

A Dual Adaptive Interaction Click-Through Rate Prediction Based on Attention Logarithmic Interaction Network

Abstract
:1. Introduction
- We design a novel attention logarithmic network (ALN) to model adaptive-order feature interactions and distinguish the importance of different high-order feature interactions through the squeeze and excitation network (SENet);
- The input of ALN must be positive, which could cause a loss of information. Thus, we integrate Newton’s identity modeling feature interactions with ALN to propose a new model called ALIN;
- Comprehensive experiments on two datasets are conducted to show that our proposed model outperforms the state-of-the-art methods.
2. Related Materials
2.1. Feature Interaction in CTR Prediction
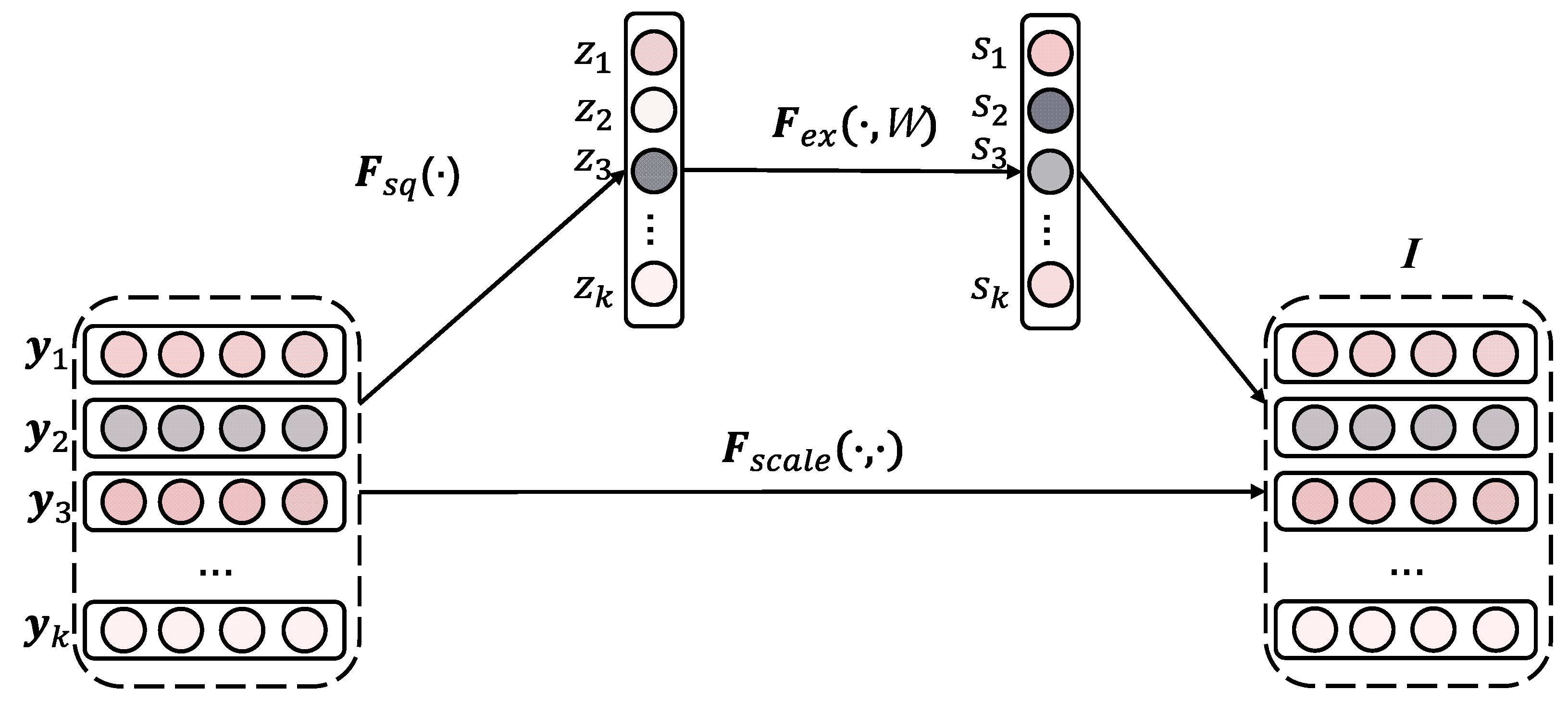
2.2. Squeeze and Excitation Network
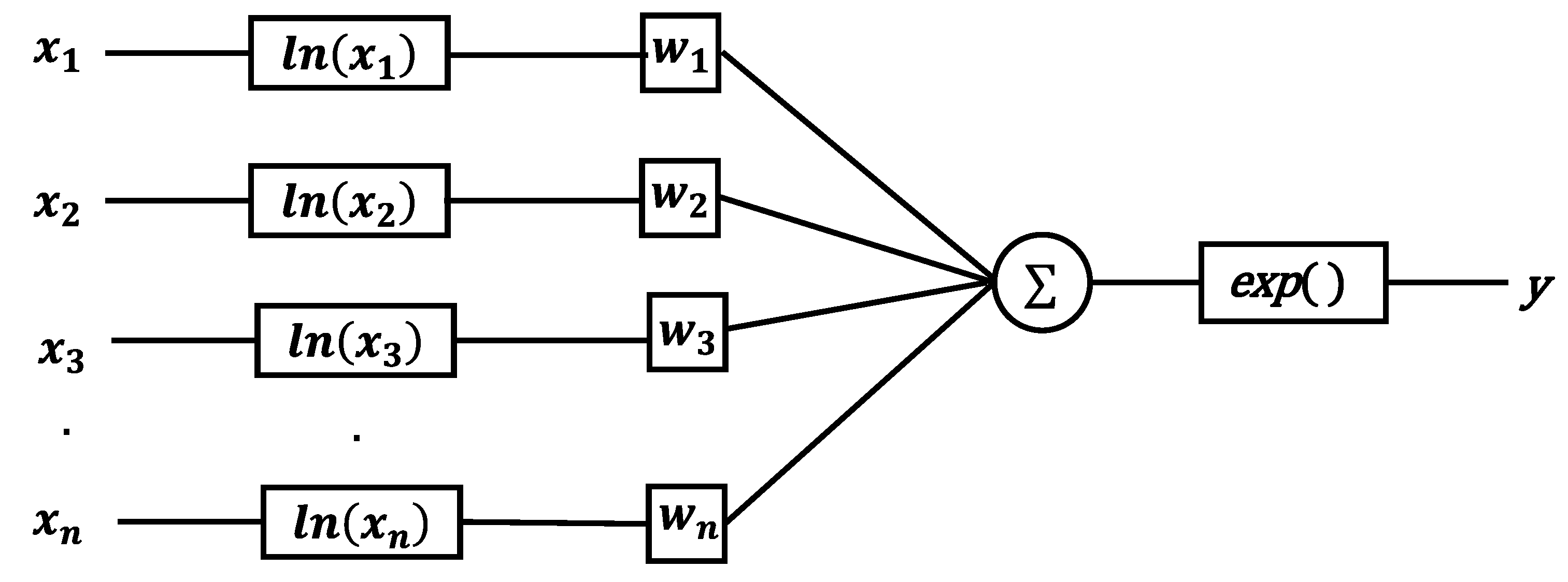
2.3. Logarithmic Neural Network (LNN)
2.4. Newton’s Identity
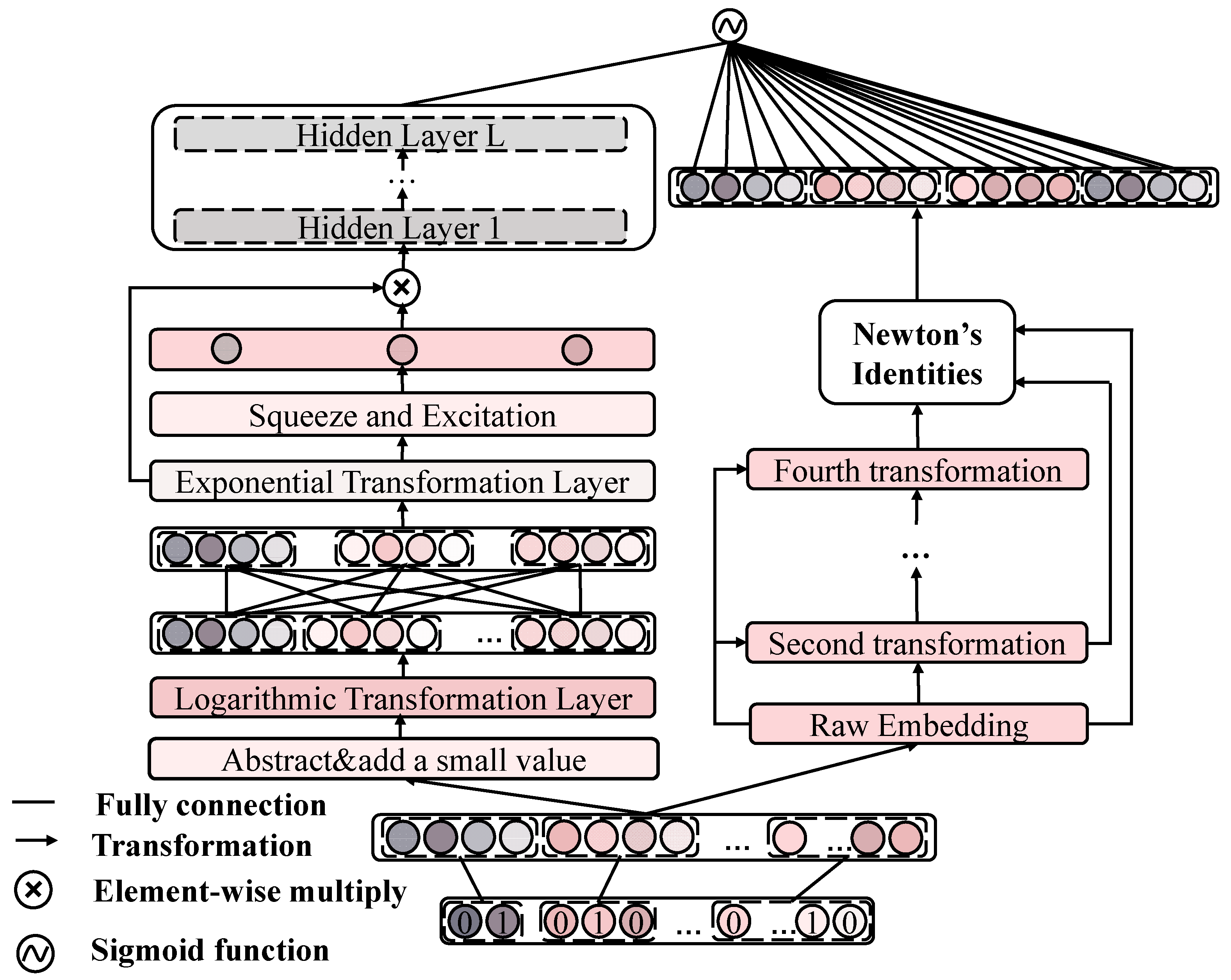
3. Methods
3.1. Problem Definition
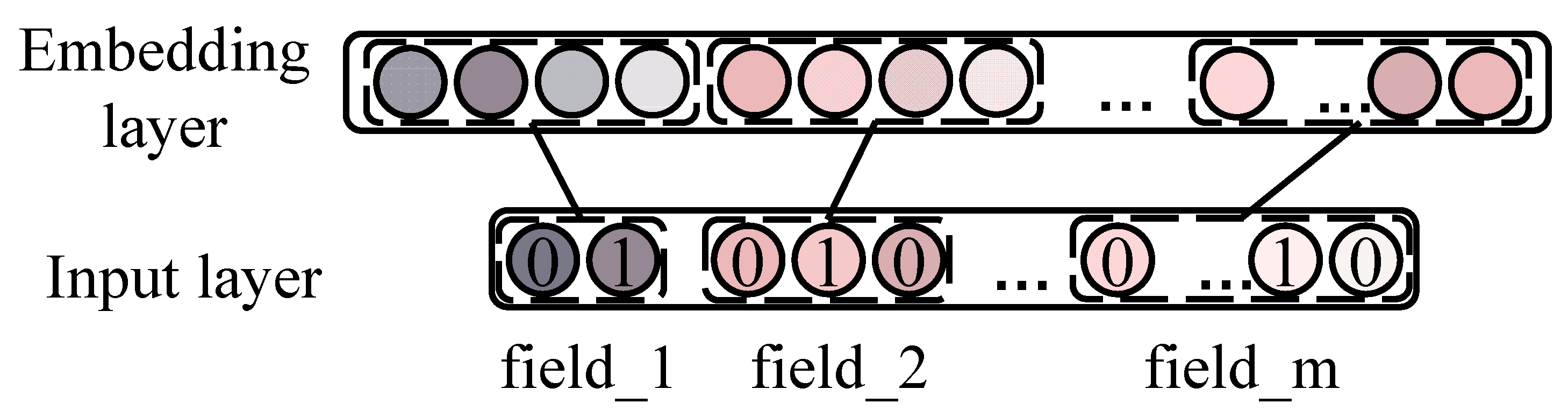
3.2. Input Layer
3.3. Embedding Layer
3.4. Attention Logarithmic Network
3.5. Newton’s Identity Component
3.6. Prediction Layer
3.7. Optimization and Training
4. Results
4.1. Datasets and Experiment Setup
4.1.1. Datasets
- Criteo (https://www.kaggle.com/datasets/mrkmakr/criteo-dataset, accessed publicly): Criteo is a famous benchmarking dataset for CTR prediction. It has 13 numerical feature fields and 26 categorical feature fields, all of which are anonymous feature fields;
- Criteo_600K: We split 600 K samples from the full Criteo dataset randomly. It also includes 39 anonymous feature fields as in the full Criteo dataset.
4.1.2. Evaluation Metrics
- AUC: The AUC metric is widely used in CTR prediction, which measures the probability of a positive sample ranking higher than randomly chosen negative samples [36]. The larger the AUC value, the better the CTR effect. Moreover, the upper limit of AUC is 1. The definition of AUC is as follows:where M and N denote the number of positive instances and negative instances, respectively; and indicate the prediction value of positive instances and negative instances, respectively. denotes the indication function; when the condition is satisfied, = 1, and = 0 otherwise;
- 2.
- Log loss: Log loss is defined in Equation (22), which measures the distance between real labels and prediction scores. A lower log loss indicates better CTR prediction performance. It should be noted that slightly improvement in AUC or decrease in log loss, e.g., at 0.001 level, is be regarded as huge improvement in CTR prediction;
- 3.
- RI: Relative improvement (RI) measures the improvement of our proposed model over other models. RI can be formulated as:where X denotes the AUC or log loss in this paper, M represents the proposed method and B represents compared models.
4.1.3. Baselines
- LR [21]: LR models first order feature interactions and weight individual features for CTR prediction;
- FM [11]: FM learns the hidden presentation for every feature, then models the second order by the inner product;
- AFM [13]: Based on FM, AFM employs the attention network to model second-order feature interaction importance;
- NFM [33]: NFM is a neural networked version of FM. NFM utilizes a bi-interaction pooling layer for modeling second-order feature interaction; then, MLPs are stacked on the layer to learn high-order feature interactions;
- PNN [32]: PNN models product feature interactions in a product neural network, which is capable of modeling complex feature interactions;
- Wide & Deep [20]: Wide & Deep combines LR and DNNs for modeling low-order and high-order feature interactions, respectively;
- DeepFM [22]: DeepFM replaces the wide component of Wide & Deep with FM to learn more informative feature interactions;
- AFN [28]: AFN implements the feature interaction adaptive order via a logarithmic neural network;
- AFN+ [28]: AFN+ is an ensemble model that combines AFN and DNNs to learn feature interactions.
4.1.4. Implementation Detail
4.2. Comparison Experiment
4.2.1. Effectiveness Comparison
- The performance of LR is the worst among all the comparison models, indicating that first-order interaction is inadequate for CTR prediction;
- The higher-order model outperforms the second-order model, which shows that finer-grained feature interactions can improve model performance;
- ALN achieves the best performance among all the high-order models, indicating that it is necessary to consider the importance of feature interactions and the order of feature interactions;
- ALIN performs best among all the ensemble models, indicating that combining Newton’s identity can reduce noisy information caused by logarithmic neurons.
4.2.2. Efficiency Comparison
4.3. Hyper-Parameter Experiments
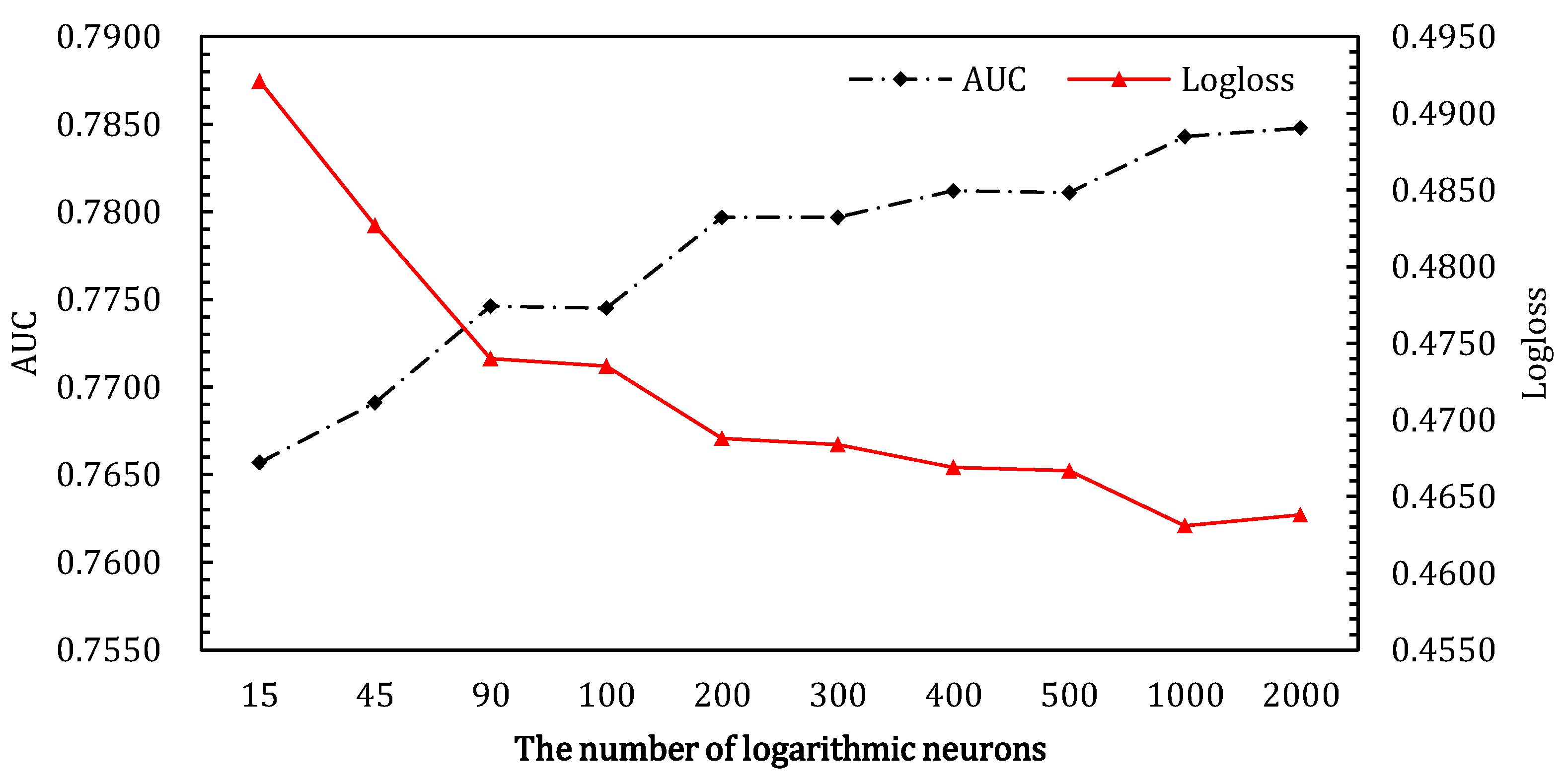
4.3.1. The Number of Logarithmic Neuros in ALN
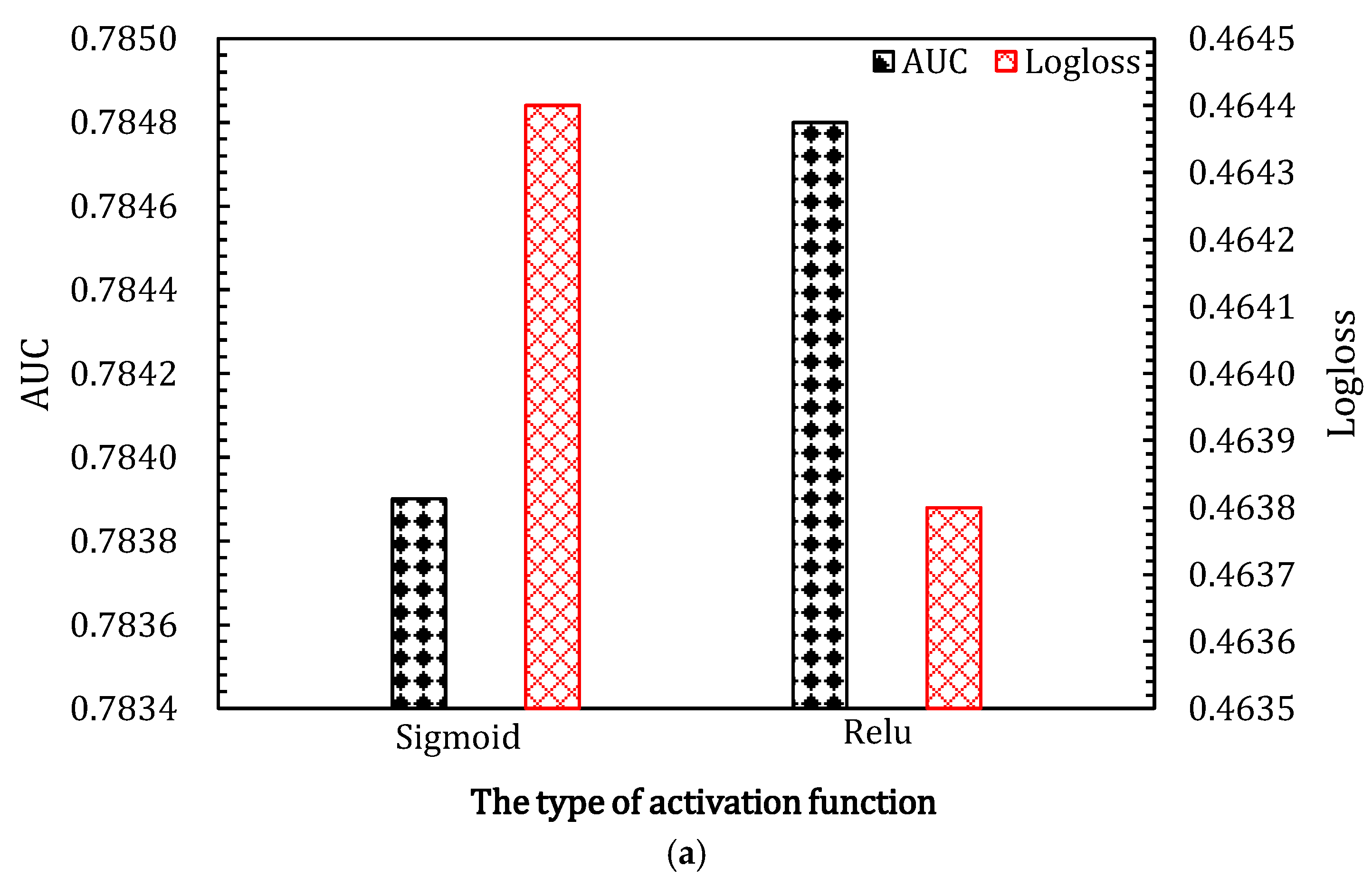
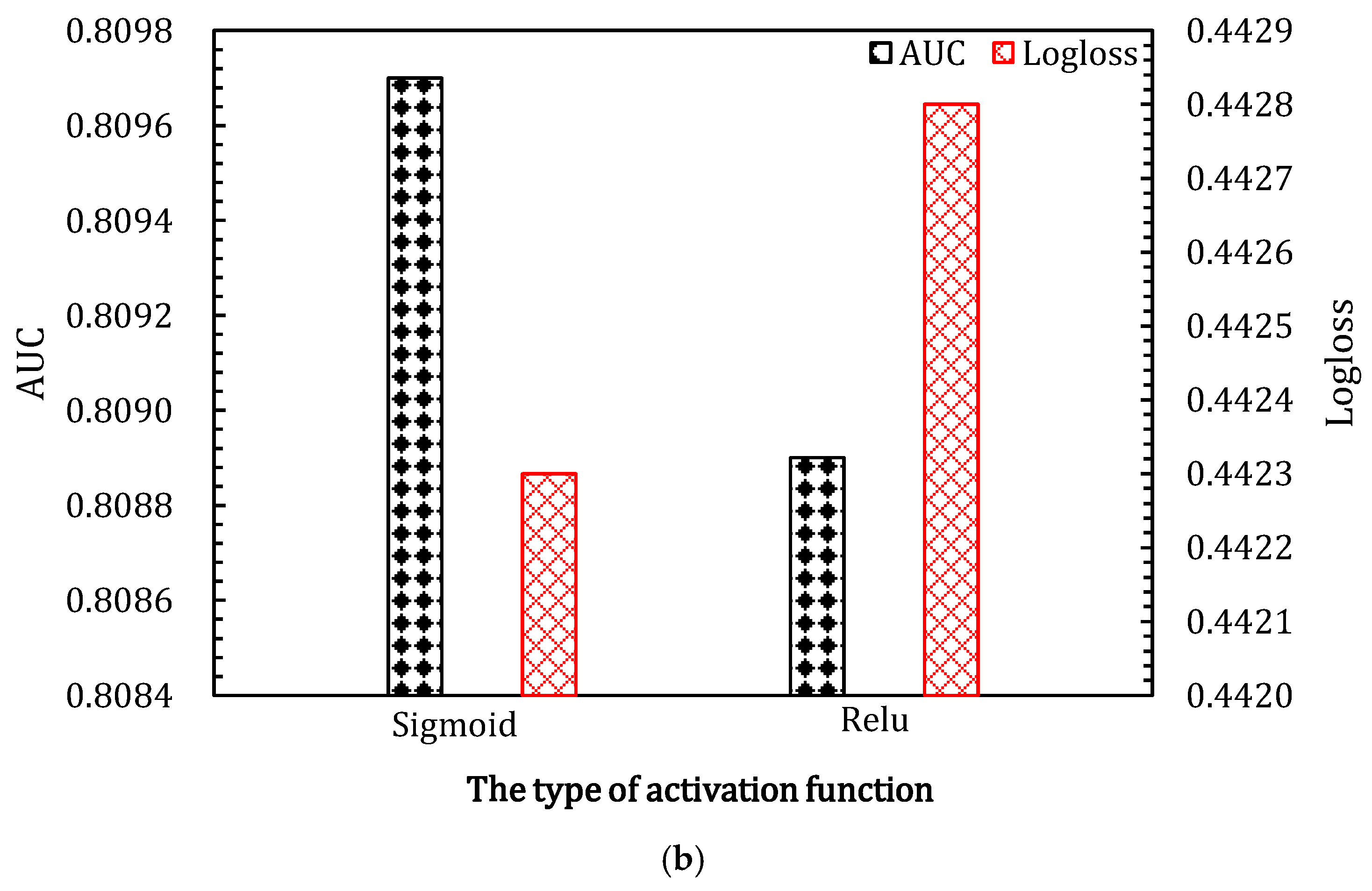
4.3.2. The Type of Activation Functions in SENet
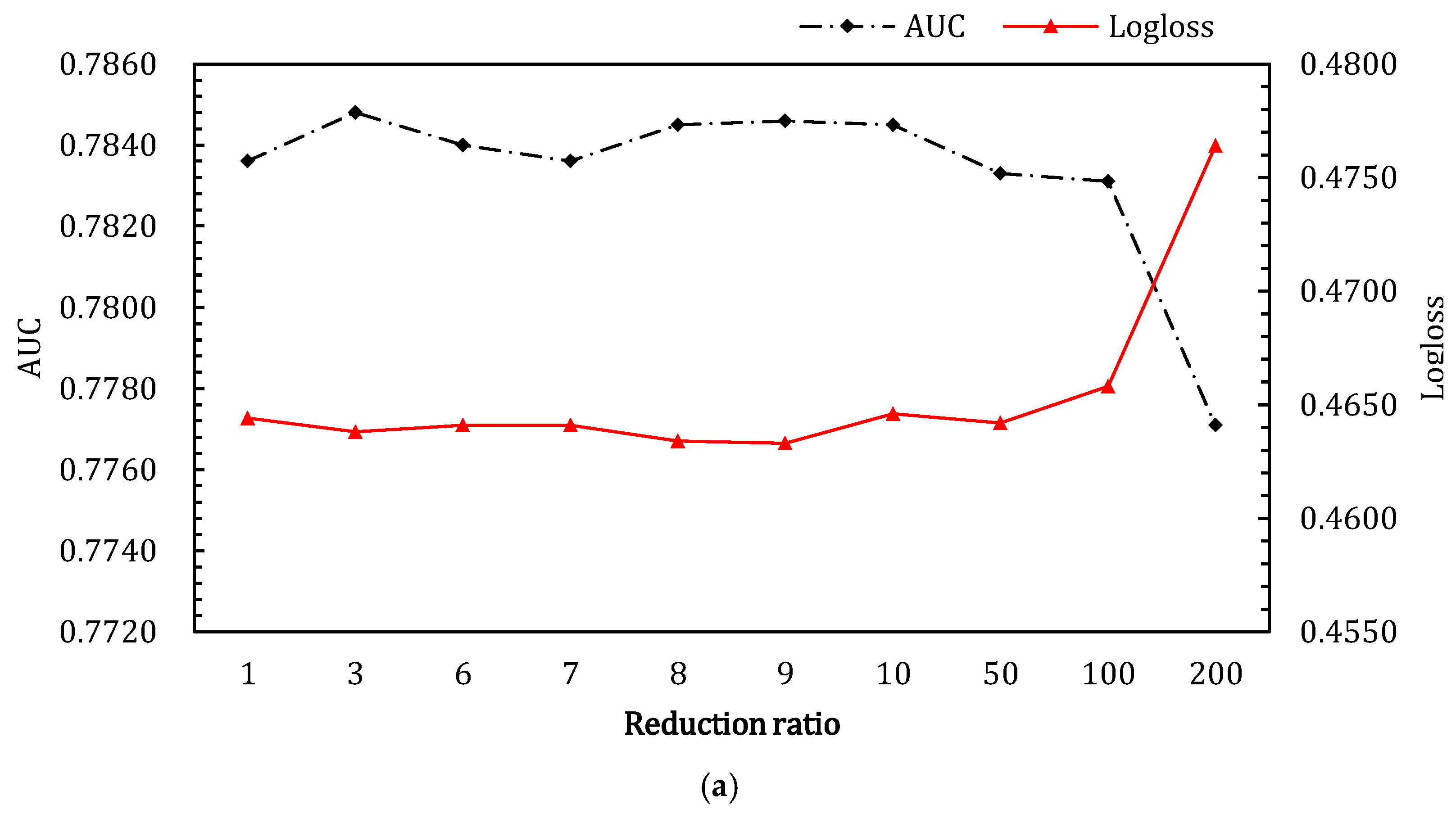
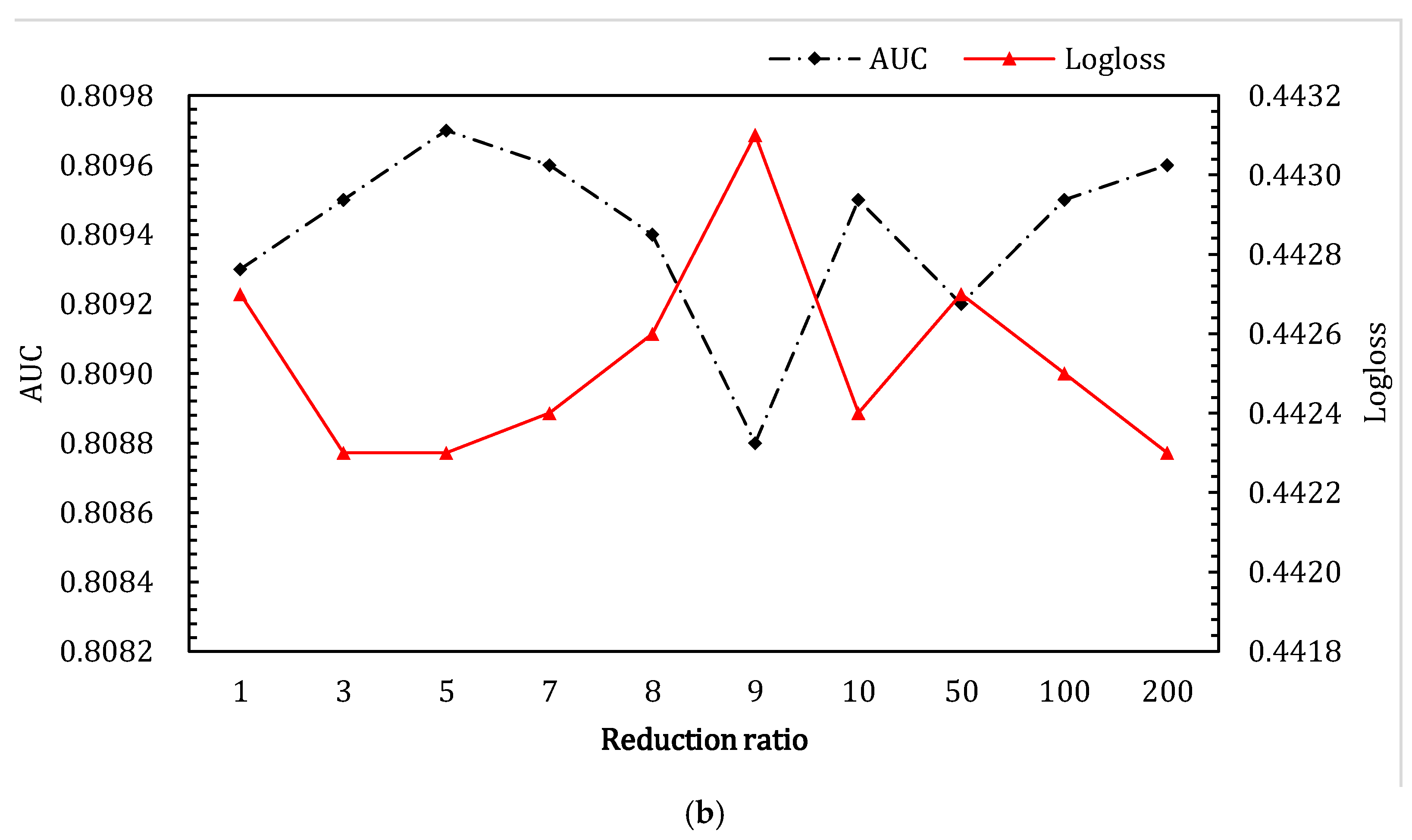
4.3.3. The Reduction Ratio in SENet
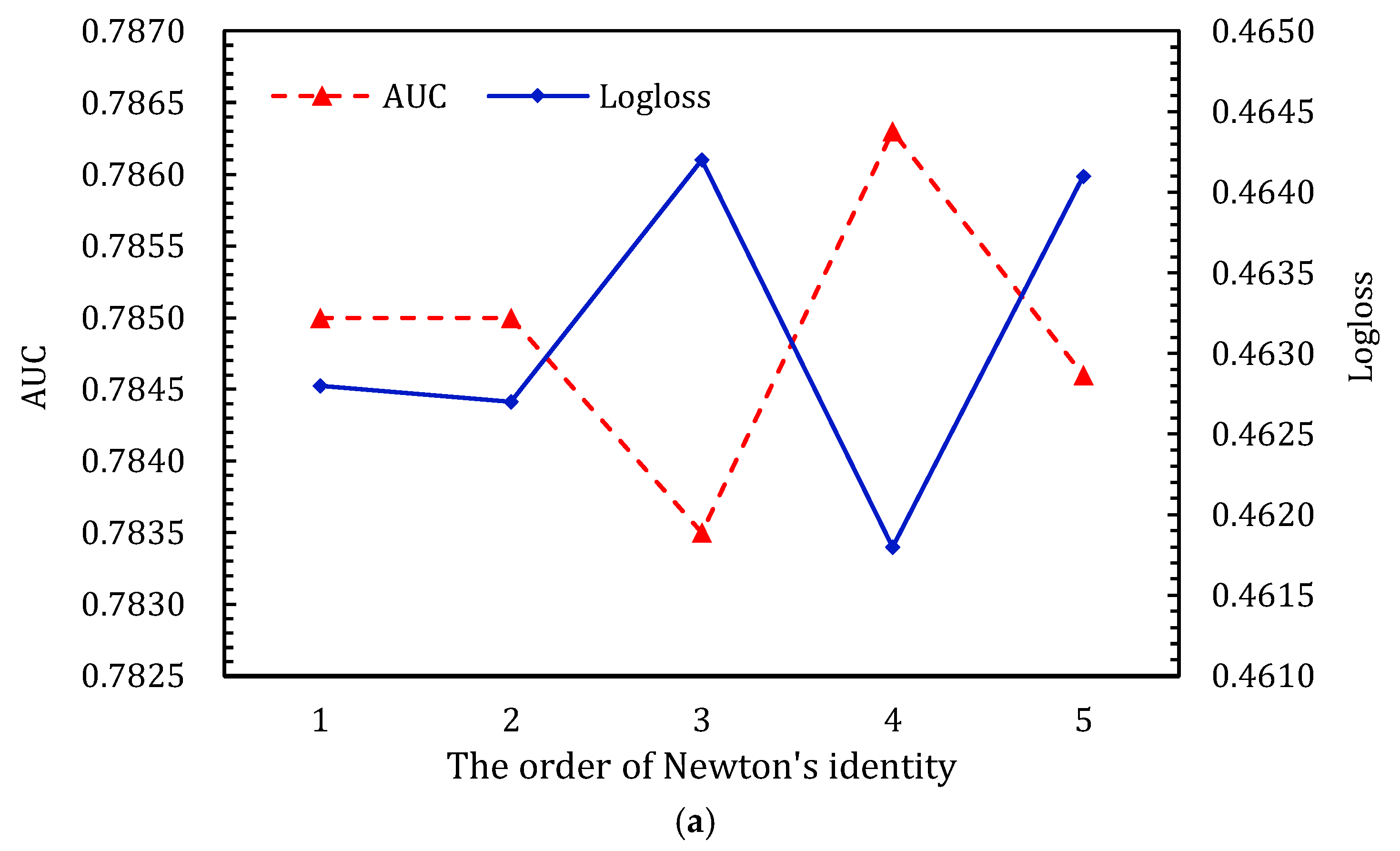
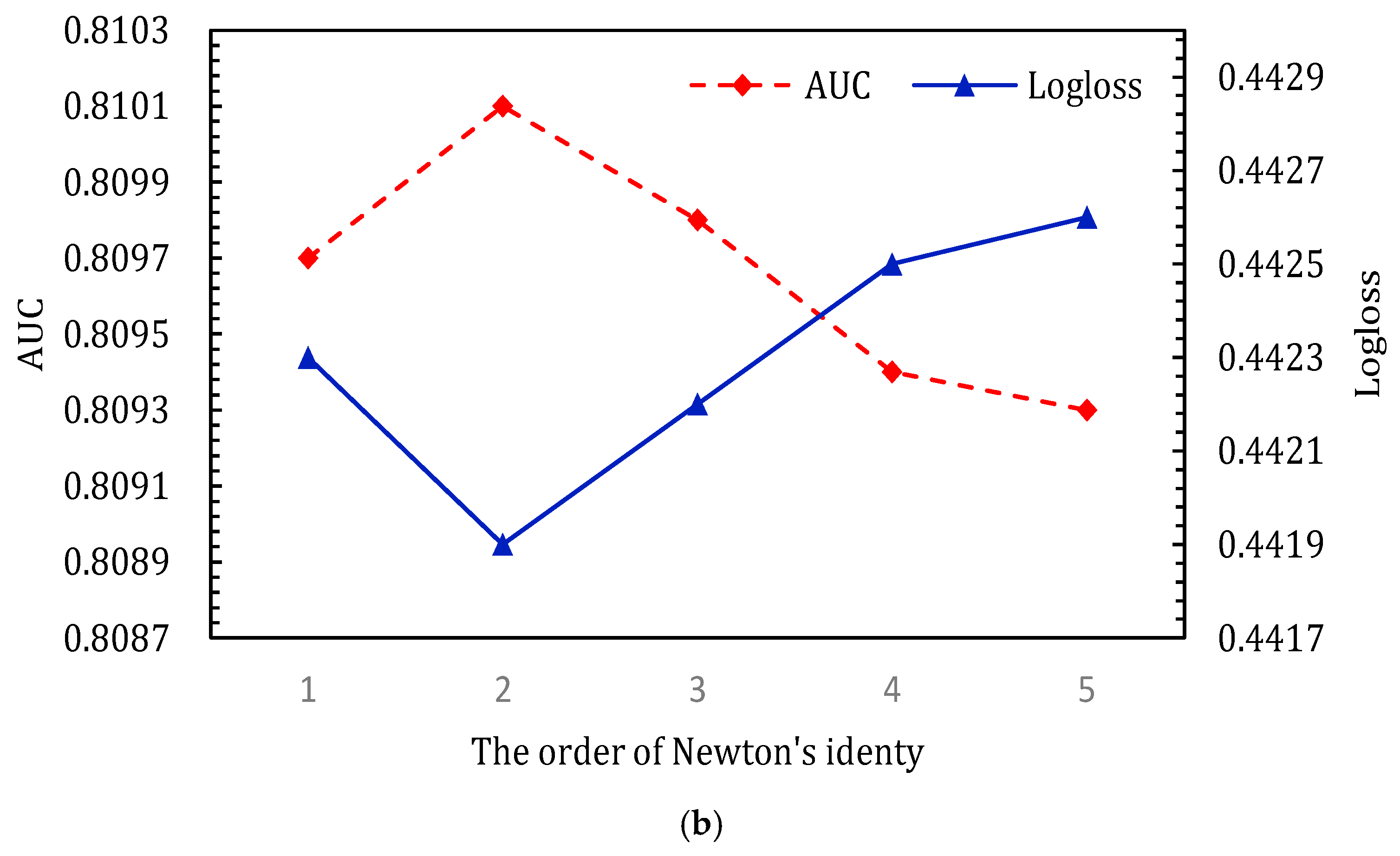
4.3.4. The Order in Newton’s Identity
4.4. Ablation Study
- The variant ALIN w/o NI, also known as ALN, outperforms ALN w/o SE, indicating that SENet is beneficial for improving CTR performance. This also shows that it is necessary to consider the importance of feature interactions using SENet;
- Comparing ALIN w/o NI to ALIN, we can see that ALIN outperforms ALIN w/o NI, which indicates that Newton’s identity can further complement feature interactions to reduce the noise caused by LNN;
- We can see from the comparison between ALN w/o se and ALIN that the two strategies proposed in this paper significantly enhance CTR performance in both datasets.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Moon, Y.; Kwon, C. Online advertisement service pricing and an option contract. Electron. Commer. Res. Appl. 2011, 10, 38–48. [Google Scholar] [CrossRef] [Green Version]
- Pan, J.; Xu, J.; Ruiz, A.L.; Zhao, W.; Pan, S.; Sun, Y.; Lu, Q. Field-weighted factorization machines for click-through rate prediction in display advertising. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1349–1357. [Google Scholar]
- Lu, W.; Yu, Y.; Chang, Y.; Wang, Z.; Li, C.; Yuan, B. A dual input-aware factorization machine for CTR prediction. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 3139–3145. [Google Scholar]
- Hu, L.; Li, C.; Shi, C.; Yang, C.; Shao, C. Graph neural news recommendation with long-term and short-term interest modeling. Inf. Process. Manag. 2020, 57, 102142. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.; Wu, F.; Ge, S.; Qi, T.; Huang, Y.; Xie, X. Neural news recommendation with multi-head self-attention. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 6389–6394. [Google Scholar]
- Wang, H.; Wu, F.; Liu, Z.; Xie, X. Fine-grained interest matching for neural news recommendation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 836–845. [Google Scholar]
- Li, C.; Liu, Z.; Wu, M.; Xu, Y.; Huang, P.; Zhao, H.; Kang, C.; Chen, Q.; Li, W.; Lee, D.L. Multi-interest network with dynamic routing for recommendation at Tmall. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2615–2623. [Google Scholar]
- Cen, Y.; Zhang, J.; Zou, X.; Zhou, C.; Yang, H.; Tang, J. Controllable multi-interest framework for recommendation. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, San Digeo, CA, USA, 22–27 August 2020; pp. 2942–2951. [Google Scholar]
- Li, D.; Hu, B.; Chen, Q.; Wang, X.; Qi, Q.; Wang, L.; Liu, H. Attentive capsule network for click-through rate and conversion rate prediction in online advertising. Knowl.-Based Syst. 2021, 211, 106522. [Google Scholar] [CrossRef]
- Li, Z.; Cui, Z.; Wu, S.; Zhang, X.-Y.; Wang, L. Fi-gnn: Modeling feature interactions via graph neural networks for ctr prediction. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 539–548. [Google Scholar]
- Rendle, S. Factorization machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Washington, DC, USA, 13 December 2010; IEEE: Piscataway Township, NJ, USA, 2010; pp. 995–1000. [Google Scholar]
- Juan, Y.; Zhuang, Y.; Chin, W.S.; Lin, C.-J. Field-aware factorization machines for CTR prediction. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 43–50. [Google Scholar]
- Xiao, J.; Ye, H.; He, X.; Zhang, H.; Wu, F.; Chua, T.-S. Attentional factorization machines: Learning the weight of feature interactions via attention networks. arXiv 2017, arXiv:1708.04617, 2017. [Google Scholar]
- Blondel, M.; Fujino, A.; Ueda, N.; Ishihata, M. Higher-order factorization machines. Adv. Neural Inf. Process. Syst. 2016, 29, 3359–3367. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao HY, M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Xu, X.; Zhao, M.; Shi, P.; Ren, R.; He, X.; Wei, X.; Yang, H. Crack Detection and Comparison Study Based on Faster R-CNN and Mask R-CNN. Sensors 2022, 22, 1215. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 15. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473,. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, New York, NY, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Richardson, M.; Dominowska, E.; Ragno, R. Predicting clicks: Estimating the click-through rate for new ads. In Proceedings of the 16th International Conference on World Wide Web, New York, NY, USA, 8–12 May 2007; pp. 521–530. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. arXiv 2017, arXiv:1703.04247, 2017. [Google Scholar]
- Yang, X.; Liu, Q.; Su, R.; Tang, R.; Liu, Z.; He, X.; Yang, J. Click-through rate prediction using transfer learning with fine-tuned parameters. Inf. Sci. 2022, 612, 188–200. [Google Scholar] [CrossRef]
- Lian, J.; Zhou, X.; Zhang, F.; Chen, Z.; Xie, X.; Sun, C. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 19–23 August 2018; pp. 1754–1763. [Google Scholar]
- Zhang, J.; Ma, C.; Zhong, C.; Zhao, P.; Mu, X. Multi-scale and multi-channel neural network for click-through rate prediction. Neurocomputing 2022, 480, 157–168. [Google Scholar] [CrossRef]
- Jose, A.; Shetty, S.D. Interpretable click-through rate prediction through distillation of the neural additive factorization model. Inf. Sci. 2022, 617, 91–102. [Google Scholar] [CrossRef]
- Hines, J.W. A logarithmic neural network architecture for unbounded non-linear function approximation. In Proceedings of the International Conference on Neural Networks (ICNN’96), Washington, DC, USA, 3–6 June 1996; IEEE: Piscataway Township, NJ, USA, 1996; Volume 2, pp. 1245–1250. [Google Scholar]
- Cheng, W.; Shen, Y.; Huang, L. Adaptive factorization network: Learning adaptive-order feature interactions. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3609–3616. [Google Scholar]
- Mead, D.G. Newton’s identities. Am. Math. Mon. 1992, 99, 749–751. [Google Scholar] [CrossRef]
- Yu, F.; Liu, Z.; Liu, Q.; Zhang, H.; Wu, S.; Wang, L. Deep interaction machine: A simple but effective model for high-order feature interactions. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, 19–23 October 2020; pp. 2285–2288. [Google Scholar]
- Wang, R.; Fu, B.; Fu, G.; Wang, M. Deep & cross network for ad click predictions. In Proceedings of the ADKDD’17, Halifax, NS, Canada, 14 August 2017; pp. 1–7. [Google Scholar]
- Qu, Y.; Cai, H.; Ren, K.; Zhang, W.; Yu, Y.; Wen, Y.; Wang, J. Product-based neural networks for user response prediction. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; IEEE: Piscataway Township, NJ, USA, 2016; pp. 1149–1154. [Google Scholar]
- He, X.; Chua, T.S. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 355–364. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Yang, H.; Daneshkhah, E.; Augello, R.; Xu, X.; Carrera, E. Numerical vibration correlation technique for thin-walled composite beams under compression based on accurate refined finite element. Compos. Struct. 2022, 280, 114861. [Google Scholar] [CrossRef]
- Fielding, A.H.; Bell, J.F. A review of methods for the assessment of prediction errors in conservation presence/absence models. Environ. Conserv. 1997, 24, 38–49. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Instances | #Train | #Valid | #Test | #Fields |
|---|---|---|---|---|---|
| Criteo_600K | 600,000 | 480,000 | 60,000 | 60,000 | 39 |
| Criteo | 45,840,617 | 36,672,495 | 4,584,061 | 4,584,061 | 39 |
| Model Type | Model | Criteo_600K | Criteo | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AUC | RIAUC | Log loss | RILogloss | AUC | RIAUC | Log loss | RILog loss | ||
| First-order | LR | 0.7657 | 0.0% | 0.4858 | 0.0% | 0.7920 | 0.0% | 0.4578 | 0.0% |
| Second-order | FM | 0.7804 | 1.90% | 0.4684 | 3.58% | 0.7997 | 0.97% | 0.4517 | 1.33% |
| AFM | 0.7665 | 0.10% | 0.4809 | 1.01% | 0.7968 | 0.61% | 0.4547 | 0.68% | |
| High-order | NFM | 0.7838 | 2.36% | 0.4664 | 3.99% | 0.8027 | 1.35% | 0.4488 | 1.97% |
| PNN | 0.7829 | 2.25% | 0.4724 | 2.76% | 0.8085 | 2.08% | 0.4435 | 3.12% | |
| AFN | 0.7827 | 2.22% | 0.4665 | 3.97% | 0.8087 | 2.11% | 0.4431 | 3.21% | |
| ALN | 0.7848 | 2.49% | 0.4638 | 4.53% | 0.8097 | 2.23% | 0.4423 | 3.39% | |
| Ensemble model | Wide & Deep | 0.7827 | 2.22% | 0.4661 | 4.06% | 0.8063 | 1.81% | 0.4460 | 2.58% |
| DeepFM | 0.7832 | 2.29% | 0.4659 | 4.10% | 0.8049 | 1.63% | 0.4470 | 2.36% | |
| AFN+ | 0.7847 | 2.48% | 0.4656 | 4.16% | 0.8100 | 2.27% | 0.4420 | 3.45% | |
| ALIN | 0.7863 | 2.69% | 0.4618 | 4.94% | 0.8101 | 2.29% | 0.4419 | 3.47% | |
| Model | Time (s) | Params |
|---|---|---|
| AFN | 274.95 | 15,490.25 K |
| ALN | 330.20 | 16,390.25 K |
| AFN+ | 368.20 | 25,077.34 K |
| ALIN | 339.70 | 16,390.28 K |
| Variant | Criteo_600K | Criteo | ||
|---|---|---|---|---|
| AUC | Log Loss | AUC | Log Loss | |
| ALN w/o SE | 0.7827 | 0.4665 | 0.8087 | 0.4431 |
| ALIN w/o NI | 0.7848 | 0.4638 | 0.8097 | 0.4423 |
| ALIN | 0.7863 | 0.4618 | 0.8101 | 0.4419 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Cui, Z.; Pei, Y. A Dual Adaptive Interaction Click-Through Rate Prediction Based on Attention Logarithmic Interaction Network. Entropy 2022, 24, 1831. https://doi.org/10.3390/e24121831
Li S, Cui Z, Pei Y. A Dual Adaptive Interaction Click-Through Rate Prediction Based on Attention Logarithmic Interaction Network. Entropy. 2022; 24(12):1831. https://doi.org/10.3390/e24121831
Chicago/Turabian StyleLi, Shiqi, Zhendong Cui, and Yongquan Pei. 2022. "A Dual Adaptive Interaction Click-Through Rate Prediction Based on Attention Logarithmic Interaction Network" Entropy 24, no. 12: 1831. https://doi.org/10.3390/e24121831