
Revisiting Local Descriptors via Frequent Pattern Mining for Fine-Grained Image Retrieval

Abstract
:1. Introduction
- We learn global–local aware feature representation, which promotes the discriminative property to identify different fine-grained classes.
- We propose to revisit the local feature via FPM, which mines the correlation among different parts.
- We verify our method on five popular fine-grained datasets. Extensive experiments demonstrate the effectiveness of our method.
2. Related Works
2.1. Content-Based Image Retrieval
2.2. Fine-Grained Feature Representation
2.3. Frequent Pattern Mining
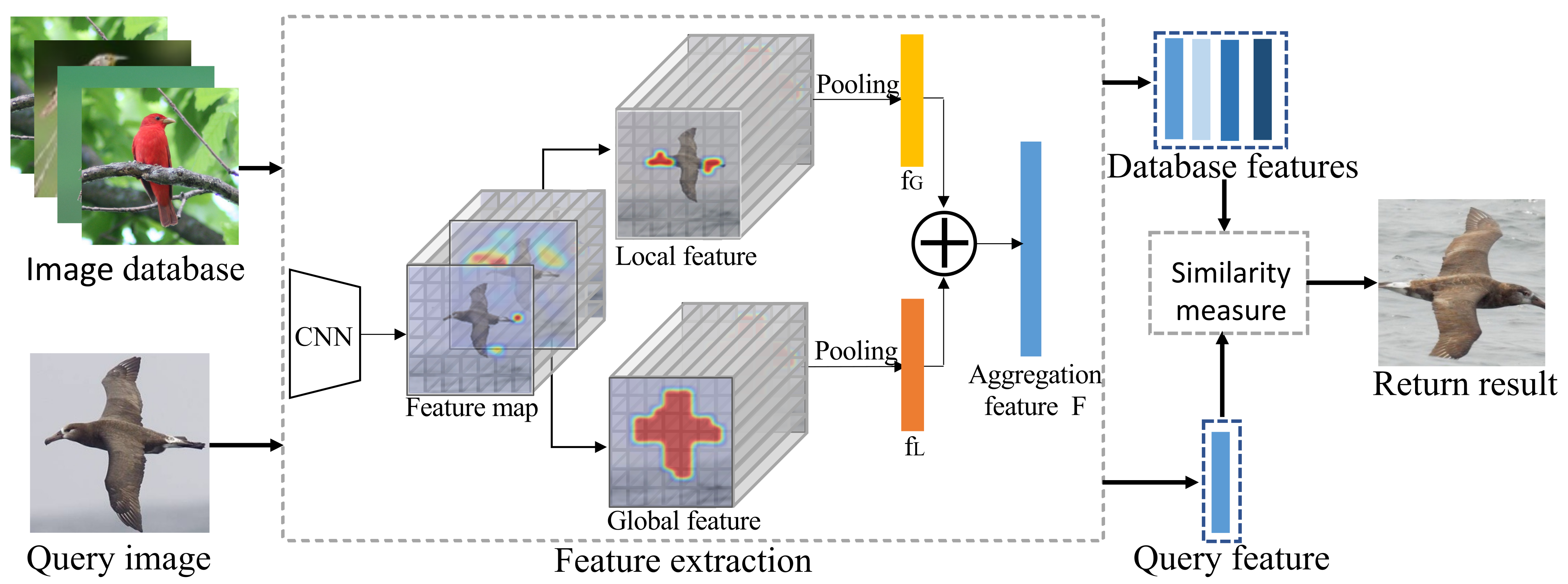
3. Fine-Grained Image Retrieval via Global and Local Features
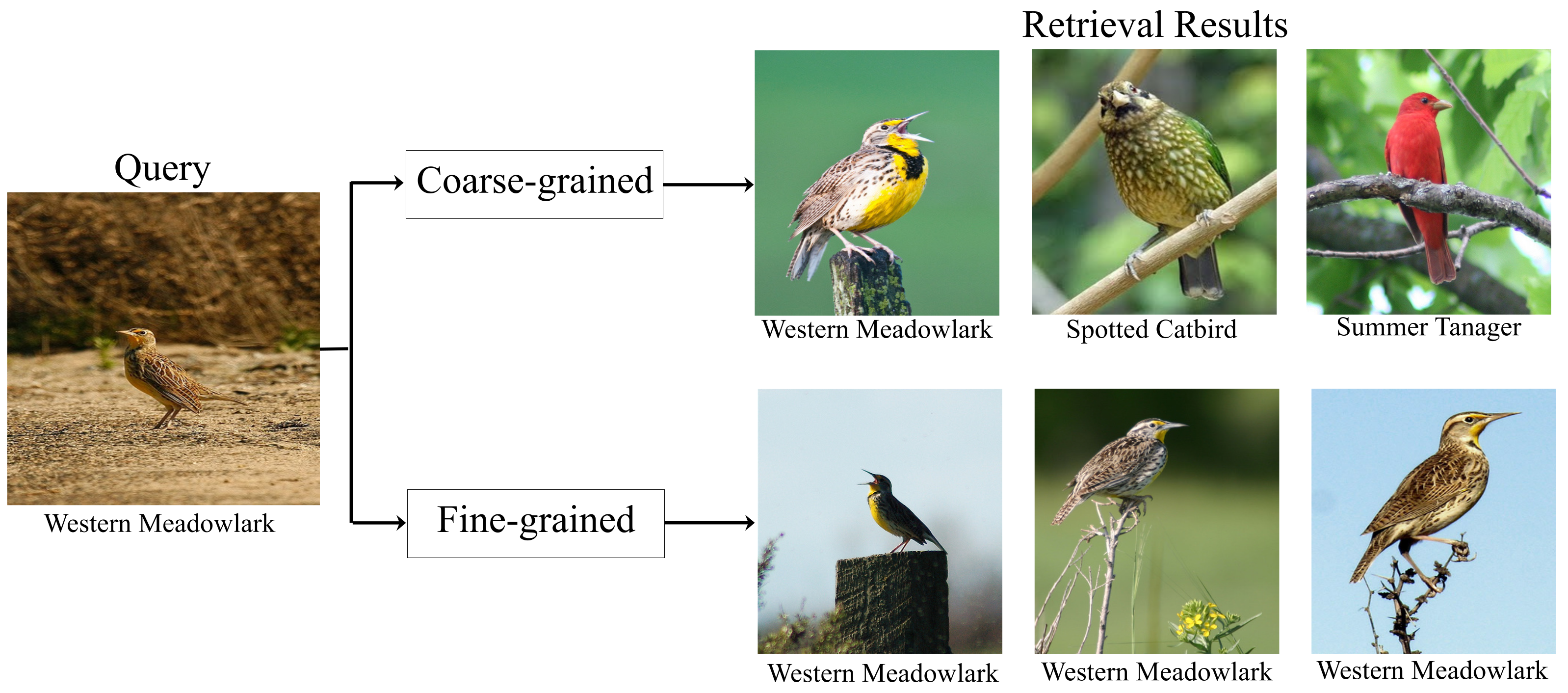
3.1. Motivation and Overview
3.2. Global Feature Learning
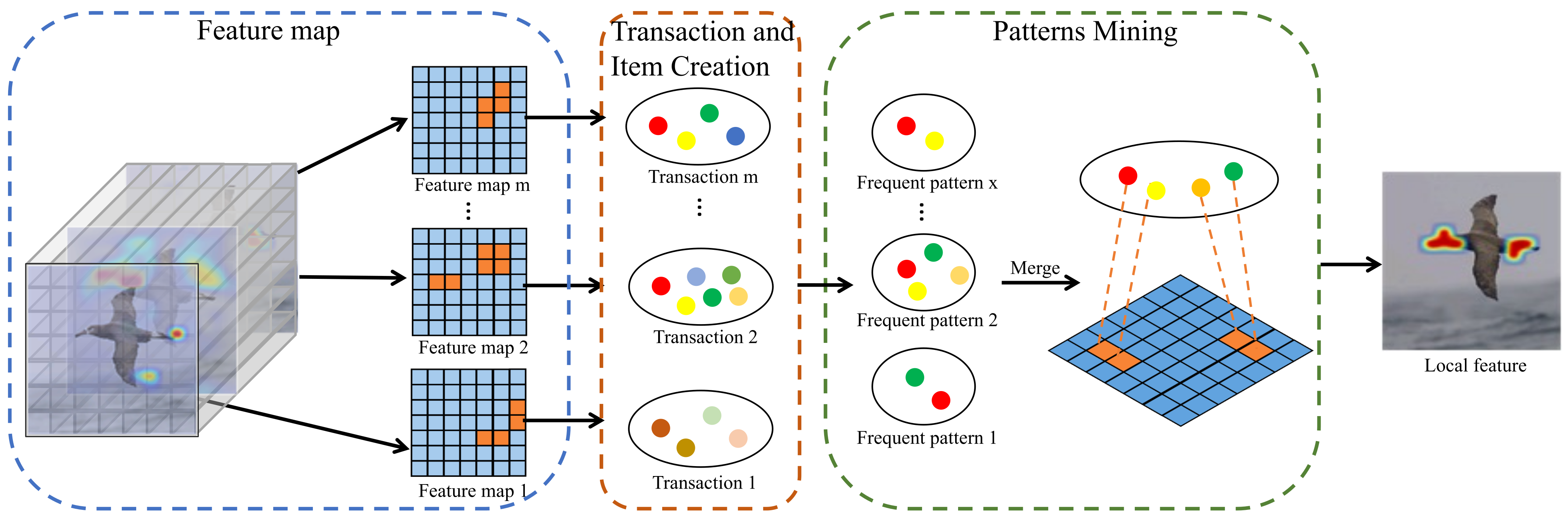
3.3. Local Feature Learning
3.3.1. Preliminary
- Create the root of FP-tree.
- Scan the transactions. For each transaction, sort the reserved items in order of decreasing support.
- Create a branch for the first transaction and insert subsequent transactions into the FP-tree one by one. Specifically, when inserting a new transaction, check whether a shared prefix exists between the transaction and the existing branches. If so, increase the count of all shared prefix nodes by 1 and create a new branch for the items after the shared prefix.
- For any frequent item, construct its conditional pattern base. Here, the conditional pattern base refers to the FP-subtree corresponding to the node we want to mine as the leaf node. To obtain the FP-subtree, we set the count of each node in the subtree to equal the count of the leaf node, and delete the nodes whose count is lower than .
- Mine frequent patterns recursively after obtaining the conditional pattern base. When the conditional pattern base is empty, its leaf node is the frequent pattern; otherwise, enumerate all combinations and connect them with the leaf node to obtain frequent patterns.
3.3.2. Transaction and Item Creation
3.3.3. Frequent Pattern Mining
| Algorithm 1 Revisiting Local Feature Learning via FPM |
| Input: Feature maps , Activated positions . Output: Local feature ). 1: FP-tree construct: generate frequent positions through , and compress them in an FP-tree; 2: FP growth: for any frequent position of FP-tree, construct its conditional pattern base and mine frequent patterns recursively; 3: By the pooling operation, extract the local feature from the frequent patterns. |
3.4. Retrieval Procedure
3.5. Discussion
4. Experiments
4.1. Experimental Settings
- Dataset 1: CUB200-2011 [27] contains 11,788 images of 200 subcategories.
- Dataset 2: Stanford Dog [28] contains 20,580 images of 120 subcategories.
- Dataset 3: Oxford Flower [29] contains 8189 images of 102 subcategories.
- Dataset 4: Aircraft [30] contains 10,200 images of 100 subcategories.
- Dataset 5: Car [31] contains 16,185 images of 196 subcategories.
- SIFT_FV (coarse-grained): The SIFT features are conducted with Fisher Vector encoding as the handcrafted feature-based retrieval baseline. The parameters of SIFT and FV used in our experiment follow [4]. The feature dimension is 32,768. In addition, we replace the whole image with the region within the ground truth bounding box as the input, which is named “SIFT_FV_gtBBox”.
- Fc_8 (coarse-grained): For the Fc_8 baseline, because it requires the input images at a fixed size, the original images are resized to and then fed into VggNet-16. Similarly, we replace the whole image with the region within the ground truth bounding box as the input, which is named “Fc_8_gtBBox”.
- Pool_5 (coarse-grained): For the Pool_5 baseline, it is extracted directly without any selection procedure. We concatenate the max-pooling (512-) and average-pooling (512-) into avg+maxPool (1024-), as the image feature. In addition, VLAD and FV are employed to encode the selected deep descriptors, and we denote the two methods as SelectVLAD and SelectFV, which have larger dimensionality.
- SPoC [34] (coarse-grained): SPoC aggregates local deep features to produce compact global descriptors for image retrieval.
- CroW [35] (coarse-grained): CroW presents a generalized framework that includes cross-dimensional pooling and weighting steps; then, it proposes specific nonparametric schemes for both spatial and channelwise weighting.
- R-MAC [36] (coarse-grained): R-MAC builds compact feature vectors that encode several image regions without feeding multiple inputs to the network. Furthermore, it extends integral images to handle max-pooling on convolutional layer activations.
- SCDA [7] (fine-grained): SCDA utilizes the pretrained CNN model to localize the main object, and meanwhile discards the noisy background. Then, SCDA aggregates the relevant features and reduces the dimensionality into a short feature vector.
- CRL [5] (fine-grained): CRL proposes an efficient centralized ranking loss and a weakly supervised attractive feature extraction, which segments object contours with top-down saliency.
- DCLNS [6] (fine-grained): DCLNS presents a metric learning scheme, which contains two crucial components, i.e., Normalize-Scale Layer and Decorrelated Global-aware Centralized Ranking Loss. The former eliminates the gap between training and testing as well as inner-product and the Euclidean distance, while the latter encourages learning the embedding function to directly optimize interclass compactness and intraclass separability.
- PCE [16] (fine-grained): PCE proposes a variant of cross entropy loss to enhance model generalization and promote retrieval performance.
4.2. Comparisons with State-of-the-Art Methods
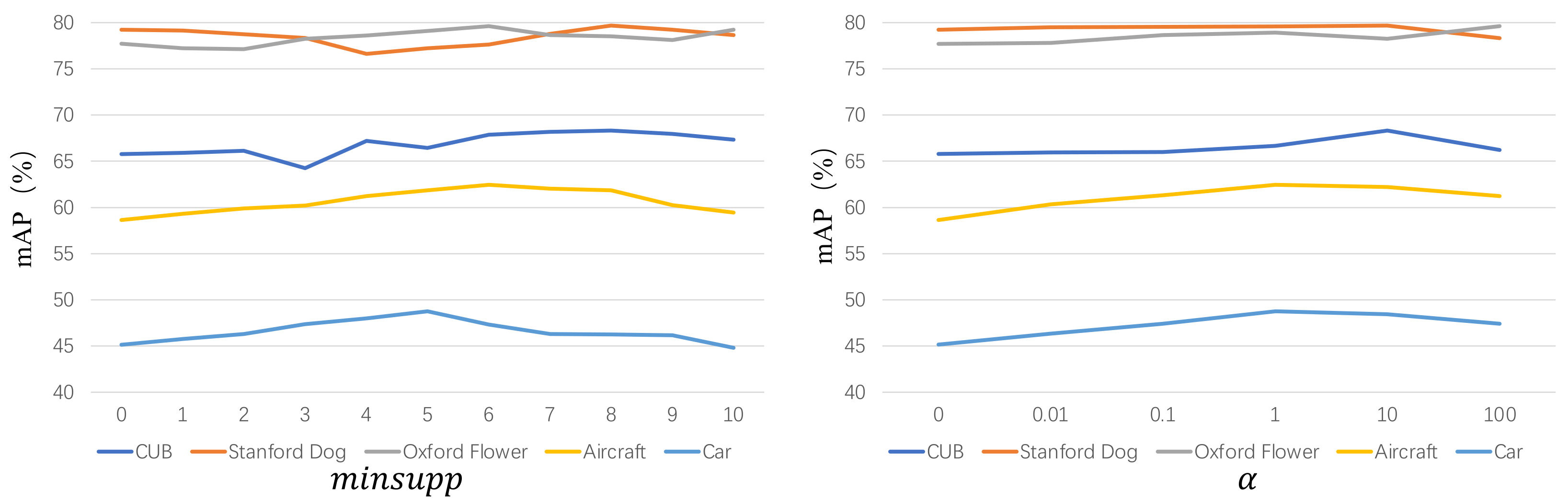
4.3. Ablation Study
- Compared with the “Original”, “Global-stream”, and “Local-stream”, the proposed method boosts performance significantly. This is mainly because global–local aware feature representation combines “Global-stream” and “Local-stream” simultaneously. On the one hand, global feature learning could localize the saliency areas and discard the noises correctly. On the other hand, local feature learning could learn the coactivated local features, which are mutually complementary with the “Global-stream”, to enhance the discriminative property.
- Compared with “Global-stream”, the retrieval results of “Local stream” are also promising. The reason is that subtle visual differences exist in different subcategories. “Global-stream” encodes the basic-level object features but ignores the subtle features, while “Local stream” captures the subtle and minute differences among different subcategories, and mines the inner relationship.
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Smeulders, A.; Worring, M.; Santini, S.; Gupta, A.; Jain, R. Content-Based Image Retrieval at the End of the Early Years. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar]
- Gordo, A.; Almazán, J.; Revaud, J.; Larlus, D. End-to-End Learning of Deep Visual Representations for Image Retrieval. Int. J. Comput. Vis. 2017, 124, 237–254. [Google Scholar] [CrossRef] [Green Version]
- Xie, L.; Wang, J.; Zhang, B.; Tian, Q. Fine-Grained Image Search. IEEE Trans. Multimed. 2015, 17, 636–647. [Google Scholar] [CrossRef]
- Zheng, X.; Ji, R.; Sun, X.; Wu, Y.; Huang, F.; Yang, Y. Centralized Ranking Loss with Weakly Supervised Localization for Fine-Grained Object Retrieval. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 1226–1233. [Google Scholar]
- Zheng, X.; Ji, R.; Sun, X.; Zhang, B.; Wu, Y.; Huang, F. Towards Optimal Fine Grained Retrieval via Decorrelated Centralized Loss with Normalize-Scale Layer. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2019; pp. 9291–9298. [Google Scholar]
- Wei, X.S.; Luo, J.H.; Wu, J.; Zhou, Z.H. Selective Convolutional Descriptor Aggregation for Fine-Grained Image Retrieval. IEEE Trans. Image Process. 2017, 26, 2868–2881. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Li, A.; Sun, J.; Ng, J.; Yu, R.; Morariu, V.I.; Davis, L. Generating Holistic 3D Scene Abstractions for Text-Based Image Retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1942–1950. [Google Scholar]
- Sural, S.; Qian, G.; Pramanik, S. Segmentation and histogram generation using the HSV color space for image retrieval. In Proceedings of the International Conference on Image Processing, New York, NY, USA, 22–25 September 2002; Volume 2. [Google Scholar]
- Chun, Y.; Kim, N.; Jang, I. Content-Based Image Retrieval Using Multiresolution Color and Texture Features. IEEE Trans. Multimed. 2008, 10, 1073–1084. [Google Scholar] [CrossRef]
- Xu, X.; Lee, D.J.; Antani, S.; Long, L.R. A Spine X-ray Image Retrieval System Using Partial Shape Matching. IEEE Trans. Inf. Technol. Biomed. 2008, 12, 100–108. [Google Scholar] [PubMed]
- Xiao, Y.; Wang, C.; Gao, X. Evade Deep Image Retrieval by Stashing Private Images in the Hash Space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 9648–9657. [Google Scholar]
- Zhang, Z.; Zou, Q.; Lin, Y.; Chen, L.; Wang, S. Improved Deep Hashing With Soft Pairwise Similarity for Multi-Label Image Retrieval. IEEE Trans. Multimed. 2020, 22, 540–553. [Google Scholar] [CrossRef] [Green Version]
- Cui, H.; Zhu, L.; Li, J.; Yang, Y.; Nie, L. Scalable Deep Hashing for Large-Scale Social Image Retrieval. IEEE Trans. Image Process. 2020, 29, 1271–1284. [Google Scholar] [CrossRef] [PubMed]
- Zeng, X.; Zhang, Y.; Wang, X.; Chen, K.; Li, D.; Yang, W. Fine-Grained Image Retrieval via Piecewise Cross Entropy loss. Image Vis. Comput. 2020, 93, 103820. [Google Scholar] [CrossRef]
- Zhang, N.; Donahue, J.; Girshick, R.; Darrell, T. Part-Based R-CNNs for Fine-Grained Category Detection. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Wei, X.S.; Xie, C.W.; Wu, J.; Shen, C. Mask-CNN: Localizing parts and selecting descriptors for fine-grained bird species categorization. Pattern Recognit. 2018, 76, 704–714. [Google Scholar] [CrossRef]
- Ge, W.; Lin, X.; Yu, Y. Weakly Supervised Complementary Parts Models for Fine-Grained Image Classification from the Bottom Up. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3029–3038. [Google Scholar]
- Huang, Z.; Li, Y. Interpretable and Accurate Fine-grained Recognition via Region Grouping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8659–8669. [Google Scholar]
- Lin, T.Y.; RoyChowdhury, A.; Maji, S. Bilinear CNN Models for Fine-Grained Visual Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1449–1457. [Google Scholar]
- Sun, G.; Cholakkal, H.; Khan, S.; Khan, F.; Shao, L. Fine-grained Recognition: Accounting for Subtle Differences between Similar Classes. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12047–12054. [Google Scholar]
- Agrawal, R.; Imielinski, T.; Swami, A.N. Mining association rules between sets of items in large databases. In Proceedings of the ACM Conference on Management of Data, Washington, DC, USA, 26–28 May 1993; pp. 207–216. [Google Scholar]
- Han, J.; Pei, J.; Yin, Y. Mining frequent patterns without candidate generation. In Proceedings of the ACM Conference on Management of Data, Cairo, Egypt, 10–14 September 2000; pp. 1–12. [Google Scholar]
- Fernando, B.; Fromont, É.; Tuytelaars, T. Effective Use of Frequent Itemset Mining for Image Classification. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 214–227. [Google Scholar]
- Zhang, R.; Huang, Y.; Pu, M.; Zhang, J.; Guan, Q.; Zou, Q.; Ling, H. Object Discovery From a Single Unlabeled Image by Mining Frequent Itemsets With Multi-Scale Features. IEEE Trans. Image Process. 2020, 29, 8606–8621. [Google Scholar] [CrossRef] [PubMed]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset; Technical Report; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Khosla, A.; Jayadevaprakash, N.; Yao, B.; Fei-Fei, L. Novel Dataset for Fine-Grained Image Categorization: Stanford Dogs. In Proceedings of the CVPR Workshop on Fine-Grained Visual Categorization (FGVC), Colorado Springs, CO, USA, 21–23 June 2011; pp. 1–3. [Google Scholar]
- Nilsback, M.E.; Zisserman, A. Automated Flower Classification over a Large Number of Classes. In Proceedings of the 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, Bhubaneswar, India, 16–19 December 2008; pp. 722–729. [Google Scholar]
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.B.; Vedaldi, A. Fine-Grained Visual Classification of Aircraft. arXiv 2013, arXiv:1306.5151. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar]
- Wei, X.S.; Wu, J.; Cui, Q. Deep Learning for Fine-Grained Image Analysis: A Survey. arXiv 2019, arXiv:1907.03069. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Babenko, A.; Lempitsky, V.S. Aggregating Deep Convolutional Features for Image Retrieval. arXiv 2015, arXiv:1510.07493. [Google Scholar]
- Kalantidis, Y.; Mellina, C.; Osindero, S. Cross-Dimensional Weighting for Aggregated Deep Convolutional Features. In European Conference on Computer Vision Workshops; Springer: Cham, Switzerland, 2015; pp. 685–701. [Google Scholar]
- Tolias, G.; Sicre, R.; Jégou, H. Particular object retrieval with integral max-pooling of CNN activations. arXiv 2016, arXiv:1511.05879. [Google Scholar]
- Berg, T.; Liu, J.; Lee, S.W.; Alexander, M.L.; Jacobs, D.; Belhumeur, P. Birdsnap: Large-Scale Fine-Grained Visual Categorization of Birds. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2019–2026. [Google Scholar]
- Horn, G.V.; Aodha, O.M.; Song, Y.; Cui, Y.; Sun, C.; Shepard, A.; Adam, H.; Perona, P.; Belongie, S.J. The iNaturalist Species Classification and Detection Dataset. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8769–8778. [Google Scholar]
- Wei, X.S.; Cui, Q.; Yang, L.; Wang, P.; Liu, L. RPC: A Large-Scale Retail Product Checkout Dataset. arXiv 2019, arXiv:1901.07249. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Images | Categories | BBox | Part Anno |
|---|---|---|---|---|
| CUB200-2011 | 11,788 | 200 | ✓ | ✓ |
| Stanford Dog | 20,580 | 120 | ✓ | |
| Oxford Flower | 8189 | 102 | ||
| Aircraft | 10,200 | 100 | ✓ | |
| Car | 16,185 | 196 | ✓ |
| Dataset | CUB | Stanford Dog | Oxford Flower | Aircraft | Car |
|---|---|---|---|---|---|
| SIFT_FV | 8.07 | 16.38 | 36.19 | 37.44 | 24.11 |
| SIFT_FV_gtBBox | 14.29 | 21.15 | - | 46.87 | 40.34 |
| Fc_8 | 48.10 | 72.69 | 60.37 | 35.00 | 25.77 |
| Fc_8_gtBBox | 55.34 | 76.61 | - | 41.25 | 37.45 |
| Pool_5 | 63.66 | 75.55 | 74.05 | 53.61 | 41.86 |
| SelectFV | 59.19 | 73.74 | 73.60 | 54.68 | 41.60 |
| SelectVLAD | 62.51 | 74.43 | 76.86 | 56.37 | 43.84 |
| SPoC | 47.30 | 55.69 | 70.05 | 48.95 | 33.88 |
| CroW | 59.69 | 68.33 | 76.16 | 58.62 | 51.18 |
| R-MAC | 59.02 | 66.28 | 78.19 | 54.94 | 52.98 |
| SCDA | 65.79 | 79.24 | 77.70 | 58.64 | 45.16 |
| CRL | 67.23 | 76.43 | 78.65 | 60.21 | 48.16 |
| DGCRL | 67.97 | 78.25 | 79.21 | 59.34 | 49.67 |
| PCE | 66.79 | 78.43 | 78.23 | 60.64 | 47.16 |
| Ours | 68.32 | 79.68 | 79.62 | 62.45 | 48.76 |
| Dataset | CUB | Stanford Dog | Oxford Flower | Aircraft | Car |
|---|---|---|---|---|---|
| Original | 56.21 | 64.63 | 58.31 | 50.69 | 40.46 |
| Global-stream | 65.79 | 79.24 | 77.70 | 58.64 | 45.16 |
| Local-stream | 67.78 | 77.23 | 78.98 | 60.98 | 48.35 |
| Global–Local aware | 68.32 | 79.68 | 79.62 | 62.45 | 48.76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, M.; Geng, Y.; Li, Q. Revisiting Local Descriptors via Frequent Pattern Mining for Fine-Grained Image Retrieval. Entropy 2022, 24, 156. https://doi.org/10.3390/e24020156
Zheng M, Geng Y, Li Q. Revisiting Local Descriptors via Frequent Pattern Mining for Fine-Grained Image Retrieval. Entropy. 2022; 24(2):156. https://doi.org/10.3390/e24020156
Chicago/Turabian StyleZheng, Min, Yangliao Geng, and Qingyong Li. 2022. "Revisiting Local Descriptors via Frequent Pattern Mining for Fine-Grained Image Retrieval" Entropy 24, no. 2: 156. https://doi.org/10.3390/e24020156