1. Introduction
Stock exchanges provide an organized platform for traders to exchange securities, which is known as the limit order book. Traders use orders as a tool to indicate their willingness to buy or sell an instrument in the market. Generally, orders are one of two types: bid (indicating willingness to buy) and ask (indicating willingness to sell). Each order can further be classified as one of two main categories: limit and market. A limit order is an agreement to buy (or sell) a given number of shares of a particular stock at a given price (or better). This type of order is usually not fulfilled immediately and is instead listed in the limit order book while waiting for a match. In contrast, market orders are orders to buy or sell at the best currently available price in the limit order book. Since these orders have no price restrictions, market orders are typically fulfilled instantaneously.
Every order is recorded in the limit order book, and when a match between a buyer and a seller occurs, the exchange executes an exchange of securities—a trade—and the corresponding orders are removed from the book. At any point in time, there may be outstanding orders to buy or sell a certain amount of a security at different price points. These price points can be thought of as the layers of the order book. Overall, the time evolution of the limit order book encapsulates an enormous amount of information, which includes all of the financial actions of all traders, including both fulfilled and unfulfilled orders.
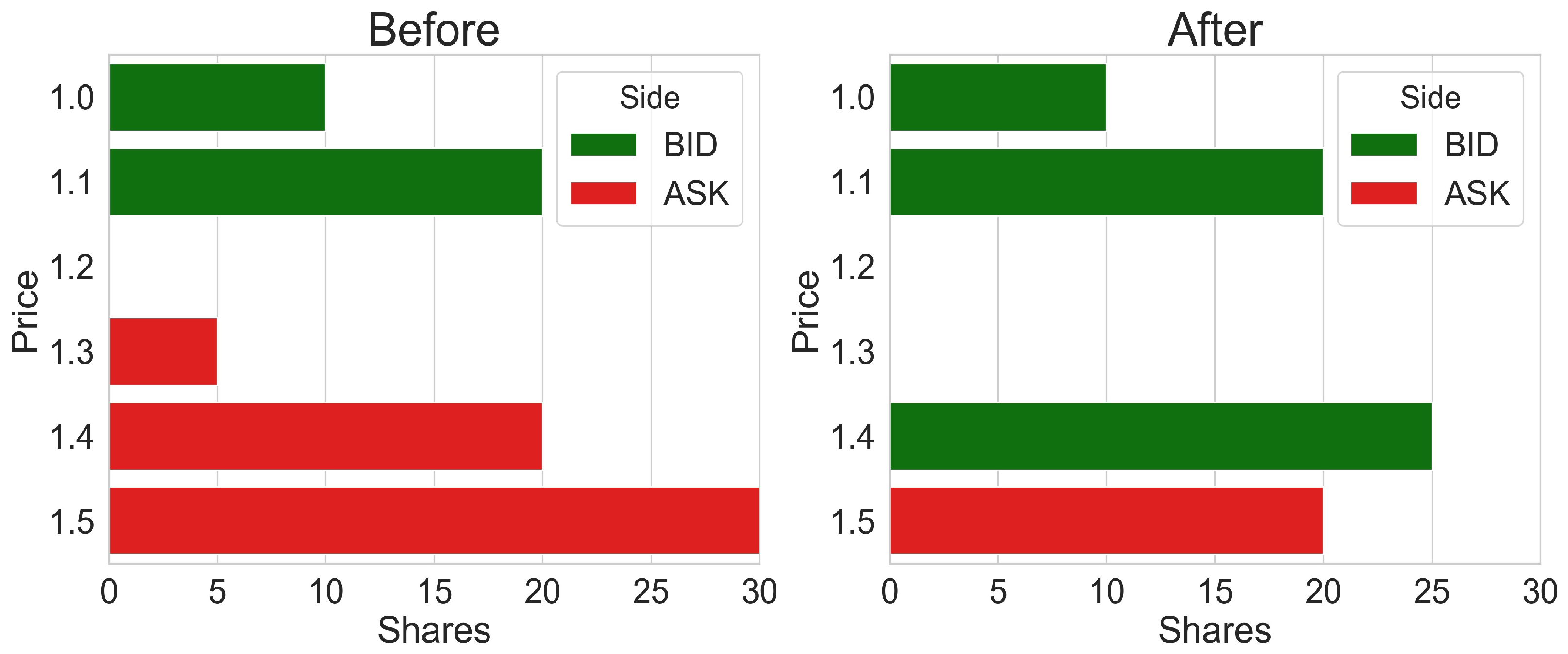
The highest price at which buyers are willing to buy a security and the lowest price at which sellers are willing to sell a security collectively comprise the “bid–ask” layers, which are the uppermost layers and represent the current market price of a security. Additional layers are price points that are further away from the bid–ask. Each layer consists of a price and volume. The bid–ask layers change continuously throughout the day based on supply and demand, resulting in shifts in the security’s market price. For instance, a flow of buy orders can exhaust the volume available in the uppermost ask layer. This would uncover the next available layer on the ask side, making this layer the new ask market layer and thereby raising the stock price. Thus, the limit order book contains hidden data that may become visible throughout the trading day (see
Figure 1 for an example).
The ability of a market to sustain a large order while avoiding a significant change in price is called the market depth, and it is considered a proxy for the liquidity of the market. Deep markets enjoy a large number and volume of orders waiting for execution in the different layers. Conceptually, market depth summarizes the state of the different layers of the limit order book and thus may act as one mechanism for the information leak we have discovered between the layers.
Some of the orders populating the deeper layers have a specific nature. Stop losses are limit orders placed far from the bid–ask layer and in the opposite direction of the trader’s belief of price change. Larger orders may be put relatively deep to soothe their influence on the price. Slower traders sometimes use a limit order on the medium-distanced layers to mitigate their inability to control for short-term variance in price. In all of these cases, traders express their expectations for the price in the deeper layers. Our results coincide with this view of shared information between layers, increasing with depth.
In addition to and rising from their primary role as a trading platform, stock exchanges serve multiple additional functions. One of these involves price determination, e.g., the market pricing of a certain security at a given time. For example, Alan and Schwartz [
1] studied the impact of exchange factors, such as trading volatility, on stock price discovery. Sirignano and Cont [
2] showed that the price movements of a given security can be predicted from the price history and order flow of other securities, suggesting that the exchanges have a role in price formation.
The layers of the limit order book that are further away from the market price play a role in price determination. Information recorded in the deeper layers of the order book, beyond the market bid–ask layers, has been typically hidden from most traders and reserved for specific groups or types of traders, which are generally more sophisticated or experienced. However, as stock exchanges around the world have shifted to an electronic format, sharing the data from the deeper layers became more practical. This introduced a debate about the value of the information contained in the deeper layers. The debate is still the subject of active research. For example, Harris [
3] suggests that specialists leverage information from the deeper layers when placing trades. Bloomfield [
4] finds that the number of limit orders increases when traders have access to information about the deeper layers. In addition, Madhavan [
5] discovered that traders at the Toronto Stock Exchange placed fewer orders after the top four layers became visible to all traders.
These studies have focused mostly on the stock market. However, studies of the FX market paint a different picture. For example, Kozhan and Salmon [
6] showed that in the Dollar Sterling market, although variables such as depth, spread, and order flow can explain returns, incorporating these data into trading strategies does not yield profits that are statistically significant from those obtained in trading without this information on hand. Meanwhile, Gençay and Gradojevic [
7] show that up to
of the variation in the FX market can be explained by private trader information, implying that information in the order book indeed has limited utility in this market. Gradojevic et al. [
8] show that although the limit order book can be useful in the FX market, its efficacy can quickly disappear for arbitrage traders in a highly volatile market. The authors contend that in such scenarios, arbitrage traders are likely to be more successful by using liquidity measures. Kozhan and Tham [
9] also research arbitrage traders and found that factors such as the number of market participants as well as speed have a substantial impact on execution risk, including resulting profits and/or loss from trades. Thus, different aspects of the market may come into play for different trading scenarios.
The debate surrounding the information content of the limit order book is associated with a practical one, namely, how many layers of the limit order book should be exposed to traders by the exchanges. “Information” here means anything that affects the distribution of the measured quantity. Different agents in the market may have an interest in different segments of the information content of the limit order book. Since the bid–ask layers play a major role in determining future prices, this information is relevant for all traders. Anyone who wishes to execute large orders should take the deeper layers into account; hence, the information in these layers is of particular importance for a large volume of players.
Research on the deeper layers of the limit order book generally suggests that the deeper layers include some information. For instance, Libman et al. [
10] showed that compared to the uppermost bid–ask layers, using information from the deeper layers improves accuracy in predicting the log quoted depth, which is a measure of liquidity. Cao [
11] concluded that data from the deeper layers promotes price discovery, while Baruch [
12] claims that the NYSE’s open limit order book benefits traders.
In this paper, we address a more basic question—how much new information is contained in the deep layers, if at all? We decided to look at this question in the context of smaller exchanges. For this paper, we worked with the Tel Aviv Stock Exchange (TASE). Generally, the limit order book in small exchanges repopulates slowly (e.g., the order book has low resilience), which underscores the importance of studying the layer depth.
Rather than measuring the efficacy of the deep layers in forecasting of particular trading measures, we examine the mutual information (MI) between the layers. Entropy and MI have been previously applied in financial data, as described in the a review by Zhou et al. [
13]. Specifically, Cai et al. [
14] and Almog and Shmueli [
15] use entropy to study the effect of auto-correlations in stock and FOREX time-series. Avellaneda [
16] and Avellaneda et al. [
17] used minimum relative entropy to fine-tune pricing models. Sakalauskas and Kriksciuniene [
18] combined Shannon’s entropy with Hurst exponents to forecast changes in stock price trends, while Kim et al. [
19] combined effective transfer entropy with machine learning models to forecast changes in the direction of stock prices. In Dionisio et al. [
20] and Darbellay and Wuertz [
21], MI is applied to stock market indexes. Two papers specifically studied the MI between securities traded on the NYSE (Fiedor [
22]) and Shanghai Stock Exchange (Guo et al. [
23]). Both works found that the MI method yields different results compared to correlation coefficients. These findings suggest the existence of nonlinear relationships in financial markets.
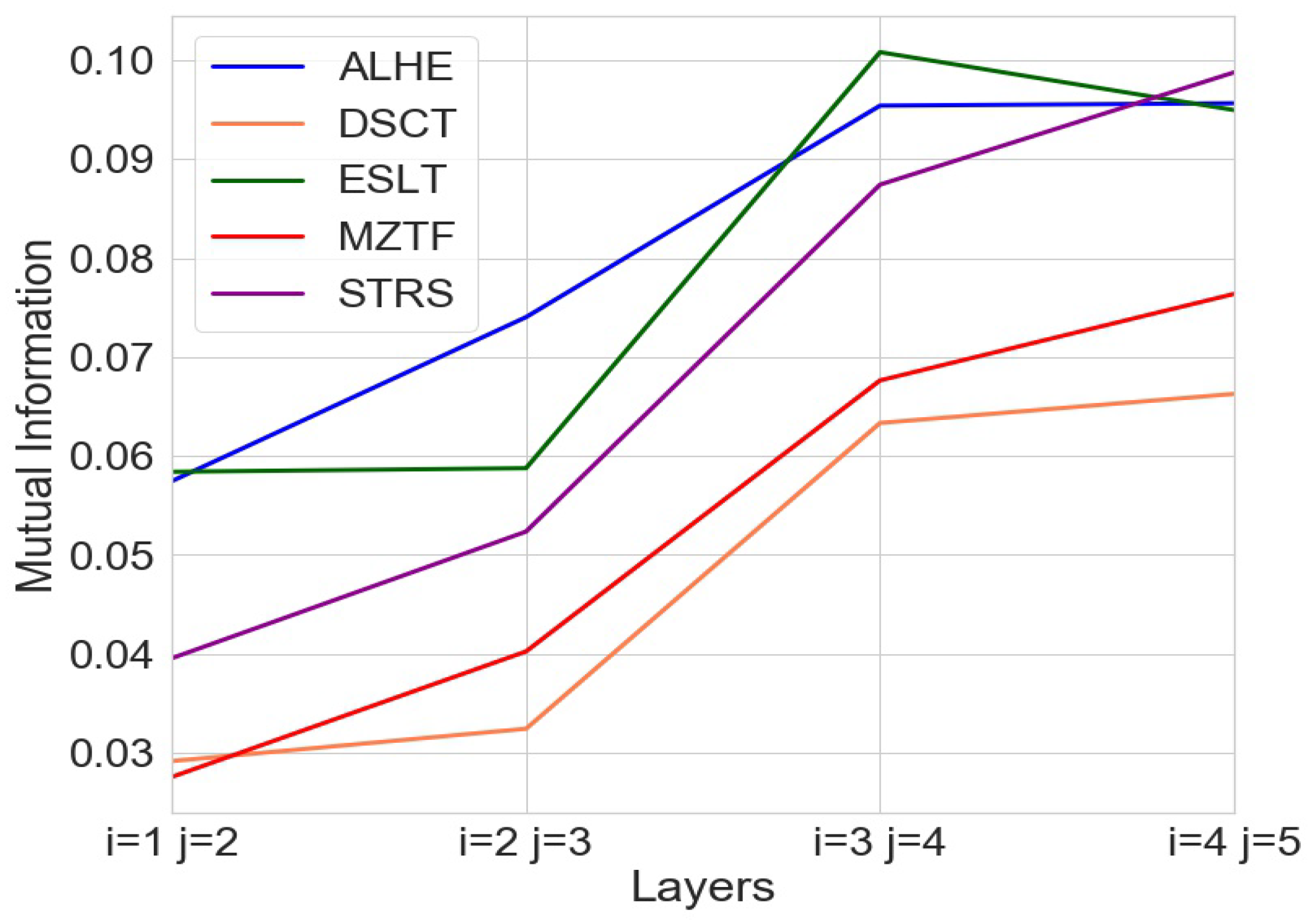
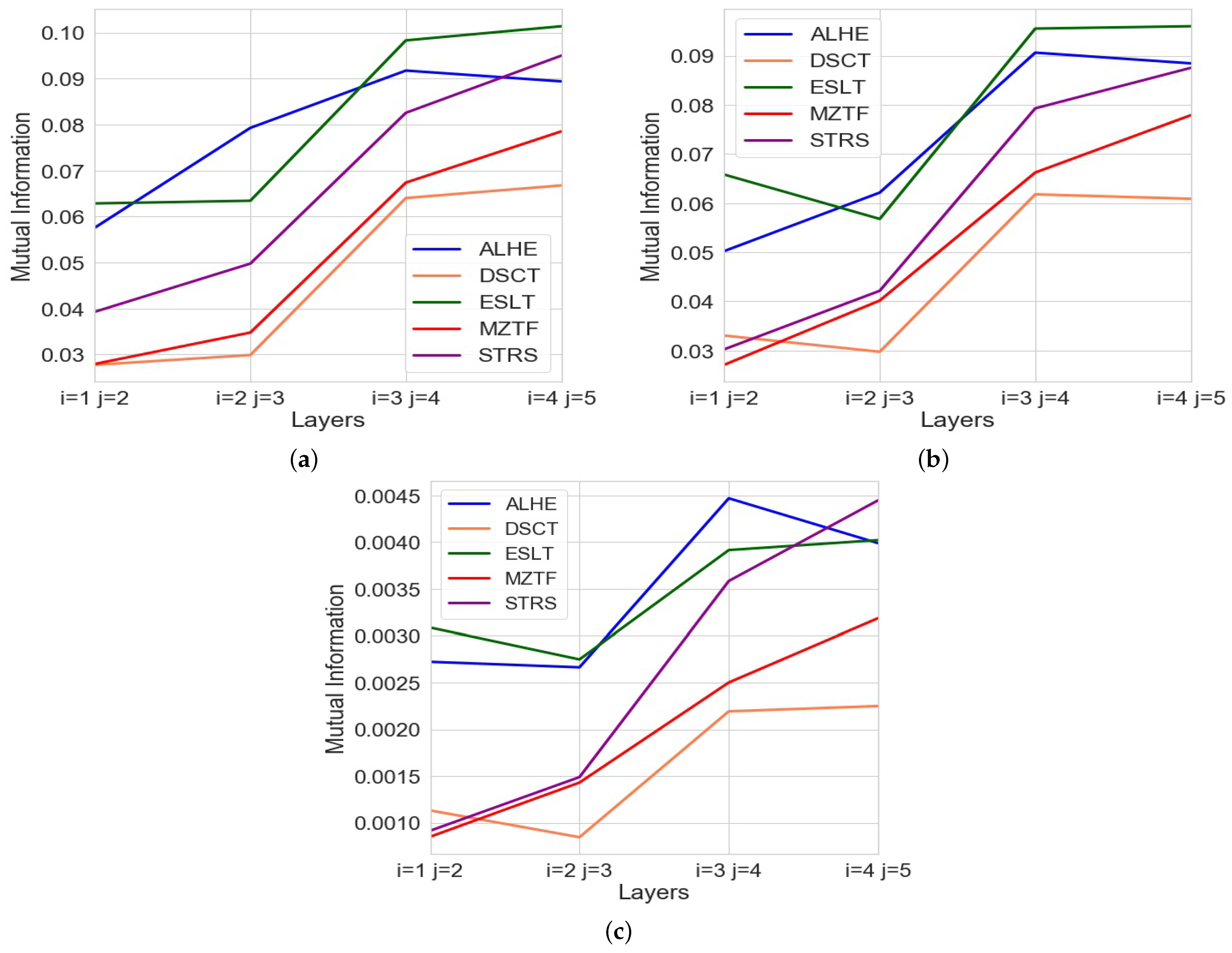
To the best of our knowledge, the current study is one of the early papers that addresses the information content in the limit order book. Our results indicate that the amount of MI increases with layer depth, and therefore, deeper layers have a higher degree of similarity to each other. This implies that the amount of new information offered by each layer decreases as depth increases; e.g., as we descend deeper into the order book, each layer reveals less new information than the one preceding it. Our findings suggest that not all of the deeper layers might be equally of interest to traders.
2. Methodology
Our contribution involves calculating the entropy between the order book layers. To accomplish this, we used the trading data of thirty-five securities traded on the Tel Aviv Stock Exchange (TASE) in 2017. To make our analysis practical, we were compelled to select stocks that had sufficient trading activity and thus resembled stocks in larger exchanges. For this reason, we focused our analysis on stocks featured in the TA-35, which represents the 35 most actively traded stocks with the highest market capitalization on the Tel Aviv Stock Exchange. For clarity, we show the full analysis for five of these stocks, aiming to select a variety of industries, ranging from technology to banking, real estate, and consumer products. Then, we list the summarized results for all thirty-five stocks in the index.
The trading activity dataset, which was provided directly by TASE, was comprised of one text file for all order submissions (including cancelled orders) and another text file for executed transactions. The files were separated by security and date.
Table 1 shows several summary statistics for each of the five securities.
Each of the stocks had a minimum price increment, or interval, defined by the TASE. This meant that orders could only be placed at specific price points. For instance, if the increment was 0.10 Israeli Shekels (ILS) and the market price was 7.50, the next price layer would be at 7.40 from the bid side or 7.60 from the ask side. Thus, since the prices were subject to constraints by the exchange, the price variable on both the bid and ask side would always originate from a finite set. For our calculations, we used the number of increments from the uppermost layer, e.g., best bid–ask, rather than the nominal price point itself. This provided additional uniformity in the price. These characteristics of the price allowed us to regard the price as a discrete variable.
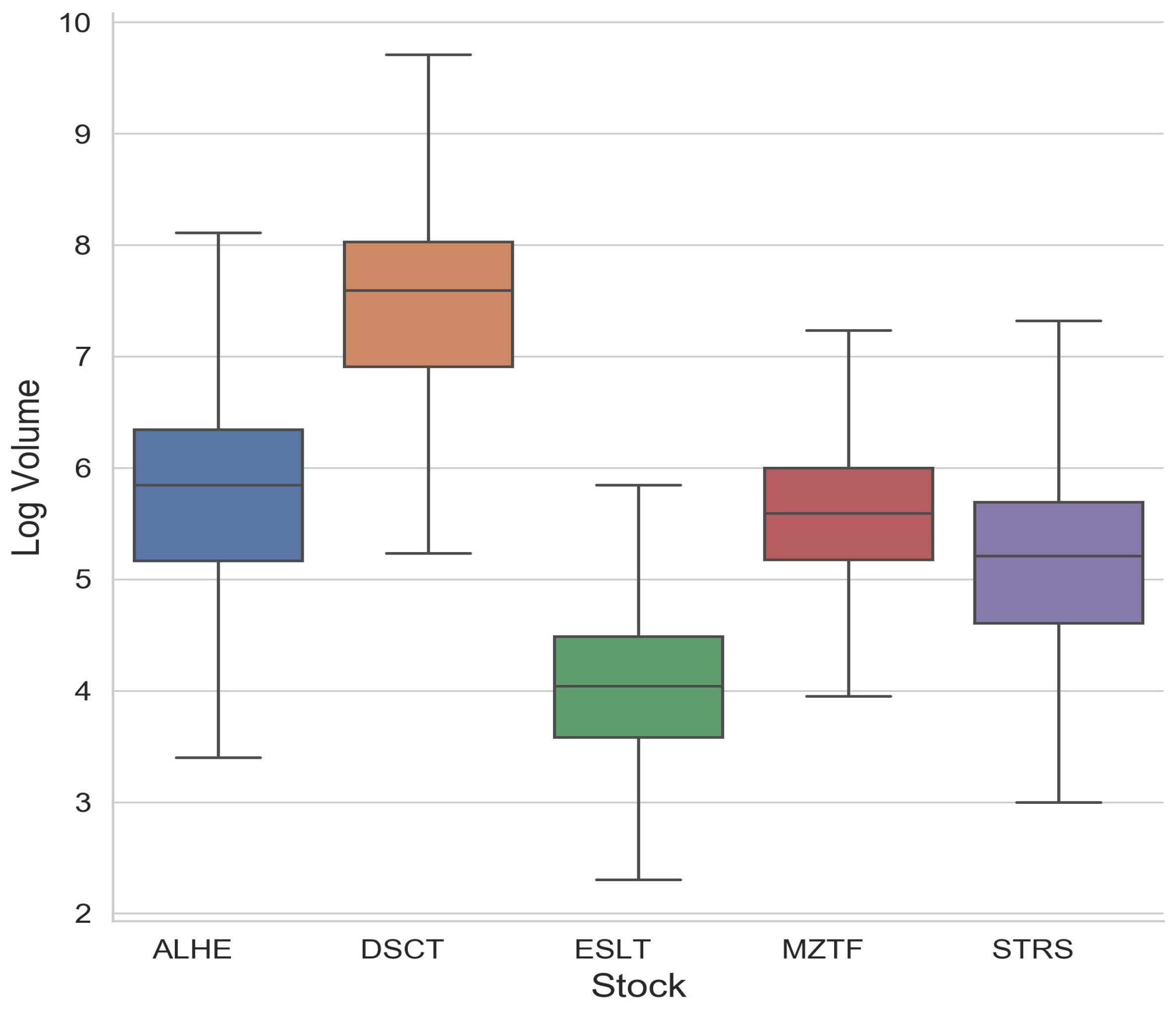
The volume data behaved far differently than the price. Since there were few restrictions on the volume of orders, the volume could change freely between the layers, and indeed, the volume data included a wide variety of different values. For this reason, we regarded the volume as a continuous variable. In order to be certain that the volume resembled a continuous distribution, we added some random noise uniformly distributed between zero and one to the log volume dataset. To validate that the noise did not contribute to the results, we also ran the same analysis using a different noise that was normally distributed and had a standard deviation of one. This ensured that no two values were exactly the same, while the data integrity remained intact. For our calculations, we used the natural log of the volume. This helped normalize the dataset and is supported by the fact that orders placed in the financial markets generally follow a power law. See, for example, Zovko and Farmer [
24]. The statistics of the log volume of the orders for each security can be seen in
Figure 2.
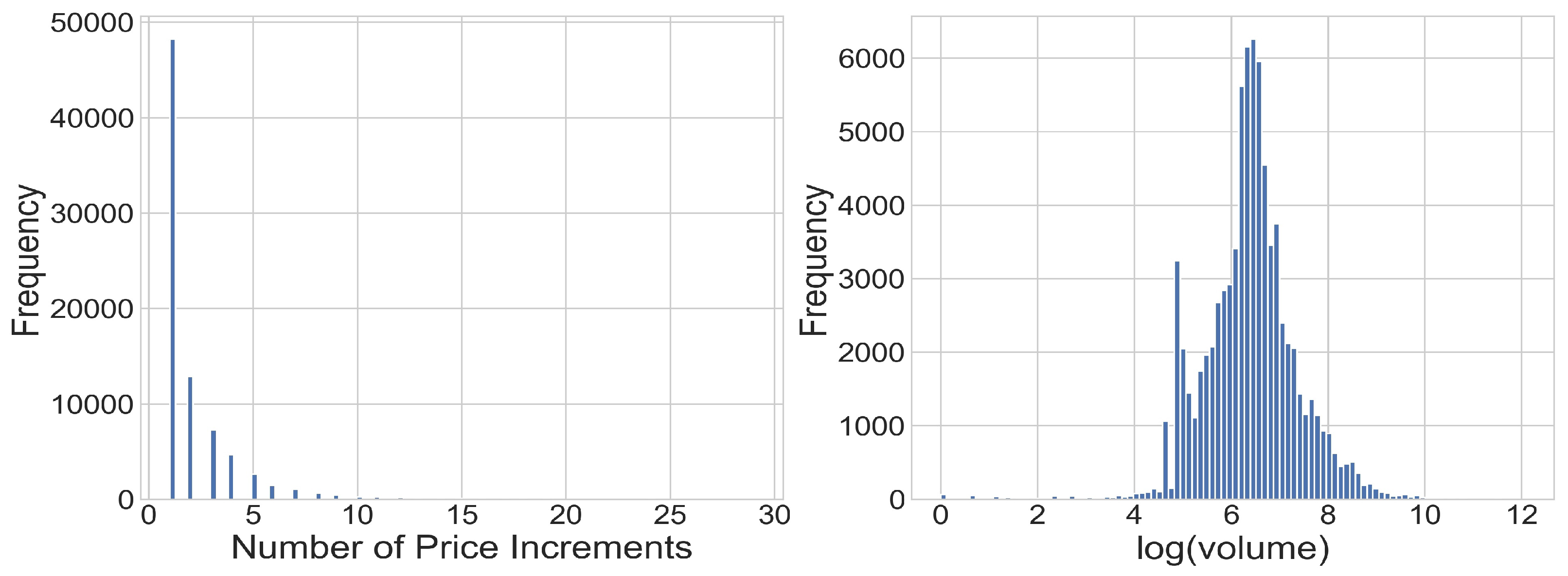
Figure 3 shows a histogram of price differences between the layers and the log volume.
The information from the TASE orders was used to recreate the dynamics of the limit order book, classifying each incoming order to the bid or ask side, while keeping a record of the previous orders and executing a transaction whenever a match occurred. As a benchmark, we compared the trading output from our simulation to the actual transaction records and verified the two were identical. Next, we proceeded to capture the order book layers’ status after every transaction. Since accounting for factors such as intraday seasonality and day-of-the-week effects would have meant splitting the data into smaller batches which would have rendered the high-dimensional entropy estimation inaccurate in our case, we opted to run the analysis on data pooled from all times of day and week.
These snapshots were created for the bid and ask sides separately, yielding a snapshot of the order book sorted by price points, or layers. In order to validate the consistency of the observed patterns, results were compared to a diluted time series in which every other snapshot (or two out of three) were discarded. No qualitative differences were observed.
A major challenge in measuring the entropy of the order book layers was the fact that each layer of the book is described by side (e.g., bid or ask), volume, and price. Since our data are comprised of discrete and continuous variables (e.g., price and volume, respectively), we split the dataset based on the different values of the discrete random variable and used the conditional entropy to sum the entropies.
We can describe a snapshot of the order book by setting G={bid,ask} and . Using this formulation, we can define and as the log(volume) and price difference, respectively, for layer k after transaction t. Thus, the log(volume) for the bid side in the first layer after the first transaction can be represented as . Similarly, the price difference for the ask side on the second layer after the third transaction of the day can be represented as .
The full snapshot of the first five layers of the book after transaction
n can be represented using a vector in
as follows:
The mutual information between two order book layers
i and
j can be separated into three contributions using the entropy of the layers as follows:
Each of these components, e.g.,
,
, and
, can be represented as a conditional entropy that is conditioned on the price, which is discrete in nature. Thus, calculating
can be completed by defining
and
as follows (note that different
Y values correspond to different
X values):
Calculating the difference in price entropy
was accomplished using the method proposed by Valiant and Valiant [
25], who provide a method for estimating discrete entropy when some parts of the distribution are rare and therefore undersampled, which is a phenomenon we encountered in the price data. Indeed, this method was a good fit for our case, since our analysis showed that differences in prices tend to have some rare outliers that are difficult to measure.
Evaluating
is also non-trivial. While the probability of
X to be a certain value can be easily estimated by counting the occurrences divided by the length of the dataset, it is not practical to measure
for all values of
X. Doing so would have generated some filters with very limited data counts that are insufficient for reliable estimation of the entropy for the continuous part. Instead, we split the the data into three equal-size groups based on the
X values. This was achieved by estimating the cumulative distribution function of
X and splitting three intervals
such that for
. The results for each of the different groups is detailed in
Appendix A,
Table A1.
Calculating
, which is the entropy for a multi-dimensional continuous random variable comprised of the log volume data after filtering to
, can be done using the recursive method described by Ariel and Louzoun in [
26].
The general idea underlying the algorithm in [
26] is to apply the Sklar’s theorem, which states that any continuous distribution
can be decomposed as
where
are the marginal distributions of
,
are the commutative distribution functions, and
is the joint density, which is called the copula. Substituting
into the definition of the continuous entropy yields,
where
is the one-dimensional entropy of the marginal distributions, which is straightforward to calculate using one of the numerical estimation methods described in Berilant et al. [
27].
Estimating
, the copula entropy, is more complex. For this, Ariel and Louzoun [
26] proposed a recursive method that involves splitting the length of the dimensions into statistically independent blocks. Then, for each of these blocks, the method involves performing a change of variables similar to an integral transformation, which uses the actual data to transform each of the points over each dimension to its empirical CDF value. This value can be defined as
. Then, the transformed dataset is split into two groups along the median of one of the dimensions. Next, the recursive part reruns the entropy estimation of each one of the two subsets. This continues recursively and essentially converts the original problem into a series of summations on one-dimensional entropies. The Python code we have used is provided in [
28] as open source under GPL.
Ariel and Louzon [
26] showed that unlike other algorithms, where performance might differ among distributions, their method is fairly accurate for a wide family of distributions. Other advantages of the method included a relatively low complexity and ability to converge fast at the order
where
N is the sample size.
For each one of our experiments, we rejected the hypothesis that the mutual information equals zero. This was accomplished by computing
, which is the mutual information after creating a random permutation of the data in layer
j. We repeated this experiment 1000 times for each of the layers under examination and calculated the ratio of times for which we obtained a higher value,
. This numerical
p-value indicates the probability of achieving at least the number we obtained in a random setting. The mutual information obtained in the shuffled data was far lower and the pattern seen with the real data was not visible. The results are given in
Appendix A,
Table A1.
Checking for the significance of the increase in the mutual information between the upper layers of the book and the deeper ones was done using a Student’s t-test for the mean of paired samples, where we checked the hypothesis that there was an increase in the mean of the MI when comparing the two uppermost layers to the two deepest layers, e.g., the mean of the MI of the two deepest layers is higher.
To verify the stability of the results and ensure that the way we sampled the book after each transaction did not impact the results, we repeated the analysis using three different configurations for the sampling of the order book layers. The first took a snapshot after every transaction, the second took a snapshot after every two transactions, and the third took a snapshot after every three transactions. All three configurations yielded the same phenomena. We took this as evidence against the hypothesis that sampling the snapshots after each transaction affected the results.
We had sufficient data to calculate the entropy for the first five layers of the book; e.g., we had five layers of data in every snapshot. However, we realized that particularly in a small stock exchange such as the TASE, we sometimes may not have data for deeper layers, which would make entropy estimation difficult (if not impractical). For this reason, we decided not to extend the analysis to deeper layers. However, since the work with the five stocks indicated that the significance of new layers was declining substantially by layer 5, we expect that deeper layers will behave similarly.
A more detailed analysis of the full entropy calculation, including by groups of price differences, is presented in
Appendix A,
Table A1.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




