
Coupled VAE: Improved Accuracy and Robustness of a Variational Autoencoder


Abstract
:1. Introduction
2. The Variational Autoencoder
2.1. Vae Loss Function
2.2. Comparison with Other Generative Machine Learning Methods
3. Accounting for Risk with Coupled Entropy
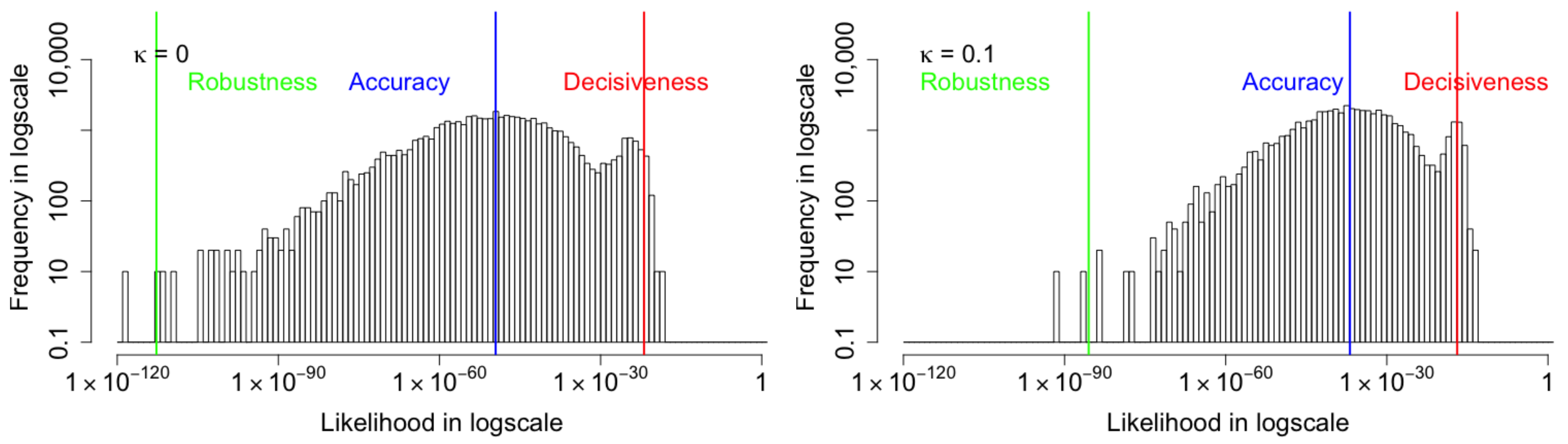
3.1. Assessing Probabilistic Forecasts with the Generalized Mean
3.2. Definition of Negative Coupled ELBO
4. Results Using the MNIST Handwritten Numerals
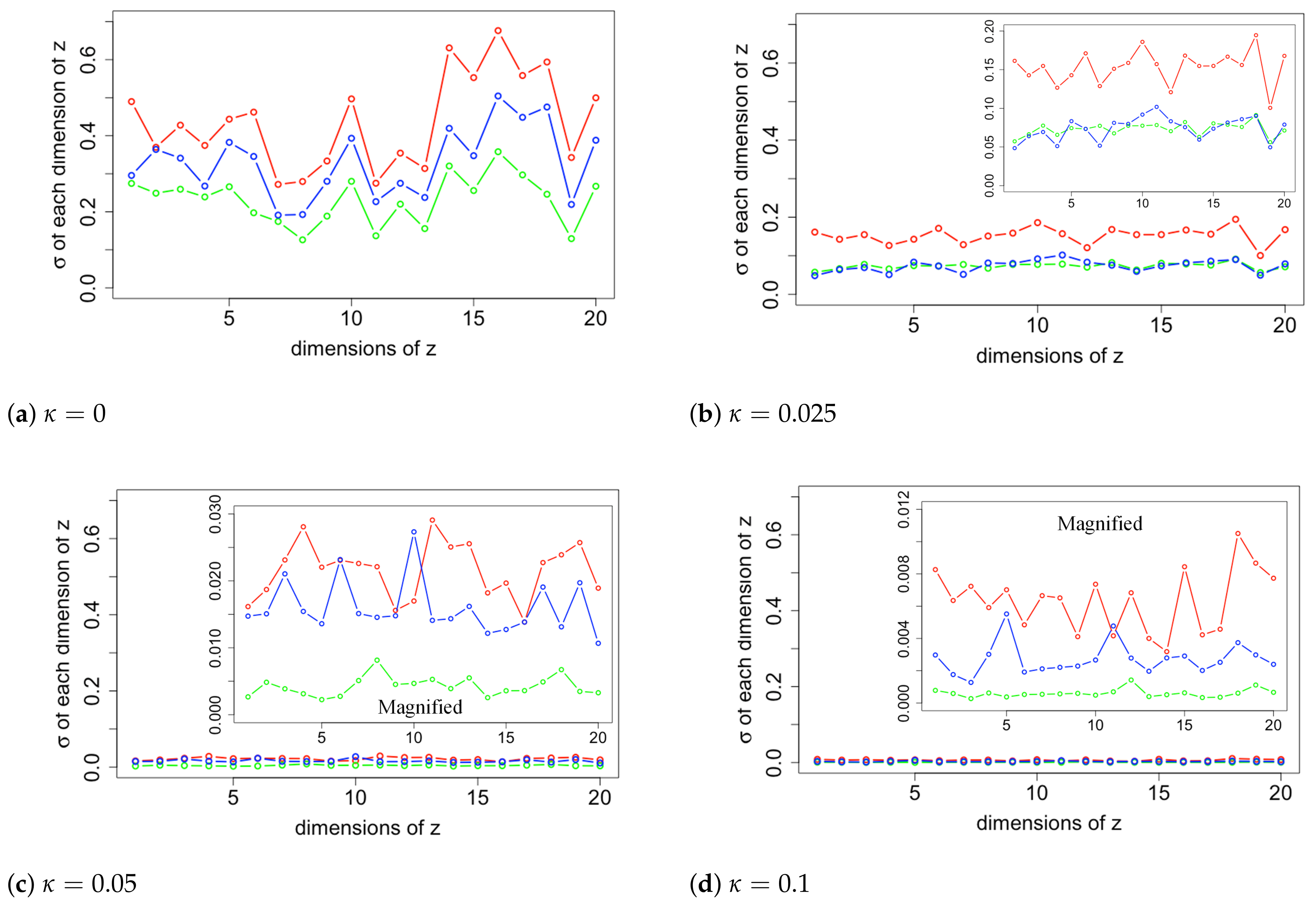
5. Visualization of Latent Distribution
6. Performance with Corrupted Images
7. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Derivation of Negative Coupled ELBO
Appendix A.2. Origin of the Generalized Probability Metrics
References
- Srivastava, A.; Sutton, C. Autoencoding Variational Inference for Topic Models. arXiv 2017, arXiv:1703.01488. [Google Scholar]
- Dilokthanakul, N.; Mediano, P.A.M.; Garnelo, M.; Lee, M.C.H.; Salimbeni, H.; Arulkumaran, K.; Shanahan, M. Deep Unsupervised Clustering with Gaussian Mixture Variational Autoencoders. arXiv 2016, arXiv:1611.02648. [Google Scholar]
- Akrami, H.; Joshi, A.A.; Li, J.; Aydore, S.; Leahy, R.M. Robust variational autoencoder. arXiv 2019, arXiv:1905.09961. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Tran, D.; Hoffman, M.D.; Saurous, R.A.; Brevdo, E.; Murphy, K.; Blei, D.M. Deep probabilistic programming. In Proceedings of the Fifth International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Bowman, S.R.; Vilnis, L.; Vinyals, O.; Dai, A.M.; Jozefowicz, R.; Bengio, S. Generating Sentences from a Continuous Space. In Proceedings of the Twentieth Conference on Computational Natural Language Learning (CoNLL), Beijing, China, 26–31 July 2015. [Google Scholar]
- Zalger, J. Application of Variational Autoencoders for Aircraft Turbomachinery Design; Technical Report; Stanford University: Stanford, CA, USA, 2017. [Google Scholar]
- Xu, H.; Feng, Y.; Chen, J.; Wang, Z.; Qiao, H.; Chen, W.; Zhao, N.; Li, Z.; Bu, J.; Li, Z.; et al. Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications. In Proceedings of the 2018 World Wide Web Conference on World Wide Web, Lyon, France, 23–27 April 2018; ACM Press: New York, NY, USA, 2018; pp. 187–196. [Google Scholar]
- Luchnikov, I.A.; Ryzhov, A.; Stas, P.J.; Filippov, S.N.; Ouerdane, H. Variational autoencoder reconstruction of complex many-body physics. Entropy 2019, 21, 1091. [Google Scholar] [CrossRef] [Green Version]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2016, 112, 859–877. [Google Scholar] [CrossRef] [Green Version]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. beta-vae: Learning basic visual concepts with a constrained variational framework. In Proceedings of the ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Burgess, C.P.; Higgins, I.; Pal, A.; Matthey, L.; Watters, N.; Desjardins, G.; Lerchner, A. Understanding disentangling in beta-VAE. arXiv 2018, arXiv:1804.03599. [Google Scholar]
- Niemitalo, O. A Method for Training Artificial Neural Networks to Generate Missing Data within a Variable Context. Internet Archive (Wayback Machine). 2010. Available online: https://web.archive.org/web/20120312111546/http://yehar.com/blog/?p=167 (accessed on 5 February 2022).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Dutchess County, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Donahue, J.; Darrell, T.; Krähenbühl, P. Adversarial feature learning. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017—Conference Track Proceedings, International Conference on Learning Representations, ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Mastropietro, O.; Lamb, A.; Arjovsky, M.; Courville, A. Adversarially learned inference. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017—Conference Track Proceedings, International Conference on Learning Representations, ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Neyshabur, B.; Bhojanapalli, S.; Chakrabarti, A. Stabilizing GAN training with multiple random projections. arXiv 2017, arXiv:1705.07831. [Google Scholar]
- Pearl, J. Bayesian Netwcrks: A Model cf Self-Activated Memory for Evidential Reasoning; Technical Report; University of California: Oakland, CA, USA, 1985. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Ebbers, J.; Heymann, J.; Drude, L.; Glarner, T.; Haeb-Umbach, R.; Raj, B. Hidden Markov Model Variational Autoencoder for Acoustic Unit Discovery. In Proceedings of the INTERSPEECH 2017, Stockholm, Sweden, 20–24 August 2017; pp. 488–492. [Google Scholar]
- Nelson, K.P.; Umarov, S. Nonlinear statistical coupling. Phys. Stat. Mech. Its Appl. 2010, 389, 2157–2163. [Google Scholar] [CrossRef] [Green Version]
- Nelson, K.P.; Umarov, S.R.; Kon, M.A. On the average uncertainty for systems with nonlinear coupling. Phys. Stat. Mech. Its Appl. 2017, 468, 30–43. [Google Scholar] [CrossRef] [Green Version]
- Nelson, K.P. Reduced Perplexity: A simplified perspective on assessing probabilistic forecasts. In Info-Metrics Volume; Chen, M., Dunn, J.M., Golan, A., Ullah, A., Eds.; Oxford University Press: Oxford, UK, 2020. [Google Scholar]
- Tsallis, C. Introduction to Nonextensive Statistical Mechanics: Approaching a Complex World; Springer: New York, NY, USA, 2009; pp. 1–382. [Google Scholar]
- Weberszpil, J.; Helayël-Neto, J.A. Variational approach and deformed derivatives. Phys. Stat. Mech. Its Appl. 2016, 450, 217–227. [Google Scholar] [CrossRef] [Green Version]
- Venkatesan, R.; Plastino, A. Generalized statistics variational perturbation approximation using q-deformed calculus. Phys. Stat. Mech. Its Appl. 2010, 389, 1159–1172. [Google Scholar] [CrossRef] [Green Version]
- McAlister, D. XIII. The law of the geometric mean. Proc. R. Soc. 1879, 29, 367–376. [Google Scholar]
- Nelson, K.P.; Scannell, B.J.; Landau, H. A risk profile for information fusion algorithms. Entropy 2011, 13, 1518–1532. [Google Scholar] [CrossRef] [Green Version]
- Frogner, C.; Zhang, C.; Mobahi, H.; Araya, M.; Poggio, T.A. Learning with a Wasserstein Loss. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; pp. 2053–2061. [Google Scholar]
- Vahdat, A.; Kautz, J. Nvae: A deep hierarchical variational autoencoder. Adv. Neural Inf. Process. Syst. 2020, 33, 19667–19679. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C.J. The MNIST Database of Handwritten Digits. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 5 February 2022).
- Chen, K.R.; Svoboda, D.; Nelson, K.P. Use of Student’s t-Distribution for the Latent Layer in a Coupled Variational Autoencoder. arXiv 2020, arXiv:2011.10879. [Google Scholar]
- Takahashi, H.; Iwata, T.; Yamanaka, Y.; Yamada, M.; Yagi, S. Student-t Variational Autoencoder for Robust Density Estimation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 2696–2702. [Google Scholar]
- Mu, N.; Gilmer, J. Mnist-c: A robustness benchmark for computer vision. arXiv 2019, arXiv:1906.02337. [Google Scholar]
- Van Der Maaten, L.; Hinton, G. Visualizing Data using T-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Thurner, S.; Corominas-Murtra, B.; Hanel, R. Three faces of entropy for complex systems: Information, thermodynamics, and the maximum entropy principle. Phys. Rev. E 2017, 96, 032124. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abe, S. Stability of Tsallis entropy and instabilities of Rényi and normalized Tsallis entropies: A basis for q-exponential distributions. Phys. Rev. E 2002, 66, 046134. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rényi, A. On the foundations of information theory. Rev. L’Inst. Int. Stat. 1965, 33, 1–14. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coupling | Decisiveness | Accuracy | Robustness |
|---|---|---|---|
| 0 | |||
| Coupling | Coupled KL-Divergence | Coupled RE Loss | Coupled ELBO | KL Proportion | RE Proportion |
|---|---|---|---|---|---|
| 0 | 5.8 +/− 1.7 | 166.5 +/− 52.2 | 172.3 | 3.38% | 96.62% |
| 5.7 +/− 1.6 | 156.4 +/− 49.8 | 162.1 | 3.53% | 96.47% | |
| 5.6 +/− 1.6 | 149.2 +/− 46.6 | 154.8 | 3.61% | 96.39% | |
| 5.6 +/− 1.7 | 141.1 +/− 44.6 | 146.7 | 3.82% | 96.18% |
| Coupling | Coupled KL-Divergence | Coupled RE Loss | Coupled ELBO | KL Proportion | RE Proportion |
|---|---|---|---|---|---|
| 23.9 +/− 3.8 | 131.6 +/− 40.7 | 155.5 | 15.34% | 84.66% | |
| 29.6 +/− 2.3 | 119.9 +/− 38.5 | 149.5 | 19.80% | 80.20% | |
| 26.0 +/− 0.9 | 111.1 +/− 36.5 | 137.1 | 18.94% | 80.06% | |
| 21.4 +/− 0.5 | 104.4 +/− 34.3 | 125.8 | 16.98% | 83.02% | |
| 18.4 +/− 0.6 | 98.9 +/− 32.7 | 117.3 | 15.71% | 84.28% |
| Coupling | Coupled KL-Divergence | Coupled RE Loss | Coupled ELBO | KL Proportion | RE Proportion |
|---|---|---|---|---|---|
| 22.3 +/− 3.5 | 196.1 +/− 55.3 | 218.4 | 10.19% | 89.81% | |
| 29.4 +/− 2.0 | 178.8 +/− 50.1 | 208.2 | 14.12% | 85.88% | |
| 25.5 +/− 0.7 | 164.1 +/− 45.7 | 189.6 | 13.44% | 86.56% | |
| 20.9 +/− 0.4 | 154.0 +/− 43.0 | 174.9 | 11.96% | 88.04% | |
| 18.0 +/− 0.4 | 145.1 +/− 40.0 | 163.1 | 11.05% | 88.95% |
| Coupling | Coupled KL-Divergence | Coupled RE Loss | Coupled ELBO | KL Proportion | RE Proportion |
|---|---|---|---|---|---|
| 24.2 +/− 3.8 | 170.7 +/− 34.7 | 195.0 | 12.43% | 87.57% | |
| 29.9 +/− 2.2 | 148.0 +/− 31.0 | 177.9 | 16.81% | 83.19% | |
| 26.0 +/− 0.8 | 131.6 +/− 28.5 | 157.7 | 16.52% | 83.48% | |
| 21.4 +/− 0.6 | 120.9 +/− 26.7 | 142.3 | 15.05% | 84.95% | |
| 18.5 +/− 0.6 | 111.8 +/− 25.2 | 130.3 | 14.21% | 85.79% |
| Coupling | Coupled KL-Divergence | Coupled RE Loss | Coupled ELBO | KL Proportion | RE Proportion |
|---|---|---|---|---|---|
| 23.9 +/− 3.8 | 98.9 +/− 28.3 | 122.8 | 19.45% | 80.55% | |
| 29.9 +/− 2.4 | 88.9 +/− 26.2 | 118.8 | 25.14% | 74.86% | |
| 26.1 +/− 1.0 | 81.8 +/− 25.0 | 108.0 | 24.21% | 75.80% | |
| 21.6 +/− 0.7 | 77.6 +/− 23.9 | 99.2 | 21.80% | 78.20% | |
| 18.6 +/− 0.6 | 73.4 +/− 22.8 | 92.0 | 20.17% | 79.83% |
| Coupling | Coupled KL-Divergence | Coupled RE Loss | Coupled ELBO | KL Proportion | RE Proportion |
|---|---|---|---|---|---|
| 24.8 +/− 4.0 | 114.1 +/− 31.7 | 138.9 | 17.85% | 82.15% | |
| 30.4 +/− 2.4 | 102.3 +/− 29.0 | 132.7 | 22.92% | 77.08% | |
| 26.1 +/− 0.9 | 94.7 +/− 27.5 | 120.8 | 21.61% | 78.39% | |
| 21.8 +/− 0.7 | 89.5 +/− 26.3 | 111.3 | 19.61% | 80.39% | |
| 18.6 +/− 0.6 | 84.9 +/− 24.9 | 103.5 | 17.97% | 82.03% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, S.; Li, J.; Nelson, K.P.; Kon, M.A. Coupled VAE: Improved Accuracy and Robustness of a Variational Autoencoder. Entropy 2022, 24, 423. https://doi.org/10.3390/e24030423
Cao S, Li J, Nelson KP, Kon MA. Coupled VAE: Improved Accuracy and Robustness of a Variational Autoencoder. Entropy. 2022; 24(3):423. https://doi.org/10.3390/e24030423
Chicago/Turabian StyleCao, Shichen, Jingjing Li, Kenric P. Nelson, and Mark A. Kon. 2022. "Coupled VAE: Improved Accuracy and Robustness of a Variational Autoencoder" Entropy 24, no. 3: 423. https://doi.org/10.3390/e24030423