
Thermodynamics of the Ising Model Encoded in Restricted Boltzmann Machines

Abstract
:1. Introduction
2. Models and Methods
2.1. Dataset of Ising Configurations Generated by Monte Carlo Simulations
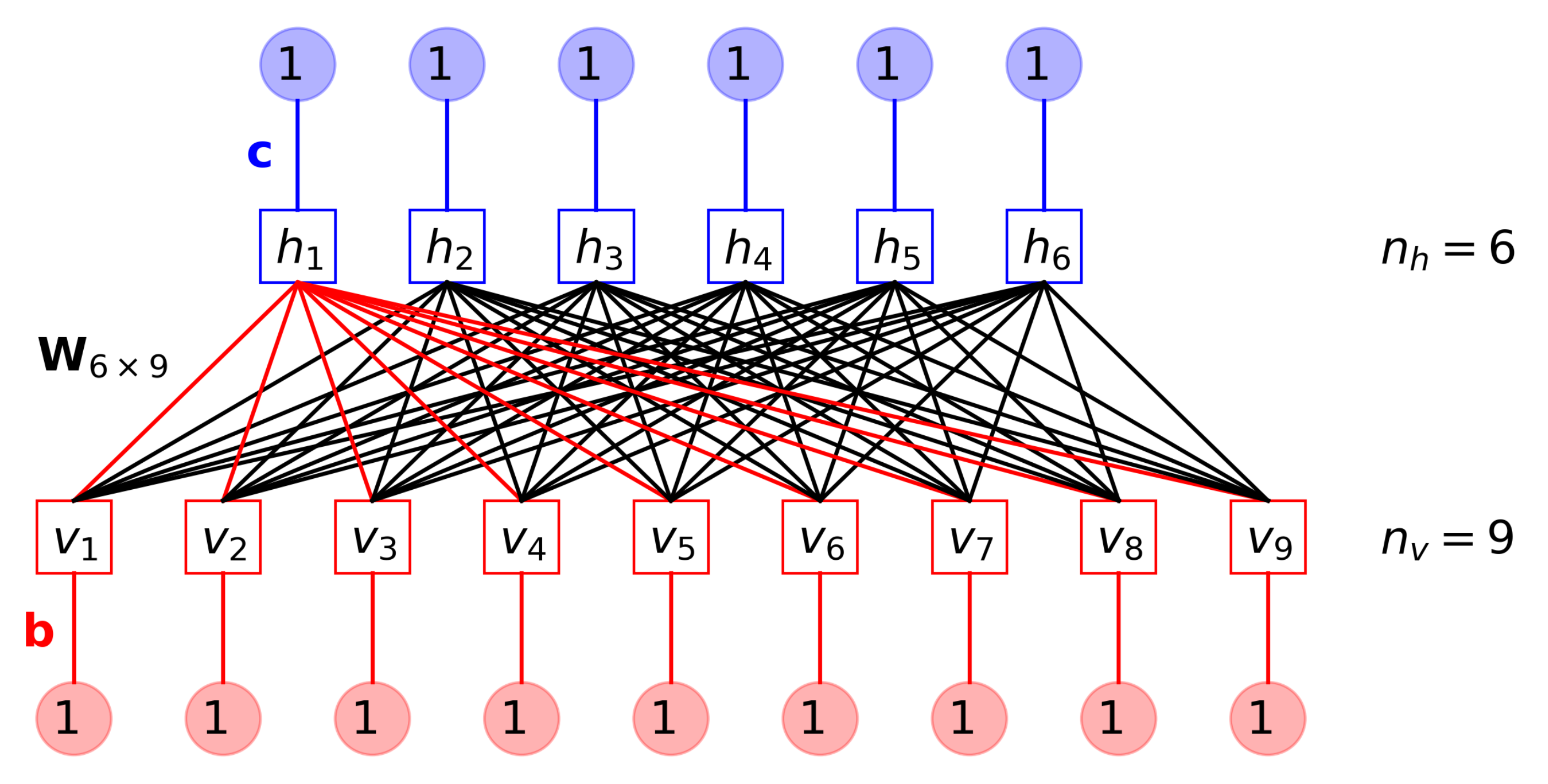
2.2. Restricted Boltzmann Machine
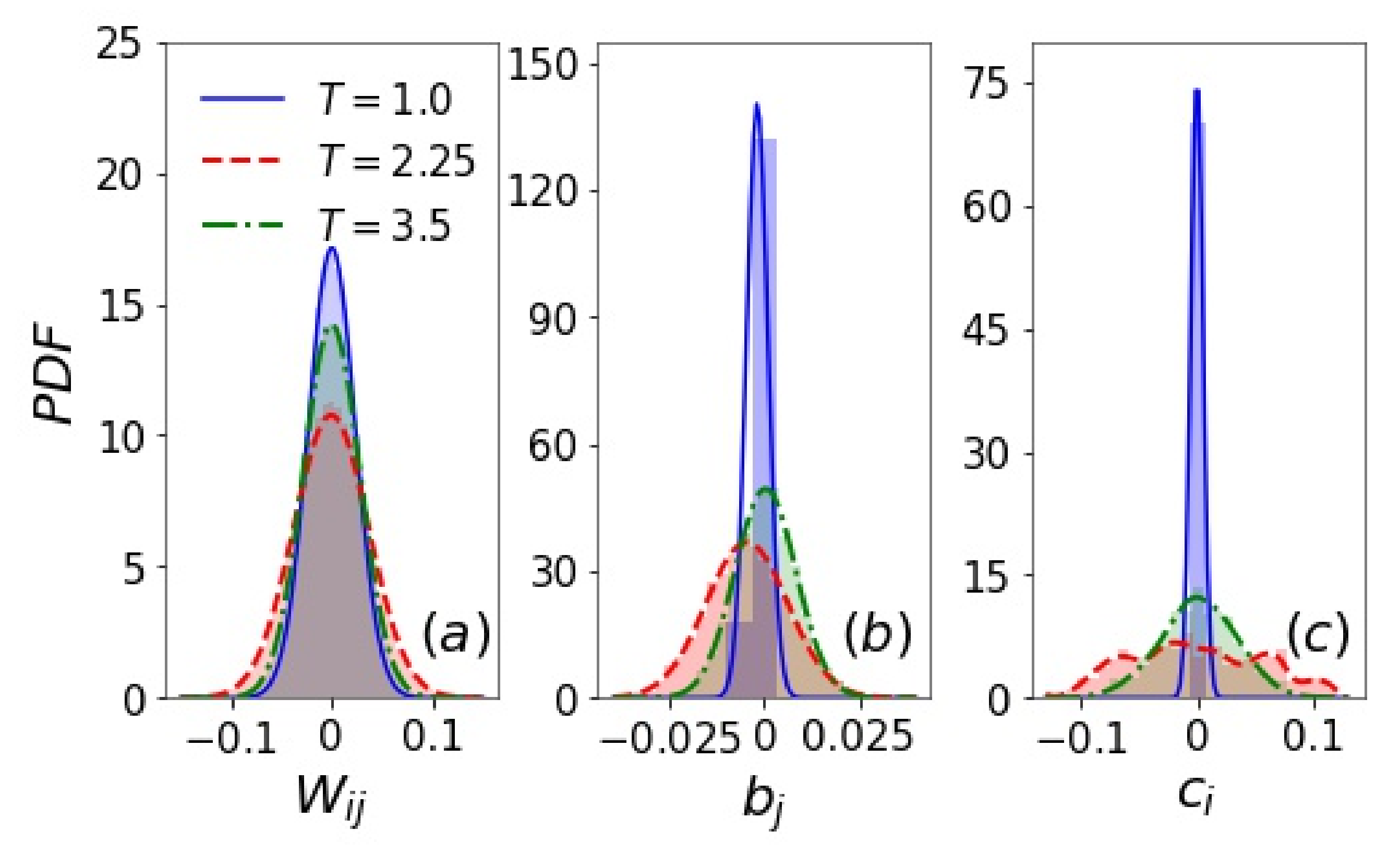
2.3. Loss Function and Training of RBMs
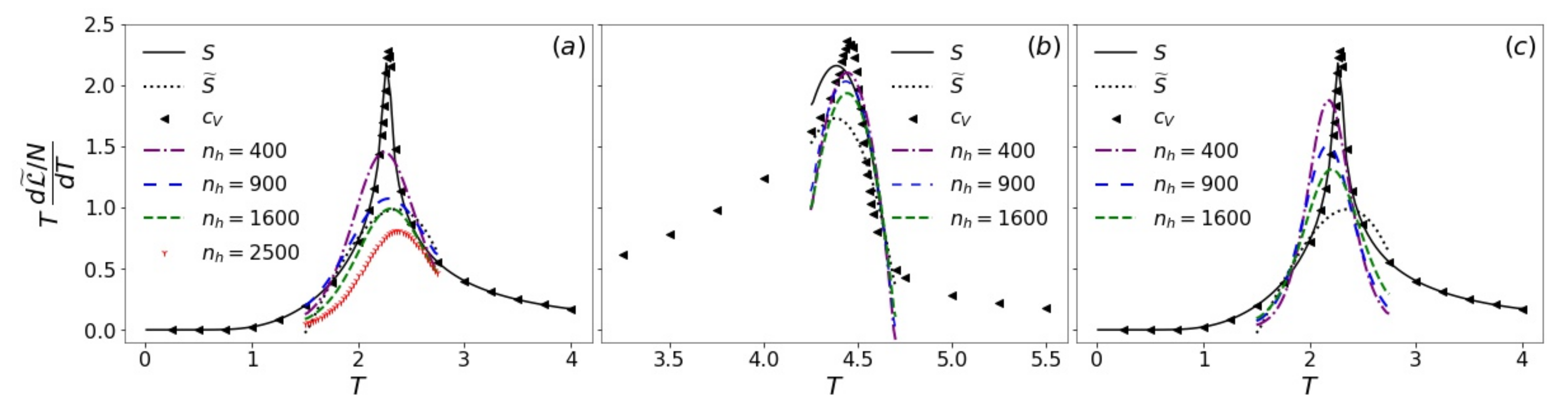
3. Results and Discussion
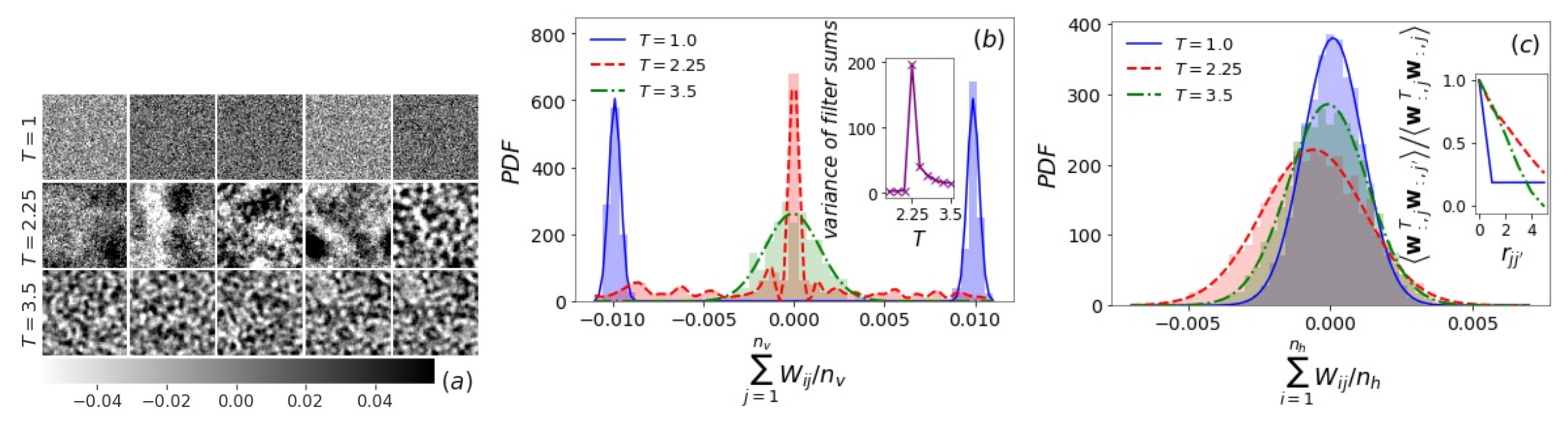
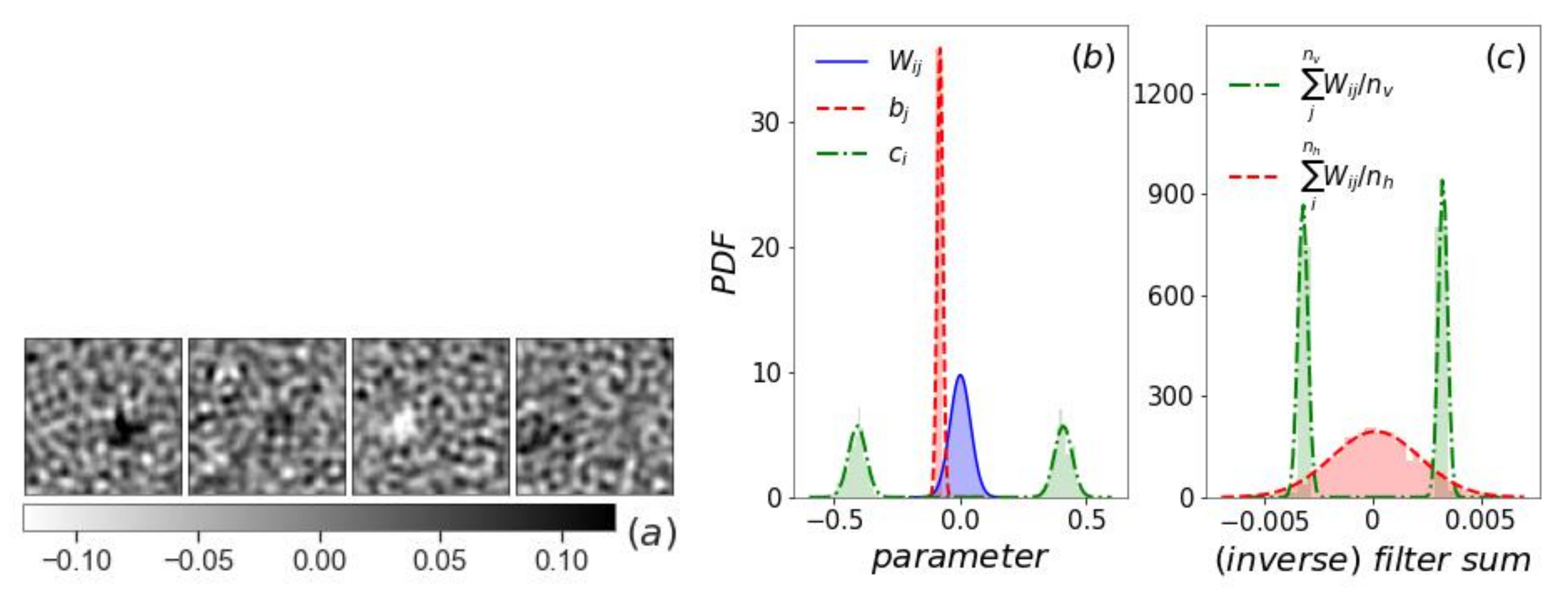
3.1. Filters and Inverse Filters
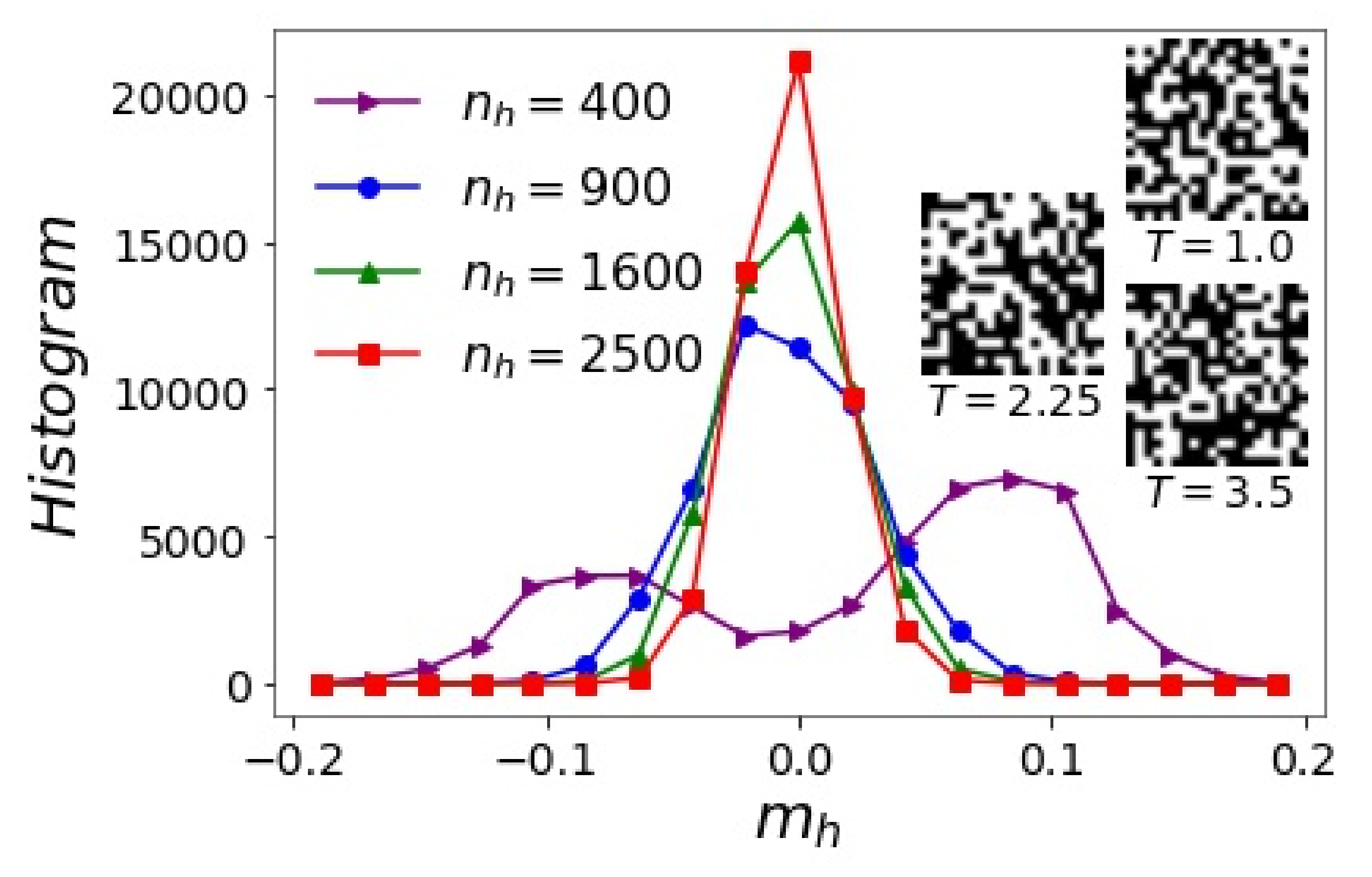
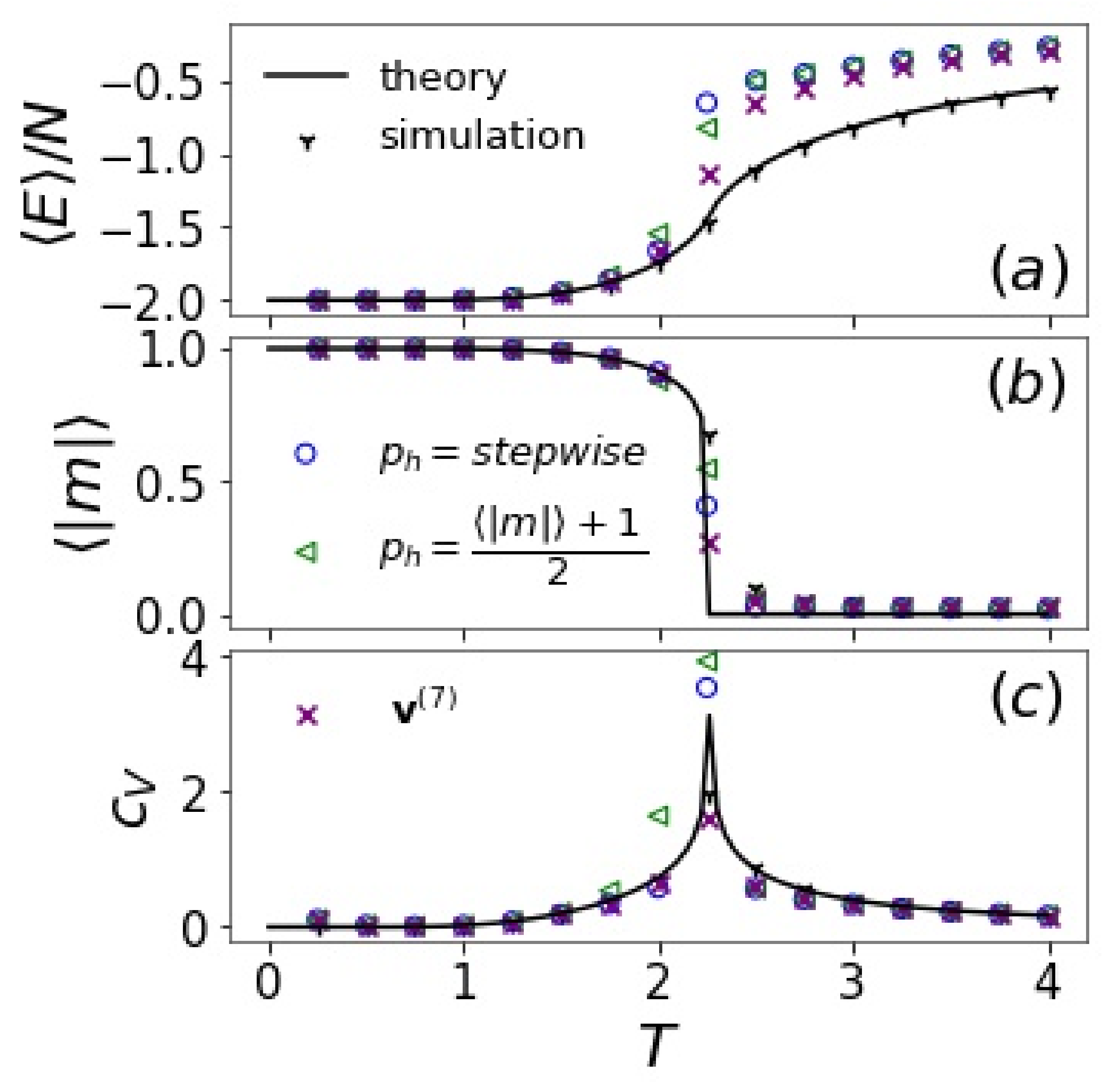
3.2. Hidden Layer
- At low , if , ; if , . This will be an encoding of an ferromagnetic configuration. To encode of an ferromagnetic configuration, just flip the sign of .
- At high , randomly assign or with equal probability. This will be an encoding of a paramagnetic configuration with .
- At intermediate , to encode an Ising configuration, if , assign with probability and with probability ; if , assign with probability and with probability . is a predetermined parameter, and the above two algorithms are just the special cases with () and (), respectively. In practice, one may approximately use or use linear interpolation within , .
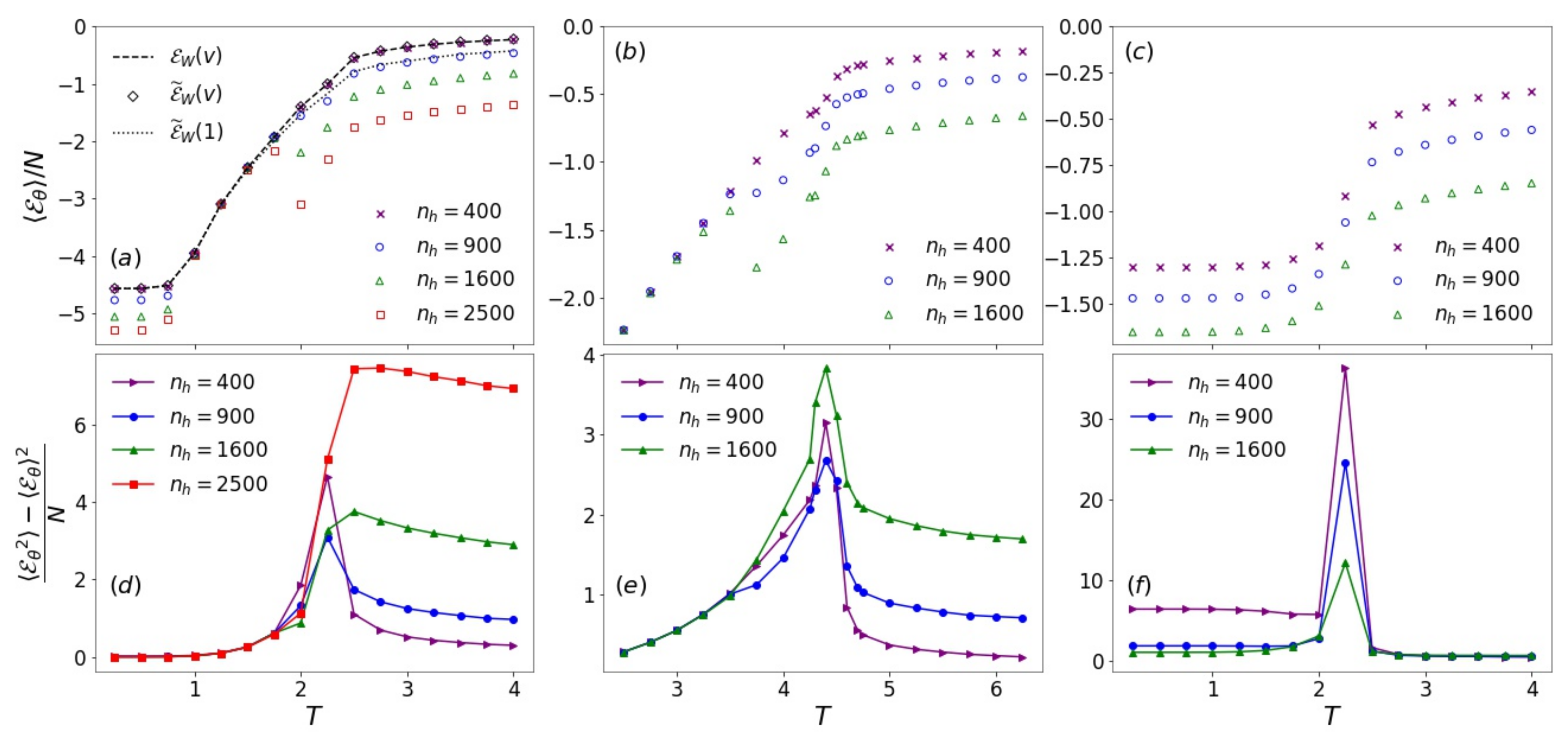
3.3. Visible Energy
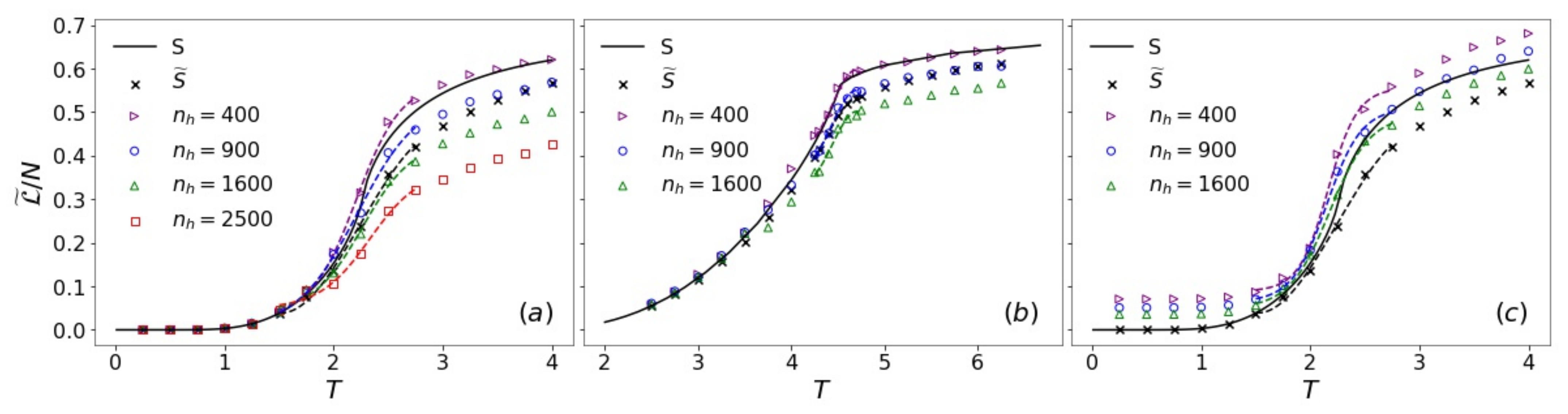
3.4. Pseudo-Likelihood and Entropy Estimation
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| RBM | restricted Boltzmann machine |
| T-RBM | single-temperature restricted Boltzmann machine |
| -RBM | all-temperature restricted Boltzmann machine |
Appendix A. Statistical Thermodynamics of Ising Model
Appendix B. Energy and Probability of RBMs
Appendix C. Maximum Likelihood Estimation and Gradient Descent of RBMs
- k Step contrastive divergence (CD-k):For each parameter update, draw (or a minibatch) from the training data and run Gibbs sampling for k steps. Even CD-1 can work reasonably well.
- Persistent contrastive divergence (PCD-k):Always keep the same MC during the entire training process. For each parameter update, run this persistent MC for another k steps to collect states.
References
- Carleo, G.; Cirac, I.; Cranmer, K.; Daudet, L.; Schuld, M.; Tishby, N.; Vogt-Maranto, L.; Zdeborová, L. Machine learning and the physical sciences. Rev. Mod. Phys. 2019, 91, 045002. [Google Scholar] [CrossRef] [Green Version]
- Bahri, Y.; Kadmon, J.; Pennington, J.; Schoenholz, S.S.; Sohl-Dickstein, J.; Ganguli, S. Statistical mechanics of deep learning. Annu. Rev. Condens. Matter Phys. 2020, 11, 501. [Google Scholar] [CrossRef] [Green Version]
- Lin, H.W.; Tegmark, M.; Rolnick, D. Why does deep and cheap learning work so well? J. Stat. Phys. 2017, 168, 1223–1247. [Google Scholar] [CrossRef] [Green Version]
- Ballard, A.J.; Das, R.; Martiniani, S.; Mehta, D.; Sagun, L.; Stevenson, J.D.; Wales, D.J. Energy landscapes for machine learning. Phys. Chem. Chem. Phys. 2017, 19, 12585–12603. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Saxe, A.M.; Advani, M.S.; Lee, A.A. Energy–entropy competition and the effectiveness of stochastic gradient descent in machine learning. Mol. Phys. 2018, 116, 3214–3223. [Google Scholar] [CrossRef] [Green Version]
- Baity-Jesi, M.; Sagun, L.; Geiger, M.; Spigler, S.; Arous, G.B.; Cammarota, C.; LeCun, Y.; Wyart, M.; Biroli, G. Comparing dynamics: Deep neural networks versus glassy systems. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2018; pp. 314–323. [Google Scholar]
- Geiger, M.; Spigler, S.; d’Ascoli, S.; Sagun, L.; Baity-Jesi, M.; Biroli, G.; Wyart, M. Jamming transition as a paradigm to understand the loss landscape of deep neural networks. Phys. Rev. E 2019, 100, 012115. [Google Scholar] [CrossRef] [Green Version]
- Feng, Y.; Tu, Y. The inverse variance–flatness relation in stochastic gradient descent is critical for finding flat minima. Proc. Natl. Acad. Sci. USA 2021, 118, e2015617118. [Google Scholar] [CrossRef]
- Roberts, D.A.; Yaida, S.; Hanin, B. The Principles of Deep Learning Theory: An Effective Theory Approach to Understanding Neural Networks; Cambridge University Press: New York, NY, USA, 2022. [Google Scholar]
- Zdeborová, L.; Krzakala, F. Statistical physics of inference: Thresholds and algorithms. Adv. Phys. 2016, 65, 453–552. [Google Scholar] [CrossRef] [Green Version]
- Behler, J.; Parrinello, M. Generalized neural-network representation of high-dimensional potential-energy surfaces. Phys. Rev. Lett. 2007, 98, 146401. [Google Scholar] [CrossRef]
- Carrasquilla, J.; Melko, R.G. Machine learning phases of matter. Nat. Phys. 2017, 13, 431–434. [Google Scholar] [CrossRef]
- Tibaldi, S.; Magnifico, G.; Vodola, D.; Ercolessi, E. Unsupervised and supervised learning of interacting topological phases from single-particle correlation functions. arXiv 2022, arXiv:2202.09281. [Google Scholar]
- Bapst, V.; Keck, T.; Grabska-Barwińska, A.; Donner, C.; Cubuk, E.D.; Schoenholz, S.S.; Obika, A.; Nelson, A.W.; Back, T.; Hassabis, D.; et al. Unveiling the predictive power of static structure in glassy systems. Nat. Phys. 2020, 16, 448–454. [Google Scholar] [CrossRef]
- Iten, R.; Metger, T.; Wilming, H.; del Rio, L.; Renner, R. Discovering physical concepts with neural networks. Phys. Rev. Lett. 2020, 124, 010508. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bedolla, E.; Padierna, L.C.; Castaneda-Priego, R. Machine learning for condensed matter physics. J. Phys. Condens. Matter 2020, 33, 053001. [Google Scholar] [CrossRef]
- Cichos, F.; Gustavsson, K.; Mehlig, B.; Volpe, G. Machine learning for active matter. Nat. Mach. Intell. 2020, 2, 94–103. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Smolensky, P. Information processing in dynamical systems: Foundations of harmony theory. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition; MIT Press: Cambridge, MA, USA, 1986; pp. 194–281. [Google Scholar]
- Sherrington, D.; Kirkpatrick, S. Solvable model of a spin-glass. Phys. Rev. Lett. 1975, 35, 1792. [Google Scholar] [CrossRef]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for Boltzmann machines. Cogn. Sci. 1985, 9, 147–169. [Google Scholar] [CrossRef]
- Cocco, S.; Monasson, R. Adaptive cluster expansion for inferring Boltzmann machines with noisy data. Phys. Rev. Lett. 2011, 106, 090601. [Google Scholar] [CrossRef] [Green Version]
- Aurell, E.; Ekeberg, M. Inverse Ising inference using all the data. Phys. Rev. Lett. 2012, 108, 090201. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, H.C.; Zecchina, R.; Berg, J. Inverse statistical problems: From the inverse Ising problem to data science. Adv. Phys. 2017, 66, 197–261. [Google Scholar] [CrossRef]
- Huang, L.; Wang, L. Accelerated Monte Carlo simulations with restricted Boltzmann machines. Phys. Rev. B 2017, 95, 035105. [Google Scholar] [CrossRef] [Green Version]
- Carleo, G.; Troyer, M. Solving the quantum many-body problem with artificial neural networks. Science 2017, 355, 602–606. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Melko, R.G.; Carleo, G.; Carrasquilla, J.; Cirac, J.I. Restricted Boltzmann machines in quantum physics. Nat. Phys. 2019, 15, 887–892. [Google Scholar] [CrossRef]
- Yu, W.; Liu, Y.; Chen, Y.; Jiang, Y.; Chen, J.Z. Generating the conformational properties of a polymer by the restricted Boltzmann machine. J. Chem. Phys. 2019, 151, 031101. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mehta, P.; Schwab, D.J. An exact mapping between the variational renormalization group and deep learning. arXiv 2014, arXiv:1410.3831. [Google Scholar]
- Chen, J.; Cheng, S.; Xie, H.; Wang, L.; Xiang, T. Equivalence of restricted Boltzmann machines and tensor network states. Phys. Rev. B 2018, 97, 085104. [Google Scholar] [CrossRef] [Green Version]
- Salazar, D.S. Nonequilibrium thermodynamics of restricted Boltzmann machines. Phys. Rev. E 2017, 96, 022131. [Google Scholar] [CrossRef] [Green Version]
- Decelle, A.; Fissore, G.; Furtlehner, C. Thermodynamics of restricted Boltzmann machines and related learning dynamics. J. Stat. Phys. 2018, 172, 1576–1608. [Google Scholar] [CrossRef] [Green Version]
- Decelle, A.; Furtlehner, C. Restricted Boltzmann machine: Recent advances and mean-field theory. Chin. Phys. B 2021, 30, 040202. [Google Scholar] [CrossRef]
- LeCun, Y. A path towards autonomous machine intelligence. Openreview 2022. Available online: https://openreview.net/forum?id=BZ5a1r-kVsf (accessed on 17 October 2022).
- Torlai, G.; Melko, R.G. Learning thermodynamics with Boltzmann machines. Phys. Rev. B 2016, 94, 165134. [Google Scholar] [CrossRef] [Green Version]
- Morningstar, A.; Melko, R.G. Deep Learning the Ising Model Near Criticality. J. Mach. Learn. Res. 2018, 18, 1–17. [Google Scholar]
- D’Angelo, F.; Böttcher, L. Learning the Ising model with generative neural networks. Phys. Rev. Res. 2020, 2, 023266. [Google Scholar] [CrossRef]
- Iso, S.; Shiba, S.; Yokoo, S. Scale-invariant feature extraction of neural network and renormalization group flow. Phys. Rev. E 2018, 97, 053304. [Google Scholar] [CrossRef] [Green Version]
- Funai, S.S.; Giataganas, D. Thermodynamics and feature extraction by machine learning. Phys. Rev. Res. 2020, 2, 033415. [Google Scholar] [CrossRef]
- Koch, E.D.M.; Koch, R.D.M.; Cheng, L. Is deep learning a renormalization group flow? IEEE Access 2020, 8, 106487–106505. [Google Scholar] [CrossRef]
- Veiga, R.; Vicente, R. Restricted Boltzmann Machine Flows and The Critical Temperature of Ising models. arXiv 2020, arXiv:2006.10176. [Google Scholar]
- Funai, S.S. Feature extraction of machine learning and phase transition point of Ising model. arXiv 2021, arXiv:2111.11166. [Google Scholar]
- Wang, L. Discovering phase transitions with unsupervised learning. Phys. Rev. B 2016, 94, 195105. [Google Scholar] [CrossRef] [Green Version]
- Hu, W.; Singh, R.R.; Scalettar, R.T. Discovering phases, phase transitions, and crossovers through unsupervised machine learning: A critical examination. Phys. Rev. E 2017, 95, 062122. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wetzel, S.J. Unsupervised learning of phase transitions: From principal component analysis to variational autoencoders. Phys. Rev. E 2017, 96, 022140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tanaka, A.; Tomiya, A. Detection of phase transition via convolutional neural networks. J. Phys. Soc. Jpn. 2017, 86, 063001. [Google Scholar] [CrossRef] [Green Version]
- Kashiwa, K.; Kikuchi, Y.; Tomiya, A. Phase transition encoded in neural network. Prog. Theor. Exp. Phys. 2019, 2019, 083A04. [Google Scholar] [CrossRef] [Green Version]
- Cipra, B.A. An introduction to the Ising model. Am. Math. Mon. 1987, 94, 937–959. [Google Scholar] [CrossRef]
- Newman, M.E.J.; Barkema, G.T. Monte Carlo Methods in Statistical Physics; Oxford University: Oxford, UK, 1999. [Google Scholar]
- Kramers, H.A.; Wannier, G.H. Statistics of the Two-Dimensional Ferromagnet: Part I. Phys. Rev. 1941, 60, 252–262. [Google Scholar] [CrossRef]
- Onsager, L. Crystal statistics. I. A two-dimensional model with an order-disorder transition. Phys. Rev. 1944, 65, 117. [Google Scholar] [CrossRef]
- Yang, C.N. The Spontaneous Magnetization of a Two-Dimensional Ising Model. Phys. Rev. 1952, 85, 808–816. [Google Scholar] [CrossRef]
- Plischke, M.; Bergersen, B. Equilibrium Statistical Physics; World Scientific: Singapore, 1994. [Google Scholar]
- Landau, D.; Binder, K. A Guide to Monte Carlo Simulations in Statistical Physics; Cambridge University Press: New York, NY, USA, 2021. [Google Scholar]
- Fischer, A.; Igel, C. An introduction to restricted Boltzmann machines. In Proceedings of the Iberoamerican Congress on Pattern Recognition, Havana, Cuba, 28–31 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 14–36. [Google Scholar]
- Oh, S.; Baggag, A.; Nha, H. Entropy, free energy, and work of restricted boltzmann machines. Entropy 2020, 22, 538. [Google Scholar] [CrossRef]
- Huang, H.; Toyoizumi, T. Advanced mean-field theory of the restricted Boltzmann machine. Phys. Rev. E 2015, 91, 050101(R). [Google Scholar] [CrossRef] [Green Version]
- Cossu, G.; Del Debbio, L.; Giani, T.; Khamseh, A.; Wilson, M. Machine learning determination of dynamical parameters: The Ising model case. Phys. Rev. B 2019, 100, 064304. [Google Scholar] [CrossRef] [Green Version]
- Besag, J. Statistical analysis of non-lattice data. J. R. Stat. Soc. Ser. D 1975, 24, 179–195. [Google Scholar] [CrossRef] [Green Version]
- LISA. Deep Learning Tutorials. 2018. Available online: https://github.com/lisa-lab/DeepLearningTutorials (accessed on 1 August 2022).
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Rao, W.J.; Li, Z.; Zhu, Q.; Luo, M.; Wan, X. Identifying product order with restricted Boltzmann machines. Phys. Rev. B 2018, 97, 094207. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Wang, L.; Zhang, P. Solving statistical mechanics using variational autoregressive networks. Phys. Rev. Lett. 2019, 122, 080602. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nicoli, K.A.; Nakajima, S.; Strodthoff, N.; Samek, W.; Müller, K.R.; Kessel, P. Asymptotically unbiased estimation of physical observables with neural samplers. Phys. Rev. E 2020, 101, 023304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yevick, D.; Melko, R. The accuracy of restricted Boltzmann machine models of Ising systems. Comput. Phys. Commun. 2021, 258, 107518. [Google Scholar] [CrossRef]
- Ferrenberg, A.M.; Landau, D.P. Critical behavior of the three-dimensional Ising model: A high-resolution Monte Carlo study. Phys. Rev. B 1991, 44, 5081. [Google Scholar] [CrossRef] [PubMed]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Boston, MA, USA, 2012. [Google Scholar]
- Hinton, G.E. A practical guide to training restricted Boltzmann machines. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 599–619. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | 900 | 1600 | 2500 | S | MC | Exact | ||
|---|---|---|---|---|---|---|---|---|
| T-RBM | 2.240 | 2.291 | 2.316 | 2.367 | 2.267 | 2.367 | 2.28 | 2.269 |
| -RBM | 2.189 | 2.163 | 2.214 | - | 2.267 | 2.367 | 2.28 | 2.269 |
| T-RBM | 4.444 | 4.434 | 4.444 | - | 4.390 | 4.383 | 4.44 | 4.511 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, J.; Zhang, K. Thermodynamics of the Ising Model Encoded in Restricted Boltzmann Machines. Entropy 2022, 24, 1701. https://doi.org/10.3390/e24121701
Gu J, Zhang K. Thermodynamics of the Ising Model Encoded in Restricted Boltzmann Machines. Entropy. 2022; 24(12):1701. https://doi.org/10.3390/e24121701
Chicago/Turabian StyleGu, Jing, and Kai Zhang. 2022. "Thermodynamics of the Ising Model Encoded in Restricted Boltzmann Machines" Entropy 24, no. 12: 1701. https://doi.org/10.3390/e24121701