In this section, we first present our approach to modeling identities under noisy environments and a method for constructing stable representations; additionally, we describe the sparse dictionary learning structure for feature selection. Finally, we present our overall framework for effective jointly learning discriminative representations.
3.1. The Stochastic Process Model on Point Cloud Faces
Let one identity be denoted as
, with
i ranging through the different identities; we consider point cloud faces as realizations of a modeled noisy observation process as follows:
where each sample only provides spatial coordinates and can be expressed as a vector
, where
K is usually in 10k magnitudes. The
is a function that models the above geometric transformation, illumination, and occlusion variances. In addition, the
can be seen as a low-dimension random vector encoding the global illumination and rigid affine transformations [
33], though in general, the ergodicity of
is hard to be satisfied.
As a possible solution, a graph-based method [
14] applied a dynamic approximation procession to transform raw point clouds into uniform point/vertex sequences with lengths of thousands; then, it was used to compute the corresponding embedded features in order to imitate a universal characteristic representation.
This method shed light on defining signals with near-independent distributions between global and local variables; however, it required heavy training to realize the asymptotic stability, which is neither available nor necessary in modeling more consistent structures, e.g., faces, where geometric deformation and/or illumination/pose variances will not lead to large universal interferences.
Upon these observations, we built Euclidean lattices and learned the spatially aware features using solid scattering transform-based local operators; by applying subsequent sparse dictionary learning in the scattering domain, the uncorrelated signal components of the identity in question were jointly learned and inhibited.
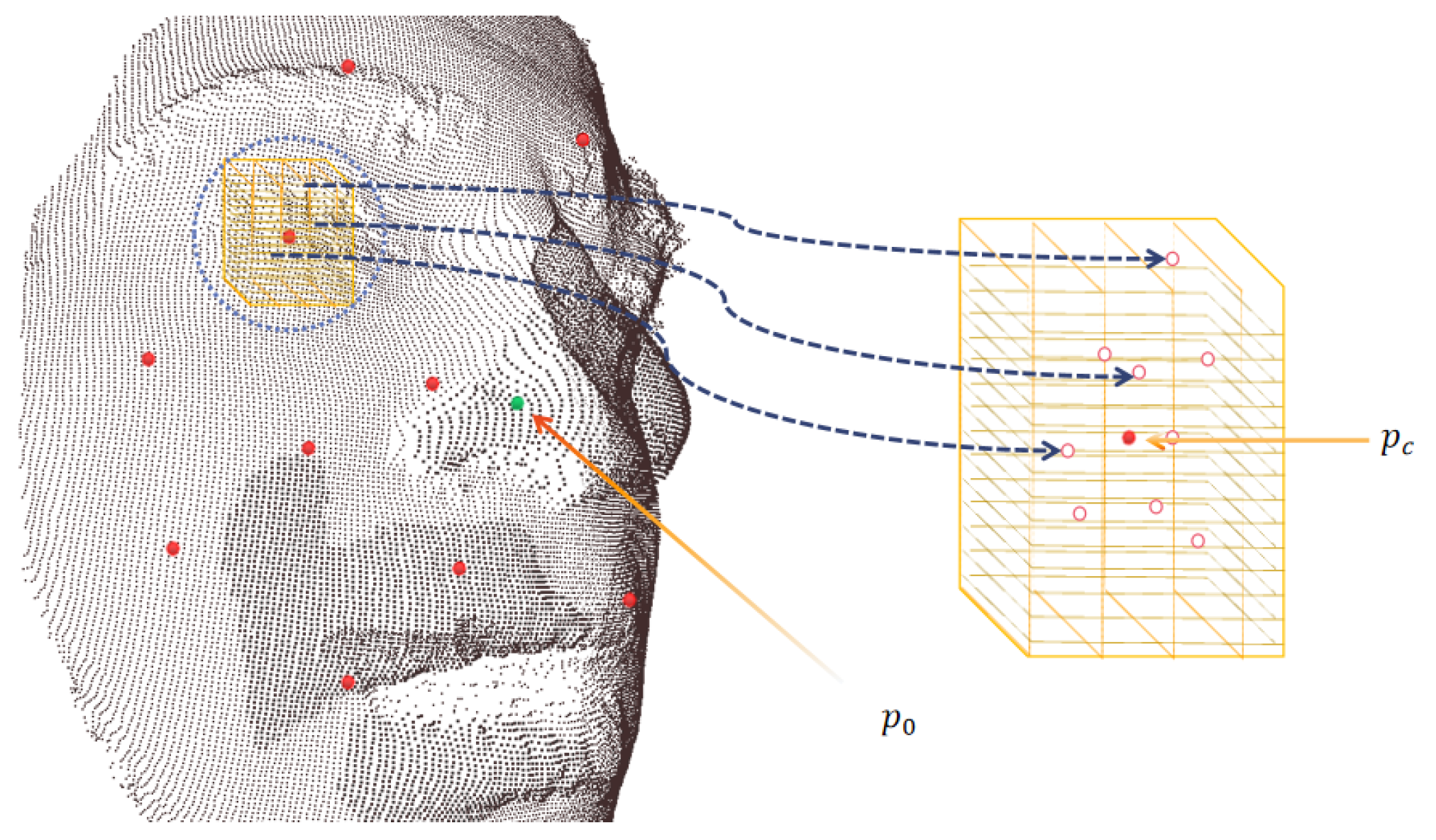
The local 3D lattice operator: We used
to denote the centroid of
, which was easy to obtain, and from
we constructed the 3D global coordination,
. The succeeding step used farthest point (FP) [
10] sampling on
; note that we only needed to draw the countable
points as query points,
, for the subsequent spatial thresholding nearest-neighbor searching. From each
, we drew the N nearest points from their ambient spaces to form a leaf subset:
where we picked a threshold radius—
—to dynamically assure coverage. Furthermore, within each ambient space, we associated a 3D local lattice coordination
and defined the overall density estimation function as the concatenation of C local areas:
where each
was parameterized by
which is a sum of the Gaussian densities centered on each
. This spatial construction sliced each
into
C local receptive fields; we adjusted the width parameter,
, of the Gaussian equivalent to the distance from the nearest alternative entry point, i.e.,
. By renominating each
with indicator function
, a raw point was transformed into a naive Borel set, which had a uniform probability measure, so we defined the global piece-wise density function as
.
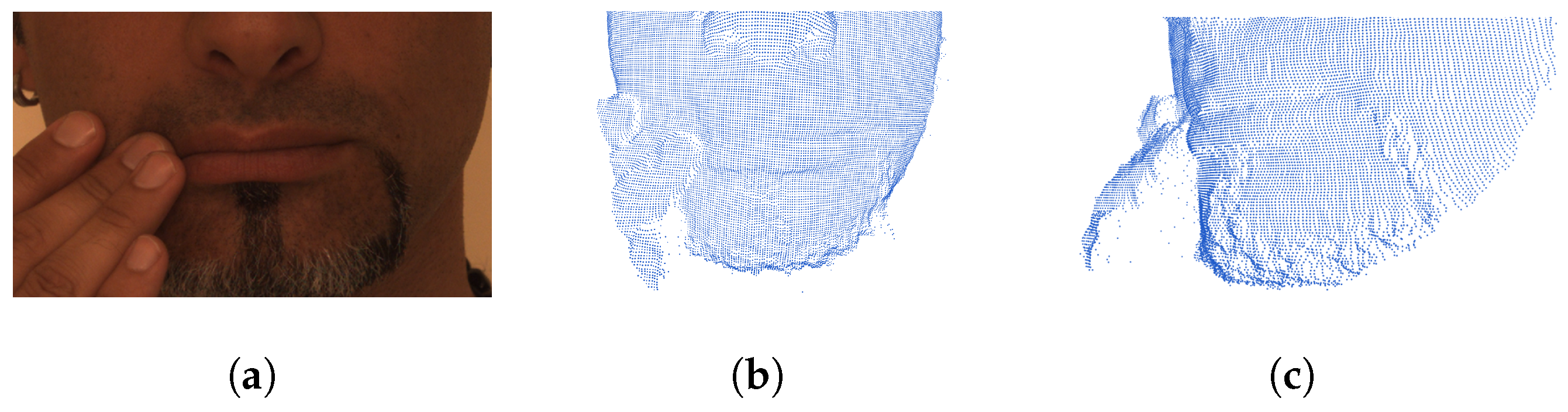
This approach encoded a raw point cloud face into a more regular continuous probability density representation, with local fields being invariant to the permutations of the input order; each characteristic vector also had a corresponding length, which enabled the windowed operations (See
Figure 4 for illustration).
However, the above isometric deformations not only broke the order consistency but also gave rise to mixed deformations and polluted the geometric features; therefore, we needed to add a stabilizer to obtain the rotation and translation invariances.
To illustrate the operation, a piece of pseudocode is given below as Algorithm 1:
| Algorithm 1 The Local Lattice Operation: |
- Require:
(the centroid of a raw face scan ), - 1:
Set as the initial point of farthest point sampling and - 2:
DrawC points from - 3:
for in do - 4:
Set as the origin, and - 5:
Compute - 6:
Compute local lattice - 7:
Compute local density estimation - 8:
end for - 9:
Concatenate local densities to form the overall function as - 10:
return
|
Note that since the direction of local lattice
was exactly covariant to the global coordination of the scanned face, the above-obtained local density feature actually exposed itself to a risk of being sensitive to rigid rotation, as well as to the order permutation of the grid position points (see
Figure 5 for an illustration). Therefore, we needed to construct a stabilizer to eliminate such isometry.
Windowed solid harmonic wavelet scattering: A scattering transform is a geometric deep learning framework that replaces learning-based cross-correlation kernels with predefined filter banks. Induced stability for multiple species of isometrics and translation invariances can be prescribed with a group-invariant structure built from a deliberately configured wavelet filter bank [
19,
20]. For 2D signals (e.g., images), the constitutive substructure in a scattering network comprises the wavelet filters with zero integrals and yields fast decay along
; each can be parameterized by a rotation parameter,
, and dilation parameter,
j, as
where
belongs to a finite-rotation group of
.
For 3D signals—as in 3D face recognition with point cloud samples—3D rotation invariance is crucial since the random pose variation may provide an alias for the local density feature obtained by our local lattice operator (see
Figure 5). Accordingly, we built a stabilizer in the solid harmonic scattering approach from [
8], whereby solving the Laplacian equation with the 3D spherical coordinates and replacing the exponent term in the spherical harmonic function,
, the solid harmonic wavelet can be expressed as follows:
In addition, by summing up the energies over
m, a 3D covariant modulus operator can be defined as
In short, a solid harmonic scattering transform is defined as the operation of summing up the above modulus coefficients over
to produce translation-/rotation-invariant representation within each local field (see
Figure 6 for illustration). Furthermore, by raising
to exponent q and then sub-sampling
at
with an oversampling factor—
to avoid aliasing, the first-order solid scattering coefficients are
Then, by iterating subsampling at intervals
with
and recomputing the scattering coefficient on the first-order output, we obtained the following second-order scattering transform:
These representations can hold local invariant spatial information up to a predefined scale,
; in our case, this was adjusted to be equivalent to the local threshold diameter,
. Furthermore, we needed to extend this operation to a universal representation. Here, we defined the windowed first and second solid harmonic wavelet scattering as follows:
Figure 6.
Illustration of the localized solid harmonic scattering transformation; the dashed blocks represent the extracted invariant representations from each local ambient space.
Figure 6.
Illustration of the localized solid harmonic scattering transformation; the dashed blocks represent the extracted invariant representations from each local ambient space.
For a better illustration, a brief pseudo-code is stated below as Algorithm 2:
| Algorithm 2 Windowed Solid Harmonic Wavelet Scattering |
- Require:
(local density features), J (scale parameter), L (rotation phase parameter), Q (exponential parameter) - 1:
Set wavelet t according to a predefined parameter with Equation [ 6] - 2:
for in do - 3:
for do - 4:
Compute the dilated modulus operation on scattering convolution , e.g., Equation [ 7] - 5:
end for - 6:
Compute the first-order coefficients as Equation [ 8] - 7:
Compute the second-order coefficients as Equation [ 9] - 8:
Concatenate first and second coefficients as the local invariant representation - 9:
end for - 10:
Concatenate as the global invariant representation - 11:
return
|
3.2. Piece-Wise Smoothed Solid Harmonic Scattering Coefficient Representation
The above strategy makes the representation stable to local deformations, and since face point clouds share a largely consistent global structure, it allows us to represent them even if no effective global embedding exists.
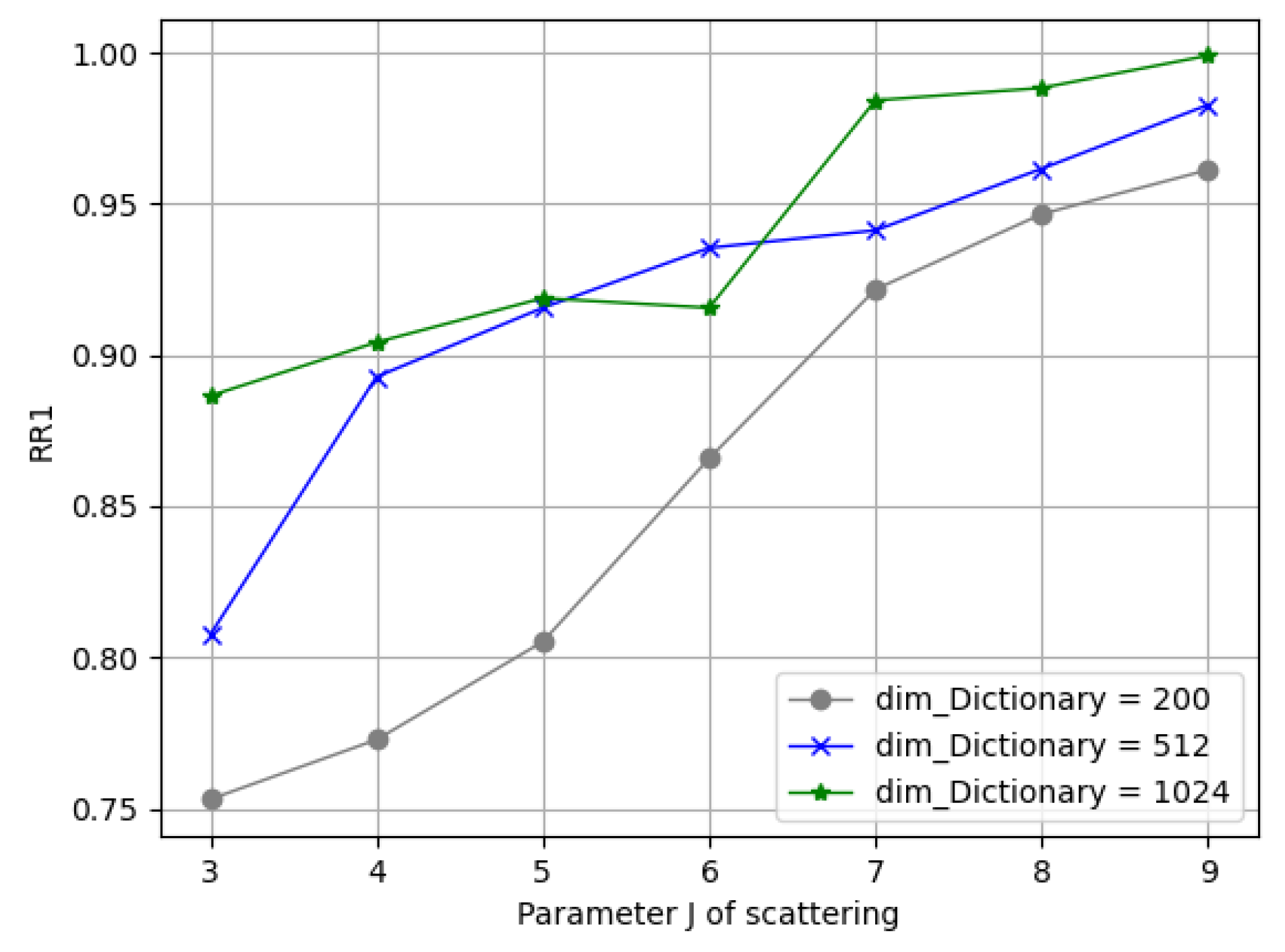
To balance the computation complexity and resolution in our experiments, we chose
,
, and
; here, the above windowed operation and scattering coefficients were implemented with the Kymatio software package [
34]. To simplify our notation, we wrote the scattering representation in shorthand as follows:
where
p is the union of the first and second indices
and
, respectively, and the overall scattering coefficients of a point cloud face are
To give an illustration of this representation, we mapped the first-order scattering coefficients of two identities (bs001 and bs070) onto the scattering indices shown in
Figure 7; identity bs001 from Bosphorus had two realizations and we could see that, although there was a significant visual difference between them, their scattering coefficients had a similar appearance.
To enhance the discrimination of this representation—and inspired by [
7]—in the next section, we construct a “facial scattering coefficients dictionary” from the above representation to associate multiscale properties for 3D facial recognition. Specifically, based on the good results from the 2D scattering coefficients in [
9], we follow their idea for utilizing supervised dictionary learning to select the most relative classification features from the 3D scattering coefficients.
3.3. Constructing a Local Dictionary with Semi-Supervised Sparse Coding on Scattering Coefficients
The scattering representation brings desired properties including Lipschitz continuity to translations and deformations [
19]; however, the overall structure constructed using FPS and local nearest searching and normalization assumes uniform energy distribution among the realizations of each identity. In real scan scenarios, this assumption can be damaged when permutations, e.g., occlusion/rigid overall rotation, break the integrity of the face samples. In some severe cases, a certain portion of points are missing from face samples in Bosphorus. To reduce this category of intraclass variance, we imposed the homotopy dictionary learning framework presented by [
9] to build a local coefficient dictionary. Then, we trained the network to select the most relative classification features from the scattering coefficients.
Supervised Sparse Dictionary Learning: The idea of selecting the sparse combination of functions from redundant/over-complete dictionaries to match the random signal structure was presented by [
35] and flourishes in multiple fields related to signal processing. Supervised dictionary learning was first presented by [
36] to solve the following optimization problem:
where
indicates a simple classifier’s parameters;
ℓ is the loss function for computing the penalization on the prediction
;
is the sparse code of the input signal,
, with the learned dictionary,
D.
In our problem, the input signal,
, had a union form; hence, we constructed a global dictionary with structured local dictionaries defined as:
where
are C sub-dictionaries with a certain structure—
. Here, K indicates the length of the local pseudo coordination,
p, of
; the aim was to represent
B input samples (
B—batch size) as linear combinations of
D’s elements. Each
had
normalized atoms/columns—
. Then, the sparse approximation optimization was used to solve
where
is the concatenated sparse codes
. Suppose the optimized sparse coefficient matrix is
for a batch of input signals,
, where each sub-dictionary has a local code
.
Expected Scattering Operation: Since we regrouped the raw point clouds and individually computed the invariant representations, , the windowed representation also had a non-expansive property; within each local field, the translation converged to being negligible by taking .
In practice, this will possibly bring ambiguity. By setting a small C, each field becomes too large and results in the loss of higher-frequency components. Yet, for a larger C, the computing complexity amounts to , and the optimization of such a concatenation will lead to supernumerary consideration, e.g., vanishing gradients.
Thanks to the integral normalized scattering transform [
20], which preserves a uniform norm by utilizing the non-expansive operator
, we considered our question of structured learning for some random processes using the supposed condition. For the underlying distributions of point cloud faces yet to be established in practice, we focused on finding a solution with the above intuition and incautiously assumed our representation to be a stationary process up to negligible higher components; thus, the metric among (a batch of) spatial realizations reduced to a summation of the mean-square distances is
This definition is simple but effective as a regression term with a forward–backward approximation, which is based on an operation called proximal projection [
37].
where it encloses a solution with a forward step by computing a reconstructed
and a backward step by putting it back into the proximal projection operator, updating
and
D. Since our aim was to implement an efficient classification model, the sparse code should be able to preserve the principle components of the input signal; additionally, with the experimental observation of the point cloud faces’ solid scattering coefficients, we saw most energy being carried by its rare lower-frequency components and characterized by larger-magnitude coefficients; therefore, we picked the recent generalized ISTC algorithm [
9], which adopts an auxiliary dictionary to accelerate convergence. Here, the ReLU function acts as a positive soft thresholding implementation of proximal projection. Then, the optimization can be reached in an unsupervised
-iteration-updating scheme, expressed as follows:
The overall architecture is shown in
Figure 8.
To effectively demonstrate our methods, a pseudo-code is given in Algorithm 3:
| Algorithm 3 Dictionary learning on local facial coefficients |
- Require:
(training set), D (initial dictionary), (initial Lagrange multiplier, e.g., thresholding bias), (classifier parameter), N (number of iterations), (learning rate), v (regulation parameter) - 1:
Draw a batch of samples and compute the scattering coefficients using the methods in Section 3.2; denote the coefficient vectors as - 2:
fordo - 3:
for do - 4:
Compute where - 5:
Compute - 6:
Update - 7:
end for - 8:
Compute and - 9:
end for - 10:
Compute the classification loss - 11:
Update the parameters by a projected gradient step [ 36] - 12:
, - 13:
- 14:
return Learned Dictionary D
|






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









