
Automatic Search Dense Connection Module for Super-Resolution



Abstract
:1. Introduction
- We introduce a novel lightweight ASDCN model for single image super-resolution, selecting key connection paths effectively, and suppressing redundant information.
- We equip a softmax function to relax the dense connection paths into a continuous space and integrate the architecture search into the model for training. According to the weights of the paths, the appropriate connections are screened out. Selecting the essential features from intermediate layers enables the network to be more compact and efficient.
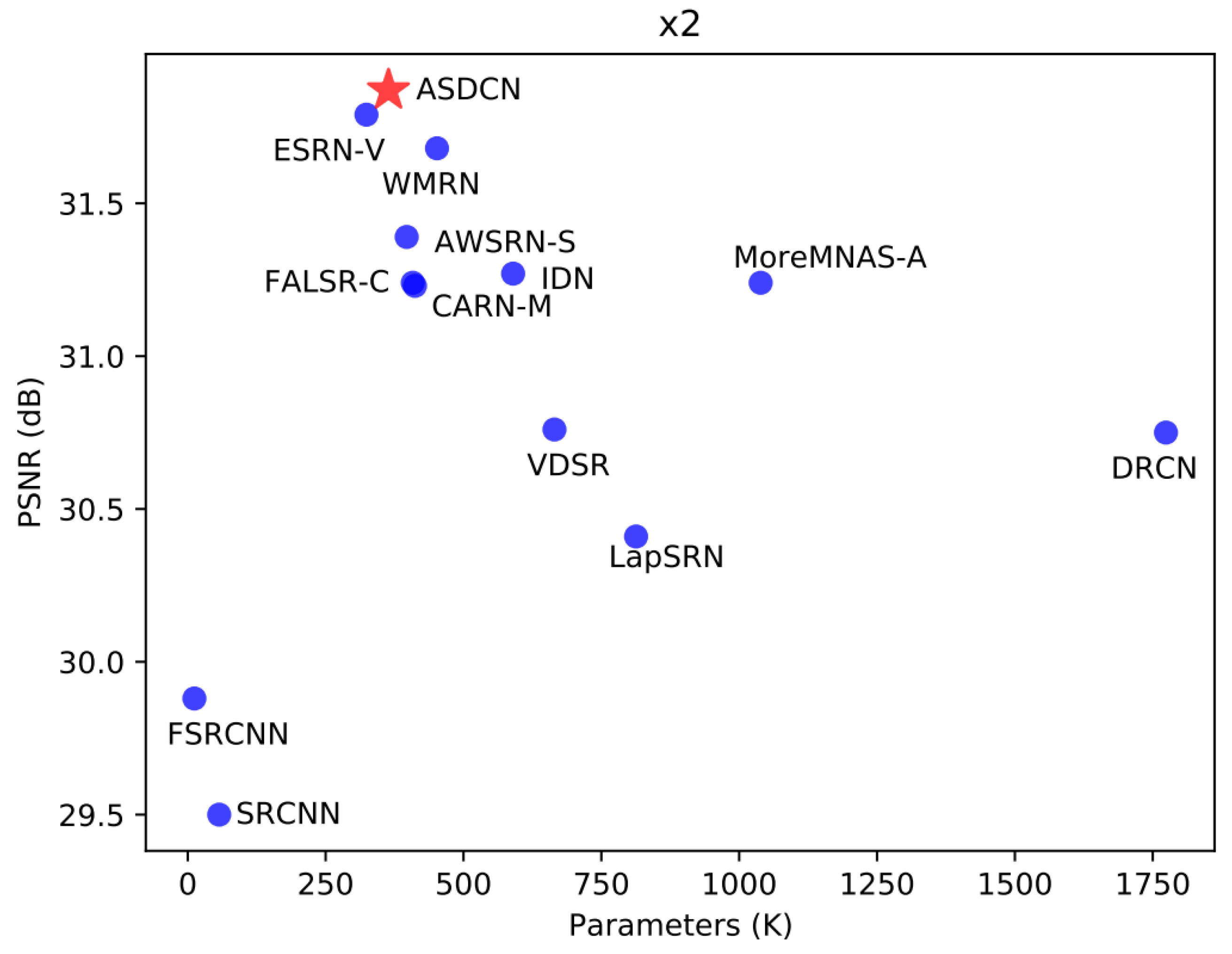
- Comprehensive experiments on five public benchmark datasets have demonstrated that our derived model achieves comparable performance to the most advanced methods. Our proposed method strikes a trade-off between reconstruction results and model sizes.
2. Related Work
2.1. Deep CNN-Based Super-Resolution
2.2. Neural Architecture Search
3. Proposed Method
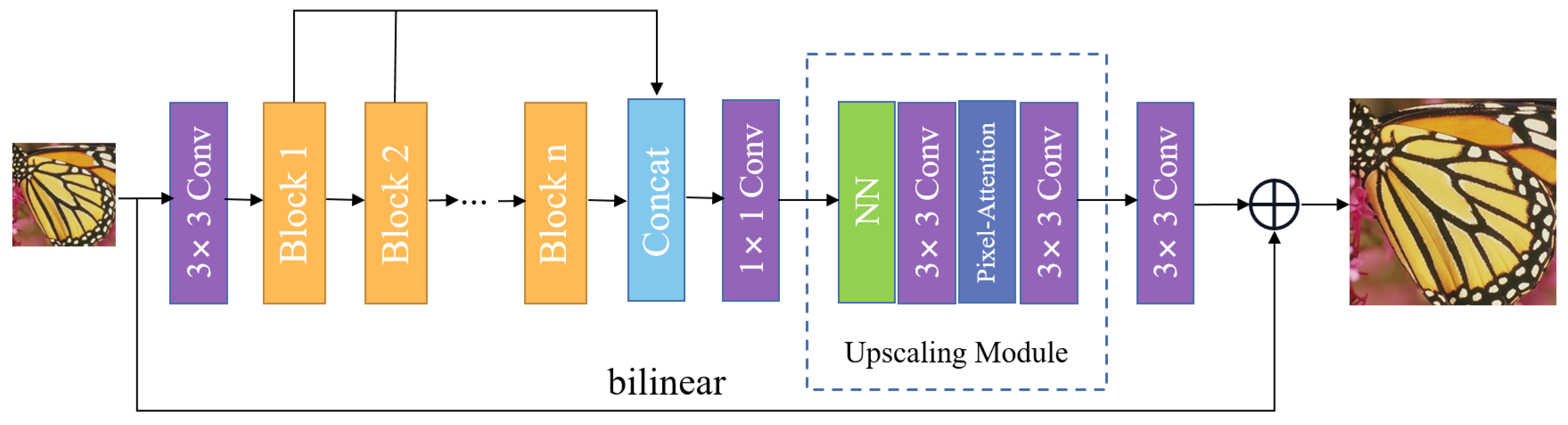
3.1. Network Architecture
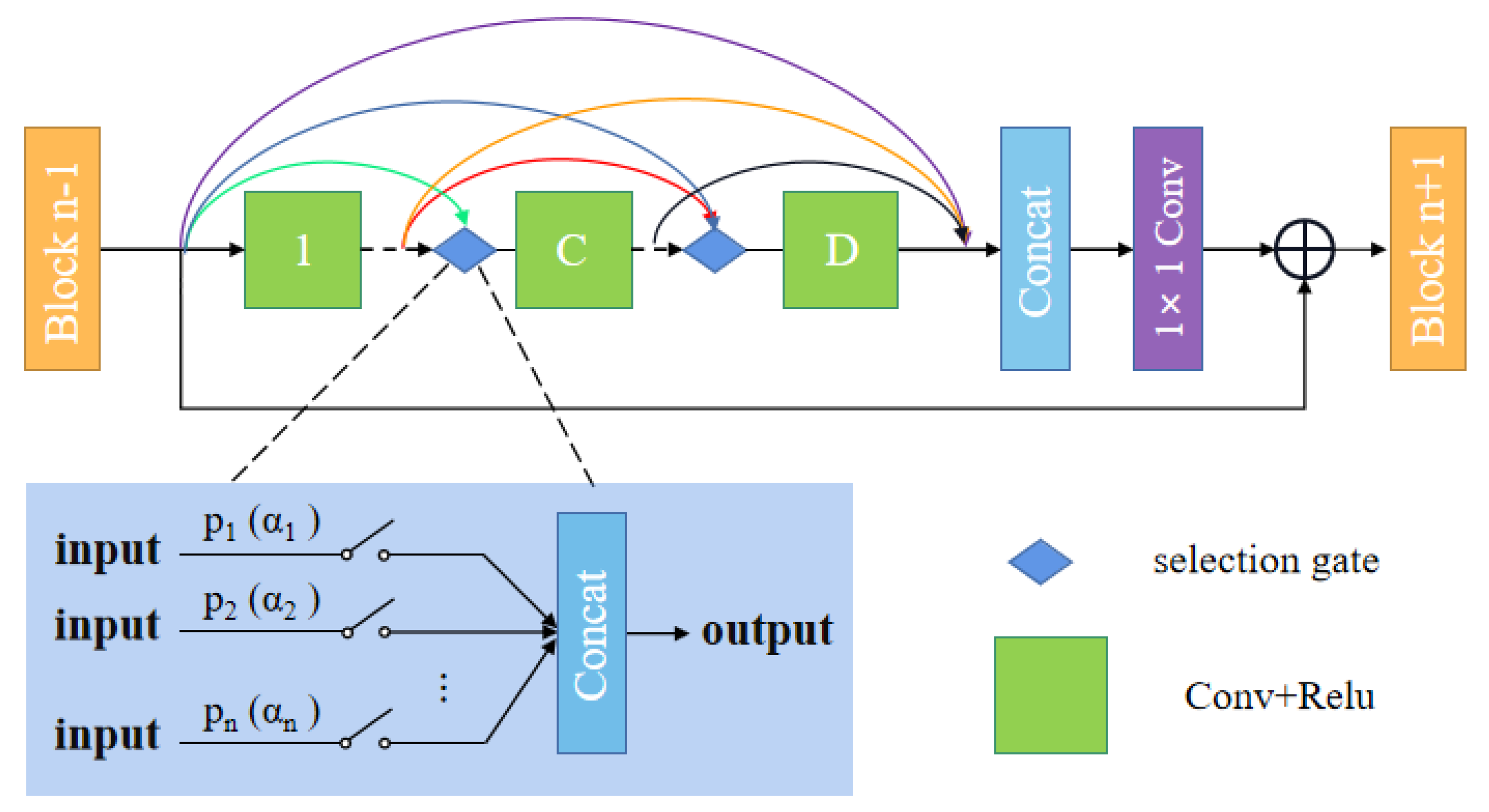
3.2. Automatic Search Dense Connection Module
3.3. Search Procedure
| Algorithm 1 Training process. |
|
4. Experiments
4.1. Datasets and Metrics
4.2. Implementation Details
4.3. Ablation Study
4.3.1. Comparison with RDN with the Same Setup
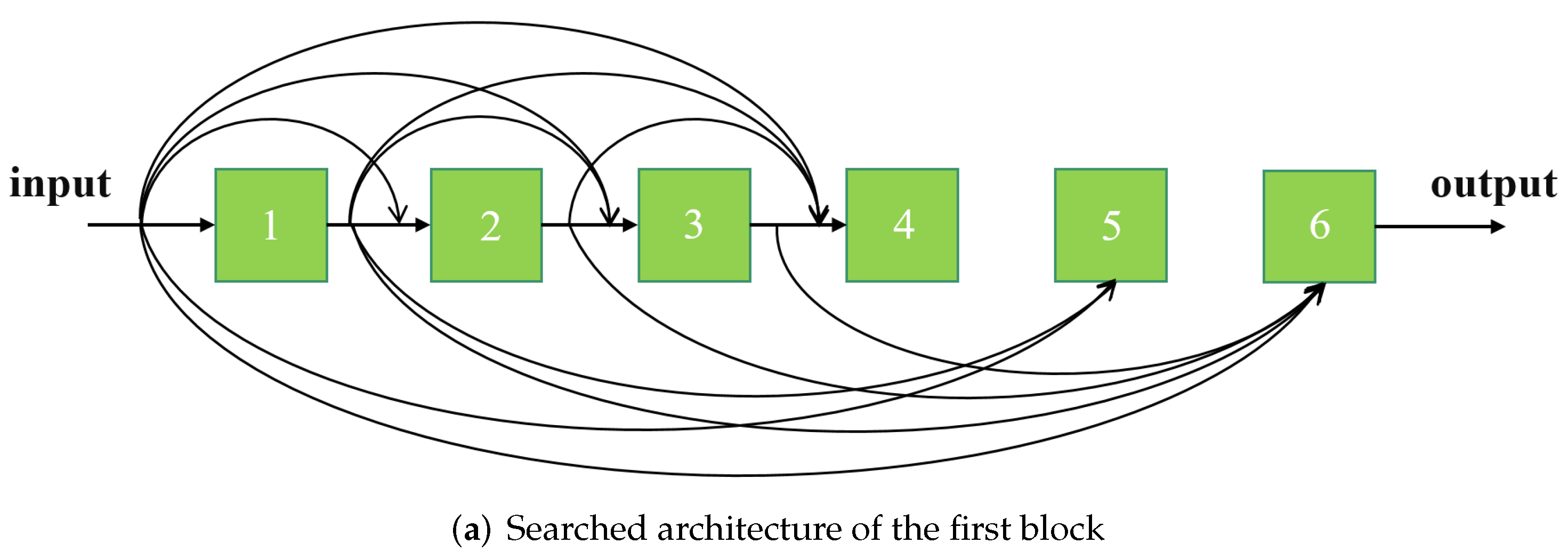
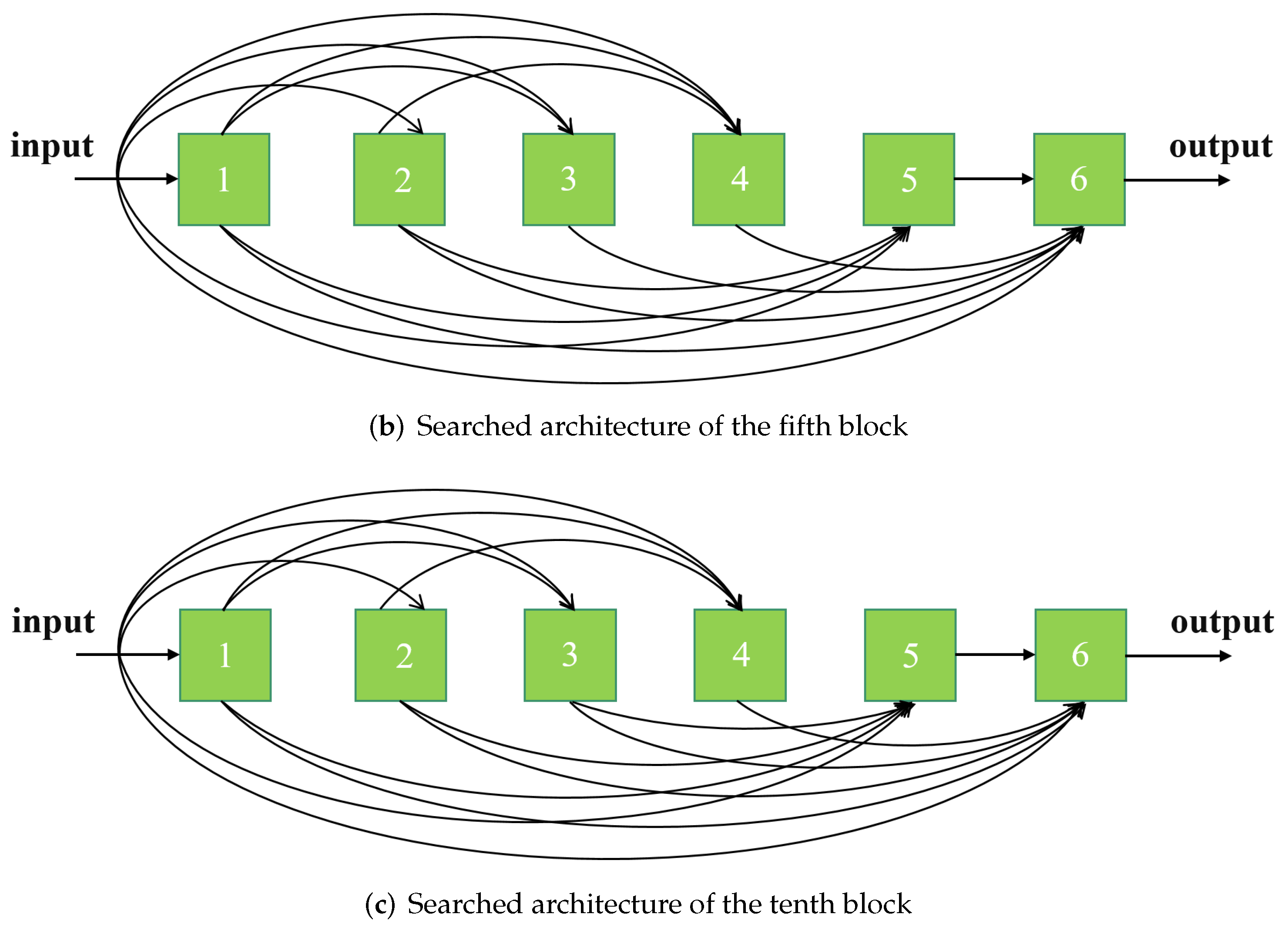
4.3.2. Searched Architectures
4.4. Comparison with State-of-the-Art Methods
4.5. Visualization on Real-World Images
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, T.; Dai, T.; Liu, L.; Zhu, Z.; Xia, S.-T. S2A:Scale Attention-Aware Networks for Video Super-Resolution. Entropy 2021, 23, 1398. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Liang, J.; Gool, L.V.; Timofte, R. Designing a practical degradation model for deep blind image super-resolution. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Online, 11–17 October 2021; pp. 4771–4780. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Sun, L.; Liu, Z.; Sun, X.; Liu, L.; Lan, R.; Luo, X. Lightweight Image Super-Resolution via Weighted Multi-Scale Residual Network. IEEE/CAA J. Autom. Sin. 2021, 8, 1271–1280. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the European Conference on Computer Vision–ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2790–2798. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1874–1883. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Li, Z.; Wang, C.; Wang, J.; Ying, S.; Shi, J. Lightweight adaptive weighted network for single image super-resolution. Comput. Vis. Image Underst. 2021, 211, 103254. [Google Scholar] [CrossRef]
- Lan, R.; Sun, L.; Liu, Z.; Lu, H.; Pang, C.; Luo, X. MADNet: A Fast and Lightweight Network for Single-Image Super Resolution. IEEE Trans. Cybern. 2021, 51, 1443–1453. [Google Scholar] [CrossRef] [PubMed]
- Tang, R.; Chen, L.; Zou, Y.; Lai, Z.; Albertini, M.K.; Yang, X. Lightweight network with one-shot aggregation for image super-resolution. J. Real-Time Image Process. 2021, 18, 1275–1284. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Huang, G.; Liu, S.; der Maaten, L.V.; Weinberger, K.Q. Condensenet: An efficient densenet using learned group convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing neural network architectures using reinforcement learning. arXiv 2016, arXiv:1611.02167. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2014, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Quan, R.; Yu, X.; Liang, Y.; Weinberger, Y. Removing raindrops and rain streaks in one go. In Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 9147–9156. [Google Scholar]
- Peng, H.; Chen, X.; Zhao, J. Densely connected convolutional networks. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 2012–2020. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1637–1645. [Google Scholar]
- Anwar, S.; Barnes, N. Densely Residual Laplacian Super-Resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1192–1204. [Google Scholar] [CrossRef] [PubMed]
- Hui, Z.; Wang, X.; Gao, X. Fast and accurate single image superresolution via information distillation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 723–731. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, C.; Li, Z.; Shi, J. Lightweight Image Super-Resolution with Adaptive Weighted Learning Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Tian, C.; Xu, Y.; Zuo, W.; Zhang, B.; Fei, L.; Lin, C.W. Coarse-to-fine cnn for image super-resolution. IEEE Trans. Multimed. 2020, 23, 1489–1502. [Google Scholar] [CrossRef]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized evolution for image classifier architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 4780–4789. [Google Scholar]
- Zhang, T.; Lei, C.; Zhang, Z.; Meng, X.-B.; Chen, C.L.P. AS-NAS: Adaptive Scalable Neural Architecture Search With Reinforced Evolutionary Algorithm for Deep Learning. IEEE Trans. Evol. Comput. 2021, 25, 830–841. [Google Scholar] [CrossRef]
- Pham, H.; Guan, M.Y.; Zoph, B.; Le, Q.V.; Dean, J. Efficient neural architecture search via parameter sharing. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Vienna, Austria, 25–31 July 2018. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. DARTS: Differentiable architecture search. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Chu, X.; Zhang, B.; Ma, H.; Xu, R.; Li, J.; Li, Q. Fast, accurate and lightweight super-resolution with neural architecture search. In Proceedings of the Conference: 2020 25th International Conference on Pattern Recognition (ICPR), Online, 10–15 January 2020. [Google Scholar]
- Chu, X.; Zhang, B.; Xu, R.; Ma, H. Multi-objective reinforced evolution in mobile neural architecture search. In Proceedings of the European Conference on Computer Vision (ECCV), Online, 23–28 August 2020. [Google Scholar]
- Song, D.; Xu, C.; Jia, X.; Chen, Y.; Xu, C.; Wang, Y. Efficient residual dense block search for image super-resolution. In Proceedings of the The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Peng, H.; Chen, X.; Zhao, J. Residual pixel attention network for spectral reconstruction from RGB images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the ICML Workshop on Deep Learning for Audio, Speech and Language Processing, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 June 2017. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; pp. 135.1–135.10. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Curves and Surfaces; Boissonnat, J.-D., Chenin, P., Cohen, A., Gout, C., Lyche, T., Mazure, M.-L., Schumaker, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 711–730. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the 8th International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Huang, J.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Singh, D.; Kaur, M.; Jabarulla, M.Y.; Kumar, V.; Lee, H.N. Evolving fusion-based visibility restoration model for hazy remote sensing images using dynamic differential evolution. IEEE Trans. Geosci. Remote Sens. 2022, 15, 5765. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Params | Multi-Adds | Set5 | Set10 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|---|
| (K) | (G) | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | |
| RDN | 520 | 119.9 | 37.90/0.9601 | 33.45/0.9165 | 32.12/0.8990 | 31.87/0.9259 | 38.28/0.9764 |
| ASDCN (ours) | 364 | 83.8 | 37.91/0.9603 | 33.48/0.9176 | 32.12/0.8990 | 31.87/0.9261 | 38.30/0.9765 |
| Method | Scale | Params | Multi-Adds | Set5 | Set10 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|---|---|
| (K) | (G) | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| SRCNN [5] | ×2 | 57 | 52.7 | 36.66/0.9542 | 32.42/0.9063 | 31.36/0.8879 | 29.50/0.8946 | 35.60/0.9663 |
| VDSR [6] | ×2 | 665 | 612.6 | 37.53/0.9587 | 33.03/0.9124 | 31.90/0.8960 | 30.76/0.9140 | 37.22/0.9729 |
| LapSRN [3] | ×2 | 813 | 29.9 | 37.52/0.9590 | 33.08/0.9130 | 31.80/0.8950 | 30.41/0.9100 | 37.27/0.9740 |
| IDN [23] | ×2 | 590 | 174.1 | 37.83/0.9600 | 33.30/0.9148 | 32.08/0.8950 | 31.27/0.9196 | - |
| CARN-M [24] | ×2 | 412 | 91.2 | 37.53/0.9583 | 33.26/0.9141 | 31.92/0.8960 | 31.23/0.9193 | - |
| MoreMNAS-A [33] | ×2 | 1039 | 238.6 | 37.63/0.9584 | 33.23/0.9138 | 31.95/0.8961 | 31.24/0.9187 | - |
| FALSR-C [32] | ×2 | 408 | 93.7 | 37.66/0.9586 | 33.26/0.9140 | 31.96/0.8965 | 31.24/0.9187 | - |
| AWSRN-S [25] | ×2 | 397 | 91.2 | 37.75/0.9596 | 33.31/0.9151 | 32.00/0.8974 | 31.39/0.9207 | 37.90/0.9755 |
| ESRN-V [34] | ×2 | 324 | 73.4 | 37.85/0.9600 | 33.42/0.9161 | 32.10/0.8987 | 31.79/0.9248 | - |
| MADNet-L1 [12] | ×2 | 878 | 187.1 | 37.85/0.9600 | 33.38/0.9161 | 32.04/0.8979 | 31.62/0.9233 | - |
| OAN-S [13] | ×2 | 450 | 104.9 | 37.85/0.9600 | 33.41/0.9162 | 32.06/0.8983 | 31.61/0.9230 | 38.16/0.9761 |
| WMRN [4] | ×2 | 452 | 103 | 37.83/0.9599 | 33.41/0.9162 | 32.08/0.8984 | 31.68/0.9241 | 38.27/0.9763 |
| ASDCN(ours) | ×2 | 364 | 83.8 | 37.91/0.9603 | 33.48/0.9176 | 32.12/0.8990 | 31.87/0.9261 | 38.30/0.9765 |
| SRCNN [5] | ×3 | 57 | 52.7 | 32.75/0.9090 | 29.28/0.8209 | 28.41/0.7863 | 26.24/0.7989 | 30.59/0.9107 |
| VDSR [6] | ×3 | 665 | 612.6 | 33.66/0.9213 | 29.77/0.8314 | 28.82/0.7976 | 27.14/0.8279 | 32.01/0.9310 |
| CARN-M [24] | ×3 | 412 | 46.1 | 33.99/0.9236 | 30.08/0.8367 | 28.91/0.8000 | 26.86/0.8263 | - |
| IDN [23] | ×2 | 590 | 105.6 | 34.11/0.9253 | 29.99/0.8354 | 28.95/0.8013 | 27.42/0.8359 | - |
| AWSRN-S [25] | ×3 | 447 | 48.6 | 34.02/0.9240 | 30.09/0.8376 | 28.92/0.8009 | 27.57/0.8391 | 32.82/0.9393 |
| ESRN-V [34] | ×3 | 324 | 36.2 | 34.23/0.9262 | 30.27/0.8400 | 29.03/0.8039 | 27.95/0.8481 | - |
| MADNet-L1 [12] | ×3 | 930 | 88.4 | 34.16/0.9253 | 30.21/0.8398 | 28.98/0.8023 | 27.77/0.8439 | - |
| OAN-S [13] | ×3 | 490 | 51.2 | 34.17/0.9255 | 30.20/0.8395 | 28.99/0.8023 | 27.80/0.8438 | 33.06/0.9144 |
| WMRN [4] | ×3 | 556 | 57 | 34.11/0.9251 | 30.17/0.8390 | 28.98/0.8021 | 27.80/0.8448 | 33.07/0.9413 |
| ASDCN(ours) | ×3 | 364 | 37.28 | 34.27/0.9266 | 30.27/0.8413 | 29.06/0.8041 | 28.03/0.8499 | 33.28/0.9430 |
| SRCNN [5] | ×4 | 57 | 52.7 | 30.48/0.8628 | 27.49/0.7503 | 26.90/0.7101 | 24.52/0.7221 | 27.66/0.8505 |
| VDSR [6] | ×4 | 665 | 612.6 | 31.35/0.8838 | 28.01/0.7674 | 27.29/0.7251 | 25.18/0.7524 | 28.83/0.8809 |
| LapSRN [3] | ×4 | 813 | 149.4 | 31.54/0.8850 | 28.19/0.7720 | 27.32/0.7280 | 25.21/0.7560 | 29.09/0.8845 |
| IDN [23] | ×4 | 590 | 81.8 | 31.82/0.8903 | 28.25/0.7730 | 27.41/0.7297 | 25.41/0.7632 | - |
| CARN-M [24] | ×4 | 412 | 32.5 | 31.92/0.8903 | 28.42/0.7762 | 27.44/0.7304 | 25.63/0.7688 | - |
| AWSRN-S [25] | ×4 | 588 | 33.7 | 31.77/0.8893 | 28.35/0.7761 | 27.41/0.7304 | 25.56/0.7678 | 29.74/0.8982 |
| ESRN-V [34] | ×4 | 324 | 20.7 | 31.99/0.8919 | 28.49/0.7779 | 27.50/0.7331 | 25.87/0.7782 | - |
| MADNet-L1 [12] | ×4 | 1002 | 54.1 | 31.95/0.8917 | 28.44/0.7780 | 27.47/0.7327 | 25.76/0.7746 | - |
| OAN-S [13] | ×4 | 520 | 42.5 | 31.99/0.8926 | 28.49/0.7975 | 27.49/0.7332 | 25.81/0.7760 | 30.10/0.9036 |
| WMRN [4] | ×4 | 536 | 45.7 | 32.00/0.8952 | 28.47/0.7786 | 27.49/0.7328 | 25.89/0.7789 | 30.11/0.9040 |
| ASDCN(ours) | ×4 | 375 | 21.59 | 32.06/0.8937 | 28.53/0.7806 | 27.54/0.7351 | 25.98/0.7831 | 30.23/0.9063 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zang, H.; Cheng, G.; Duan, Z.; Zhao, Y.; Zhan, S. Automatic Search Dense Connection Module for Super-Resolution. Entropy 2022, 24, 489. https://doi.org/10.3390/e24040489
Zang H, Cheng G, Duan Z, Zhao Y, Zhan S. Automatic Search Dense Connection Module for Super-Resolution. Entropy. 2022; 24(4):489. https://doi.org/10.3390/e24040489
Chicago/Turabian StyleZang, Huaijuan, Guoan Cheng, Zhipeng Duan, Ying Zhao, and Shu Zhan. 2022. "Automatic Search Dense Connection Module for Super-Resolution" Entropy 24, no. 4: 489. https://doi.org/10.3390/e24040489