
Representation Learning for Dynamic Functional Connectivities via Variational Dynamic Graph Latent Variable Models


Abstract
:1. Introduction
2. Background and Related Work
2.1. Latent Variable Models (LVMs)
2.2. Dynamic Functional Connectivities (DFC)
2.3. Graph Neural Networks (GNNs)
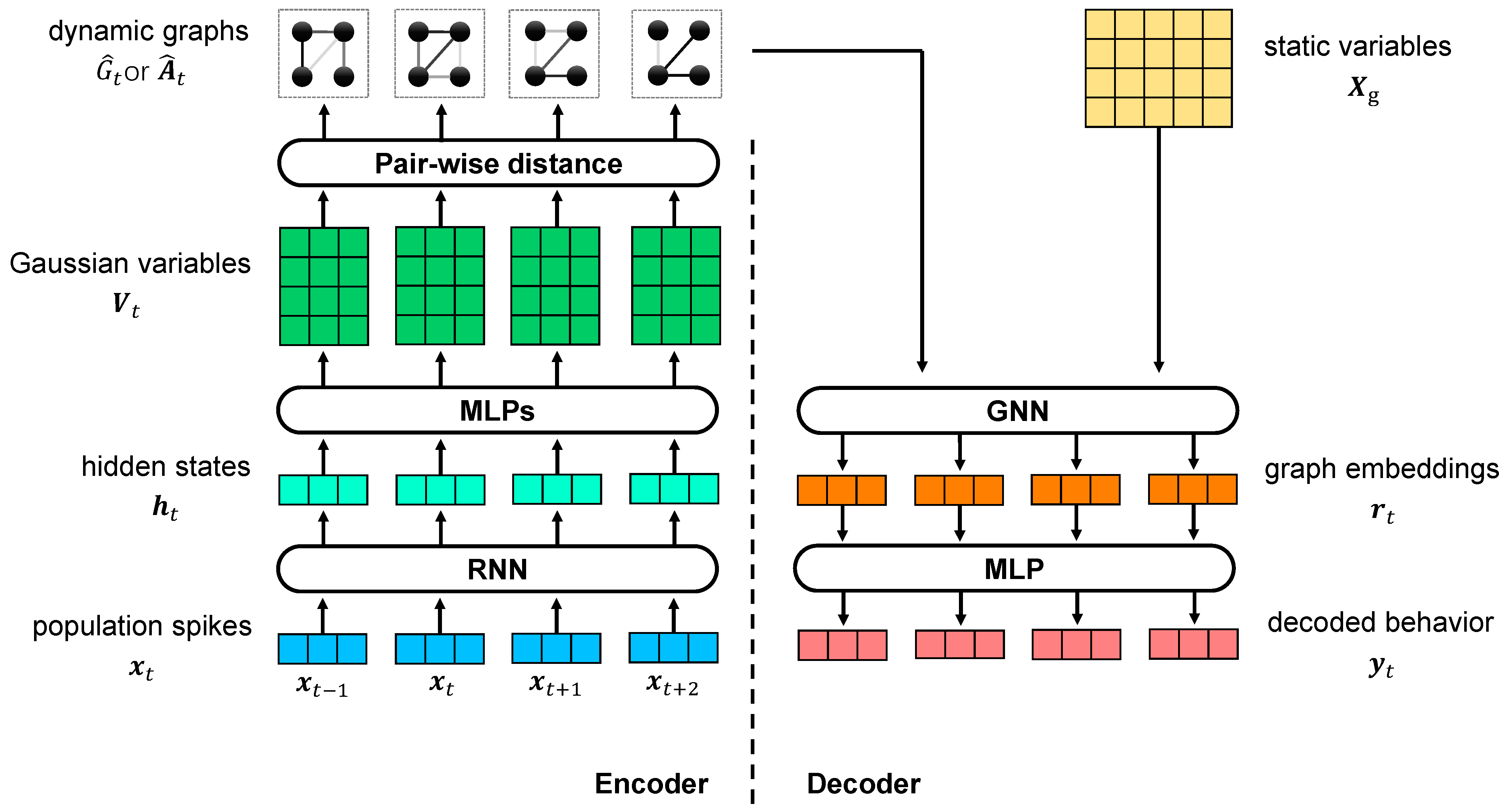
3. Methodology
3.1. Variational Information Bottleneck (VIB)
3.2. Dynamic Graphs as Dynamic Functional Connectivities
3.3. VDGLVM
3.3.1. Encoder
3.3.2. Decoder
3.4. Differences from Existing Work
4. Experimental Setup
4.1. Dataset Description
4.2. Model Configurations
5. Results
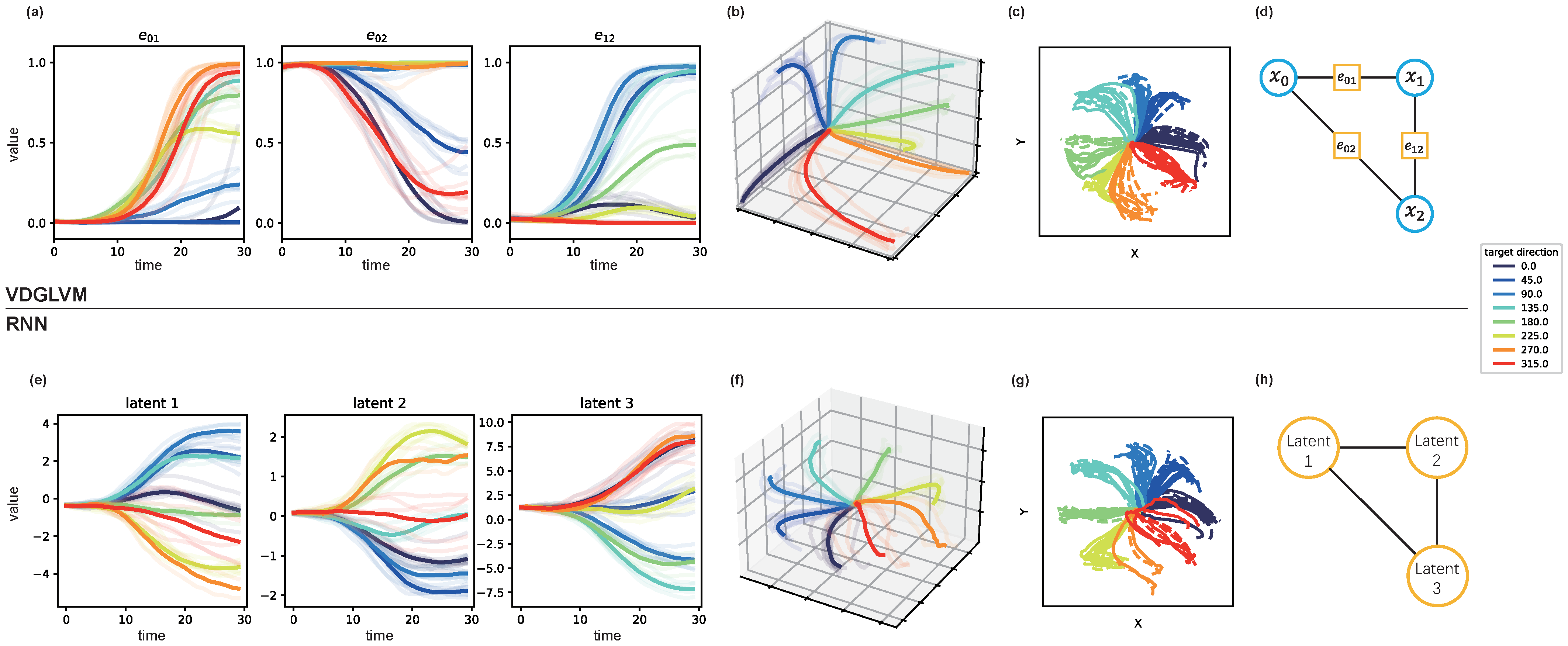
5.1. Performance of Decoding Kinematics
5.2. Latent Structure for Behavior Decoding
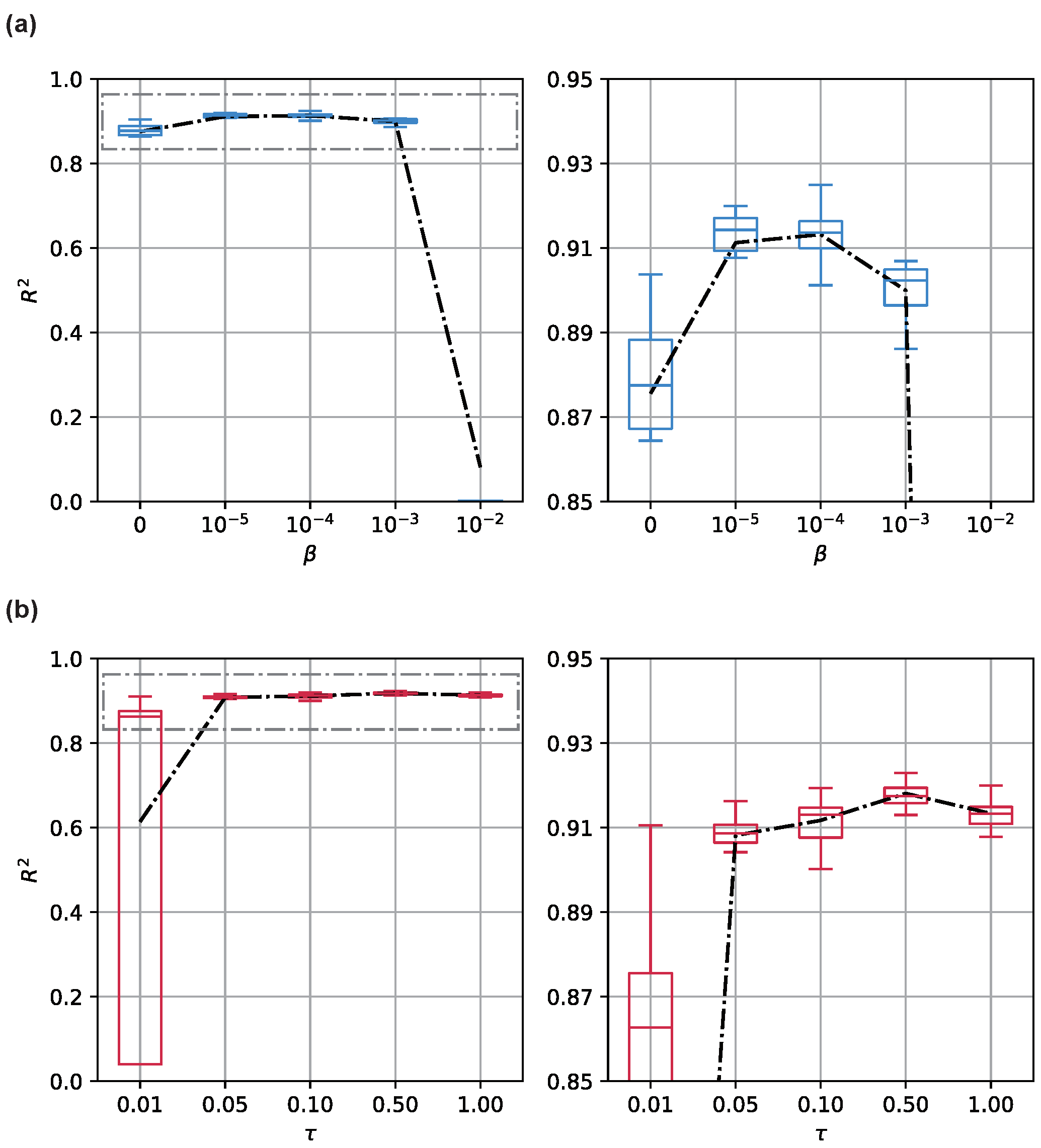
5.3. Hyperparameter Tuning
5.3.1. in VIB Objective Function
5.3.2. in Graph Generation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jun, J.J.; Steinmetz, N.A.; Siegle, J.H.; Denman, D.J.; Bauza, M.; Barbarits, B.; Lee, A.K.; Anastassiou, C.A.; Andrei, A.; Aydın, Ç.; et al. Fully integrated silicon probes for high-density recording of neural activity. Nature 2017, 551, 232–236. [Google Scholar] [CrossRef] [Green Version]
- Hong, G.; Lieber, C.M. Novel electrode technologies for neural recordings. Nat. Rev. Neurosci. 2019, 20, 330–345. [Google Scholar] [CrossRef]
- Steinmetz, N.A.; Aydin, C.; Lebedeva, A.; Okun, M.; Pachitariu, M.; Bauza, M.; Beau, M.; Bhagat, J.; Böhm, C.; Broux, M.; et al. Neuropixels 2.0: A miniaturized high-density probe for stable, long-term brain recordings. Science 2021, 372, 6539. [Google Scholar] [CrossRef] [PubMed]
- Sych, Y.; Chernysheva, M.; Sumanovski, L.T.; Helmchen, F. High-density multi-fiber photometry for studying large-scale brain circuit dynamics. Nat. Methods 2019, 16, 553–560. [Google Scholar] [CrossRef] [Green Version]
- DiCarlo, J.J.; Zoccolan, D.; Rust, N.C. How does the brain solve visual object recognition? Neuron 2012, 73, 415–434. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stringer, C.; Pachitariu, M.; Steinmetz, N.; Carandini, M.; Harris, K.D. High-dimensional geometry of population responses in visual cortex. Nature 2019, 571, 361–365. [Google Scholar] [CrossRef]
- Cunningham, J.P.; Byron, M.Y. Dimensionality reduction for large-scale neural recordings. Nat. Neurosci. 2014, 17, 1500–1509. [Google Scholar] [CrossRef]
- Pandarinath, C.; O’Shea, D.J.; Collins, J.; Jozefowicz, R.; Stavisky, S.D.; Kao, J.C.; Trautmann, E.M.; Kaufman, M.T.; Ryu, S.I.; Hochberg, L.R.; et al. Inferring single-trial neural population dynamics using sequential auto-encoders. Nat. Methods 2018, 15, 805–815. [Google Scholar] [CrossRef] [Green Version]
- Keshtkaran, M.R.; Pandarinath, C. Enabling hyperparameter optimization in sequential autoencoders for spiking neural data. Adv. Neural Inf. Process. Syst. 2019, 32, 15937–15947. [Google Scholar]
- Ye, J.; Pandarinath, C. Representation learning for neural population activity with Neural Data Transformers. Neurons Behav. Data Anal. Theory 2021. [Google Scholar] [CrossRef]
- Hurwitz, C.; Kudryashova, N.; Onken, A.; Hennig, M.H. Building population models for large-scale neural recordings: Opportunities and pitfalls. arXiv 2021, arXiv:2102.01807. [Google Scholar] [CrossRef]
- Gallego, J.A.; Perich, M.G.; Naufel, S.N.; Ethier, C.; Solla, S.A.; Miller, L.E. Cortical population activity within a preserved neural manifold underlies multiple motor behaviors. Nat. Commun. 2018, 9, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Perich, M.G.; Gallego, J.A.; Miller, L.E. A neural population mechanism for rapid learning. Neuron 2018, 100, 964–976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Degenhart, A.D.; Bishop, W.E.; Oby, E.R.; Tyler-Kabara, E.C.; Chase, S.M.; Batista, A.P.; Byron, M.Y. Stabilization of a brain–computer interface via the alignment of low-dimensional spaces of neural activity. Nat. Biomed. Eng. 2020, 4, 672–685. [Google Scholar] [CrossRef] [PubMed]
- Bassett, D.S.; Sporns, O. Network neuroscience. Nat. Neurosci. 2017, 20, 353–364. [Google Scholar] [CrossRef] [Green Version]
- Bassett, D.S.; Zurn, P.; Gold, J.I. On the nature and use of models in network neuroscience. Nat. Rev. Neurosci. 2018, 19, 566–578. [Google Scholar] [CrossRef] [PubMed]
- Breakspear, M. “Dynamic” connectivity in neural systems. Neuroinformatics 2004, 2, 205–224. [Google Scholar] [CrossRef]
- Hutchison, R.M.; Womelsdorf, T.; Allen, E.A.; Bandettini, P.A.; Calhoun, V.D.; Corbetta, M.; Della Penna, S.; Duyn, J.H.; Glover, G.H.; Gonzalez-Castillo, J.; et al. Dynamic functional connectivity: Promise, issues, and interpretations. Neuroimage 2013, 80, 360–378. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gonzalez-Castillo, J.; Bandettini, P.A. Task-based dynamic functional connectivity: Recent findings and open questions. Neuroimage 2018, 180, 526–533. [Google Scholar] [CrossRef]
- Avena-Koenigsberger, A.; Misic, B.; Sporns, O. Communication dynamics in complex brain networks. Nat. Rev. Neurosci. 2018, 19, 17–33. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [Green Version]
- Alemi, A.A.; Fischer, I.; Dillon, V.J.; Murphy, K. Deep Variational Information Bottleneck. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Byron, M.Y.; Cunningham, J.P.; Santhanam, G.; Ryu, S.I.; Shenoy, K.V.; Sahani, M. Gaussian-process factor analysis for low-dimensional single-trial analysis of neural population activity. In Proceedings of the Advances in Neural Information Processing Systems 22 (NIPS 2009), Vancouver, BC, Canada, 7–10 December 2009; pp. 1881–1888. [Google Scholar]
- Zhao, Y.; Park, I.M. Variational latent gaussian process for recovering single-trial dynamics from population spike trains. Neural Comput. 2017, 29, 1293–1316. [Google Scholar] [CrossRef] [PubMed]
- Wu, A.; Roy, N.A.; Keeley, S.; Pillow, J.W. Gaussian process based nonlinear latent structure discovery in multivariate spike train data. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3499–3508. [Google Scholar]
- She, Q.; Wu, A. Neural dynamics discovery via gaussian process recurrent neural networks. In Proceedings of the 35th Uncertainty in Artificial Intelligence Conference, Virtual online, 3–6 August 2020; pp. 454–464. [Google Scholar]
- Liu, D.; Lengyel, M. A universal probabilistic spike count model reveals ongoing modulation of neural variability. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Macke, J.H.; Buesing, L.; Cunningham, J.P.; Yu, B.M.; Shenoy, K.V.; Sahani, M. Empirical models of spiking in neural populations. In Proceedings of the Advances in Neural Information Processing Systems 24: 25th Conference on Neural Information Processing Systems (NIPS 2011), Granada, Spain, 12–15 December 2011; pp. 1350–1358. [Google Scholar]
- Gao, Y.; Archer, E.W.; Paninski, L.; Cunningham, J.P. Linear dynamical neural population models through nonlinear embeddings. Adv. Neural Inf. Process. Syst. 2016, 29, 163–171. [Google Scholar]
- Liu, R.; Azabou, M.; Dabagia, M.; Lin, C.H.; Gheshlaghi Azar, M.; Hengen, K.; Valko, M.; Dyer, E. Drop, Swap, and Generate: A Self-Supervised Approach for Generating Neural Activity. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34. [Google Scholar]
- Zhou, D.; Wei, X.X. Learning identifiable and interpretable latent models of high-dimensional neural activity using pi-VAE. Adv. Neural Inf. Process. Syst. 2020, 33, 7234–7247. [Google Scholar]
- Bastos, A.M.; Schoffelen, J.M. A tutorial review of functional connectivity analysis methods and their interpretational pitfalls. Front. Syst. Neurosci. 2016, 9, 175. [Google Scholar] [CrossRef] [Green Version]
- Handwerker, D.A.; Roopchansingh, V.; Gonzalez-Castillo, J.; Bandettini, P.A. Periodic changes in fMRI connectivity. Neuroimage 2012, 63, 1712–1719. [Google Scholar] [CrossRef] [Green Version]
- Thompson, G.J.; Magnuson, M.E.; Merritt, M.D.; Schwarb, H.; Pan, W.J.; McKinley, A.; Tripp, L.D.; Schumacher, E.H.; Keilholz, S.D. Short-time windows of correlation between large-scale functional brain networks predict vigilance intraindividually and interindividually. Hum. Brain Mapp. 2013, 34, 3280–3298. [Google Scholar] [CrossRef]
- Zalesky, A.; Fornito, A.; Cocchi, L.; Gollo, L.L.; Breakspear, M. Time-resolved resting-state brain networks. Proc. Natl. Acad. Sci. USA 2014, 111, 10341–10346. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hindriks, R.; Adhikari, M.H.; Murayama, Y.; Ganzetti, M.; Mantini, D.; Logothetis, N.K.; Deco, G. Can sliding-window correlations reveal dynamic functional connectivity in resting-state fMRI? Neuroimage 2016, 127, 242–256. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Granger, C.W. Investigating causal relations by econometric models and cross-spectral methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Dhamala, M.; Rangarajan, G.; Ding, M. Analyzing information flow in brain networks with nonparametric Granger causality. Neuroimage 2008, 41, 354–362. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- West, T.O.; Halliday, D.M.; Bressler, S.L.; Farmer, S.F.; Litvak, V. Measuring directed functional connectivity using non-parametric directionality analysis: Validation and comparison with non-parametric Granger Causality. NeuroImage 2020, 218, 116796. [Google Scholar] [CrossRef] [PubMed]
- Fallahi, A.; Pooyan, M.; Lotfi, N.; Baniasad, F.; Tapak, L.; Mohammadi-Mobarakeh, N.; Hashemi-Fesharaki, S.S.; Mehvari-Habibabadi, J.; Ay, M.R.; Nazem-Zadeh, M.R. Dynamic functional connectivity in temporal lobe epilepsy: A graph theoretical and machine learning approach. Neurol. Sci. 2021, 42, 2379–2390. [Google Scholar] [CrossRef]
- Qiao, C.; Hu, X.Y.; Xiao, L.; Calhoun, V.D.; Wang, Y.P. A deep autoencoder with sparse and graph Laplacian regularization for characterizing dynamic functional connectivity during brain development. Neurocomputing 2021, 456, 97–108. [Google Scholar] [CrossRef]
- Jiang, B.; Huang, Y.; Panahi, A.; Yu, Y.; Krim, H.; Smith, S.L. Dynamic Graph Learning: A Structure-Driven Approach. Mathematics 2021, 9, 168. [Google Scholar] [CrossRef]
- Dimitriadis, S.I.; Laskaris, N.A.; Del Rio-Portilla, Y.; Koudounis, G.C. Characterizing dynamic functional connectivity across sleep stages from EEG. Brain Topogr. 2009, 22, 119–133. [Google Scholar] [CrossRef]
- Allen, E.; Damaraju, E.; Eichele, T.; Wu, L.; Calhoun, V.D. EEG signatures of dynamic functional network connectivity states. Brain Topogr. 2018, 31, 101–116. [Google Scholar] [CrossRef]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 2, pp. 729–734. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [Green Version]
- Jin, W.; Barzilay, R.; Jaakkola, T. Junction tree variational autoencoder for molecular graph generation. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2323–2332. [Google Scholar]
- Kawahara, J.; Brown, C.J.; Miller, S.P.; Booth, B.G.; Chau, V.; Grunau, R.E.; Zwicker, J.G.; Hamarneh, G. BrainNetCNN: Convolutional neural networks for brain networks; towards predicting neurodevelopment. NeuroImage 2017, 146, 1038–1049. [Google Scholar] [CrossRef] [PubMed]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1263–1272. [Google Scholar]
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the 2015 IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Gilbert, E.N. Random graphs. Ann. Math. Stat. 1959, 30, 1141–1144. [Google Scholar] [CrossRef]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful are Graph Neural Networks? In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Chepuri, S.P.; Liu, S.; Leus, G.; Hero, A.O. Learning sparse graphs under smoothness prior. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 6508–6512. [Google Scholar]
- Pei, F.C.; Ye, J.; Zoltowski, D.M.; Wu, A.; Chowdhury, R.H.; Sohn, H.; O’Doherty, J.E.; Shenoy, K.V.; Kaufman, M.; Churchland, M.M.; et al. Neural Latents Benchmark ‘21: Evaluating latent variable models of neural population activity. In Proceedings of the Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), Virtual, 6–14 December 2021. [Google Scholar]
- Chowdhury, R.H.; Glaser, J.I.; Miller, L.E. Area 2 of primary somatosensory cortex encodes kinematics of the whole arm. eLife 2020, 9, e48198. [Google Scholar] [CrossRef] [PubMed]
- Churchland, M.M.; Cunningham, J.P.; Kaufman, M.T.; Ryu, S.I.; Shenoy, K.V. Cortical preparatory activity: Representation of movement or first cog in a dynamical machine? Neuron 2010, 68, 387–400. [Google Scholar] [CrossRef] [PubMed] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Model | Area2_Bump | MC_Maze | MC_Maze_L | MC_Maze_M | MC_Maze_S |
|---|---|---|---|---|---|
| Smoothing | 0.595 | 0.642 | 0.597 | 0.546 | 0.481 |
| GPFA | 0.613 | 0.669 | 0.598 | 0.571 | 0.533 |
| SLDS | 0.762 | 0.812 | 0.792 | 0.772 | 0.667 |
| RNN | 0.901 | 0.896 | 0.862 | 0.794 | 0.710 |
| VDGLVM | 0.927 | 0.912 | 0.898 | 0.818 | 0.794 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Yu, Z. Representation Learning for Dynamic Functional Connectivities via Variational Dynamic Graph Latent Variable Models. Entropy 2022, 24, 152. https://doi.org/10.3390/e24020152
Huang Y, Yu Z. Representation Learning for Dynamic Functional Connectivities via Variational Dynamic Graph Latent Variable Models. Entropy. 2022; 24(2):152. https://doi.org/10.3390/e24020152
Chicago/Turabian StyleHuang, Yicong, and Zhuliang Yu. 2022. "Representation Learning for Dynamic Functional Connectivities via Variational Dynamic Graph Latent Variable Models" Entropy 24, no. 2: 152. https://doi.org/10.3390/e24020152