
Multiview Clustering of Adaptive Sparse Representation Based on Coupled P Systems



Abstract
:1. Introduction
- (1)
- A new coupled P system is proposed, which integrates the construction of a single view matrix and the formation of a unified graph into the P system to perform clustering tasks.
- (2)
- To construct the similarity matrix of each view, this paper introduces a natural neighbor search algorithm without parameters, which can automatically determine the number of neighbors in each view. After that, sparse representation and various learning methods are imported to construct the similarity matrix to preserve the internal geometry of the views.
- (3)
- In forming a unified graph, this paper adopts a soft thresholding operator to learn a consistent sparse structure affinity matrix from the similarity matrix of each view and then obtain the clustering result. Iterative optimization is not required, and better clustering results can be captured and obtained quickly.
- (4)
- Nine multiview data sets are employed to simulate and verify the clustering performances of MVCS-CP.
2. Related Work
2.1. Notations
2.2. Graph-Based Clustering and Graph Learning
2.3. Natural Neighbours
2.4. P System
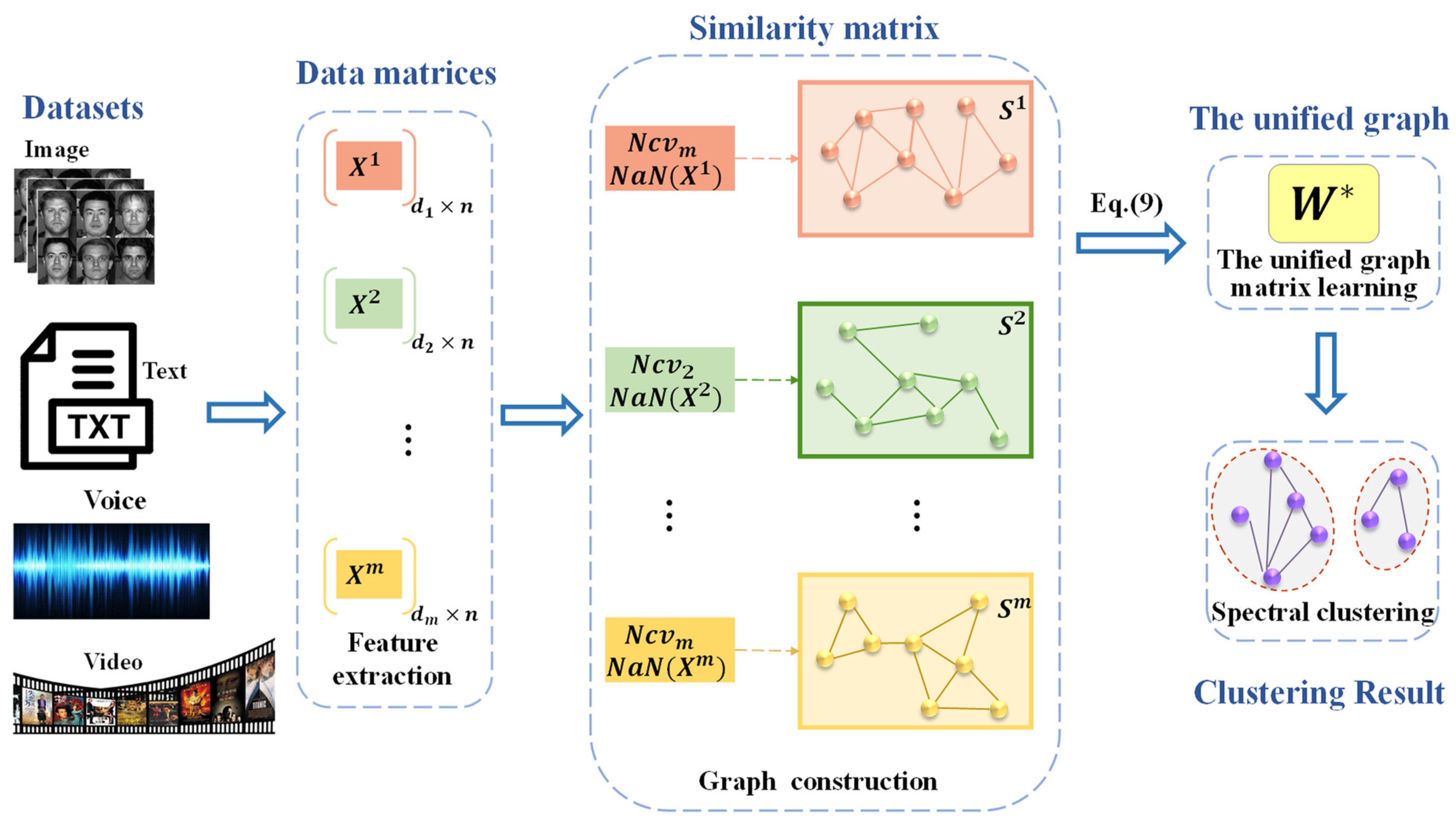
3. Multi-View Clustering of Adaptive Sparse Representation Based on Coupled P Systems
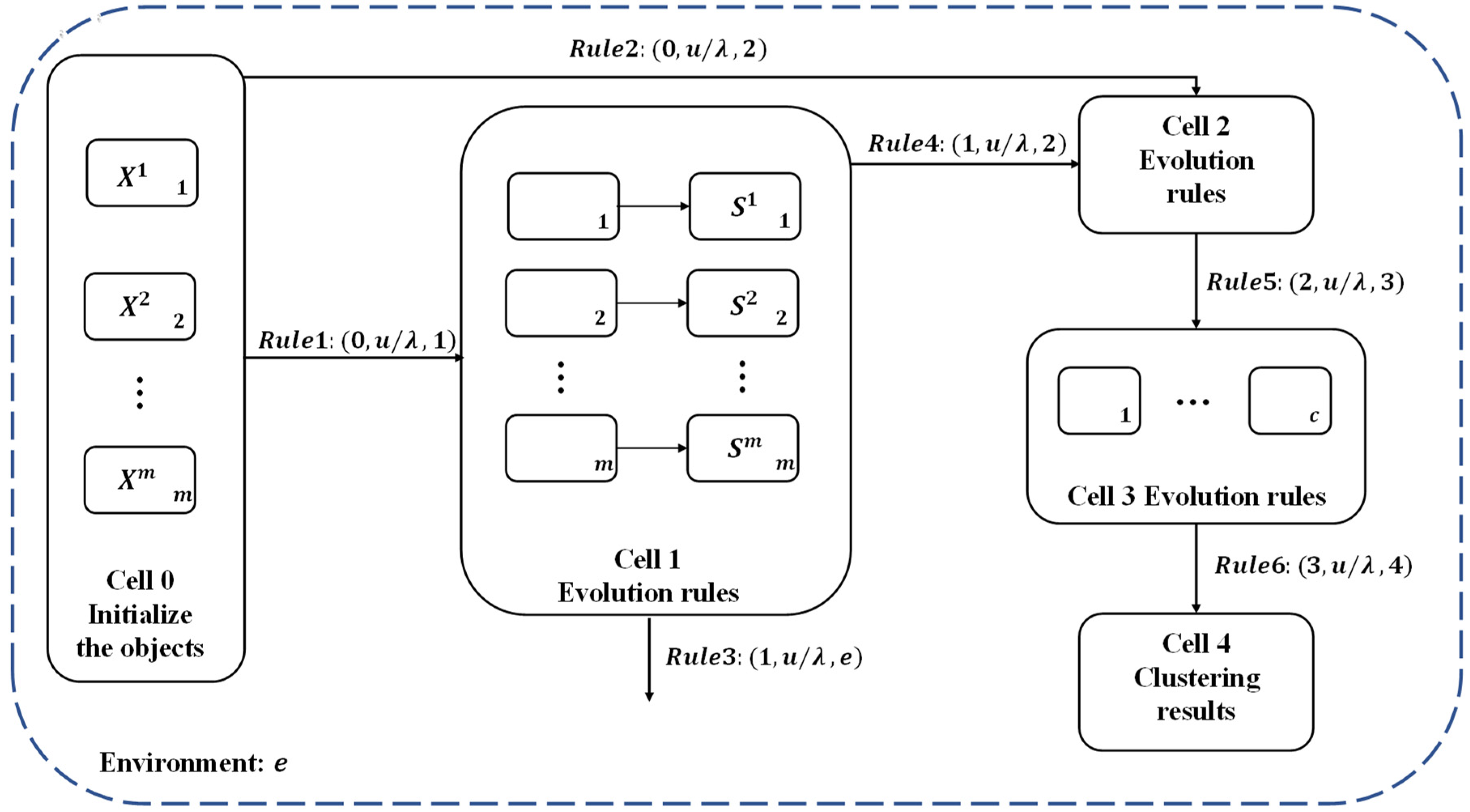
3.1. The General Framework of the Proposed Coupled P System
- . , represent the original data ofviews and the similarity matrix corresponding to each view, respectively.is the natural neighbor of the data pointin the view.refers to the characteristic natural value, and the number of reverse neighbors ofis denoted as. represents the learned uniform unified graph matrix.andindicate the degree matrix and Laplacian matrix, respectively. The parametersandrespectively refer to the parameters required for the experiment and the number of clusters.
- is the initial objects in the coupled systems.
- signifies the synapse between cells, whose main function is to connect cells and make them communicate with each other.
- denotes the cells (membrane) in the system.depends on the number of views and the number of clusters in the data set, that is, the total number of cells in the system.
- represents a collection of communication rules and evolution rules in the system. The role of evolution rules is to modify objects and communication rules are used to transfer objects between cells (membranes).
- is cell 0, which is the input membrane.is cell 5, output membrane, used to store the final clustering results.
3.2. The Evolution Rules
3.2.1. The Evolution Rules of Determining Ncv and Constructing Similarity Matrix in Cell 1
- R11 (Iterative search rules): At the th iteration, for each data point in the single view , we search for its th neighbor using a KD tree. After that, correspond to the concepts in Section 2.3. will be transported to the related subcell to construct the similarity matrix .
- R12 (Iterative stop rules): If the number of reverse neighbors of data point does not change or , the evolution rules stop.
- R13 (Determine the rule): The natural characteristic value is calculated by Equation (2), which is equivalent to the number of neighbors , and then is transmitted to the relevant subunits to prepare for the construction of .
- R14 (Lagrange function rule): The Lagrange function of Equation (17) is
- R15 (Constraint rule): Based on the Karush–Kuhn–Tucker constraint, the optimal solution can be acquired, where . As a result of the constraints , it has .
- R16 (Determining rule): Since there are only non-zero values in , has a maximum value, which is conveyed as .
- R17 (Getting the rule): The -th element of is as follows:
3.2.2. The Evolution Rules of Constructing the Unified Graph Matrix, Degree Matrix, Laplacian Matrix in Cell 2
- (1).
- The unified graph matrix and the similarity matrix of each view tend to be as consistent as possible.
- (2).
- The unified graph matrix is sparse, which can further alleviate the noises generated by different views.
- R21 (Removing the rule): Removing the cons, then the problem (11) is redefined as , where .
- R22 (Soft-thresholding operator rule): Based on the above, when the soft-thresholding operator is introduced here:
- R23 (Obtaining rule): By conducting the element-wise, it can be extended to the matrix. In addition, as shown in [52], the approximate solution to problem (13) is .
- R24 (Constructing the Degree Matrix rule): According to , the degree matrix is gained.
- R25 (Constructing the Laplacian Matrix rule): In terms of the Laplacian Matrix, it is based upon and , .
3.2.3. The Evolution Rules of K-Means in Cell 3
- R31 (Building new cluster instances rule): The formation of clustering new instances is conducive to K-means clustering. We select the eigenvectors corresponding to the first eigenvalues of , and standardize it to obtain .
- R32 (Randomly selecting clustering centers rule): Among the points of , it randomly selects points as the initial clustering centers and stores them in the subcells.
- R33 (Clustering rule): After that, the distance from each instance to each cluster center is computed in the subcells simultaneously and transported to cell 3. Finally, the instances are allocated based on the principle of minimum distance to form different clusters in cell 3.
- R34 (Outputting result rules): For clusters divided in accordance with rule R35, it takes the current average distance of each cluster as the new cluster center. Comparing the current cluster center with the previous cluster center, if there is a change, it repeats rule R35. Conversely, the result of clustering is outputted to cell 4.
3.3. The Communication Rules between Different Cells
- (1)
- Unidirectional transport between cells. is a string containing the object. is the empty string.
- : It feeds containing the original data of views into cell 2 for the determination of the similarity matrix for each view.
- : The including the parameter and the number of clusters are transferred to cell 3 to format the unified graph matrix and construct the degree matrix and the Laplacian matrix.
- : The string of similarity matrix for each view produced by cell 1 is transported to cell 2 for the construction of the unified graph matrix.
- : It conveys the string containing the Laplacian matrix and the number of clusters to cell 3 for K-means clustering.
- : The string of clustering results generated by K-means is transmitted to cell 4 for storage.
- (2)
- Unidirectional transport between cells and the environment.
- : It transports the string of the resulting reverse neighbor into the environment to release.
4. Experiments
4.1. Datasets
- Caltech101 [59]: Coltech101-07 and Coltech101-20 are selected from the Caltech101 dataset, which includes 2386 and 1474 images, respectively. Each image contains six feature vectors of GABOR, WM (wavelet moment), CENT (Centrist features), HOG, GIST and LBP.
- NUS [60]: It contains 2400 images in 12 categories. The six features of colour histogram, CM, edge direction histogram, wavelet texture, block-wise colour moment and SIFT description are included for each image.
- ORL [61]: This dataset contains 400 images with four feature vectors of GIST, HOG, LBP, and CENT.
- 3sources: This dataset contains 169 news documents reported by three online news organizations, BBC, The Guardian and Reuters.
- BBC [62]: It is a collection of 685 documents from the BBC News website, each divided into four feature vectors.
- BBC_Sport [62]: This dataset consists of 544 documents collected from the BBC Sports website; each document has two feature vectors.
- 100leaves [63]: It consists of 1600 samples from the UCI repository, each of which is one of a hundred species.
- Scene15 [64]: It consists of 4485 images of indoor and outdoor scenes with a total of three views.
4.2. Evaluation Metrics
- (1).
- Accuracy: ACC refers to the ratio of the number of correctly clustered samples to the total number of instances .
- (2).
- Adjusted Rand Index: The value range of the ARI is [−1, 1].
- (3).
- Normalized Mutual Information: measures the difference between cluster partitions through information theory. The value range is [0, 1]
- (4).
- : It represents the probability of the true positive sample among all predicted positive samples.
- (5).
- F1-score: is the harmonic mean of precision and recall to comprehensively measure the clustering effect.
- (6).
- : The general idea of cluster purity is to divide the number of correctly clustered instances by the total number of instances.
4.3. Compared Methods
- SC [65] performs clustering on every single view and concatenates all views in the dataset into one view (Featconcat) for clustering.
- GBS [33] proposes a general graph-based multiview clustering system. The number of neighbors takes its default setting of 5.
- AMGL [66] is a parameter-free model for spectral embedding learning that automatically learns the weights for each view by solving a square root trace minimization problem.
- MVGL [67] uses it to explore the Laplacian rank-constrained graph after obtaining the similarity graph for each view, where the number of neighbors is set to a default value of 10.
- ASMV [32] adaptively jointly optimizes the data correlation between multiple features, and the number of neighbors is set to 15.
- CDMGC [36] is a graph clustering method of explicitly exploiting both multiview consistency and multiview diversity. The parameters in the experiment leverage the default values in the code provided by the author.
- CoMSC [68] is a multiview subspace clustering algorithm that groups objects and simultaneously removes data redundancy. In the experiment, the two parameters and are respectively searched in and , where is the number of classes.
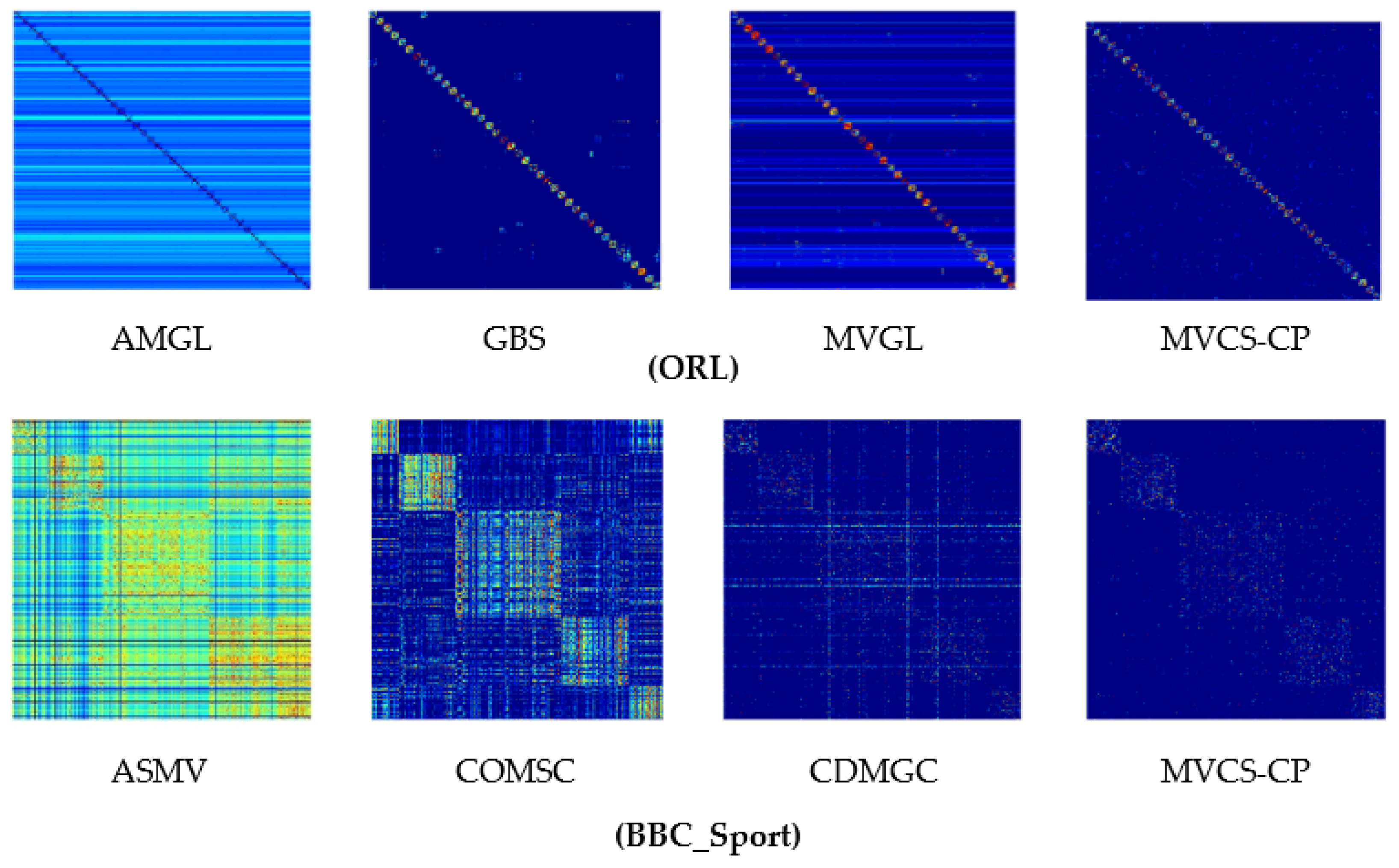
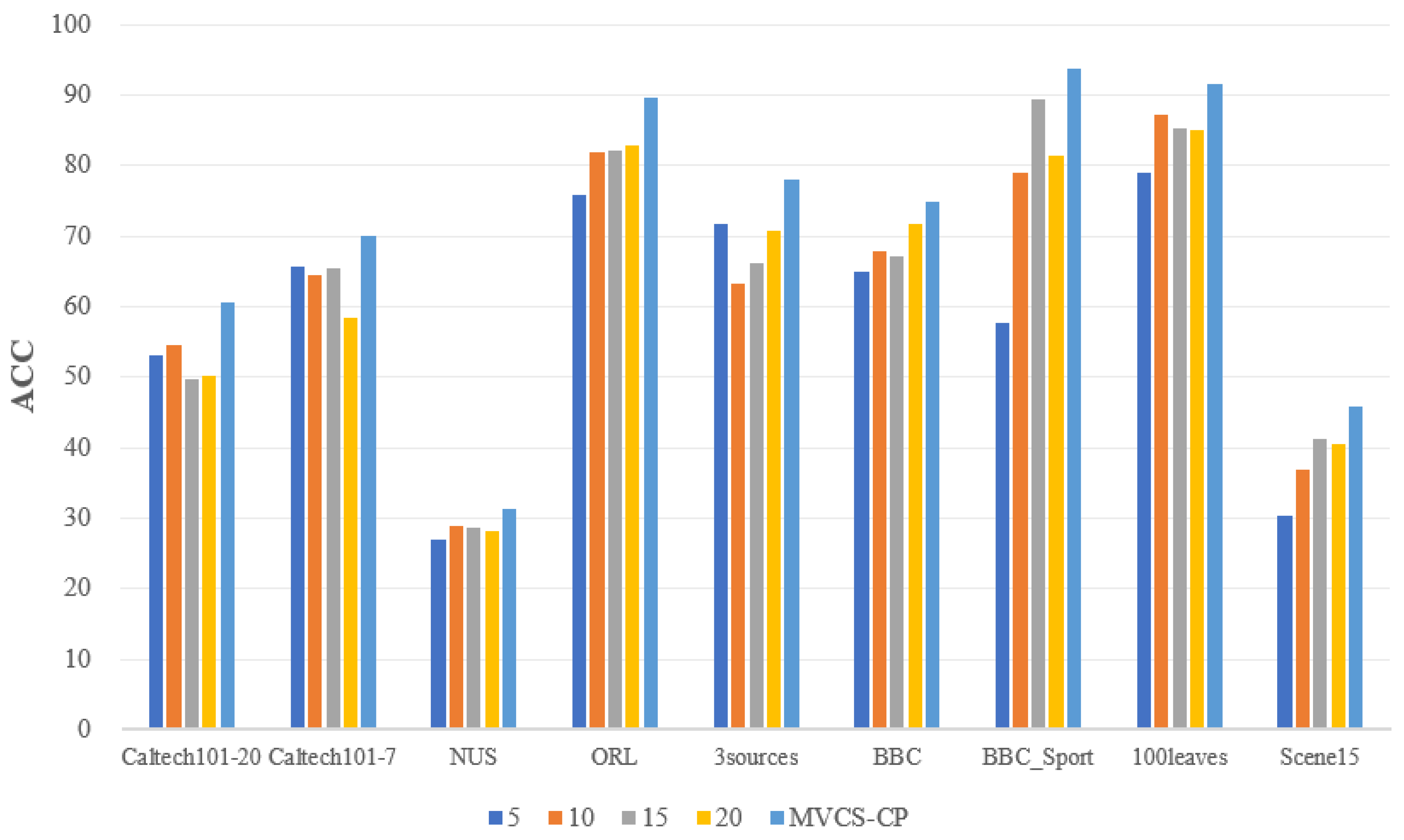
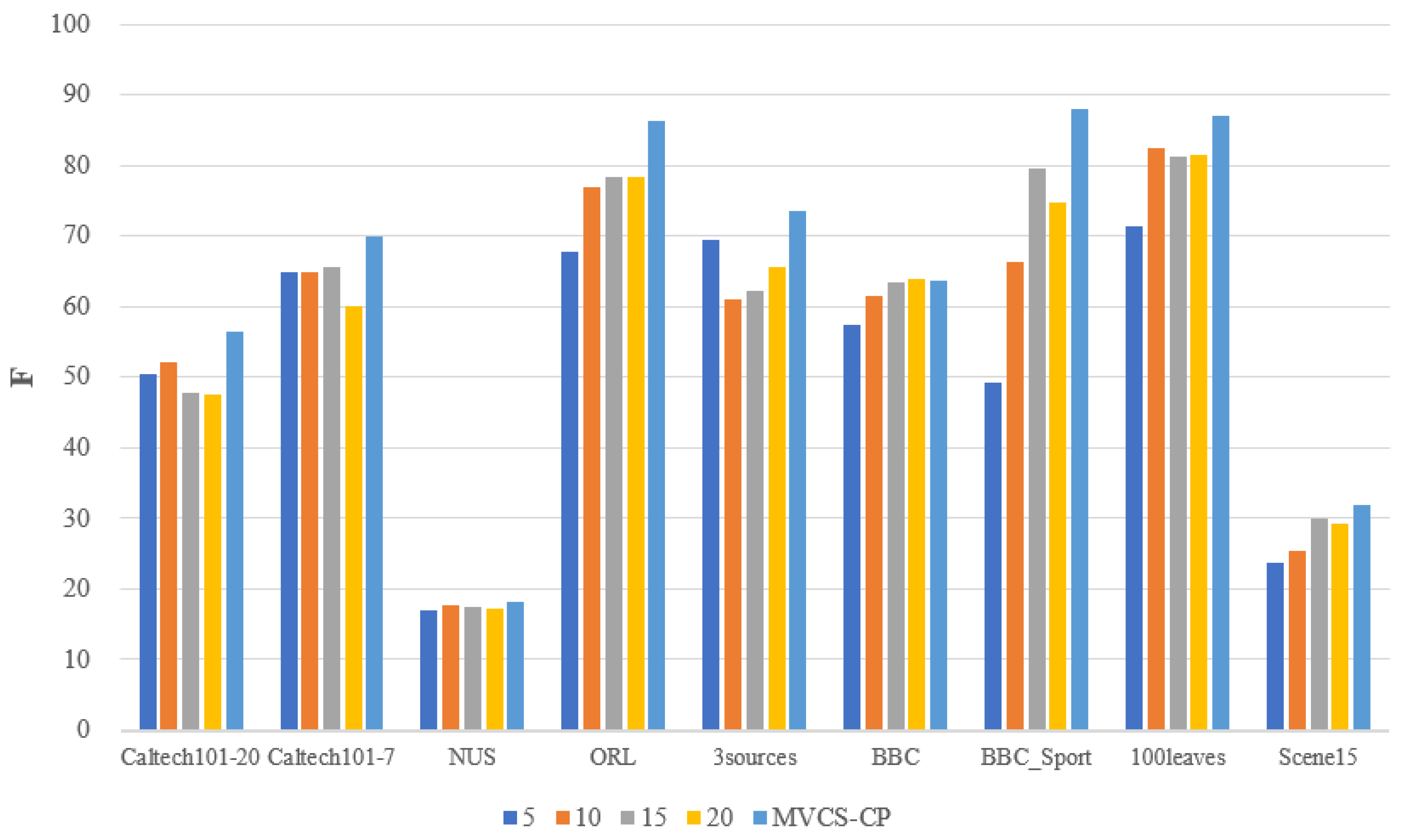
- The proposed MVCS-CP method performs better on six evaluation metrics on all datasets, basically being the best or second best. In the caltech101-20 dataset, it has the best performance on the four metrics of ARI, NMI, precision and purity with 8%, 2%, 4% and 6% improvement over the second-best results. As far as the caltech101-7 dataset is concerned, the three indicators of ACC, Precision and Purity are the best, and the remaining indicators ARI, NMI and F are the second best. In terms of the NUS dataset, except for the F indicator, the rest of the indicators perform the best. Compared with the better overall performance of CoMSC, the effect was increased by 5% (ACC), 2% (ARI), 2% (NMI), 2% (Precision) and 16% (Purity), respectively. Synthesizing the caltech101-20, caltech101-7 and NUS datasets, it can be concluded that the proposed MVCS-CP can achieve better results in processing more than five views. MVCS-CP performs optimally on all six metrics for the ORL dataset, with an average of 2% improvement for each metric over the second-best result. As for the 100leaves dataset, except for the NMI indicator, which is 0.5% lower than the second-best, all other indicators perform the best. The ORL and 100 leaves datasets have more clusters numbers (40 and 100 categories, respectively). Based on the above experimental results, it can be found that MVCS-CP can cope well with rich clusters number. On the 3sources dataset and the BBC dataset, the proposed algorithm demonstrates obvious improvement on all indicators. In addition, the BBC_Sport dataset has the best performance on the remaining five metrics except for Precision, which is the second-best. Combining the three datasets of 3sources, BBC and BBC_Sport, all of them have a higher dimension of the order of thousands. It can be seen that the proposed MVCS-CP can achieve satisfactory results when dealing with datasets with higher dimensions.
- Furthermore, the Scene dataset has the best performance on four metrics (ACC, ARI, Precision and Purity), especially on Purity, which is 7% better than the second-best result. And it is comparable to the best results on the NMI indicator. This illustrates that MVCS-CP can handle larger-scale datasets.
- Compared with the state-of-the-art multiview clustering algorithms, the MVCS-CP algorithm has better or comparable performance. This suggests that taking each view’s geometry and sparse representation into account yields better results.
- In terms of the single-view method, it is found that the multiview clustering algorithm is basically better than it, which shows that considering the multiple features of the dataset can be better clustered. However, on the BBC_Sport dataset, Featconcat performs the best in terms of Precision, which means that the multiview clustering method still needs further improvement.
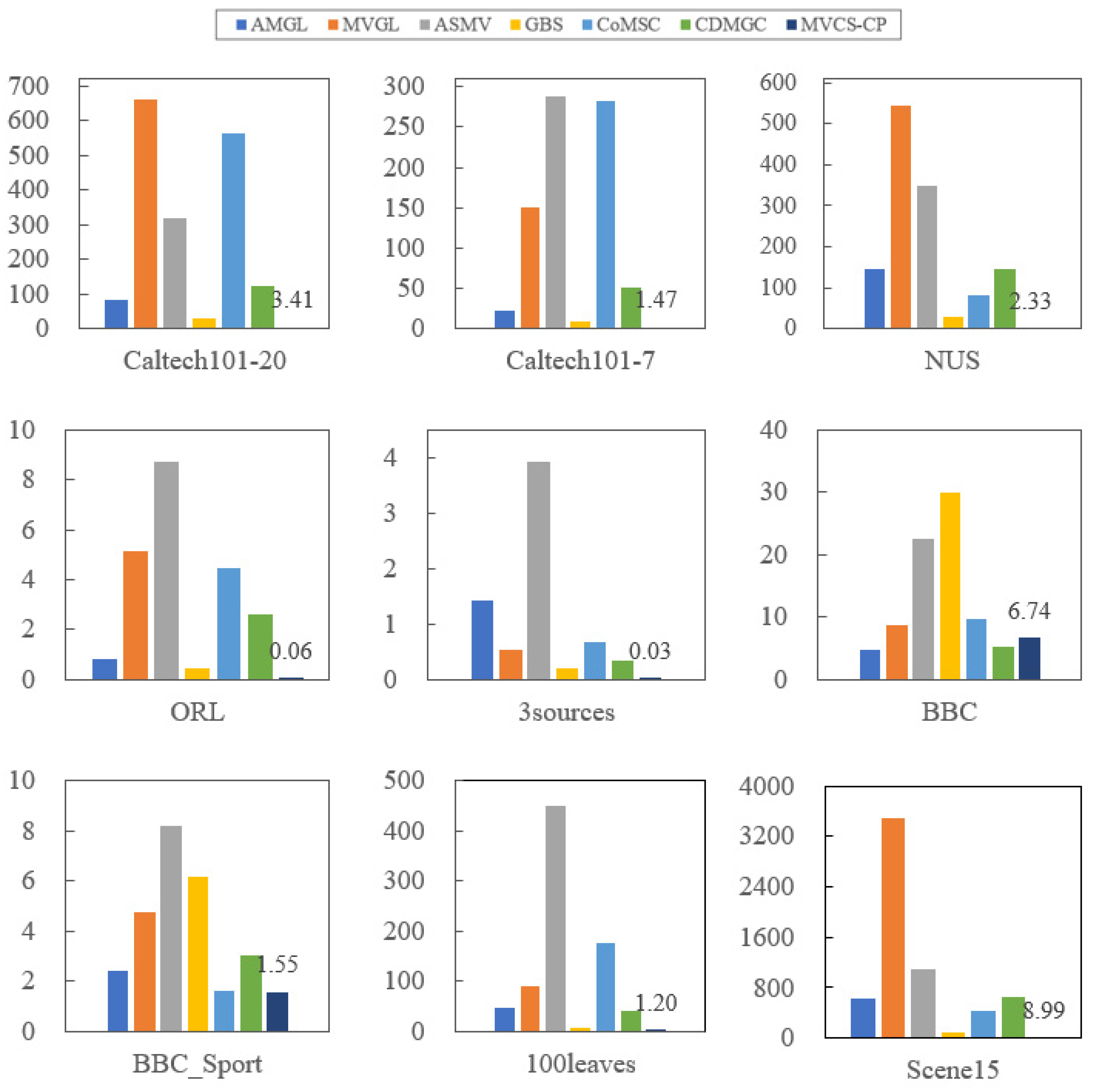
4.4. Running Time
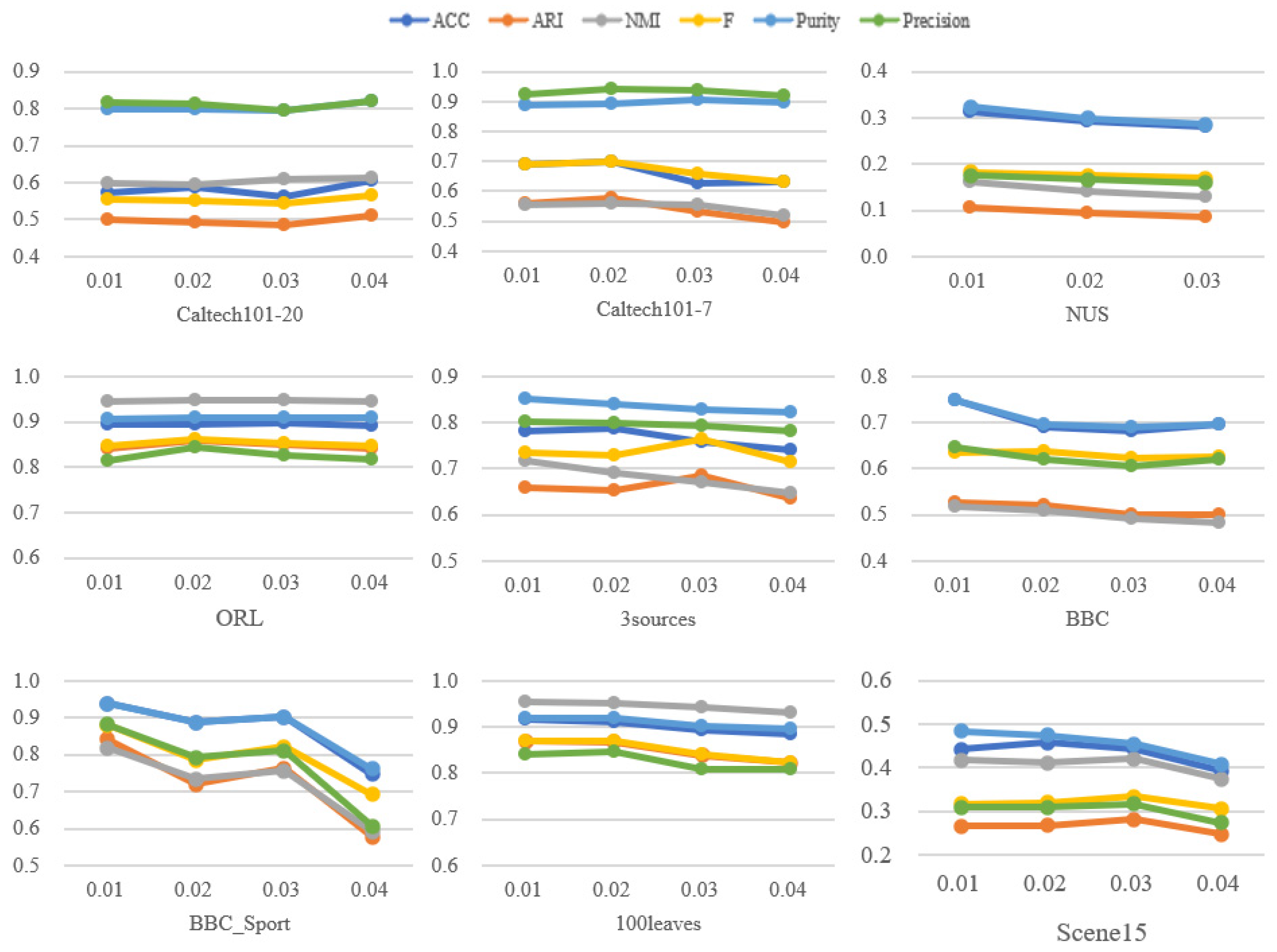
4.5. Comparison of the Number of Neighbors
4.6. Parameter Analysis
4.7. Result Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Janani, R.; Vijayarani, S. Text document clustering using Spectral Clustering algorithm with Particle Swarm Optimization. Expert Syst. Appl. 2019, 134, 192–200. [Google Scholar] [CrossRef]
- Djenouri, Y.; Belhadi, A.; Fournier-Viger, P.; Lin, J.C.W. Fast and effective cluster-based information retrieval using frequent closed itemsets. Inf. Sci. 2018, 453, 154–167. [Google Scholar] [CrossRef] [Green Version]
- Ge, C.J.; de Oliveira, R.A.; Gu, I.Y.H.; Bollen, M.H.J. Deep Feature Clustering for Seeking Patterns in Daily Harmonic Variations. IEEE Trans. Instrum. Meas. 2021, 70, 2501110. [Google Scholar] [CrossRef]
- Bang, H.; Zhou, X.K.; Van Epps, H.L.; Mazumdar, M. Statistical Methods in Molecular Biology; Humana Press: Totowa, NJ, USA, 2010. [Google Scholar]
- Fu, L.L.; Lin, P.F.; Vasilakos, A.V.; Wang, S.P. An overview of recent multi-view clustering. Neurocomputing 2020, 402, 148–161. [Google Scholar] [CrossRef]
- Hu, Z.X.; Nie, F.P.; Chang, W.; Hao, S.Z.; Wang, R.; Li, X.L. Multi-view spectral clustering via sparse graph learning. Neurocomputing 2020, 384, 1–10. [Google Scholar] [CrossRef]
- Tan, J.P.; Yang, Z.J.; Cheng, Y.Q.; Ye, J.L.; Wang, B.; Dai, Q.Y. SRAGL-AWCL: A two-step multi-view clustering via sparse representation and adaptive weighted cooperative learning. Pattern Recognit. 2021, 117, 107987. [Google Scholar] [CrossRef]
- Cai, Y.; Jiao, Y.Y.; Zhuge, W.Z.; Tao, H.; Hou, C.P. Partial multi-view spectral clustering. Neurocomputing 2018, 311, 316–324. [Google Scholar] [CrossRef]
- Shi, S.J.; Nie, F.P.; Wang, R.; Li, X.L. Auto-weighted multi-view clustering via spectral embedding. Neurocomputing 2020, 399, 369–379. [Google Scholar] [CrossRef]
- Li, Z.L.; Tang, C.; Chen, J.J.; Wan, C.; Yan, W.Q.; Liu, X.W. Diversity and consistency learning guided spectral embedding for multi-view clustering. Neurocomputing 2019, 370, 128–139. [Google Scholar] [CrossRef]
- Wu, J.L.; Lin, Z.C.; Zha, H.B. Essential Tensor Learning for Multi-View Spectral Clustering. IEEE Trans. Image Process. 2019, 28, 5910–5922. [Google Scholar] [CrossRef] [Green Version]
- Brbic, M.; Kopriva, I. Multi-view low-rank sparse subspace clustering. Pattern. Recogn. 2018, 73, 247–258. [Google Scholar] [CrossRef] [Green Version]
- Niu, G.L.; Yang, Y.L.; Sun, L.Q. One-step multi-view subspace clustering with incomplete views. Neurocomputing 2021, 438, 290–301. [Google Scholar] [CrossRef]
- Zhu, W.C.; Lu, J.W.; Zhou, J. Structured general and specific multi-view subspace clustering. Pattern. Recognit. 2019, 93, 392–403. [Google Scholar] [CrossRef]
- Xiong, L.Y.; Wang, C.; Huang, X.H.; Zeng, H. An Entropy Regularization k-Means Algorithm with a New Measure of between-Cluster Distance in Subspace Clustering. Entropy 2019, 21, 683. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zong, L.L.; Zhang, X.C.; Zhao, L.; Yu, H.; Zhao, Q.L. Multi-view clustering via multi-manifold regularized non-negative matrix factorization. Neural Netw. 2017, 88, 74–89. [Google Scholar] [CrossRef] [Green Version]
- Luo, P.; Peng, J.Y.; Guan, Z.Y.; Fan, J.P. Dual regularized multi-view non-negative matrix factorization for clustering. Neurocomputing 2018, 294, 1–11. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Gao, H.B.; Li, G.P.; Zhao, J.H.; Huo, J.H.; Yin, J.L.; Liu, Y.C.; Zheng, L. Multi-view clustering based on graph-regularized nonnegative matrix factorization for object recognition. Inf. Sci. 2018, 432, 463–478. [Google Scholar] [CrossRef]
- Huang, A.P.; Zhao, T.S.; Lin, C.W. Multi-View Data Fusion Oriented Clustering via Nuclear Norm Minimization. IEEE Trans. Image Process. 2020, 29, 9600–9613. [Google Scholar] [CrossRef]
- Lu, G.F.; Zhao, J.B. Latent multi-view self-representations for clustering via the tensor nuclear norm. Appl. Intell. 2022, 52, 6539–6551. [Google Scholar] [CrossRef]
- Zhang, X.Q.; Sun, H.J.; Liu, Z.G.; Ren, Z.W.; Cui, Q.J.; Li, Y.M. Robust low-rank kernel multi-view subspace clustering based on the Schatten p-norm and correntropy. Inf. Sci. 2019, 477, 430–447. [Google Scholar] [CrossRef]
- Wang, Q.; Dou, Y.; Liu, X.W.; Xia, F.; Lv, Q.; Yang, K. Local kernel alignment based multi-view clustering using extreme learning machine. Neurocomputing 2018, 275, 1099–1111. [Google Scholar] [CrossRef]
- Huang, Z.Y.; Hu, P.; Peng, X. Partially View-aligned Clustering. In Proceedings of the 33th Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- Yang, M.X.; Li, Y.F.; Huang, Z.Y.; Liu, Z.T.; Hu, P.; Peng, X. Partially View-aligned Representation Learning with Noise-robust Contrastive Loss. In Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Yang, M.X.; Li, Y.F.; Hu, P.; Bai, J.F.; Lv, J.C.; Peng, X. Robust Multi-View Clustering with Incomplete Information. IEEE Trans. Pattern. Anal. 2022; online ahead of print. [Google Scholar] [CrossRef] [PubMed]
- Jiang, B.; Qiu, F.Y.; Wang, L.P.; Zhang, Z.J. Bi-level weighted multi-view clustering via hybrid particle swarm optimization. Inf. Process. Manag. 2016, 52, 387–398. [Google Scholar] [CrossRef]
- De Gusmao, R.P.; de Carvalho, F.D.T. Clustering of multi-view relational data based on particle swarm optimization. Expert Syst. Appl. 2019, 123, 34–53. [Google Scholar] [CrossRef]
- De Gusmao, R.P.; de Carvalho, F.D.T. PSO for Fuzzy Clustering of Multi-View Relational Data. Int. J. Pattern. Recognit. 2020, 34, 2050022. [Google Scholar] [CrossRef]
- Dutta, P.; Mishra, P.; Saha, S. Incomplete multi-view gene clustering with data regeneration using Shape Boltzmann Machine. Comput. Biol. Med. 2020, 125, 103965. [Google Scholar] [CrossRef] [PubMed]
- Saini, N.; Bansal, D.; Saha, S.; Bhattacharyya, P. Multi-objective multi-view based search result clustering using differential evolution framework. Expert Syst. Appl. 2021, 168, 114299. [Google Scholar] [CrossRef]
- Guerin, J.; Thiery, S.; Nyiri, E.; Gibaru, O.; Boots, B. Combining pretrained CNN feature extractors to enhance clustering of complex natural images. Neurocomputing 2021, 423, 551–571. [Google Scholar] [CrossRef]
- Zhan, K.; Chang, X.; Guan, J.; Chen, L.; Ma, Z.; Yang, Y. Adaptive Structure Discovery for Multimedia Analysis Using Multiple Features. IEEE Trans. Cybern. 2019, 49, 1826–1834. [Google Scholar] [CrossRef]
- Wang, H.; Yang, Y.; Liu, B.; Fujita, H. A study of graph-based system for multi-view clustering. Knowl.-Based Syst. 2019, 163, 1009–1019. [Google Scholar] [CrossRef]
- Peng, X.; Huang, Z.Y.; Lv, J.C.; Zhou, J.T. COMIC: Multi-View Clustering without Parameter Selection. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Wang, H.; Yang, Y.; Liu, B. GMC: Graph-Based Multi-View Clustering. IEEE Trans. Knowl. Data Eng. 2020, 32, 1116–1129. [Google Scholar] [CrossRef]
- Huang, S.; Tsang, I.; Xu, Z.; Lv, J.C. Measuring Diversity in Graph Learning: A Unified Framework for Structured Multi-View Clustering. IEEE Trans. Knowl. Data Eng. 2021; early access. [Google Scholar] [CrossRef]
- Paun, G. Computing with membranes. J. Comput. Syst. Sci. 2000, 61, 108–143. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.X.; Pan, L.Q. A Survey of Membrane Computing as a New Branch of Natural Computing. Chin. J. Comput. 2010, 33, 208–214. [Google Scholar]
- Wu, T.; Pan, L.; Yu, Q.; Tan, K.C. Numerical Spiking Neural P Systems. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 2443–2457. [Google Scholar] [CrossRef]
- Ren, Q.; Liu, X.; Sun, M. Turing Universality of Weighted Spiking Neural P Systems with Anti-Spikes. Comput. Intell. Neurosci. 2020, 2020, 8892240. [Google Scholar] [CrossRef]
- Wang, L.P.; Liu, X.Y.; Zhao, Y.Z. Universal Nonlinear Spiking Neural P Systems with Delays and Weights on Synapses. Comput. Intell. Neurosci. 2021, 2021, 3285719. [Google Scholar] [CrossRef]
- Song, B.S.; Li, K.L.; Zeng, X.X. Monodirectional Evolutional Symport Tissue P Systems with Promoters and Cell Division. IEEE Trans. Parall. Distr. 2022, 33, 332–342. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, L.; Liu, Z.; Peng, H.; Wang, J. ConvSNP: A deep learning model embedded with SNP-like neurons. J. Membr. Comput. 2022, 4, 87–95. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, X.; Wang, L. Spectral Clustering Algorithm Based on Improved Gaussian Kernel Function and Beetle Antennae Search with Damping Factor. Comput. Intell. Neurosci. 2020, 2020, 1648573. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, X. Noises Cutting and Natural Neighbors Spectral Clustering Based on Coupling P System. Processes 2021, 9, 439. [Google Scholar] [CrossRef]
- Jiang, Z.; Liu, X.; Sun, M. A Density Peak Clustering Algorithm Based on the K-Nearest Shannon Entropy and Tissue-Like P System. Math. Probl. Eng. 2019, 2019, 1713801. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.W.; Libraty, N.; On, O.; On, K.A.; On, K.A. The Laplacian spectrum of graphs. Int. J. Combin. Appl. 1991, 18, 871–898. [Google Scholar]
- Surhone, L.M.; Tennoe, M.T.; Henssonow, S.F. Spectral Graph Theory; Published for the Conference Board of the Mathematical Sciences by the American Mathematical Society; American Mathematical Society: Providence, RI, USA, 2010. [Google Scholar]
- Tarjan, R. Depth-first search and linear graph algorithms. In Proceedings of the Symposium on Switching & Automata Theory, East Lansing, MI, USA, 13–15 October 1971. [Google Scholar]
- Fan, K. On a Theorem of Weyl Concerning Eigenvalues of Linear Transformations I. Proc. Natl. Acad. Sci. USA 1949, 35, 11. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.L.; Zhu, Q.S.; Yang, L.J.; Feng, J. A non-parameter outlier detection algorithm based on Natural Neighbor. Knowl.-Based Syst. 2016, 92, 71–77. [Google Scholar] [CrossRef]
- Zhu, Q.S.; Feng, J.; Huang, J.L. Natural neighbor: A self-adaptive neighborhood method without parameter K. Pattern. Recognit. Lett. 2016, 80, 30–36. [Google Scholar] [CrossRef]
- Cai, D.; He, X.F.; Han, J.W.; Huang, T.S. Graph Regularized Nonnegative Matrix Factorization for Data Representation. IEEE Trans. Pattern. Anal. 2011, 33, 1548–1560. [Google Scholar]
- Hao, W.; Yan, Y.; Li, T. Multi-View Clustering via Concept Factorization with Local Manifold Regularization. In Proceedings of the IEEE International Conference on Data Mining (ICDM2016), Barcelona, Spain, 12–15 December 2016. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern. Anal. 2009, 31, 210–227. [Google Scholar] [CrossRef] [Green Version]
- Nie, F.; Wang, X.; Jordan, M.I.; Huang, H. The Constrained Laplacian Rank Algorithm for Graph-Based Clustering. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI’16), Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Candes, E.J.; Wakin, M.B. An introduction to compressive sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Candes, E.J.; Li, X.D.; Ma, Y.; Wright, J. Robust Principal Component Analysis? J. ACM 2011, 58, 11. [Google Scholar] [CrossRef]
- Dueck, D.; Frey, B.J. Non-metric affinity propagation for unsupervised image categorization. In Proceedings of the IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007. [Google Scholar]
- Tat-Seng Chua, J.T.; Li, H.; Luo, Z.; Zheng, Y. NUS-WIDE: A real-world web image database from National University of Singapore. In Proceedings of the ACM International Conference on Image and Video Retrieval, Fira, Greece, 8–10 July 2009. [Google Scholar]
- Samaria, F.S.; Harter, A.C. Parameterisation of a stochastic model for human face identification. In Proceedings of the 1994 IEEE Workshop on Applications of Computer Vision, Sarasota, FL, USA, 5–7 December 1994. [Google Scholar]
- Greene, D.; Cunningham, P. Practical solutions to the problem of diagonal dominance in kernel document clustering. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006. [Google Scholar]
- Mallah, C.; Cope, J.; Orwell, J. Plant Leaf Classification Using Probabilistic Integration of Shape, Texture and Margin Features; Acta Press: Calgary, AB, USA, 2013. [Google Scholar]
- Li, F.F.; Perona, P. A Bayesian Hierarchical Model for Learning Natural Scene Categories. In Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On Spectral Clustering: Analysis and an Algorithm. In Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic, Vancouver, BC, Canada, 3–8 December 2001. [Google Scholar]
- Nie, F.P.; Li, J.; Li, X.L. Parameter-Free Auto-Weighted Multiple Graph Learning: A Framework for Multiview Clustering and Semi-Supervised Classification. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Zhan, K.; Zhang, C.; Guan, J.; Wang, J. Graph Learning for Multiview Clustering. IEEE Trans. Cybern. 2018, 48, 2887–2895. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Liu, X.; Yang, Y.; Guo, X.; Kloft, M.; He, L. Multiview Subspace Clustering via Co-Training Robust Data Representation. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Objects | View | Clusters | d | d | d | d | d | d |
|---|---|---|---|---|---|---|---|---|---|
| Caltech101-20 | 2386 | 6 | 20 | 48 | 40 | 254 | 1984 | 512 | 928 |
| Caltech101-7 | 1474 | 6 | 20 | 48 | 40 | 254 | 1984 | 512 | 928 |
| NUS | 2400 | 6 | 12 | 64 | 44 | 73 | 128 | 155 | 500 |
| ORL | 400 | 4 | 40 | 512 | 89 | 864 | 254 | - | - |
| 3sources | 169 | 3 | 6 | 3560 | 3631 | 3068 | - | - | - |
| BBC | 685 | 4 | 5 | 4659 | 4633 | 4665 | 4684 | - | - |
| BBC_Sport | 544 | 2 | 5 | 3183 | 3203 | - | - | - | - |
| 100leaves | 1600 | 3 | 100 | 64 | 64 | 64 | - | - | - |
| Scene15 | 4485 | 3 | 15 | 20 | 59 | 40 | - | - | - |
| Caltech101-20 | ACC | ARI | NMI | Precision | F | Purity |
|---|---|---|---|---|---|---|
| SC1 | 26.55 ± 1.46 | 11.73 ± 1.03 | 26.99 ± 0.4 | 36.13 ± 1.79 | 19.47 ± 1.01 | 52.46 ± 0.92 |
| SC2 | 28.32 ± 1.38 | 16.27 ± 0.26 | 33.43 ± 0.32 | 46.73 ± 0.86 | 22.96 ± 0.32 | 59.62 ± 0.63 |
| SC3 | 28.32 ± 1.38 | 16.27 ± 0.26 | 33.43 ± 0.32 | 46.73 ± 0.86 | 22.96 ± 0.32 | 59.62 ± 0.63 |
| SC4 | 40.49 ± 1.13 | 30.05 ± 1.67 | 52.89 ± 0.99 | 71.02 ± 1.78 | 35.78 ± 1.67 | 75.43 ± 0.68 |
| SC5 | 39.28 ± 1.72 | 27.47 ± 1.85 | 48.82 ± 0.98 | 67.2 ± 2.4 | 33.31 ± 1.81 | 73.19 ± 1.15 |
| SC6 | 35.44 ± 2.75 | 24.18 ± 1.93 | 43.31 ± 1.37 | 60.39 ± 3.51 | 30.39 ± 1.8 | 68.64 ± 1.6 |
| Featconcat | 49.97 ± 0.13 | 14.52 ± 0.35 | 20.2 ± 0.29 | 23.09 ± 0.19 | 36.51 ± 0.21 | 52.77 ± 0.12 |
| AMGL | 52.73 ± 3.14 | 26.82 ± 2.82 | 52.19 ± 3.33 | 35.21 ± 3.1 | 40.67 ± 1.99 | 67.62 ± 1.88 |
| MVGL | 60.69 ± 0 | 28.92 ± 0 | 50.73 ± 0 | 33.54 ± 0 | 44.15 ± 0 | 71.29 ± 0 |
| ASMV | 41.17 ± 2.07 | 28.79 ± 2.06 | 54.23 ± 0.65 | 63.13 ± 2.75 | 35.25 ± 2 | 74.78 ± 0.7 |
| GBS | 64 ± 0 | 34.08 ± 0 | 53.73 ± 0 | 37.07 ± 0 | 47.95 ± 0 | 73.34 ± 0 |
| CoMSC | 53.98 ± 4.83 | 43.01 ± 6.31 | 59.47 ± 6.59 | 78.6 ± 4.91 | 78.21 ± 5.05 | 48.77 ± 2.32 |
| CDMGC | 55.7 ± 9.49 | 22.72 ± 10.33 | 44.68 ± 8.29 | 29.28 ± 6.34 | 40.43 ± 6.76 | 65.08 ± 8.99 |
| MVCS-CP | 60.6 ± 0.59 | 51.05 ± 2.2 | 61.36 ± 1.48 | 82.23 ± 1.56 | 56.56 ± 2.07 | 81.98 ± 1.01 |
| Caltech101-7 | ACC | ARI | NMI | Precision | F | Purity |
|---|---|---|---|---|---|---|
| SC1 | 28.83 ± 2.1 | 7.94 ± 0.92 | 11.51 ± 0.5 | 48.77 ± 0.97 | 29.14 ± 1.45 | 65.88 ± 1.66 |
| SC2 | 34.79 ± 2.24 | 19.67 ± 1.26 | 24.18 ± 0.59 | 66.23 ± 1.46 | 36.94 ± 1.13 | 73.09 ± 0.75 |
| SC3 | 55.6 ± 0.22 | 2.81 ± 0.26 | 3.15 ± 0.37 | 39.44 ± 0.09 | 55.91 ± 0.03 | 56.61 ± 0.29 |
| SC4 | 42.43 ± 2.57 | 29.55 ± 1.99 | 37.88 ± 1.62 | 78.48 ± 2.15 | 45.18 ± 1.9 | 81.25 ± 1.46 |
| SC5 | 40.72 ± 0.39 | 28.11 ± 1.48 | 35.36 ± 0.7 | 77.99 ± 1.45 | 43.59 ± 1.37 | 81.41 ± 0.54 |
| SC6 | 46.15 ± 3.24 | 30.32 ± 1.91 | 36.04 ± 1.17 | 78.42 ± 2.02 | 46.1 ± 1.64 | 80.62 ± 1.07 |
| Featconcat | 54.04 ± 0.04 | 1.22 ± 0.08 | 1.47 ± 0.03 | 38.93 ± 0.03 | 55.69 ± 0.06 | 54.52 ± 0.06 |
| AMGL | 64.46 ± 6.14 | 44.36 ± 5.82 | 54.6 ± 1.96 | 70.94 ± 6.65 | 63.71 ± 4.75 | 84.79 ± 0.77 |
| MVGL | 57.06 ± 0 | 45.96 ± 0 | 53.17 ± 0 | 87.25 ± 0 | 60.37 ± 0 | 87.04 ± 0 |
| ASMV | 40.77 ± 1.2 | 29.04 ± 1.22 | 41.55 ± 0.81 | 76.53 ± 0.75 | 45.2 ± 1.22 | 82.5 ± 0.53 |
| GBS | 69.2 ± 0 | 59.43 ± 0 | 60.56 ± 0 | 88.58 ± 0 | 72.17 ± 0 | 88.47 ± 0 |
| CoMSC | 63.28 ± 3.68 | 49.02 ± 3.96 | 53.62 ± 3.9 | 86.26 ± 4.95 | 63.49 ± 3.55 | 86.57 ± 1.32 |
| CDMGC | 51.74 ± 11.66 | 5.97 ± 23.25 | 23.71 ± 16 | 42.53 ± 12.76 | 50.26 ± 10.59 | 61.8 ± 12.3 |
| MVCS-CP | 69.95 ± 0.03 | 57.69 ± 0.07 | 56.13 ± 0.3 | 94.27 ± 1.29 | 69.99 ± 0.16 | 89.48 ± 0 |
| NUS | ACC | ARI | NMI | Precision | F | Purity |
|---|---|---|---|---|---|---|
| SC1 | 21.25 ± 0.42 | 4.32 ± 0.35 | 8.74 ± 0.19 | 12.03 ± 0.37 | 12.71 ± 0.22 | 22.99 ± 0.58 |
| SC2 | 20.76 ± 0.42 | 4.23 ± 0.18 | 8.75 ± 0.34 | 12.04 ± 0.2 | 12.42 ± 0.09 | 22.41 ± 0.34 |
| SC3 | 18.7 ± 0.22 | 3.4 ± 0.17 | 7.18 ± 0.23 | 11.33 ± 0.17 | 11.62 ± 0.15 | 19.94 ± 0.2 |
| SC4 | 23.43 ± 1.1 | 5.23 ± 0.36 | 10.02 ± 0.61 | 13.02 ± 0.31 | 13.21 ± 0.36 | 24.84 ± 0.84 |
| SC5 | 21.03 ± 0.45 | 4.73 ± 0.22 | 9.64 ± 0.72 | 12.44 ± 0.2 | 12.98 ± 0.22 | 22.41 ± 0.65 |
| SC6 | 11.43 ± 0.18 | 0.32 ± 0.01 | 4.61 ± 0.14 | 8.44 ± 0.01 | 15.31 ± 0.02 | 13.09 ± 0.2 |
| Featconcat | 10.79 ± 0.23 | 0.32 ± 0.02 | 4.5 ± 0.16 | 8.44 ± 0.01 | 15.4 ± 0.02 | 12.75 ± 0.12 |
| AMGL | 21.43 ± 0.96 | 4.15 ± 0.66 | 12.2 ± 0.96 | 10.68 ± 0.48 | 16.33 ± 0.2 | 23.37 ± 0.99 |
| MVGL | 13 ± 0 | 0.36 ± 0 | 5.57 ± 0 | 8.46 ± 0 | 15.44 ± 0 | 13.83 ± 0 |
| ASMV | 12.13 ± 1.2 | 0.71 ± 0.84 | 8.13 ± 2.21 | 9.14 ± 0.94 | 14.21 ± 0.15 | 22.46 ± 2.67 |
| GBS | 16.5 ± 0 | 1.24 ± 0 | 7.88 ± 0 | 8.88 ± 0 | 15.92 ± 0 | 17.88 ± 0 |
| CoMSC | 26.83 ± 2.65 | 8.32 ± 3.47 | 14.12 ± 3.47 | 15.84 ± 2.98 | 27.46 ± 2.76 | 16 ± 1.49 |
| CDMGC | 11.96 ± 1.43 | 0.27 ± 0.25 | 4.14 ± 1.57 | 8.42 ± 0.12 | 15.42 ± 0.17 | 12.68 ± 1.54 |
| MVCS-CP | 31.38 ± 0.83 | 10.49 ± 0.58 | 16.1 ± 0.29 | 17.52 ± 0.52 | 18.21 ± 0.52 | 32.42 ± 0.38 |
| ORL | ACC | ARI | NMI | Precision | F | Purity |
|---|---|---|---|---|---|---|
| SC1 | 75.7 ± 1.95 | 68.01 ± 1.65 | 89.92 ± 0.68 | 58.42 ± 1.75 | 68.86 ± 1.6 | 80.6 ± 1.31 |
| SC2 | 49.25 ± 2.02 | 35.32 ± 2.11 | 70.37 ± 1.16 | 34.84 ± 1.7 | 36.86 ± 2.07 | 53.3 ± 1.87 |
| SC3 | 65.45 ± 1.16 | 58.83 ± 2.31 | 85.05 ± 0.81 | 51.09 ± 2.7 | 59.92 ± 2.23 | 71.8 ± 0.87 |
| SC4 | 53.65 ± 2.06 | 37.44 ± 2.82 | 72.1 ± 1.5 | 36.77 ± 2.74 | 38.94 ± 2.76 | 57.15 ± 1.71 |
| Featconcat | 74.4 ± 0.72 | 68.87 ± 1.18 | 89.37 ± 0.41 | 60.55 ± 1.72 | 69.67 ± 1.14 | 79.5 ± 0.71 |
| AMGL | 72.91 ± 3.33 | 65.43 ± 6.51 | 89.69 ± 1.77 | 54.66 ± 7.71 | 66.39 ± 6.27 | 80.21 ± 2.54 |
| MVGL | 73.75 ± 0 | 52.74 ± 0 | 87.15 ± 0 | 40.38 ± 0 | 54.17 ± 0 | 80.25 ± 0 |
| ASMV | 67 ± 1.23 | 49.46 ± 0.67 | 81.08 ± 0.45 | 43.59 ± 1.37 | 50.79 ± 0.82 | 72.34 ± 0.71 |
| GBS | 83.75 ± 0 | 76.32 ± 0 | 92.6 ± 0 | 68.75 ± 0 | 76.92 ± 0 | 86.75 ± 0 |
| CoMSC | 86.5 ± 9.67 | 83.63 ± 13.03 | 94.42 ± 6.76 | 80.84 ± 11.97 | 84.01 ± 12.72 | 88.75 ± 9.78 |
| CDMGC | 71.35 ± 1.9 | 47.16 ± 3.27 | 86.7 ± 0.85 | 33.95 ± 3.15 | 48.88 ± 3.12 | 79.2 ± 0.96 |
| MVCS-CP | 89.5 ± 2.71 | 85.96 ± 0.46 | 94.87 ± 0.08 | 84.27 ± 0.82 | 86.28 ± 0.45 | 90.75 ± 1.41 |
| 3sources | ACC | ARI | NMI | Precision | F | Purity |
|---|---|---|---|---|---|---|
| SC1 | 30.3 ± 0.77 | −2.87 ± 0.42 | 6.34 ± 0.73 | 22.06 ± 0.19 | 34.37 ± 0.53 | 36.45 ± 0.9 |
| SC2 | 37.4 ± 0.77 | 4.58 ± 0.44 | 10.37 ± 1.6 | 25.19 ± 0.2 | 38.27 ± 0.2 | 39.76 ± 1.28 |
| SC3 | 31.95 ± 0 | −2 ± 0.19 | 7.07 ± 0.62 | 22.42 ± 0.08 | 35 ± 0.23 | 37.63 ± 0.79 |
| Featconcat | 31.01 ± 1.36 | −0.37 ± 1.36 | 5.45 ± 2.12 | 23.09 ± 0.77 | 27.54 ± 1.84 | 37.28 ± 1.82 |
| AMGL | 34.02 ± 2.69 | −1.66 ± 1.45 | 7.2 ± 2.95 | 22.58 ± 0.6 | 34.78 ± 0.56 | 39.25 ± 2.73 |
| MVGL | 30.77 ± 0 | −3.38 ± 0 | 6.6 ± 0 | 21.86 ± 0 | 34.17 ± 0 | 37.87 ± 0 |
| ASMV | 69.82 ± 4.7 | 60.01 ± 7.14 | 64.07 ± 4.56 | 65.99 ± 6.45 | 69.84 ± 5.23 | 77.51 ± 3.75 |
| GBS | 69.23 ± 0 | 44.31 ± 0 | 54.8 ± 0 | 48.44 ± 0 | 60.47 ± 0 | 74.56 ± 0 |
| CoMSC | 64.93 ± 4.39 | 53.44 ± 5.59 | 62.41 ± 3.63 | 68.11 ± 4.98 | 63.54 ± 4.4 | 78.27 ± 3.18 |
| CDMGC | 34.91 ± 0 | −1.26 ± 0.05 | 6.31 ± 0.26 | 22.73 ± 0.02 | 35.77 ± 0.08 | 39.35 ± 0.31 |
| MVCS-CP | 78.11 ± 0.74 | 65.86 ± 1.27 | 71.62 ± 1.41 | 80.31 ± 3.49 | 73.49 ± 0.69 | 85.21 ± 0.56 |
| BBC | ACC | ARI | NMI | Precision | F | Purity |
|---|---|---|---|---|---|---|
| SC1 | 33.11 ± 2.04 | −1.4 ± 0.71 | 7.73 ± 2.46 | 22.88 ± 0.29 | 35.09 ± 0.39 | 36.15 ± 3.35 |
| SC2 | 31.53 ± 0 | −0.66 ± 0 | 1.24 ± 0.13 | 23.2 ± 0 | 37.26 ± 0 | 33.02 ± 0.07 |
| SC3 | 30.92 ± 1.38 | −0.71 ± 0.37 | 2.1 ± 0.16 | 23.17 ± 0.15 | 36.84 ± 0.6 | 33.28 ± 0.21 |
| SC4 | 33.75 ± 0.28 | −0.29 ± 0.13 | 2.71 ± 0.32 | 23.34 ± 0.05 | 37.24 ± 0.13 | 35.07 ± 0.52 |
| Featconcat | 33.26 ± 0.12 | −0.23 ± 0.03 | 1.19 ± 0.07 | 23.37 ± 0.01 | 37.59 ± 0.03 | 34.01 ± 0.18 |
| AMGL | 35.66 ± 2.75 | 0.88 ± 1.22 | 2.23 ± 1.28 | 23.83 ± 0.51 | 37.22 ± 0.45 | 36.66 ± 2.93 |
| MVGL | 35.04 ± 0 | 0.24 ± 0 | 3.82 ± 0 | 23.55 ± 0 | 37.49 ± 0 | 36.35 ± 0 |
| ASMV | 63.94 ± 1.2 | 46.07 ± 3.02 | 46.82 ± 1.25 | 50.86 ± 0.86 | 0 ± 3.33 | 64.09 ± 1.21 |
| GBS | 69.34 ± 0 | 47.89 ± 0 | 48.52 ± 0 | 50.12 ± 0 | 63.33 ± 0 | 69.34 ± 0 |
| CoMSC | 70.18 ± 5.63 | 45.72 ± 8.07 | 51.49 ± 6.53 | 60.36 ± 6.92 | 57.99 ± 6.06 | 71.77 ± 3.89 |
| CDMGC | 31.53 ± 1.24 | −0.69 ± 0.09 | 1.08 ± 1.03 | 23.19 ± 0.03 | 36.93 ± 0.13 | 32.99 ± 1.16 |
| MVCS-CP | 74.89 ± 0.15 | 52.64 ± 0.19 | 51.76 ± 0.28 | 64.67 ± 0.11 | 63.56 ± 0.16 | 74.89 ± 0.15 |
| BBC_Sport | ACC | ARI | NMI | Precision | F | Purity |
|---|---|---|---|---|---|---|
| SC1 | 35.59 ± 0.1 | −0.07 ± 0.06 | 1.33 ± 0.05 | 23.83 ± 0.02 | 38.25 ± 0.04 | 36.54 ± 0.08 |
| SC2 | 36.76 ± 0 | 0.36 ± 0.02 | 1.78 ± 0.06 | 23.99 ± 0.01 | 38.41 ± 0 | 37.1 ± 0.08 |
| Featconcat | 0.12 ± 0.12 | 1.4 ± 0.22 | 38.27 ± 0.08 | 96.04 ± 0.38 | 36.84 ± 0.28 | 23.9 ± 0.05 |
| AMGL | 36.21 ± 0 | 0.15 ± 0 | 1.34 ± 0.3 | 23.91 ± 0 | 38.42 ± 0.04 | 36.58 ± 0 |
| MVGL | 39.15 ± 0 | 1.89 ± 0 | 6.98 ± 0 | 24.59 ± 0 | 39.07 ± 0 | 39.52 ± 0 |
| ASMV | 69.12 ± 6.7 | 40.78 ± 5.49 | 39.26 ± 5.09 | 48.07 ± 4.8 | 57.76 ± 3.04 | 69.3 ± 5.95 |
| GBS | 80.7 ± 0 | 72.18 ± 0 | 72.26 ± 0 | 72.71 ± 0 | 79.43 ± 0 | 84.38 ± 0 |
| CoMSC | 88.6 ± 0.81 | 72.37 ± 2.66 | 71.63 ± 1.84 | 80.28 ± 0.99 | 78.84 ± 2.15 | 88.6 ± 0.81 |
| CDMGC | 36.03 ± 0.19 | 0.06 ± 0.14 | 1.43 ± 0.06 | 23.88 ± 0.05 | 38.33 ± 0.09 | 36.76 ± 0.19 |
| MVCS-CP | 93.75 ± 0.41 | 84.18 ± 0.65 | 81.77 ± 0.44 | 88.2 ± 1.88 | 87.94 ± 0.78 | 93.75 ± 0.63 |
| 100leaves | ACC | ARI | NMI | Precision | F | Purity |
|---|---|---|---|---|---|---|
| SC1 | 41.78 ± 1.23 | 28.47 ± 1.17 | 67.71 ± 0.43 | 26.94 ± 1.16 | 29.2 ± 1.16 | 44.39 ± 1.29 |
| SC2 | 33.3 ± 1.04 | 20.85 ± 0.84 | 62.44 ± 0.76 | 18.51 ± 0.76 | 21.72 ± 0.83 | 36.28 ± 1 |
| SC3 | 45.96 ± 2.08 | 31.41 ± 1.85 | 70.13 ± 0.87 | 29.73 ± 1.91 | 32.1 ± 1.83 | 48.85 ± 1.86 |
| Featconcat | 62.91 ± 2.45 | 52.85 ± 2.42 | 82.01 ± 1.03 | 49.96 ± 2.59 | 53.32 ± 2.39 | 66.23 ± 2.15 |
| AMGL | 77.58 ± 2.5 | 47.47 ± 11.8 | 87.87 ± 2.17 | 34.87 ± 11.62 | 48.18 ± 11.58 | 81.25 ± 1.94 |
| MVGL | 81.06 ± 0 | 51.55 ± 0 | 89.12 ± 0 | 37.95 ± 0 | 52.17 ± 0 | 83.31 ± 0 |
| ASMV | 48.5 ± 0.41 | 23.8 ± 0.59 | 71.38 ± 0.51 | 16.36 ± 0.37 | 24.89 ± 0.19 | 54.06 ± 0.58 |
| GBS | 82.44 ± 0 | 57.11 ± 0 | 91.15 ± 0 | 42.67 ± 0 | 57.65 ± 0 | 85.13 ± 0 |
| CoMSC | 88.5 ± 6.83 | 86.56 ± 6.95 | 95.95 ± 4.84 | 82.92 ± 6.83 | 86.69 ± 6.2 | 90.88 ± 5.49 |
| CDMGC | 88.61 ± 1.34 | 76.15 ± 9.08 | 94.54 ± 1.1 | 66.56 ± 12.45 | 76.42 ± 8.95 | 89.93 ± 1.04 |
| MVCS-CP | 91.5 ± 0.74 | 86.82 ± 0.17 | 95.39 ± 0.13 | 84.1 ± 0.43 | 86.95 ± 0.16 | 92 ± 0.32 |
| Scene15 | ACC | ARI | NMI | Precision | F | Purity |
|---|---|---|---|---|---|---|
| SC1 | 34.69 ± 0.7 | 19.64 ± 0.26 | 36.53 ± 0.19 | 24.87 ± 0.38 | 25.29 ± 0.23 | 40.08 ± 0.56 |
| SC2 | 25.39 ± 0.43 | 10.05 ± 0.14 | 21.86 ± 0.29 | 14.06 ± 0.22 | 18.01 ± 0.1 | 27.87 ± 0.54 |
| SC3 | 22.7 ± 0.99 | 8.82 ± 0.6 | 19.89 ± 0.18 | 14.77 ± 0.56 | 15.38 ± 0.57 | 28.54 ± 0.34 |
| Featconcat | 14.46 ± 0.59 | 1.58 ± 0.33 | 10.49 ± 1.05 | 7.68 ± 0.17 | 13.78 ± 0.16 | 17.33 ± 0.66 |
| AMGL | 32.78 ± 2.41 | 15.1 ± 1.73 | 30.79 ± 1.84 | 16.66 ± 1.6 | 23.38 ± 1.16 | 34.06 ± 2.09 |
| MVGL | 23.21 ± 0 | 6.01 ± 0 | 20.44 ± 0 | 10 ± 0 | 17.16 ± 0 | 24.41 ± 0 |
| ASMV | 34.09 ± 0.41 | 17.52 ± 0.48 | 33.74 ± 0.51 | 22.38 ± 0.54 | 23.51 ± 0.41 | 38.86 ± 0.69 |
| GBS | 14 ± 0 | 0.42 ± 0 | 5.82 ± 0 | 7.11 ± 0 | 13.17 ± 0 | 14.65 ± 0 |
| CoMSC | 43.15 ± 2.69 | 25.86 ± 1.97 | 41.24 ± 1.39 | 30.72 ± 2.02 | 47.29 ± 2.53 | 31.04 ± 1.79 |
| CDMGC | 12.44 ± 0.73 | 0.19 ± 0.13 | 3.99 ± 0.84 | 7 ± 0.06 | 13.01 ± 0.09 | 12.97 ± 0.71 |
| MVCS-CP | 45.84 ± 2.12 | 26.71 ± 1.01 | 41.18 ± 0.39 | 30.85 ± 1.01 | 31.95 ± 0.92 | 47.42 ± 0.81 |
| Time(s) | AMGL | MVGL | ASMV | GBS | CoMSC | CDMGC | MVCS-CP |
|---|---|---|---|---|---|---|---|
| Caltech101-20 | 80.954 | 662.011 | 317.870 | 28.231 | 562.93 | 122.846 | 3.411 |
| Caltech101-7 | 21.3763 | 150.587 | 288.339 | 8.102 | 282.196 | 51.511 | 1.467 |
| NUS | 144.625 | 545.729 | 349.962 | 27.655 | 81.597 | 144.333 | 2.333 |
| ORL | 0.809 | 5.115 | 8.740 | 0.459 | 4.441 | 2.612 | 0.062 |
| 3sources | 1.436 | 0.528 | 3.918 | 0.193 | 0.683 | 0.354 | 0.028 |
| BBC | 4.837 | 8.776 | 22.629 | 29.819 | 9.583 | 5.269 | 6.742 |
| BBC_Sport | 2.387 | 4.753 | 8.214 | 6.199 | 1.628 | 3.054 | 1.552 |
| 100leaves | 47.818 | 90.341 | 449.571 | 5.849 | 175.703 | 40.080 | 1.204 |
| Scence15 | 616.978 | 3485.092 | 1100.982 | 97.190 | 432.381 | 641.264 | 8.988 |
| Datasets | d1 | d2 | d3 | d4 | d5 | d6 |
|---|---|---|---|---|---|---|
| Caltech101-20 | 18 | 18 | 21 | 33 | 25 | 33 |
| Caltech101-7 | 17 | 16 | 21 | 28 | 31 | 27 |
| NUS | 13 | 2 | 4 | 5 | 5 | 16 |
| ORL | 7 | 10 | 8 | 19 | - | - |
| 3sources | 8 | 8 | 8 | - | - | - |
| BBC | 16 | 13 | 9 | 15 | - | - |
| BBC_Sport | 14 | 16 | - | - | - | - |
| 100leaves | 17 | 26 | 14 | - | - | - |
| Scene15 | 24 | 18 | 31 | - | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Liu, X. Multiview Clustering of Adaptive Sparse Representation Based on Coupled P Systems. Entropy 2022, 24, 568. https://doi.org/10.3390/e24040568
Zhang X, Liu X. Multiview Clustering of Adaptive Sparse Representation Based on Coupled P Systems. Entropy. 2022; 24(4):568. https://doi.org/10.3390/e24040568
Chicago/Turabian StyleZhang, Xiaoling, and Xiyu Liu. 2022. "Multiview Clustering of Adaptive Sparse Representation Based on Coupled P Systems" Entropy 24, no. 4: 568. https://doi.org/10.3390/e24040568