
Genetic Algorithm Based on a New Similarity for Probabilistic Transformation of Belief Functions †
Abstract
:1. Introduction
1.1. Background and Research Motivation
1.2. Challenges
1.3. Contributions
- The 2D criteria, PIC and Jousselme’s distance have pointed out its drawbacks in many references [17,24]. Thus, an efficient and different aggregation measure is proposed. Its novelty lies in considering the drawback of the past description of the distance between the evidence. In other words, up to now, most distances were defined according to the corresponding focal elements between two sources of evidence, and the sequence inside the assignments of the focal elements themselves was not considered. The sequence might also lead to dissimilarity, which is referred to as “self-conflict or self-contradiction” [25];
- More specific steps of evolutionary-based algorithms are given in detail. Aside from that, the convergence analysis of the MOEPT is illustrated to prove the rationality of using GAs. Moreover, some bugs are detected and fixed when using the MOEPT with traditional constraints;
- The specific application problem, target type tracking (TTT), is efficiently solved and discussed based on the proposed method with a novel simple constraint.
2. Basis of Belief Functions
2.1. DST Basis
2.2. Classical Probabilistic Transformations
Pignistic Transformation (BetP)
2.3. Distance Proposed by Han and Dezert
3. New Evidence for Similarity Characterization
3.1. The Consistency of Focal Elements between Two BOEs
- Symmetry: ;
- Consistency: ;
- Nonnegative: ;
- Triangle inequality: .
- When , , and thusBecause , thus⇒ satisfy triangle inequality;
- When , , thusBecause , thus ⇒ satisfies the triangle inequality.
3.2. The Inconsistency of the Focal Elements between Two BOEs
- Step 1:, ,, ,, ,, ;
- Step 2: The parameter ς denotes the width of the belief interval, where , , , , , , and ;
- Step 3: and are the indexes of focal elements whose ς values are sorted in increasing order, where and ;
- Step 4: is calculated based on Equation (10).
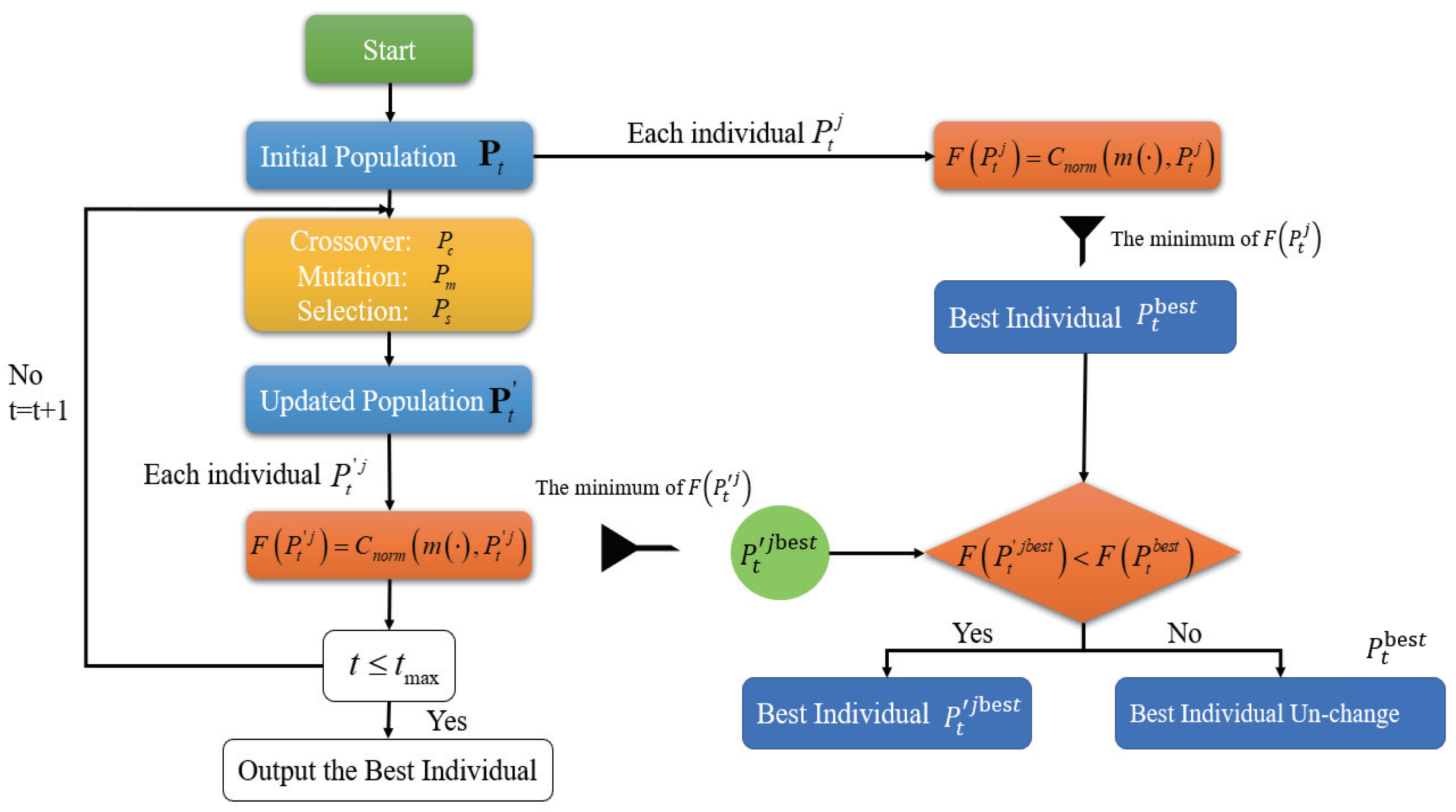
4. Multi-Objective Evolutionary Algorithm Based on Two-Dimensional Criteria
4.1. Multiple-Objective Evolutionary-Based Probabilistic Transformation
- Step 0 (setting parameters): Assume is the maximum number of iterations, is the population size in each iteration, is the selection probability, is the crossover probability, and is the mutation probability.
- Step 1 (population generation and encoding mechanism): A set of random probability values is generated such that the constraints in Equations (14)–(16) for are satisfied in order to make each random set of probabilities compatible with the original or target BBA to approximate. (The lower (Bel) and upper (Pl) limits of each focal element are calculated using Equations (2) and (3) based on the value of .) In other words, we have
- Step 2 (fitness assignment): For each probability set , (), we compute its fitness value F based on Equation (13). More precisely, one takes .
- Step 3 (best approximation of ): The best probability set with a minimum fitness value is sought, and its associated index is stored in and .
- Step 4 (selection, crossover and mutation): The tournament selection, crossover and mutation operators drawn from the evolutionary theory framework [33] are implemented to create the associated offspring population based on the parent population . If , then the remains unchanged; otherwise, .
- -
- Crossover operator: The crossover operator is one of the most important operators in the genetic algorithm. The crossover operation is conducted for the selected pairs of individuals. The feasibility condition of each individual is described as follows. The value of each subsegment must be between 0 and 1, and the sum of the individuals should be 1. Although the initial population is formed in a way that all individuals are feasible and correct, using the standard crossover operators leads to defective sub-segments, and a normalization procedure is needed for such a situation. Consider the following two individuals to be parents: and . (Here, the vertical bar represents the intersection point with the crossover operator.) With the single-point classic crossover operator, the following offspring will be produced: and , where is equal to 1.1, which is greater than 1, and is equal to 0.9, which is less than 1. Therefore, and have defective values for which a normalization factor is needed, which leads to the following:,.
- -
- Mutation operator: The mutation operator randomly alters the value of a sub-segment. After applying the mutation operator, normalization of the changed individuals is required. The normalization will be performed in a similar way to the crossover operator.
- Step 5 (stopping MOEPT): Steps 1–4 illustrate the tth iteration of the MOEPT method. If , then the MOEPT method is complete; otherwise, another iteration must be performed by taking and going back to step 1.
| Algorithm 1: Multi-Objective Evolutionary-Based PT (MOEPT). |
|
4.2. Convergence Analysis
- Encoding mechanism: The size of the population is , the length of individual (chromosome) is N, and the initial population is ;
- Retain the best individual directly for the next generation;
- Randomly select the other non-optimal individuals in to cross over so as to form the intermediate population ;
- The population is mutated to form a population ;
- The better individuals in the population are selected as the new generation population .
- Crossover operator: For a single-point crossover, a new individual k is produced based on their parents: individuals i and j:where is the number of individuals k, is the crossover probability and a is the minimum probability for individuals :
- Mutation operator:where is the mutation probability, is the Hamming distance between i and j and b is the minimum probability:
- Selection operator: An MOEPT uses the strategy of retaining the elite options, and the best individual is retained for the next generation which does not participate in the competition. Assume that m individuals are selected based on the following equations:where represents an increasing scale function. That aside, the probability of selecting the first individual in the next generation’s population iswhere is the number of individuals in and is the cardinality of the optimal set of .
- ;
- ;
- .
5. Simulation Results
5.1. Simple Examples
| Algorithm 2: Random generation of BBAs. |
|
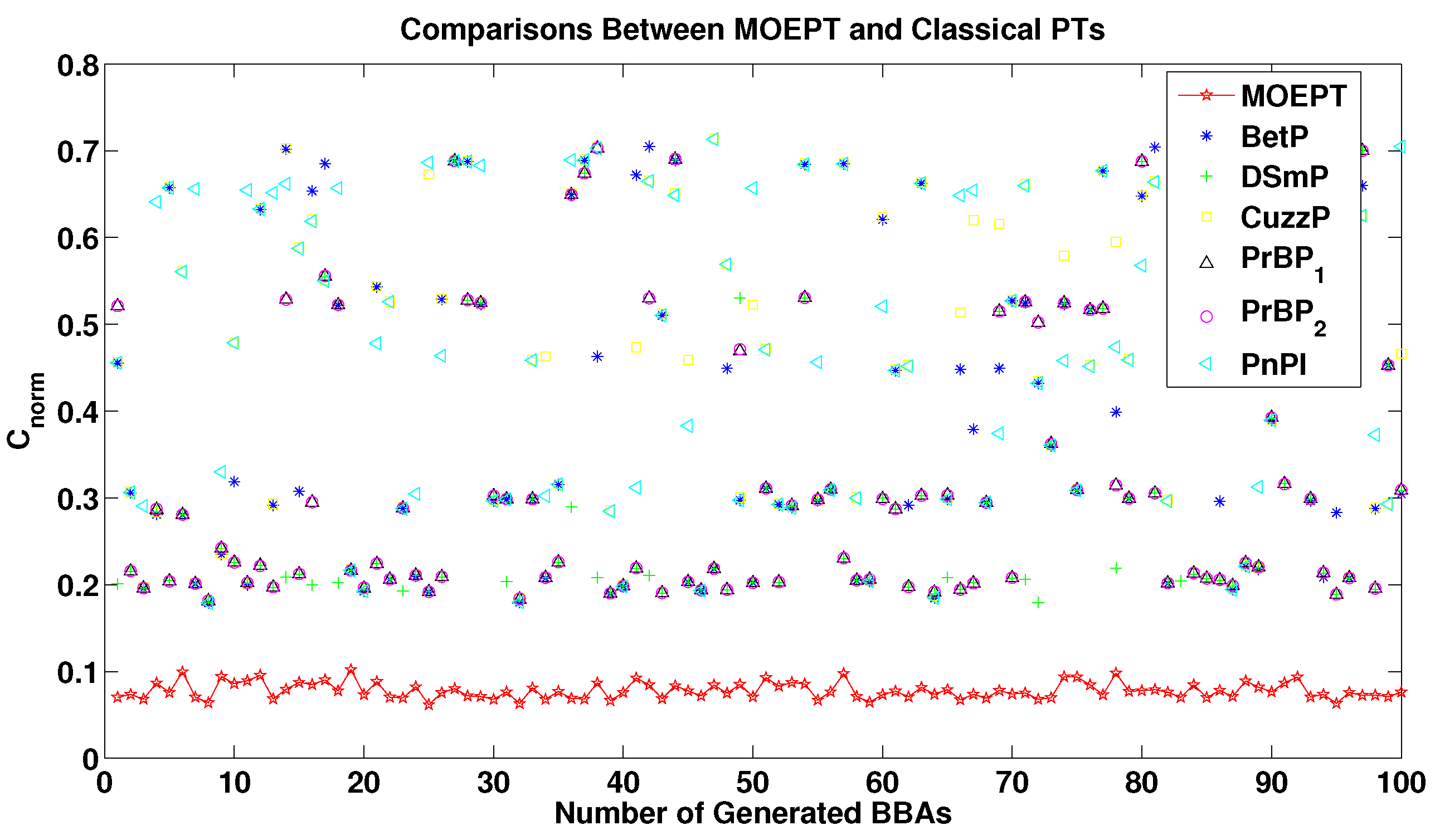
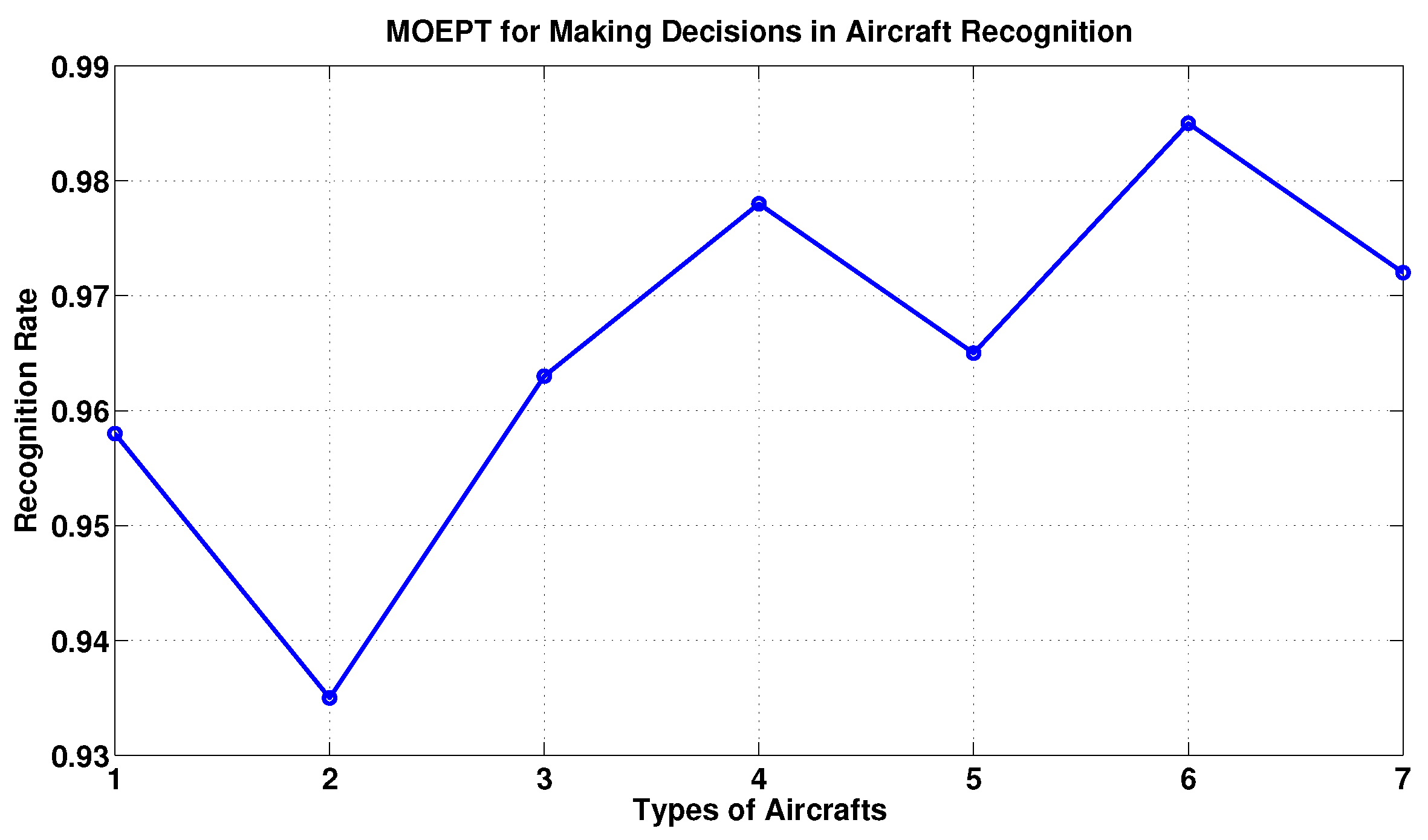
5.2. Example of Pattern Classification Using the MOEPT
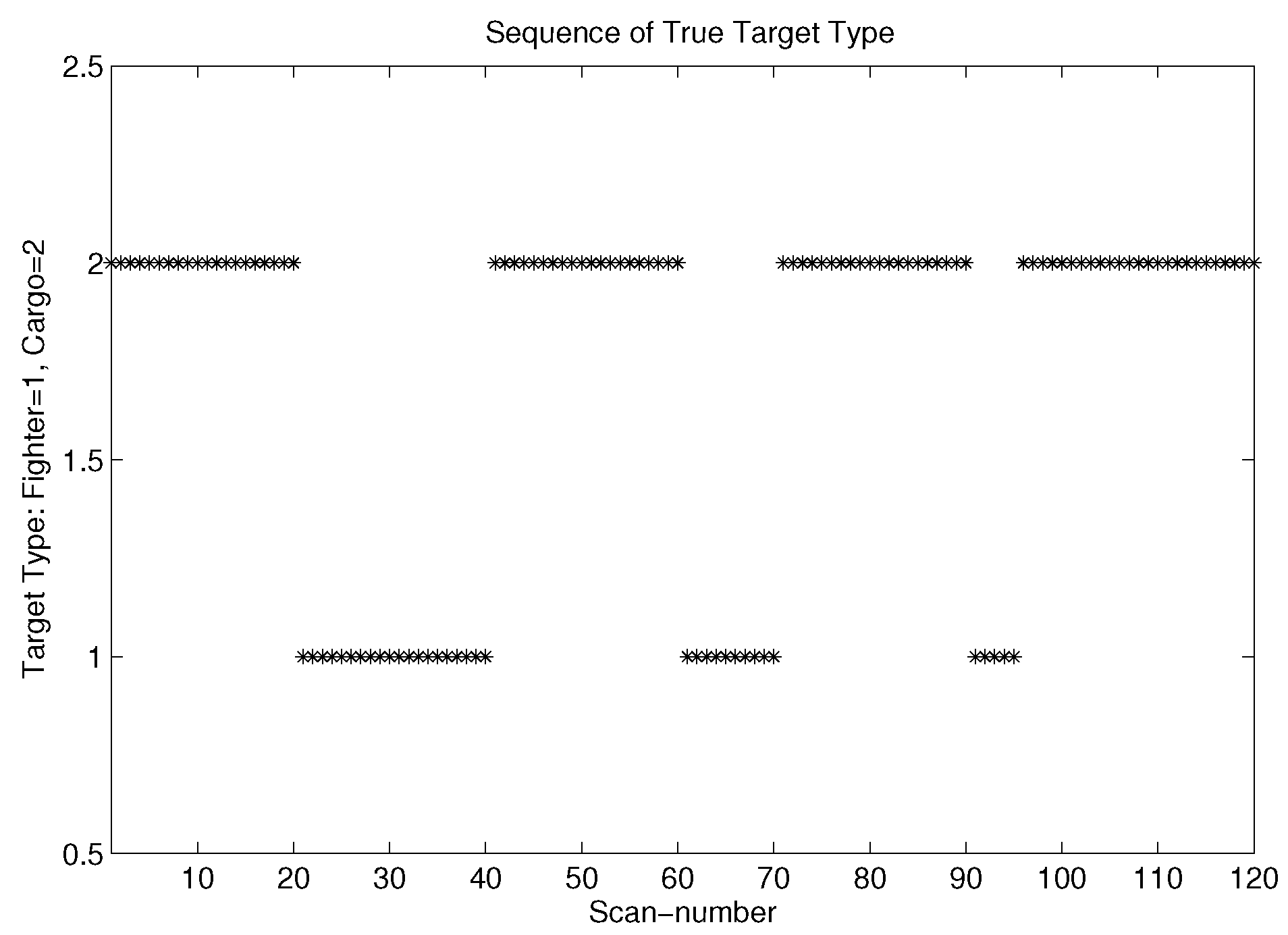
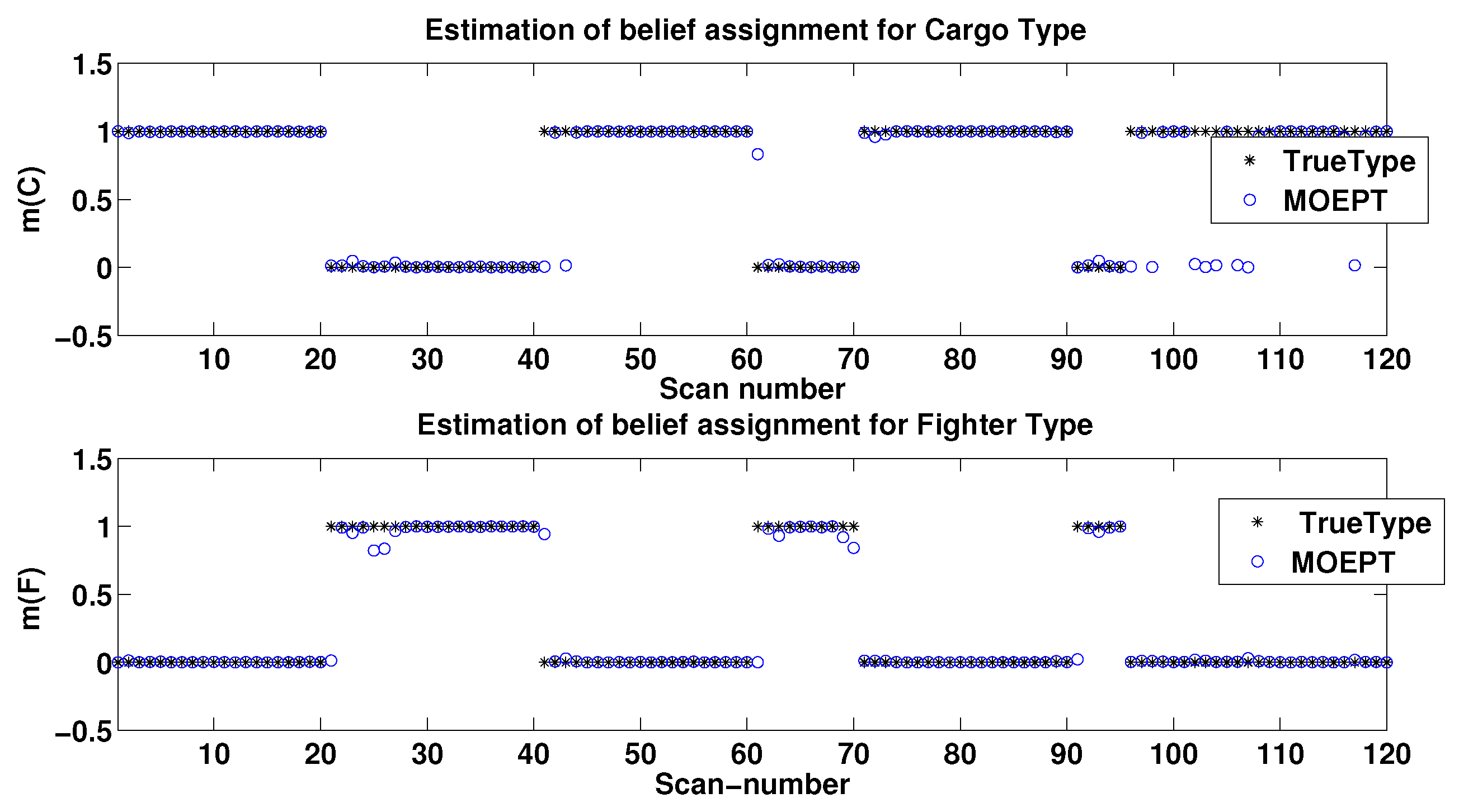
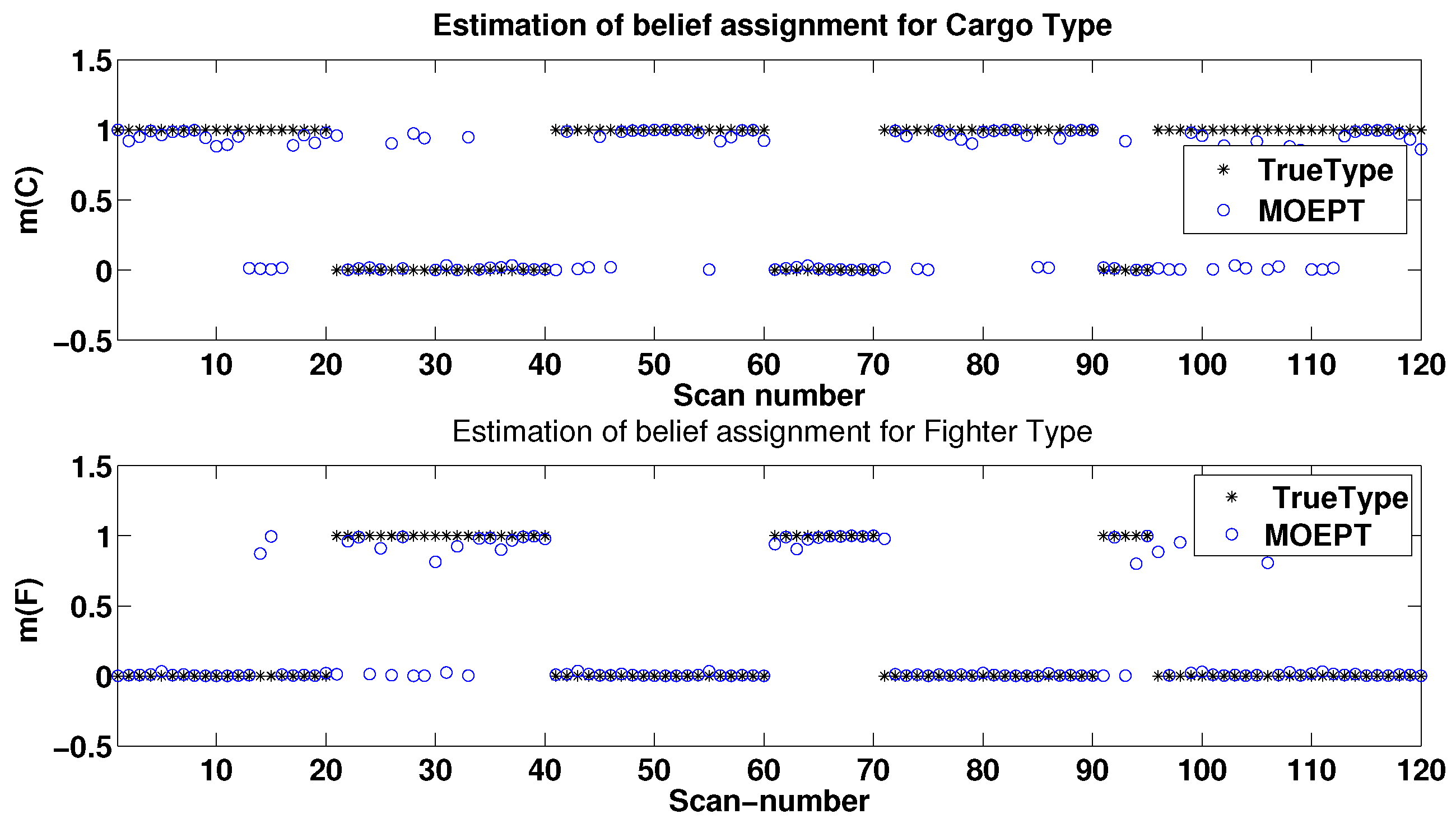
5.3. Example of Target Type Tracking Using the MOEPT
5.3.1. Target Type Tracking Problem (TTT)
5.3.2. Raw Dataset of TTT
- Step 1: Let ;
- Step 2: If , then
- Step 3: If , then
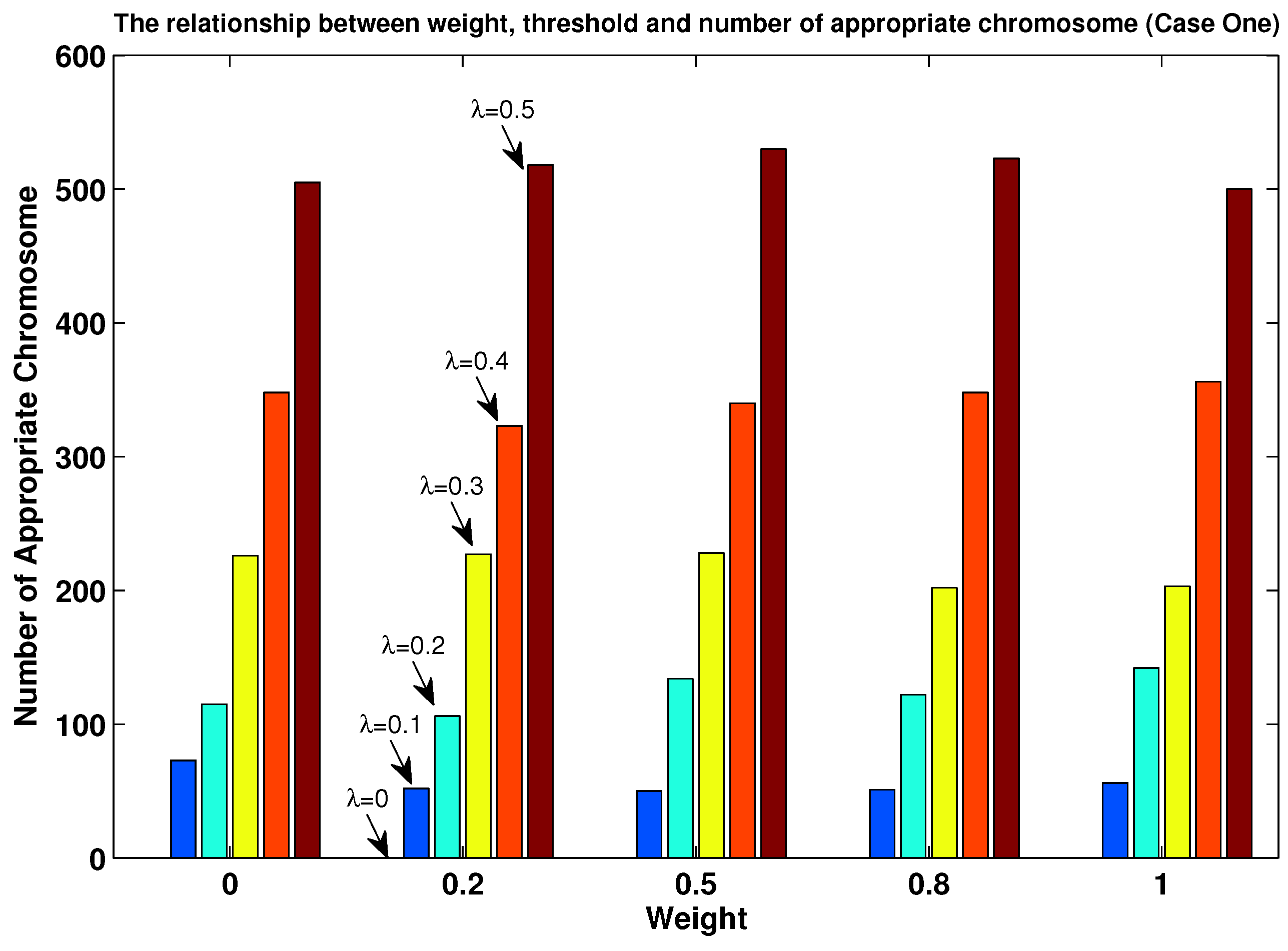
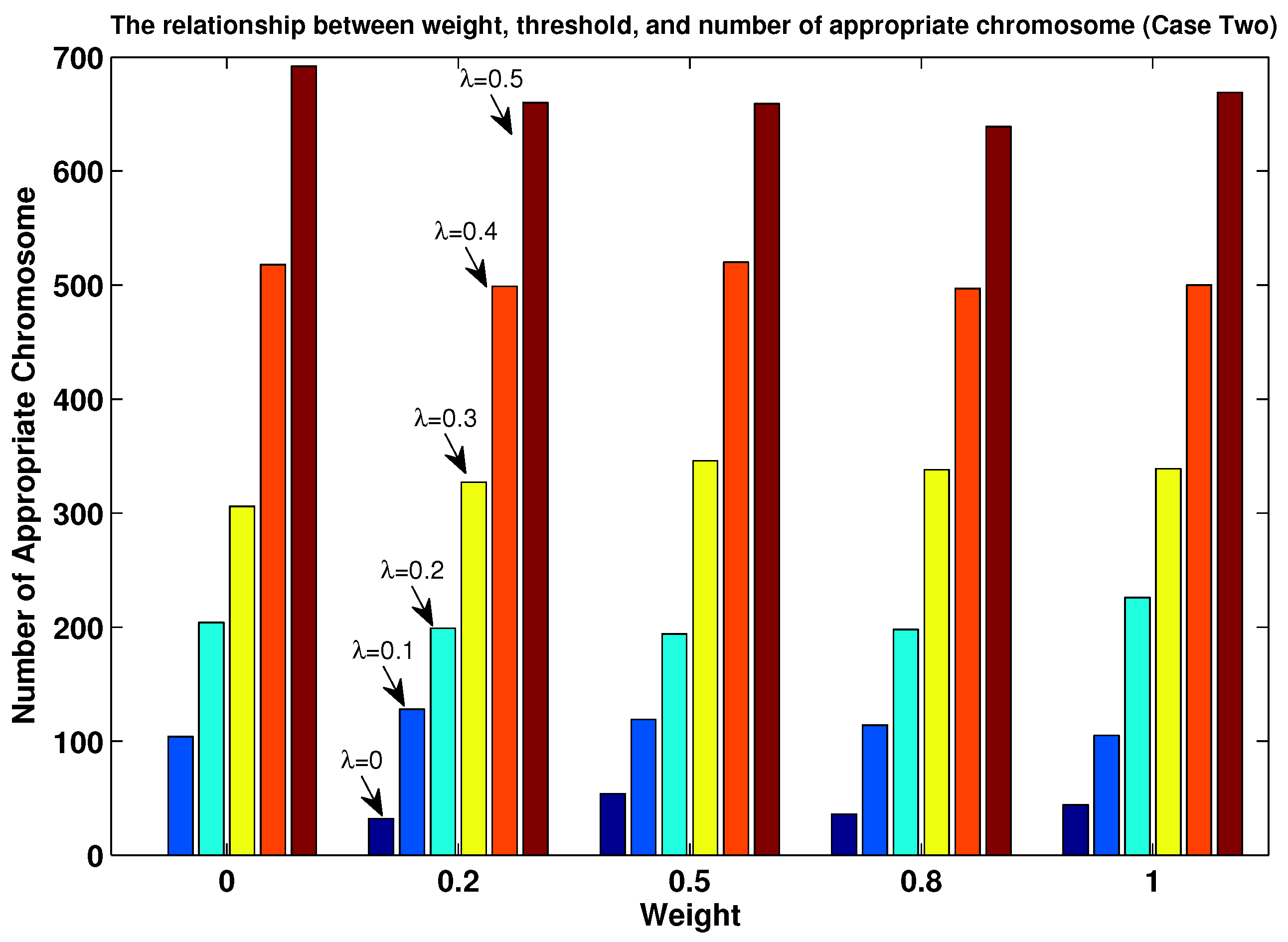
- The value of parameter was set to five possible values: 0, 0.1, 0.2, 0.3, 0.4 and 0.5;
- We randomly generated an initial population based on , which was also subject to the constraints in Equations (14)–(16).
5.3.3. Simulation Results of TTT Based on the Modified MOEPT
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dempster, A.P. Upper and lower probabilities induced by a multivalued mapping. Ann. Math. Stat. 1967, 38, 325–339. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, VA, USA, 1976. [Google Scholar]
- Ghaffari, M.; Ghadiri, N. Ambiguity-driven fuzzy C-means clustering: How to detect uncertainty clustered records. Appl. Intell. 2016, 2, 293–304. [Google Scholar] [CrossRef] [Green Version]
- Su, X.Y.; Mahadevan, S.; Han, W.H.; Deng, Y. Combining dependent bodies of evidence. Appl. Intell. 2015, 3, 634–644. [Google Scholar] [CrossRef]
- Denœux, T. Inner and outer approximation of belief structures using a hierarchical clustering approach. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2001, 9, 437–460. [Google Scholar] [CrossRef]
- Smets, P. The Combination of Evidence in the Transferable Belief Model. IEEE Trans. PAMI 1990, 5, 29–39. [Google Scholar] [CrossRef]
- Smarandache, F.; Dezert, J. (Eds.) Advances and Applications of DSmT for Information Fusion; American Research Press: Rehoboth, NM, USA, 2015; pp. 1–4. [Google Scholar]
- Daniel, M. Probabilistic Transformations of Belief Functions. In Proceedings of the 8th European Conference on Symbolic and Quantitative Approaches to Reasoning and Uncertainty (ECSQARU), Barcelona, Spain, 6–8 July 2005; pp. 539–551. [Google Scholar]
- Dezert, J.; Smarandache, F. A new probabilistic transformation of belief mass assignment. In Proceedings of the11th International Conference on Information Fusion, Cologne, Germany, 30 June–3 July 2008; pp. 1–8. [Google Scholar]
- Cobb, B.R.; Shenoy, P.P. On the plausibility transformation method for translating belief function models to probability models. Int. J. Approx. Reason. 2006, 41, 314–330. [Google Scholar] [CrossRef] [Green Version]
- Sudano, J. Equivalence between belief theories and naive bayesian fusion for systems with independent evidential data: Part I, the theory. In Proceedings of the Fusion 2003, Cairns, Australia, 8–11 July 2003. [Google Scholar]
- Cuzzolin, F. The Intersection probability and its properties. In Proceedings of the ECSQARU Conference, Verona, Italy, 1–3 July 2009. [Google Scholar]
- Han, D.Q.; Dezert, J.; Han, C.; Yang, Y. Is entropy enough to evaluate the probability transformation approach of belief function? In Proceedings of the 13th Conference on Information Fusion, Edinburgh, UK, 26–29 July 2010; pp. 286–293. [Google Scholar]
- Bucci, D.J.; Acharya, S.; Pleskac, T.J.; Kam, T.J. Performance of probability transformations using simulated human opinions. In Proceedings of the 17th International Conference on Information Fusion, Salamanca, Spain, 7–10 July 2014; pp. 1–8. [Google Scholar]
- Yang, Y.; Han, D.Q. A new distance-based total uncertainty measure in the theory of belief function. Knowl.-Based Syst. 2016, 94, 114–123. [Google Scholar] [CrossRef]
- Liu, W.R. Analyzing the degree of conflict among belief functions. Artif. Intell. 2006, 170, 909–924. [Google Scholar] [CrossRef] [Green Version]
- Han, D.Q.; Dezert, J.; Yang, Y. New Distance Measures of Evidence based on Belief Intervals. In Proceedings of the International Conference on Belief Functions, Oxford, UK, 26–28 September 2014. [Google Scholar]
- Frikha, A. On the use of a multi-criteria approach for reliability estimation in belief function theory. Inf. Fusion 2014, 18, 20–32. [Google Scholar] [CrossRef]
- Han, D.Q.; Dezert, J.; Duan, Z.S. Evaluation of Probability Transformations of Belief Functions for Decision Making. IEEE Trans. Syst. Man Cybern. Syst. 2015, 99, 93–108. [Google Scholar] [CrossRef]
- Liu, Z.G.; Dezert, J.; Pan, Q.; Mercier, G. Combination of sources of evidence with different discounting factors based on a new dissimilarity measure. Decis. Support Syst. 2011, 52, 133–141. [Google Scholar] [CrossRef]
- Deng, Z.; Wang, J. A novel decision probability transformation method based on belief interval. Knowl.-Based Syst. 2020, 208, 427–450. [Google Scholar] [CrossRef]
- Zhao, K.Y.; Chen, Z.Q.; Li, L.; Li, J.Y.; Sun, R.Z.; Yuan, G. DPT: An importance-based decision probability transformation method for uncertain belief in evidence theory. Expert Syst. Appl. 2022, 11, 120–133. [Google Scholar] [CrossRef]
- Ma, M.M.; An, J.Y. Combination of evidence with different weighting factors: A novel probabilistic-based dissimilarity measure approach. J. Sens. 2015, 2015, 509385. [Google Scholar] [CrossRef] [Green Version]
- Dezert, J.; Han, D.Q.; Tacnet, J.M.; Carladous, S.; Yang, Y. Decision-Making with Belief Interval Distance. In Proceedings of the International Conference on Belief Functions, Prague, Czech Republic, 21–23 September 2016. [Google Scholar]
- Han, D.Q.; Deng, Y.; Han, C.Z. Sequential weighted combination for unreliable evidence based on evidence variance. Decis. Support Syst. 2013, 56, 387–393. [Google Scholar] [CrossRef]
- Smets, P. Decision making in the TBM: The necessity of the pignistic transformation. Int. Approx. Reason. 2005, 38, 133–147. [Google Scholar] [CrossRef] [Green Version]
- Pan, W.; Hong, J.Y. New methods of transforming belief functions to pignistic probability functions in evidence theory. In Proceedings of the 2009 International Workshop on Intelligent Systems and Applications, Wuhan, China, 23–24 May 2009. [Google Scholar]
- Jousselme, A.L.; Liu, C.S.; Grenier, D.; Bossé, E. Measuring Ambiguity in the Evidence Theory. IEEE Trans. Syst. Man Cybern. Part Syst. Hum. 2009, 36, 890–903. [Google Scholar] [CrossRef]
- Irpino, A.; Verde, R. Dynamic clustering of interval data using a wasserstein-based distance. Pattern Recognit. Lett. 2008, 29, 1648–1658. [Google Scholar] [CrossRef]
- Burger, T. Geometric views on conflicting mass functions: From distances to angles. Int. J. Approx. Reason. 2016, 70, 36–50. [Google Scholar] [CrossRef]
- Sudano, J. The system probability information content (PIC) relationship to contributing components, combining independent multisource beliefs, hybrid and pedigree pignistic probabilities. In Proceedings of the 5th International Conference on Information Fusion. FUSION 2002.(IEEE Cat. No. 02EX5997), Annapolis, MA, USA, 8–11 July 2002; pp. 1277–1283. [Google Scholar]
- Li, X.; Wang, F. A Clustering-Based Evidence Reasoning Method. Int. J. Intell. Syst. 2016, 31, 698–721. [Google Scholar] [CrossRef]
- Srinivas, N.; Deb, K. Multiobjective function optimization using nondominated sorting genetic algorithms. Evol. Comput. 1995, 2, 221–248. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A Fast and Elitist Multiobjective Genetic Algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.B. Analysis of Convergence of Ant Colony Optimization Algorithms. Control Decis. 2006, 21, 764–770. [Google Scholar] [CrossRef]
- Jousselme, A.L.; Maupin, P. On some properties of distances in evidence theory. In Proceedings of the Workshop on Theory of Belief Functions, Brest, France, 31 March–2 April 2010; pp. 1–6. [Google Scholar]
- Li, X.D.; Yang, W.D.; Dezert, J. An Airplane Image Target’s Multi-feature Fusion Recognition Method. Acta Autom. Sin. 2012, 38, 1299–1307. [Google Scholar] [CrossRef]
- Bi, Y.; Bell, D.; Guan, J. Combining evidence from classifiers in text categorization. In Proceedings of the 8th International Conference on Knowledge-Based and Intelligent Information and Engineering Systems, Wellington, New Zealand, 20–25 September 2004; pp. 521–528. [Google Scholar]
- Dezert, J.; Tchamova, A.; Smarandache, F.; Konstantinova, P. Target Type Tracking with PCR5 and Dempster’s rules: A Comparative Analysis. In Proceedings of the 2006 9th International Conference on Information Fusion, Florence, Italy, 10–13 July 2006. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
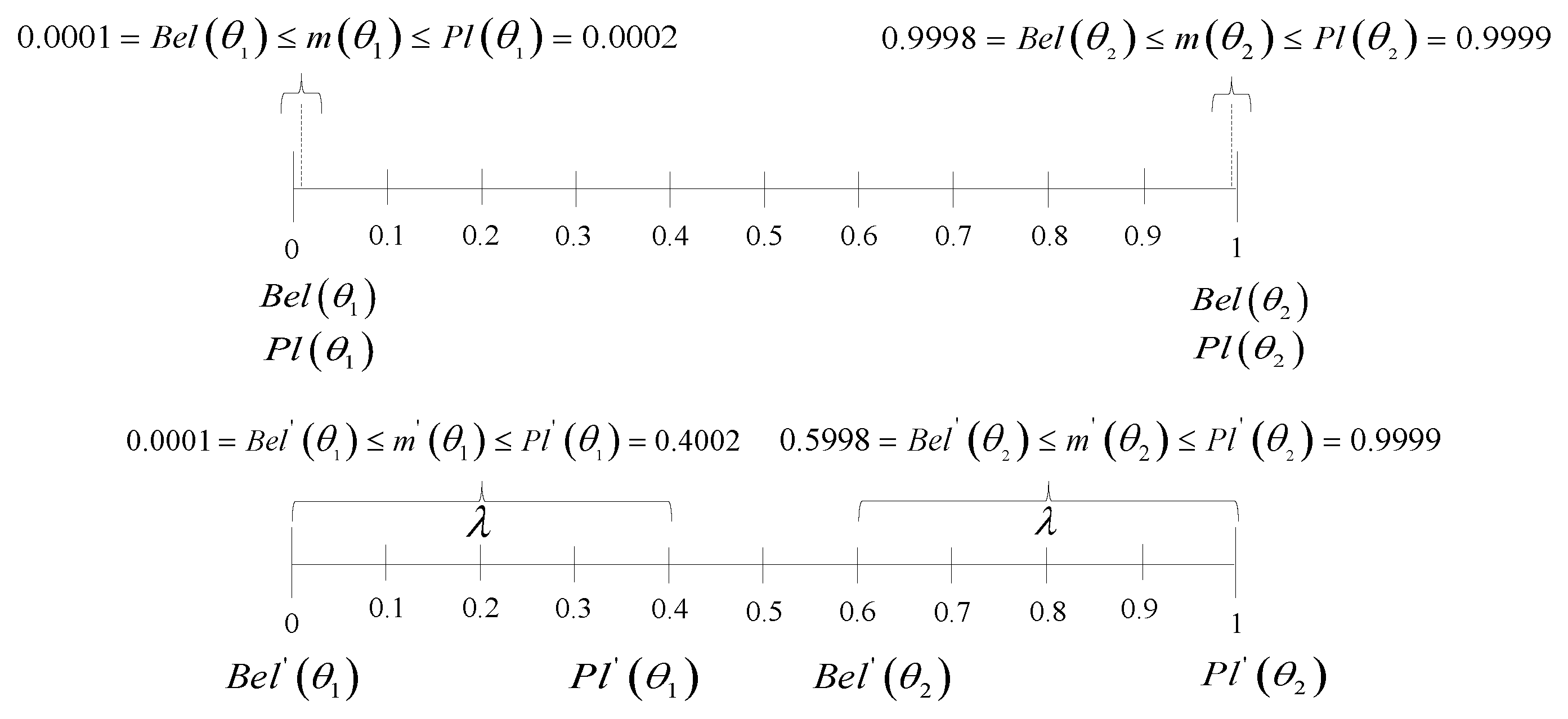{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.3860 | 0.3382 | 0.1607 | 0.1151 | 0.2800 | |
| 0.3983 | 0.3433 | 0.1533 | 0.1050 | 0.2799 | |
| 0.5176 | 0.4051 | 0.0303 | 0.0470 | 0.1897 | |
| 0.5162 | 0.4043 | 0.0319 | 0.0477 | 0.1896 | |
| 0.5419 | 0.3998 | 0.0243 | 0.0340 | 0.1918 | |
| 0.5578 | 0.3842 | 0.0226 | 0.0353 | 0.1933 | |
| 0.3980 | 0.3322 | 0.1156 | 0.1541 | 0.1849 | |
| 0.3985 | 0.3983 | 0.0623 | 0.1409 | 0.0733 |
| 0.3983 | 0.3433 | 0.1533 | 0.1050 | 0.3974 | |
| 0.2500 | 0.2500 | 0.2500 | 0.2500 | 0.5458 | |
| 0.5419 | 0.3998 | 0.0243 | 0.0340 | 0.6368 | |
| 0.5578 | 0.3842 | 0.0226 | 0.0353 | 0.6412 | |
| 0.2500 | 0.1597 | 0.3578 | 0.2325 | 0.3415 | |
| 0.2483 | 0.2485 | 0.2496 | 0.2536 | 0.1708 | |
| 0.2484 | 0.2488 | 0.2489 | 0.2539 | 0.0450 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Y.; Cao, L.; Zuo, K. Genetic Algorithm Based on a New Similarity for Probabilistic Transformation of Belief Functions. Entropy 2022, 24, 1680. https://doi.org/10.3390/e24111680
Dong Y, Cao L, Zuo K. Genetic Algorithm Based on a New Similarity for Probabilistic Transformation of Belief Functions. Entropy. 2022; 24(11):1680. https://doi.org/10.3390/e24111680
Chicago/Turabian StyleDong, Yilin, Lei Cao, and Kezhu Zuo. 2022. "Genetic Algorithm Based on a New Similarity for Probabilistic Transformation of Belief Functions" Entropy 24, no. 11: 1680. https://doi.org/10.3390/e24111680