1. Introduction
Climate change combined with changes in land use is causing increased frequencies of drought and flooding events in many parts of the world. In 2021, extreme rainfall hit the Henan Province of China in July, Western Europe suffered severe flooding in mid-July, while extreme rainfall and flooding also affected the northern Amazon basin in South America and several parts of Africa. At the same time, prolonged droughts plagued several parts of the world. Such adverse impacts have been anticipated by scientists [
1]. Climate and land-use changes affect ecosystems and human societies globally. One of the main concerns is their impact on the availability of water resources. It is thus important to better understand and forecast the spatial and temporal patterns of precipitation since these patterns affect the hydrological cycle and are crucial for the sustainability of human life on the planet.
Expert estimates—included in the Sixth Assessment Report of the Intergovernmental Panel on Climate Change—indicate an increase in the global averaged precipitation since 1950 [
2]. In certain areas, both the frequency and intensity of heavy precipitation events have increased. In the Mediterranean region, on the other hand, it is expected that summer precipitation will decrease, thus increasing the risk of drought and aridification. In addition, there is evidence that the number of precipitation events has decreased while the intensity per event has increased [
3]. Heavy precipitation events are expected to increase in several Mediterranean countries leading to increased flooding risks [
4]. The impact of climate change on societies worldwide has renewed interest in quantitative methodologies that can estimate spatiotemporal climate and weather patterns [
5]. Certain areas, including the Mediterranean basin, have been characterized as “climate change hot spots” [
6]. Especially in such regions the interplay of climate change and changes in land use is crucial for water resource availability [
4].
Accurate spatial models of precipitation are difficult to formulate, due to the variability and intermittent nature of precipitation across different temporal and spatial scales. In the Mediterranean region, the two large water bodies (the Atlantic Ocean and the Mediterranean Sea), as well as the major European mountain ranges are considered the main causes of extreme precipitation [
7,
8]. The total amount of precipitation received by an area over a specific time window is often modeled by means of parametric, non-Gaussian, probability distributions. If the temporal dimension is taken into account, modeling is further complicated due to the strong seasonal variability and intermittence of precipitation. Furthermore, despite significant progress over the last 30 years, the modeling of interactions between spatial and temporal correlations is an open research topic [
9,
10,
11].
The spatial patterns of precipitation are calculated by means of stochastic spatial interpolation methods known as Kriging [
12,
13,
14,
15,
16]. Kriging has been successfully used in environmental, meteorological, and hydrological studies to generate spatial maps based on partial data [
17,
18,
19,
20,
21]. The predictive equations used by kriging also appear in the framework of Gaussian process regression (GPR) [
22,
23]. Kriging and GPR methods are based on the assumption of an underlying joint normal (Gaussian) distribution. However, the observed probability distributions of precipitation (as well as other environmental variables) are typically skewed (non-Gaussian) [
24,
25]. In geostatistical literature, non-Gaussian distributions are treated using nonlinear transformations that restore normality of the marginal distribution in a latent space; for reviews of such transformations see [
14,
16,
23]. The application of nonlinear transformations to achieve normality is known as “Gaussian anamorphosis”. The spatial analysis is carried out in the latent space using the transformed data. Predictions in the observation space are derived by inverse transforming the predictions in the latent space. A similar “warping” approach has been applied to Gaussian process regression [
26]. The term “warping” herein refers to the nonlinear transformation of the Gaussian process.
This study has two main objectives. First, we introduce a new, non-parametric (data-driven) warping approach. The warping transformation employs the kernel-based estimate of the cumulative distribution function (CDF) recently presented in [
27]. This non-parametric method provides better estimates of the CDF of skewed probability distributions than other commonly used kernel-based methods. Secondly, we show that non-parametric warped Gaussian process regression (wGPR) can be used to model the spatial distribution of non-Gaussian variables such as precipitation. We focus on precipitation amounts because the respective probability distributions vary significantly in time, and the shape of the respective CDFs is not satisfactorily captured by parametric expressions. In order to assess the performance of
non-parametric wGPR, we compare the results of cross-validation analysis with those obtained by non-warped GPR (i.e., Kriging). We apply cross-validation to a simulated noisy test function used in [
26] as well as Leave-One-Out Cross-Validation (LOO-CV) to a reanalysis precipitation dataset from the island of Crete. The spatial dependence in the case of the test function is expressed in terms of a covariance model which corresponds to a linear, damped harmonic oscillator driven by white noise [
23]. The enhanced interpolation accuracy provided by this model, which is not well-known in the machine learning and geostatistical literature, motivates its further use in Gaussian process regression.
The remainder of this paper is structured as follows:
Section 2 presents the proposed wGPR methodology which involves Gaussian anamorphosis using the kernel-based CDF, spatial interpolation (prediction) of the normalized process employing standard GPR, and generation of the predictive distribution of precipitation by inverting the warping transformation.
Section 3 presents an application of wGPR to a one-dimensional (1D) synthetic dataset which helps to illustrate the method.
Section 4 compares GPR and wGPR using an ERA5 precipitation reanalysis dataset. Lastly,
Section 5 presents discussion and conclusions and suggests future directions of research.
2. Methodology
Models of space-time processes rely on the spatial and temporal correlations inherent in the data. Most of the commonly used geostatistical approaches as well as GPR are developed to optimally perform Gaussian processes. However, non-Gaussian data are often encountered in nature. For example, precipitation amounts do not follow the Gaussian distribution. Typical models used include the exponential [
28], gamma [
29,
30,
31], lognormal [
32,
33,
34], Weibull [
28], generalized extreme value (GEV) [
35,
36,
37,
38,
39,
40], and Pareto distributions [
41]. The optimal model depends on the geographical location, the climate zone, as well as the analyzed temporal and spatial scale [
3,
21,
27]. It is thus necessary to relax Gaussian assumptions when modeling such data.
The wGPR approach proposed herein tackles non-Gaussian distributions using non-parametric warping of the observation space. The wGPR method involves the following steps: (i) Transformation of the data into standard normal values (normal scores) using a kernel-based warping function to conduct Gaussian anamorphosis; (ii) GP model specification based on variogram estimation; (iii) GPR using the normal scores; (iv) inversion of the warping transform to obtain predictions of precipitation values; and (v) calculation of cross-validation metrics for the assessment of predictive performance. These steps are described in more detail below.
2.1. Introduction to Gaussian Process Regression
A Gaussian process (GP) defines a prior distribution over functions which can then be used for Bayesian regression [
22]. Herein we consider Gaussian processes having as input space the geographical coordinates
(
) of the domain of interest
D. More generally, the input space can be extended to include the altitude and time as well as other potentially relevant for precipitation topographic parameters. Since a Gaussian process is fully determined by its mean and covariance kernel, we will denote the GP
by means of
, where
is the mean function (expectation) and
is the covariance (kernel) function; the latter is a non-negative definite function. The mean function and the covariance kernel are determined from a set of
hyperparameters. In geostatistical parlance, a Gaussian process whose input space is restricted to spatial location is a Gaussian random field [
23].
Measurements of the process typically include a noise term
which represents a collection of independent identically (normally) distributed random variables with zero mean and constant variance
. Then, the observed process is given by
denotes the normal probability model, and the symbol ∼ implies that the probability distribution of the variable preceding ∼ follows the probability law specified after ∼. In the following,
denotes the CDF of the standard normal distribution. The noise variance
is known in geostatistics as the nugget term [
16].
Assuming that measurements are available at
N points
, where
, for all
, the joint PDF of the data is given by
where ⊤ denotes the vector (matrix) transpose,
the vector of expected values, and
, for
the elements of the covariance matrix.
Let us consider a set of points (in general this set is disjoint from the sampling set),
where the unknown values
,
of the process should be estimated. The joint PDF between the data and the predictions is given by
where
is the vector of mean values,
are the elements of the
covariance matrix between sampling and prediction points,
is the
covariance matrix between the prediction and sampling points, and
are the elements of the
covariance matrix between all pairs of the prediction points.
Since the joint PDF of the Gaussian process is normal, it is straightforward to obtain the conditional (on the data) PDF of the vector
at the prediction points. The conditional PDF is also jointly normal with mean and covariance given respectively by the posterior mean,
and covariance,
, i.e.,
where the posterior mean is given by
and the posterior covariance by means of
The GPR Equations (
4)–(
6) look identical to those of simple kriging [
16]. However, in simple kriging, the mean is assumed constant and known, while in GPR the mean can comprise a superposition of basis functions with unknown coefficients (hyperparameters) which are estimated by maximizing the likelihood of the model [
22]. Then, GPR is equivalent to universal kriging. More information regarding the relation between kriging and GPR can be found in [
22,
23]. Model selection in Gaussian processes is based on methods like Bayesian inference and cross-validation. In the former case, a prior function that captures
a priori beliefs regarding the values of the hyperparameters is used.
Gaussian processes assume that the data follow the multivariate Gaussian distribution and that the observation noise is also Gaussian. The Gaussian assumption simplifies the calculations and leads to explicit predictive expressions. The optimal GPR prediction at a point
is given by the conditional mean,
, while the uncertainty is determined by the conditional standard deviation
. The prediction interval at confidence level
for
is given by
where
and
are, respectively, the
and
quantiles of the standard normal distribution.
2.2. Warping (Gaussian Anamorphosis) for Non-Gaussian Distributions
If the data follow a skewed probability distribution or exhibit heteroskedasticity (dependence of the variance on the spatial location), the assumption of normality may be inadequate. The standard approach for handling non-Gaussianity applies nonlinear normalizing transformations that restore marginal normality in a latent space. In geostatistical literature, this procedure is known as
Gaussian anamorphosis (GA). In the Gaussian process framework,
warped GPs incorporate nonlinear “warping” transforms of the observation space [
26].
Hence, “warping” applies a nonlinear transformation to a non-Gaussian GP
, leading to a
latent Gaussian process . More precisely, warping is defined as a
monotonic mapping such that
has Gaussian marginal distribution with zero mean and unit variance [
16,
23]. Then,
can be modeled as a Gaussian process—under the bold assumption that not only the marginal but also the joint PDF of any vector
is Gaussian.
If
is the marginal CDF of
, the
warping transform is defined by means of
such that
The inverse transformation from the latent to the observation space is given by the
inverse warping function
. The latter is defined by means of
so that
is given by the monotonic mapping from the latent Gaussian variable
y to the observation variable
x [
14,
23]. Often, closed-form expressions can be obtained for the functions
and
. In other cases, they are numerically determined from the function composition of the CDF
with
and of
with the inverse
.
Predictions of
in the warped space can be obtained by applying GPR as shown in
Section 2.1. Transferring these predictions to the observation space is straightforward by means of the principle of
quantile invariance, which states that the quantiles of a probability distribution remain invariant under a monotonic transformation, i.e., if
and
, then it holds that
[
23]. Therefore, the predictive distribution in the observation space can be reconstructed from the respective distribution in the warped space by means of the function
defined in Equation (
9). More precisely, the optimal prediction is given by
while the predictive interval at confidence level
is given by
Note that Equation (
10) returns the median of the marginal predictive distribution in the observation space. This is due to the principle of quantile invariance, taking into account that the conditional mean
is also the median of the latent variable’s marginal conditional distribution.
2.3. Data-Driven Warping of Gaussian Processes
Non-parametric (data-driven) warping refers to model-free warping functions based on non-parametric estimates of the CDF from the data. Such estimates can be obtained using kernel functions and are more flexible than those provided by parametric models [
27,
42]. To avoid confusion, we emphasize that GPR is by construction a non-parametric method, in the sense that the underlying process is approximated without invoking a parametric model in the space of functions (albeit the GPs involve a number of hyper-parameters that control the shape of possible functions). So, the term “non-parametric” in relation to the wGPR refers to the data-driven warping function.
Closed-form parametric probability distributions are not sufficiently flexible to provide accurate models for the precipitation amount over different time scales. An example is the amount of precipitation in semi-arid Mediterranean areas, where the optimal model varies significantly across months but also across years for the same month [
21]. In addition, parametric models that were accurate for past observations may not adequately capture future precipitation patterns due to climate change and the expected increase of extreme weather events [
43]. Thus, the CDF of the data often cannot be accurately represented by a parametric model.
A non-parametric estimate of the CDF
is obtained by integrating kernel density estimators (KDEs), leading to semi-explicit CDF expressions as shown in [
27]. The method of kernel cumulative distribution function estimation (KCDE) uses an adaptive plug-in kernel bandwidth based on the theoretical considerations presented in [
42]. The KCDE method is shown to provide better estimates of
than the empirical (staircase) CDF estimate and kernel density estimation based on the normal-reference rule bandwidth.
A smoothing kernel is a real-valued, non-negative function , which respects the properties of normalization, i.e., , and reflection symmetry, i.e., . The parameter is the kernel bandwidth.
If
represents the
i-th order statistic (i.e., the
i-th smallest value) of the sample vector
, the standard PDF kernel density estimator is given by [
44]
A kernel-based non-parametric estimate of the CDF
can be obtained by means of the following weighted sum [
27]
In Equation (
13),
is the
CDF kernel step defined by means of the following integral
Equation (
13) is obtained from Equation (
12) using the integral
. The CDF kernel steps are smoothed versions of the discontinuous steps used in the staircase CDF estimation. Explicit expressions of CDF kernel steps for various kernel functions are obtained in [
27].
Once
is known, it can be used in Equations (
8) and (
9) to obtain the warping transform and its inverse. Since it is not in general possible to derive explicit expressions for the warping function and its inverse, the function
is defined in terms of a lookup table which contains CDF values,
, at
discretization points; these are uniformly distributed over the interval
, where
,
are respectively the minimum and maximum sample values and
h is the kernel bandwidth. The respective values of
are given by means of
. The inverse transform requires finding
x for a given probability level set by
. This is accomplished by linear interpolation of
based on the two
values in the lookup table nearest to
.
2.4. Hyperparameter Estimation
The spatial correlations of the process
—or the transformed GP
—are determined by means of the variogram function; the latter is also known as the second-order structure function in turbulence studies [
45]. The variogram is defined as the semi-variance of the process’ increments, i.e.,
[
16]. The variogram is purely a function of
if the increments are stationary (intrinsic hypothesis), a condition less strict than the stationarity of
.
In the case of stationary
, the covariance kernel and the variogram of the observed process
are connected by means of the equation
where
is the total variance and
. As is known, the observation noise leads to a discontinuity of the variogram at the origin by
(nugget effect).
The variogram estimates are less sensitive to stochastic trends than covariance estimates due to the differencing operation implied in the increments. Thus, stochastic kriging methods are based on the variogram to generate spatial predictions [
13,
15,
16]. An empirical variogram function can be straightforwardly estimated from the data using the
method of moments [
46]. The empirical variogram comprises a set of lag distances and respective estimates of the increment process’ semi-variance. This discrete function is then fitted to a theoretical model, i.e., a permissible (conditionally negative definite) function that is well-defined at every possible lag distance
. This procedure, albeit less efficient than maximum likelihood estimation, provides a computationally fast and visually clear alternative.
A list of commonly used variogram models is given in
Appendix A.
2.5. Assessment of Predictive Performance
Cross-validation (CV) is a methodology that employs a set of statistical criteria in order to assess the predictive performance of spatial models. The data are split into two disjoint sets for training and validation. Strategies for selecting training and validation sets are reviewed in [
47]. The training set is used to tune the GP hyperparameters. The validation data are used for comparison with the model predictions and assessment of the model’s performance [
48]. A single training validation (100–400) split is used for the synthetic data example in
Section 3.
A common strategy for sparse datasets is leave-one-out cross-validation (LOO-CV)—also known as delete-one CV [
49], ordinary CV [
50,
51] or simply CV [
52]. In LOO-CV the training set contains
values and the validation set contains a single value. All
N possible partitions of the data into training and validation sets are used. This approach is employed in
Section 4 for assessing the GPR and wGPR performance on the precipitation reanalysis data.
The predictive performance of different models is assessed by means of statistical measures which include: the bias or mean error (ME), the mean absolute error (MAE), the root mean square error (RMSE), Pearson’s linear correlation coefficient (RP), the Nash-Sutcliffe coefficient (NS), the Empirical interval coverage (CVG), and the Negatively oriented interval score (NINTS) (see
Appendix B for the definitions).
3. Application of GPR and Warped GPR to Synthetic Data
We apply the non-parametric wGPR approach to the synthetic 1D example used in [
26]. The observation data are given by 100 random samples of
where
and
provides the noise contamination of the underlying process
.
The process
is approximated using GPR and wGPR. The performance of the reconstructions is evaluated by comparing the regression estimates with a sample
at
uniformly distributed validation points in
. In the case of GPR, the point predictions are obtained from the marginal posterior mean, Equation (
5), the uncertainty is determined from the posterior covariance, Equation (
6), and
prediction intervals are calculated according to Equation (
7) with
. In the case of wGPR, the prediction and the 95.45% predictive intervals are obtained from Equations (
10) and (
11) respectively.
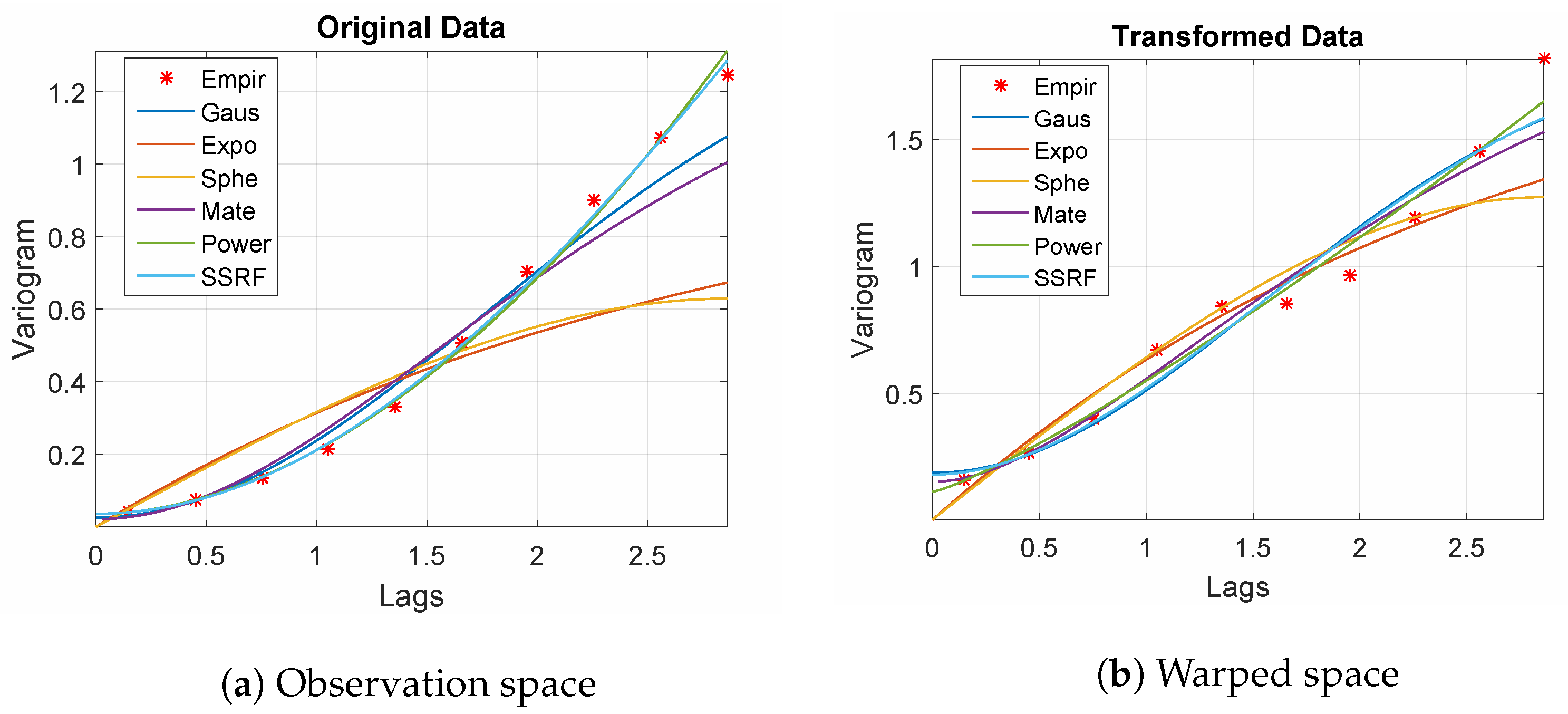
The empirical variograms for both the sample (in observation space) and its counterpart in the warped space are shown in
Figure 1. Note that the spherical and exponential models, which imply continuous but non-differentiable stationary processes, provide poor fits for the empirical variogram (shown by markers), especially in the observation space. This is due to the fact that the true process is a differentiable function mixed with noise. All the other models tested provide reasonable fits to the empirical variograms (with the inclusion of a small discontinuity term at the origin which reflects the noise). Remarkably, the power-law model (
) which corresponds to a non-stationary, continuous but non-differentiable process also gives a good fit. The best fit for the empirical variograms is provided by the Spartan model given by Equation (
A4). In one dimension, the Spartan covariance model represents the covariance function of a damped linear harmonic oscillator driven by white noise [
23], (Chapter 9). Hence, it is a suitable candidate for the oscillatory observation process defined by Equation (
16).
The bitriangular kernel is used in wGPR for estimating the data-derived CDF based on which the warping is performed. The kernel is defined by means of
for
and
for
. In both cases (GPR and wGPR) the Spartan variogram (covariance kernel) of Equation (
A4) is used. Variograms corresponding to other covariance kernels (e.g., exponential, spherical, and Gaussian) were also studied. In general, non-differentiable kernels (e.g., spherical and exponential) lead to rougher reconstructions (exhibiting slope discontinuities) than the differentiable kernels (e.g., Gaussian and Spartan models).
Table 1 compares cross-validation metrics for the GPR and wGPR methods. Warped GPR achieves better performance in terms of most prediction metrics. High-performing prediction implies ME, MAE, and RMSE close to zero, RP and NS close to one, and small magnitudes of minimum and maximum errors. The bias (ME) is slightly lower for GPR, while the magnitudes of the minimum (ErrMin) and maximum (ErrMax) prediction errors are higher for wGPR than for GPR. The ErrMin and ErrMax values are influenced by the wGPR behavior near the left and right boundaries of the domain, where wGPR is closer than GPR to the observations. However, near the boundary the latter are mostly determined by
because
near
. The non-parametric warping transform used in wGPR is based on the CDF of the observations, thus enhancing adaptability to the data (for better or worse).
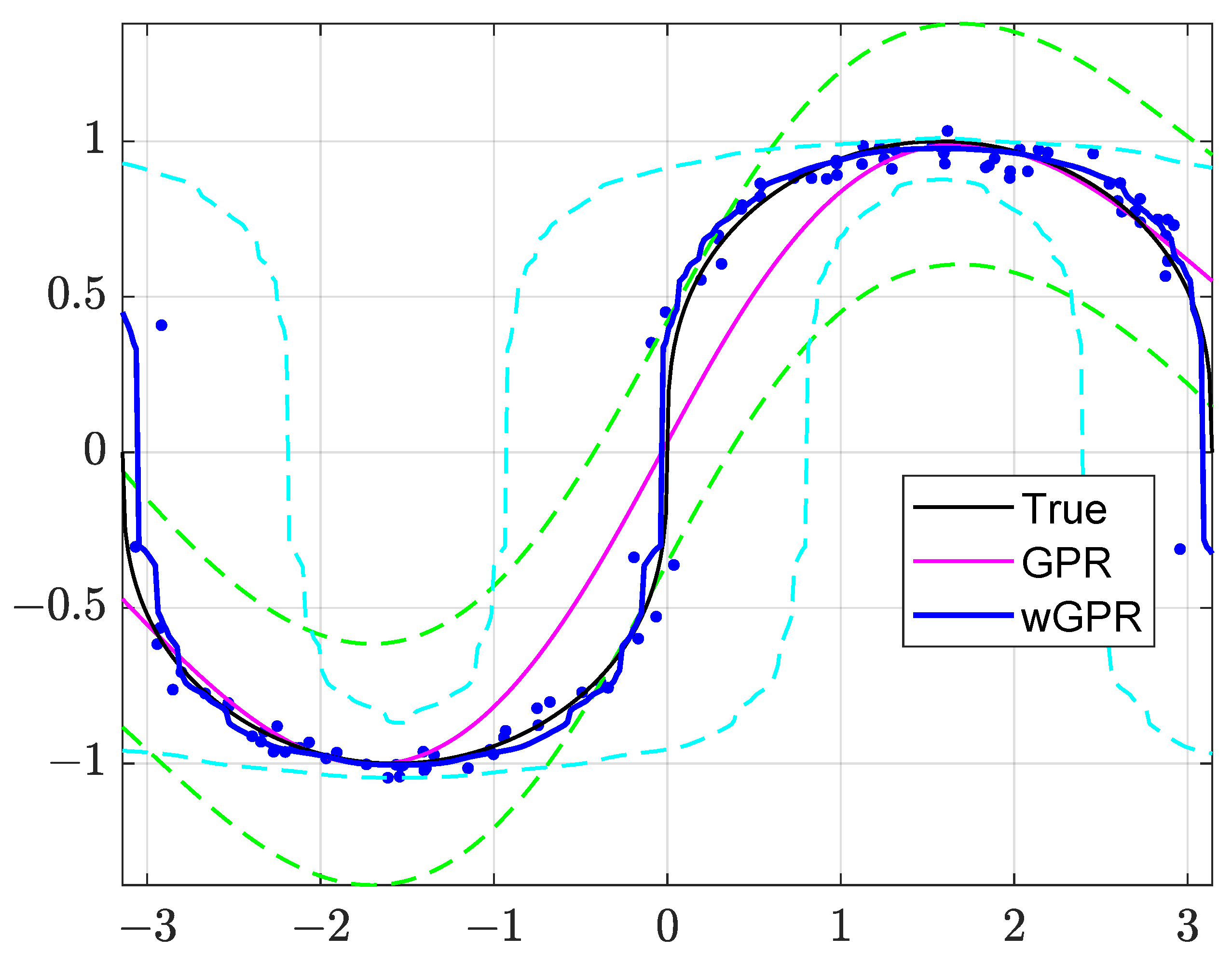
The approximations of
obtained by means of GPR and wGPR are illustrated in
Figure 2: this figure shows the noisy training data (markers), the true process
(black curve), as well as the GPR (magenta line) and wGPR (blue line) approximations with their respective 95.45% prediction intervals. Note that the validation values,
, lie on the black curve (unmarked). As evidenced in the plots of
Figure 2, GPR provides a smooth, differentiable approximation of
, while wGPR yields a continuous but rough (non-differentiable) approximation that adapts more closely to the training data. In addition, the wGPR approximation is closer to the true
almost everywhere except for the boundaries (as discussed above).
The GPR predictive intervals (green dashed lines) are symmetric around , while the wGPR intervals (cyan dashed lines) are asymmetric and their width adjusts to the local slope of . Both prediction intervals contain most of the test values , (the prediction coverage is 100% for wGPR and for GPR). On the other hand, GPR achieves this coverage with tighter intervals than wGPR. This is due to the fact that wGPR adapts the warping transform to the CDF of the training data, and is thus influenced by random errors.
4. Application of GPR and Warped GPR to Reanalysis Data
In this section, GPR and wGPR are applied to a sparse, non-Gaussian, precipitation reanalysis dataset.
4.1. Study Area and Data Description
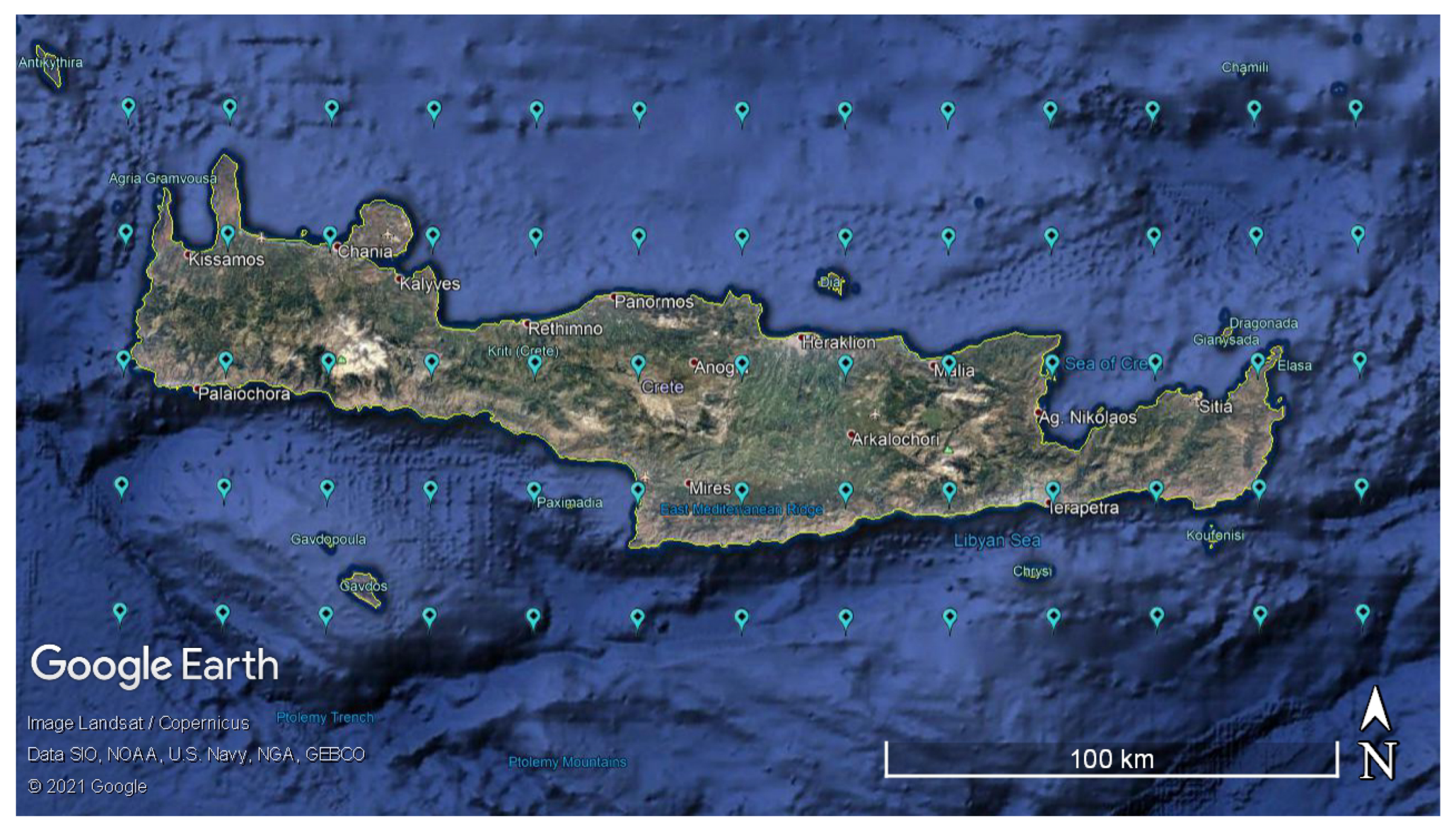
The study area is the island of Crete (Greece) in the southeastern part of the Mediterranean basin. Crete is the largest island in Greece with an area of 8336
, length of 260 km, width ranging from 12 km to 57 km, and a maximum elevation of 2456 m. The island’s climate exhibits a transition from the Mediterranean to semi-arid as is common in Mediterranean regions [
21,
53]. Temperature and precipitation exhibit significant local variations due to three mountain ranges which are among the highest in Europe. The island is divided into four administrative regional units (from West to East): Chania, Rethymno, Heraklion, and Lasithi.
ERA5 reanalysis precipitation data were downloaded from the Copernicus Climate Change Service [
54]. They include 23,360,610 values of hourly total precipitation for a period of 41 years (from 1 January 1979 06:00:00 to 31 December 2019 23:00:00) at the nodes of a
spatial grid (see
Figure 3); the grid nodes are on and around the Greek island of Crete (see
Figure 3). The average spatial resolution is ≈0.28 degrees (grid cell size
km). A total of 359,394 hourly precipitation values are available at every node.
Reanalysis is a systematic approach that employs data assimilation and numerical methods to generate weather and climate products over high-resolution grids [
55]. Data assimilation involves mathematical techniques which can fuse data collected from several sources. Reanalysis products may contain bias due to errors and approximations in the observations and models used. Several studies have focused on the bias correction of meteorological variables, including precipitation, which are derived from reanalysis products [
56,
57,
58]. This study does not apply bias correction methods since the aim is to validate the proposed wGPR methodology, not to compare reanalysis-based interpolation with results obtained from ground measurements.
To avoid modeling complications arising from zero values, we analyze monthly precipitation amounts for the wet season which involves the months from October until March. The resulting dataset includes 15,990 values of monthly precipitation amount (mm) for a period of 246 wet-season months (January 1979 to December 2019) at the 65 nodes of the ERA5 grid.
4.2. Exploratory Statistical Analysis
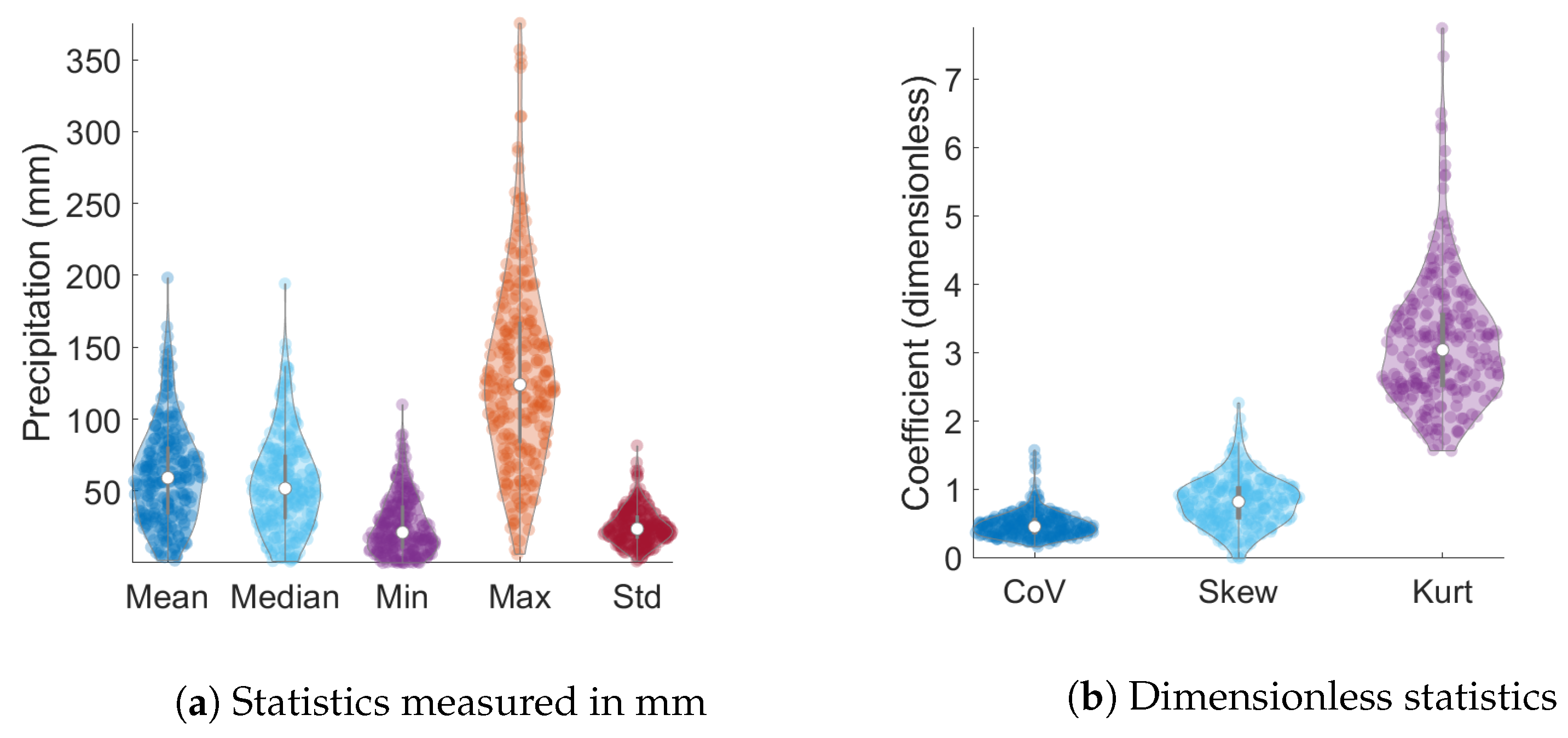
Table 2 lists the summary statistics of the monthly precipitation data for the wet season. They include the mean value, the median, the minimum, and maximum values, the standard deviation, the coefficient of variation (ratio of the standard deviation over the mean), the skewness (coefficient of asymmetry), and the kurtosis. The way to read this table is as follows: the second column corresponds to the minimum value (evaluated over all months) of the monthly statistic shown along a given row (evaluated for each month from the 65 sites). The table is supplemented by
Figure 4 which shows the probability distribution of the monthly statistics (corresponding to different columns of
Table 2 calculated over the 246 months. These plots exhibit an asymmetric distribution of the statistics and considerable dispersion. The non-zero skewness, the deviation of the minimum and maximum kurtosis from the Gaussian value of three, and the unsuccessful fitting of the monthly histograms to the normal distribution (see
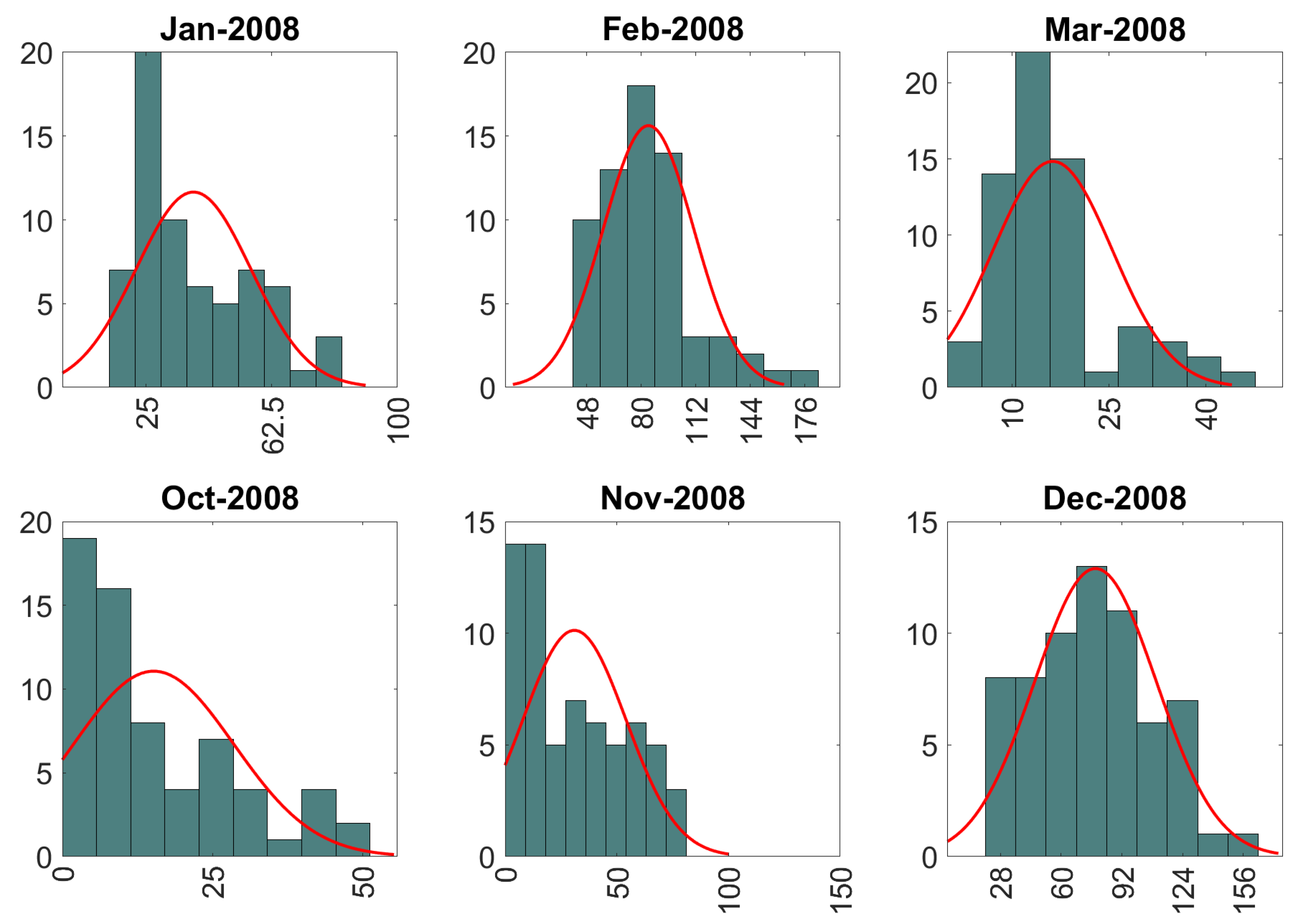
Figure 5), strongly suggest that monthly precipitation data follow non-Gaussian distributions.
To investigate the deviations from Gaussian behavior the data are first grouped by location and then by month. The models that were tested include the generalized Pareto, inverse Gaussian, lognormal, t-Scale location, generalized extreme value, Weibull, Gaussian, Birnbaum-Saunders, exponential, extreme value, gamma, Nakagami, logistic, log-logistic, Rayleigh, and Rician probability distributions. According to Akaike’s Information Criterion (AIC), the Nakagami model is optimal at 45 of 65 nodes, the Weibull at 14, the gamma at 4, and the Rayleigh distribution at the remaining two locations. The results based on the Bayesian Information Criterion (BIC) are similar, with the Nakagami model being optimal at 40 of 65 nodes, the Weibull at 12, the gamma at 4, and the Rayleigh distribution at the remaining 9 nodes. For the data grouped by month, the optimal distribution according to AIC is the Nakagami model for 8 out of the 246 wet months, the Weibull for 3, the gamma for 13, the GEV for 25, the Rayleigh for 1, the generalized Pareto for 126, the log-logistic for 2, the lognormal for 3, the Birnbaum-Saunders for 25, and the inverse Gaussian distribution for the remaining 40 wet months.
In the analysis below, GPR and wGPR are applied to data for each wet-season month at all locations. Hence, a different spatial model is generated for each month. However, monthly data follow a different non-Gaussian probability distribution each month, and hence the warping function in wGPR changes every time. For illustration, the precipitation probability distributions for the year 2008 are investigated. Sixteen parametric probability distribution models (as listed above) were tested. The optimal probability model per each wet season month is presented in
Table 3 (based on BIC) (see also
Figure 5). The optimal distribution for most months is the generalized Pareto (GP). However, this only means that GP achieves a better BIC value than the other models, but it does not ensure that GP is an accurate representation of the empirical distribution.
4.3. GPR and Warped GPR Comparison Based on the Reanalysis Data
The following section presents LOO-CV analysis using GPR and wGPR for the six wet-season months over the 41-year period. The bitriangular kernel is used to estimate the non-parametric CDF which generates the warping function in wGPR. For both GPR and wGPR the spatial correlations are modeled by means of the exponential, Equation (
A1), and Matérn, Equation (
A3), variograms. The Spartan variogram, Equation (
A5), was also tested, but the results obtained were nearly identical to those obtained with the exponential model. Hence, we kept the latter based on the principle of parsimony (the exponential model involves two hyperparameters compared to three for the Spartan model).
The distribution of LOO-CV metrics are shown in the violin plots of
Figure 6,
Figure 7 and
Figure 8. Each violin plot is generated by 246 values (6 months × 41 years) of the respective LOO-CV metric which is calculated based on the 65 values at the grid nodes. The LOO-CV metrics used include the mean error (ME), the mean absolute error (MAE), the root mean square error (RMSE), and the Spearman correlation coefficient (RS). In addition to these, we also use two-interval scores (see
Appendix B): the interval coverage (CVG) and the negatively oriented interval score (NINTS) [
60]. Negatively oriented scores imply that lower scores correspond to better predictions.
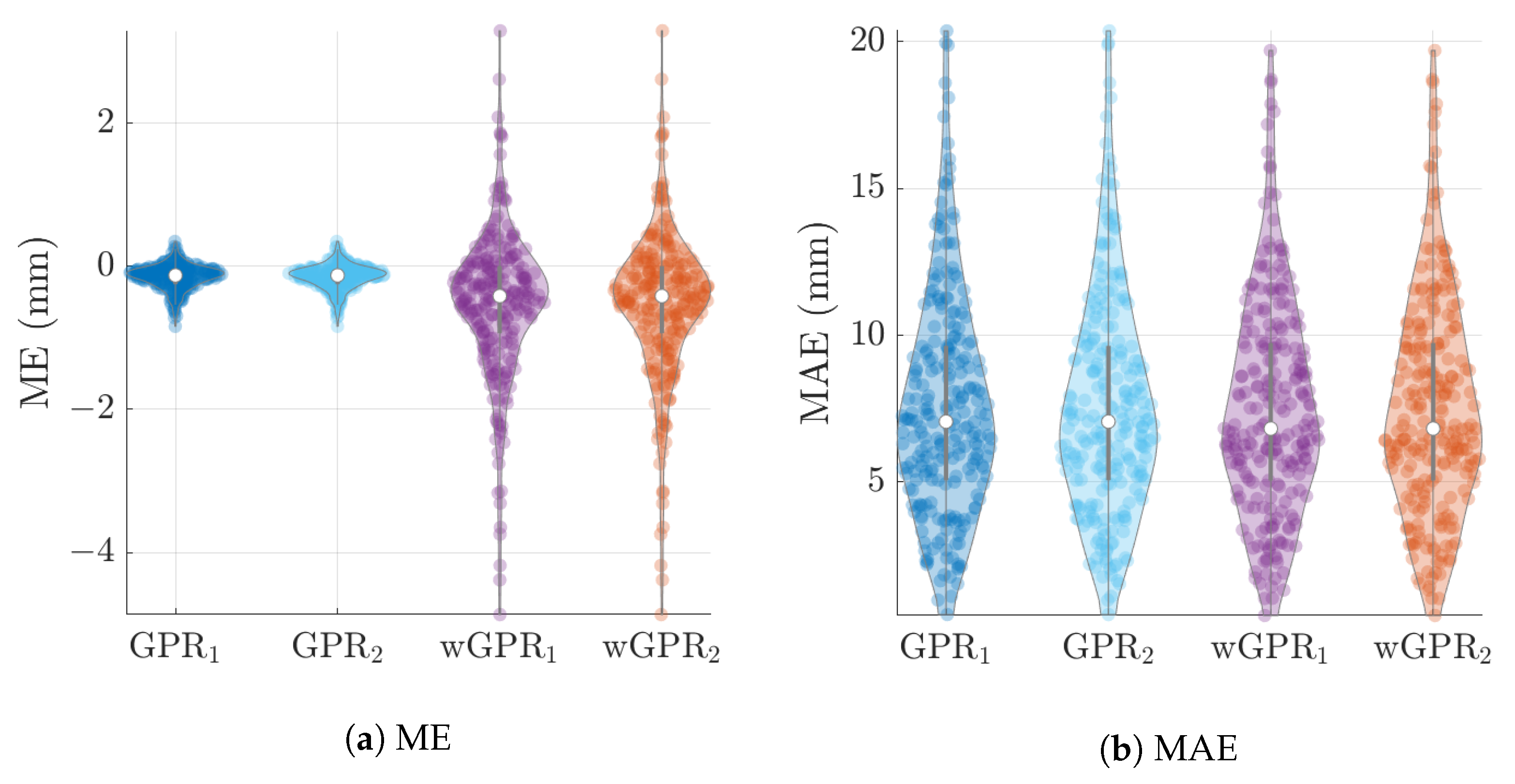
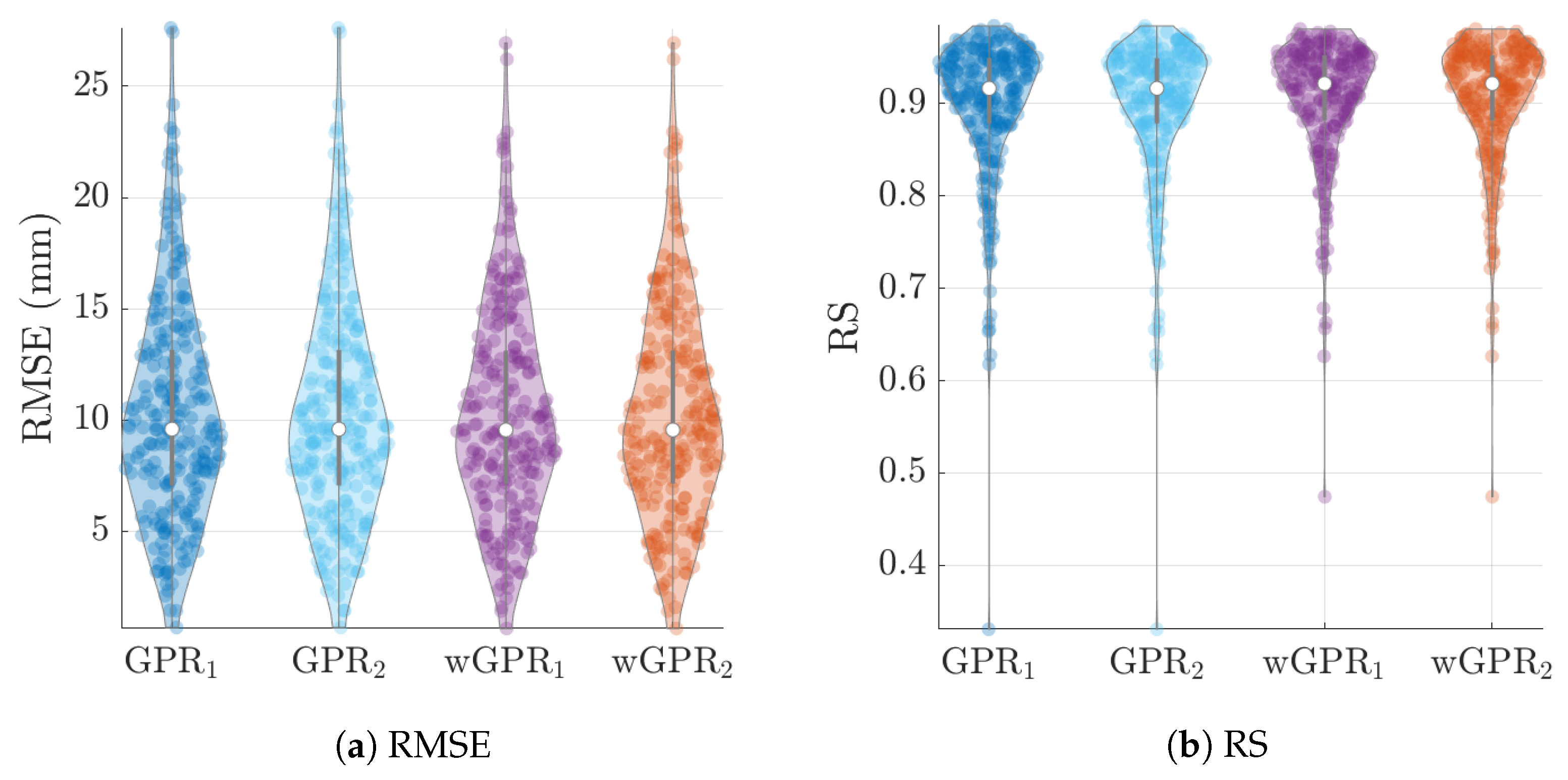
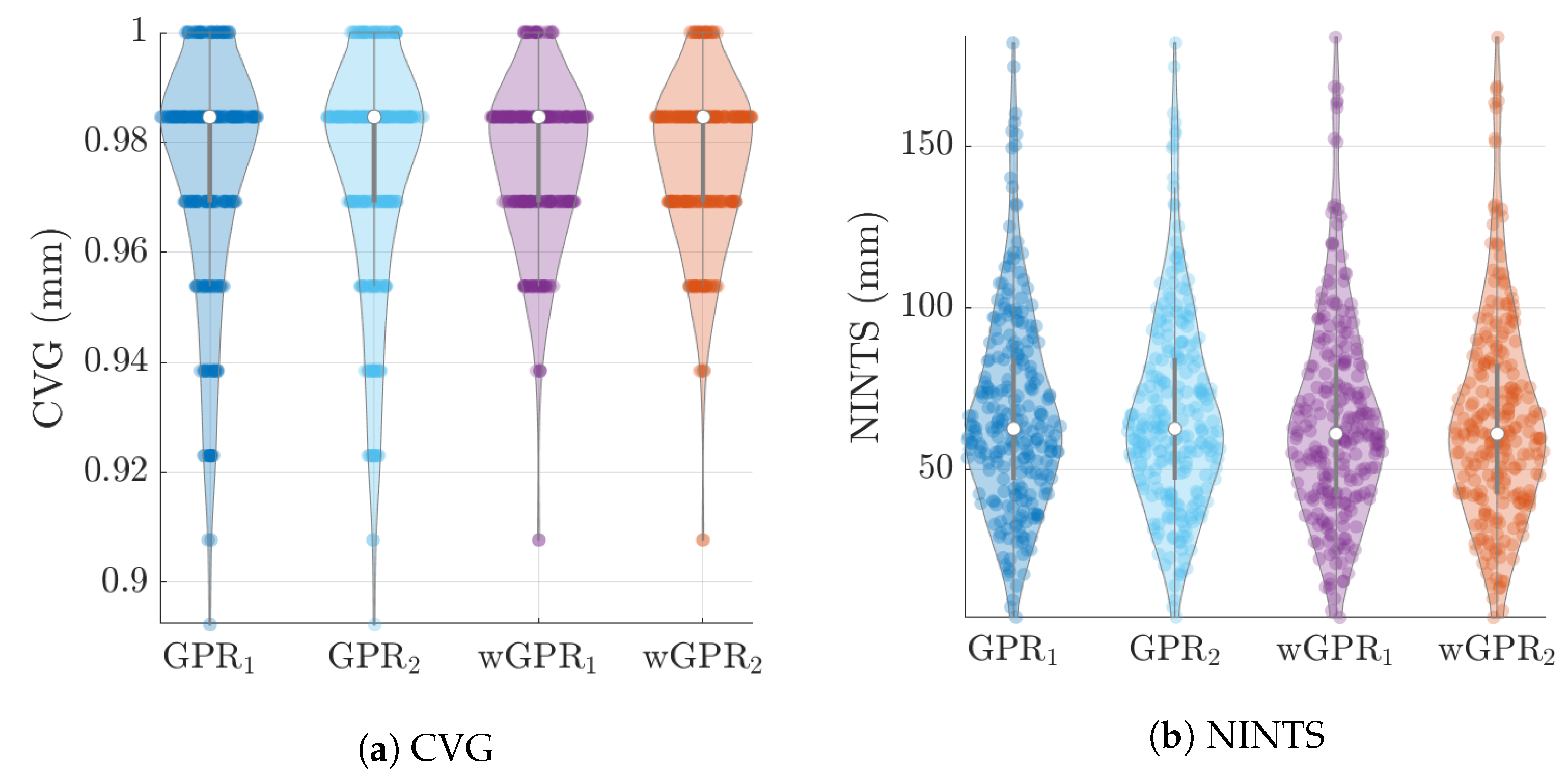
The average values of the cross-validation metrics over all 246 time slices are shown in
Table 4. The values of the metric have been rounded up to the second decimal place. Based on
Table 4 and
Figure 6,
Figure 7 and
Figure 8 there is practically no difference between the results obtained with the two different covariance kernels, in spite of the fact that the Matérn kernel allows for varying smoothness of the spatial function used to interpolate the data. The main differences are between GPR and wGPR. The mean error (bias) has a smaller magnitude for GPR than for wGPR. This is apparent in both the average values (
mm versus
mm) as well as the higher dispersion of the wGPR bias shown in
Figure 6a. This behavior is expected since GPR is implemented so as to enforce a zero-bias constraint. Nonetheless, the wGPR bias is still a small fraction of the average minimum of the data (cf.
Table 2). The wGPR-derived MAE and RMSE metrics are better than the respective GPR-based values, achieving both lower averages (
Table 4) and lower extreme values (see
Figure 6b and
Figure 7a). The average values of the Spearman correlation are identical for both methods. However, as shown in
Figure 7b, the wGPR lower tail of the Spearman correlation distribution is shorter than that of GPR; this implies that wGPR predictions do not lead to poor (rank) correlations with the true data. In terms of the interval scores, wGPR is superior since it leads to lower average NINTS and higher average coverage (CVG) values. In addition, as seen in
Figure 8a the lower values of the wGPR interval coverage are higher than those of GPR.
5. Discussion and Conclusions
There is a strong interest in the application of Gaussian processes to model spatial and spatiotemporal data [
61,
62,
63]. In the case of data exhibiting non-Gaussian distribution (e.g., precipitation), nonlinear transforms are applied to the observations in order to allow the application of Gaussian assumptions and methods. In geostatistics, this practice is known as Gaussian anamorphosis [
14,
16], while in machine learning this approach is known as Gaussian process warping [
26,
63]. In the study that introduced warped Gaussian processes, the hyperbolic tangent function is used to implement the warping transformation [
26]. Other closed-form, nonlinear, monotonic transforms (e.g., square root, Box-Cox, logarithm, Tukey g-and-h) can be used for this purpose [
23] (Chapter 14), [
16,
63,
64].
In this study, we introduce a data-driven (non-parametric) warping method for Gaussian processes which employs kernel-based estimates of the data CDF. The latter is derived directly from the observations and conforms to the shape of the probability distribution that underlies the data. This is different from the Snelson et al. [
26] approach which used an explicit warping function. To our knowledge the proposed method for warping Gaussian processes is new. The term “non-parametric warping” has also been used to denote deformations of the input space which can generate non-stationary Gaussian processes [
61]. In this context, the warping function deforms the coordinate space so that in the new frame the resulting process can be considered stationary. In addition to applications in Gaussian processes, the non-parametric warping approach presented herein can also be used to perform Gaussian anamorphosis in the geostatistical framework.
Non-parametric warping of Gaussian processes allows greater flexibility than the use of parametric warping models: the shape of the data-driven warping function adapts to the features of the dataset at hand instead of being determined from a closed-form expression. Thus, non-parametric warping can provide improved approximation accuracy compared to GPR as evidenced in the 1D example studied in
Section 3 and the precipitation reanalysis data (cf.
Section 4). However, as shown in
Section 3, non-parametric warping can lead to rough approximating functions if the data are contaminated by noise.
We combine non-parametric warping of Gaussian processes with Gaussian prediction (i.e., GPR/Kriging) and the principle of quantile invariance, in order to derive non-Gaussian marginal predictive distribution functions that capture the characteristics of the data distribution. The geostatistical method of variogram modeling is used to estimate the covariance kernel hyperparameters. Fitting the empirical variogram to theoretical models is a statistically less efficient procedure than likelihood maximization. However, it can lead to significant computational savings for large datasets where the computational cost of inverting the covariance (Gram) matrix may be prohibitive for likelihood optimization.
Our comparison of GPR and wGPR also employs monthly precipitation reanalysis (ERA5) data for the island of Crete. Reanalysis data provide valuable information regarding meteorological variables and the impact of climate change on their space-time patterns. Reanalysis data are especially useful in areas where environmental monitoring systems are sparse. As mentioned in
Section 4, reanalysis datasets typically require bias correction in order to provide locally accurate estimates of precipitation. Bias correction can be conducted in combination with measurements from ground gauges, if such data are available. The GPR and wGPR methods can be used in combination with reanalysis and/or ground datasets to generate enhanced-resolution spatiotemporal maps for water resources management applications. A cross-validation comparison of the two methods (GPR and wGPR) showed that GPR has a lower bias, but wGPR is better with respect to other measures including interval scores. In addition, wGPR exhibits better performance in extreme cases where GPR led to poor cross-validation results. No significant differences are found between covariance kernels capable of exponential-like behavior (e.g., the exponential, Spartan, and Matérn models). This is attributed to the irregular spatial patterns of precipitation over Crete which are marked by exponentially decaying correlations [
21].
The warped GPR model can be further investigated along the research directions described below. The present study does not model the dependence of precipitation on altitude. This can be accomplished by means of polynomial trend functions or other function bases. More complex measures of distance can be used in the covariance kernel to account for the anisotropic dependence of spatial precipitation patterns in the West-East and North-South directions of the island [
21]. The scaling of the amount of precipitation with respect to the spatial support (i.e., the area over which the amount of precipitation is measured) is an important factor in the assessment of flood risk in ungauged watersheds [
65], which needs to be linked to the interpolation procedure. The data from each wet-season month were herein treated as separate time slices. It is in principle possible to view the dataset in a space-time continuum and to adopt a spatiotemporal model for correlations. From the modeling perspective, the main difficulty is the construction of space-time covariance kernels that can adequately capture interactions between spatial and temporal correlations, as mentioned in the Introduction. From the numerical perspective, the covariance kernel inversion for the spatiotemporal problem has a significantly higher computation cost due to the respectively larger size of the dataset; the latter would in this case include
points, where
is the number of ERA5 nodes and
the total number of time slices. The issue of increased computational complexity can be addressed by replacing the Gaussian process with a stochastic local interaction model (SLI). The latter expresses space-time correlations in terms of sparse precision matrices. In SLI models the precision matrix is built using a data-adaptive strategy; this can lead to extremely sparse structures, thus reducing the computational cost of interpolation [
23,
66,
67]. In addition to the above, in the space-time framework, a suitable temporal distance should be defined to capture seasonal trends in the precipitation patterns and space-time interaction of the correlations.
In conclusion, we have demonstrated that warped GPR equipped with non-parametric (data-driven) warping functions provides increased flexibility and enhanced accuracy for the spatial prediction of non-Gaussian distributions based on incomplete spatial datasets. The case studies that we examined include a synthetic test function with non-Gaussian noise and precipitation reanalysis data. The probability distributions representative of these datasets involves various degrees of departure from Gaussianity. Based on this evidence, we believe that wGPR will perform well in different applications that involve non-Gaussian data, although this remains to be explicitly demonstrated in future studies. Application of wGPR modeling may lead to poor results for certain types of non-Gaussian probability distributions: these include distributions that allow for isolated spatial extremes, and distributions with discrete spikes (e.g., zero-inflated precipitation during the dry season). The latter could be addressed by means of methods such as the variational, zero-inflated Gaussian process regression [
68].












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}