
Audio Augmentation for Non-Native Children’s Speech Recognition through Discriminative Learning


Abstract
:1. Introduction
- A lack of accessibility to a large amount of training data for non-native children’s speech [2];
- Reading miscues, such as lexical disfluency, hesitations, intra-word switching (combining two languages within a single word), incomplete words, and filled interruptions, word repetitions, word boundary errors, and the adoption of some native language sounds and phonology are among them.
2. Related Work
3. Children Speech Corpora
3.1. Participants
3.2. Data Collection
3.3. Data Processing
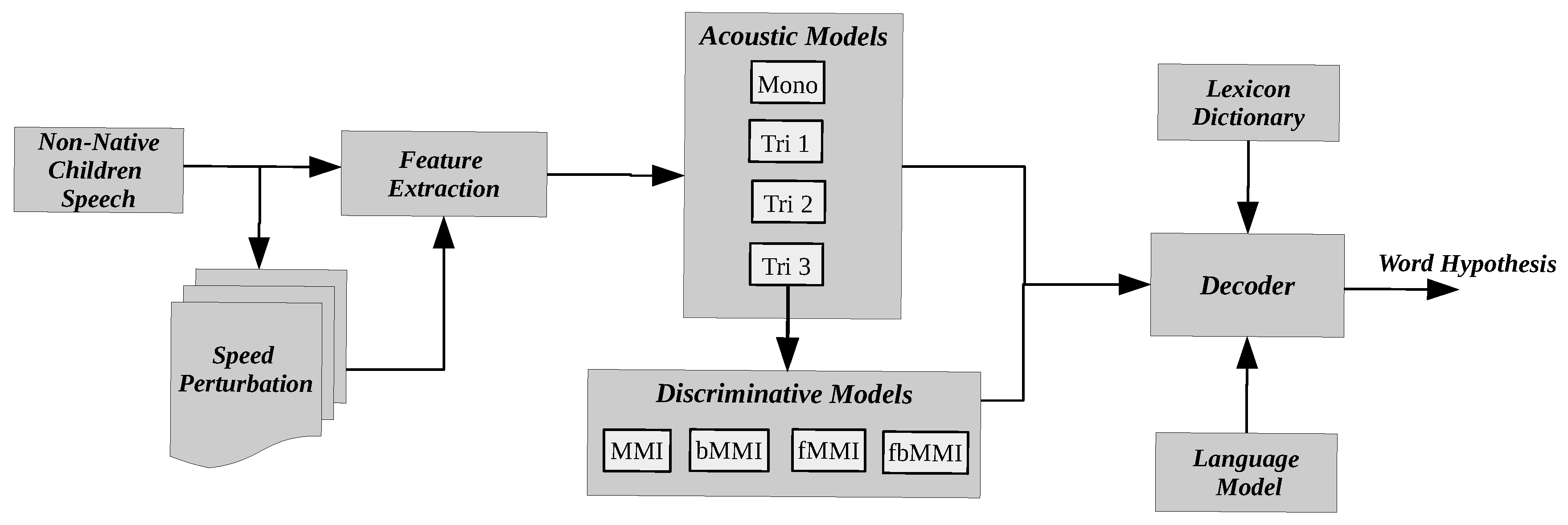
4. Proposed System Overview
4.1. Acoustic Models
4.2. Discriminative Models
4.2.1. Maximum Mutual Information (MMI)
4.2.2. Boosted Maximum Mutual Information (bMMI)
4.2.3. Feature-Space Maximum Mutual Information (fMMI)
4.2.4. Boosted Feature-Space Maximum Mutual Information (fbMMI)
5. Experimental Setup
5.1. Data Interpretation
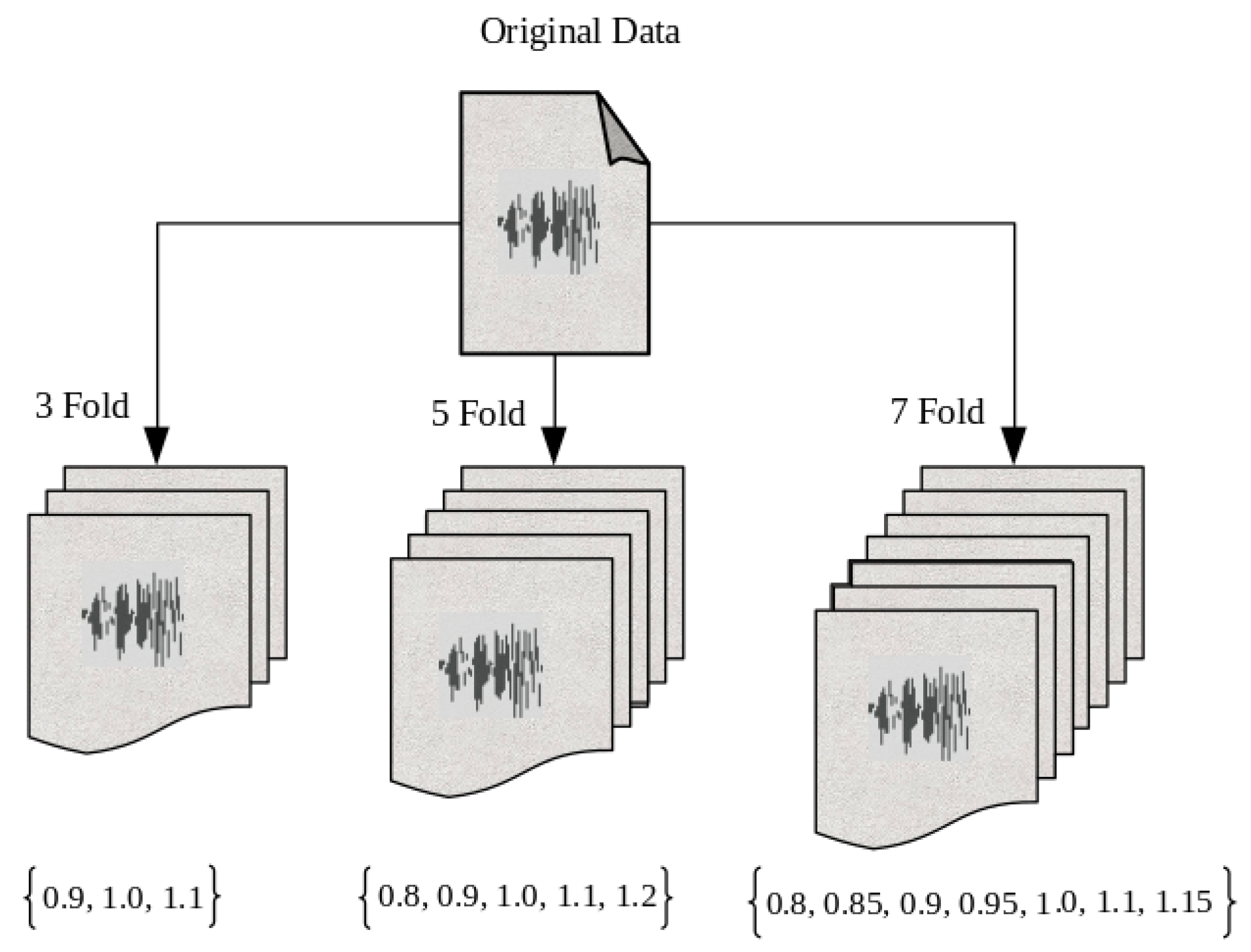
5.2. Speed Perturbation
6. Experimental Results and Discussion
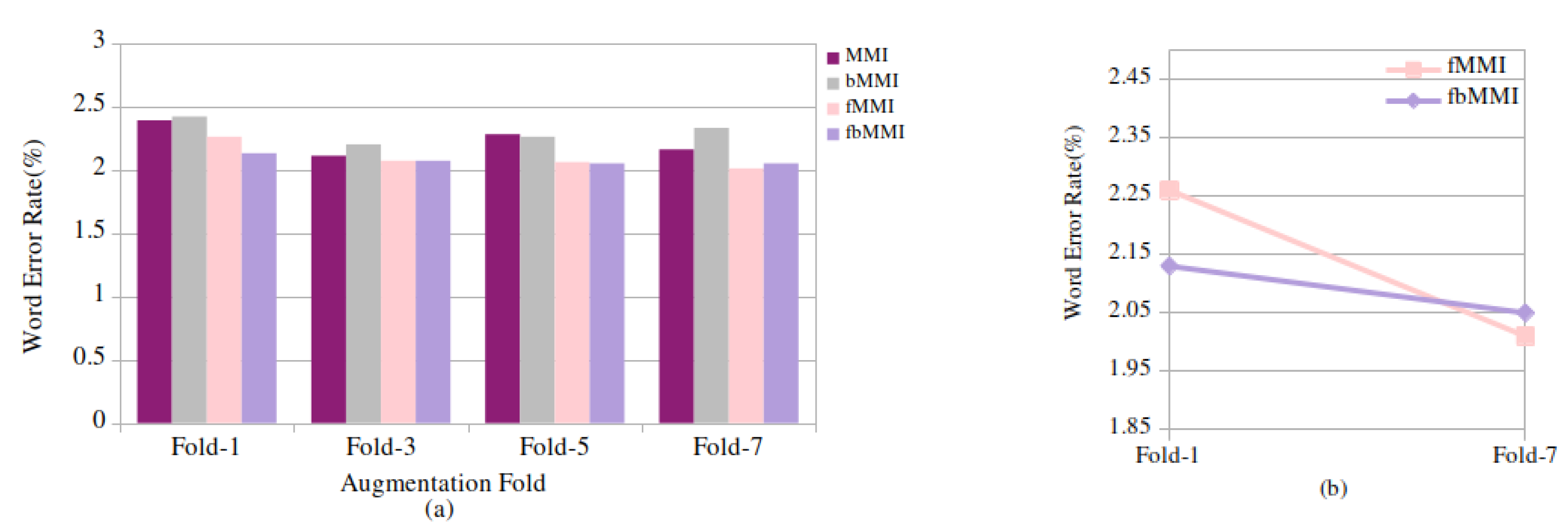
6.1. Performance Analysis of Proposed Models on Read Speech Task
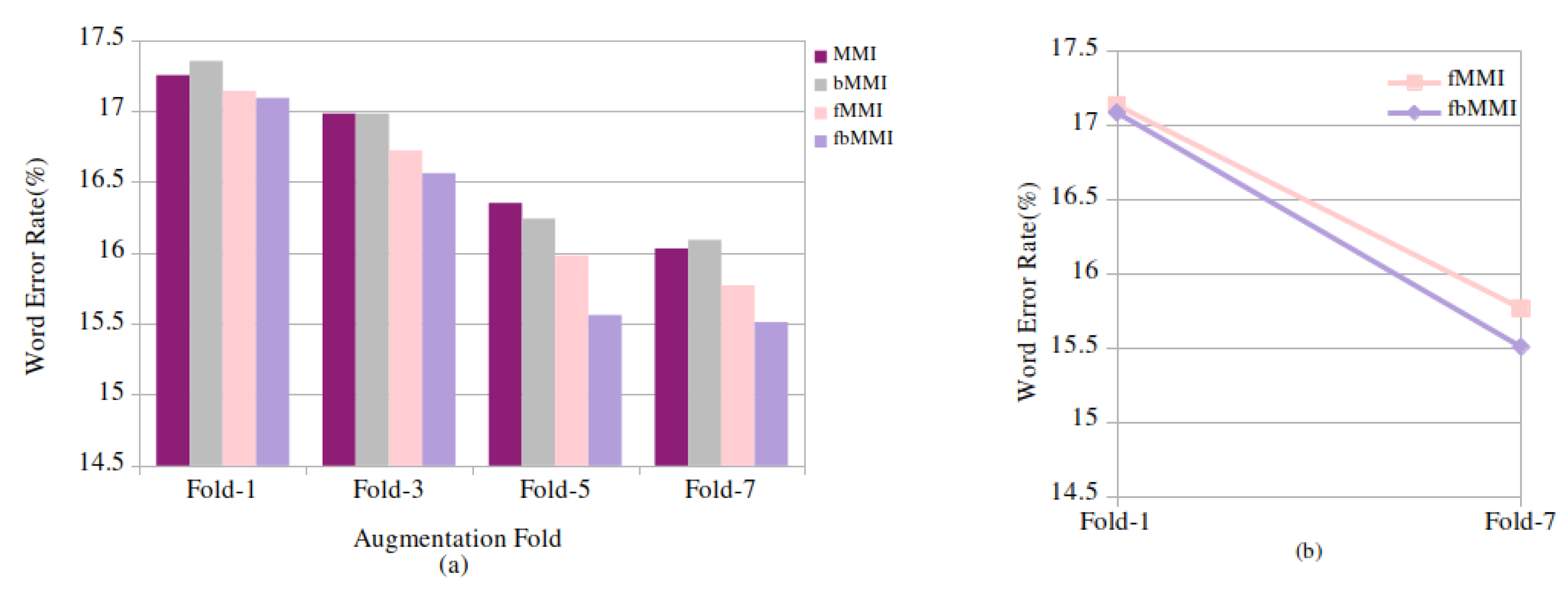
6.2. Performance Analysis of Proposed Models on Spontaneous Speech Task
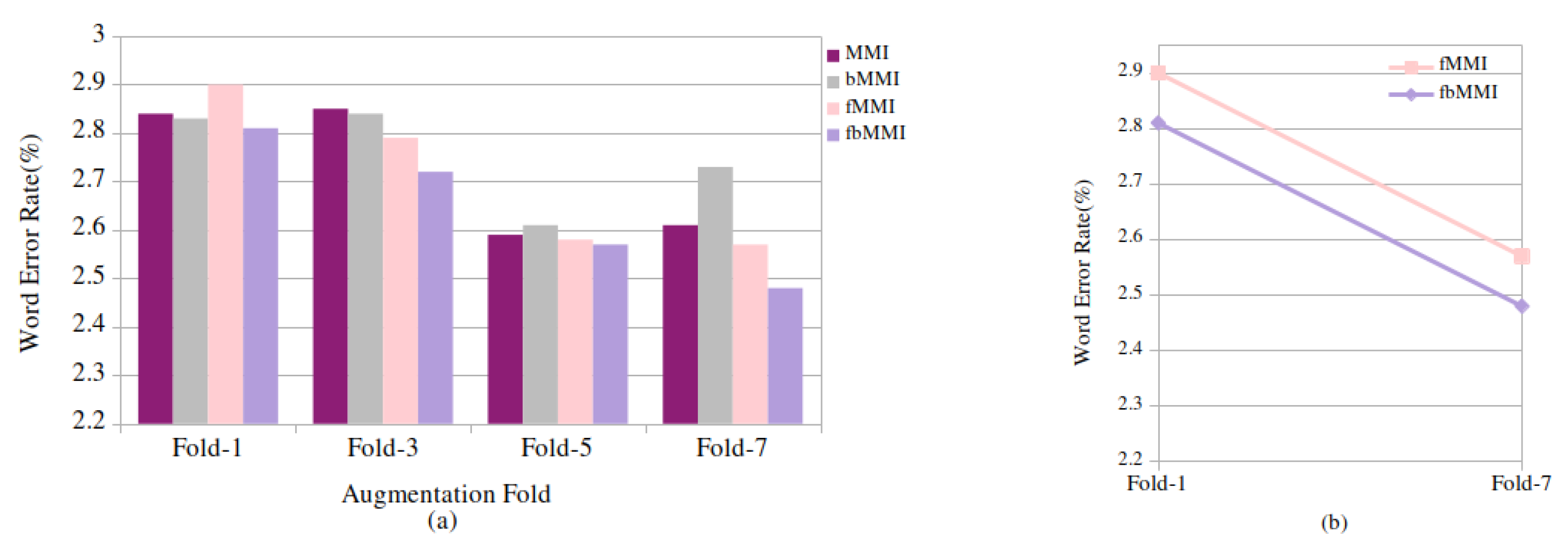
6.3. Performance Analysis of Proposed Models on Combined Speech Task
6.4. Comparative Analysis of Earlier State of the Art on Non-Native Children Speech Recognition
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Xiong, W.; Droppo, J.; Huang, X.; Seide, F.; Seltzer, M.L.; Stolcke, A.; Yu, D.; Zweig, G. Toward human parity in conversational speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2410–2423. [Google Scholar] [CrossRef]
- Park, S.; Culnan, J. A comparison between native and non-native speech for automatic speech recognition. J. Acoust. Soc. Am. 2019, 145, 1827. [Google Scholar] [CrossRef]
- Pandey, K.K.; Jha, S. Exploring the interrelationship between culture and learning: The case of English as a second language in India. Asian Englishes 2021, 1–17. [Google Scholar] [CrossRef]
- O’Brien, M.G.; Derwing, T.M.; Cucchiarini, C.; Hardison, D.M.; Mixdorff, H.; Thomson, R.I.; Strik, H.; Levis, J.M.; Munro, M.J.; Foote, J.A.; et al. Directions for the future of technology in pronunciation research and teaching. J. Second Lang. Pronunc. 2018, 4, 182–207. [Google Scholar] [CrossRef] [Green Version]
- Mulholland, M.; Lopez, M.; Evanini, K.; Loukina, A.; Qian, Y. A comparison of ASR and human errors for transcription of non-native spontaneous speech. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 5855–5859. [Google Scholar]
- Kovtun, V.; Kovtun, O.; Semenov, A. Entropy-Argumentative Concept of Computational Phonetic Analysis of Speech Taking into Account Dialect and Individuality of Phonation. Entropy 2022, 24, 1006. [Google Scholar] [CrossRef]
- Yarra, C.; Srinivasan, A.; Gottimukkala, S.; Ghosh, P.K. SPIRE-fluent: A Self-Learning App for Tutoring Oral Fluency to Second Language English Learners. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 968–969. [Google Scholar]
- Kelly, A.C.; Karamichali, E.; Saeb, A.; Veselỳ, K.; Parslow, N.; Deng, A.; Letondor, A.; O’Regan, R.; Zhou, Q. Soapbox Labs Verification Platform for Child Speech. In Proceedings of the INTERSPEECH, Shanghai, China, 25–29 October 2020; pp. 486–487. [Google Scholar]
- Zhang, J.; Zhang, Z.; Wang, Y.; Yan, Z.; Song, Q.; Huang, Y.; Li, K.; Povey, D.; Wang, Y. Speechocean762: An open-source non-native English speech corpus for pronunciation assessment. arXiv 2021, arXiv:2104.01378. [Google Scholar]
- Evanini, K.; Wang, X. Automated speech scoring for non-native middle school students with multiple task types. In Proceedings of the INTERSPEECH, Lyon, France, 25–29 August 2013; pp. 2435–2439. [Google Scholar]
- Mostow, J. Why and how our automated reading tutor listens. In Proceedings of the International Symposium on Automatic Detection of Errors in Pronunciation Training (ISADEPT), Stockholm, Sweden, 6–8 June 2012; pp. 43–52. [Google Scholar]
- Radha, K.; Bansal, M.; Shabber, S.M. Accent Classification of Native and Non-Native Children using Harmonic Pitch. In Proceedings of the 2022 2nd International Conference on Artificial Intelligence and Signal Processing (AISP), Vijayawada, India, 12–14 February 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Bansal, M.; Sircar, P. Phoneme Based Model for Gender Identification and Adult-Child Classification. In Proceedings of the 2019 13th International Conference on Signal Processing and Communication Systems (ICSPCS), Surfers Paradise, Australia, 16–18 December 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Bansal, M.; Sircar, P. AFM Signal Model for Digit Recognition. In Proceedings of the 2021 Sixth International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 25–27 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 354–358. [Google Scholar]
- Gretter, R.; Matassoni, M.; Falavigna, G.D.; Keelan, E.; Leong, C.W. Overview of the interspeech tlt2020 shared task onasr for non-native children’s speech. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020. [Google Scholar]
- Li, Q.; Russell, M.J. An analysis of the causes of increased error rates in children’s speech recognition. In Proceedings of the Seventh International Conference on Spoken Language Processing, Denver, CO, USA, 16–20 September 2002. [Google Scholar]
- Shivakumar, P.G.; Georgiou, P. Transfer learning from adult to children for speech recognition: Evaluation, analysis and recommendations. Comput. Speech Lang. 2020, 63, 101077. [Google Scholar] [CrossRef] [Green Version]
- Matassoni, M.; Gretter, R.; Falavigna, D.; Giuliani, D. Non-native children speech recognition through transfer learning. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 6229–6233. [Google Scholar]
- Laptev, A.; Andrusenko, A.; Podluzhny, I.; Mitrofanov, A.; Medennikov, I.; Matveev, Y. Dynamic acoustic unit augmentation with bpe-dropout for low-resource end-to-end speech recognition. Sensors 2021, 21, 3063. [Google Scholar] [CrossRef]
- Qian, Y.; Evanini, K.; Wang, X.; Lee, C.M.; Mulholland, M. Bidirectional LSTM-RNN for Improving Automated Assessment of Non-Native Children’s Speech. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; pp. 1417–1421. [Google Scholar]
- Kathania, H.; Singh, M.; Grósz, T.; Kurimo, M. Data augmentation using prosody and false starts to recognize non-native children’s speech. arXiv 2020, arXiv:2008.12914. [Google Scholar]
- Lo, T.H.; Chao, F.A.; Weng, S.Y.; Chen, B. The NTNU system at the interspeech 2020 non-native Children’s speech ASR challenge. arXiv 2020, arXiv:2005.08433. [Google Scholar]
- Knill, K.M.; Wang, L.; Wang, Y.; Wu, X.; Gales, M.J. Non-Native Children’s Automatic Speech Recognition: The INTERSPEECH 2020 Shared Task ALTA Systems. In Proceedings of the INTERSPEECH, Shanghai, China, 25–29 October 2020; pp. 255–259. [Google Scholar]
- Shahin, M.A.; Lu, R.; Epps, J.; Ahmed, B. UNSW System Description for the Shared Task on Automatic Speech Recognition for Non-Native Children’s Speech. In Proceedings of the INTERSPEECH, Shanghai, China, 25–29 October 2020; pp. 265–268. [Google Scholar]
- Chen, G.; Na, X.; Wang, Y.; Yan, Z.; Zhang, J.; Ma, S.; Wang, Y. Data Augmentation For Children’s Speech Recognition–The “Ethiopian” System For The SLT 2021 Children Speech Recognition Challenge. arXiv 2020, arXiv:2011.04547. [Google Scholar]
- Ghazi, S.R.; Ullah, K. Concrete operational stage of Piaget’s cognitive development theory: An implication in learning general science. Gomal Univ. J. Res. [GUJR] 2015, 31, 78–89. [Google Scholar]
- SurveyLex. Available online: http://neurolex.co/uploads/ (accessed on 1 January 2022).
- Schwoebel, J. SurveyLex. Available online: https://www.surveylex.com/ (accessed on 1 January 2022).
- Fernando, S.; Moore, R.K.; Cameron, D.; Collins, E.C.; Millings, A.; Sharkey, A.J.; Prescott, T.J. Automatic recognition of child speech for robotic applications in noisy environments. arXiv 2016, arXiv:1611.02695. [Google Scholar]
- Radha, K.; Bansal, M. Non-Native Children Speech Mini Corpus. Available online: https://doi.org/10.34740/KAGGLE/DS/2160743 (accessed on 9 May 2022).
- (cbagwell@users.sourceforge.net), C.B. Sound Exchange. Available online: http://sox.sourceforge.net/SoX/Resampling (accessed on 5 February 2022).
- Goodman, J.T. A bit of progress in language modeling. Comput. Speech Lang. 2001, 15, 403–434. [Google Scholar] [CrossRef]
- Mohri, M.; Pereira, F.; Riley, M. Speech recognition with weighted finite-state transducers. In Springer Handbook of Speech Processing; Springer: Berlin/Heidelberg, Germany, 2008; pp. 559–584. [Google Scholar]
- Ben-Yishai, A.; Burshtein, D. A discriminative training algorithm for hidden Markov models. IEEE Trans. Speech Audio Process. 2004, 12, 204–217. [Google Scholar] [CrossRef]
- Morris, A.C.; Maier, V.; Green, P. From WER and RIL to MER and WIL: Improved evaluation measures for connected speech recognition. In Proceedings of the Eighth International Conference on Spoken Language Processing, Jeju Island, Korea, 4–8 October 2004. [Google Scholar]
- Dua, M.; Aggarwal, R.K.; Biswas, M. Discriminatively trained continuous Hindi speech recognition system using interpolated recurrent neural network language modeling. Neural Comput. Appl. 2019, 31, 6747–6755. [Google Scholar] [CrossRef]
- Lu, C.; Tang, C.; Zhang, J.; Zong, Y. Progressively Discriminative Transfer Network for Cross-Corpus Speech Emotion Recognition. Entropy 2022, 24, 1046. [Google Scholar] [CrossRef]
- Hasija, T.; Kadyan, V.; Guleria, K.; Alharbi, A.; Alyami, H.; Goyal, N. Prosodic Feature-Based Discriminatively Trained Low Resource Speech Recognition System. Sustainability 2022, 14, 614. [Google Scholar] [CrossRef]
- Gillick, D.; Wegmann, S.; Gillick, L. Discriminative training for speech recognition is compensating for statistical dependence in the HMM framework. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 4745–4748. [Google Scholar]
- Heigold, G.; Ney, H.; Schluter, R.; Wiesler, S. Discriminative training for automatic speech recognition: Modeling, criteria, optimization, implementation, and performance. IEEE Signal Process. Mag. 2012, 29, 58–69. [Google Scholar] [CrossRef]
- Povey, D.; Kanevsky, D.; Kingsbury, B.; Ramabhadran, B.; Saon, G.; Visweswariah, K. Boosted MMI for model and feature-space discriminative training. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 30 March–4 April 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 4057–4060. [Google Scholar]
- Seide, F.; Fu, H.; Droppo, J.; Li, G.; Yu, D. On parallelizability of stochastic gradient descent for speech DNNS. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 235–239. [Google Scholar] [CrossRef]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 11–15 December 2011; IEEE Signal Processing Society: Piscataway, NJ, USA, 2011. [Google Scholar]
- Leung, W.K.; Liu, X.; Meng, H. CNN-RNN-CTC based end-to-end mispronunciation detection and diagnosis. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8132–8136. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Hulstijn, J.H. Language proficiency in native and nonnative speakers: An agenda for research and suggestions for second-language assessment. Lang. Assess. Q. 2011, 8, 229–249. [Google Scholar] [CrossRef] [Green Version]
- Kathania, H.K.; Kadiri, S.R.; Alku, P.; Kurimo, M. Using data augmentation and time-scale modification to improve asr of children’s speech in noisy environments. Appl. Sci. 2021, 11, 8420. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Baseline | Utterances | Total Words | Unique Words | Duration (hours) | |
|---|---|---|---|---|---|
| Read Speech | Train | 1585 | 18,154 | 155 | 1.82 |
| Test | 588 | 6769 | 123 | 0.65 | |
| Spontaneous Speech | Train | 569 | 6906 | 131 | 0.67 |
| Test | 156 | 1896 | 82 | 0.18 | |
| Combined Speech | Train | 2274 | 26,443 | 256 | 2.65 |
| Test | 624 | 7286 | 183 | 0.67 | |
| Type of Disfluency | Example |
|---|---|
| Word Repetitions | this is a umbrella it is it is useful when it rains |
| Word Fragments | there was a sa- sad dog he did not have any friend |
| Intra-Word Switching | everyone in my schooluu likes icecream |
| Hesitations | on his way home he hmm he crossed a river and saw another dog |
| Ungrammatical Words | this is a pencil we will use it when when we should write our home works |
| Datasets | Fold | Perturb. Factors | #Hrs | #Tokens |
|---|---|---|---|---|
| Read Speech | 1 | Baseline | 1.82 | 1.58 K |
| 3 | 0.9, 1.0, 1.1 | 5.51 | 4.75 K | |
| 5 | 0.8, 0.9, 1.0, 1.1, 1.2 | 9.32 | 7.92 K | |
| 7 | 0.8, 0.85, 0.9, 0.95, 1.0, 1.1, 1.15 | 13.46 | 11.1 K | |
| Spontaneous Speech | 1 | Baseline | 0.67 | 0.56 K |
| 3 | 0.9, 1.0, 1.1 | 2.03 | 1.7 K | |
| 5 | 0.8, 0.9, 1.0, 1.1, 1.2 | 3.43 | 2.84 K | |
| 7 | 0.8, 0.85, 0.9, 0.95, 1.0, 1.1, 1.15 | 4.95 | 3.98 K | |
| Combined Speech | 1 | Baseline | 2.65 | 2.27 K |
| 3 | 0.9, 1.0, 1.1 | 8 | 6.82 K | |
| 5 | 0.8, 0.9, 1.0, 1.1, 1.2 | 13.53 | 11.37 K | |
| 7 | 0.8, 0.85, 0.9, 0.95, 1.0, 1.1, 1.15 | 19.53 | 15.9 K |
| Type of Speech | Fold | Acoustic Models | Discriminative Models | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Mono | Tri1 | Tri2 | Tri3 | MMI | bMMI | fMMI | fbMMI | ||
| Read Speech | 1 | 2.87 | 2.30 | 2.22 | 2.66 | 2.39 | 2.42 | 2.26 | 2.13 |
| 3 | 2.60 | 2.67 | 2.22 | 2.25 | 2.11 | 2.20 | 2.07 | 2.07 | |
| 5 | 2.93 | 2.35 | 2.07 | 2.33 | 2.28 | 2.26 | 2.06 | 2.05 | |
| 7 | 2.90 | 2.16 | 2.06 | 2.42 | 2.16 | 2.33 | 2.01 | 2.05 | |
| Spontaneous Speech | 1 | 19.51 | 15.82 | 16.17 | 17.25 | 17.25 | 17.35 | 17.14 | 17.09 |
| 3 | 22.73 | 18.67 | 16.09 | 17.09 | 16.98 | 16.98 | 16.72 | 16.56 | |
| 5 | 21.78 | 16.77 | 16.51 | 15.98 | 16.35 | 16.24 | 15.98 | 15.56 | |
| 7 | 21.89 | 16.24 | 15.55 | 15.82 | 16.03 | 16.09 | 15.77 | 15.51 | |
| Combined Speech | 1 | 3.43 | 2.85 | 2.96 | 3.03 | 2.84 | 2.83 | 2.90 | 2.81 |
| 3 | 3.46 | 2.99 | 2.68 | 2.72 | 2.85 | 2.84 | 2.79 | 2.72 | |
| 5 | 3.69 | 2.83 | 2.64 | 2.92 | 2.59 | 2.61 | 2.58 | 2.57 | |
| 7 | 3.72 | 2.85 | 2.90 | 2.79 | 2.61 | 2.73 | 2.57 | 2.48 | |
| Type of Speech | Fold | #Hrs | WER (%) | Rel. Improvement (%) | ||
|---|---|---|---|---|---|---|
| fMMI | fbMMI | fMMI | fbMMI | |||
| Read Speech | 1 | 1.82 | 2.26 | 2.13 | 11.06 | 3.7 |
| 7 | 13.46 | 2.01 | 2.05 | |||
| Spontaneous Speech | 1 | 0.67 | 17.14 | 17.09 | 7.99 | 9.24 |
| 7 | 4.95 | 15.77 | 15.51 | |||
| Combined Speech | 1 | 2.65 | 2.90 | 2.81 | 11.37 | 11.74 |
| 7 | 19.53 | 2.57 | 2.48 | |||
| Year/ Author | Augmentation Type | Dataset Type | Front-End Approach | State-of-the-Art Model | Performance |
|---|---|---|---|---|---|
| 2017 [20] | No augmentation | English read, picture narration, and spontaneous speech (11–15 years) from native Arabic, Chinese, French, German, and many other children speaking English | MFCC | BiLSTM-RNN | WER of 13.4% is obtained |
| 2018 [18] | No augmentation | Italian, German, English, and Swedish children aged 9–10 years | MFCC | DNN | Non-native adaption was used in transfer learning and results in 14.2% WER for Italian and 15% for German speaking English |
| 2020 [21] | Prosody-based augmentation, spectrogram augmentation | TLT non-native corpus— English read speech from native Italian children (9–16 years) | MFCC | TDNN+BiLSTM +VTLN | WER of 18.71% with spectrogram augmentation |
| 2020 [22] | Speed perturbation, spectrogram perturbation | TLT non-native corpus— English read speech from native Italian children (9–16 years) | MFCC+ i vectors, CMVN, VTLN | TDNN-F, CNN-TDNN-F | WER is 17.59% with semi-supervised learning |
| 2020 [23] | Spectrogram augmentation | TLT non-native English, German, and Italian children corpus—spontaneous speech (9–16 years) | MFCC | TDNN-F+LSTM | WER is 15.7% by combining all systems independent of grade |
| 2020 [24] | Speed perturbation, room impulse response (RIR), babble noise, non-speech noise | OGI, MyST, CU, CMU (5–16 years) read and spontaneous speech | MFCC | GMM-HMM CNN+TDNN-F | WER is 16.59 with min. Bayes-risk decoding |
| 2020 [25] | Pitch, speed, volume, tempo, reverberation perturbations | SLT Mandarin children read and conversational speech (4–16 years) | MFCC | CNN-TDNN-F, EspNet | CER is 16.48% by combining all types of perturbations |
| 2021 [47] | Data augmentation, time-scale modification | Clean adult’s speech WSJCAM0 (train data) Noisy children’s speech PF-STAR (test data) | MFCC | DNN-HMM | WER is 14.88% by all types of data augmentation in combined system |
| Proposed work | Speed perturbation- 3Way, 5Way, and 7Way | 7–12 years of English read and spontaneous speech from native Indian (Telugu) children | MFCC CMVN | GMM-HMM MMI, bMMI, fMMI, fbMMI | WER for different styles of speech 2.01% (read), 15.51% (spontaneous), 2.48% (combined) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Radha, K.; Bansal, M. Audio Augmentation for Non-Native Children’s Speech Recognition through Discriminative Learning. Entropy 2022, 24, 1490. https://doi.org/10.3390/e24101490
Radha K, Bansal M. Audio Augmentation for Non-Native Children’s Speech Recognition through Discriminative Learning. Entropy. 2022; 24(10):1490. https://doi.org/10.3390/e24101490
Chicago/Turabian StyleRadha, Kodali, and Mohan Bansal. 2022. "Audio Augmentation for Non-Native Children’s Speech Recognition through Discriminative Learning" Entropy 24, no. 10: 1490. https://doi.org/10.3390/e24101490