
A Review of the Asymmetric Numeral System and Its Applications to Digital Images



Abstract
:1. Introduction
- We present an in-depth and systematic discussion about various ANS-related technologies for providing a clear picture of this new lossless compression tool;
- We address several selected applications of ANS in response to the survey nature of this work;
- We explore the chaotic property of ANS and apply it to compress and encrypt digital images jointly, which is the desired mechanism for most digital image generators;
- We present a detailed performance comparison of various lossless compression algorithms in terms of compression ratio and execution speed.
2. Background Knowledge
2.1. Basic Concepts of Asymmetric Numeral Systems
- ANS-encoding: (input, current state) → (next state)
- ANS-decoding: (current state) → (previous state, output).
2.2. Huffman Coding, Arithmetic Coding, and the Asymmetric Numeral Systems
2.3. Types of the Asymmetric Numeral Systems
- (i)
- Uniform Asymmetric Binary System (uABS)
- (ii)
- Range Asymmetric Numeral System (rANS)
- (iii)
- Table Asymmetric Numeral System (tANS)
3. Variations in Asymmetric Numeral Systems
3.1. The Uniform Asymmetric Binary System (uABS)
- (a)
- uABS Constructions for Uniformly Distributed Binary Sources
- (b)
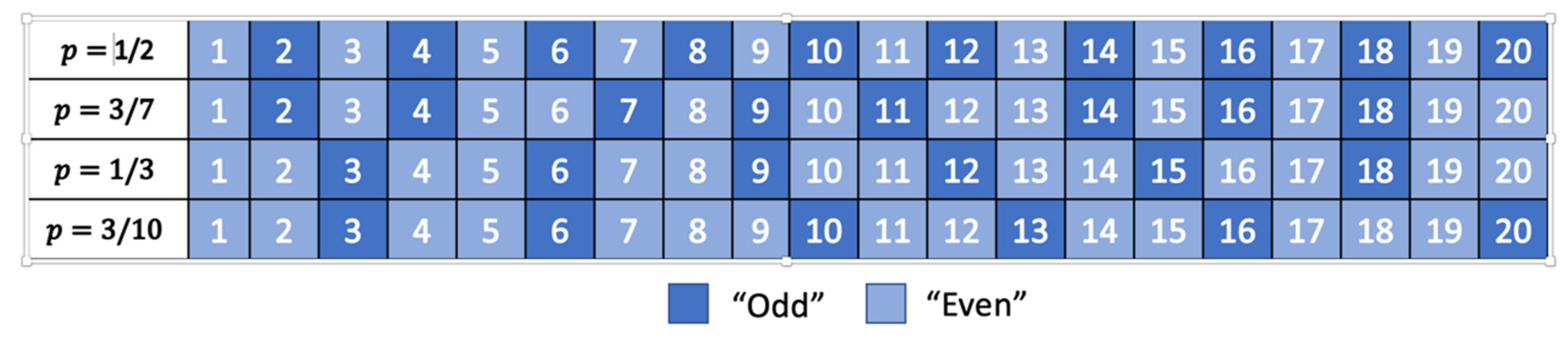
- ABS Constructions for Non-Uniformly Distributed Binary Sources and the Symbol Spread Function
3.2. The Range Asymmetric Numeral System (rANS)
- (a)
- The Basic rANS Construction
- (b)
- Streaming ANS Coding and the Renormalization Process
3.3. The Table Asymmetric Numeral System (tANS)
- (a)
- The Encoding and Decoding Functions of tANS:
- (b)
- The construction of Coding Tables for tANS
- (c)
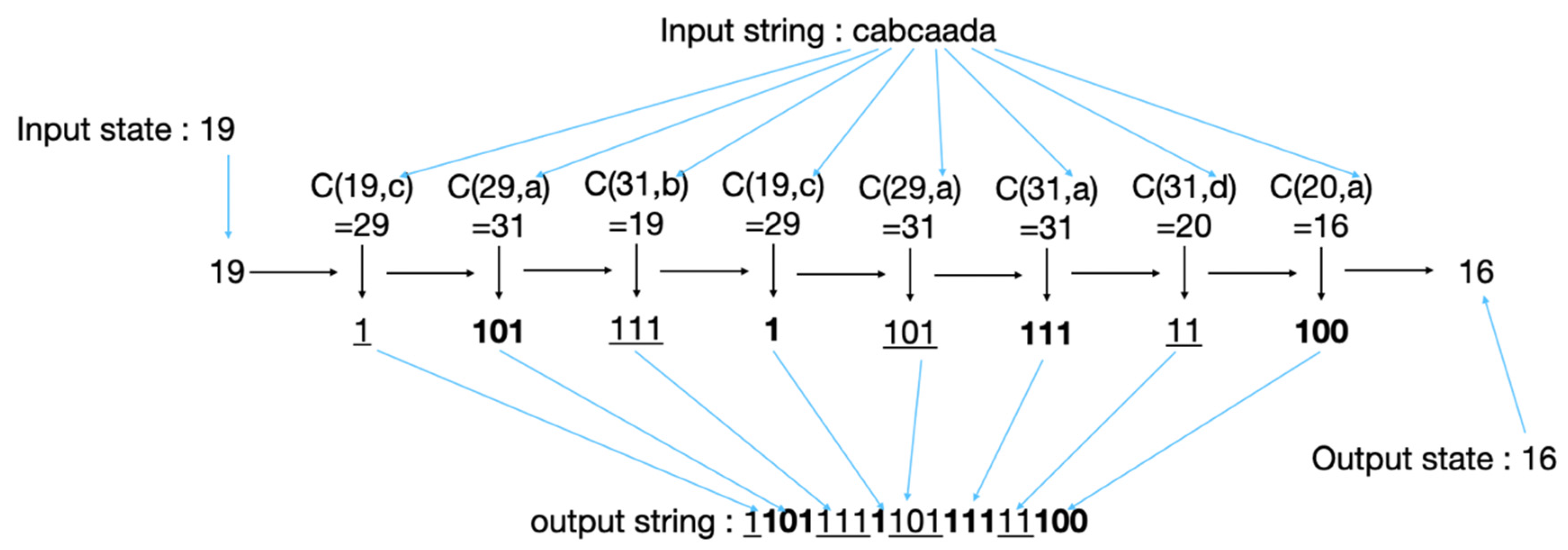
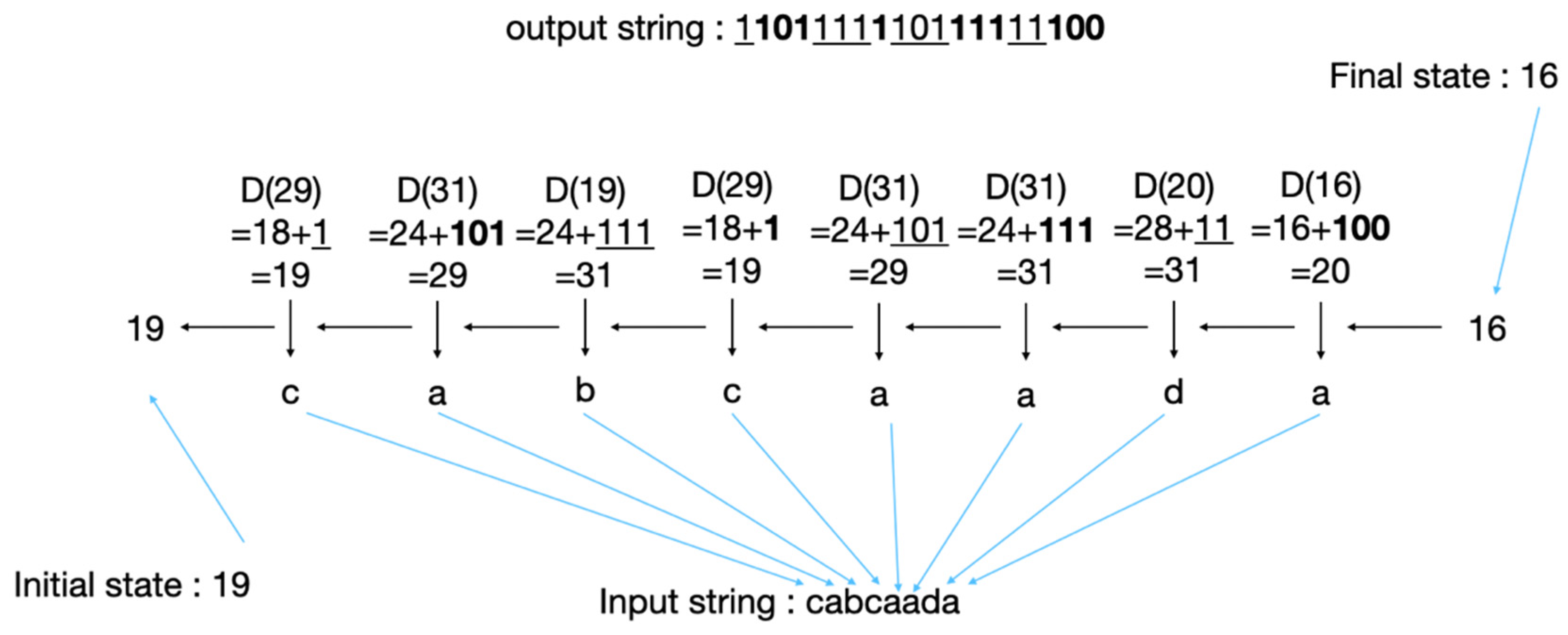
- The Complete Encoding and Decoding Processes of tANS
- Calculate the actual symbol probability in the to-be-compressed file,
- Determine the allowable state range and the state range of each symbol
- Use to approximate .
- Determine the proper SSF, ,
- Establish the tabularized encoding state function composed of and a tabularized decoding function composed of .
- Determine the encoding and decoding tables according to the SSF determined in Step 2.
- Start the encoding and decoding processes.
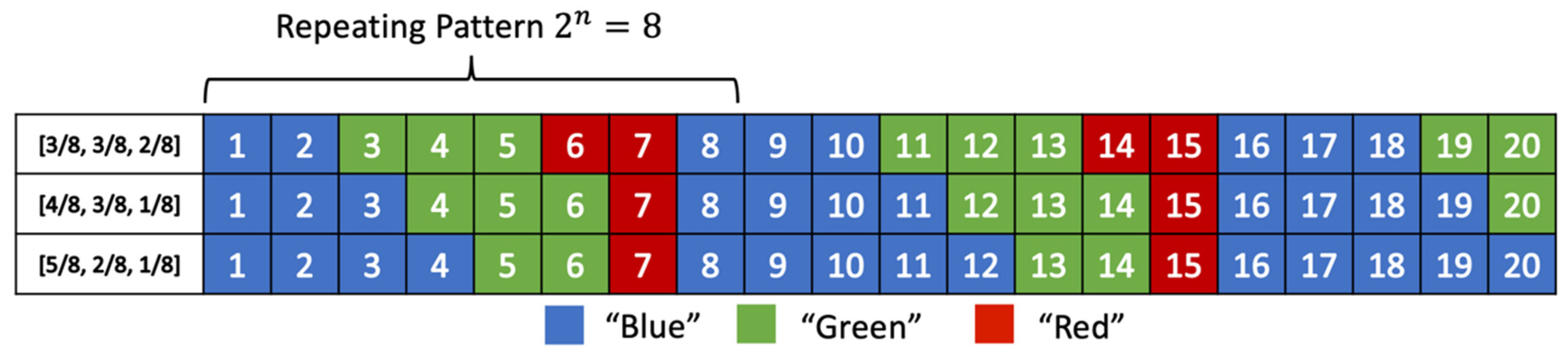
3.4. The Avalanche Effect of the tANS
4. Applications of the Asymmetric Numeral Systems
4.1. ANS in Index Compression and Machine Learning-Based Lossless Data Compression
4.2. ANS in Joint Compression and Encryption of Digital Images
4.3. ANS in Intellectual Property Rights Management and Integrity Checking of Digital Images
- (a)
- Some Specific Characteristics of ANS
- 1.
- Lossless and Compressive Representation
- 2.
- Avalanche and Retrospective Properties
- 3.
- Severability
- (b)
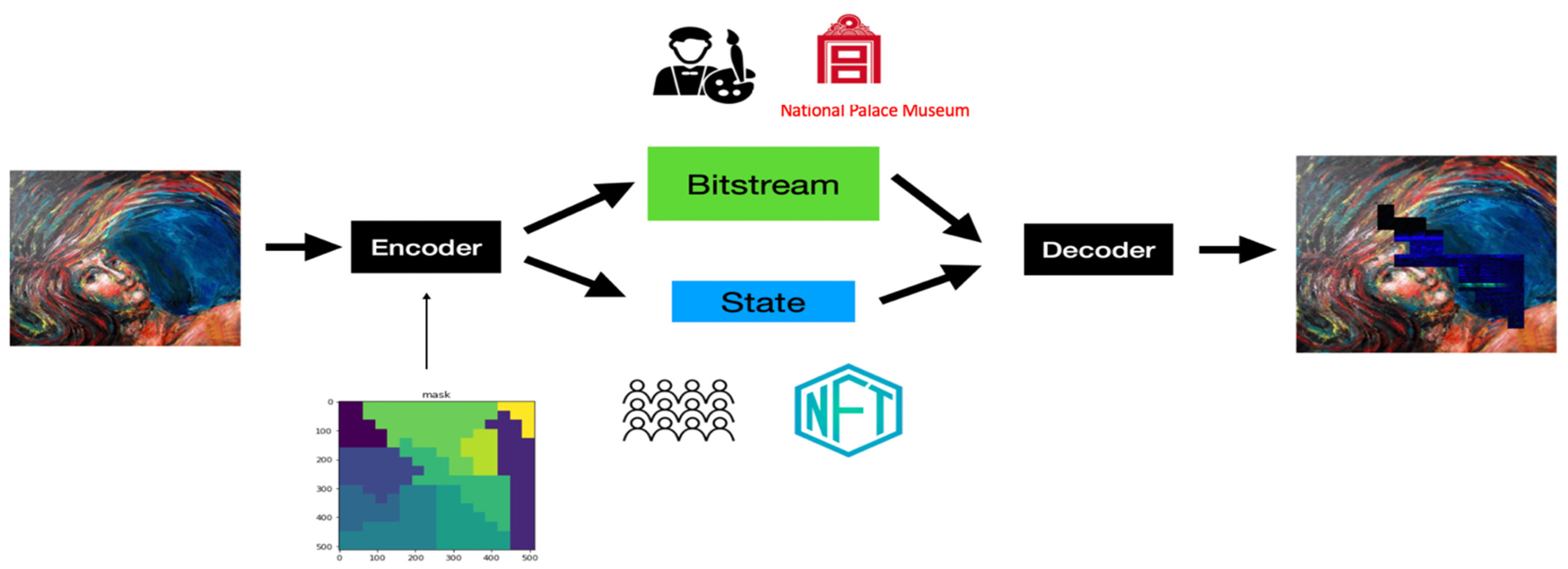
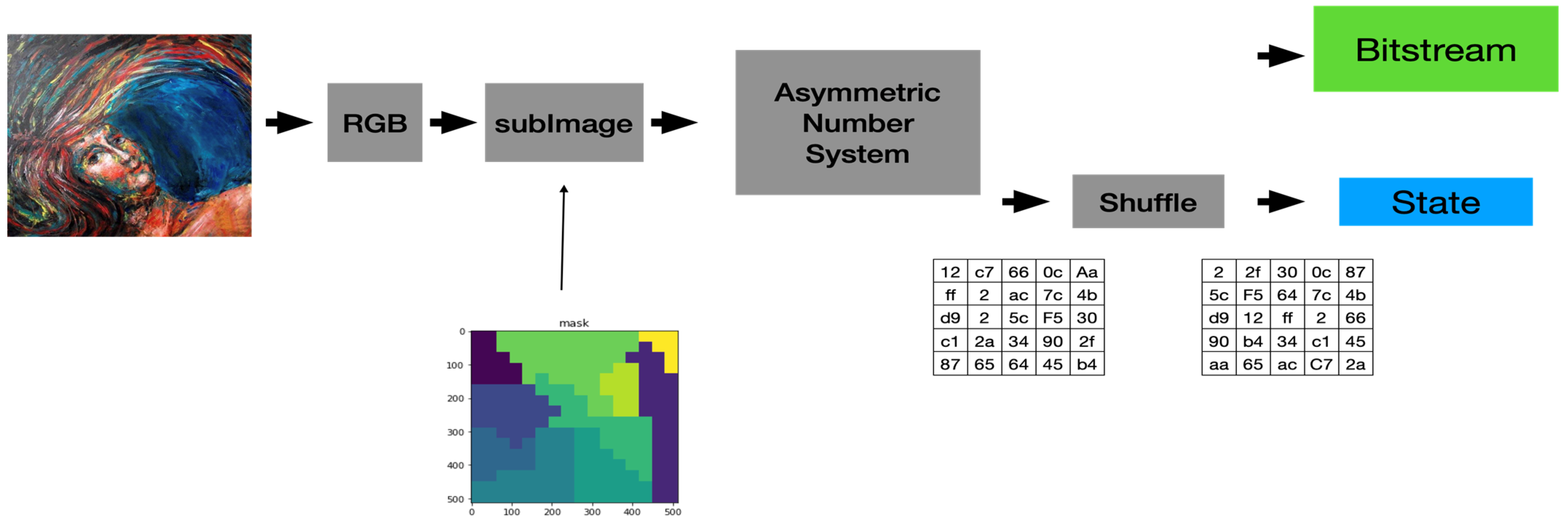
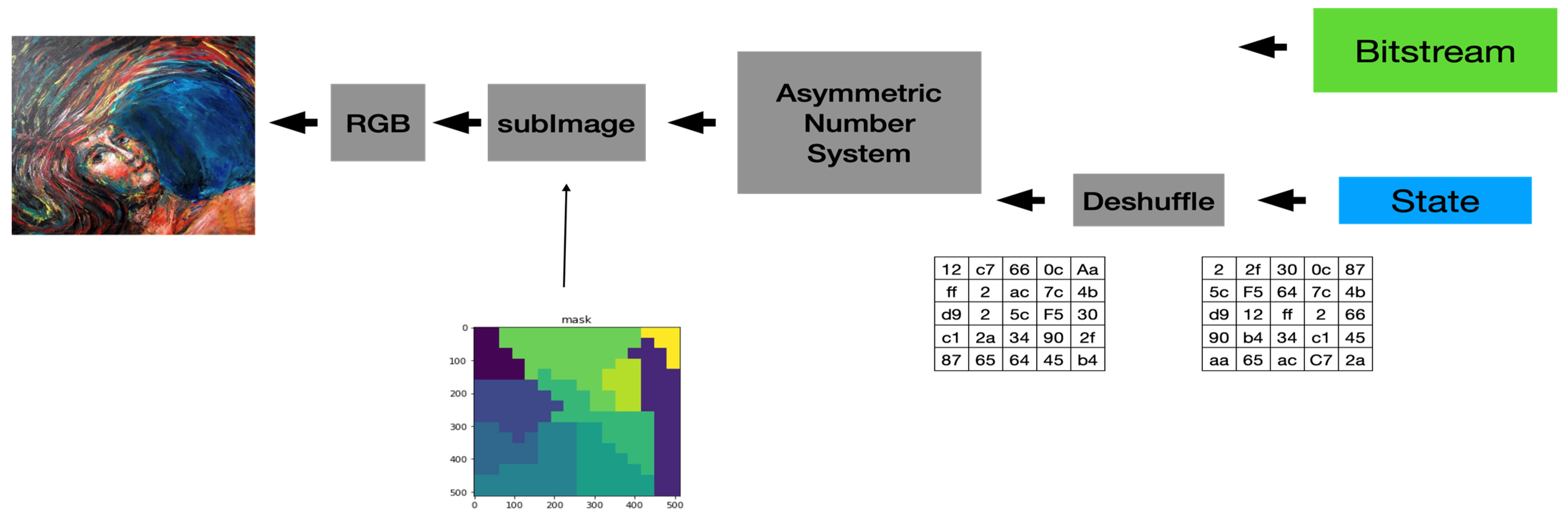
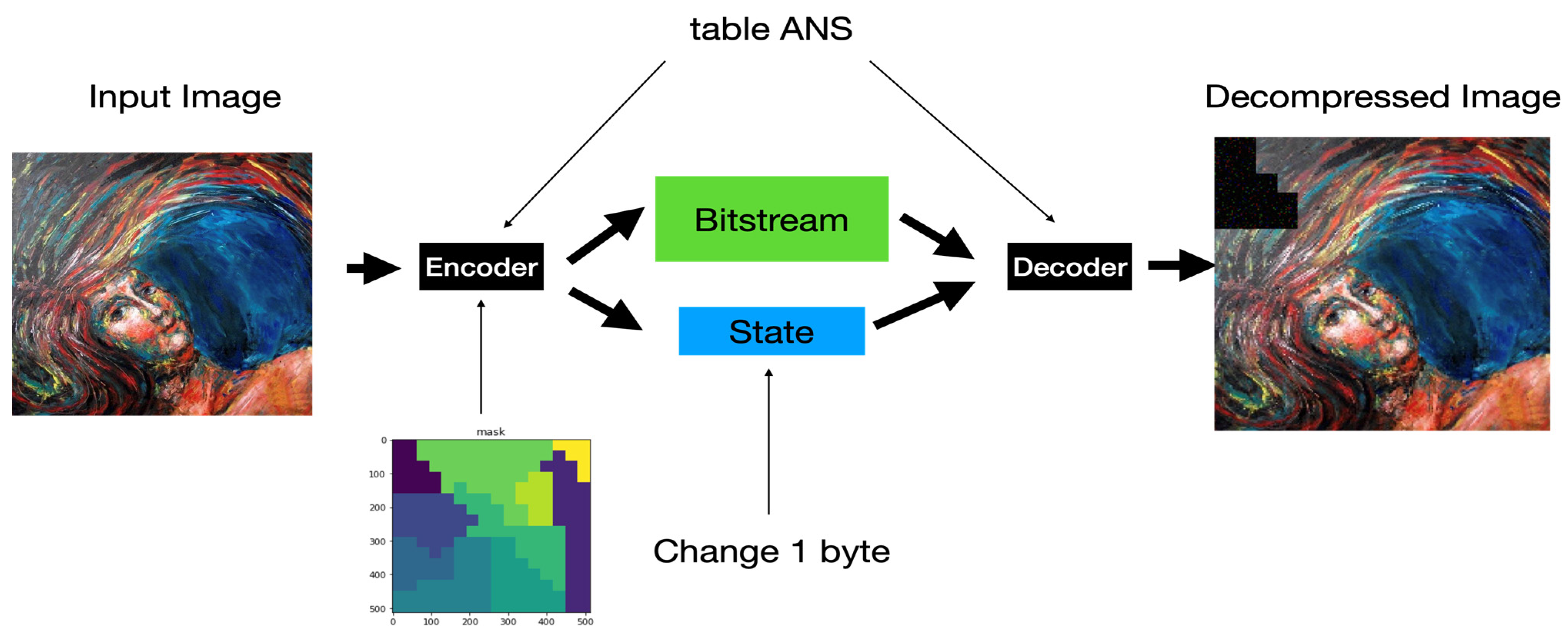
- The Proposed Applications of ANS-based Digital Image Processing System
5. Experimental Results
5.1. tANS in IPRs Protection of Digital Artwork Collections
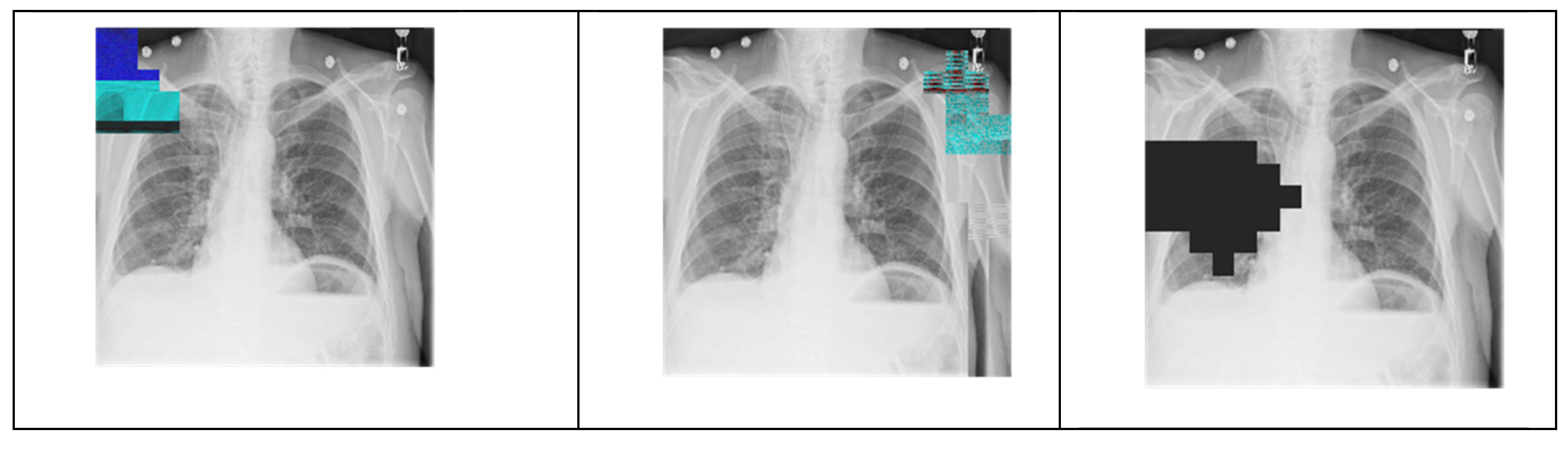
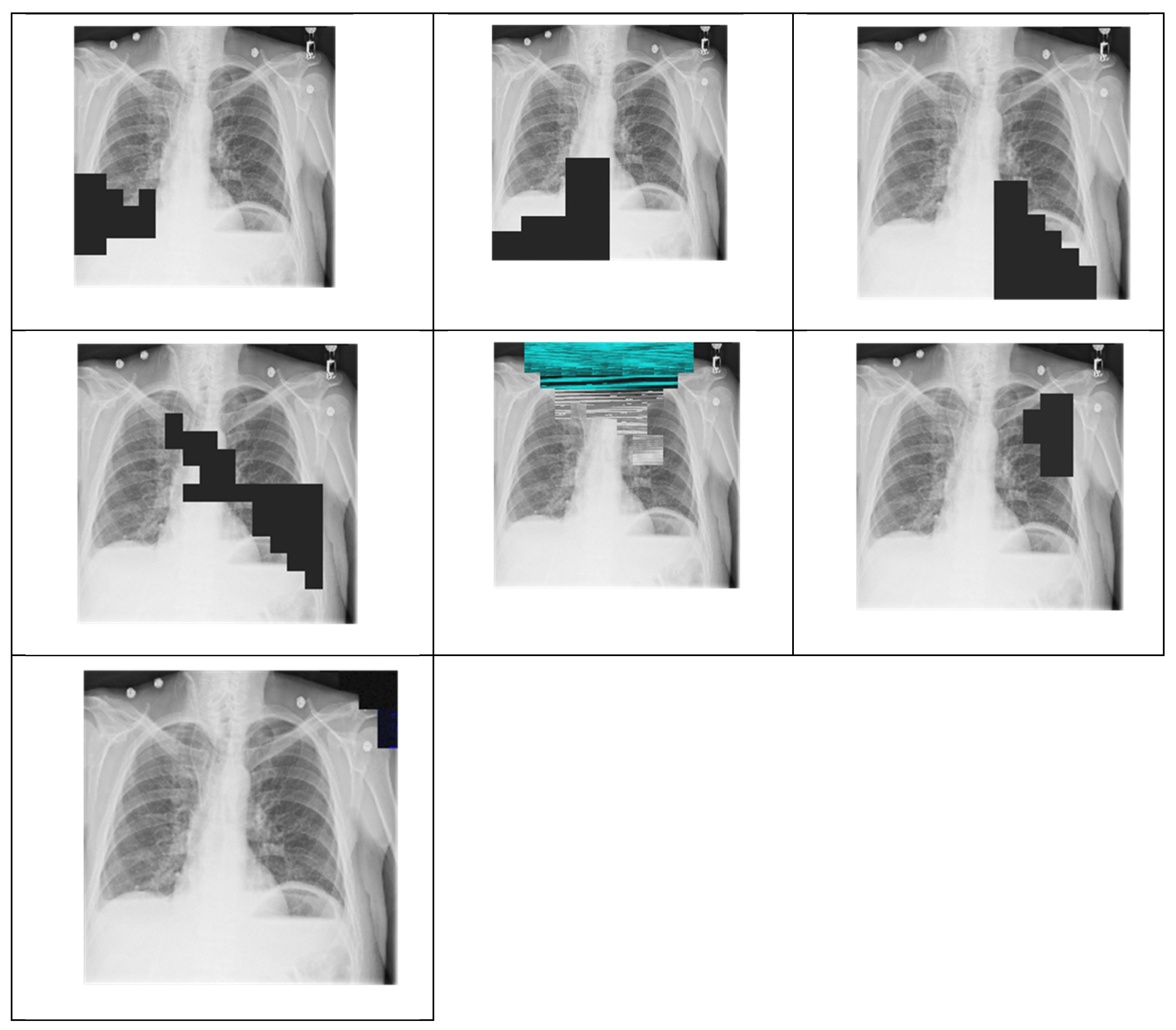
- (1)
- Does the damaged area of the decompressed image locate in the same areas where the state value changed?
- (2)
- Is the degree of contamination in the damage severe or not?
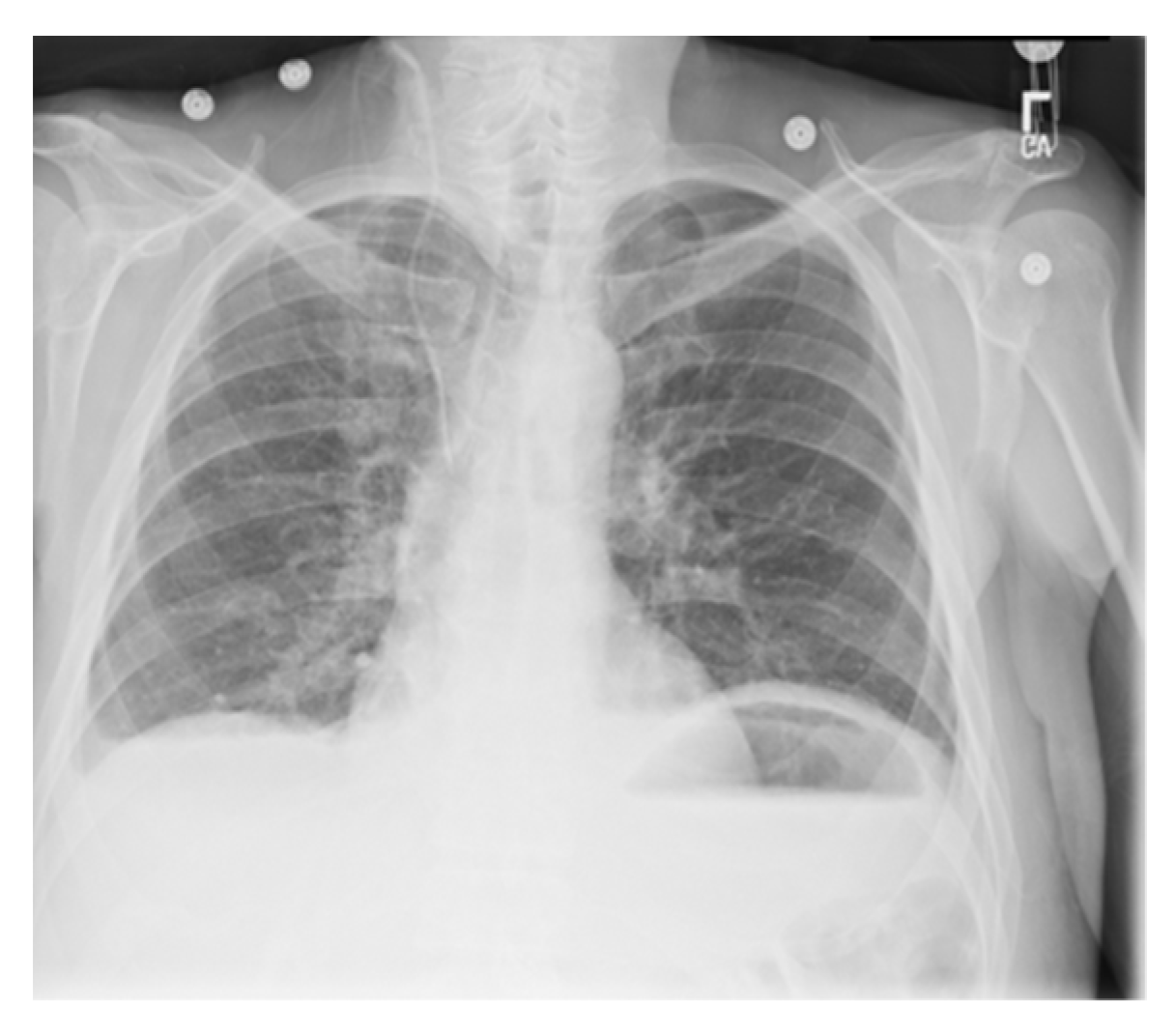
5.2. tANS in Integrity Checking of Digital Medical Images
6. Performance Comparison among Various Lossless Compression Algorithms
6.1. Description of Experimental Settings
6.2. Experiment Results
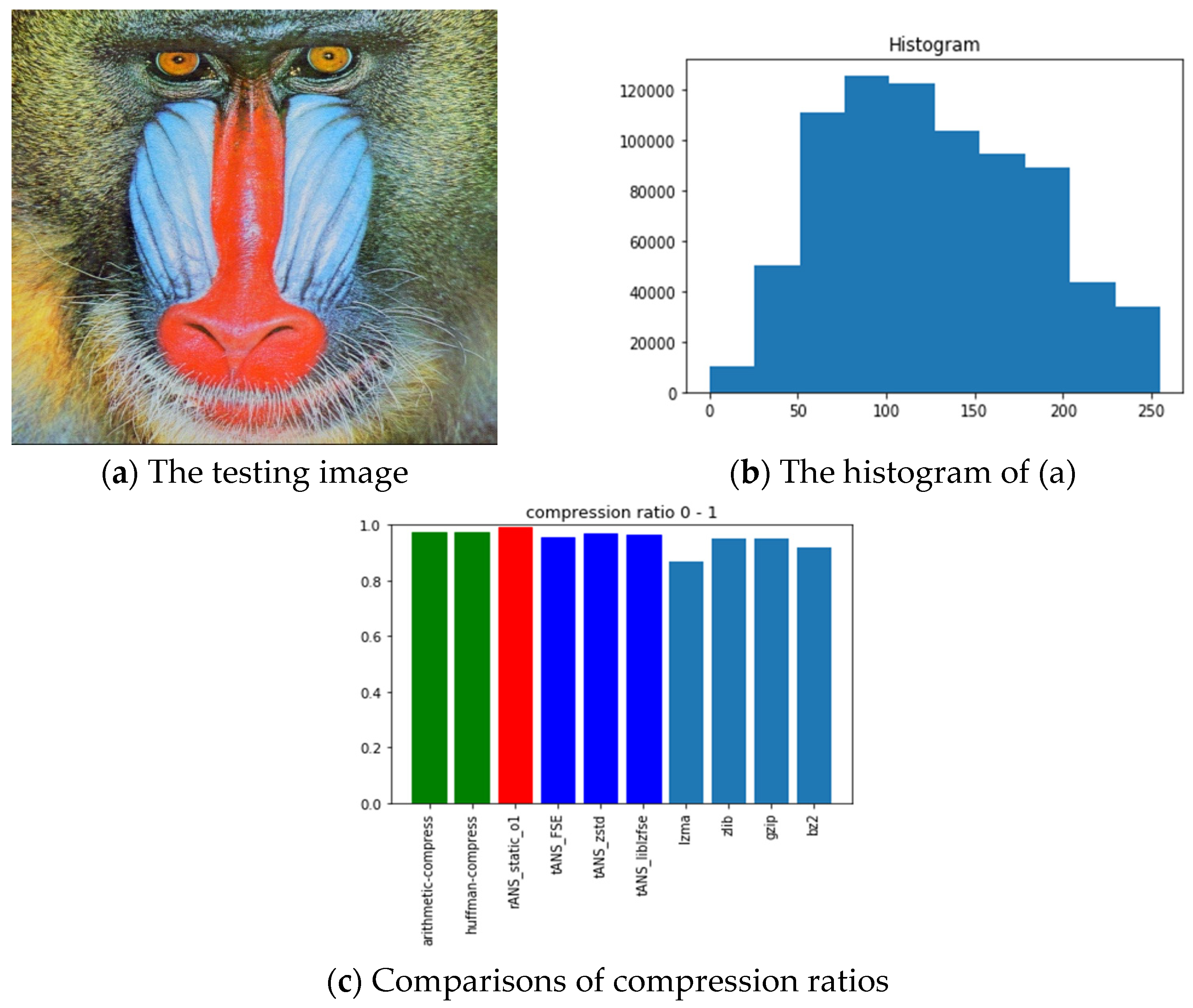
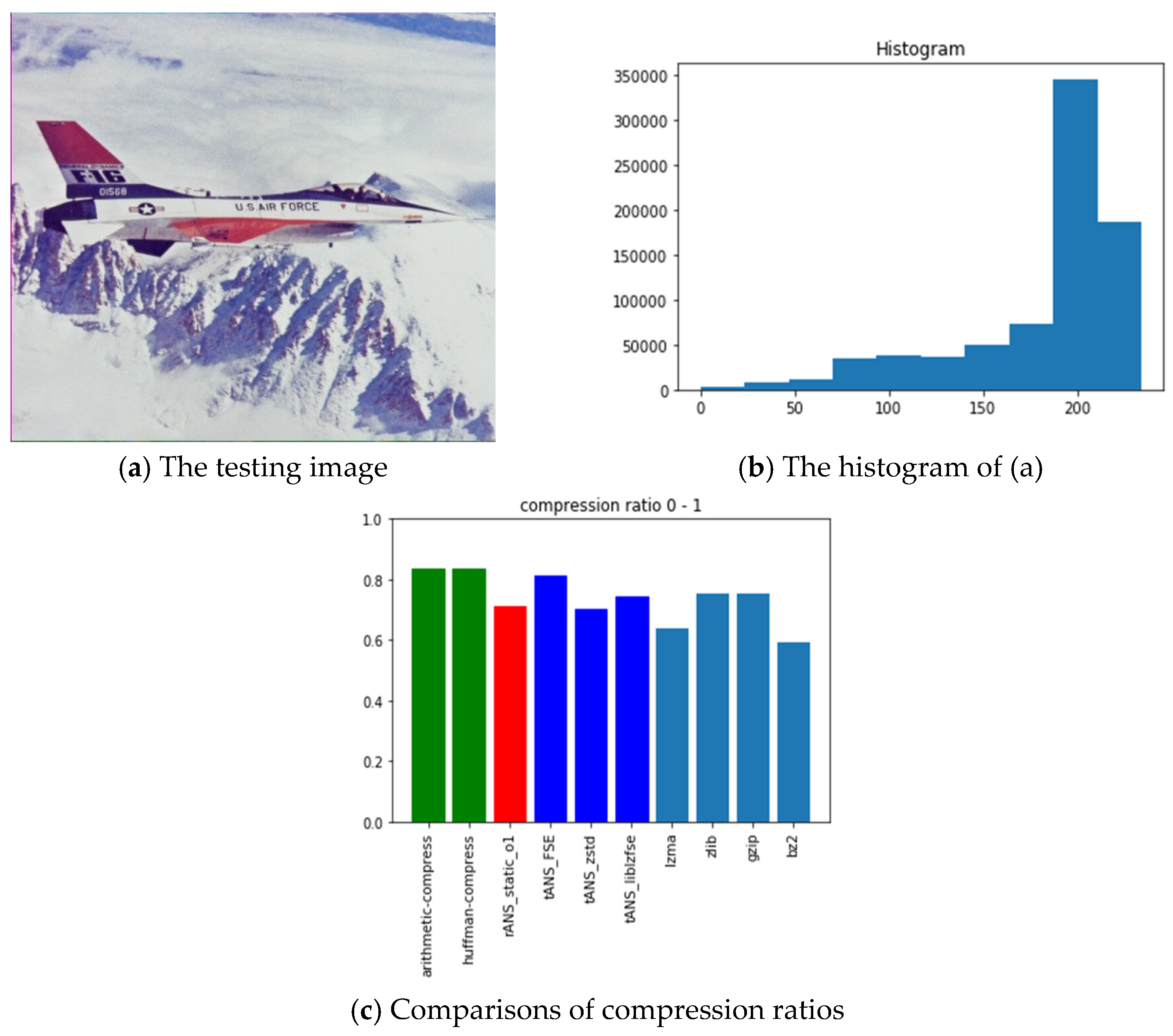
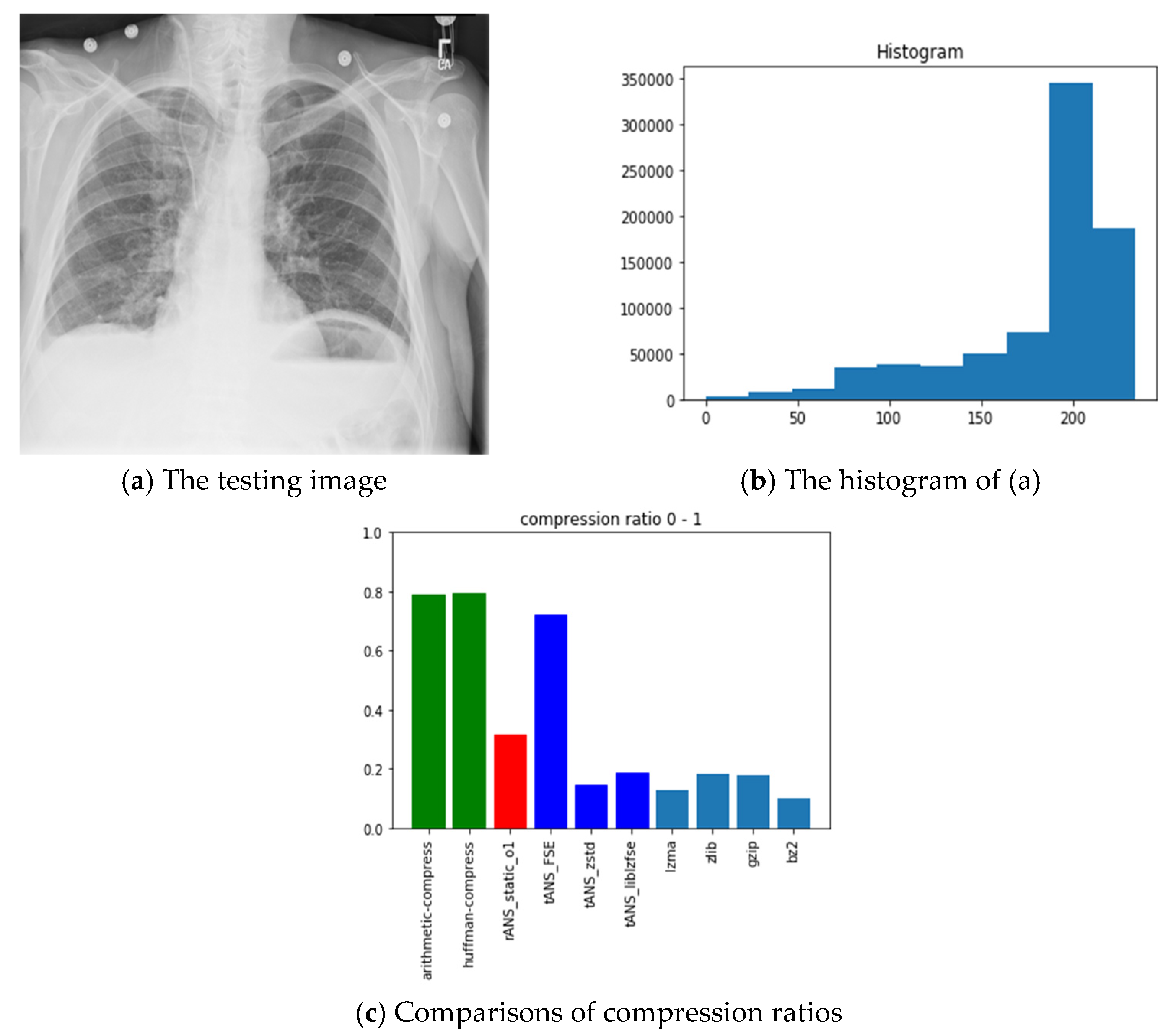
6.3. Observations Obtained from Our Experiments
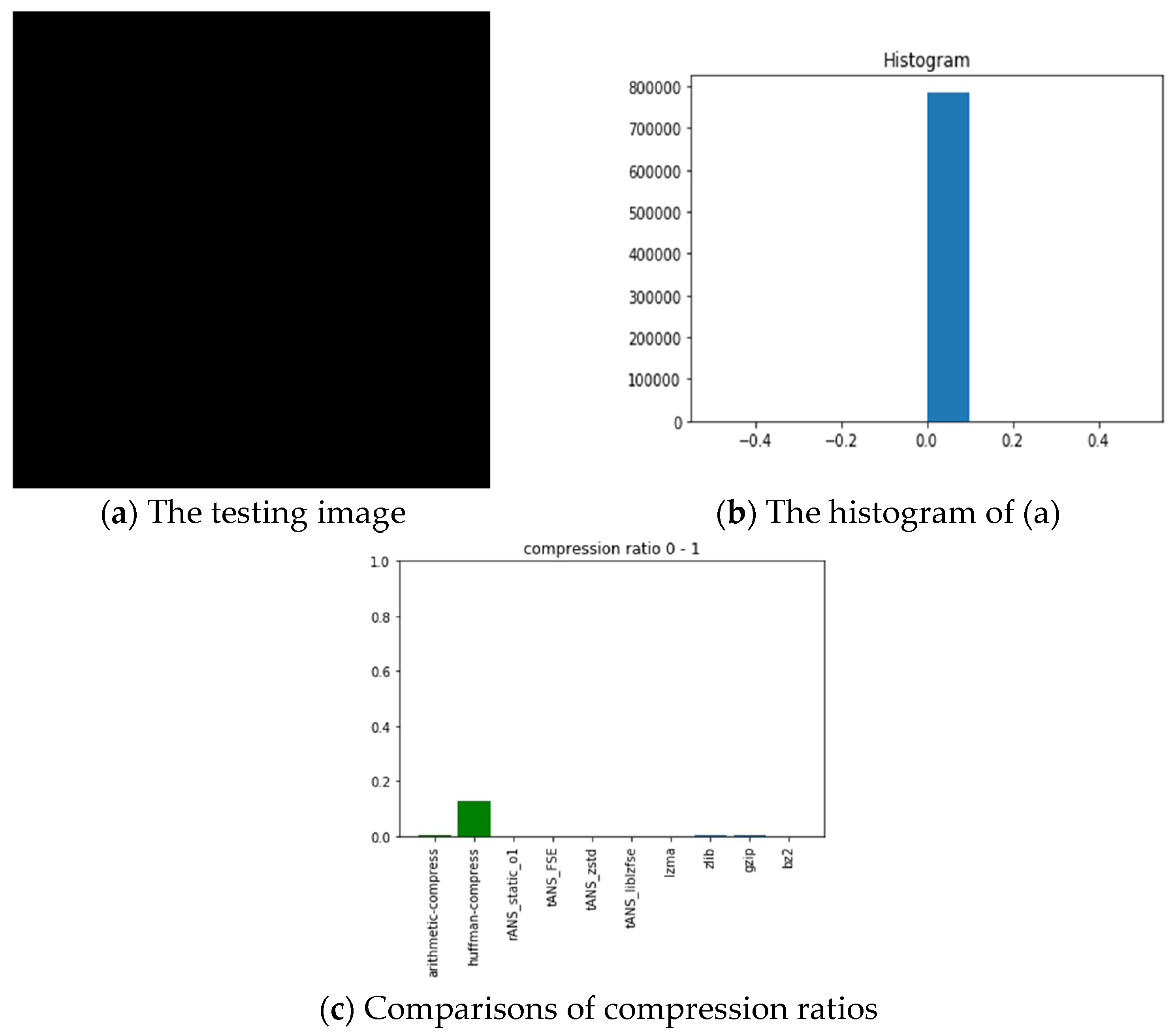
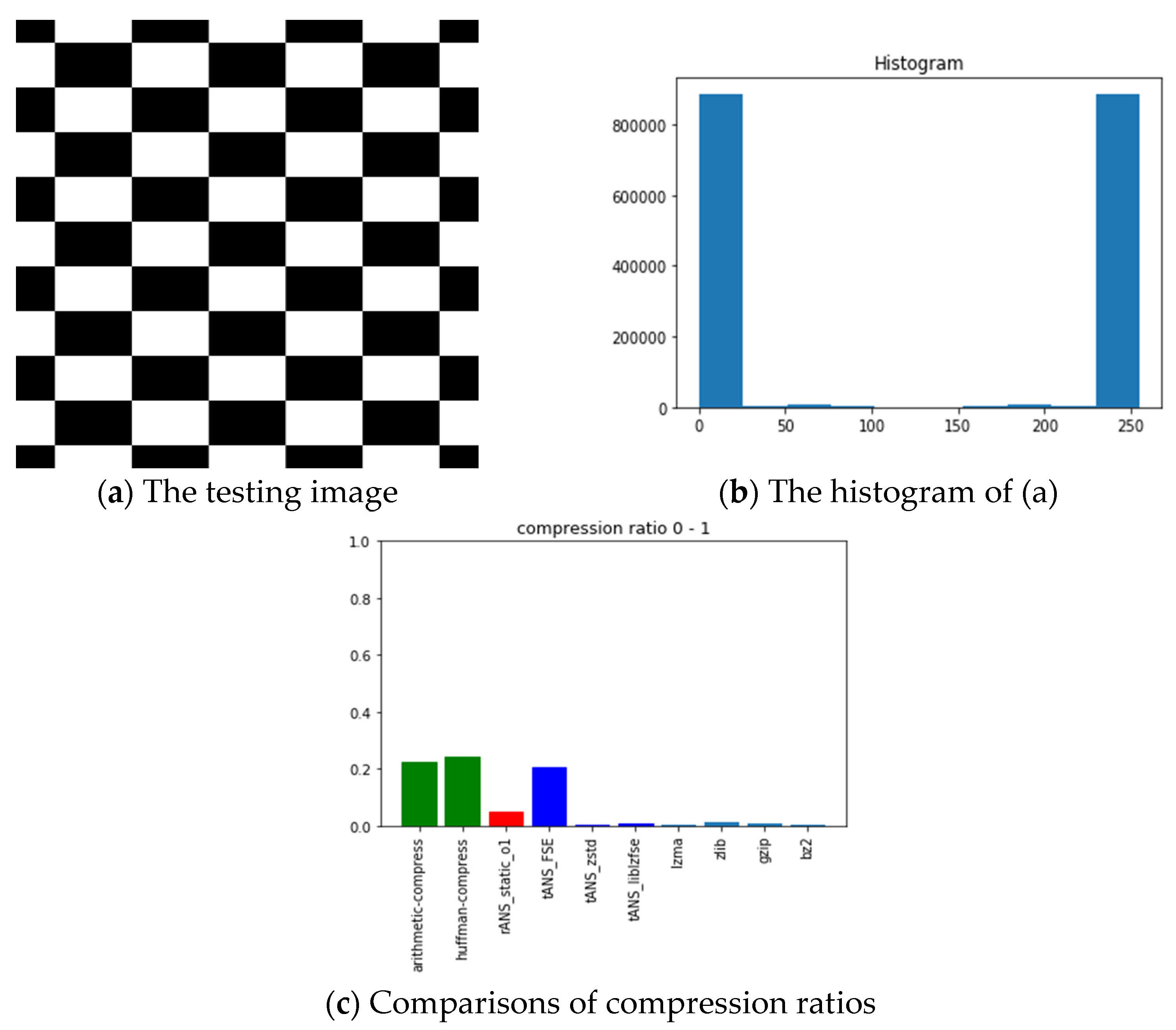
- ANS-related algorithms performed well if the data distribution is highly skewed, inferred from the all-black and the lattice images.
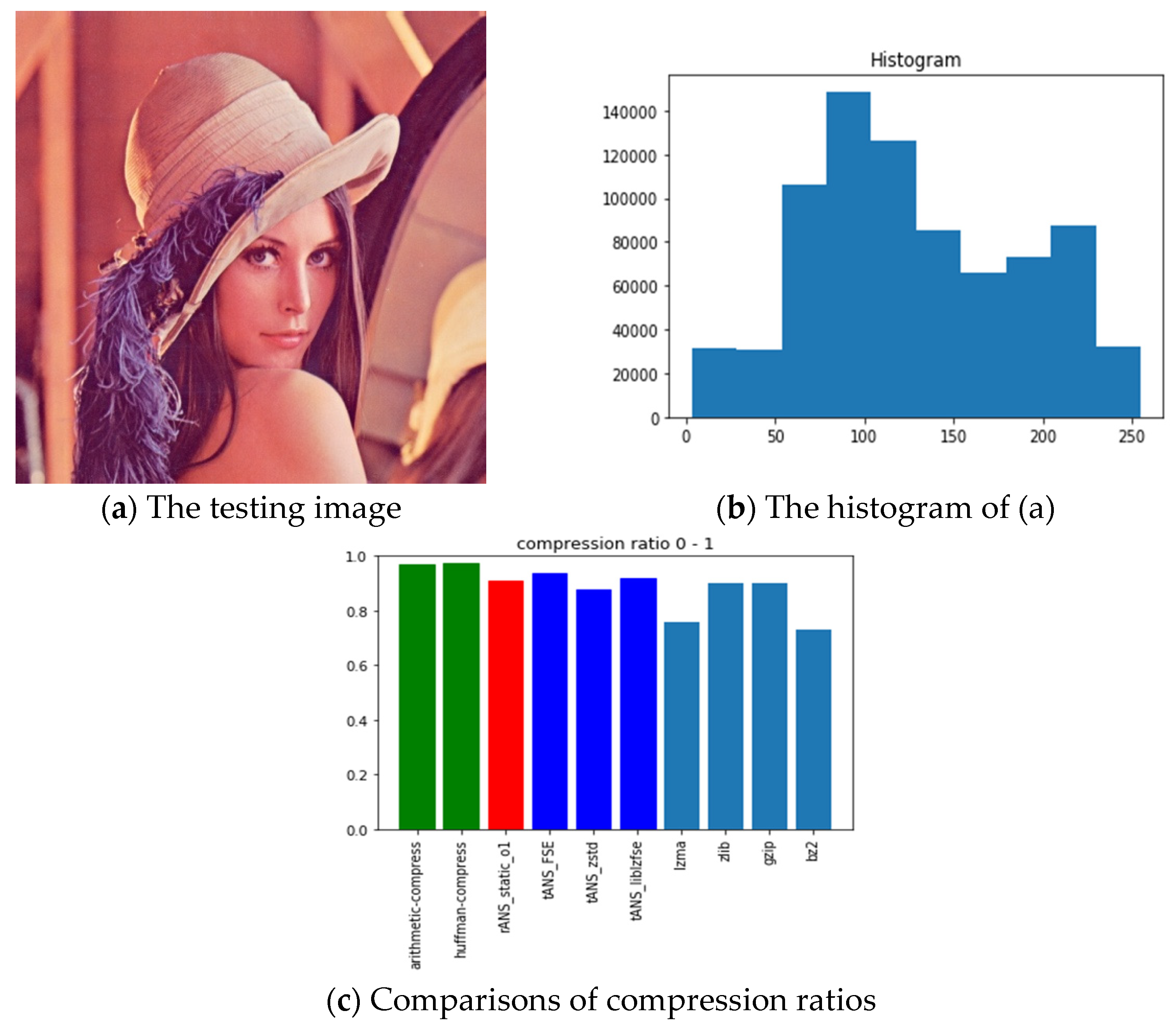
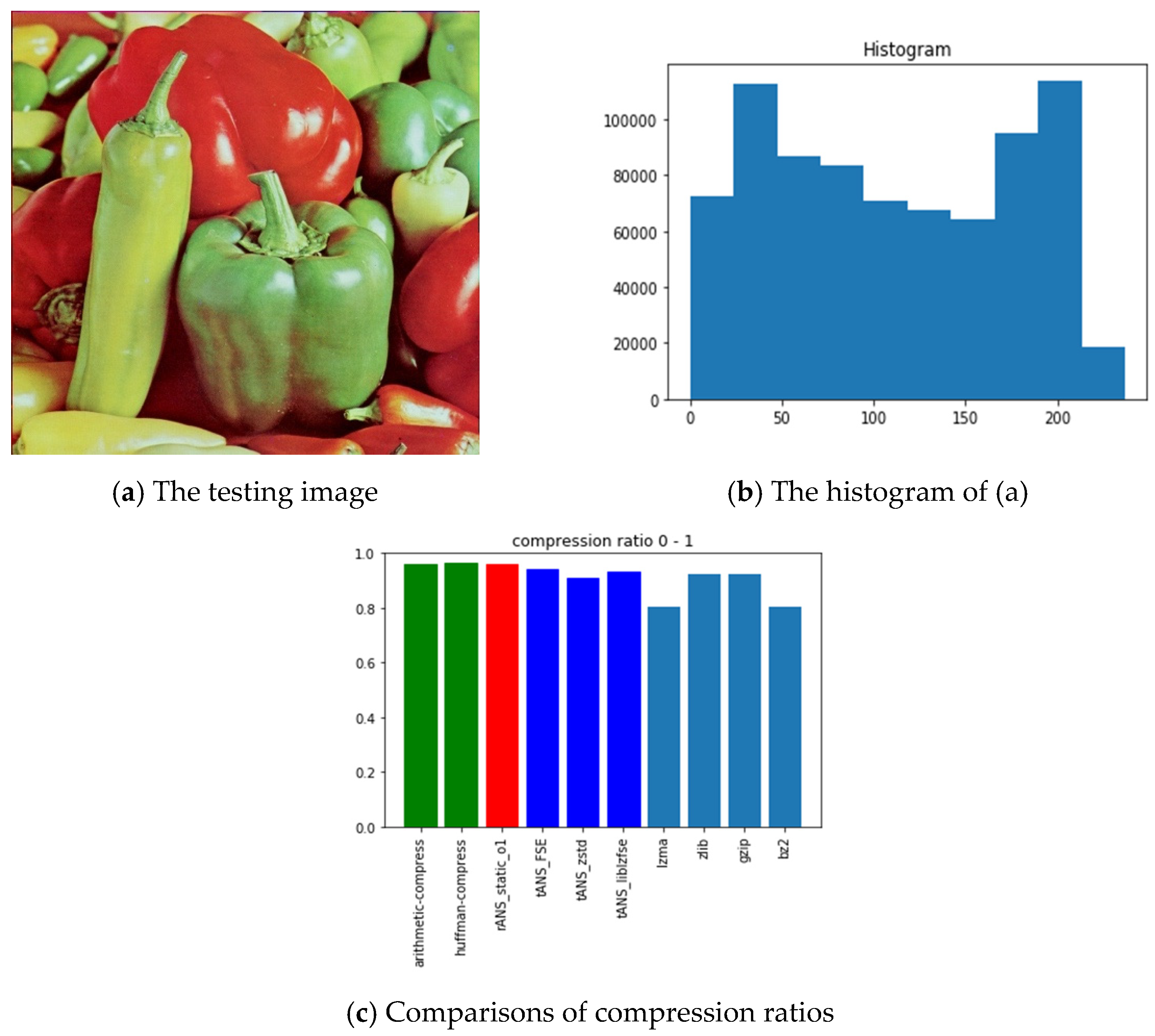
- ANS-related algorithms performed generally if the data distribution is almost uniform, inferred from Lena, fruits, and baboon images.
- ANS-related algorithms performed well for medical images (c.f., chest image) because most of the area in a medical image is of the same color black or white), which also coincides with our first comment.
- As for the compression ratio, we found that ANS-related algorithms performed almost the same as the arithmetic coding or a little bit better, which is as expected from the theoretical point of view.
- As for the time consumption, we found that ANS-related algorithms almost need the least execution time among all algorithms and are comparable to the Huffman code, which is also as expected from the theoretical point of view.
7. Conclusions
- (1)
- The combinatorial complexity in designing proper SSF makes developing an optimal ANS codec concerning a specific target becomes very challenging. Thus, finding a heuristic approach for reaching an effective ANS solution for a given input source is of great interest.
- (2)
- Based on the obtained states and bitstreams, develop some post-processing, such as prefix or suffix coding, or go through a hash function to find a unique state representation is worthy of doing.
- (3)
- Develop an efficient way to combine image recognition and segmentation techniques to automatically find Region of Interests (ROIs) in a picture so that the mask does not need to be manually set. This subject is of interest and beneficial to those planning to develop ANS-based image protection applications systematically and automatically.
- (4)
- Since one of the tANS coded results is a bitstream, which indeed can be losslessly compressed again to make the space smaller, then, “what is the best combination of all possible entropy coders?” would be an exciting research topic.
- (5)
- Before the image enters the ANS coder, it can be processed (transformed) in advance. Since the mask can divide an image at will, applying other image processing techniques to a sub-image with arbitrary shapes becomes challenging.
- (6)
- As mentioned at the end of Section 4.1, properly combining ANS with DNN to produce a fast compression mechanism with a high compression ratio is a research direction worthy of further exploration and investigation.
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| x′ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x | s = 0 | 0 | 1 | 2 | 3 | ||||||||||
| x | s = 1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |

Appendix B
Appendix C
| x | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| s | |||||||||||
| a | 16 | 31 | - | - | - | - | - | - | - | - | |
| b | - | 19 | 22 | 26 | - | - | - | - | - | - | |
| c | - | - | - | 17 | 21 | 24 | 27 | 29 | - | - | |
| d | 18 | 20 | 23 | 25 | 28 | 30 | |||||
| x′ | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| x | 2 | 5 | 6 | 3 | 7 | 6 | 4 | 8 | 7 | 9 | 5 | 8 | 10 | 9 | 11 | 3 |
| x | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| s = a | 16 000 | 16 001 | 16 010 | 16 011 | 16 100 | 16 101 | 16 110 | 16 111 | 31 000 | 31 001 | 31 010 | 31 011 | 31 100 | 31 101 | 31 110 | 31 111 |
| s = b | 22 00 | 22 01 | 22 10 | 22 11 | 26 00 | 26 01 | 26 10 | 26 11 | 19 000 | 19 001 | 19 010 | 19 010 | 19 100 | 19 101 | 19 110 | 19 111 |
| s = c | 27 0 | 27 1 | 29 0 | 29 1 | 17 00 | 17 01 | 17 10 | 17 11 | 21 00 | 21 01 | 21 10 | 21 11 | 24 00 | 24 01 | 24 10 | 24 10 |
| s = d | 23 0 | 23 1 | 25 0 | 25 1 | 28 0 | 28 1 | 30 0 | 30 1 | 18 00 | 18 01 | 18 10 | 18 11 | 20 00 | 20 01 | 20 10 | 20 11 |
| x′ (Current State) | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| s (generated symbol) | a | c | d | b | d | c | b | d | c | d | b | c | d | c | d | a |
| K (# of bits extracted from the bitstream variable) | 3 | 2 | 2 | 3 | 2 | 2 | 2 | 1 | 2 | 1 | 2 | 1 | 1 | 1 | 1 | 3 |
| X (next state) + y | 16 +y | 20 +y | 24 +y | 24 +y | 28 +y | 24 +y | 16 +y | 16 +y | 28 +y | 18 +y | 20 +y | 16 +y | 20 +y | 18 +y | 22 +y | 24 +y |


References
- Duda, J. Asymmetric numeral systems. arXiv 2009, arXiv:0902.0271. [Google Scholar]
- Duda, J. Asymmetric numeral systems: Entropy coding combining speed of Huffman coding with compression rate of arithmetic coding. arXiv 2014, arXiv:1311.2540v2. [Google Scholar]
- Duda, J.; Tahboub, K.; Gadgil, N.J.; Delp, E.J. The use of asymmetric numeral systems as an accurate replacement for Huffman coding. In Proceedings of the Picture Coding Symposium, Cairns, Australia, May 2015; pp. 65–69. [Google Scholar]
- GitHub: Zstandard—Fast Real-Time Compression Algorithm. Available online: https://github.com/facebook/zst (accessed on 30 January 2022).
- GitHub: LZFSE Compression Library and Command Line Tool. Available online: https://github.com/lzfse/lzfse (accessed on 30 January 2022).
- GitHub: Google/Pik: A New Lossy/Lossless Image Format for Photos and the Internet. Available online: https://github.com/google/pik (accessed on 30 January 2022).
- Gladding, D.E.; Gopalakrishnan, S.; Shaileshkumar, D.K.; Lin, H.-K. Features of Range Asymmetric Number System Encoding and Decoding, JUSTIA Patents: Publication Number: 20200413106. Available online: https://patents.justia.com/search?q=Asymmetric+number+system+coding (accessed on 30 January 2022).
- Wikipedia: JPEG XL. Available online: https://en.wikipedia.org/wiki/JPEG_XL (accessed on 30 January 2022).
- Wikipedia: Avalanche Effect. Available online: https://en.wikipedia.org/wiki/Avalanche_effect (accessed on 30 January 2022).
- Goodwin, J. What Is an NFT? Non-Fungible Tokens Explained, CNN Business. Updated 2003 GMT (0403), 10 November 2021. Available online: https://edition.cnn.com/2021/03/17/business/what-is-nft-meaning-fe-series/index.html (accessed on 30 January 2022).
- Wikipedia: Asymmetric Numeral Systems. Available online: https://en.wikipedia.org/wiki/Asymmetric_numeral_systems (accessed on 30 January 2022).
- Moffat, A. Huffman Coding. ACM Comput. Surv. 2019, 52, 1–35. [Google Scholar] [CrossRef]
- Razaq, U.; Lizhong, X.; Li, C.; Usman, M. Evolution and Advancement of Arithmetic Coding over Four Decades. Open J. Sci. Technol. 2020, 3, 194–236. [Google Scholar]
- Witten, I.H.; Neal, R.; Cleary, J. Arithmetic coding for data compression. Commun. ACM 1987, 30, 520–540. [Google Scholar] [CrossRef]
- Belyaev, E.; Liu, K.; Gabbouj, M.; Li, Y. An efficient adaptive binary range coder and its VLSI architecture. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1435–1446. [Google Scholar] [CrossRef]
- Belyaev, E.; Forchhammer, S.; Liu, K. An Adaptive Multialphabet Arithmetic Coding Based on Generalized Virtual Sliding Window. IEEE Signal Processing Lett. 2017, 24, 1034–1038. [Google Scholar] [CrossRef]
- Giesen, F. Interleaved entropy coders. arXiv 2014, arXiv:1402. 3392v1. [Google Scholar]
- Najmabadi, S.M.; Wang, Z.; Baroud, Y.; Simon, S. High Throughput Hardware Architectures for Asymmetric Numeral Systems Entropy Coding. In Proceedings of the 9th International Symposium on Image and Signal Processing and Analysis (ISPA), Zagreb, Croatia, 7–9 September 2015; pp. 256–259. [Google Scholar] [CrossRef]
- Duda, J.; Niemiec, M. Lightweight compression with encryption based on asymmetric numeral systems. arXiv 2016, arXiv:1612.04662. [Google Scholar]
- Yokoo, H. On the stationary distribution of asymmetric binary systems. In Proceedings of the International Symposium on Information Theory, Barcelona, Spain, 10–15 July 2016; pp. 11–15. [Google Scholar]
- Yokoo, H. On the stationary distribution of asymmetric numeral systems. In Proceedings of the International Symposium on Information Theory and its Applications, Monterey, CA, USA, 30 October 2016; pp. 631–635. [Google Scholar]
- Moffat, A.; Petri, M. ANS-based index compression. In Proceedings of the International Conference on Information and Knowledge Management, Singapore, 6–11 November 2017; pp. 677–686. [Google Scholar]
- Moffat, A.; Petri, M. Index compression using byte-aligned ANS coding and two- dimensional contexts. In Proceedings of the International Conference on Web Search and Data Mining, Marina del Rey, CA, USA, 5–9 February 2018; pp. 405–413. [Google Scholar]
- Yokoo, H.; Shimizu, T. Probability approximation in asymmetric numeral systems. In Proceedings of the International Symposium on Information Theory and Its Applications, Singapore, 28–31 October 2018; pp. 670–674. [Google Scholar]
- Fujisaki, H. Invariant measures for the subshifts associated with the asymmetric binary systems. In Proceedings of the International Symposium on Information Theory and Its Applications (ISITA), Singapore, 28–31 October 2018; pp. 675–679. [Google Scholar]
- Dubé, D.; Yokoo, H. Empirical evaluation of the effect of the symbol distribution on the performance of ANS. In Proceedings of the Poster Presented at the SITA Symposium, Iwaki, Fukushima, Japan, 18–21 December 2018. [Google Scholar]
- Dubé, D.; Yokoo, H. Fast Construction of Almost Optimal Symbol Distributions for Asymmetric Numeral Systems. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019. [Google Scholar]
- Townsend, J.; Bird, T.; Barber, D. Practical Lossless Compression with Latent Variables Using Bits Back Coding ICLR. arXiv 2019, arXiv:1901.04866. [Google Scholar]
- Kingma, F.; Abbeel, P.; Ho, J. Bit-Swap: Recursive Bits-Back Coding for Lossless Compression with Hierarchical Latent Variables. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 3408–3417. [Google Scholar]
- Fujisaki, H. On irreducibility of the stream version of the asymmetric binary systems. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2020, 103, 757–768. [Google Scholar] [CrossRef]
- Najmabadi, S.M.; Tran, T.-H.; Eissa, S.; Tungal, H.S.; Simon, S. An architecture for asymmetric numeral systems entropy decoder—A comparison with a canonical Huffman decoder. J. Signal Processing Syst. 2019, 91, 805–817. [Google Scholar] [CrossRef]
- Moffat, A.; Petri, M. Large-Alphabet Semi-Static Entropy Coding Via Asymmetric Numeral Systems. ACM Trans. Inf. Syst. 2020, 1, 1–33. [Google Scholar] [CrossRef]
- Wang, N.; Wang, C.; Lin, S.-J. A simplified variant of tabled asymmetric numeral systems with a smaller look-up table. Distrib. Parallel Database 2021, 39, 711–732. [Google Scholar] [CrossRef]
- Camtepe, S.; Duda, J.; Mahboubi, A.; Morawiecki, P.; Nepal, S.; Pawlowski, M.; Pieprzyk, J. Compcrypt—Lightweight ANS-based Compression and Encryption. IEEE Trans. Inf. Forensics Secur. 2021, 16, 3859–3873. [Google Scholar] [CrossRef]
- Lossless Compression with Asymmetric Numeral Systems, Posted by by Brian Keng (2020/9/26). Available online: https://bjlkeng.github.io/posts/lossless-compression-with-asymmetric-numeral-systems/ (accessed on 30 January 2022).
- Culpepper, J.S.; Moffat, A. Enhanced byte codes with restricted prefix properties. In International Symposium on String Processing and Information Retrieval; Buenos Aires Argentina, November 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1–12. [Google Scholar]
- Hinton, G.; van Camp, D. Keeping neural networks simple by minimizing the description length of the weights. In Proceedings of the Sixth Annual Conference on Computational Learning Theory (COLT), Santa Cruz, CA, USA, 26–28 July 1993; pp. 5–13. [Google Scholar]
- FiniteStateEntropy Algorithm. Available online: https://github.com/Cyan4973/FiniteStateEntropy (accessed on 30 January 2022).
- Caldelli, R.; Filippini, F.; Becarelli, R. Reversible Watermarking Techniques: An Overview and a Classification. EURASIP J. Inf. Secur. 2010, 2010, 134546. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.Y.; Wu, J.L. Two-Bit Embedding Histogram-Prediction-Error Based Reversible Data Hiding for Medical Images with Smooth Area. Computers 2021, 10, 152. [Google Scholar] [CrossRef]
- LZMA Algorithm from Python Usage. Available online: https://docs.python.org/3/library/lzma.html (accessed on 30 January 2022).
- LZMA Algorithm from Wikipedia. Available online: https://en.wikipedia.org/wiki/Lempel%E2%80%93Ziv%E2%80%93Markov_chain_algorithm (accessed on 30 January 2022).
- Zlib Algorithm from Python Usage. Available online: https://docs.python.org/3/library/zlib.html (accessed on 30 January 2022).
- Zlib Algorithm from Wikipedia. Available online: https://en.wikipedia.org/wiki/Zlib (accessed on 30 January 2022).
- Gzip Algorithm from Python Usage. Available online: https://docs.python.org/3/library/gzip.html (accessed on 30 January 2022).
- Gzip Algorithm from Wikipedia. Available online: https://en.wikipedia.org/wiki/Gzip (accessed on 30 January 2022).
- Bzip2 Algorithm from Python Usage. Available online: https://docs.python.org/3/library/bz2.html (accessed on 30 January 2022).
- Bzip2 Algorithm from Wikipedia. Available online: https://en.wikipedia.org/wiki/Bzip2 (accessed on 30 January 2022).
- Zstd Algorithm from Python Usage. Available online: https://pypi.org/project/zstd/ (accessed on 30 January 2022).
- Zstd Algorithm from Wikipedia. Available online: https://en.wikipedia.org/wiki/Zstd (accessed on 30 January 2022).
- Liblzfse Algorithm from Python Usage. Available online: https://github.com/ydkhatri/pyliblzfse (accessed on 30 January 2022).
- Liblzfse Algorithm from Wikipedia. Available online: https://en.wikipedia.org/wiki/LZFSE (accessed on 30 January 2022).
- rANS Algorithm. Available online: https://github.com/rygorous/ryg_rans (accessed on 30 January 2022).
- Test Images for Experiment. Available online: https://sipi.usc.edu/database/database.php?volume=misc&image=28#top (accessed on 30 January 2022).


















| x′ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x | s = 0 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | |||||||
| x | s = 1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| x′ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x | s = 0 | 0 | 1 | 2 | ||||||||
| x | s = 1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| x′ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x | s = a | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | |||||||||
| x | s = b | 0 | 1 | 2 | 3 | 4 | 5 | ||||||||||||||||||
| x | s = c | 0 | 1 | 2 |

| x′ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x | s = a | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||||||
| x | s = b | 0 | 1 | 2 | 3 | ||||||||||||
| x | s = c | 0 | 1 |

| x = L | x = L + 1 | … | x = 2L − 1 | ||
|---|---|---|---|---|---|
| s | |||||
| … | |||||
| si | next state = ; bit sequence = | ||||
| … | |||||
| sn | |||||
| x′ (Current State) | L | L + 1 | … | 2L − 1 |
|---|---|---|---|---|
| s (generated symbol) | ||||
| K (# of bits extracted from the bitstream Variable) | ||||
| X (next state) |
| Picture | All Black | Lattice | Lena | Fruits | Baboon | Airplane | Chest | |
|---|---|---|---|---|---|---|---|---|
| Algorithm | ||||||||
| Arithmetic-code | 0.00131 | 0.22174 | 0.97008 | 0.96003 | 0.97161 | 0.83429 | 0.79038 | |
| Huffman-code | 0.12533 | 0.24435 | 0.97291 | 0.96212 | 0.97544 | 0.83673 | 0.79266 | |
| rANS | 4 × 10−5 | 0.047 | 0.90697 | 0.95826 | 0.98997 | 0.71251 | 0.31487 | |
| tANS_FSE | 7 × 10−5 | 0.2058 | 0.93765 | 0.94194 | 0.95575 | 0.81241 | 0.72081 | |
| tANS_zstd | 5 × 10−5 | 0.00238 | 0.87594 | 0.90971 | 0.96825 | 0.70071 | 0.14375 | |
| tANS_liblzfse | 0.00077 | 0.00576 | 0.91833 | 0.93128 | 0.96233 | 0.74537 | 0.18732 | |
| lzma | 0.00031 | 0.00214 | 0.75684 | 0.80398 | 0.86879 | 0.63955 | 0.12609 | |
| zlib | 0.001 | 0.0132 | 0.89948 | 0.92114 | 0.94867 | 0.75443 | 0.18086 | |
| gzip | 0.00101 | 0.00967 | 0.89949 | 0.92116 | 0.94869 | 0.75447 | 0.17982 | |
| bz2 | 6 × 10−5 | 0.00216 | 0.73081 | 0.80389 | 0.91668 | 0.59302 | 0.1007 | |
| Picture | All Black | Lattice | Lena | Fruits | Baboon | Airplane | Chest | |
|---|---|---|---|---|---|---|---|---|
| Algorithm | ||||||||
| Arithmetic-code | 0.00543 | 0.00416 | 0.00395 | 0.00485 | 0.00646 | 0.00515 | 0.0057 | |
| Huffman-code | 0.00249 | 0.0022 | 0.00206 | 0.00263 | 0.00247 | 0.00267 | 0.00263 | |
| rANS | 0.00183 | 0.00223 | 0.00178 | 0.002 | 0.00233 | 0.00196 | 0.00228 | |
| tANS_FSE | 0.00241 | 0.00212 | 0.00189 | 0.00219 | 0.0018 | 0.00188 | 0.0017 | |
| tANS_zstd | 0.01235 | 0.11686 | 0.11693 | 0.12242 | 0.10236 | 0.18194 | 1.84513 | |
| tANS_liblzfse | 0.00887 | 0.0187 | 0.01367 | 0.01394 | 0.01223 | 0.01776 | 0.07471 | |
| lzma | 0.03119 | 0.15142 | 0.19254 | 0.19741 | 0.18212 | 0.20994 | 2.00818 | |
| zlib | 0.00372 | 0.01307 | 0.02393 | 0.02478 | 0.02246 | 0.02851 | 0.15271 | |
| gzip | 0.00449 | 0.0497 | 0.024 | 0.02522 | 0.02261 | 0.02967 | 0.2924 | |
| bz2 | 0.00866 | 0.07017 | 0.06489 | 0.07004 | 0.07578 | 0.06919 | 0.19868 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsieh, P.A.; Wu, J.-L. A Review of the Asymmetric Numeral System and Its Applications to Digital Images. Entropy 2022, 24, 375. https://doi.org/10.3390/e24030375
Hsieh PA, Wu J-L. A Review of the Asymmetric Numeral System and Its Applications to Digital Images. Entropy. 2022; 24(3):375. https://doi.org/10.3390/e24030375
Chicago/Turabian StyleHsieh, Ping Ang, and Ja-Ling Wu. 2022. "A Review of the Asymmetric Numeral System and Its Applications to Digital Images" Entropy 24, no. 3: 375. https://doi.org/10.3390/e24030375