
Log Sequence Anomaly Detection Method Based on Contrastive Adversarial Training and Dual Feature Extraction

Abstract
:1. Introduction
- (1)
- Most log sequence anomaly detection methods do not fully consider the robustness issues caused by the update of the log message template, and lack specialized training on the robustness of log sequence anomaly detection.
- (2)
- Most log sequence anomaly detection methods have not conducted more in-depth research and attention on the semantic features generated by normal and abnormal log sequences, that is, the distance relationship between the semantic features of normal and abnormal log sequences in the semantic space is not used to improve the accuracy of anomaly detection.
- (3)
- Most log sequence anomaly detection methods only use the semantic features of the log sequence to perform anomaly detection, and do not combine the information in the statistical characteristics of the log sequence to improve the accuracy of anomaly detection.
- (1)
- This paper uses the FGM (Fast Gradient Method) [21] algorithm to perturb the embedding layer of the BERT [22] model to generate the perturbed semantic features, and then narrow the distance between the semantic features generated by the log sequence before and after the embedding layer is perturbed, so that the model can still obtain the correct anomaly detection results even when the original log sequence has some slight changes. This kind of special training for robustness can make the anomaly detection model obtain good robustness.
- (2)
- Contrastive learning [23] is used to reduce the similarity between the semantic features of normal and abnormal log sequences, so that the semantic features generated by normal and abnormal log sequences are farther in the semantic space, and the difference is greater, thereby improving the accuracy of anomaly detection.
- (3)
- This paper counts the times that each word of the log sequence appears in the normal and abnormal label and uses a VAE [24] to extract the statistical results to obtain statistical features [25]. The statistical features and semantic features of the log sequence are then combined to obtain semantic features enhanced by the statistics features to train the model, and the enhanced semantic features will contain more information, thereby improving the accuracy of model anomaly detection.
2. Related Research
3. Method Overview
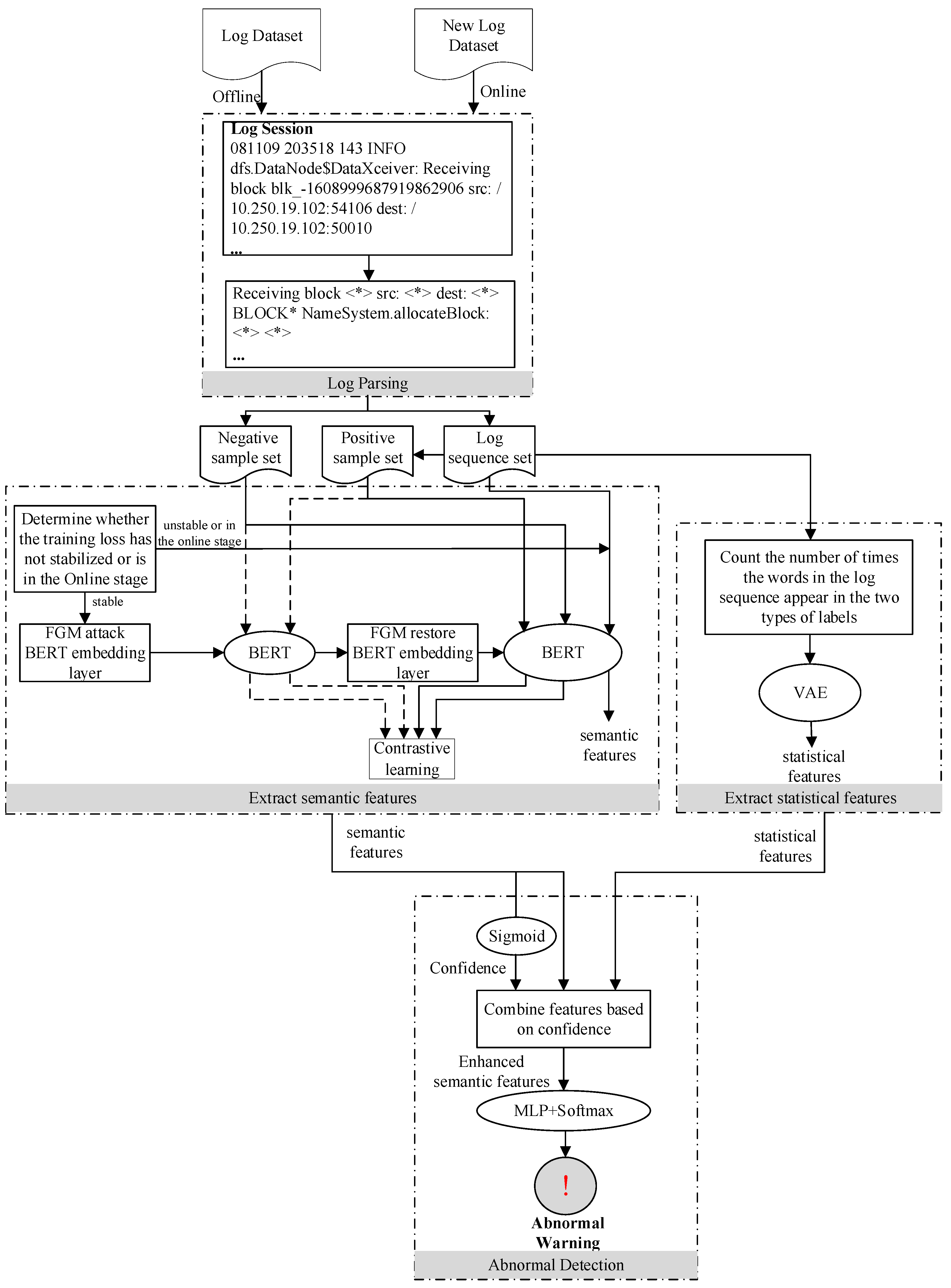
3.1. Method Flow
- (1)
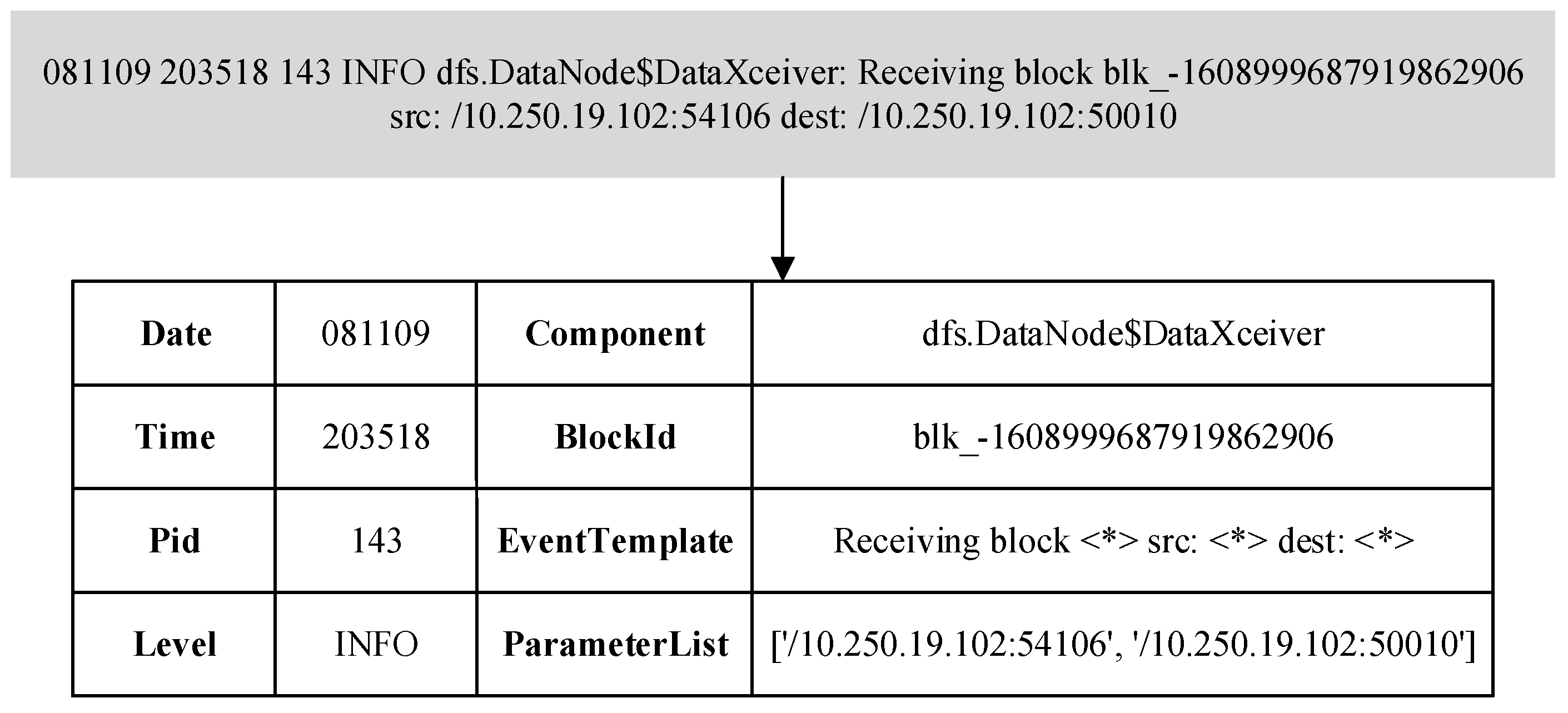
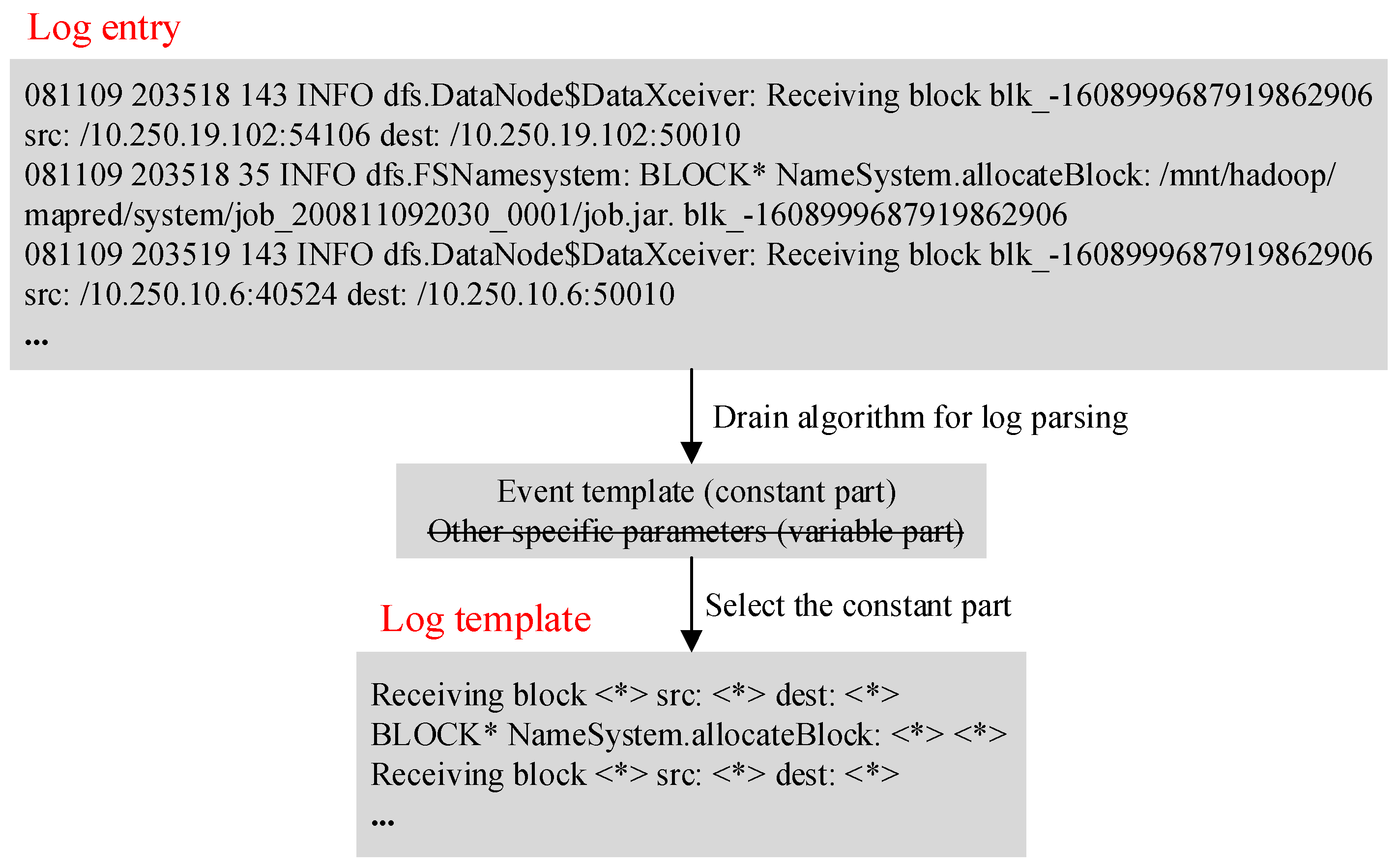
- First, the Drain algorithm [26] is used in the log parsing stage to convert unstructured log entries into structured log templates.
- (2)
- Then, the log sequence is obtained according to the session ID or sliding window, and a set of negative sample log sequences is extracted.
- (3)
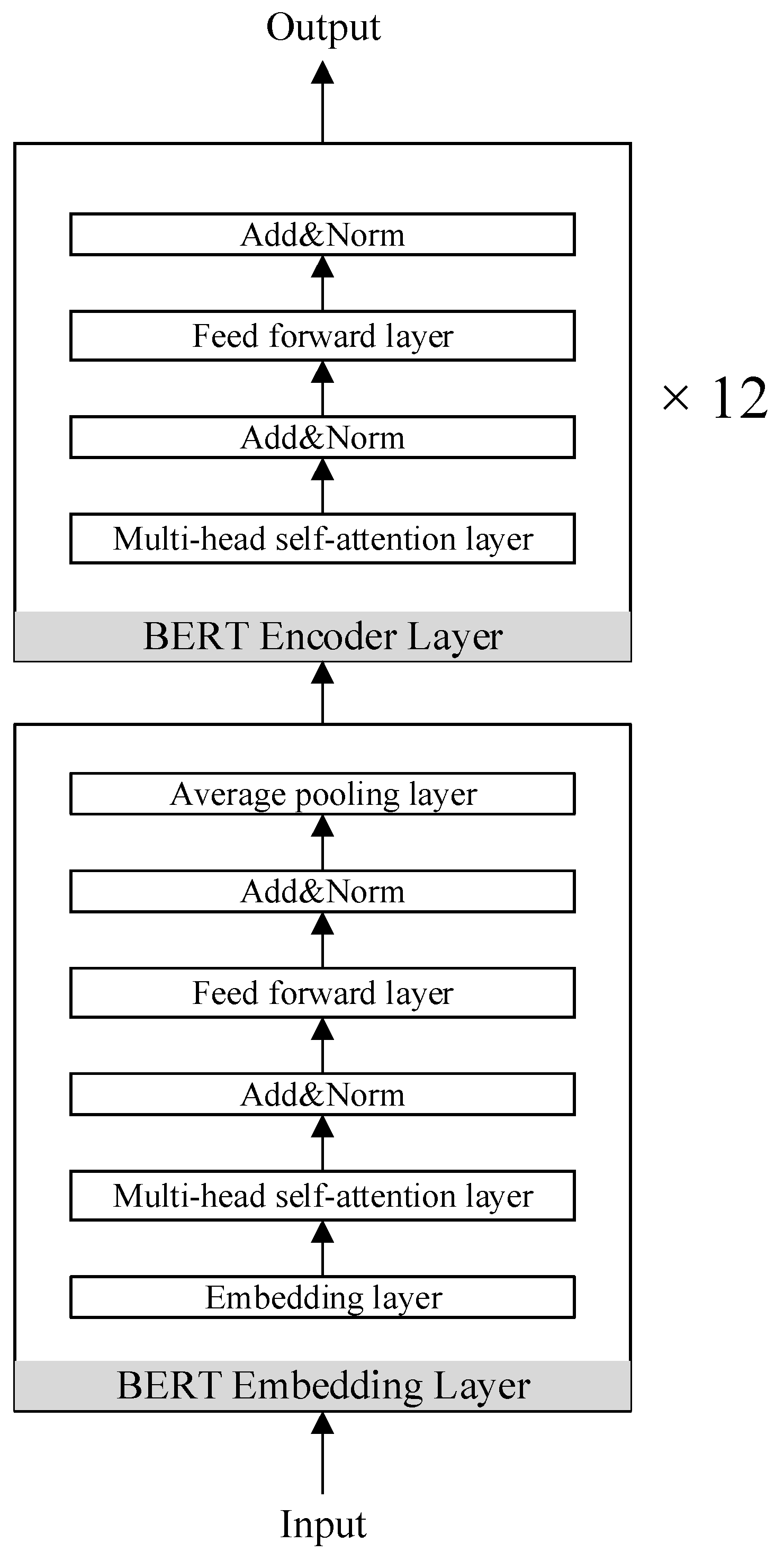
- Next, in the feature extraction stage, BERT is used to semantically encode the acquired log sequence to obtain semantic features. The number of times each word in the log sequence appears in the normal and abnormal label is counted and entered into the VAE, outputting the hidden variables to obtain statistical features.
- (4)
- The log sequences in the training set and the corresponding labels are used to supervise the training of the anomaly detection model.
- (5)
- When the training loss of the model tends to stabilize, while maintaining the original supervised training task, contrastive adversarial training is used to continue training the model. That is, the FGM algorithm is used to perturb the BERT embedding layer to generate perturbed semantic features. Contrast learning is then used to increase the similarity between the semantic features generated by the normal log sequence when the embedding layer of BERT is not perturbed and perturbed, and the similarity between the semantic features of normal and abnormal log sequences is reduced.
- (1)
- First, the Drain algorithm is used in the log parsing stage to convert unstructured log entries into structured log templates.
- (2)
- Then, the log sequence is obtained according to the session ID or sliding window.
- (3)
- Next, in the feature extraction stage, BERT is used to semantically encode the acquired log sequence to obtain semantic features. The number of times each word in the log sequence appears in the normal and abnormal label is counted and entered into the VAE, and the hidden variables outputted to obtain statistical features.
- (4)
- The semantic feature is input into the Sigmoid activation function to obtain the confidence, and the statistical feature and the semantic feature are combined according to the confidence to obtain the semantic feature enhanced by the statistical feature.
- (5)
- The enhanced semantic features are input into the trained anomaly detection model and the log sequence is judged on whether it has anomalies according to the output of the model.
3.2. Log Analysis
3.3. Feature Extraction
3.3.1. Semantic Features
3.3.2. Statistical Features
3.4. Anomaly Detection Model Based on Contrastive Adversarial Training
| Algorithm 1: Algorithm for contrastive adversarial training |
| input: Log sequence training set ; |
| Negative sample log sequence . |
| output: Trained anomaly detection model. |
| 1 repeat |
| 2 for all do |
| 3 Update parameter with as the loss function |
| 4 end |
| 5 until Training loss has stabilized; |
| 6 repeat |
| 7 for alldo |
| 8 Select all normal log sequences from the current batch to form a positive sample log sequence set |
| 9 Use the FGM algorithm to add a perturbation of to the embedding layer of BERT |
| 10 Input the set of positive and negative sample log sequences into the BERT that the embedding layer is perturbed to obtain the perturbed semantic vector of the positive and negative sample log sequence and |
| 11 Cancel the disturbance to the BERT embedding layer and input the positive and negative sample log sequences into the BERT again to obtain the semantic vector of the positive and negative sample log sequence and |
| 12 Update parameter with formula (6) as the optimization function |
| 13 end |
| 14 until Model converges; |
| 15 return Model with well-trained parameters |
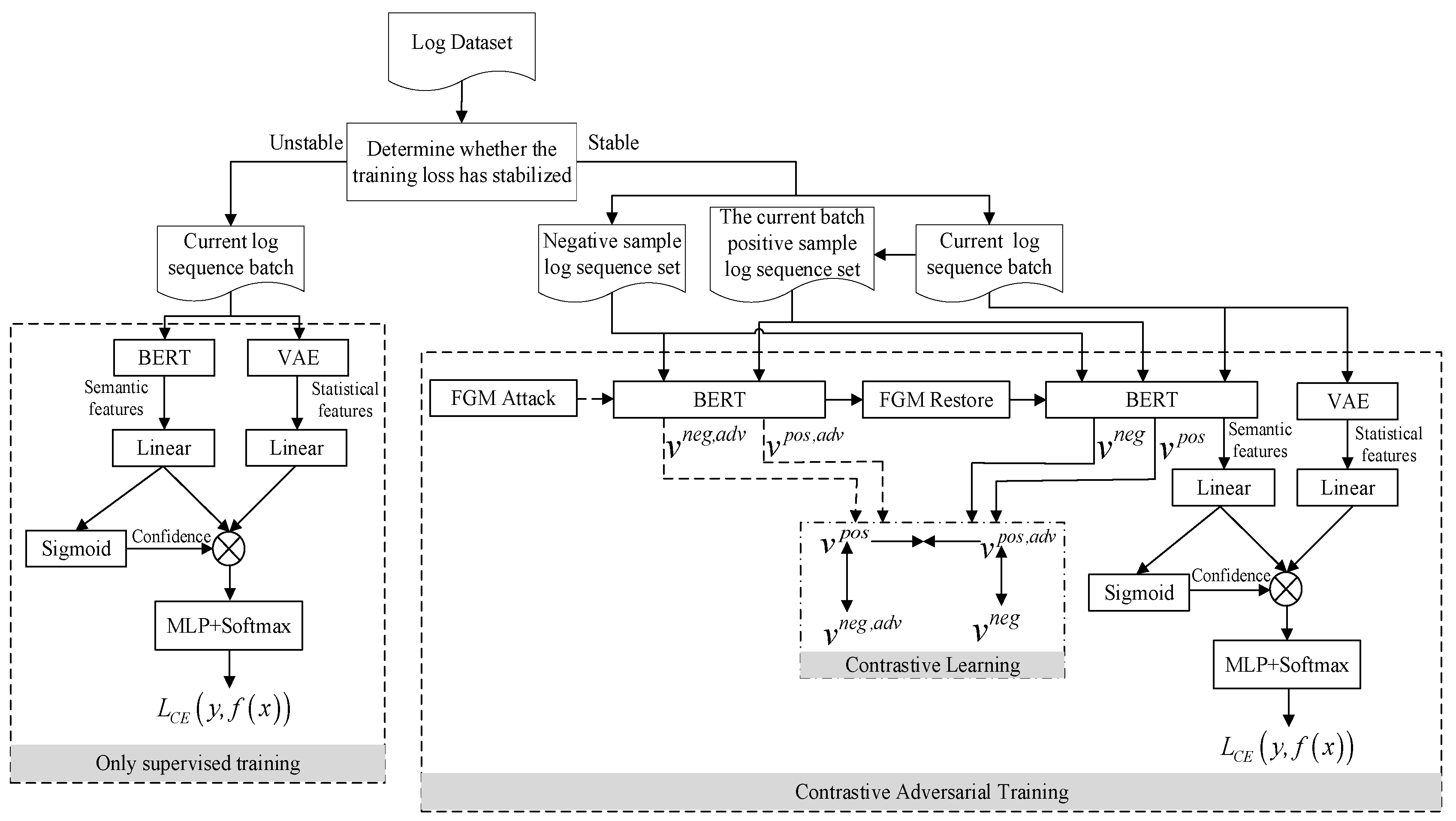
- (1)
- The log sequence and the corresponding label in the training set is used to supervise the training of the anomaly detection model.
- (2)
- When the loss generated during training stabilizes, the FGM algorithm is used to perturb the embedding layer of the BERT model.
- (3)
- A negative sample set is constructed by randomly selecting abnormal log sequences from the training set.
- (4)
- The log sequence in the training set and the corresponding label and negative sample set are input into the model.
- (5)
- All normal log sequences in the log sequence of the current batch are selected input to the model to form a positive sample set.
- (6)
- The positive and negative sample set are input into the perturbed BERT model of the embedding layer to obtain the semantic features of the normal and abnormal log sequences after the perturbation, and then cancel the perturbation to the embedding layer.
- (7)
- The positive and negative sample set and the log sequence of the training set are input to the undisturbed BERT model of the embedding layer to obtain the semantic features of the normal and abnormal log sequences and the log sequence of the training set.
- (8)
- While contrastive learning is used to increase the similarity between the semantic features generated by the normal log sequence when the embedding layer of BERT is disturbed and undisturbed, as well as to reduce the semantic features between all normal log sequences and the set of negative sample log sequences, the original supervised training task is continued to train the model. Steps 4 to 8 are repeated until the loss of contrast adversarial training stabilizes.
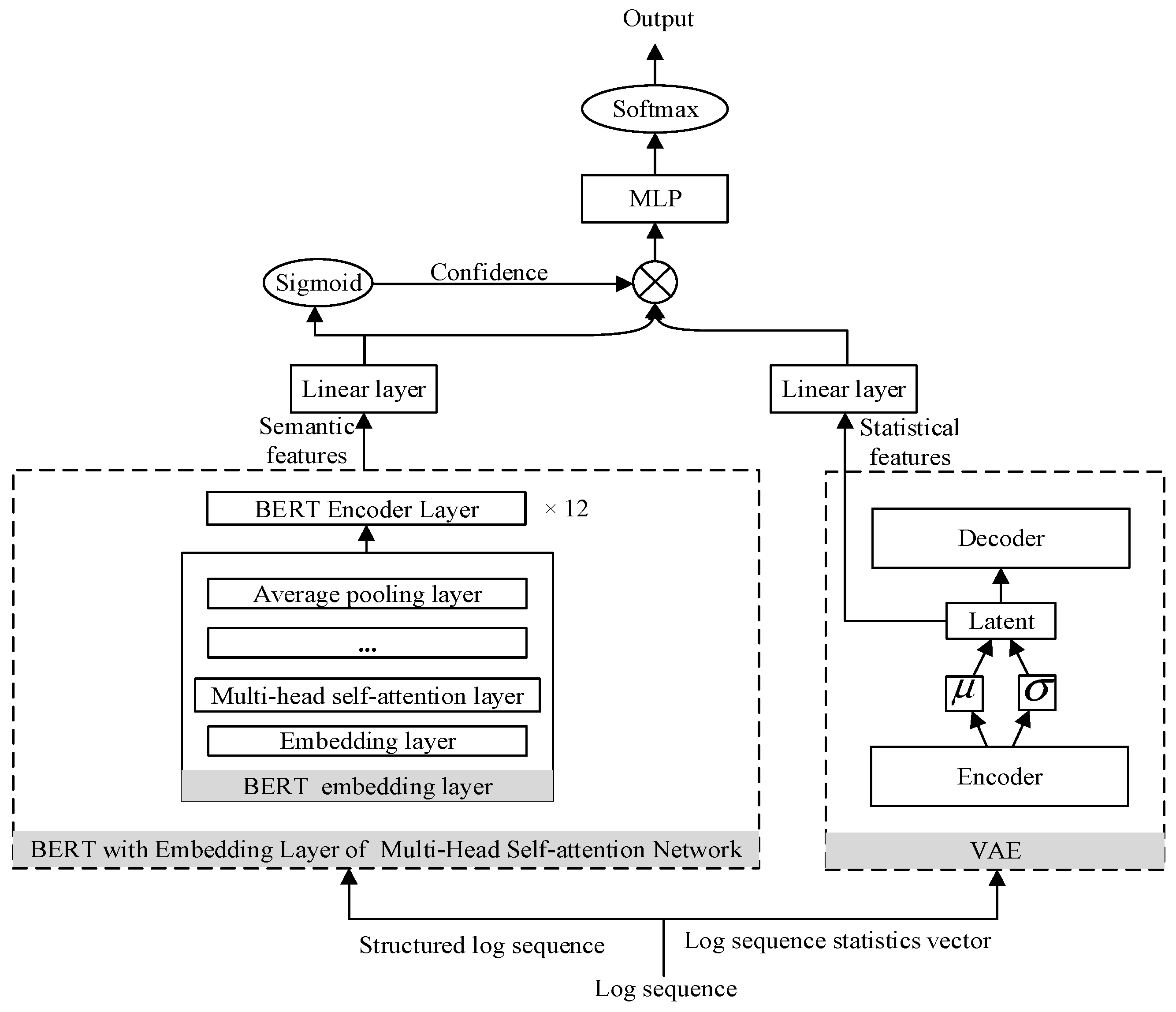
- (1)
- The log sequence is input to be detected into the trained anomaly detection model.
- (2)
- The fine-tuned BERT model is used to convert the log sequence to be detected after log parsing into semantic features.
- (3)
- The trained VAE model is used to convert the log sequence statistical vector to be detected into statistical features.
- (4)
- The semantic features and statistical features are input to the fully connected layer so that they become feature vectors of the same dimension.
- (5)
- The semantic features output by the fully connected layer are input into the Sigmoid function to obtain its confidence, and the semantic features and the statistical features are combined according to the confidence to obtain the semantic features enhanced by the statistical features.
- (6)
- The enhanced semantic features are input into the MLP, and the output result of the model is checked to determine whether there is an abnormality in the log sequence.
4. Experimental Evaluation
- (1)
- The impact of the confidence threshold on the accuracy of anomaly detection.
- (2)
- The effectiveness of the anomaly detection method in this paper.
- (3)
- The robustness of the anomaly detection method in this paper.
4.1. Dataset and Experimental Environment
4.2. Baseline Methods and Indicators Evaluation
4.3. Experimental Parameter Settings
4.4. Test of the Influence of the Confidence Threshold on the Accuracy of Anomaly Detection
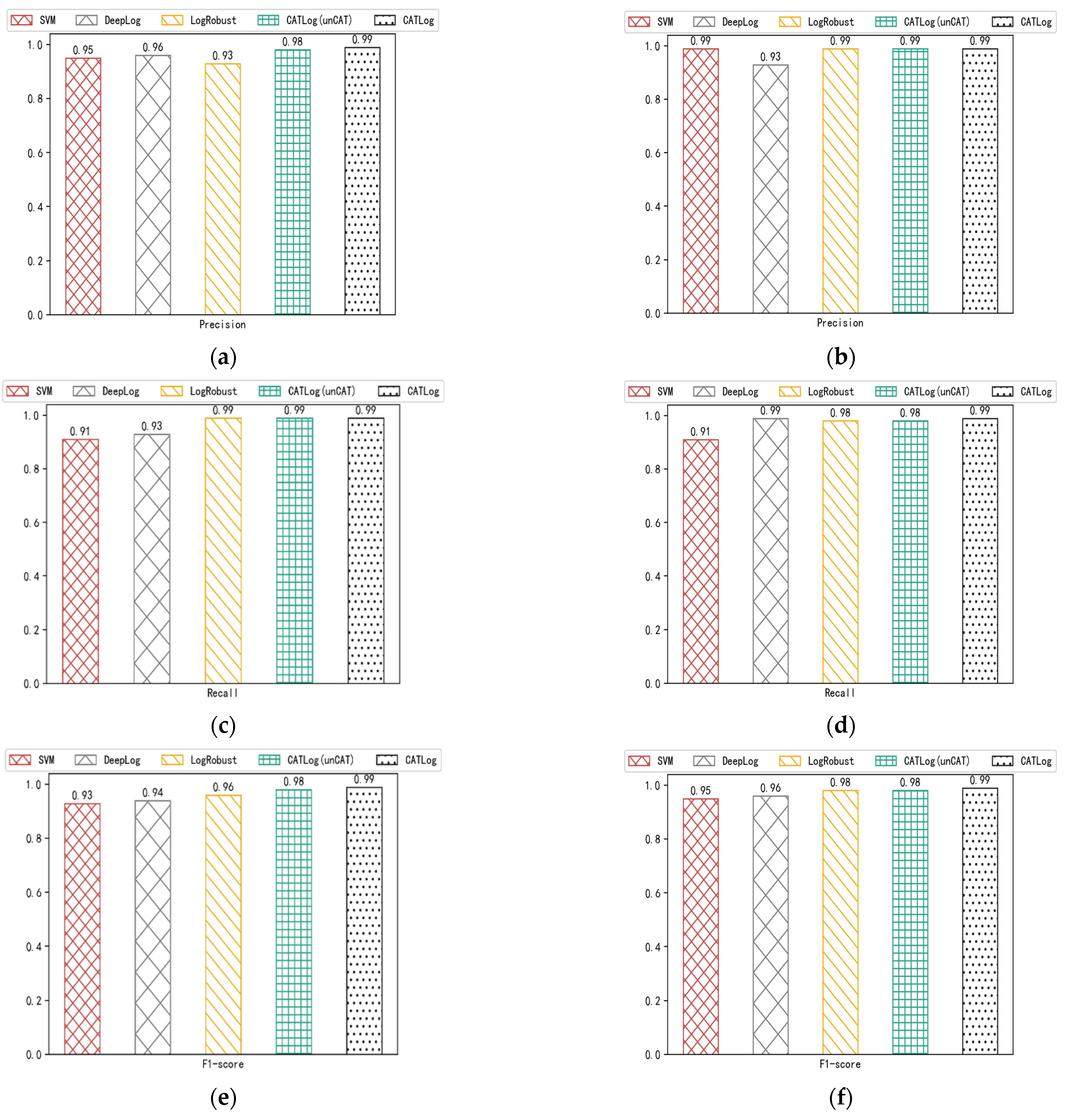
4.5. Test of Effectiveness
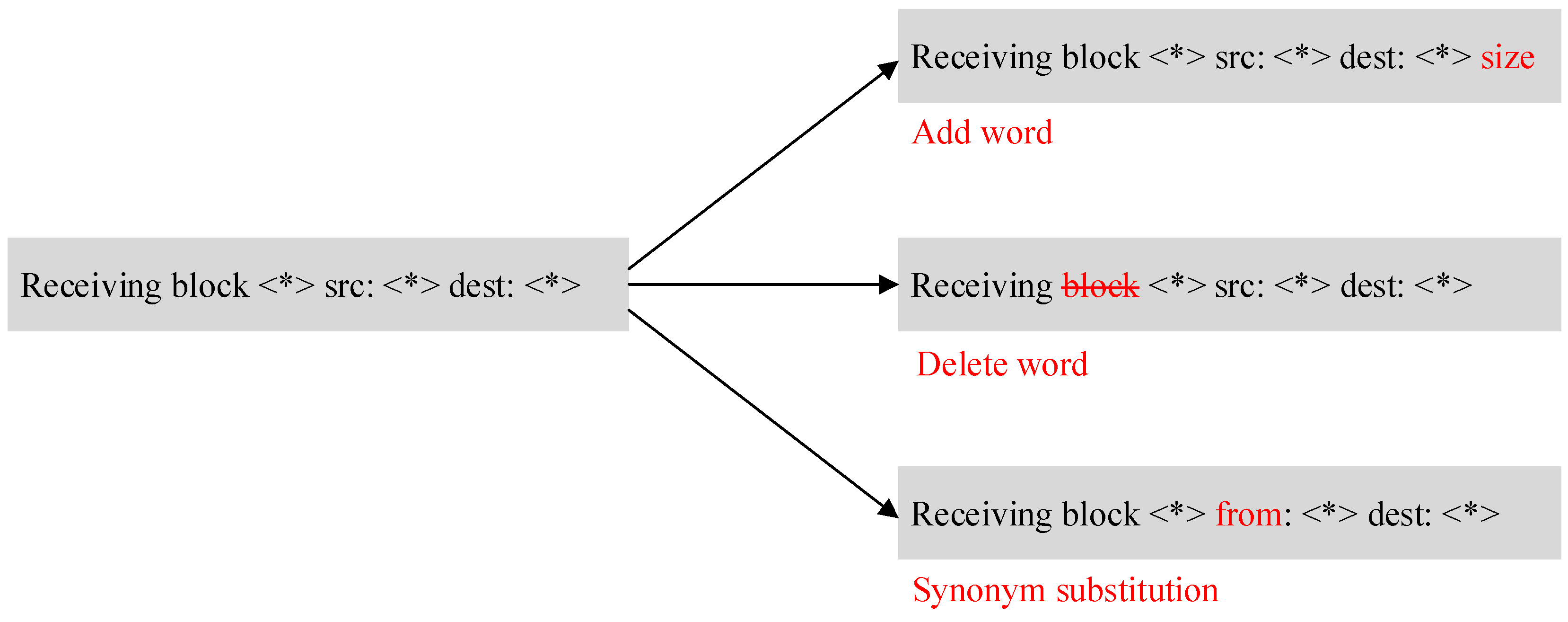
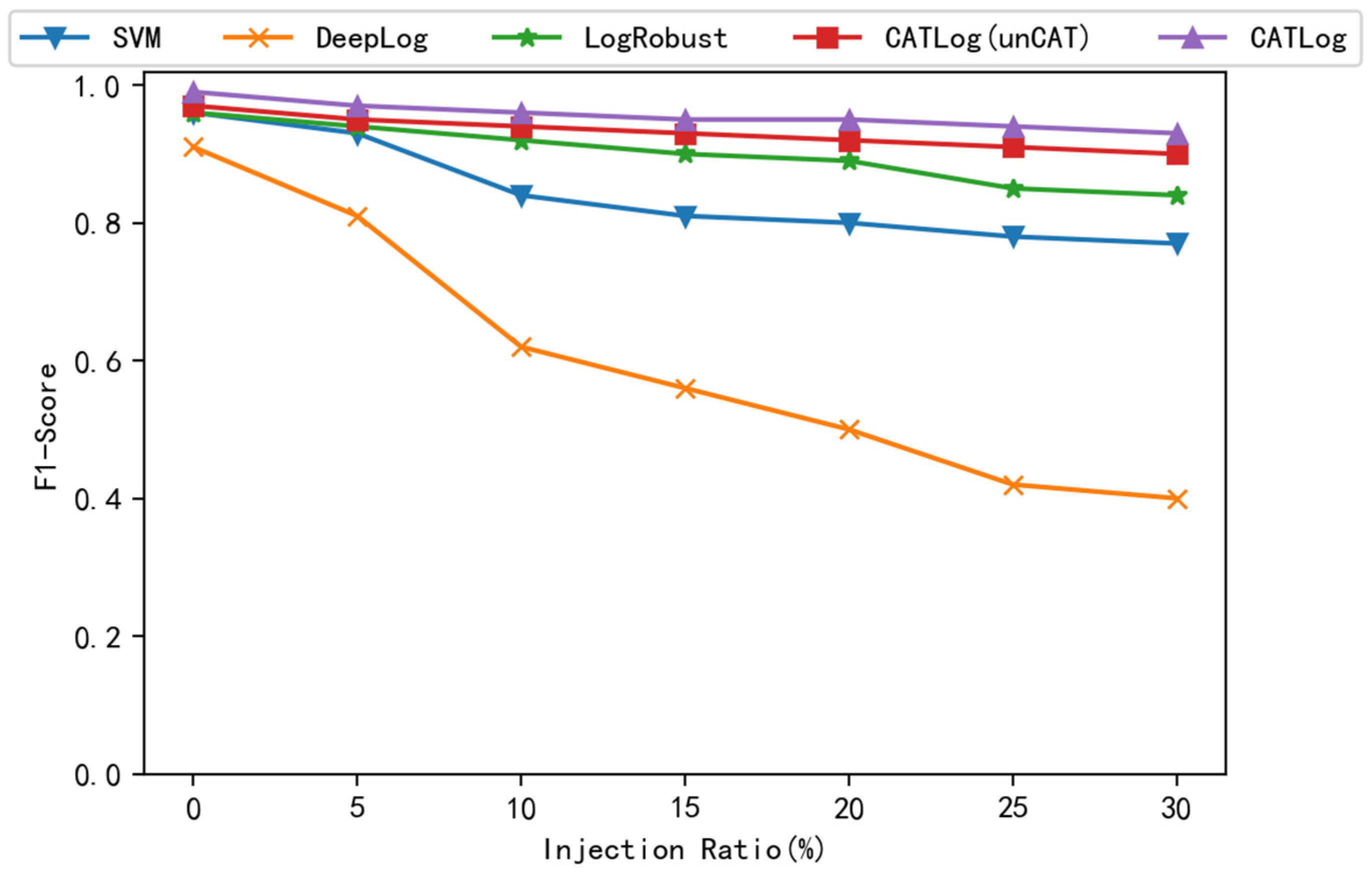
4.6. Test of Robustness
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Z.; Liu, J.; Gu, W. Experience Report: Deep Learning-based System Log Analysis for Anomaly Detection. arXiv 2021, arXiv:2107.05908. [Google Scholar]
- Lou, J.G.; Fu, Q.; Yang, S. Mining Invariants from Console Logs for System Problem Detection. In Proceedings of the USENIX Annual Technical Conference, Boston, MA, USA, 23–25 June 2010; pp. 1–14. [Google Scholar]
- Xu, W.; Huang, L.; Fox, A. Detecting large-scale system problems by mining console logs. In Proceedings of the 22nd ACM Symposium on Operating Systems Principles 2009, Big Sky, MT, USA, 11–14 October 2009; pp. 117–132. [Google Scholar]
- He, P.; Zhu, J.; He, S.; Li, J.; Lyu, M.R. Towards Automated Log Parsing for Large-Scale Log Data Analysis. IEEE Trans. Dependable Secur. Comput. 2017, 15, 931–944. [Google Scholar] [CrossRef]
- Liang, Y.; Zhang, Y.; Xiong, H. Failure prediction in ibm bluegene/l event logs. In Proceedings of the 7th IEEE International Con-ference on Data Mining, Omaha, NE, USA, 28–31 October 2007; pp. 583–588. [Google Scholar]
- Zhou, Z.; Zhang, Y.; Wang, S. A Coordination System between Decision Making and Controlling for Autonomous Collision Avoidance of Large Intelligent Ships. J. Mar. Sci. Eng. 2021, 9, 1202. [Google Scholar] [CrossRef]
- Du, M.; Li, F.; Zheng, G. Deeplog: Anomaly detection and diagnosis from system logs through deep learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1285–1298. [Google Scholar]
- Vinayakumar, R.; Soman, K.P.; Poornachandran, P. Long short-term memory based operation log anomaly detection. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics, Udupi, India, 13–16 September 2017; pp. 236–242. [Google Scholar] [CrossRef]
- Brown, A.; Tuor, A.; Hutchinson, B.; Nichols, N. Recurrent neural network attention mechanisms for interpretable system log anomaly detection. First Workshop Mach. Learn. Comput. Syst. 2018, 12, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Lu, S.; Wei, X.; Li, Y. Detecting anomaly in big data system logs using convolutional neural network. In Proceedings of the 2018 IEEE 16th International Conference on Dependable, Autonomic and Secure Computing and 16th International Conference on Pervasive Intelligence and Computing and 4th International Conference on Big Data Intelligence and Computing and Cyber Science and Technology Congress, Athens, Greece, 12–15 August 2018; pp. 151–158. [Google Scholar]
- Farzad, A.; Gulliver, T.A. Log message anomaly detection and classification using auto-b/lstm and auto-gru. arXiv 2019, arXiv:1911.08744. [Google Scholar]
- Guo, Y.; Wen, Y.; Jiang, C. Detecting Log Anomalies with Multi-Head Attention (LAMA). arXiv 2021, arXiv:2101.02392. [Google Scholar]
- Wang, J.; Tang, Y.; He, S.; Zhao, C.; Sharma, P.K.; Alfarraj, O.; Tolba, A. LogEvent2vec: LogEvent-to-Vector based anomaly detection for large-scale logs in internet of things. Sensors 2020, 20, 2451. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Xu, Y.; Lin, Q. Robust log-based anomaly detection on unstable log data. In Proceedings of the 2018 IEEE 16th International Conference on Dependable, Autonomic and Secure Computing and 16th International Conference on Pervasive Intelligence and Computing and 4th International Conference on Big Data Intelligence and Computing and Cyber Science and Technology Congress, Athens, Greece, 12–15 August 2018; pp. 807–817. [Google Scholar]
- Li, X.; Chen, P.; Jing, L.; He, Z.; Yu, G. SwissLog: Robust and unified deep learning based log anomaly detection for diverse faults. In Proceedings of the 2020 IEEE 31st International Symposium on Software Reliability Engineering (ISSRE), Coimbra, Portugal, 12–15 October 2020; pp. 92–103. [Google Scholar] [CrossRef]
- Mei, Y.D.; Chen, X.; Sun, Y.Z. A software system anomaly detection method based on log information and CNN-text. Chin. J. Computers. 2020, 43, 366–380. [Google Scholar]
- Yang, L.; Chen, J.; Wang, Z.; Wang, W.; Jiang, J.; Dong, X.; Zhang, W. Semi-supervised log-based anomaly detection via probabilistic label estimation. In Proceedings of the 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), Madrid, Spain, 25–28 May2021; pp. 1448–1460. [Google Scholar] [CrossRef]
- Meng, W.; Liu, Y.; Zhu, Y.; Zhang, S.; Pei, D.; Liu, Y.; Chen, Y.; Zhang, R.; Tao, S.; Sun, P.; et al. LogAnomaly: Unsupervised detection of sequential and quantitative anomalies in unstructured logs. IJCAI 2019, 19, 4739–4745. [Google Scholar] [CrossRef] [Green Version]
- Xia, B.; Bai, Y.; Yin, J.; Li, Y.; Xu, J. LogGAN: A log-level generative adversarial network for anomaly detection using permutation event modeling. Inf. Syst. Front. 2020, 6, 1–14. [Google Scholar] [CrossRef]
- Duan, X.; Ying, S.; Yuan, W.; Cheng, H.; Yin, X. QLLog: A log anomaly detection method based on Q-learning algorithm. Inf. Process. Manag. 2021, 58, 102540. [Google Scholar] [CrossRef]
- Miyato, T.; Dai, A.M.; Goodfellow, I. Adversarial Training Methods for Semi-Supervised Text Classification. arXiv 2016, arXiv:1605.07725. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple contrastive learning of sentence embeddings. arXiv 2021, arXiv:2104.08821. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Li, X.; Li, Z.; Xie, H. Merging statistical feature via adaptive gate for improved text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Shenzhen, China, 2–9 February 2021; pp. 13288–13296. [Google Scholar]
- He, P.; Zhu, J.; Zheng, Z.; Lyu, M.R. Drain: An Online Log Parsing Approach with Fixed Depth Tree. In Proceedings of the 2017 IEEE International Conference on Web Services (ICWS), Honolulu, HI, USA, 25–30 June 2017; pp. 33–40. [Google Scholar] [CrossRef]
- He, S.; Zhu, J.; He, P. Experience report: System log analysis for anomaly detection. In Proceedings of the 27th IEEE International Symposium on Software Reliability Engineering, Ottawa, ON, Canada, 23–27 October 2016; pp. 207–218. [Google Scholar]
- Kwon, H. Defending Deep Neural Networks against Backdoor Attack by Using De-trigger Autoencoder. IEEE Access 2021, 10, 18. [Google Scholar] [CrossRef]
- He, S.; Zhu, J.; He, P. Loghub: A large collection of system log datasets towards automated log analytics. arXiv 2020, arXiv:2008.06448. [Google Scholar]
- Guo, H.; Yuan, S.; Wu, X. LogBERT: Log anomaly detection via BERT. arXiv 2021, arXiv:2103.04475. [Google Scholar]
- Duan, X.; Ying, S.; Yuan, W.; Cheng, H.; Yin, X. A Generative Adversarial Networks for Log Anomaly Detection. Comput. Syst. Sci. Eng. 2021, 37, 135–148. [Google Scholar] [CrossRef]
- Oliner, A.; Stearley, J. What supercomputers say: A study of five system logs. In Proceedings of the 37th Annual IEEE/IFIP International Conference on Dependable Systems and Networks, Edinburgh, UK, 25–28 June 2007; pp. 575–584. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Comparison Item Method | Input Value | Model or Algorithm | Strategy to Deal with Unseen Logs |
|---|---|---|---|
| SVM [5] | event count vector | construct a hyperplane | unable to deal with unseen logs |
| IM [2] | event count vector | singular value decomposition, brute force search algorithm | unable to deal with unseen logs |
| PCA [3] | event count vector | construct normal and abnormal subspaces | unable to deal with unseen logs |
| DeepLog [7] | logkey, parameter value | LSTM | unable to deal with unseen logs |
| CNN [10] | logkey | CNN | unable to deal with unseen logs |
| LogRobust [14] | semantic vector | Bi-LSTM with Attention | semantic vector conversion, attention mechanism |
| CATLog | semantic vector, statistical vector | BERT, VAE | semantic vector conversion, contrastive adversarial training |
| η Value Size | 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Round | |||||||||||||
| First round | 0.985 | 0.985 | 0.985 | 0.985 | 0.986 | 0.986 | 0.988 | 0.988 | 0.987 | 0.987 | 0.987 | 0.987 | |
| Second round | 0.984 | 0.986 | 0.987 | 0.989 | 0.988 | 0.987 | |||||||
| Third round | 0.984 | 0.986 | 0.987 | 0.988 | 0.987 | 0.988 | |||||||
| Fourth round | 0.986 | 0.985 | 0.986 | 0.987 | 0.987 | 0.987 | |||||||
| Fifth round | 0.985 | 0.985 | 0.985 | 0.988 | 0.987 | 0.988 | |||||||
| η Value Size | 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Round | |||||||||||||
| First round | 0.988 | 0.987 | 0.989 | 0.988 | 0.990 | 0.991 | 0.989 | 0.990 | 0.987 | 0.988 | 0.987 | 0.989 | |
| Second round | 0.987 | 0.988 | 0.991 | 0.990 | 0.989 | 0.988 | |||||||
| Third round | 0.987 | 0.987 | 0.992 | 0.990 | 0.989 | 0.990 | |||||||
| Fourth round | 0.987 | 0.988 | 0.990 | 0.989 | 0.988 | 0.990 | |||||||
| Fifth round | 0.988 | 0.988 | 0.990 | 0.991 | 0.988 | 0.989 | |||||||
| Datasets | SVM | DeepLog | LogRobust | CATLog(unCAT) | CATLog |
|---|---|---|---|---|---|
| HDFS | 5 | 4 | 3 | 2 | 1 |
| BGL | 5 | 4 | 2.5 | 2.5 | 1 |
| The average ordinal values | 5 | 4 | 2.75 | 2.25 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Zhang, X.; Wang, X.; Cao, Z. Log Sequence Anomaly Detection Method Based on Contrastive Adversarial Training and Dual Feature Extraction. Entropy 2022, 24, 69. https://doi.org/10.3390/e24010069
Wang Q, Zhang X, Wang X, Cao Z. Log Sequence Anomaly Detection Method Based on Contrastive Adversarial Training and Dual Feature Extraction. Entropy. 2022; 24(1):69. https://doi.org/10.3390/e24010069
Chicago/Turabian StyleWang, Qiaozheng, Xiuguo Zhang, Xuejie Wang, and Zhiying Cao. 2022. "Log Sequence Anomaly Detection Method Based on Contrastive Adversarial Training and Dual Feature Extraction" Entropy 24, no. 1: 69. https://doi.org/10.3390/e24010069