
Decoupled Early Time Series Classification Using Varied-Length Feature Augmentation and Gradient Projection Technique

Abstract
:1. Introduction
- We propose an end-to-end framework to decouple the ETSC task into VTSC and early exiting, named DETSCNet;
- To enhance the adaptive capabilities of the classification model to the data length variation, a feature augmentation module based on random length truncation and a multi-task loss function specially designed for VTSC are proposed;
- To handle the conflict between the classification and early exiting, a gradient projection technique is designed;
- The proposed method achieves superior performance on 12 public datasets.
2. Related Work
3. Methods
3.1. Overview
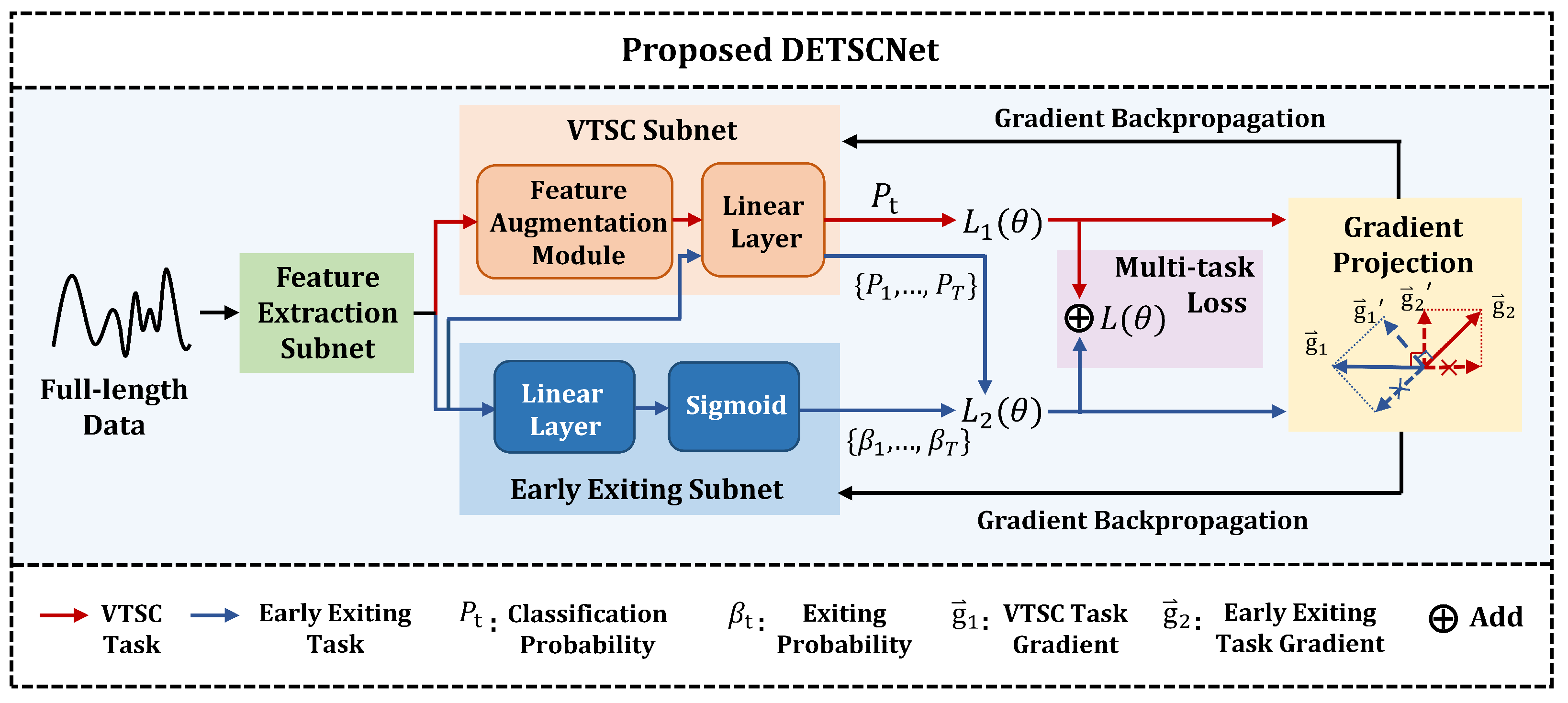
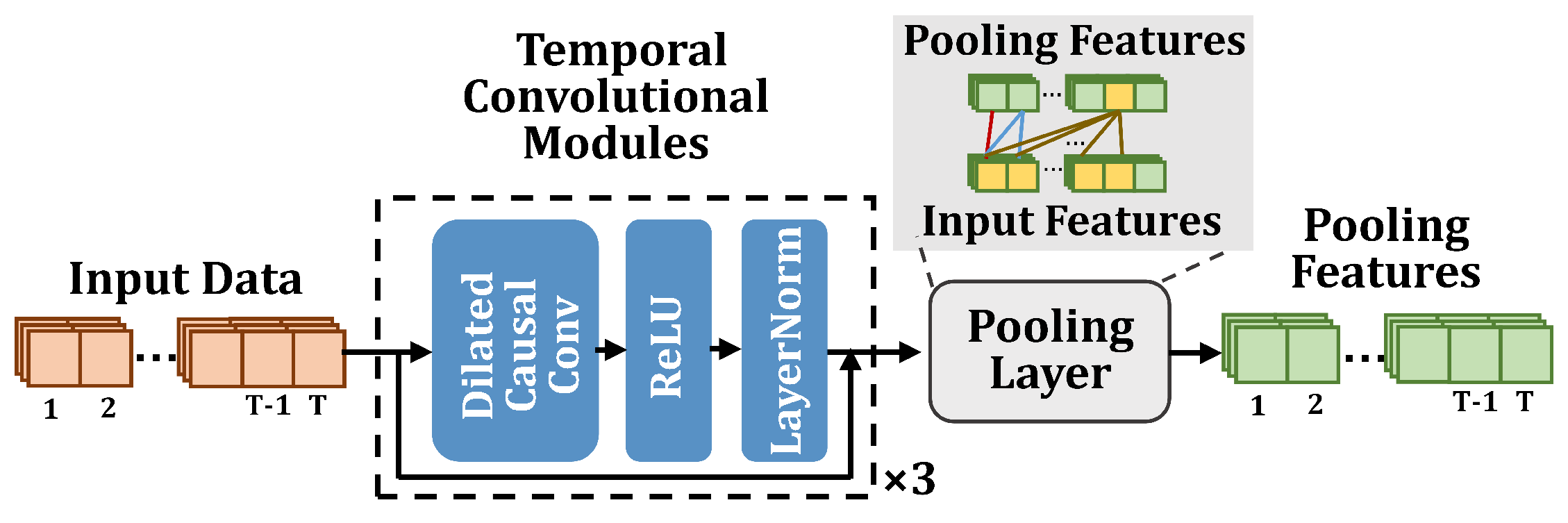
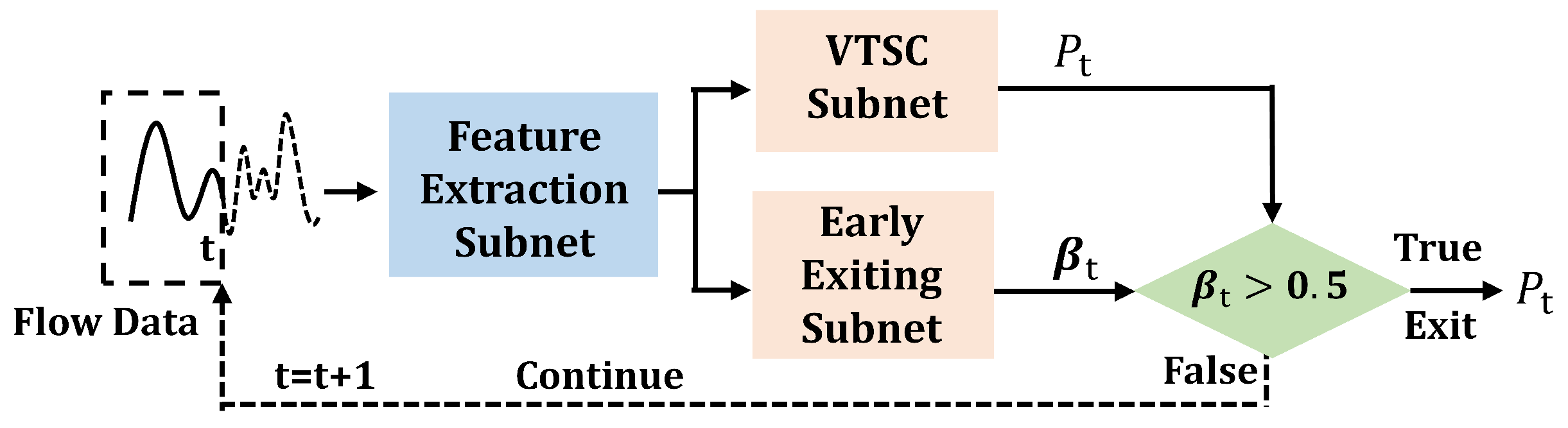
3.2. The Architecture of DETSCNet
3.3. Varied-Length Time Series Classification
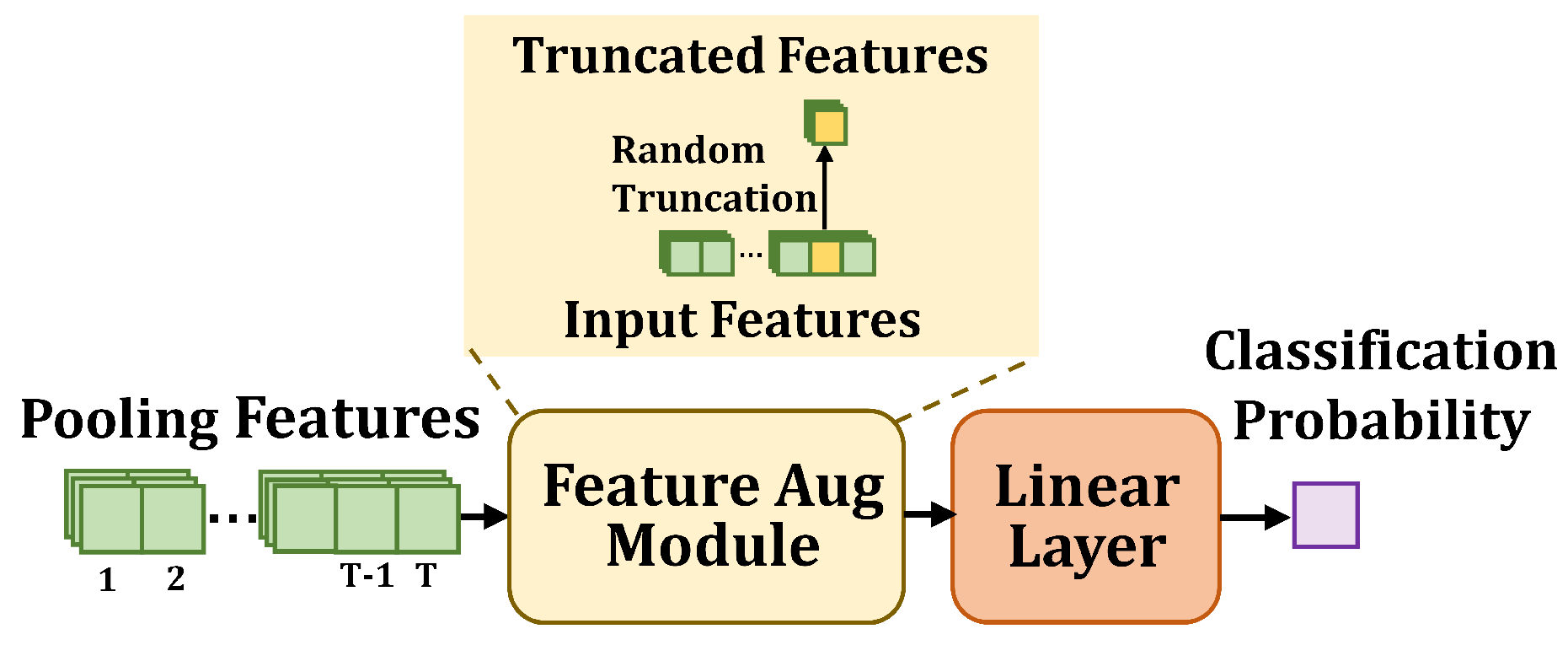
3.3.1. The Varied-Length Feature Augmentation Module
3.3.2. The Multi-Task Loss Function
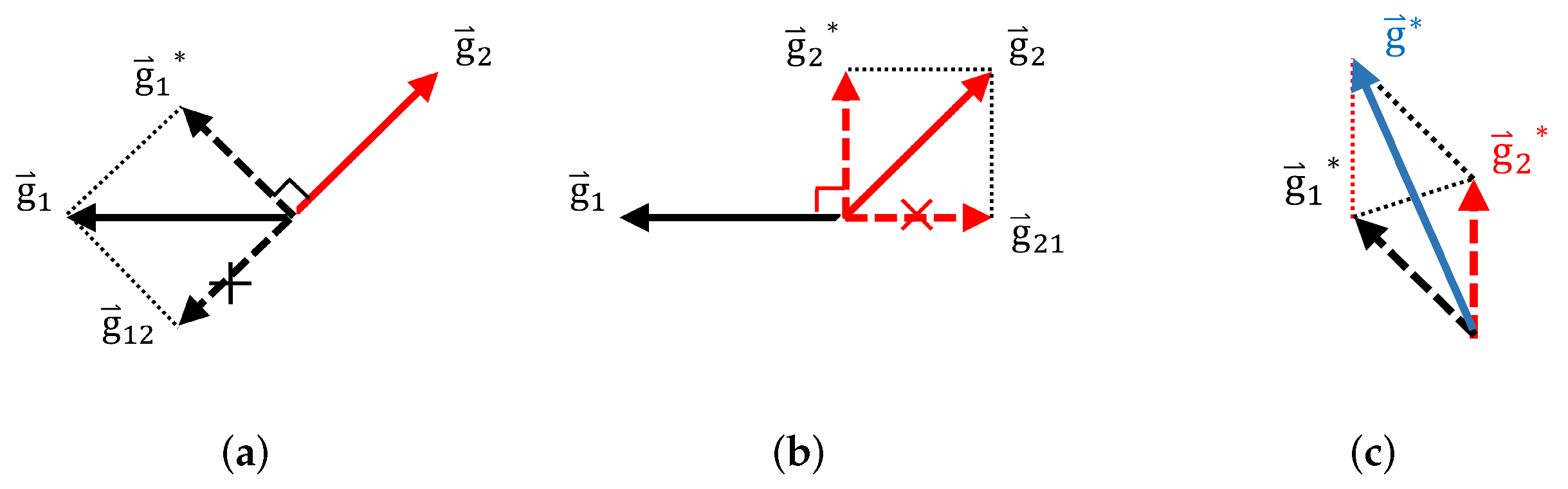
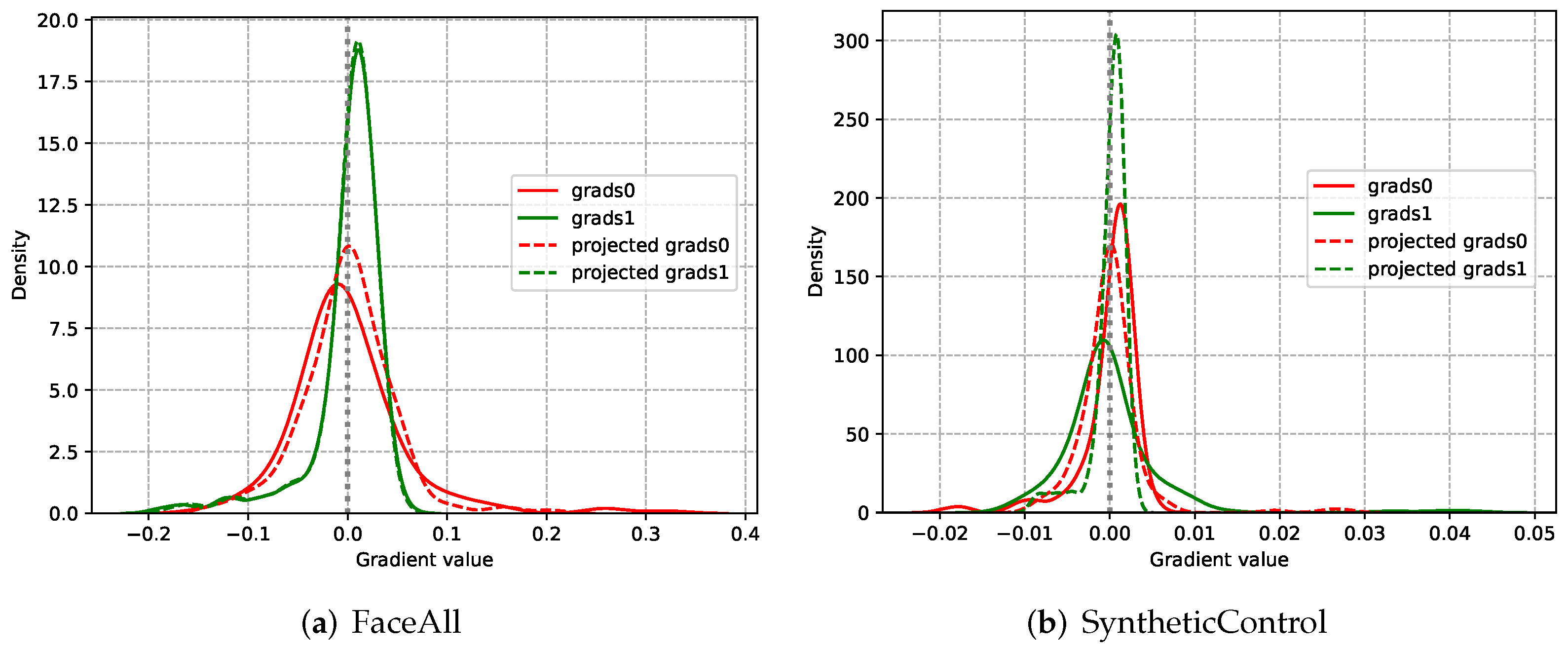
3.4. Gradient Projection Technique
4. Experiments
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Training Procedures
4.1.3. Test Procedures
4.1.4. Evaluation Rule
4.2. Comparisons of Different Methods
4.3. Ablation Study
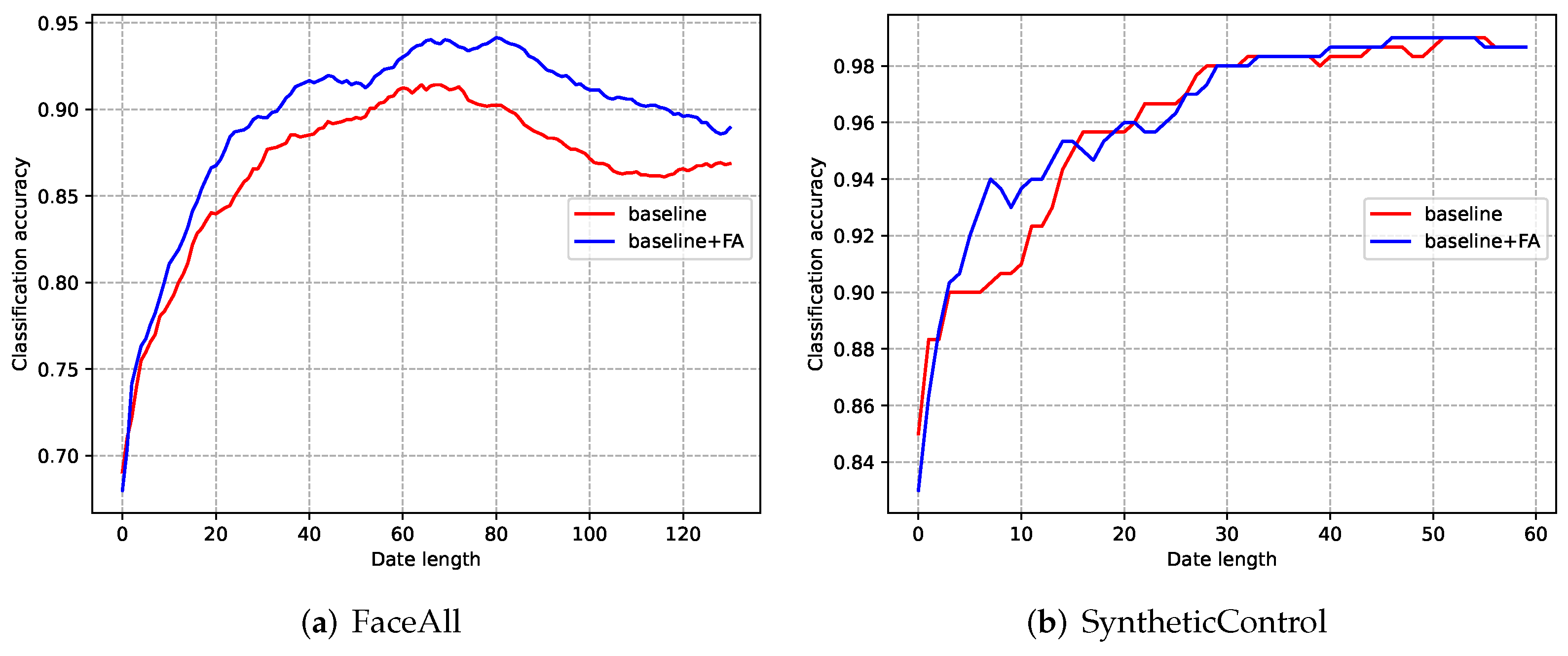
4.3.1. Ablation Experiments of the VTSC Subnet
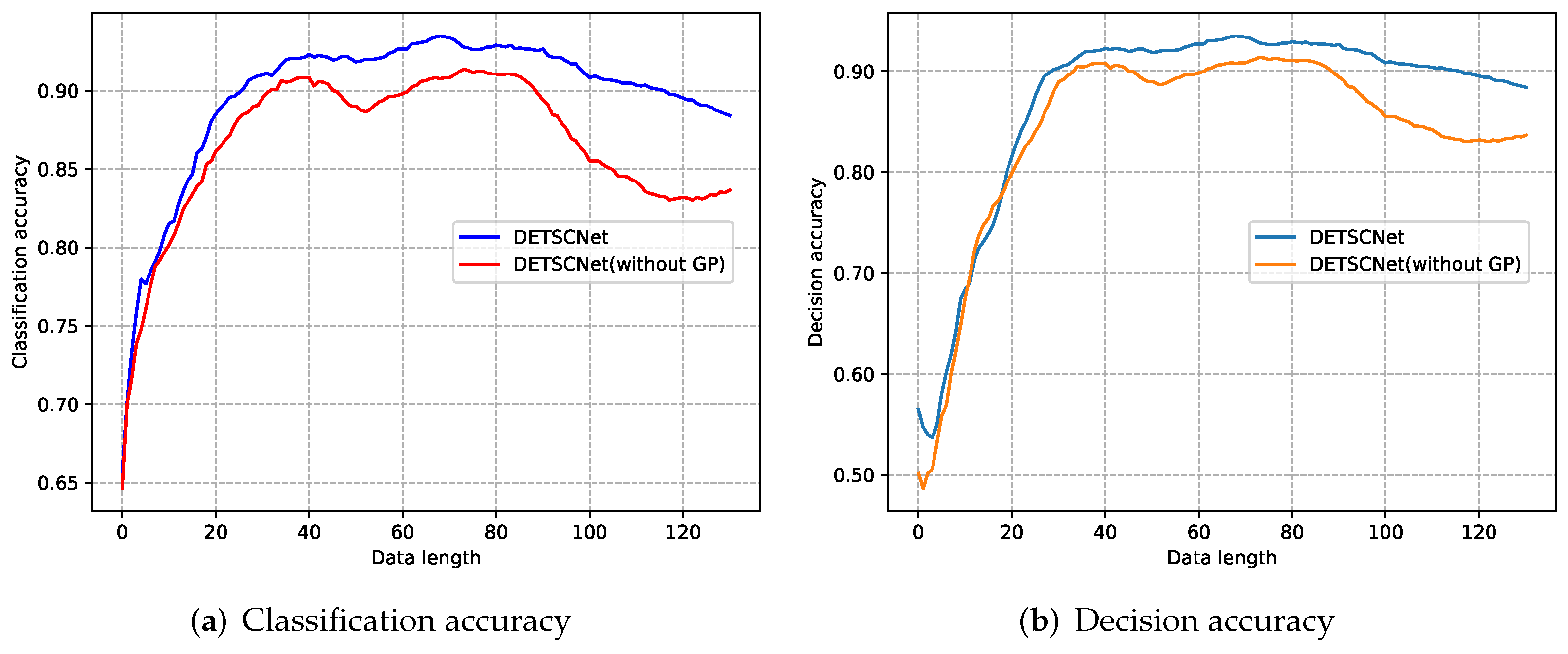
4.3.2. Ablation Experiments of Gradient Projection Technique
5. Discussion
5.1. Varied-Length Time Series Classification
5.2. The Conflict between Varied-Length Time Series Classification Task and Early Exiting Task
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Faouzi, J. Time Series Classification: A review of Algorithms and Implementations. Mach. Learn. (Emerg. Trends Appl.) 2022, in press. [Google Scholar]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Nivetha, G.; Venkatalakshmi, K. Hybrid outlier detection (HOD) method in sensor data for human activity classification. Intell. Data Anal. 2018, 22, 245–260. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, L.; Chen, H.; Tian, A.; Zhou, S.; Guo, Y. IF-ConvTransformer: A Framework for Human Activity Recognition Using IMU Fusion and ConvTransformer. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, New York, NY, USA, 7 July 2022; Volume 6, pp. 1–26. [Google Scholar]
- Sarkar, S.; Roy, A.; Kumar, S.; Das, B. Seismic Intensity Estimation Using Multilayer Perceptron for Onsite Earthquake Early Warning. IEEE Sens. J. 2021, 22, 2553–2563. [Google Scholar] [CrossRef]
- Sonkar, S.K.; Kumar, P.; George, R.C.; Philip, D.; Ghosh, A.K. Detection and Estimation of Natural Gas Leakage Using UAV by Machine Learning Algorithms. IEEE Sens. J. 2022, 22, 8041–8049. [Google Scholar] [CrossRef]
- Nath, A.G.; Sharma, A.; Udmale, S.S.; Singh, S.K. An early classification approach for improving structural rotor fault diagnosis. IEEE Trans. Instrum. Meas. 2020, 70, 3507513. [Google Scholar] [CrossRef]
- Ahn, G.; Lee, H.; Park, J.; Hur, S. Development of indicator of data sufficiency for feature-based early time series classification with applications of bearing fault diagnosis. Processes 2020, 8, 790. [Google Scholar] [CrossRef]
- Ahmad, T.; Truscan, D.; Vain, J.; Porres, I. Early Detection of Network Attacks Using Deep Learning. In Proceedings of the 2022 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), Valencia, Spain, 4–13 April 2022; pp. 30–39. [Google Scholar]
- Lemus, M.; Beirão, J.P.; Paunković, N.; Carvalho, A.M.; Mateus, P. Information-Theoretical Criteria for Characterizing the Earliness of Time-Series Data. Entropy 2019, 22, 49. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sultana, A.; Deb, K.; Dhar, P.K.; Koshiba, T. Classification of indoor human fall events using deep learning. Entropy 2021, 23, 328. [Google Scholar] [CrossRef] [PubMed]
- Achenchabe, Y.; Bondu, A.; Cornuéjols, A.; Lemaire, V. Early Classification of Time Series is Meaningful. arXiv 2021, arXiv:2104.13257. [Google Scholar]
- Kladis, E.; Akasiadis, C.; Michelioudakis, E.; Alevizos, E.; Artikis, A. An Empirical Evaluation of Early Time-Series Classification Algorithms. In Proceedings of the EDBT/ICDT Workshops, Nicosia, Cyprus, 23 March 2021. [Google Scholar]
- Xing, Z.; Pei, J.; Dong, G.; Yu, P.S. Mining sequence classifiers for early prediction. In Proceedings of the 2008 SIAM International Conference on Data Mining, Atlanta, GA, USA, 24–26 April 2008; pp. 644–655. [Google Scholar]
- Gupta, A.; Gupta, H.P.; Biswas, B.; Dutta, T. Approaches and applications of early classification of time series: A review. IEEE Trans. Artif. Intell. 2020, 1, 47–61. [Google Scholar] [CrossRef]
- Gupta, A.; Pal, R.; Mishra, R.; Gupta, H.P.; Dutta, T.; Hirani, P. Game theory based early classification of rivers using time series data. In Proceedings of the 2019 IEEE 5th World Forum on Internet of Things (WF-IoT), Limerick, Ireland, 15–18 April 2019; pp. 686–691. [Google Scholar]
- Sharma, A.; Singh, S.K.; Udmale, S.S.; Singh, A.K.; Singh, R. Early Transportation Mode Detection Using Smartphone Sensing Data. IEEE Sens. J. 2021, 21, 15651–15659. [Google Scholar] [CrossRef]
- Shekhar, S.; Eswaran, D.; Hooi, B.; Elmer, J.; Faloutsos, C.; Akoglu, L. Benefit-aware Early Prediction of Health Outcomes on Multivariate EEG Time Series. arXiv 2021, arXiv:2111.06032. [Google Scholar]
- Huang, H.S.; Liu, C.L.; Tseng, V.S. Multivariate time series early classification using multi-domain deep neural network. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 90–98. [Google Scholar]
- Rußwurm, M.; Tavenard, R.; Lefèvre, S.; Körner, M. Early classification for agricultural monitoring from satellite time series. arXiv 2019, arXiv:1908.10283. [Google Scholar]
- Rußwurm, M.; Lefèvre, S.; Courty, N.; Emonet, R.; Körner, M.; Tavenard, R. End-to-end learning for early classification of time series. arXiv 2019, arXiv:1901.10681. [Google Scholar]
- Huang, Z.; Ye, Z.; Li, S.; Pan, R. Length adaptive recurrent model for text classification. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1019–1027. [Google Scholar]
- Mori, U.; Mendiburu, A.; Keogh, E.; Lozano, J.A. Reliable early classification of time series based on discriminating the classes over time. Data Min. Knowl. Discov. 2017, 31, 233–263. [Google Scholar] [CrossRef]
- Gupta, A.; Gupta, H.P.; Biswas, B.; Dutta, T. An early classification approach for multivariate time series of on-vehicle sensors in transportation. IEEE Trans. Intell. Transp. Syst. 2020, 21, 5316–5327. [Google Scholar] [CrossRef]
- Gupta, A.; Gupta, H.P.; Biswas, B.; Dutta, T. A divide-and-conquer–based early classification approach for multivariate time series with different sampling rate components in iot. ACM Trans. Internet Things 2020, 1, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Gupta, A.; Gupta, H.P.; Dutta, T. Towards Identifying Internet Applications Using Early Classification of Traffic Flow. In Proceedings of the 2021 IFIP Networking Conference (IFIP Networking), Virtual, 21–24 June 2021; pp. 1–9. [Google Scholar]
- Yan, W.; Li, G.; Wu, Z.; Wang, S.; Yu, P.S. Extracting diverse-shapelets for early classification on time series. World Wide Web 2020, 23, 3055–3081. [Google Scholar] [CrossRef]
- He, G.; Zhao, W.; Xia, X. Confidence-based early classification of multivariate time series with multiple interpretable rules. Pattern Anal. Appl. 2020, 23, 567–580. [Google Scholar] [CrossRef]
- Zhang, W.; Wan, Y. Early classification of time series based on trend segmentation and optimization cost function. Appl. Intell. 2022, 52, 6782–6793. [Google Scholar] [CrossRef]
- Yao, L.; Li, Y.; Li, Y.; Zhang, H.; Huai, M.; Gao, J.; Zhang, A. Dtec: Distance transformation based early time series classification. In Proceedings of the 2019 SIAM International Conference on Data Mining, Calgary, AB, Canada, 2–4 May 2019; pp. 486–494. [Google Scholar]
- Mori, U.; Mendiburu, A.; Miranda, I.M.; Lozano, J.A. Early classification of time series using multi-objective optimization techniques. Inf. Sci. 2019, 492, 204–218. [Google Scholar] [CrossRef] [Green Version]
- Sharma, A.; Singh, S.K. Early classification of time series based on uncertainty measure. In Proceedings of the 2019 IEEE Conference on Information and Communication Technology, Kuala Lumpur, Malaysia, 24–26 July 2019; pp. 1–6. [Google Scholar]
- Dachraoui, A.; Bondu, A.; Cornuéjols, A. Early classification of time series as a non myopic sequential decision making problem. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Porto, Portugal, 7–11 September 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 433–447. [Google Scholar]
- Achenchabe, Y.; Bondu, A.; Cornuéjols, A.; Dachraoui, A. Early classification of time series. cost-based optimization criterion and algorithms. arXiv 2020, arXiv:2005.09945. [Google Scholar]
- Mori, U.; Mendiburu, A.; Dasgupta, S.; Lozano, J.A. Early classification of time series by simultaneously optimizing the accuracy and earliness. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 4569–4578. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sharma, A.; Singh, S.K. Early classification of multivariate data by learning optimal decision rules. Multimed. Tools Appl. 2021, 80, 35081–35104. [Google Scholar] [CrossRef]
- Zhang, Y.; Hou, Y.; OuYang, K.; Zhou, S. Multi-scale signed recurrence plot based time series classification using inception architectural networks. Pattern Recognit. 2022, 123, 108385. [Google Scholar] [CrossRef]
- Geng, Y.; Luo, X. Cost-sensitive convolutional neural networks for imbalanced time series classification. Intell. Data Anal. 2019, 23, 357–370. [Google Scholar] [CrossRef]
- Hsu, E.Y.; Liu, C.L.; Tseng, V.S. Multivariate time series early classification with interpretability using deep learning and attention mechanism. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Macau, China, 14–17 April 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 541–553. [Google Scholar]
- Gandhimathinathan, A.; Lavanya, R. Early Fault Detection in Safety Critical Systems Using Complex Morlet Wavelet and Deep Learning. In Inventive Communication and Computational Technologies; Springer: Berlin/Heidelberg, Germany, 2022; pp. 515–531. [Google Scholar]
- Min, R.; Wang, X.; Zou, J.; Gao, J.; Wang, L.; Cao, Z. Early Gesture Recognition With Reliable Accuracy Based on High-Resolution IoT Radar Sensors. IEEE Internet Things J. 2021, 8, 15396–15406. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Dau, H.A.; Bagnall, A.; Kamgar, K.; Yeh, C.C.M.; Zhu, Y.; Gharghabi, S.; Ratanamahatana, C.A.; Keogh, E. The UCR time series archive. IEEE/CAA J. Autom. Sin. 2019, 6, 1293–1305. [Google Scholar] [CrossRef]
- Schäfer, P.; Leser, U. TEASER: Early and accurate time series classification. Data Min. Knowl. Discov. 2020, 34, 1336–1362. [Google Scholar] [CrossRef]
- Frank, A. UCI Machine Learning Repository. 2010. Available online: http://archive.ics.uci.edu/ml (accessed on 1 July 2021).
- Gupta, A.; Gupta, H.P.; Biswas, B.; Dutta, T. A fault-tolerant early classification approach for human activities using multivariate time series. IEEE Trans. Mob. Comput. 2020, 20, 1747–1760. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Lv, J.; Hu, X.; Li, L.; Li, P. An Effective Confidence-Based Early Classification of Time Series. IEEE Access 2019, 7, 96113–96124. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Dilation Factor | Kernel Size | Number of Features |
|---|---|---|---|
| Temporal convolutional module1 | 1 | 3 | 64 |
| Temporal convolutional module2 | 2 | 3 | 64 |
| Temporal convolutional module3 | 4 | 3 | 64 |
| Pooling layer | ∖ | ∖ | ∖ |
| Linear layer of VTSC subnet | ∖ | ∖ | ∖ |
| Linear layer exiting subnet | ∖ | ∖ | ∖ |
| Dataset | SR2-CF2 | ECLN | ETMD | EPTS | DETSCNet |
|---|---|---|---|---|---|
| ChlorineCon | 71.13 | 69.59 | 69.35 | 48.56 | 68.12 |
| CricketX | 64.35 | 56.57 | 26.02 | 52.04 | 64.49 |
| FaceAll | 80.01 | 16.84 | 7.65 | 86.13 | 87.94 |
| MedicalImages | 81.33 | 52.08 | 4.86 | 51.25 | 80.27 |
| NonInvThorax2 | 87.52 | 80.31 | 0.15 | 73.94 | 89.47 |
| StarLightCurves | 91.51 | 29.57 | 81.17 | 80.28 | 92.86 |
| SyntheticControl | 84.62 | 22.83 | 29.59 | 91.29 | 93.88 |
| TwoPatterns | 17.00 | 17.42 | 42.84 | 57.66 | 61.85 |
| UWaveZ | 59.96 | 41.03 | 27.87 | 61.24 | 62.99 |
| Wafer | 95.76 | 86.01 | 94.00 | 94.87 | 98.78 |
| HHAR | 81.91 | 53.27 | 73.12 | 94.40 | 96.63 |
| DSA | 81.28 | 24.47 | 53.93 | 95.78 | 99.29 |
| Datasets | Baseline | Baseline + FA |
|---|---|---|
| ChlorineCon | 41.93 | 65.44 |
| CricketX | 30.3 | 62.77 |
| FaceAll | 82.92 | 87.2 |
| MedicalImages | 81.37 | 80.14 |
| NonInvThorax2 | 89.2 | 89.22 |
| StarLightCurves | 88.26 | 88.68 |
| SyntheticControl | 90.99 | 92.84 |
| TwoPatterns | 57.61 | 61.27 |
| UWaveZ | 46.17 | 54.91 |
| Wafer | 99.18 | 98.07 |
| HHAR | 95.36 | 95.76 |
| DSA | 98.85 | 99.1 |
| Datasets | DETSCNet (without GP) | DETSCNet |
|---|---|---|
| ChlorineCon | 65.44 | 68.12 |
| CricketX | 62.77 | 64.49 |
| FaceAll | 87.2 | 87.94 |
| MedicalImages | 80.14 | 80.27 |
| NonInvThorax2 | 89.22 | 89.47 |
| StarLightCurves | 88.68 | 92.86 |
| SyntheticControl | 92.84 | 93.88 |
| TwoPatterns | 61.27 | 61.85 |
| UWaveZ | 54.91 | 62.99 |
| Wafer | 98.07 | 98.78 |
| HHAR | 95.76 | 96.63 |
| DSA | 99.1 | 99.29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Zhang, Y.; Tian, A.; Hou, Y.; Ma, C.; Zhou, S. Decoupled Early Time Series Classification Using Varied-Length Feature Augmentation and Gradient Projection Technique. Entropy 2022, 24, 1477. https://doi.org/10.3390/e24101477
Chen H, Zhang Y, Tian A, Hou Y, Ma C, Zhou S. Decoupled Early Time Series Classification Using Varied-Length Feature Augmentation and Gradient Projection Technique. Entropy. 2022; 24(10):1477. https://doi.org/10.3390/e24101477
Chicago/Turabian StyleChen, Huiling, Ye Zhang, Aosheng Tian, Yi Hou, Chao Ma, and Shilin Zhou. 2022. "Decoupled Early Time Series Classification Using Varied-Length Feature Augmentation and Gradient Projection Technique" Entropy 24, no. 10: 1477. https://doi.org/10.3390/e24101477