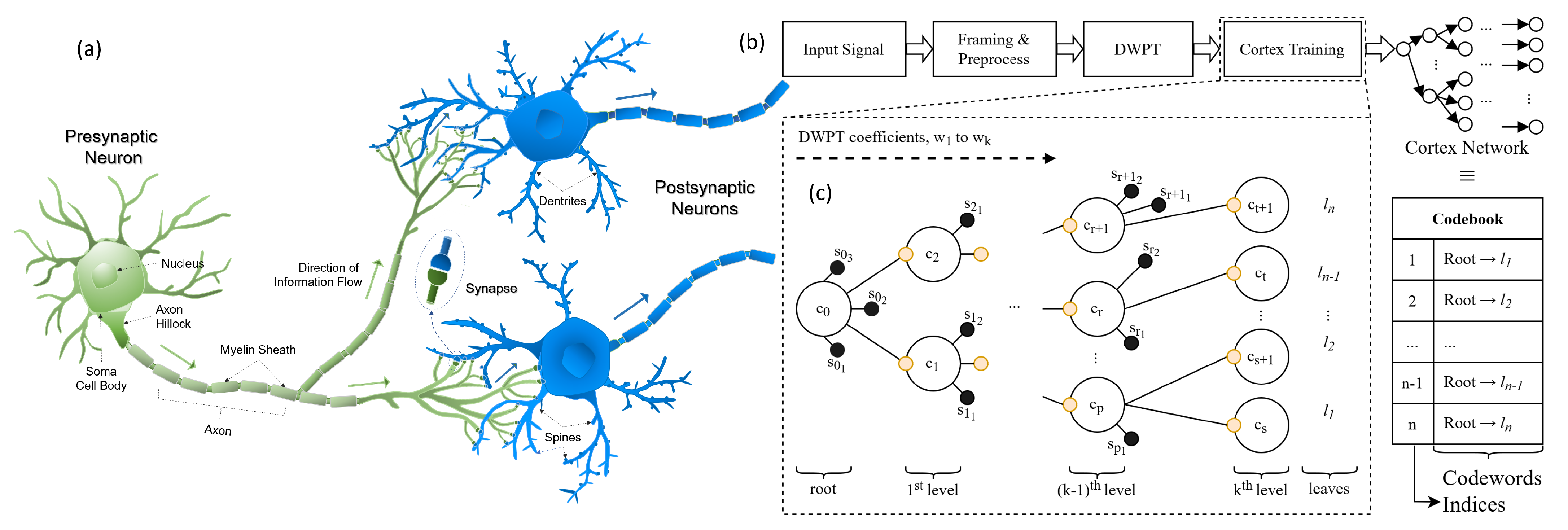
2.3. Cortical Coding Network Training Algorithm—Formation of Spines and Generation of the Network
The developed method is a combination of transformation and codebook coding. Here, the input signal was framed by predetermined window size. Then, it was normalized depending on the input signal type and compression ratio. We used DWPT with Haar kernel that was applied to the normalized signal towards achieving detailed frequency decomposition [
26,
27]. The wavelet coefficients were applied in a hierarchical order to the cortical coding tree. From root to leaves, the cortical coding tree holds wavelet coefficient(s) hierarchically ordered from low to high-frequency components. While the root node does not have any coefficient, the first level nodes have the lowest frequency coefficients, whereas last level nodes (leaves) have the highest frequency coefficients. In the beginning, the cortical coding tree has only the root node and is fed by the incoming data, with a wide range of wavelet coefficients. The nodes develop depending on the input data in a fully dynamic, self-organized, and adaptive way aiming to maximize the information entropy by minimizing the dissipation energy. Here, each cortex node has spine nodes that are generated according to the incoming wavelet coefficients and each spine node is a candidate to be a cortex node. If a spine node is triggered and well-trained, then it can turn into a cortex node. The significance of our approach is that only frequent and highly trained data can generate a node rather than every piece of data creating a node. The importance of this is that the cortical coding tree becomes highly robust eliminating the noise.
The evolution of a spine node to a cortex node is controlled with a first-order Infinite Impulse Response (IIR) Filter. IIR Filters have infinite impulse response and the output of the filter depends on both previous outputs and inputs [
28]. The maturity of the spine node is calculated with the simple two-tap IIR filter given in Equation (
4), where
is the maturity level,
is the dissipated energy and
is the level coefficient of the learning rate.
is calculated as the inverse of absolute difference between the chosen node and the incoming data,
where
is the input data and
c is the value of the chosen node.
As a result of the IIR filter, maturity cumulatively increases when the relevant node is triggered. If maturity exceeds a predetermined value, the spine node evolves into a cortex node. By controlling the coefficient, the speed of learning can be arranged. A higher value results in fast-evolving. As the cortical coding tree has a hierarchical tree structure, the probability of triggering a node at different levels of the tree is not equal. Therefore, the coefficient is set higher for high levels of the cortical coding tree.
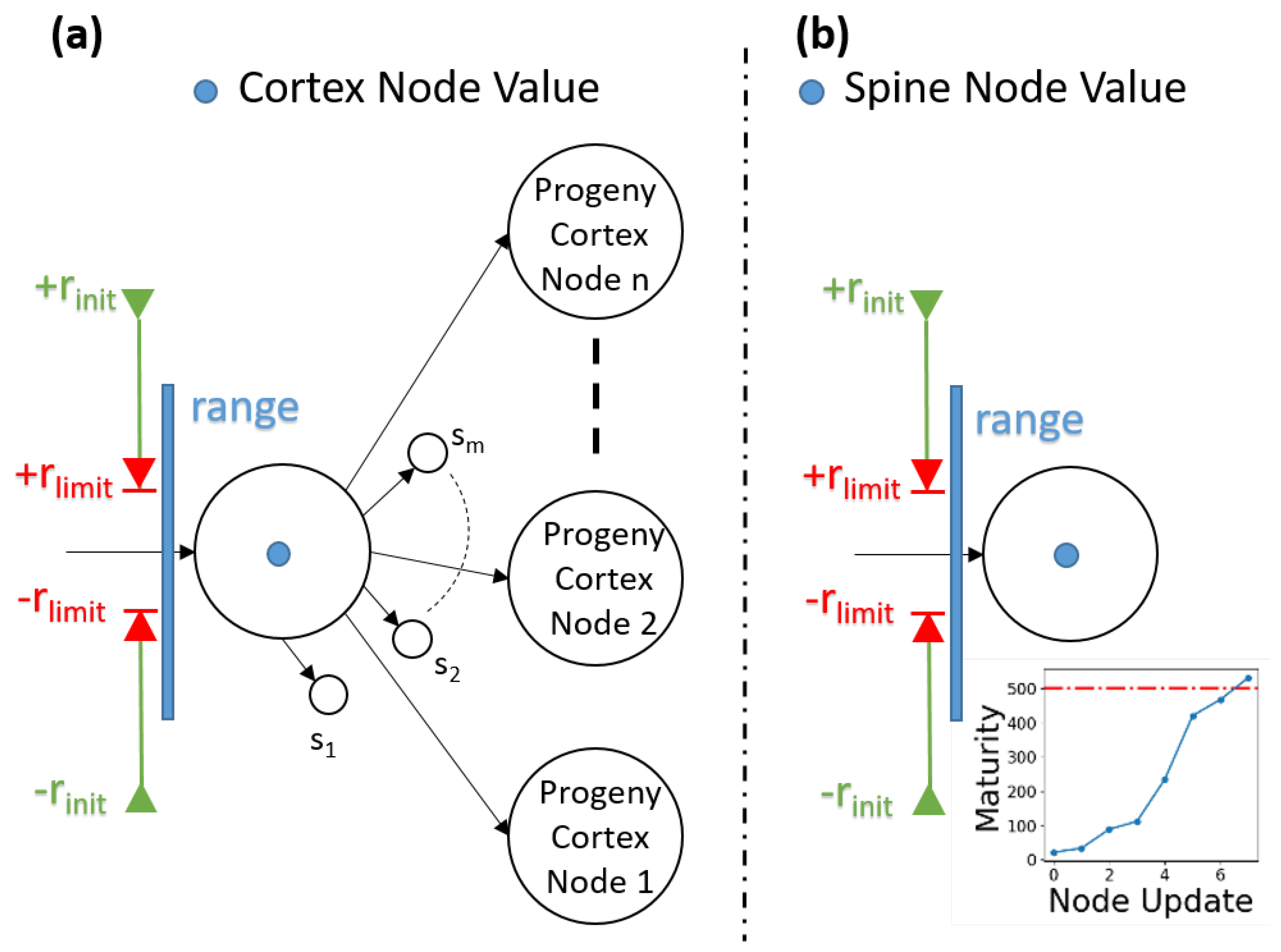
The effective covering range parameter initially covers a wide range, which then narrows down to a predefined range of limited values as it is trained. There are two conditions for a node to be triggered or updated; first, the incoming data, i.e., the wavelet coefficient, should be within the values of the node’s covering range and also be the closest to the node’s value. If the spine node satisfies the conditions, it changes its value regarding Equation (
6) and narrows down its covering range with the Equation (
5) where
r is the range parameter of the node,
is the predefined initial range of nodes,
is the lower bound of a range,
w is the pass count (weight) of the node and
l is the level constant and
k is the power coefficient of the weight parameter.
If conditions are not satisfied for the cortex and the spine nodes, a new spine node with the incoming wavelet coefficient value is generated. So, this means that if the incoming data are not well known or a previously similar value is not seen for the cortex node, then a spine node is generated for that unknown location. If this value is not an anomaly, and it will be seen more in the future, then this spine node evolves into a cortex node. As seen from Equation (
5), well-trained nodes have narrow covering ranges, whereas less trained nodes have wider covering ranges. According to the two conditions, if a node is well trained (it means that it is triggered/updated many times), the covering range will be narrower and this increases the possibility of having more neighboring nodes where incoming data are dense. An example is presented in Figure 6. There are two nodes
and
, at stage 4 in the figure, the input data are within the dynamic range of the node
and therefore the
node is updated, the value of the node decreases (the node moves downwards) and the range gets narrower and there becomes a gap between covering ranges of the
and the
nodes. Thus, a new node occurs at that gap in later stages. In order to maximize the entropy, we aim to obtain close to equally probable features. Generating more nodes dynamically at the dense locations of incoming wavelet coefficients results in more equally visited nodes in the cortical coding tree and increases entropy. The reason for limiting the range parameter to a predefined value is to prevent the range parameter not to be less than a certain value. Otherwise, a very well-trained node’s range parameter can get very close to 0, hence, this may result in generating neighboring nodes having almost similar values at the cortical coding tree. This causes a series of problems; firstly the algorithm becomes not memory efficient, extra memory is needed for new nodes having almost the same value. Secondly, the progeny of the neighboring values may not be as well trained as the original node, so at lower levels error rate increases. The cortical coding tree is a hierarchical tree and from the root to leaves, it follows the most similar path according to the incoming data and if the chain is broken at some level, the error rate may increase. Another reason for limiting the range parameter is to make the cortical coding tree convergent. Neighboring nodes range parameters can intersect, but this does not cause any harm to the overall development of the cortical coding tree because the system works in a winner takes all manner. The ranges can intersect but only the closest node to the incoming input value becomes the successive node. To summarize,
parameter can be considered the quantization sensitivity.
The training level of a spine node is controlled with a dissipation energy parameter. All the nodes in the cortical coding tree are dynamic; they adapt to the incoming data in their effective range and change their value (see Figure 6). The change in value is indirectly proportional to the train level of the node. The total change in the direction and the value of the relevant coefficients are determined by the incoming data and how well the node had been trained previously. The formula of the update of the node’s value (
) according to the incoming data is presented in Equations (
6) and (
7), where
c is the value of the node and,
is the incoming ith wavelet coefficient,
w is the pass count (weight) of the node,
l is the level coefficient where
,
n is the power of weight where
and
k is the adaption control coefficient where
Grouping
c parameter and coefficients, the formula can be simplified as in Equation (
7).
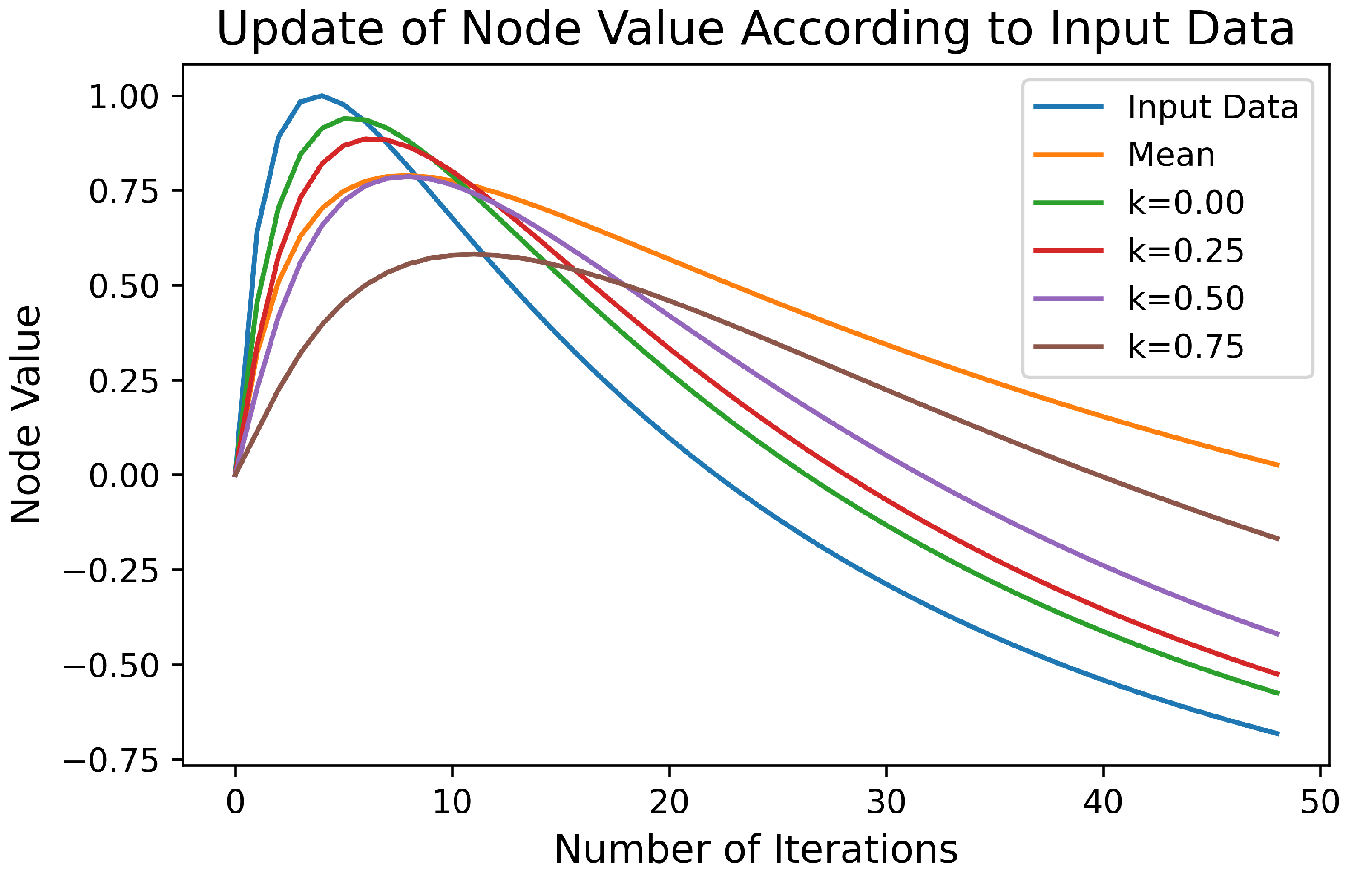
The weights represent the training level of the node, i.e., the pass count of wavelet coefficients via that node. Depending on the application type, the adaptation speed may vary. Smaller
k values increase the significance of new coming input values rather than historical ones. For instance, applications like stream clustering mostly need faster adaptation. However, in normal clustering all values are important, so in our tests,
k is chosen as
. As cortical coding network has a hierarchical tree-like structure holding wavelet coefficients from low to high frequencies, the effect of change of node in each frequency level does not equally affect the overall signal. The change in low frequencies affects more than higher frequencies. To overcome and control this variance, level coefficient
l is added to the equation. To control slower adaptation in low frequencies
l can be chosen bigger comparing high frequency
l data. In
Figure 4, examples of different
k values for dynamic change of the node value in Equation (
7) is presented. Input data could be selected randomly, but on purpose to be more visible, a nonlinear function
,
is used to create the input data values. The initial value of the node is 0 and with each iteration, the change of the value of the node is presented depending on the
k parameter in Equation (
7). As a result of dynamic change of values in training, the cortex node values adapt to frequent incoming data values and this yields the increase of information entropy.
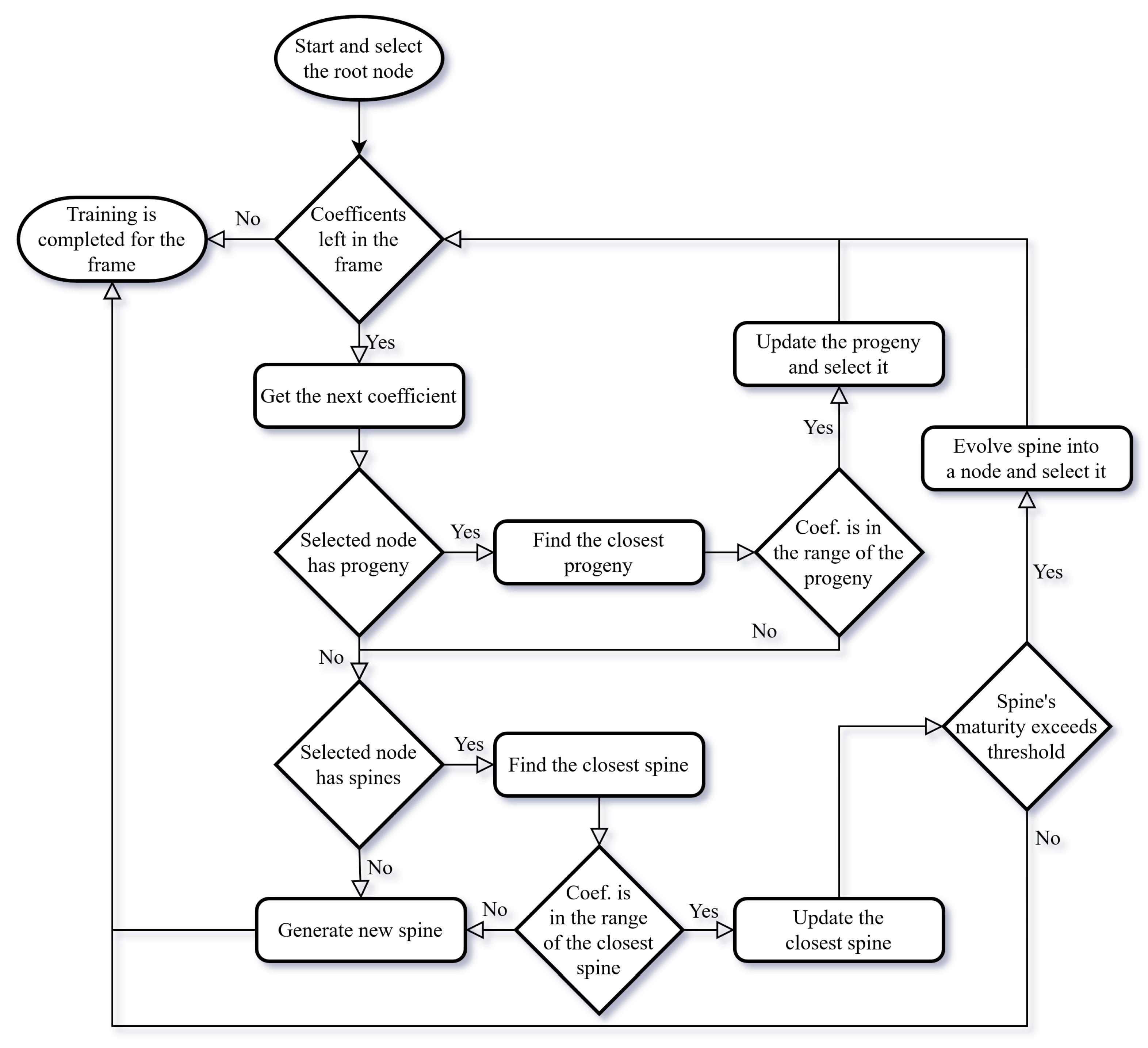
In order to better visualize the flow of the process of the cortical coding network training, an algorithm flowchart and pseudocode are presented
Figure 5 and Algorithm 1. The flow chart shows how the cortical coding network is trained with the input wavelet coefficients for one frame of input data. At the start of each frame, the root node of the cortical coding tree is assigned as the selected node. The input vector is taken and from lowest to the highest frequency, the wavelet coefficients are trained in order. For the input coefficient in order, progeny nodes of the selected node are checked whether any node is suitable to proceed. There are two main conditions for a node to be suitable; the node’s value should be the closest to the incoming coefficient and input value should be within the covering range of the closest node. First, this control is checked among the cortex nodes of the selected node. If any suitable node is found then that node is updated and assigned as the selected node for the next iteration. If none of the cortex nodes are suitable, then the same procedure is carried out for the spine nodes of the selected node. If none of the spine nodes are suitable, then a new spine node with the input value is generated as a progeny spine node of the selected node. If a spine node is found suitable, then it is updated. If the maturity of the spine node exceeds the threshold, then it is evolved to a cortex node and this new cortex node is assigned as the selected node for the next cycle. If the spine node is not mature enough then the loop is ended as there will be no cortex node to be assigned as the selected node for the next iteration.
| Algorithm 1 Cortical Coding Network Training (for one frame) |
Input
input wavelet coefficients vectors,
procedure Cortical Coding Network (Cortex) Training
for each coefficient () in the input data frame do
if node has progeny cortex node then
closest_node ← FindClosestNode(node, coefficient)
if coefficient is in the range of the closest cortex node then
node ← UpdateClosestNode(closest_node, coefficient)
continue
end if
end if
if node has spines then
closest_spine ← FindClosestSpine(node, coefficient)
if coefficient is in the range of the closest spine node then
UpdateClosestSpine(closest_spine, coefficient)
if closest_spine’s maturity > threshold then
node ← EvolveSpineToNode(closest_spine)
continue
else
break
end if
end if
end if
GenerateSpine(node, coefficient)
break
end for
end procedure |
The complexity of the cortical coding algorithm is
, where
n is the number of input vectors,
d is the depth of the cortical coding tree (vector size), and
m is the maximum number of progenies in the cortical coding tree. Since the cortical coding network is a sorted tree, finding the closest node in the algorithm is carried out with Binary Search. The complexity of Binary Search is given by
, where
k is the number of elements [
29]. In practice, as the cortical coding tree is a hierarchical tree, the average progeny nodes in the cortical coding tree are much smaller than
m, especially on lower level nodes which yields binary search operation to find the closest node on average becoming much faster on these nodes. So the algorithmic complexity can be considered as
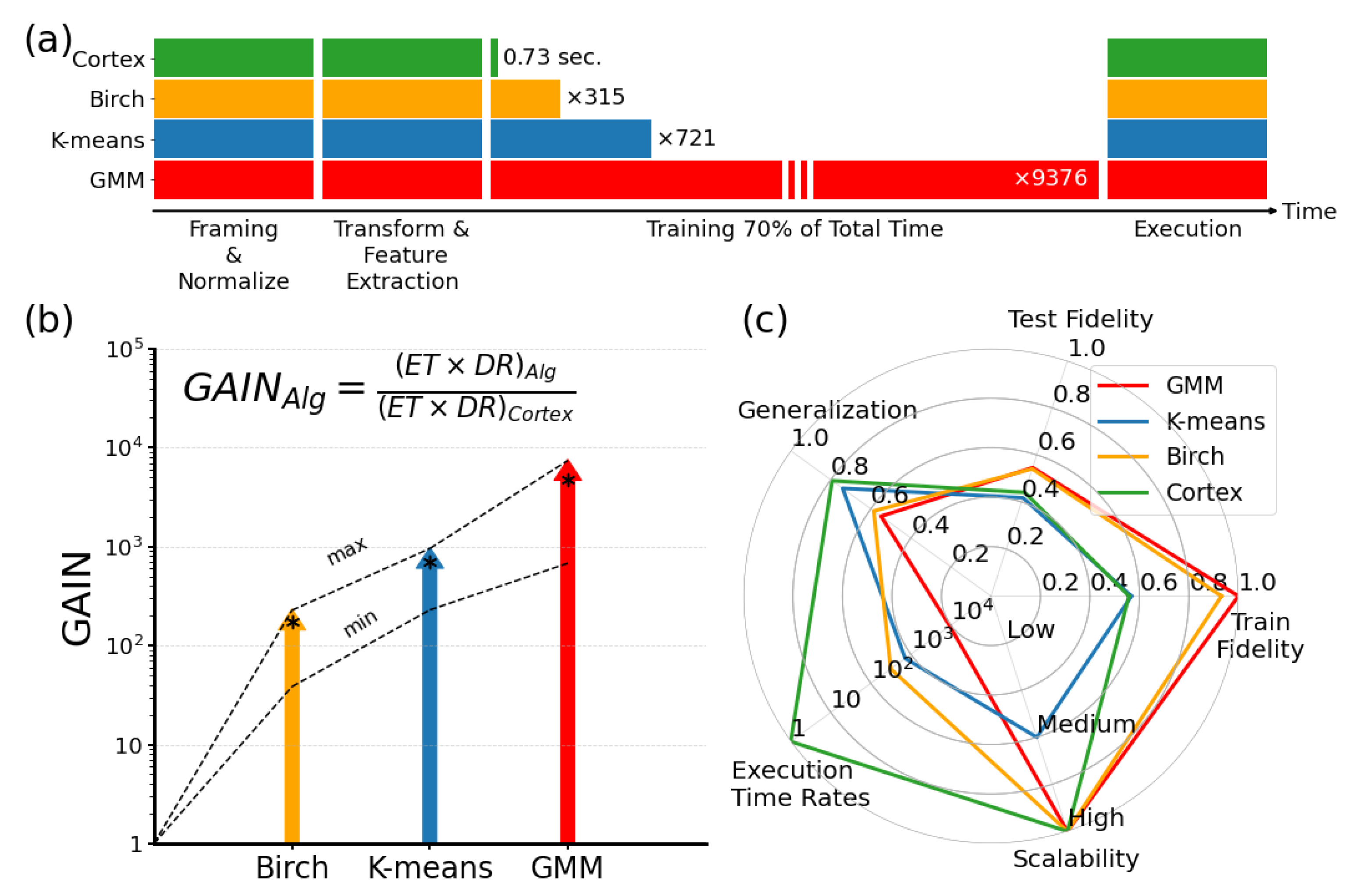
, discarding
. Additionally, there are many break commands in the algorithm which end the loop earlier. For these reasons, even though the time complexity seems bigger than Birch, the algorithm runs much faster than it.
2.4. Entropy Maximization
The major aim of the cortical coding algorithm is to maximize the information entropy at the level of the leaves of the cortical coding tree, i.e., to generate a codebook that has equally probable clustered features along each path from the root to the leaves. The process of entropy maximization is carried out at each consecutive level of the tree separately until they converge to a maximum vector feature (see
Appendix C). The two types of nodes present in the cortical coding tree are cortex and spine nodes (
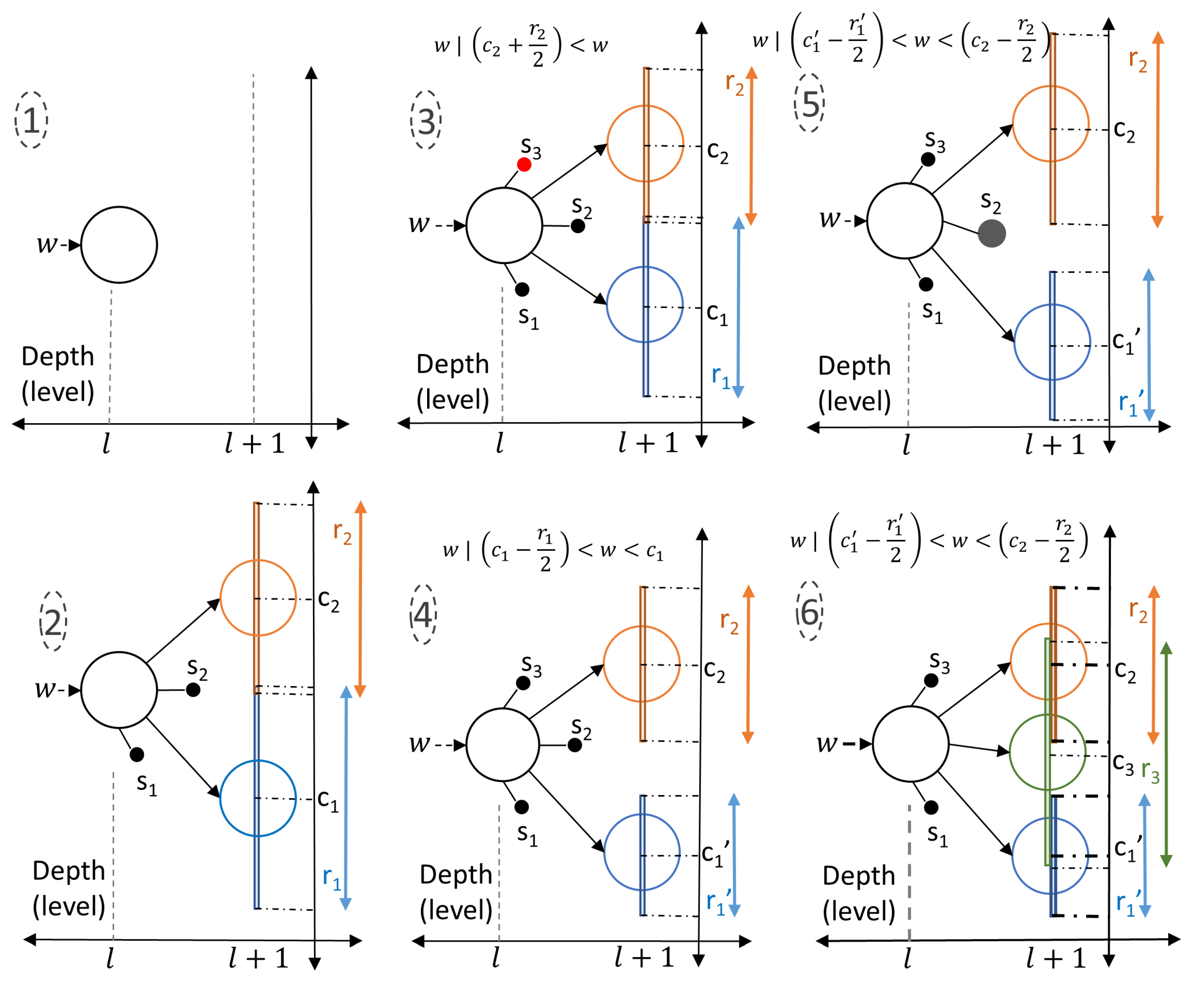
Figure 3). A spine node is the progeny of the cortex node and is the candidate to be the next cortex node. This means that a well-trained spine evolves into a cortex node. Unlike a cortex node, a spine does not have any progeny node. Each spine has a maturity level that dictates its evolution to be a cortex node. When a relevant spectral feature passes through a cortex node and if there is no progeny cortex node yet within the dynamic range of the previously created, then the spines of the node are assessed. If the wavelet coefficient is not within any of the dynamic ranges of the spine nodes, then a new spine node with the incoming wavelet coefficient is generated. If the relevant spectral feature is within the effective dynamic range of previously created spines, then the spine node in the range is triggered and updated. If the maturity of a spine node passes through a predetermined threshold, then the spine node evolves to a progeny cortex node. A numerical example is presented in
Figure 6, steps 1 through 6. Here, the formation of the nodes and the evolution of the spines into tree nodes take place according to the incoming data. The cortical coding network is generated through: (1) A
lth level node in the cortical coding tree has neither spine nor cortex nodes when first formed. (2) After a certain period of time, the node forms two spine nodes (
,
) and two progeny nodes with data
and
with covering ranges of
and
, respectively. (3) A new spine,
, is created when a signal arrives outside the range of any cortex or spine node. (4) The arrival of the new signal
w triggers an update of the range and the data values. While the node slightly changes its position, the new center becomes
and the covering range narrows down to
, which continues as the training level of the node increases eventually causing the formation of a gap between the coverage ranges of
and
. (5) When the new signal
w arrives outside the covering ranges of nodes but within the covering range of
spine node, then this node is updated, i.e., the center of
adapts to the signal with its range narrowed down. As the increased maturity level of
exceeds a threshold value, a new spine node forms as a progeny cortex node. (6) A signal
w similar to the previous one arrives, again
node is updated, as the maturity level of
node surpasses the threshold, the
node eventually evolves to a cortex node with its center at
, covering a new range
. The mathematical description of evolving of spines into cortex nodes is explained earlier in
Section 2.3).
Entropy is maximized when an equal probability condition is reached. To have an efficient vector quantization the aim is to generate equally probable visited leaves of the tree. Shannon’s information entropy
H is calculated as follows [
15]:
where
X is a discrete random variable having possible outcomes
to
and the possibility of these outcomes are
to
,
b is the base of the logarithm and it differs depending on the applications. Cortical coding network is dynamically developed and aims to maximize entropy at the leaves of the network. At each level of the tree, the rules are applied. More frequent and probable data generate more nodes comparing the severe areas. So at each level, it aims to maximize entropy. However, the main goal is to have equal probable features at the leaves of the cortical coding tree. Consecutive network levels yield an increase in entropy (see
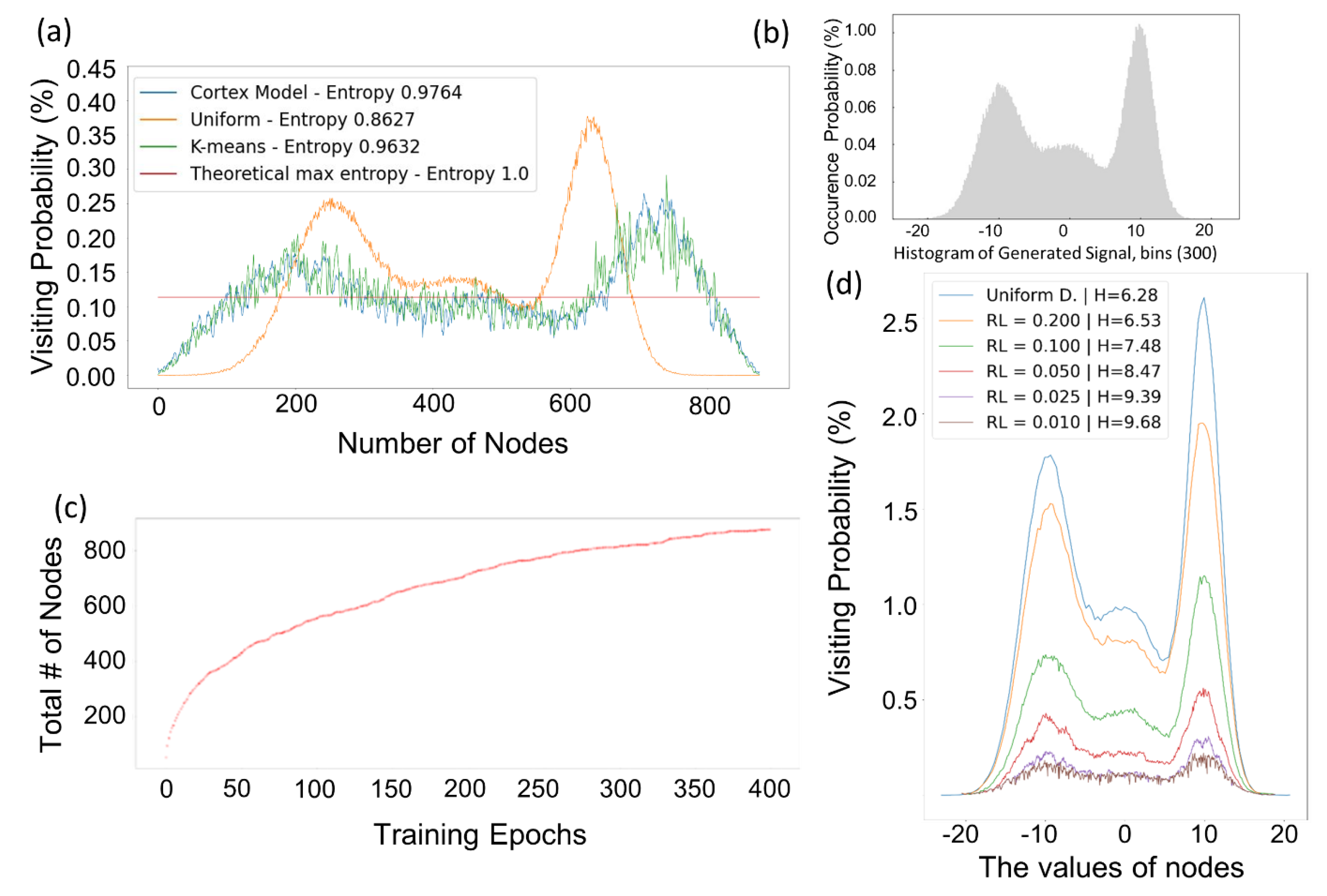
Appendix C). An example of entropy maximization in one level is given in the
Figure 7. Three random normally (Gaussian) distributed signals with means 0,
, 10 and standard deviation 5, 3 and 2 are concatenated to generate the input signal. Each signal has
samples so the generated signal has
samples. The histogram of the signal is given in
Figure 7b. The entropy maximization of the cortical coding algorithm compared with K-means, uniform distributed nodes and the theoretical maximum entropy line are presented in
Figure 7a. Uniform distributed nodes and the theoretical maximum entropy are added to comparison in order to have a baseline and upper limit comparison. The theoretical max entropy is calculated with Shannon’s entropy (
H) where the logarithmic base (
b) is equal to the number of nodes, so it is
. Uniform distributed nodes given in
Figure 7a are generated by calculating the range of the distribution (almost
to 20, see
Figure 7b
x axes) and inserting equally distanced nodes in the calculated range. As expected, the visiting probability of the uniform distributed nodes mimics the shape of the histogram of the signal with
. The cortical coding network (Cortex) entropy (
) is slightly better than K-means entropy (
). The example is given in one level of the tree. In consecutive levels of the tree, entropy is increased by each level. The node generation of the cortical coding algorithm is convergent, depending on the range limit (
) parameter. This parameter as mentioned earlier defines the minimum value of the effective range parameter to limit dynamic node generation. An example is presented in
Figure 7c, as the training epoch increases the total number of nodes increase in a convergent manner. Range Limit parameter directly affects the number of nodes generated. When it is small, it means that a well-trained node has a narrow effective range and the close neighborhood of this node is not in the node’s effective range. So, more nodes are generated in the neighborhood. In
Figure 7d the effect of range limit parameter is presented. The cortical coding network is trained with the same input data but with varying
parameters. The change in visiting probability according to
parameters can be seen from the figure. The information entropy results (
H) in
Figure 7d are presented in
scale.
2.5. Comparison of Algorithms for Codebook Generation
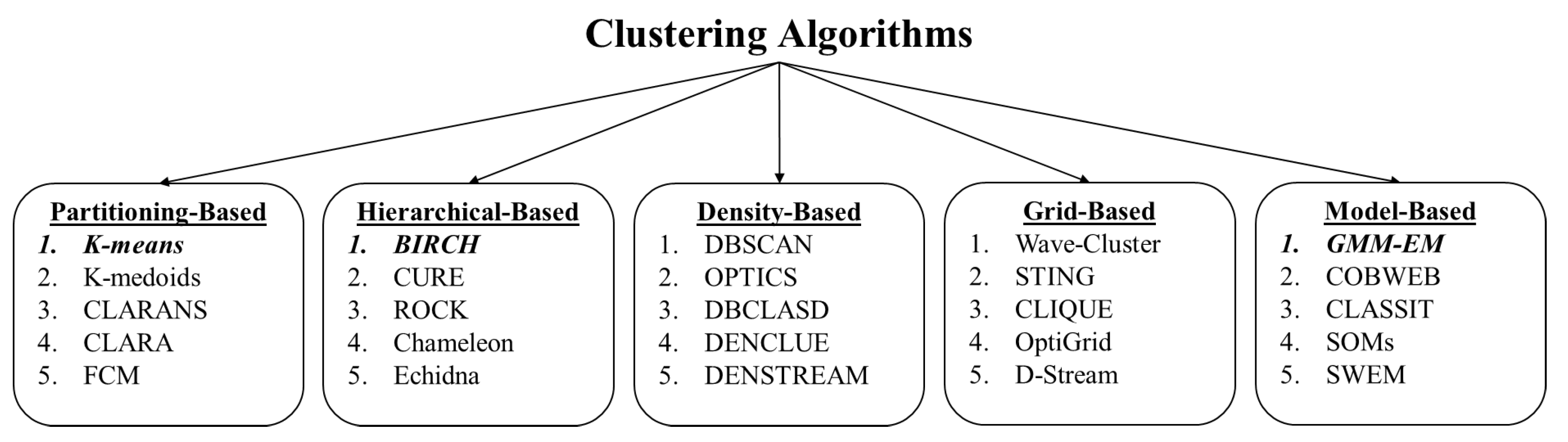
There are various types of clustering categorization in the literature. Xu, Dongkuan, and Tian made a comprehensive study on clustering types and in their research, they divide clustering methods into 19 types [
30]. Rai, Pradeep, and Sing divide clustering algorithms into four main groups, partition-based clustering, hierarchical clustering, density-based clustering and grid-based clustering [
31]. A common way of categorizing clustering algorithms is presented in
Figure 8.
In order to assess the utility of the cortical coding based algorithm in a broader context, its performance was compared with those of the commonly used clustering algorithms in vector quantization. As the representative clustering models, we choose GMM/EM, K-means, and Birch/PNN algorithms covering most categories, as shown in
Figure 8. Additionally, these models were chosen such that they would each generate a centroid point and that a number of cluster size (quantization number) could be set as an initial parameter. The algorithms were not selected from density-based and grid-based models as they would not satisfy these criteria. From partition-based clustering, K-means is chosen as it is a vector quantization method that partitions a certain number of points (n) into (k) clusters. The algorithm tries to match each point to the nearest cluster centroid (or mean) iteratively. In each iteration, the cluster centroid changes whether new points are assigned or not. The algorithm converges to a state where there is no cluster update for points. The main objective in this model is to end up in a state where in-class variances are maximum, and between-class variances are minimum. K-means is one of the most popular partition-based clustering algorithms and it is easy to implement, fairly fast, and is suitable for working with large datasets. There are many variations of K-means algorithm to increase the performance. The improvements can be classified as better initialization, repeating K-means various times, and the capability of combining the algorithm with another clustering method [
32,
33,
34]. The standard model which is also called Lloyd’s algorithm aims to match each data point to the nearest cluster centroid. The iterations continue until the algorithm converges to a state where there is no cluster update for points [
35]. The algorithm converges to the local optimum, and the performance is strictly related to determining initial centroids. K-means is considered to be an NP-hard problem [
36]. The time complexity of the standard K-means algorithm is
where
n is the number of vectors,
k is the number of clusters, and
d is the dimension of vectors while
i is the number of iteration. K-means is commonly used in many clustering and classification applications such as document clustering, identifying crime-prone areas, customer segmentation, insurance fraud detection, bioinformatics, psychology, and social science, anomaly detection, etc. [
34,
37,
38]. The pseudocode of the K-means algorithm used is presented in Algorithm 2.
| Algorithm 2 k-means |
Input
X input vectors,
k number of clusters
Output
C centroids,
procedure K-means
for do
Random vector from X
end for
while not converged do
Assign each vector in X to the closest centroid c
for each do
mean of vectors assigned to c
end for
end while
end procedure |
Birch was chosen as the second model for comparison from among the hierarchical clustering algorithms as it is one of the most popular methods for clustering large datasets and has very low time complexity yielding in fast processing. The model’s time complexity is
and a single read of the input data is enough for the algorithm to perform well. Birch consists of four phases. Firstly, it generates a Clustering Feature tree (CF) in phase 1 (see Algorithm 3). A CF tree node consists of three parts; a number, the linear sum, and the square sum of data points. Secondly, phase 2 is optional and it reduces the CF tree size by condensing it. In Phase 3, all leaf entries of the CF tree are clustered by an existing clustering algorithm. Phase 4 is also optional where refinement is carried out to overcome minor inaccuracies [
39,
40]. In Phase 3 of the Birch algorithm, an agglomerative hierarchical method (PNN) is used as the global clustering algorithm. It is one of the oldest and most basic vector quantization methods providing highly reliable results for clustering. PNN method starts with all input data points and merges the closest data points and then deletes these until a desired number of data points is left [
7,
41]. The drawback of the algorithm is its complexity, i.e., the time complexity of agglomerative hierarchical clustering is high and often not even suitable for medium size datasets. The standard algorithm has
but with refinements, the algorithm can work
. The pseudocode of PNN is presented in Algorithm 4.
| Algorithm 3 Birch |
Input
X input vectors,
T Threshold value for CF Tree
Output
C set of clusters
procedure BIRCH
for each do
find the leaf node for insertion
if leaf node is within the threshold condition then
add to cluster
update CF triples
else
if there is space for insertion then
insert as a single cluster
update CF triples
else
split leaf node
redistribute CF features
end if
end if
end for
end procedure |
| Algorithm 4 Pairwise Nearest Neighbor. |
Input
X input vectors,
k number of clusters
Output
C centroids,
procedure PNN
while do
FindNearestClusterPair()
MergeClusters
.
end while
end procedure |
From model-based clustering, Gaussian Mixture Model (GMM) with Expectation Maximization (EM) was chosen for comparison in the present work. GMM is a probabilistic model in which the vectors of the input dataset can be represented as a mixture of Gaussian distributions with unknown parameters. Clustering algorithms, such as K-means, assume that each cluster has a circular shape, which is one of their weaknesses. GMM tries to maximize the likelihood with the EM algorithm and each cluster has a spherical shape. While K-means aims to find a
k value that minimizes
, GMM aims to minimize
and has a complexity of
. It works well with real-time datasets and data clusters that do not have circular but elliptical shapes, thereby increasing the accuracy in such data types. GMM also allows mixed membership of data points and can be an alternative to fuzzy c-means, facilitating its common use in various generative unsupervised learning or clustering in a variety of implementations, such as signal processing, anomaly detection, tracking objects in a video frame, biometric systems, and speech recognition [
12,
42,
43,
44]. The pseudocode is presented in Algorithm 5.
| Algorithm 5 GMM |
Input
X input vectors,
k number of clusters
Output
C centroids, ,
procedure GMM
for do
Random vector from X
Sample covariance
end for
while not converged do
for do
end for
for do
.
end for
end while
end procedure |
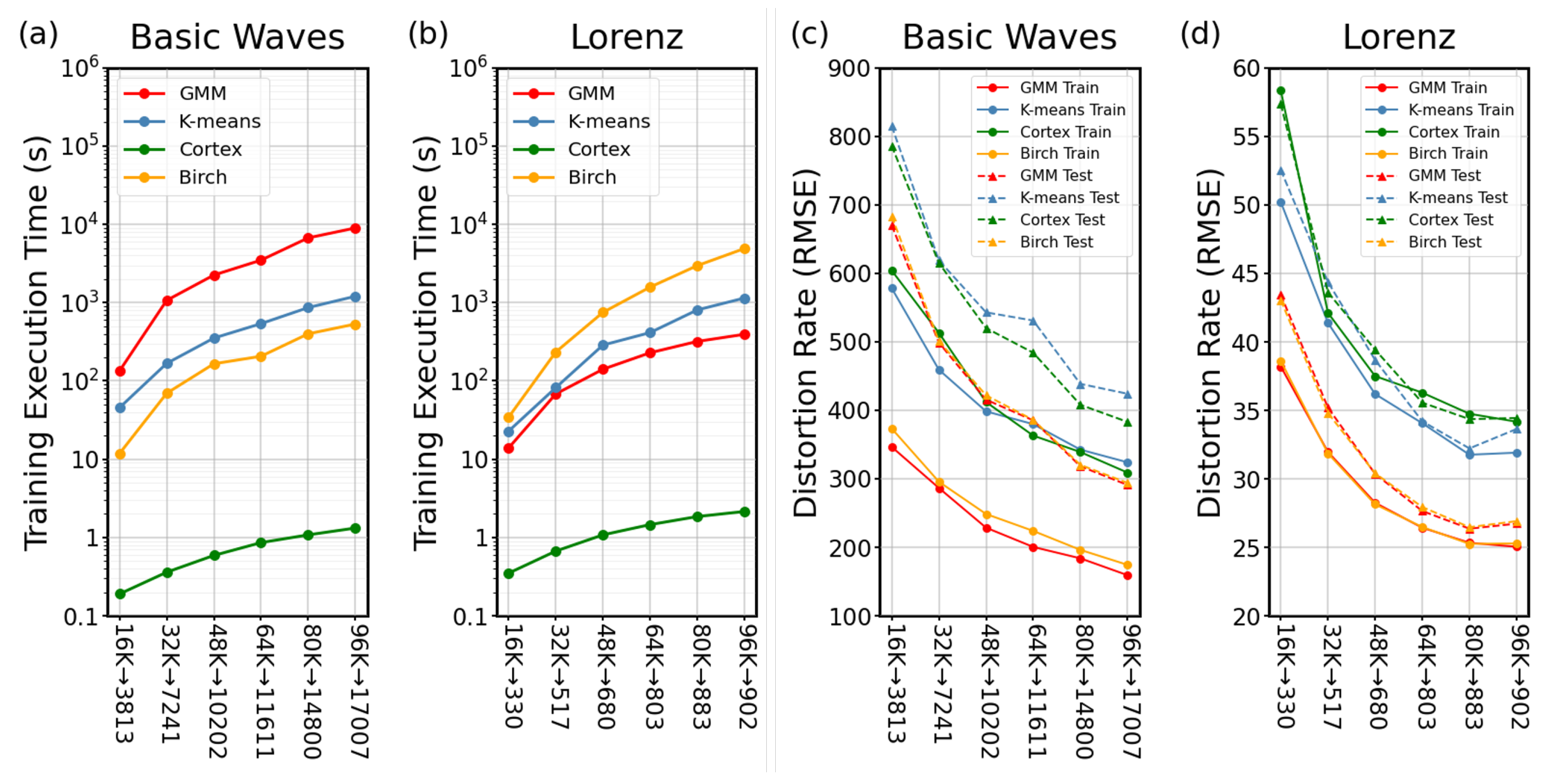
The performance of the cortical coding algorithm was compared in terms of execution time and distortion rate with the above listed commonly used clustering algorithms, each of which can create a centroid point suitable for vector quantization. As discussed, while K-means is a popular partition-based fast clustering algorithm, Birch is a hierarchical clustering algorithm that, even though it is slower than cortical coding method in terms of execution time, has an advantageous coding performance with low time complexity. GMM, as well as Birch, are model-based clustering algorithms and both are effective in overcoming the weakness of K-means. Each of the algorithms used for comparison, therefore, has different methods to solve the vector quantization and clustering problem, each having pros and cons. More specifically, K-means performance is related to initial codebook selection but has local minimum problem. In contrast, hierarchical clustering does not incorporate a random process; it is a robust method, but the algorithm is more complex than the K-means model. Agglomerative hierarchical clustering algorithms, like PNN, usually give better results in terms of distortion rate than K-means and GMM but their drawback is in time complexity. GMM produces fair distortion rates, better than K-means as it solves the weakness of this method with spherical clusters. Although GMM is a fairly fast algorithm when vector size is small, its drawback is time complexity, which increases when high dimensional vectors are present in the dataset. The common denominator of these algorithms, however, is that each uses a look-ahead buffer, which means they require the knowledge of all input vectors in the memory at the start of the process. This drawback in conventional algorithms that substantially slows down execution process, is overcome in the new model; the cortical coding algorithm works online, the key difference with K-means, Birch/PNN and GMM. This fast execution is enabled by a brain-inspired process, in which the input vectors are recorded to the cortical coding network one by one in a specific order and which then eventually become a sorted n-array tree (
Figure 1,
Figure 3 and
Figure 6).
To make the base comparisons among the algorithms, C++ is used for developing algorithms. C++ is a low-level programming language and is commonly used in many applications working on hardware, game development, OS, and real-time applications, where high performance is needed, etc., and it is especially chosen for performance reasons. We aim to compare the pure codes of the algorithms used in comparison. Commonly used libraries, however, may make use of extra optimizations in codes, some parallel processes, or extended instruction sets, which may yield performance improvements. Therefore, aiming to develop custom codes for all comparison algorithms, we wrote K-means, Birch, PNN, and GMM in C++. Custom GMM code has some problems with high dimension matrix inverse and determinant calculations; therefore, for some dataset, the convergence of the algorithm took extremely long and the quantization performance was only fair. As a result, we decide to use a commonly used machine learning C++ library for GMM. Mlpack is a well-known and widely used C++ machine learning library [
45]. We, therefore, used GMM codes in mlpack library, but, discovered that the execution time was very high. We believe that this is because the library code is not optimized for large number of clusters. We also tested PyClustering library, in which there are various types of clustering algorithms [
46]. Although most of these algorithms are written both in C++ and Python, unfortunately GMM is not one of these algorithms. Since Python is an interpreted language and usually uses libraries that were implemented in C++, it would always introduce an additional cost in execution time that is spent for calling the C++ libraries within the Python. It also has callback overhead even for libraries that were implemented in C++. Even though Python codes are slower than C++ codes, the scikit-learn is a well-optimized library and, thus, GMM results are much better (in terms of less execution time and less distortion rate) compared to mlpack library and our custom developed algorithm [
47]. As a result, we used scikit GMM codes in the comparison process discussed in the main text. In spite of these advantages of C++, to make further comparisons of the execution time and distortion for a even broader implementations, we also develop all algorithms in Python. Being an interpretable language, since it is not compiled, Python is slower than C++. Therefore execution time increases in Python versions but distortion rates stay the same. The data generated in this work, i.e., simple waves and Lorenz chaotic data, have been written in Python.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










