
Deep Learning-Based Joint CSI Feedback and Hybrid Precoding in FDD mmWave Massive MIMO Systems


Abstract
:1. Introduction
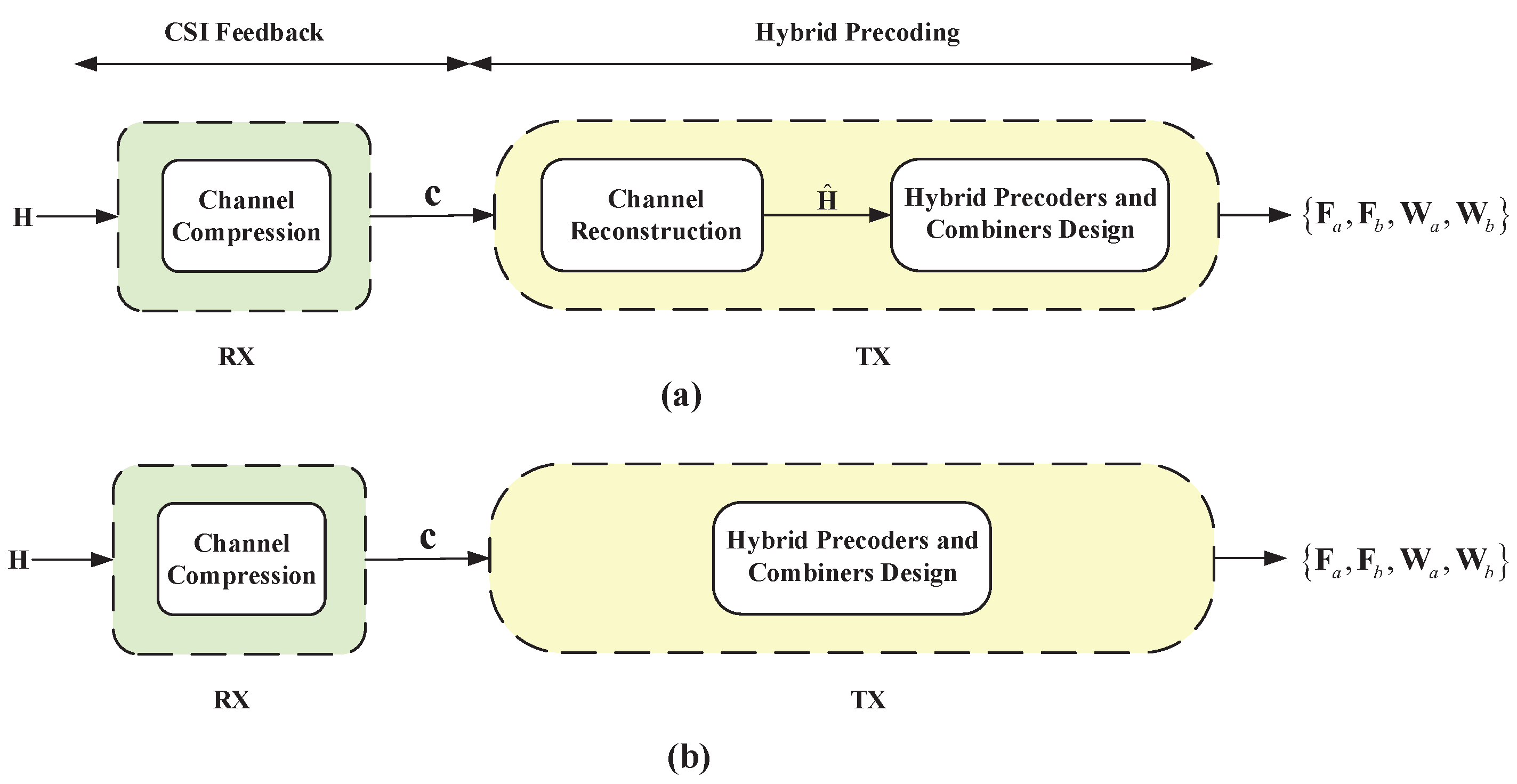
- A new deep learning-based end-to-end method of joint CSI feedback and hybrid precoding for FDD massive MIMO systems is proposed. Differing from the existing works that jointly optimize CSI feedback and hybrid precoding by using traditional algorithms, we adopt end-to-end deep learning techniques to solve the problem. Meanwhile, our proposed method bypasses channel reconstruction and directly designs the hybrid precoders and combiners from the feedback codewords for FDD massive MIMO systems, which is different from prior works that treat the CSI reconstruction and hybrid precoding as separate components and has been less investigated in the latest end-to-end works;
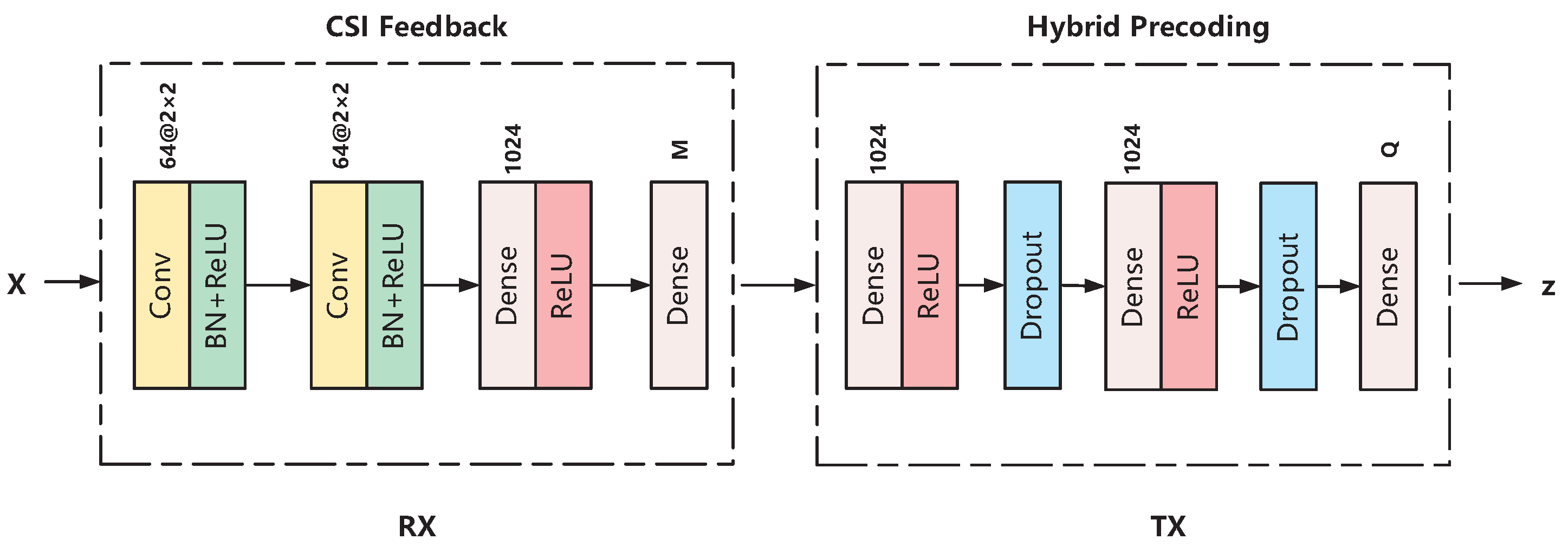
- A new end-to-end neural network structure for FDD mmWave massive MIMO systems is proposed in this paper. It consists of two parts: CSI feedback and hybrid precoding. The former, realized by CNN, transforms the channel matrices into feedback codewords and the latter, realized by DNN, transforms feedback codewords into hybrid precoders and combiners;
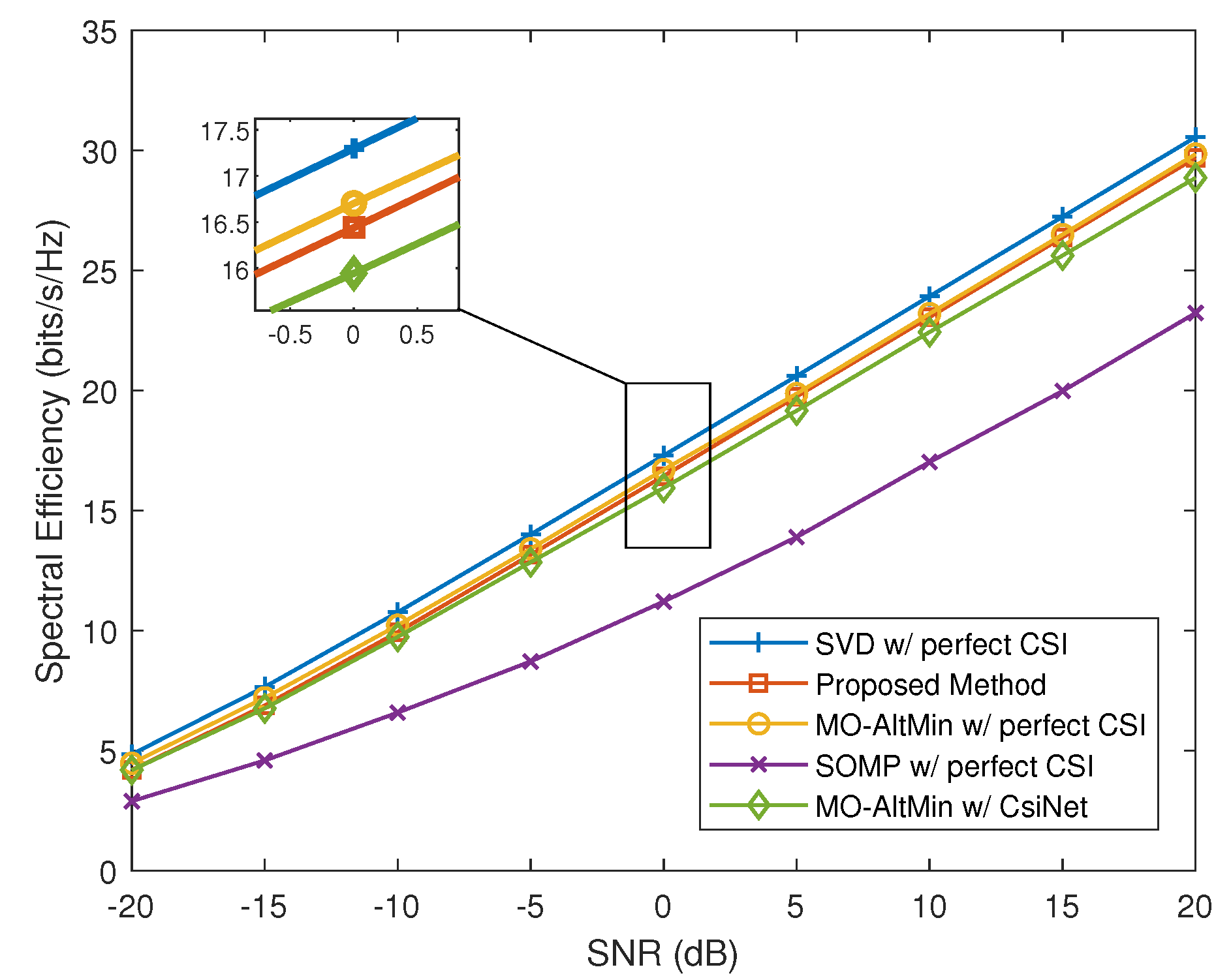
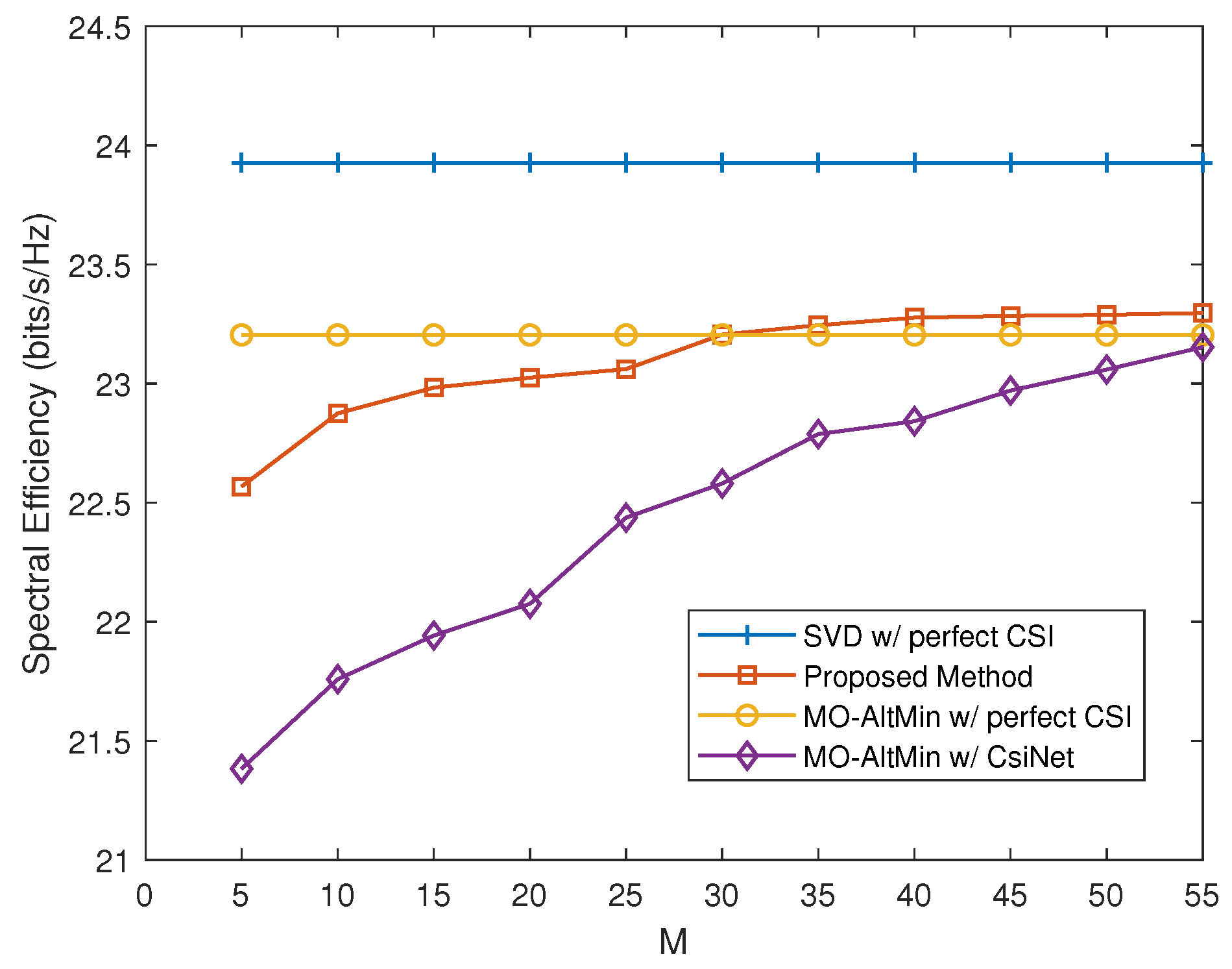
- The simulation results illustrate that compared with conventional approaches, which reserve channel reconstruction, our proposed method can significantly reduce the feedback overhead and achieve better performance, especially when the feedback resources are limited.
2. System Model
3. Proposed Deep Learning Framework for CSI Feedback and Hybrid Precoding
3.1. Deep Learning-Based Scheme
3.1.1. CSI Feedback
3.1.2. Hybrid Precoding
3.2. Dataset Generation
4. Implementation Details
5. Experiment Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sohrabi, F.; Yu, W. Hybrid Digital and Analog Beamforming Design for Large-Scale Antenna Arrays. IEEE J. Sel. Top. Signal Process. 2016, 10, 501–513. [Google Scholar] [CrossRef] [Green Version]
- Ayach, O.E.; Rajagopal, S.; Abu-Surra, S.; Pi, Z.; Heath, R.W. Spatially Sparse Precoding in Millimeter Wave MIMO Systems. IEEE Trans. Wirel. Commun. 2014, 13, 1499–1513. [Google Scholar] [CrossRef] [Green Version]
- Rusu, C.; Mèndez-Rial, R.; González-Prelcic, N.; Heath, R.W. Low Complexity Hybrid Precoding Strategies for Millimeter Wave Communication Systems. IEEE Trans. Wirel. Commun. 2016, 15, 8380–8393. [Google Scholar] [CrossRef]
- Zhang, J.; Björnson, E.; Matthaiou, M.; Ng, D.W.K.; Yang, H.; Love, D.J. Prospective Multiple Antenna Technologies for Beyond 5G. IEEE J. Sel. Areas Commun. 2020, 38, 1637–1660. [Google Scholar] [CrossRef]
- González-Coma, J.P.; Suárez-Casal, P.; Castro, P.M.; Castedo, L. FDD channel estimation via covariance estimation in wideband massive MIMO systems. Sensors 2020, 20, 930. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.; Shen, J.C.; Zhang, J.; Letaief, K.B. Alternating Minimization Algorithms for Hybrid Precoding in Millimeter Wave MIMO Systems. IEEE J. Sel. Top. Signal Process. 2016, 10, 485–500. [Google Scholar] [CrossRef] [Green Version]
- Lyu, S.; Wang, Z.; Gao, Z.; He, H.; Hanzo, L. Lattice-Based mmWave Hybrid Beamforming. IEEE Trans. Commun. 2021, 69, 4907–4920. [Google Scholar] [CrossRef]
- Huang, Y.; Liu, C.; Song, Y.; Yu, X. Near-optimal hybrid precoding for millimeter wave massive MIMO systems via cost-efficient Sub-connected structure. IET Commun. 2020, 14, 2340–2349. [Google Scholar] [CrossRef]
- Sun, Y.; Gao, Z.; Wang, H.; Shim, B.; Gui, G.; Mao, G.; Adachi, F. Principal Component Analysis-Based Broadband Hybrid Precoding for Millimeter-Wave Massive MIMO Systems. IEEE Trans. Wirel. Commun. 2020, 19, 6331–6346. [Google Scholar] [CrossRef]
- Feng, C.; Shen, W.; An, J.; Hanzo, L. Weighted Sum Rate Maximization of the mmWave Cell-Free MIMO Downlink Relying on Hybrid Precoding. IEEE Trans. Wirel. Commun. 2021. [Google Scholar] [CrossRef]
- Wen, C.K.; Shih, W.T.; Jin, S. Deep Learning for Massive MIMO CSI Feedback. IEEE Wirel. Commun. Mag. 2018, 7, 748–751. [Google Scholar] [CrossRef] [Green Version]
- Shen, W.; Dai, L.; Shim, B.; Wang, Z.; Heath, R.W. Channel Feedback Based on AoD-Adaptive Subspace Codebook in FDD Massive MIMO Systems. IEEE Trans. Commun. 2018, 66, 5235–5248. [Google Scholar] [CrossRef]
- Nair, S.S.; Bhashyam, S. Hybrid Beamforming in MU-MIMO Using Partial Interfering Beam Feedback. IEEE Commun. Lett. 2020, 24, 1548–1552. [Google Scholar] [CrossRef]
- Kuo, P.H.; Kung, H.T.; Ting, P.A. Compressive sensing based channel feedback protocols for spatially-correlated massive antenna arrays. In Proceedings of the 2012 IEEE Wireless Communications and Networking Conference (WCNC), Paris, France, 1–4 April 2012; pp. 492–497. [Google Scholar]
- Almradi, A.; Matthaiou, M.; Xiao, P.; Fusco, V.F. Hybrid Precoding for Massive MIMO With Low Rank Channels: A Two-Stage User Scheduling Approach. IEEE Trans. Commun. 2020, 68, 4816–4831. [Google Scholar] [CrossRef]
- Zhao, Y.; Xu, W.; Xu, J.; Jin, S.; Wang, K.; Alouini, M.S. Analog Versus Hybrid Precoding for Multiuser Massive MIMO With Quantized CSI Feedback. IEEE Commun. Lett. 2020, 24, 2319–2323. [Google Scholar] [CrossRef]
- Wang, T.; Wen, C.K.; Jin, S.; Li, G.Y. Deep Learning-Based CSI Feedback Approach for Time-Varying Massive MIMO Channels. IEEE Wirel. Commun. Mag. 2019, 8, 416–419. [Google Scholar] [CrossRef] [Green Version]
- Guo, J.; Wen, C.K.; Jin, S.; Li, G.Y. Convolutional Neural Network-Based Multiple-Rate Compressive Sensing for Massive MIMO CSI Feedback: Design, Simulation, and Analysis. IEEE Trans. Wirel. Commun. 2020, 19, 2827–2840. [Google Scholar] [CrossRef] [Green Version]
- Jin, Y.; Zhang, J.; Jin, S.; Ai, B. Channel Estimation for Cell-Free mmWave Massive MIMO Through Deep Learning. IEEE Trans. Veh. Technol. 2019, 68, 10325–10329. [Google Scholar] [CrossRef]
- Guo, J.; Li, X.; Chen, M.; Jiang, P.; Yang, T.; Duan, W.; Wang, H.; Jin, S.; Yu, Q. AI enabled wireless communications with real channel measurements: Channel feedback. J. Commun. Inf. Netw. 2020, 5, 310–317. [Google Scholar]
- Ye, H.; Gao, F.; Qian, J.; Wang, H.; Li, G.Y. Deep Learning-Based Denoise Network for CSI Feedback in FDD Massive MIMO Systems. IEEE Commun. Lett. 2020, 24, 1742–1746. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Song, Y.; Yang, J.; Gui, G.; Adachi, F. Deep-Learning-Based Millimeter-Wave Massive MIMO for Hybrid Precoding. IEEE Trans. Veh. Technol. 2019, 68, 3027–3032. [Google Scholar] [CrossRef] [Green Version]
- Elbir, A.M. CNN-Based Precoder and Combiner Design in mmWave MIMO Systems. IEEE Commun. Lett. 2019, 23, 1240–1243. [Google Scholar] [CrossRef]
- Elbir, A.M.; Papazafeiropoulos, A.K. Hybrid Precoding for Multiuser Millimeter Wave Massive MIMO Systems: A Deep Learning Approach. IEEE Trans. Veh. Technol. 2020, 69, 552–563. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhang, J.; Ng, D.W.K.; Jin, S.; Ai, B. Improving Sum-Rate of Cell-Free Massive MIMO With Expanded Compute-and-Forward. IEEE Trans. Signal Process. 2022, 70, 202–215. [Google Scholar] [CrossRef]
- Jin, Y.; Zhang, J.; Huang, C.; Yang, L.; Xiao, H.; Ai, B.; Wang, Z. Multiple Residual Dense Networks for Reconfigurable Intelligent Surfaces Cascaded Channel Estimation. IEEE Trans. Veh. Technol. 2022, 71, 2134–2139. [Google Scholar] [CrossRef]
- Hojatian, H.; Nadal, J.; Frigon, J.F.; Leduc-Primeau, F. Unsupervised Deep Learning for Massive MIMO Hybrid Beamforming. IEEE Trans. Wirel. Commun. 2021, 20, 7086–7099. [Google Scholar] [CrossRef]
- Elbir, A.M. A Deep Learning Framework for Hybrid Beamforming Without Instantaneous CSI Feedback. IEEE Trans. Veh. Technol. 2020, 69, 11743–11755. [Google Scholar] [CrossRef]
- Attiah, K.M.; Sohrabi, F.; Yu, W. Deep learning for channel sensing and hybrid precoding in TDD massive MIMO OFDM systems. arXiv 2021, arXiv:2011.10709. [Google Scholar]
- Jang, J.; Lee, H.; Hwang, S.; Ren, H.; Lee, I. Deep Learning-Based Limited Feedback Designs for MIMO Systems. IEEE Wirel. Commun. Mag. 2020, 9, 558–561. [Google Scholar] [CrossRef] [Green Version]
- Sohrabi, F.; Attiah, K.M.; Yu, W. Deep Learning for Distributed Channel Feedback and Multiuser Precoding in FDD Massive MIMO. IEEE Trans. Wirel. Commun. 2021, 20, 4044–4057. [Google Scholar] [CrossRef]
- Attiah, K.M.; Sohrabi, F.; Yu, W. Deep Learning Approach to Channel Sensing and Hybrid Precoding for TDD Massive MIMO Systems. In Proceedings of the 2020 IEEE Globecom Workshops (GC Wkshps), Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Jin, Q.; Yang, L.; Liao, Z. AdaBits: Neural Network Quantization with Adaptive Bit-Widths. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Running Time |
|---|---|
| Proposed method | 0.0046 s |
| MO-AltMin with perfect CSI | 1.2999 s |
| MO-AltMin with CsiNet | 1.3007 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Q.; Zhao, H.; Wang, J.; Chen, W. Deep Learning-Based Joint CSI Feedback and Hybrid Precoding in FDD mmWave Massive MIMO Systems. Entropy 2022, 24, 441. https://doi.org/10.3390/e24040441
Sun Q, Zhao H, Wang J, Chen W. Deep Learning-Based Joint CSI Feedback and Hybrid Precoding in FDD mmWave Massive MIMO Systems. Entropy. 2022; 24(4):441. https://doi.org/10.3390/e24040441
Chicago/Turabian StyleSun, Qiang, Huan Zhao, Jue Wang, and Wei Chen. 2022. "Deep Learning-Based Joint CSI Feedback and Hybrid Precoding in FDD mmWave Massive MIMO Systems" Entropy 24, no. 4: 441. https://doi.org/10.3390/e24040441