis, signals are typically decomposed into a small number of components based on the local characteristic time scale. Accurate localization of frequencies is possible. The primary concern is the instantaneous frequency and energy rather than the global frequency and energy defined by Fourier spectral analysis. Time–frequency methods can provide additional information by considering the dynamic changes provided by the non-stationarity of signals, and presenting them as an energy–frequency–time distribution.
Using the Hilbert–Huang spectrum, one can localize any event in the time domain and on the frequency axis. The Hilbert–Huang spectrum can be derived by applying the Empirical Mode Decomposition (EMD) function and the Hilbert Transform (HT) function. With the EMD function, any complicated non-linear and non-stationary signal can be decomposed into a series of “intrinsic mode functions” that admit well-behaved Hilbert Transforms. Through the subsequent Hilbert Transform of Intrinsic Mode Functions (IMFs), which are derived from local properties of signals, the instantaneous frequencies and energy are obtained as time functions, resulting in a full energy–frequency–time distribution of the original data. The paper [
24] summarized the necessary conditions to represent a nonlinear and non-stationary time series as completeness, orthogonality, locality, and adaptivity, in which completeness guarantees the precision in the expansion and orthogonality avoids leakage, locality serves nonstationary signals that have no time scale, and adaptivity is crucial for avoiding harmonic distortion of non-linear phenomena.
An IMF component involves only one oscillatory mode so that the Hilbert Transform can provide the full description of the frequency content. Contrary to the other expansion methods, the basis of HHS has derived from the raw data of the trait of riding waves expressed as one undulation riding on top of another, and they, in turn, are riding on still other fluctuations so on [
24]. The sifting process of systematically extracting the IMFs is expanded in detail, as shown in Algorithm 1. The local maxima and local minima separately define the upper and lower envelopes.
| Algorithm 1. Hilbert–Huang spectral analysis [24] |
| Input:. |
| Output:. |
- 1.
function
|
- 2.
|
- 3.
|
- 4.
|
- 5.
|
- 6.
ResidueThreshold do
|
- 7.
|
- 8.
|
- 9.
|
- 10.
|
- 11.
do
|
- 12.
|
- 13.
|
- 14.
|
- 15.
|
- 16.
|
- 17.
end for
|
- 18.
|
- 19.
|
- 20.
|
- 21.
|
- 22.
|
- 23.
end while
|
- 24.
|
- 25.
|
- 26.
end while
|
- 27.
|
- 28.
end function
|
- 29.
|
- 30.
|
- 31.
|
- 32.
|
- 33.
|
- 34.
|
- 35.
return energy, frequency
|
- 36.
end function
|
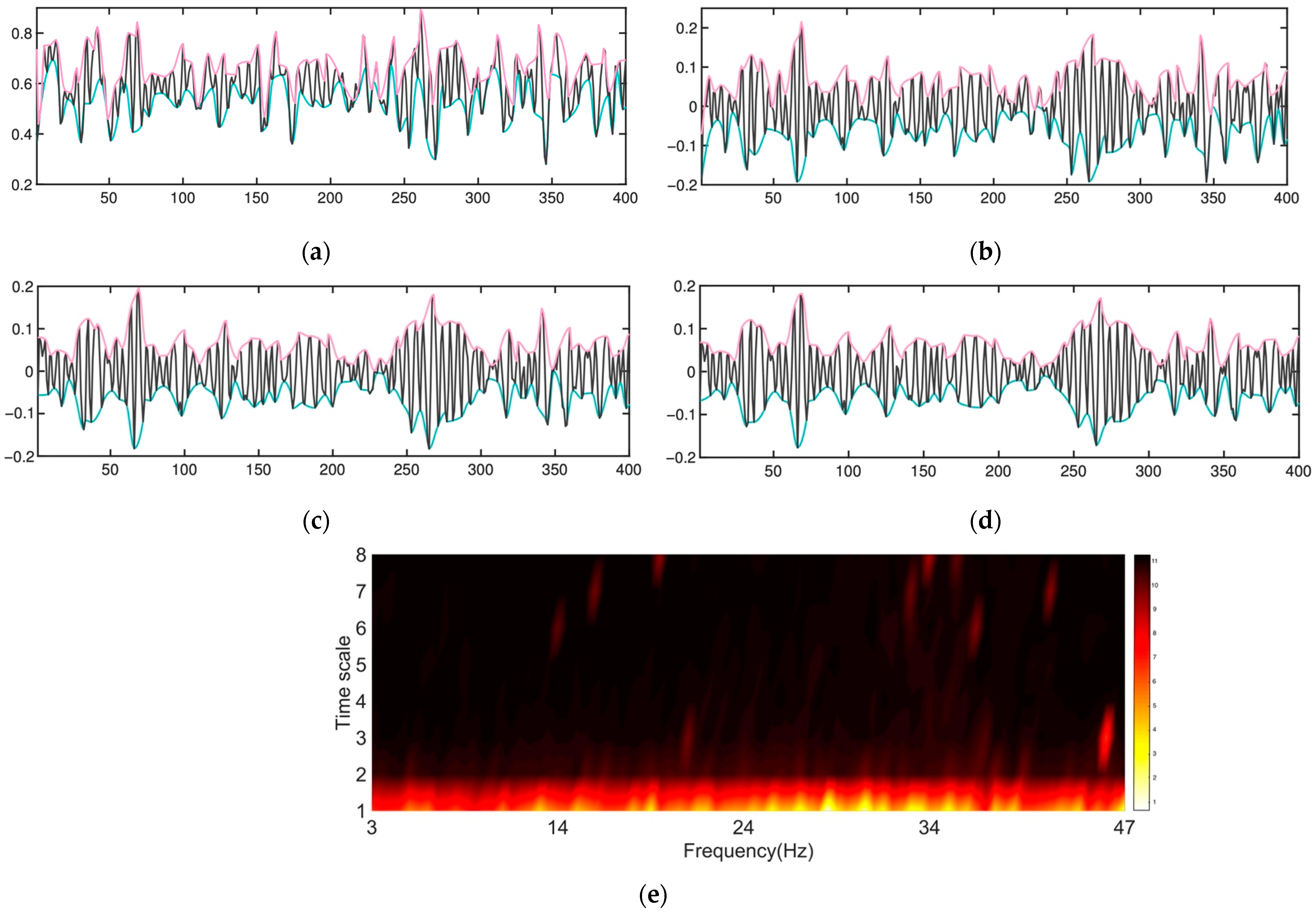
As depicted in
Figure 7, the first IMF component contains information on the whole frequency range of Hz (3–47), yet the other IMFs include knowledge of much fewer frequencies. For example, the third IMF shows a soft spike at about 21 Hz and an extremely sharp peak at around 44 Hz, and the nineth IMF shows high energy at 23 and 34 Hz.
The multi-resolution wavelet approach, gloriously called “the mathematical microscope”, has attracted widespread popularity. It is essentially a linear Fourier spectral analysis with adjustable windows. Unlike the STFT, the wavelet analysis is adaptive to the fluctuations of signals by adjusting the width of the time window and frequency scale. The general continuous definition of WT is:
where
is the dilation factor;
gives the frequency scale;
is the translation of the origin and gives the temporal location of an event;
is the mother wavelet function. The physical sense of Equation (22) can be interpreted as the energy of
of scale
at time
.
Here, we use the orthogonal and compactly supported the fourth order Daubechies wavelet to decompose the signals into detail coefficients of four levels and approximation coefficients of the fourth level, designated as D1, D2, D3, D4, and A4, respectively. Further, given the sampling rate of preprocessed signals in DEAP is 128 Hz, the corresponding frequency range of each set of coefficients is deduced by the criteria shown in
Table 3. The entropy, root mean square (RMS), and the absolute logarithmic recursive energy efficiency (abs(log(REE))) of frequency bands
are derived by extending the approach introduced in [
22].
2.3.4. Feature Selection for Reducing the Dimensionality
An abundance of features will lead to over-specification, excessive computation load, and even overfitting when some features have little influence on the classification task. Achieving the smallest, most representative, distinguished, and robust feature subset that would yield the minimum generalization error is crucial.
Generally speaking, the feature selection procedure can be considered as an optimization problem for data pre-processing and typically involves two processes. First, a subset search is performed to select a subset via a particular search engine such as the greedy forward, greedy backward, and bidirectional search, among which: the forward search recursively appends relevant features to an initial set; on the contrary, the backward method continually discards irrelevant attributes from a complete feature set; the bidirectional way combines the other two. Besides, some randomized heuristic policies have been used for selection and showed efficiency, too. Second, a subset evaluation is performed to assess the suitability of the candidate subset via the above-mentioned miscellaneous criteria.
There are three general approaches to feature selection: filters, wrappers, and embedded methods. Here, only the first two are considered. Wrapper-type methods judge the availability of a feature by the actual accuracy of the specific classifier, thus guaranteeing a specialized non-redundant feature subset that matches best with the learning method, yet requires extensive computation, so a beforehand filtering is necessary. Filtering methods are model-independent and less computationally intensive, thereby fitting the feet of large datasets. The simplest baseline approach falling in filtering categories is removing features with low variance (RFLV), which is based on the idea that variables with milder undulations can have less impact on the results. The idea is similar to Principal Component Analysis (PCA) motivation, as well as the somewhat controversial Entropy Weight Method.
The relief method inspects the problem from a correlation perspective and chooses the variables with high association with the target. As with Linear Discriminant Analysis, the Fisher score assigns the highest score to features whose values of a different class are far from each other. In contrast, values of the same class are close to one another. One common practice of filtering methods based on mutual information is the Minimal-Redundancy-Maximal-Relevance (mRMR) framework, proposed in [
5] to minimize the redundancy in feature sets obtained from the typical methods that rank genes according to some rule and pick the top-ranked ones. Mutual information itself can be used to measure the relevance or similarity of attributes.
2.4. Principal Component Analysis Compressed Representations
To examine the performance of manually extracted features, we used a simple and widely used dimension reduction method, principal component analysis, to extract the principal components of the data as reference features in a linear and unsupervised fashion. PCA learns a linear transformation
of input data
, in which the columns of the matrix
form an orthogonal basis for the
dh orthogonal directions. The transformed result is the
dh uncorrelated components. High-dimensional data can be compressed into a much smaller space while retaining most of the variation in the data set [
25]. In many cases, global representation is needed to lessen the calculative burden or visualize samples for better analysis. PCA identifies the principal components or directions in the feature space along which the variance is maximal by the unsupervised combining of all the attributes. The so-called principal components are linear combinations of the original variables. Specifically, the first principal component is the direction in the data points that shows the greatest variation. The second principal component is the direction uncorrelated to the first component and maximizes the variance of samples when projected onto the component. If the data were standardized, then the principal components were the normalized leading eigenvectors of the covariance matrix. In this piece, signals in each channel are represented by the top 25 components whose cumulative contribution rate has reached nearly 100%, instead of 3840 variables to reduce data volume and, in the meantime, minimize information loss. As a result, there are 800 dimensions for EEG and 200 dimensions for the periphery for a trial.
However, the expressive power of linear features learned by PCA is rather limited. One cannot stack these linear features to form deeper representations since the composition of linear operations yields another linear operation.
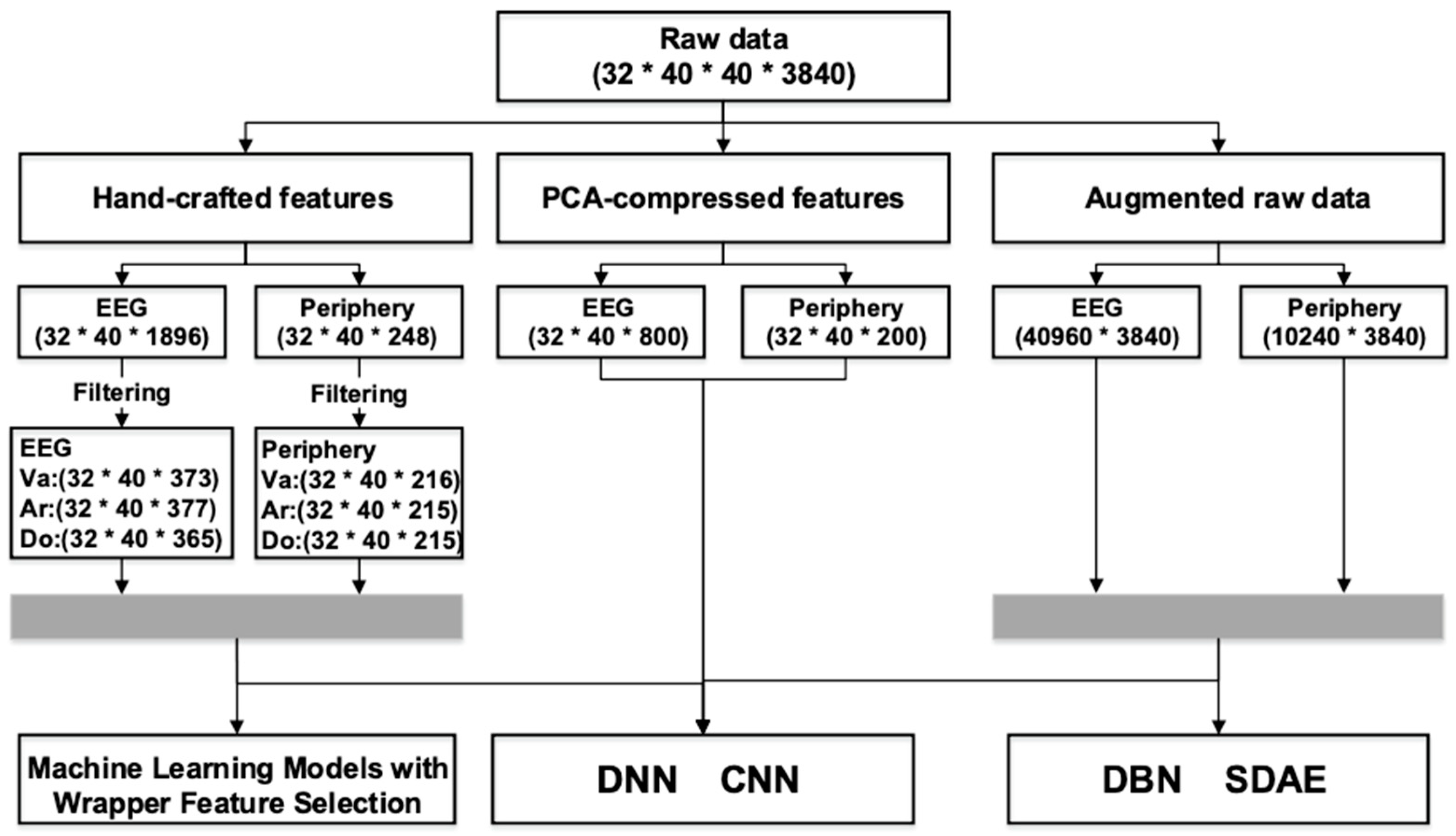
4. Performance and Evaluation
To investigate and compare the performance of our proposed method with existing mainstream methods that can be summarized as combining one or more human-designed features with one classical learning algorithm, which can be traditional machine-learning methods or deep-learning approaches, we performed substantial experiments in this section, the experimental setup, and the results are elaborated below. All data preparations are detailed in
Figure 11.
4.1. Hand-Engineered Features
As is exhibited in
Figure 11, the number of derived features was huge, which may result in the fact that some features are irrelevant to others. Hence, before proceeding any further, we performed a hybrid filtering selection as a preliminary operation to reduce the dimensionality. The Scikit-learn Python package [
31] was used for implementing the machine-learning models.
First, as a pre-step, we utilized the most fundamental RFLV to eliminate a small amount of less volatile features. The threshold was set as 0.01. As a result, a total of 148 EEG features with variances lower than 0.01 were picked out, among which were 18 from the higher-order spectra, 39 from the band power, 21 from the Hilbert–Huang spectrum, 24 from the differential asymmetry, 44 from the rational asymmetry, and 1 from the discrete wavelet transform. As for periphery modality, 31 features were removed, including 20 from the Hilbert–Huang spectrum, 3 from the discrete wavelet transform, 3 from the Hjorth, and 2 from the statistics in the time domain. The results can vary because the threshold was a hyperparameter of the unsupervised RFLV. As a result, the higher-order spectra and Hilbert–Huang spectrum fail to meet the expectation claimed in the literature.
Then, after eliminating features with small variation, we applied two supervised filtering methods and took the union of their choices as the input of learning algorithms with the mode-dependent wrapper selection. The motivation for us to do this was: as a rule, incorporating several state-of-the-art methods of feature selection surpasses a single method in performance, providing a broader coverage of the original space covered by the entire dataset, while emphasizing the discriminative efficiency. To decide which filtering methods to combine, we compared the performance of ten univariate and supervised filtering feature selection methods to recognize the valence dimension.
The result is presented in
Table 4. It is clearly exhibited that the chi-square method gets marked (bold or underlined) by four models and wins first place in two of them. The method based on mutual information follows closely behind, being marked for three times and winning a championship twice. Accordingly, filtering based on chi-square and mutual information is incorporated to conduct further filtering after RFLV: the union of the top-ranked 200 features of both methods forms the final feature set for wrapper selection and classification. Specifically, in doing so, we arrive at 373 EEG components and 216 periphery dimensions for Valence, 377 and 215 for Arousal, and 365 and 215 for dominance, as shown in
Figure 11.
4.1.1. Using Traditional Machine-Learning Algorithms with Hybrid Feature Selection
To investigate the performance of hand-engineered features and evaluate the contribution of both modalities, we conducted three binary classification tasks using seven widely-used machine-learning models in the literature. As mentioned above, a hybrid strategy of filter and wrapper type methods was employed for feature selection. The final feature subsets for three recognition tasks have been acquired.
Both cross-subject and single-subject classifications are performed. For cross-subject recognition, trials of all 32 participants are mixed, resulting in 1280 pieces of data. The results in
Table 5 were obtained through five-fold cross-validation with the greedy forward wrapper search. For single-subject recognition, the 40 trials of one subject formed a tiny individual database. To refrain from overfitting that was prone to small data sets, we performed the leave-one-out-cross-validation for each subject, which can be viewed as 40-fold ordinary cross-validation with only one piece of test data. The accuracy was calculated by dividing the total number of correct testing by 40. In addition, there can be features that can accurately distinguish dimensional size, resulting in 1.0 accuracy by itself. This was due to the small datasets that severely lack training cases. We have skipped such features in the experiment.
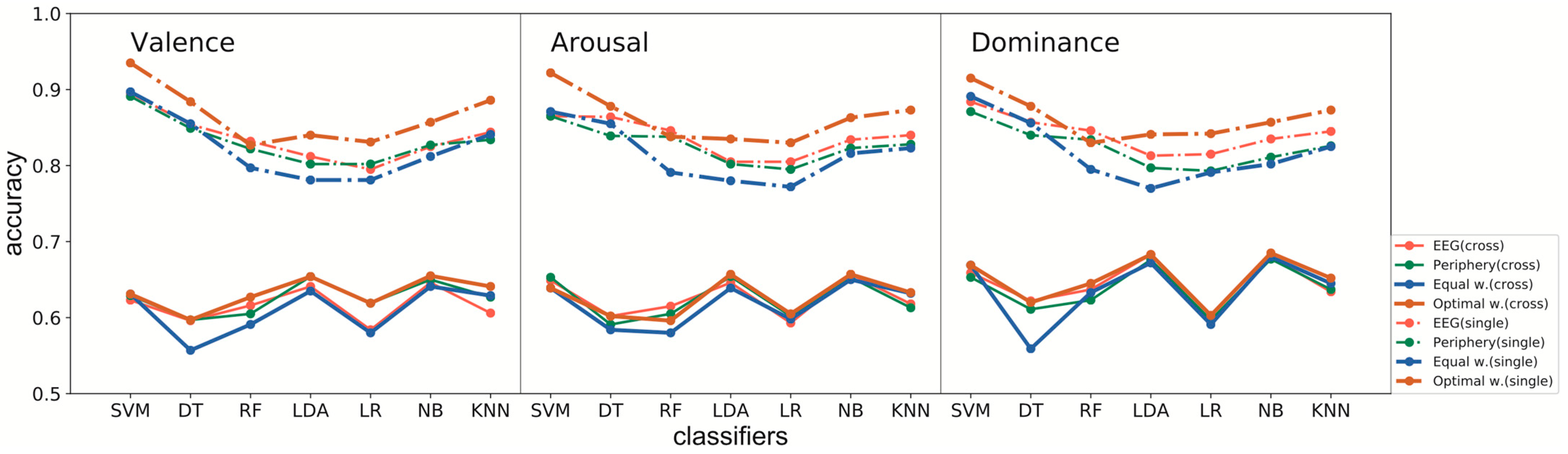
To obtain a better result, decision fusion with equal weights and the optimal weights was also investigated. The exhaustive search found the optimal weights, where the step length was set as 0.01. The fused output was the weighted average of the two sets of output probabilities from EEG and periphery modality. As
Table 5 and
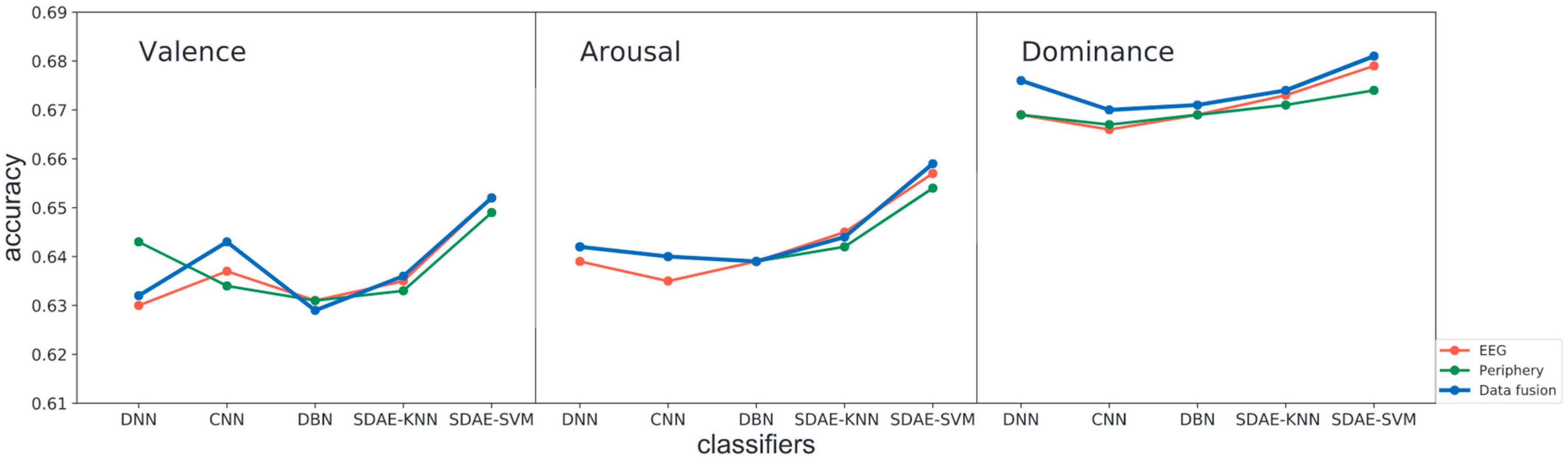
Figure 12 show, decision fusion with optimal weights outperformed the others, whereas fusion with equal weights showed the poorest performance. In this case, decision fusion using weighted average changes only changed the recognition result that the two modalities disagree on, while optimal weights tended to follow the opinion of the right modality.
In contrast, fusion with equal weights showed no preference, thus making more mistakes. Besides, distinct from the usual declarations in the literature that the periphery is inferior to EEG and plays a supporting role, we observed that the periphery modality drew equally with EEG for the valence scale in both cross-subject and single-subject recognition. For arousal and dominance, although, for the most part, the EEG outperformed the periphery modality, there were times that the periphery matched or beat EEG.
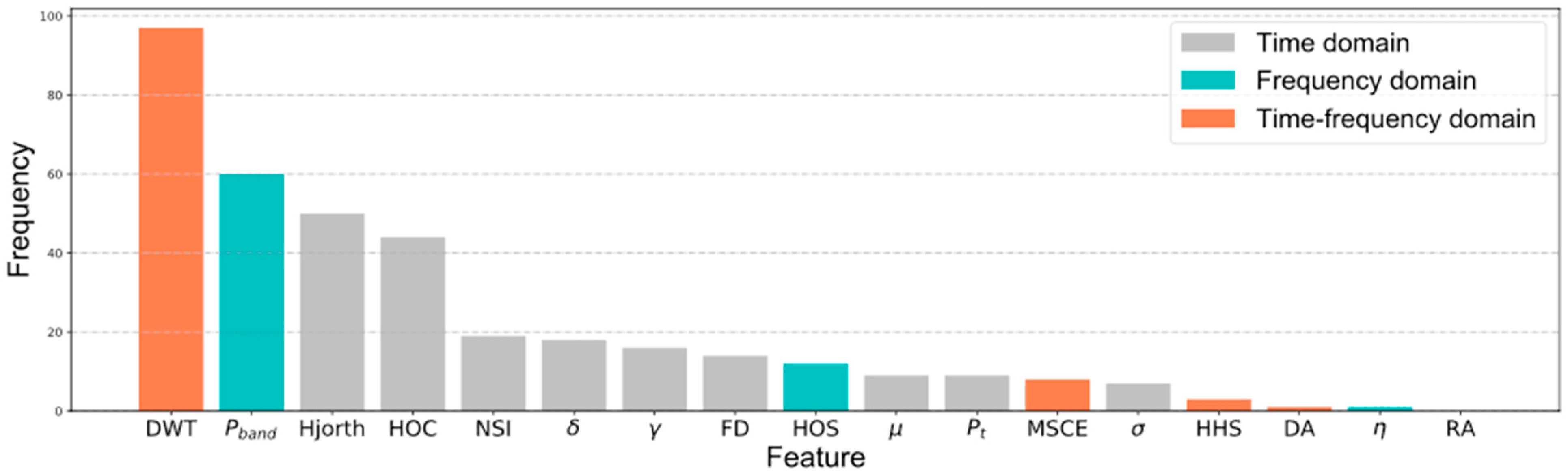
In addition, the times of various hand-engineered features selected by the machine-learning algorithms for both cross-subject and single-subject recognition on the valence, arousal, and dominance dimensions were added up, as shown in
Figure 13. Features derived from the discrete wavelet transform in the time–frequency domain were the most favored. The power of four frequency bands in the frequency domain and the mobility and complexity were defined by Hjorth features in the time domain. Most features in the time domain were running neck-and-neck; however, surprisingly, the Hilbert–Huang spectrum and electrode pairs were not as popular as expected.
4.1.2. Using Deep Neural Networks to Compare with PCA-Compressed Features
To further verify the effectiveness of the well-designed features elaborated in
Section 2.3, we will probably use PCA’s oldest feature extraction method as a reference.
We compared the performance of two feature sources: hand-crafted features introduced in
Section 2.3 and PCA-compressed features mentioned in
Section 2.4. The need for a special note was that only cross-subject recognition were to be performed using deep architectures, and single-cross recognition was merely conducted in
Section 4.1.1. In this experiment, all the 1748 features for EEG and 216 for the periphery modality were used without further filtering, except with RFLV. For PCA, the top 25 principal components were retained, so there were 800 components for EEG and 200 for the periphery. Feature fusion by concatenating the two feature vectors is also implemented. A three-hidden-layer deep neural network is used, and the dropout probabilities were set to 0.45, 0.5, and 0.25, respectively. Specifically, we employed a 1748-800-200-20-2 network for hand-engineered EEG, a 217-100-50-10-2 network for the hand-engineered periphery, and a 1965-500-100-20-2 network for the fusion of hand-crafted features. The number of neurons in three hidden layers of PCA were 500-100-20, 100-100-20, and 500-100-20 for the three feature sources. The dataset was divided into a training set with a size of 768, a validation set for adjusting hyperparameters such as learning rate and the number of training epochs, and a testing set with a size of 256. The five-fold cross-validation was also used here.
Our loss function consisted of four terms to avoid overfitting and to reduce the impact of category imbalances:
where
are the coefficients of the four terms;
and
denote the
regularization loss and the
regularization loss, respectively;
,
represents the cost of misclassification caused by class imbalance. The four coefficients and other hyperparameters are adjusted according to the crossentropy error.
The results are shown in
Table 6. Hand-engineered features outmatch the unsupervised PCA-compressed ones in all the comparisons, demonstrating these human-designed representations’ serviceability and superiority.
4.2. Automatically Generated High-Level Representations
This section compares the expressive power of several deep-learning models on an RTX 2060 GPU, including two discriminative models (DNN, CNN) and two generative models (DBN, SDA). The augmented data were utilized as input after normalization.
4.2.1. Supervised Discriminative Architectures
We focused on deep neural networks (DNN) and convolutional neural networks (CNN) for discriminative models. With the popularity of deep learning, DNN and CNN have attracted the most attention. These networks use the original data taken as input directly. Therefore, each layer in these networks can become a special feature extractor without human intervention, similar to the idea of representation learning in generative models. However, generative models can learn more parameters without overfitting, requiring no feedback from the labels. For generative models, the parameters are constrained by the number of bits required to describe the input for each training case. Yet, for discriminant models, the parameters are constrained by only the number of bits needed to describe the label [
29]. We ignored the internal differences between the two networks and just used them as examples of discriminative models to compare feature extraction performance with generative models.
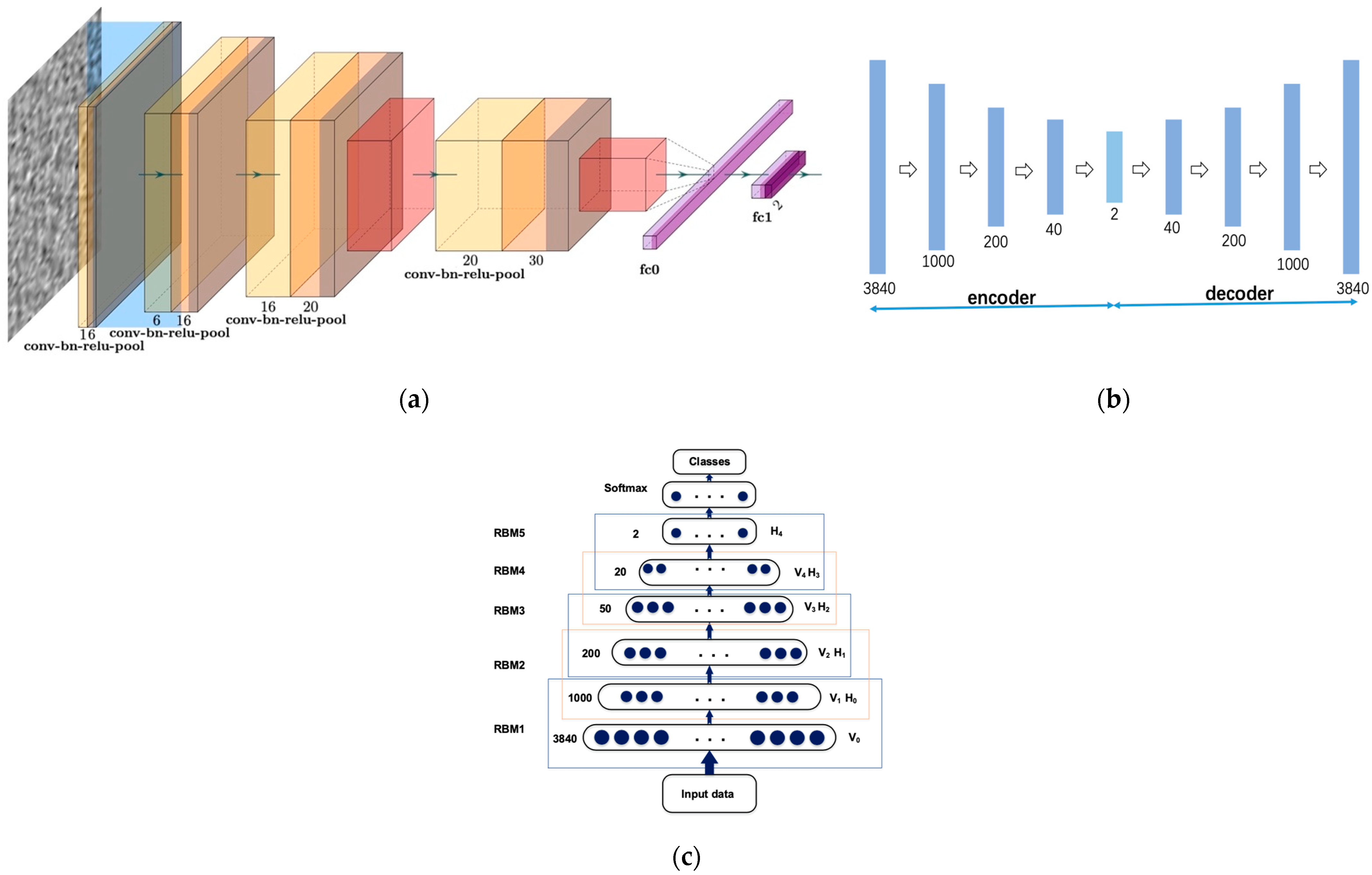
A 3840-800-200-20-2 network was designed for DNN with dropout probabilities set as 0.45, 0.5, and 0.25 for the three hidden layers. Each affine layer was followed by a batch normalization layer and a ReLU activation layer. As illustrated in
Figure 14a, the CNN model deployed in the experiment consists of four modules: the first two submodules contain a convolutional layer followed by batch normalization and ReLU; we also added an additional max-pooling layer for the last two modules. The kernel size was set as three, the striding length was set as two, and no padding was applied. A 0.85 dropout probability was set for the fully connected layer. Each piece of data was converted to a 60 × 64 size image.
4.2.2. Semi-Supervised Generative Architectures
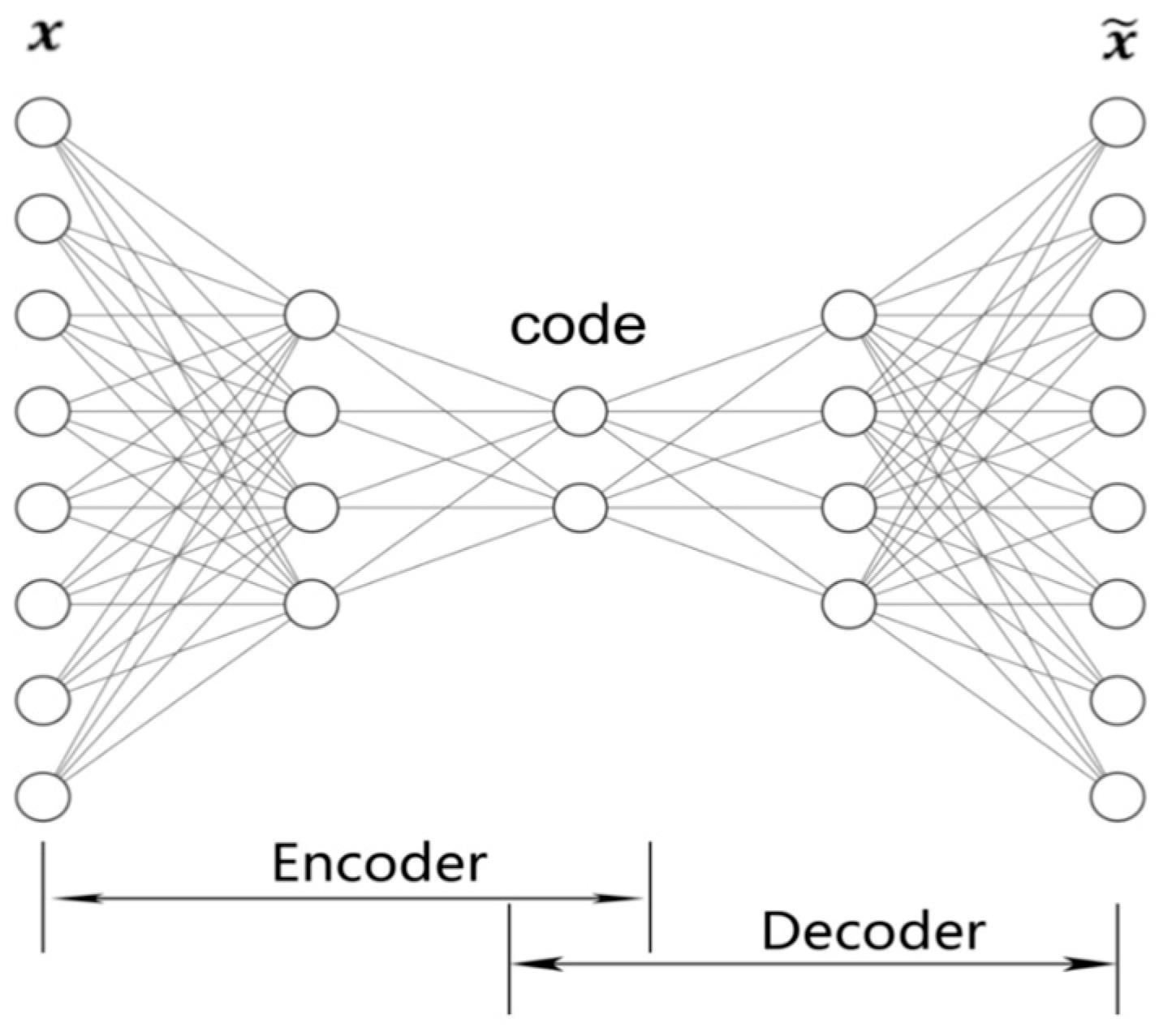
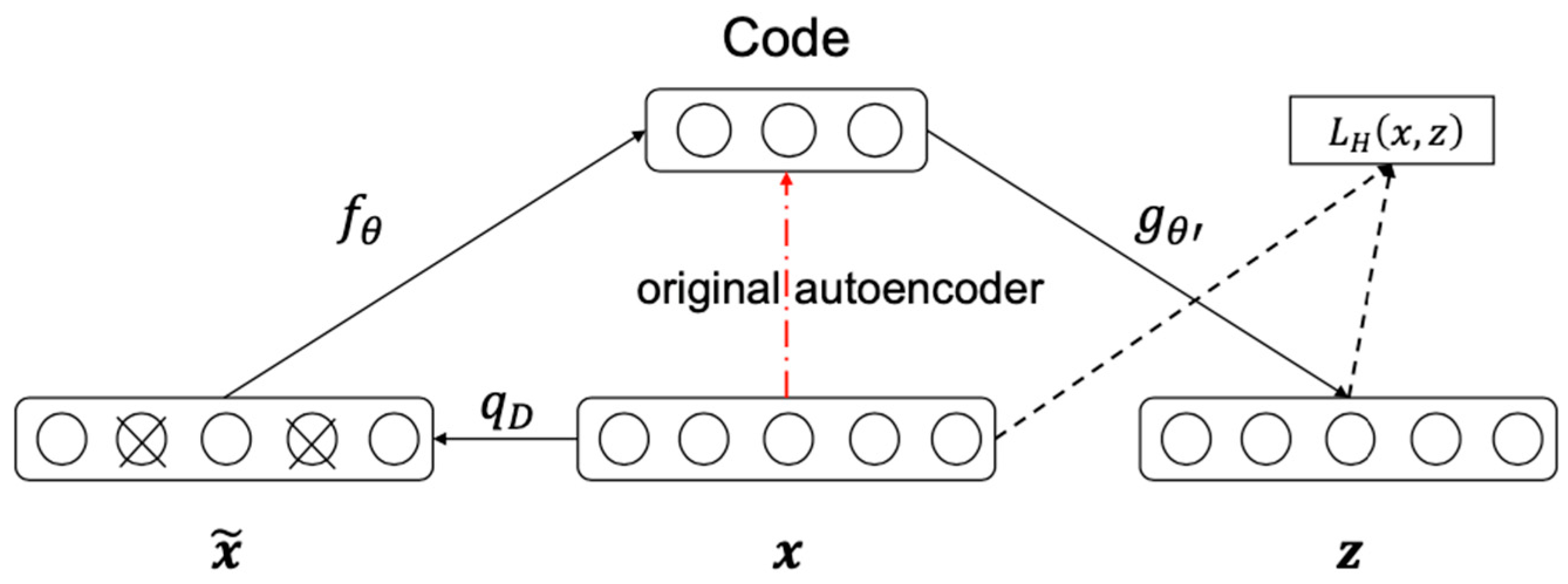
Basic concepts of the stacked denoising autoencoder (SDA) and Deep Belief Network (DBN) are similar. The data were first transformed into a new representation by unsupervised pre-training, and the supervised classifier was layered on top to map the representations into class predictions. Indeed, both minimizing the reconstruction error for autoencoders and contrastive divergence training for RBMs can be seen as an approximation of a log-likelihood gradient. However, stacking ordinary autoencoders regularly underperforms stacking-restricted Boltzmann machines. Our method of stacking denoising autoencoders exhibited superior performance in this section.
Considering that our data were real-valued, we used a linear decoder with a squared reconstruction error for SDA, whose structure is shown in
Figure 14b. For applying noise to the data, we utilized the standard “dropout” method, i.e., resetting values of a fixed random proportion of original data elements to zero. In particular, the proportion was set at 0.2. The fine-tuning output layer takes input only from the top hidden layer. Once the stack of autoencoders has been trained and the stack of encoders has thus been built, the highest-level output representations would be used as input for a stand-alone supervised learning algorithm. A K-nearest neighbor model and a support vector machine with the radial basis function kernel were implemented as classifiers.
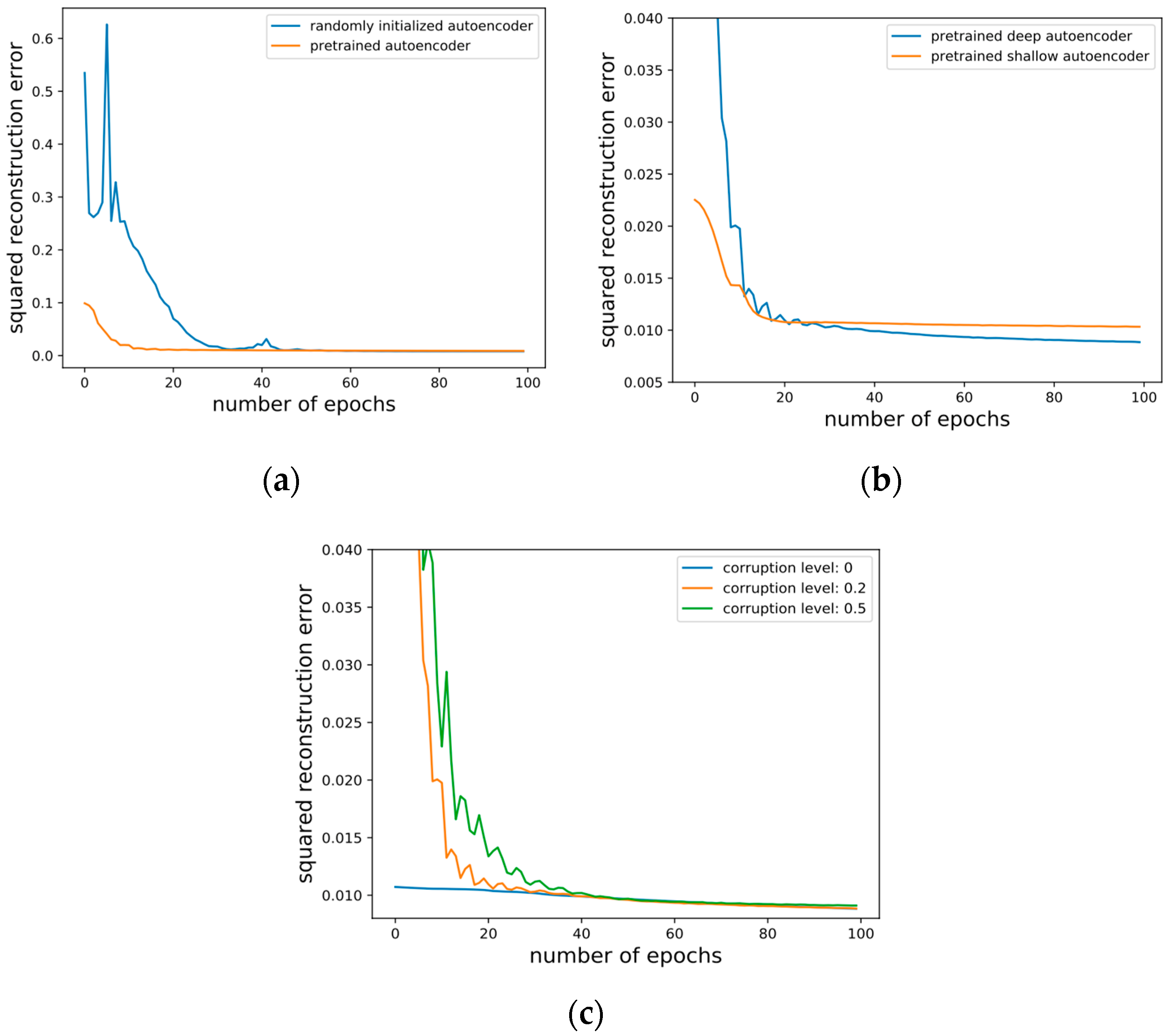
To further investigate the mechanism of action of SDA, we conducted several other experiments. These were to verify the effect of whether to pretrain the depth of stacking and the noise level added in. A 3840-1000-200-40-2 autoencoder was employed. The results are shown in the following
Figure 15.
With or without the unsupervised pre-training, it should be pointed out that the supervised optimization objective and the gradient-based scheme are the same. The only thing that differs is the starting point in the parameter space: either randomly selected or obtained by pre-training. The average squared reconstruction error per test data during fine-tuning is shown in
Figure 15a. Pre-trained autoencoder has a much lower initial error than those without pre-training. Although both decrease the error to near zero in our task, with or without pre-training, pre-training makes progress faster, thus needing less fine-tuning.
The average squared reconstruction error on the test set is shown in
Figure 15b during the fine-tuning. Initially, the error of a deep 3840-1000-200-40-2 autoencoder was greater than that of a the shallower 3840-1000-200-2 autoencoder at first, but the ultimate error of the deeper one went down more rapidly. However, we observed that the hypothesis that the deeper the network, the better the performance does not hold. An appropriate increase in the depth of the network can bring benefits, while an overly large depth seemed to increase the probability of finding poor local minima, resulting in bad performance. A deep 3840-2000-1000-400-100-20-2 autoencoder always got stuck in poor solutions, whereas a shallower 3840-1000-200-40-2 was hardly trapped.
The average squared reconstruction error of different levels of corruption during the fine-tuning on the valence scale using EEG modality only is shown in
Figure 15c. A 3840-1000-200-40-2 autoencoder was employed with 200 epochs of pre-training. The larger the noise level, the more prominent the effect of pre-training, and the fewer fine-tunings required.
The results of the four deep architectures are shown in
Table 7 and
Figure 16. The two widely-used discriminative networks and DBN showed similar performances and were slightly defeated by the two SDA models. When it comes to SDA, the SVM shows a slight advantage (shown in bold).
5. Conclusions and Future Work
In this paper, we explored learning mapping from input to a novel representation. To circumvent the labor of artificially designed features and leverage the power of deep-learning instruments, we proposed to acquire affective and robust representations automatically through the SDA architecture with unsupervised pretraining, followed by supervised fine-tuning using backpropagation of error derivatives. Performances of the different features and models were compared through three binary classification tasks based on the renowned Valence-Arousal-Dominance affection model. We conducted the following three experiments:
- 1.
Used EEG and periphery signals to generate hand-engineered features.
- (a)
We performed decision fusion using traditional machine-learning algorithms with hybrid feature selection;
- (b)
We performed feature fusion and used deep neural networks to compare hand-engineered features with PCA-compressed features.
- 2.
Used augmented data as input after normalization.
- (a)
We fed the augmented data directly into the SDA (feature extractor) after properly pre-processing and then combined the generated features with the classifier for network fine-tuning. To compare the practical effects of our method, we took two discriminative deep architectures (DNN and CNN) and another generative stacked semi-supervised architecture (DBN) as references.
The results of the mentioned experiments are listed: (1) It turns out that the fusion data achieve performances better than, or in-between the two modalities. Accuracies of single-subject recognition are about 20 percent higher than that of cross-subject classification using well-designed hand-engineered features, demonstrating the “highly-personal” nature of emotion. Besides, statistics from the hybrid feature selection showed that features derived from the wavelet transform and the band power were the most preferred in emotion-recognition tasks. Moreover, the results of the feature fusion of hand-crafted features were 0.651 in valence; (2) Results reveal that our scheme (using the model SVM) with an accuracy of 0.652 in valence (data fusion) slightly outperformed the other three deep feature extractors, and also surpassed the state-of-the-art of hand-engineered features.
Due to the diversity and complexity of human emotions, there were still many problems in correctly recognizing them by machines. The main limitations of our work were as follows:
The resulting accuracy was not that high as the model was relatively easy. We need to construct and optimize deep-learning modes by conducting further model fusion to further improve the results.
The system needs to select more effective EGG signal features.
Due to the limited size of the dataset DEAP, training cases were lacking. A larger dataset should be applied as we need to optimize raw data augmentation to decrease the error.
Although this paper has achieved relatively good results in the presented research, further research is still needed. The top issue in emotion detection is the size of databases. More powerful representations are expected to be built with a larger scale of unsupervised learning. In the scarcity of labeled data and an abundance of unlabeled data, semi-supervised learning is more practical. The pre-training and fine-tuning scale linearly in time and space with the number of training examples. The unsupervised pre-training regularizer can have a more profound positive effect on generalization when the number of training cases is larger. Hence, in the future, deep denoising autoencoders would be very affectionate for non-linear dimensionality reduction, provided that the datasets are big enough.
Future work should include investigating and understanding semi-supervised approaches where one does not separate between the unsupervised pre-training phase and the supervised fine-tuning phase. Such techniques fall more squarely into the field of “semi-supervised” learning. Other avenues for future work include using other types of noise or corruption, and the role of noise level also deserves further inquiry.
It is believed that in the near future, research on emotion-recognition technology in the field of artificial intelligence will make greater progress and be better applied in practical products.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}