
Learning Visible Thermal Person Re-Identification via Spatial Dependence and Dual-Constraint Loss

Abstract
:1. Introduction
- (1)
- We introduce a dual-path attention mechanism network model to focus on the spatial correlation between any two local features.
- (2)
- We propose a cross-modal dual-constraint loss function to constrain the center of classes and the boundary, making the intra-class compact and the inter-class separable
- (3)
- Our approach achieves good performance on RegDB and SYSU-MM01 datasets and performs favorably against existing methods
2. Related Work
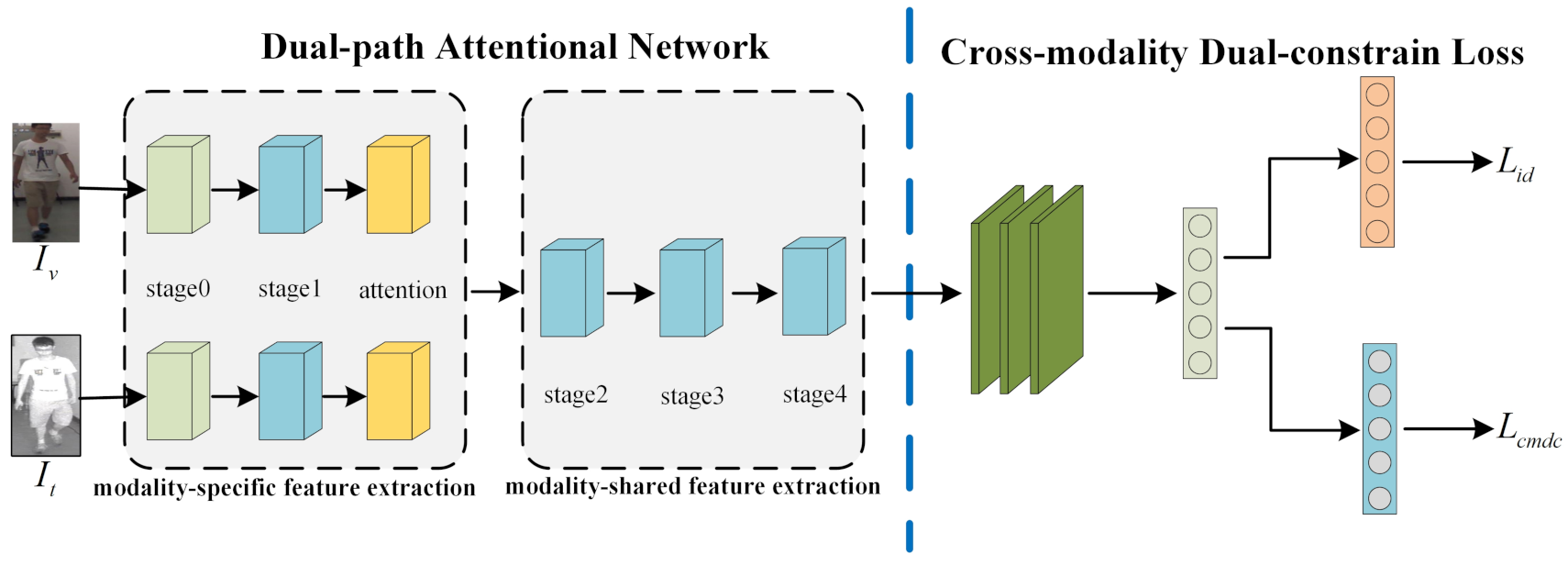
3. Our Approach
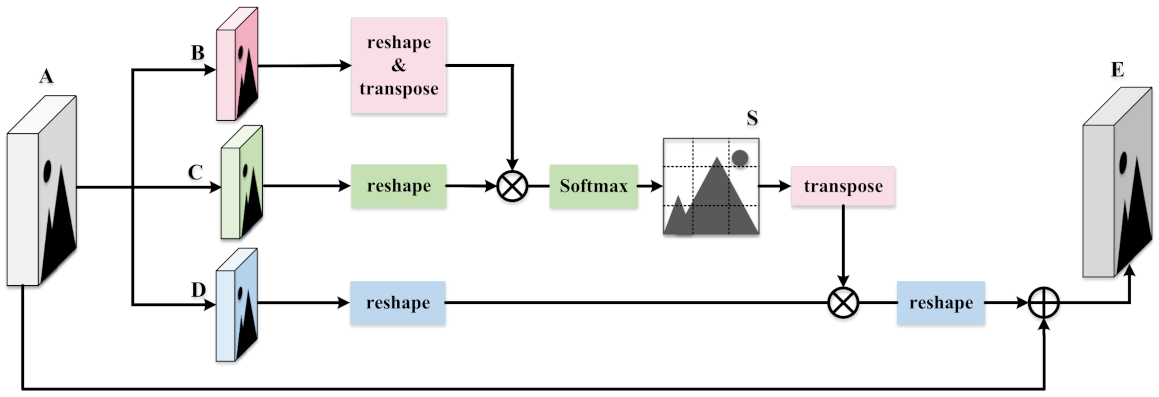
3.1. Dual-Path Attention Network
- (1)
- Modality-specific feature extraction consists of two branches that do not share the parameters. If each branch contains an entire CNN architecture, the number of network parameters will increase exponentially.
- (2)
- The internal connection between local features is neglected in the modality-specific feature extraction process.
3.2. Cross-Modality Dual-Constraint Loss
4. Experiment
4.1. Experimental Settings
4.1.1. Datasets and Settings
4.1.2. Evaluation Metrics
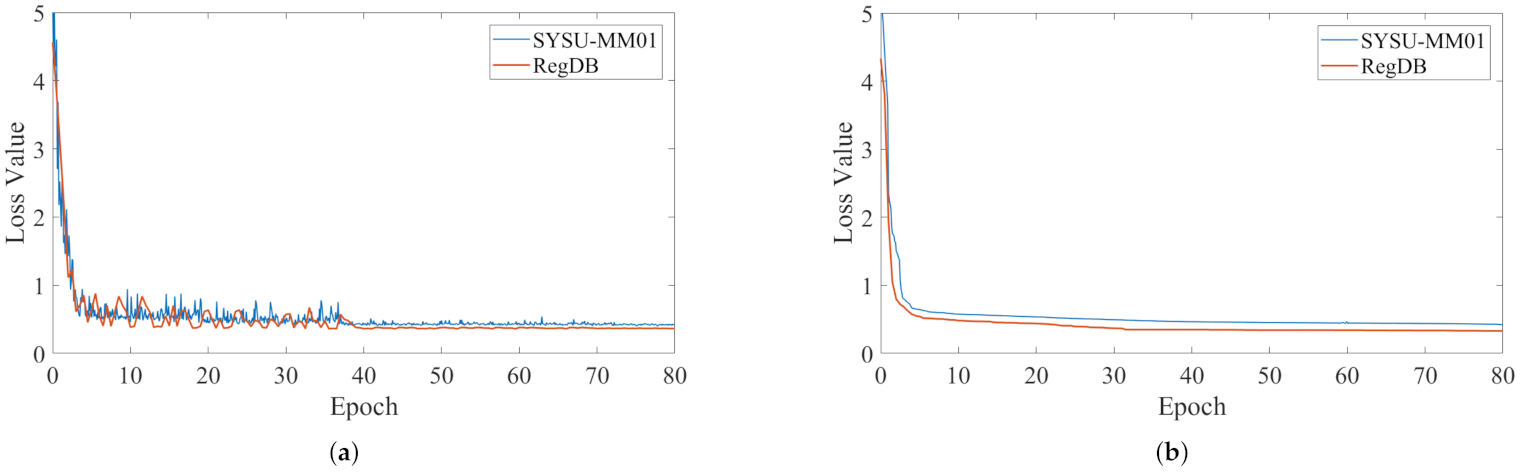
4.1.3. Implementation Details
4.2. Comparison with the State-of-the-Art
4.3. Ablation Experiments
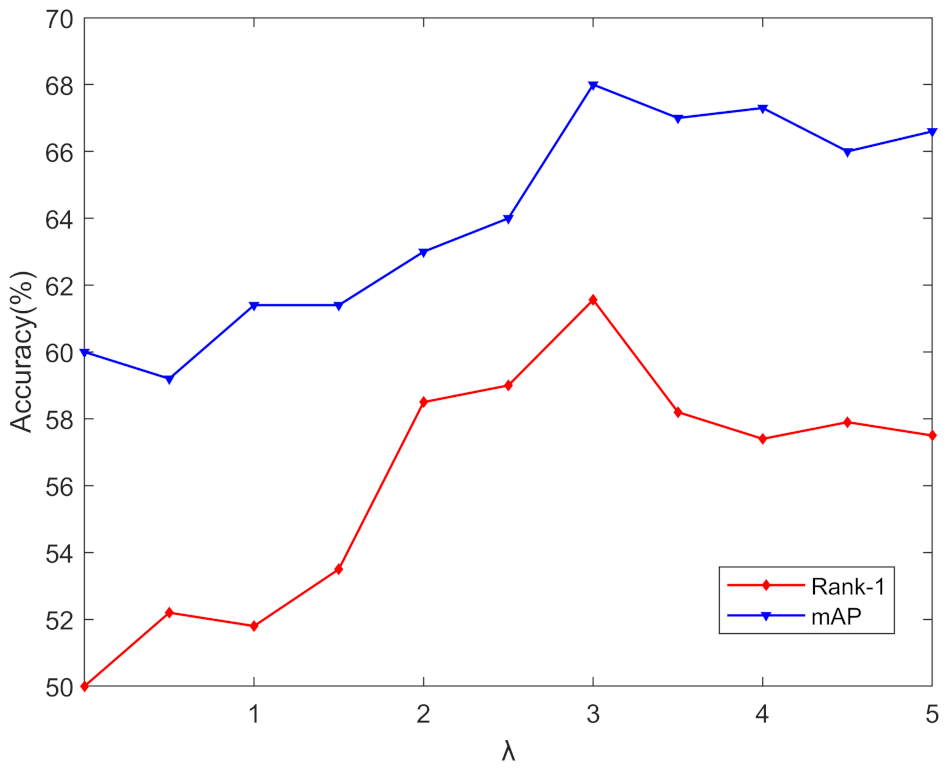
4.4. Parameter Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, L.; Bie, Z.; Sun, Y.; Wang, J.; Su, C.; Wang, S.; Tian, Q. Mars: A video benchmark for large-scale person re-identification. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 868–884. [Google Scholar]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person re-identification: Past, present and future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Deep metric learning for person re-identification. In Proceedings of the International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 34–39. [Google Scholar]
- Wu, L.; Shen, C.; Hengel, A.v.d. Personnet: Person re-identification with deep convolutional neural networks. arXiv 2016, arXiv:1601.07255. [Google Scholar]
- Chang, X.; Hospedales, T.M.; Xiang, T. Multi-level factorisation net for person re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2109–2118. [Google Scholar]
- Zhu, Y.; Yang, Z.; Wang, L.; Zhao, S.; Hu, X.; Tao, D. Hetero-center loss for cross-modality person re-identification. Neurocomputing 2020, 386, 97–109. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Chai, Y.; Tan, X.; Li, D.; Zhou, X. Strong but simple baseline with dual-granularity triplet loss for visible-thermal person re-identification. IEEE Signal Process. Lett. 2021, 28, 653–657. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Z.; Zheng, Y.; Chuang, Y.-Y.; Satoh, S. Learning to reduce dual-level discrepancy for infrared-visible person re-identification. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 618–626. [Google Scholar]
- Lu, Y.; Wu, Y.; Liu, B.; Zhang, T.; Li, B.; Chu, Q.; Yu, N. Cross-modality person re-identification with shared-specific feature transfer. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13379–13389. [Google Scholar]
- Liu, H.; Tan, X.; Zhou, X. Parameter sharing exploration and hetero-center triplet loss for visible-thermal person re-identification. IEEE Trans. Multimed. 2020, 23, 4414–4425. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 23–30 June 2016; pp. 770–778. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters–improve semantic segmentation by global convolutional network. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Stollenga, M.; Masci, J.; Gomez, F.; Schmidhuber, J. Deep networks with internal selective attention through feedback connections. arXiv 2014, arXiv:1407.3068. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 2017–2025. [Google Scholar]
- Weinberger, K.Q.; Saul, L.K. Distance metric learning for large margin nearest neighbor classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Zheng, W.-S.; Gong, S.; Xiang, T. Person re-identification by probabilistic relative distance comparison. In Proceedings of the Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 649–656. [Google Scholar]
- Wu, A.; Zheng, W.-S.; Yu, H.-X.; Gong, S.; Lai, J. Rgb-infrared cross-modality person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5380–5389. [Google Scholar]
- Hao, Y.; Wang, N.; Li, J.; Gao, X. Hsme: Hypersphere manifold embedding for visible thermal person re-identification. Assoc. Adv. Artif. Intell. 2019, 33, 8385–8392. [Google Scholar] [CrossRef]
- Dai, P.; Ji, R.; Wang, H.; Wu, Q.; Huang, Y. Cross-modality person re-identification with generative adversarial training. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; Volume 1, p. 6. [Google Scholar]
- Liu, H.; Cheng, J.; Wang, W.; Su, Y.; Bai, H. Enhancing the discriminative feature learning for visible-thermal cross-modality person re-identification. Neurocomputing 2020, 398, 11–19. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Yang, Y.; Wang, P.; Liang, G.; Zhang, X.; Zhang, Y. Attend to the difference: Cross-modality person re-identification via contrastive correlation. IEEE Trans. Image Process. 2021, 30, 8861–8872. [Google Scholar] [CrossRef]
- Basaran, E.; Gökmen, M.; Kamasak, M.E. An efficient framework for visible–infrared cross modality person re-identification. Signal Process. Image Commun. 2020, 87, 115933. [Google Scholar] [CrossRef]
- Wang, G.-A.; Zhang, T.; Yang, Y.; Cheng, J.; Chang, J.; Liang, X.; Hou, Z.-G. Cross-modality paired-images generation for rgb-infrared person re-identification. Assoc. Adv. Artif. Intell. 2020, 34, 12144–12151. [Google Scholar] [CrossRef]
- Elsayed, G.F.; Kornblith, S.; Le, Q.V. Saccader: Improving accuracy of hard attention models for vision. arXiv 2019, arXiv:1908.07644. [Google Scholar]
- Ye, M.; Wang, Z.; Lan, X.; Yuen, P.C. Visible thermal person re-identification via dual-constrainted top-ranking. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; Volume 1, p. 2. [Google Scholar]
- Zang, X.; Li, G.; Gao, W.; Shu, X. Learning to disentangle scenes for person re-identification. Image Vis. Comput. 2021, 116, 104330. [Google Scholar] [CrossRef]
- Zhao, Y.-B.; Lin, J.-W.; Xuan, Q.; Xi, X. Hpiln: A feature learning framework for cross-modality person re-identification. Inst. Eng. Technol. 2019, 13, 2897–2904. [Google Scholar] [CrossRef]
- Ye, M.; Lan, X.; Leng, Q. Modality-aware collaborative learning for visible thermal person re-identification. In Proceedings of the Association for Computing Machinery, Nice, France, 21–25 October 2019; pp. 347–355. [Google Scholar]
- Ye, M.; Lan, X.; Li, J.; Yuen, P. Hierarchical discriminative learning for visible thermal person re-identification. Assoc. Adv. Artif. Intell. 2018, 32, 7501–7508. [Google Scholar]
- Nguyen, D.T.; Hong, H.G.; Kim, K.W.; Park, K.R. Person recognition system based on a combination of body images from visible light and thermal cameras. Sensors 2017, 17, 605. [Google Scholar] [CrossRef]
- Wang, G.; Zhang, T.; Cheng, J.; Liu, S.; Yang, Y.; Hou, Z. Rgb-infrared cross-modality person re-identification via joint pixel and feature alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3623–3632. [Google Scholar]
- Wu, A.; Zheng, W.-S.; Gong, S.; Lai, J. Rgb-ir person re-identification by cross-modality similarity preservation. Int. J. Comput. Vis. 2020, 128, 1765–1785. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Hao, Y.; Wang, N.; Gao, X.; Li, J.; Wang, X. Dual-alignment feature embedding for cross-modality person re-identification. In Proceedings of the Association for Computing Machinery, Nice, France, 21–25 October 2019; pp. 57–65. [Google Scholar]
- Li, D.; Wei, X.; Hong, X.; Gong, Y. Infrared-visible cross-modal person re-identification with an x modality. Assoc. Adv. Artif. Intell. 2020, 34, 4610–4617. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Crandall, D.J.; Shao, L.; Luo, J. Dynamic dual-attentive aggregation learning for visible-infrared person re-identification. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 229–247. [Google Scholar]
- Ye, M.; Shen, J.; Shao, L. Visible-infrared person re-identification via homogeneous augmented tri-modal learning. IEEE Trans. Inf. Forensics Secur. 2020, 16, 728–739. [Google Scholar] [CrossRef]
- Chen, Y.; Wan, L.; Li, Z.; Jing, Q.; Sun, Z. Neural feature search for rgb-infrared person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 587–597. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Source | All Research | Indoor Research | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Rank-1 | Rank-10 | Rank-20 | mAP | Rank-1 | Rank-10 | Rank-20 | mAP | ||
| HCML | AAAI18 | 14.32 | 53.16 | 69.17 | 16.16 | 24.52 | 73.25 | 86.73 | 30.08 |
| BDTR | IJCAI18 | 17.00 | 55.40 | 69.20 | 16.20 | - | - | - | - |
| DRL | CVPR19 | 28.90 | 70.60 | 82.40 | 29.20 | 31.60 | 77.20 | 89.20 | 44.20 |
| MAC | MM19 | 33.26 | 79.04 | 90.09 | 36.22 | 36.43 | 63.36 | 71.63 | 37.03 |
| AlignGAN | ICCV19 | 42.40 | 85.00 | 93.70 | 40.70 | 45.90 | 87.60 | 94.40 | 54.30 |
| CMSP | IJCV20 | 43.56 | 86.25 | - | 44.98 | 48.62 | 89.50 | - | 57.50 |
| AGW | Arxiv20 | 47.50 | - | - | 47.65 | 54.17 | - | - | 62.97 |
| DFE | MM19 | 48.71 | 88.86 | 95.27 | 48.59 | 52.25 | 89.86 | 95.85 | 59.68 |
| XIV | AAAI20 | 49.92 | 89.79 | 95.96 | 50.73 | - | - | - | - |
| DDAG | ECCV20 | 54.75 | 90.39 | 95.81 | 53.02 | 61.02 | 94.06 | 98.41 | 67.98 |
| HAT | TIFS20 | 55.29 | 92.14 | 97.36 | 53.89 | 62.10 | 95.75 | 99.20 | 69.37 |
| NFS | CVPR21 | 56.91 | 91.34 | 96.52 | 55.45 | 62.79 | 96.53 | 99.07 | 69.69 |
| Our | 57.74 | 90.53 | 96.27 | 54.35 | 61.56 | 94.86 | 98.34 | 68.13 | |
| Method | Source | Rank-1 | Rank-10 | Rank-20 | mAP |
|---|---|---|---|---|---|
| HCML | AAAI18 | 24.44 | 47.53 | 56.78 | 20.80 |
| BDTR | IJCAI18 | 33.56 | 58.61 | 67.43 | 32.76 |
| DRL | CVPR19 | 43.40 | 66.10 | 76.30 | 44.10 |
| MAC | MM19 | 36.43 | 62.36 | 71.63 | 44.10 |
| AlignGAN | ICCV19 | 57.90 | - | - | 53.60 |
| XIV | AAAI20 | 62.21 | 83.13 | 91.72 | 60.18 |
| CMSP | IJCV20 | 65.07 | 83.71 | - | 64.50 |
| DDAG | ECCV20 | 69.34 | 86.19 | 91.49 | 63.46 |
| AGW | Arxiv20 | 70.05 | - | - | 66.37 |
| DFE | MM19 | 70.13 | 86.32 | 91.96 | 67.56 |
| HAT | TIFS20 | 71.83 | 87.16 | 92.16 | 67.56 |
| Our | 76.07 | 90.44 | 93.98 | 69.43 |
| Setting | Rank-1 | Rank-10 | mAP |
|---|---|---|---|
| Baseline | 51.35 | 85.80 | 49.48 |
| Baseline + DPAN | 55.10 | 87.89 | 51.73 |
| Baseline + CMDC | 54.69 | 87.19 | 51.12 |
| Baseline + DCAN + CMDC | 57.74 | 90.53 | 54.35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Zhang, C.; Feng, Y.; Ji, Y.; Ding, J. Learning Visible Thermal Person Re-Identification via Spatial Dependence and Dual-Constraint Loss. Entropy 2022, 24, 443. https://doi.org/10.3390/e24040443
Wang C, Zhang C, Feng Y, Ji Y, Ding J. Learning Visible Thermal Person Re-Identification via Spatial Dependence and Dual-Constraint Loss. Entropy. 2022; 24(4):443. https://doi.org/10.3390/e24040443
Chicago/Turabian StyleWang, Chuandong, Chi Zhang, Yujian Feng, Yimu Ji, and Jianyu Ding. 2022. "Learning Visible Thermal Person Re-Identification via Spatial Dependence and Dual-Constraint Loss" Entropy 24, no. 4: 443. https://doi.org/10.3390/e24040443