
Sparse Density Estimation with Measurement Errors

Abstract
:1. Introduction
2. Density Estimation
2.1. Mixture Models
- (H.1): the is defined as
2.2. The Density Estimation with Measurement Errors
- if
- if
3. Sparse Mixture Density Estimation
3.1. Data-Dependent Weights
- (H.2): s.t. ;
- (H.3): .
3.2. Non-Asymptotic Oracle Inequalities
3.3. Corrected Support Identification of Mixture Models
4. Simulation and Real Data Analysis
4.1. Tuning Parameter Selection
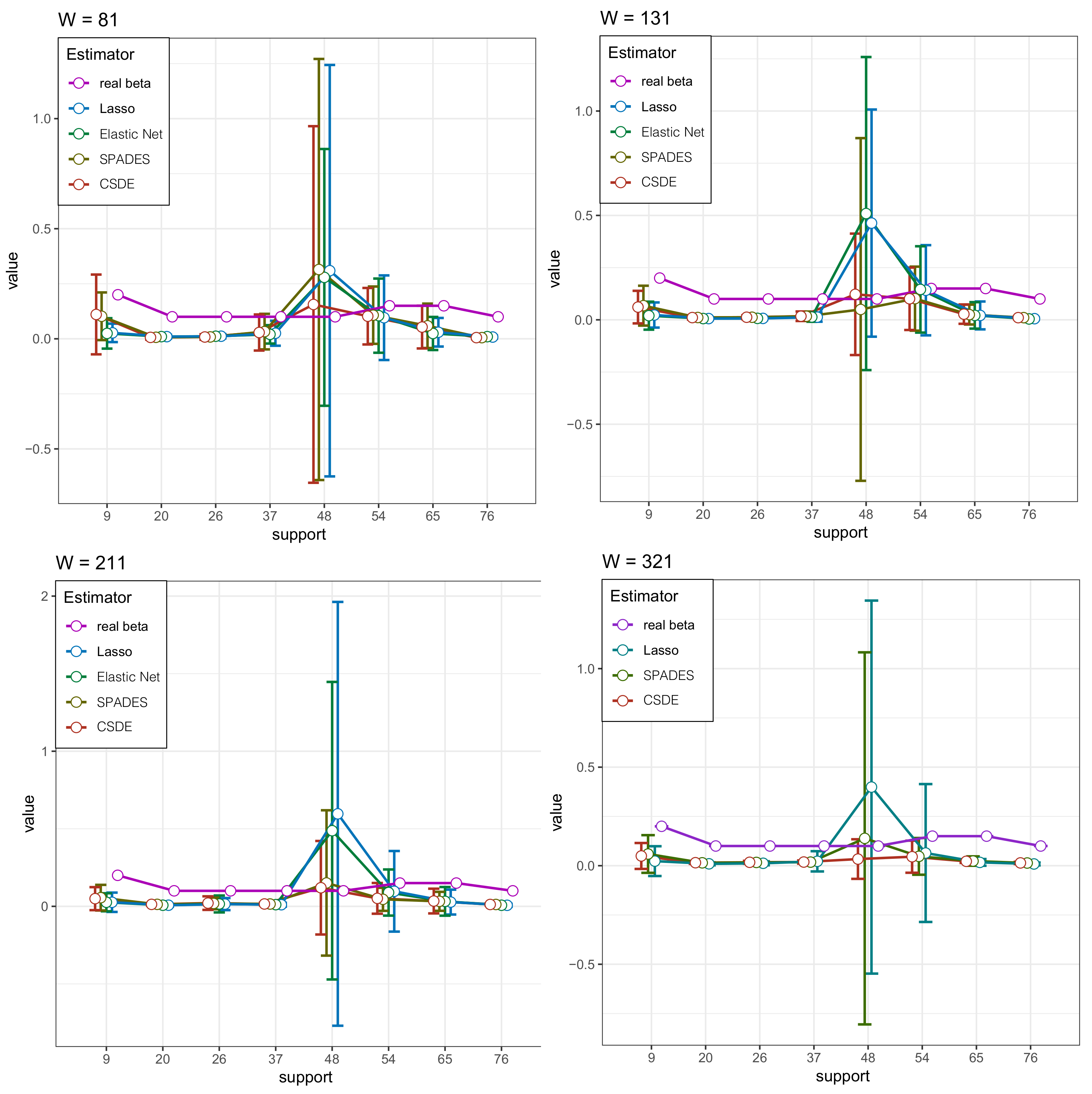
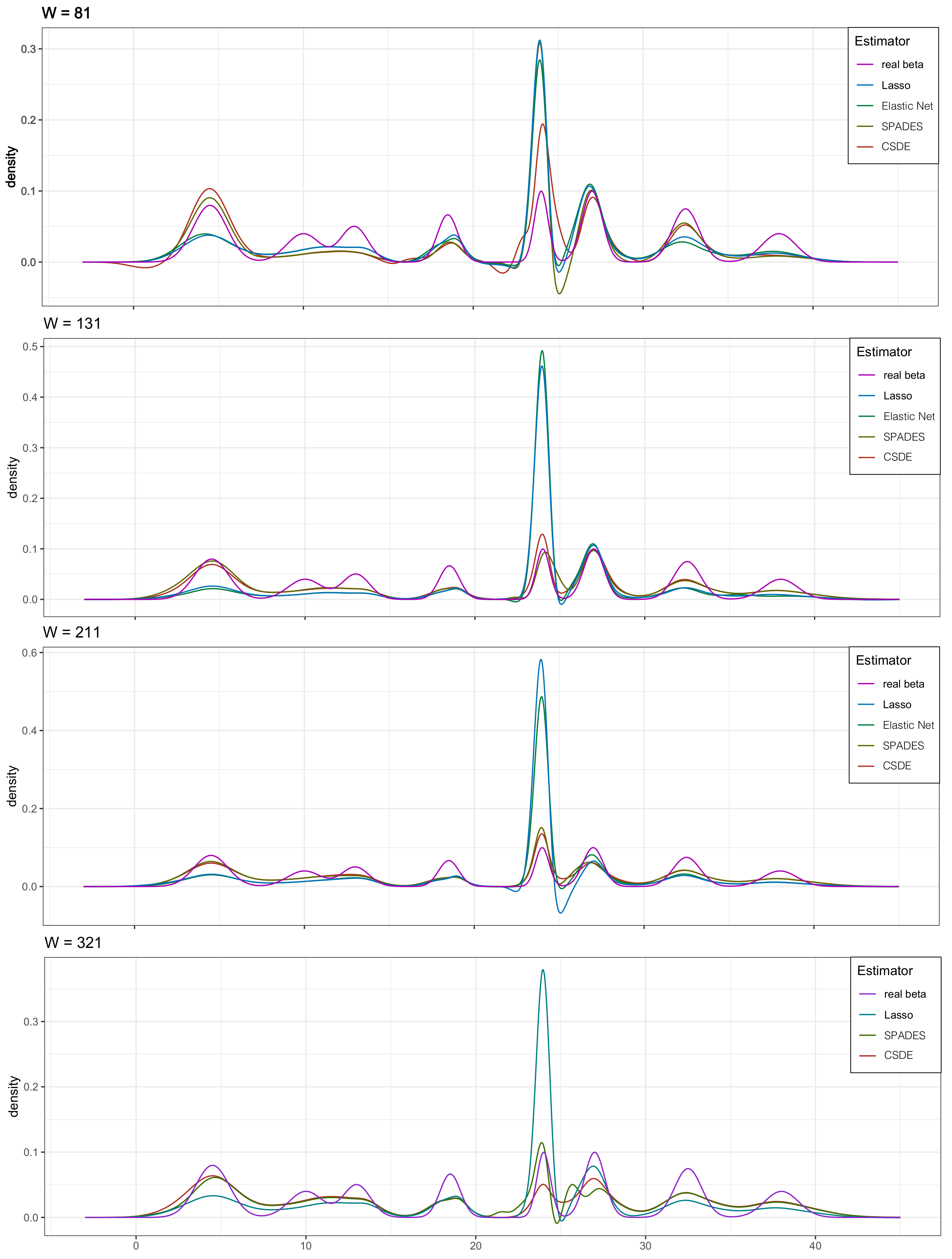
4.2. Multi-Modal Distributions
4.3. Mixture of Poisson Distributions
4.4. Low-Dimensional Mixture Model
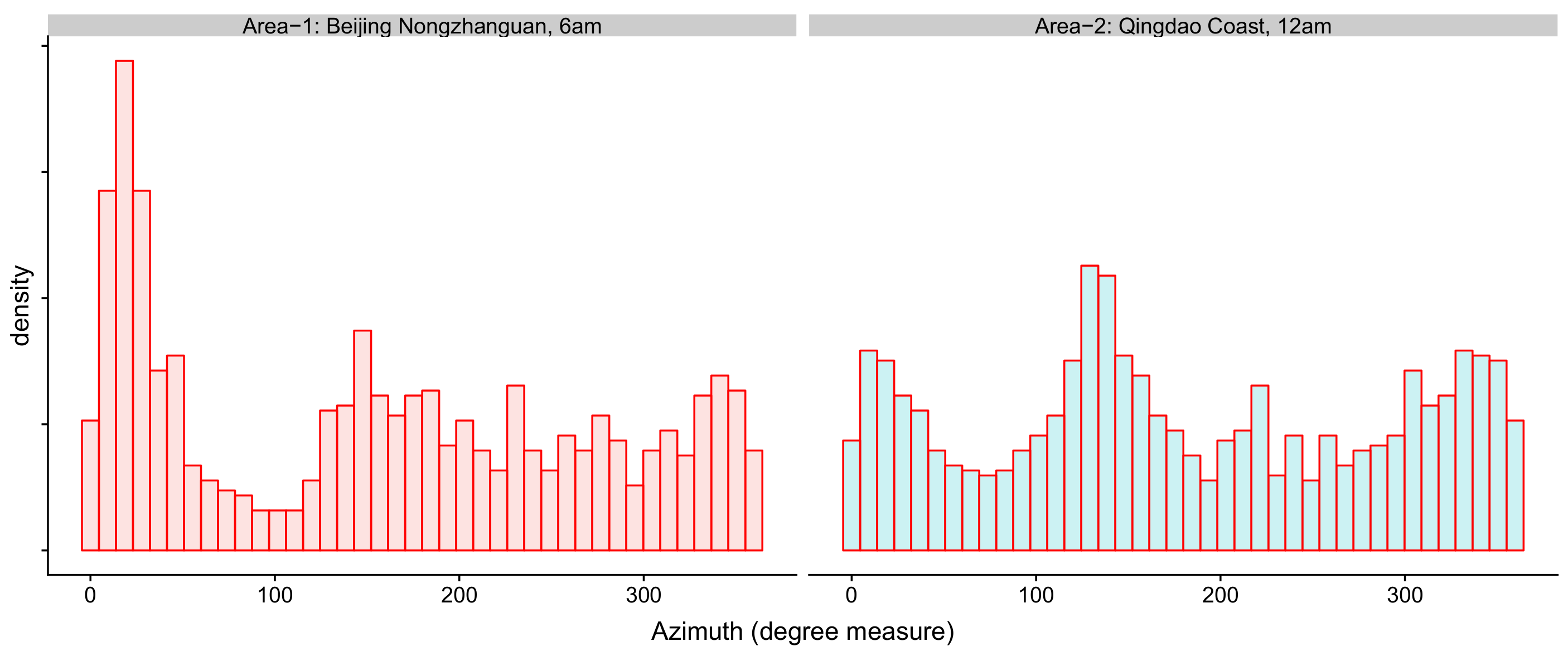
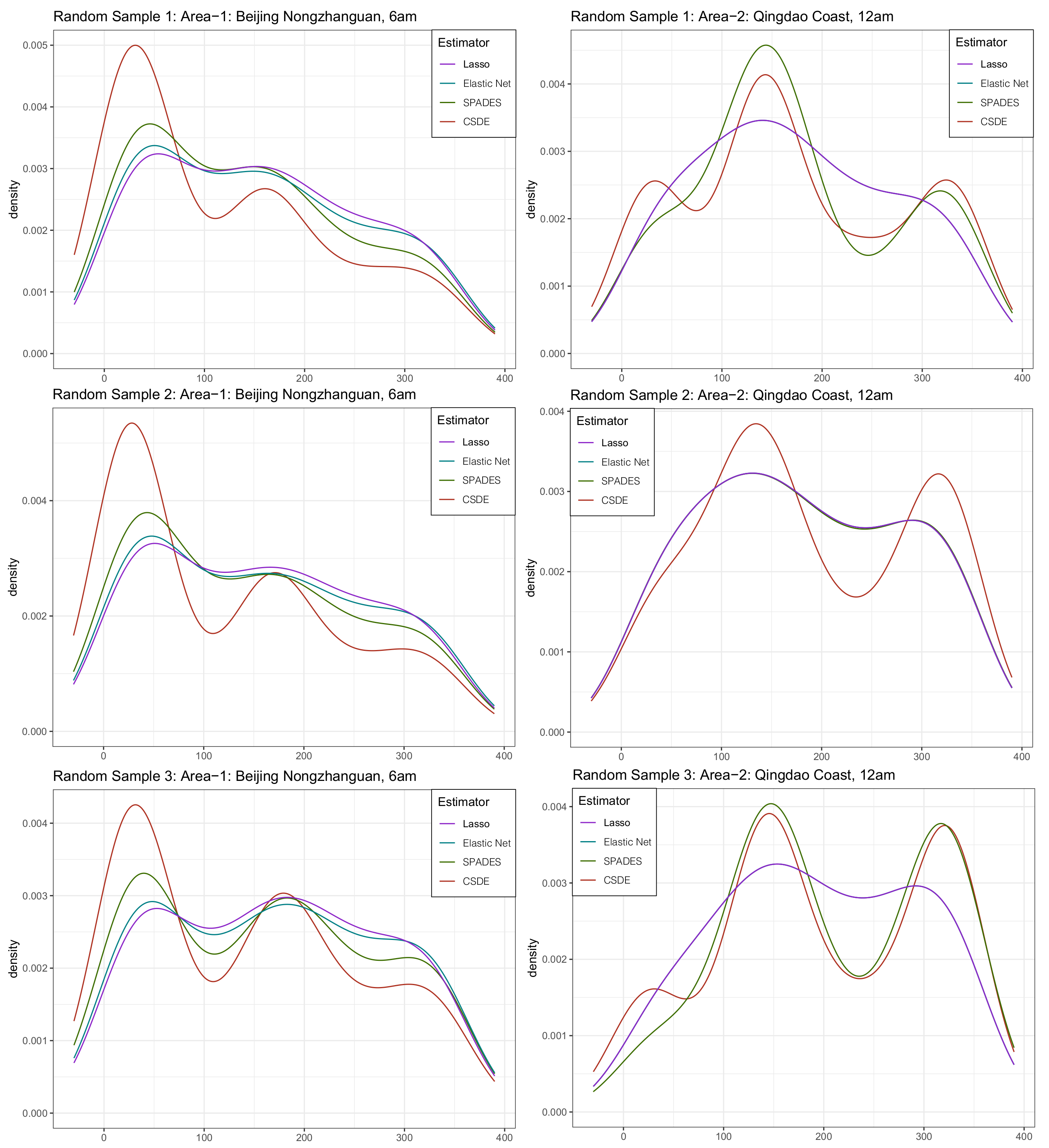
4.5. Real Data Examples
5. Summary and Discussions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Proof of Lemma A1
Appendix A.2. Proof of Theorems
Appendix A.3. Proof of Theorem 1
Appendix A.4. Proof of Theorem 2
Appendix A.5. Proof of Corollory 1
Appendix A.6. Proof of Corollary 2
Appendix A.7. Proof of Theorem 3
References
- McLachlan, G.J.; Lee, S.X.; Rathnayake, S.I. Finite mixture models. Ann. Rev. Stat. Appl. 2019, 6, 355–378. [Google Scholar] [CrossRef]
- Balakrishnan, S.; Wainwright, M.J.; Yu, B. Statistical guarantees for the EM algorithm: From population to sample-based analysis. Ann. Stat. 2017, 45, 77–120. [Google Scholar] [CrossRef]
- Wu, Y.; Zhou, H.H. Randomly initialized EM algorithm for two-component Gaussian mixture achieves near optimality in O() iterations. arXiv 2019, arXiv:1908.10935. [Google Scholar]
- Chen, J.; Khalili, A. Order selection in finite mixture models with a nonsmooth penalty. J. Am. Stat. Assoc. 2008, 103, 1674–1683. [Google Scholar] [CrossRef] [Green Version]
- DasGupta, A. Asymptotic Theory of Statistics and Probability; Springer: New York, NY, USA, 2008. [Google Scholar]
- Devroye, L.; Lugosi, G. Combinatorial Methods in Density Estimation; Springer: New York, NY, USA, 2001. [Google Scholar]
- Biau, G.; Devroye, L. Density estimation by the penalized combinatorial method. J. Multivar. Anal. 2005, 94, 196–208. [Google Scholar] [CrossRef] [Green Version]
- Martin, R. Fast Nonparametric Estimation of a Mixing Distribution with Application to High Dimensional Inference. Ph.D. Thesis, Purdue University, West Lafayette, IN, USA, 2009. [Google Scholar]
- Bunea, F.; Tsybakov, A.B.; Wegkamp, M.H.; Barbu, A. Spades and mixture models. Ann. Stat. 2010, 38, 2525–2558. [Google Scholar] [CrossRef]
- Bertin, K.; Le Pennec, E.; Rivoirard, V. Adaptive Dantzig density estimation. Annales de l’IHP Probabilités et Statistiques 2011, 47, 43–74. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Methodological 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Hall, P.; Lahiri, S.N. Estimation of distributions, moments and quantiles in deconvolution problems. Ann. Stat. 2008, 36, 2110–2134. [Google Scholar] [CrossRef]
- Meister, A. Density estimation with normal measurement error with unknown variance. Stat. Sinica 2006, 16, 195–211. [Google Scholar]
- Cheng, C.L.; van Ness, J.W. Statistical Regression with Measurement Error; Wiley: New York, NY, USA, 1999. [Google Scholar]
- Zhu, H.; Zhang, R.; Zhu, G. Estimation and Inference in Semi-Functional Partially Linear Measurement Error Models. J. Syst. Sci. Complex. 2020, 33, 1179–1199. [Google Scholar] [CrossRef]
- Zhu, H.; Zhang, R.; Yu, Z.; Lian, H.; Liu, Y. Estimation and testing for partially functional linear errors-in-variables models. J. Multivar. Anal. 2019, 170, 296–314. [Google Scholar] [CrossRef]
- Bonhomme, S. Penalized Least Squares Methods for Latent Variables Models. In Advances in Economics and Econometrics: Volume 3, Econometrics: Tenth World Congress; Cambridge University Press: Cambridge, UK, 2013; Volume 51, p. 338. [Google Scholar]
- Nakamura, T. Corrected score function for errors-in-variables models: Methodology and application to generalized linear models. Biometrika 1990, 77, 127–137. [Google Scholar] [CrossRef]
- Buonaccorsi, J.P. Measurement error. In Models, Methods, and Applications; Chapman & Hall/CRC: Boca Raton, FL, USA, 2010. [Google Scholar]
- Carroll, R.J.; Ruppert, D.; Stefanski, L.A.; Crainiceanu, C.M. Measurement error in nonlinear models. In A Modern Perspective, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2006. [Google Scholar]
- Zou, H.; Zhang, H. On the adaptive elastic-net with a diverging number of parameters. Ann. Stat. 2009, 37, 1733–1751. [Google Scholar] [CrossRef] [Green Version]
- Aitchison, J.; Aitken, C.G. Multivariate binary discrimination by the kernel method. Biometrika 1976, 63, 413–420. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Rosenbaum, M.; Tsybakov, A.B. Sparse recovery under matrix uncertainty. Ann. Stat. 2010, 38, 2620–2651. [Google Scholar] [CrossRef]
- Zhang, H.; Jia, J. Elastic-net regularized high-dimensional negative binomial regression: Consistency and weak signals detection. Stat. Sinica 2022, 32. [Google Scholar] [CrossRef]
- Buhlmann, P.; van de Geer, S. Statistics for High-Dimensional Data: Methods, Theory and Applications; Springer: New York, NY, USA, 2011. [Google Scholar]
- Belloni, A.; Rosenbaum, M.; Tsybakov, A.B. Linear and conic programming estimators in high dimensional errors-in-variables models. J. R. Stat. Soc. Series B Stat. Methodol. 2017, 79, 939–956. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Gao, Y.; Zhang, H.; Li, B. Weighted Lasso estimates for sparse logistic regression: Non-asymptotic properties with measurement errors. Acta Math. Sci. 2021, 41, 207–230. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, S.X. Concentration Inequalities for Statistical Inference. Commun. Math. Res. 2021, 37, 1–85. [Google Scholar]
- Donoho, D.L.; Johnstone, J.M. Ideal spatial adaptation by wavelet shrinkage. Biometrika 1994, 81, 425–455. [Google Scholar] [CrossRef]
- Deng, H.; Chen, J.; Song, B.; Pan, Z. Error bound of mode-based additive models. Entropy 2021, 23, 651. [Google Scholar] [CrossRef]
- Bickel, P.J.; Ritov, Y.A.; Tsybakov, A.B. Simultaneous analysis of Lasso and Dantzig selector. Ann. Stat. 2009, 37, 1705–1732. [Google Scholar] [CrossRef]
- Bunea, F. Honest variable selection in linear and logistic regression models via ℓ1 and ℓ1 + ℓ2 penalization. Electron. J. Stat. 2008, 2, 1153–1194. [Google Scholar] [CrossRef]
- Chow, Y.S.; Teicher, H. Probability Theory: Independence, Interchangeability, Martingales, 3rd ed.; Springer: New York, NY, USA, 2003. [Google Scholar]
- Hersbach, H.; de Rosnay, P.; Bell, B.; Schepers, D.; Simmons, A.; Soci, C.; Abdalla, S.; Alonso-Balmaseda, M.; Balsamo, G.; Bechtold, P.; et al. Operational Global Reanalysis: Progress, Future Directions and Synergies with NWP; European Centre for Medium Range Weather Forecasts: Reading, UK, 2018. [Google Scholar]
- Fisher, N.I. Statistical Analysis of Circular Data; Cambridge University Press: Cambridge, UK, 1995. [Google Scholar]
- Broniatowski, M.; Jureckova, J.; Kalina, J. Likelihood ratio testing under measurement errors. Entropy 2018, 20, 966. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| W | Error | Error | ||
|---|---|---|---|---|
| Lasso | 81 | 0.065 | 2.133 (2.467) | 1.137 (1.115) |
| Elastic-net | 2.061 (1.439) | 1.114 (0.805) | ||
| SPADES | 0.053 | 1.922 (2.211) | 1.258 (1.296) | |
| CSDE | 2.191 (4.812) | 1.405 (2.329) | ||
| Lasso | 131 | 0.068 | 2.032 (0.985) | 1.352 (0.712) |
| Elastic-net | 2.236 (2.498) | 1.409 (1.056) | ||
| SPADES | 0.056 | 1.880 (2.644) | 0.972 (1.204) | |
| CSDE | 1.635 (0.342) | 0.863 (0.402) | ||
| Lasso | 211 | 0.071 | 2.572 (4.187) | 1.605 (2.702) |
| Elastic-net | 2.061 (1.883) | 1.353 (1.516) | ||
| SPADES | 0.058 | 1.764 (1.041) | 0.832 (0.610) | |
| CSDE | 1.648 (0.168) | 0.791 (0.415) | ||
| Lasso | 321 | 0.074 | 2.120 (2.842) | 1.146 (1.115) |
| Elastic-net | 10.173 (82.753) | 7.839 (67.887) | ||
| SPADES | 0.061 | 2.106 (4.816) | 0.818 (1.565) | |
| CSDE | 1.623 (0.085) | 0.634 (0.199) |
| W | Error | Error | ||
|---|---|---|---|---|
| Lasso | 81 | 0.048 | 1.796 (0.006) | 0.002 (0.001) |
| Elastic-net | 1.796 (0.006) | 0.002 (0.001) | ||
| SPADES | 0.138 | 1.811 (0.013) | 0.002 (0.005) | |
| CSDE | 1.806 (0.008) | 0.003 (0.005) | ||
| Lasso | 131 | 0.051 | 1.828 (0.006) | 0.003 (0.001) |
| Elastic-net | 1.830 (0.009) | 0.004 (0.002) | ||
| SPADES | 0.145 | 1.880 (0.006) | 0.002 (0.005) | |
| CSDE | 1.854 (0.006) | 0.002 (0.004) | ||
| Lasso | 211 | 0.053 | 1.935 (0.010) | 0.005 (0.003) |
| Elastic-net | 2.061 (0.014) | 0.007 (0.008) | ||
| SPADES | 0.152 | 1.935 (0.008) | 0.005 (0.003) | |
| CSDE | 1.861 (0.005) | 0.003 (0.002) | ||
| Lasso | 321 | 0.055 | 1.927 (0.031) | 0.005 (0.002) |
| Elastic-net | 2.123 (0.026) | 0.009 (0.009) | ||
| SPADES | 0.158 | 1.938 (0.008) | 0.005 (0.003) | |
| CSDE | 1.852 (0.002) | 0.002 (0.001) |
| Error | Error | ||
|---|---|---|---|
| Scenario 1 | EM | 0.255 (0.122) | 0.205 (0.098) |
| CSDE | 0.206 (0.145) | 0.185 (0.104) | |
| Scenario 2 | EM | 0.111 (0.055) | 0.111 (0.055) |
| CSDE | 0.109 (0.037) | 0.108 (0.037) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Zhang, H.; Wei, H.; Zhang, S. Sparse Density Estimation with Measurement Errors. Entropy 2022, 24, 30. https://doi.org/10.3390/e24010030
Yang X, Zhang H, Wei H, Zhang S. Sparse Density Estimation with Measurement Errors. Entropy. 2022; 24(1):30. https://doi.org/10.3390/e24010030
Chicago/Turabian StyleYang, Xiaowei, Huiming Zhang, Haoyu Wei, and Shouzheng Zhang. 2022. "Sparse Density Estimation with Measurement Errors" Entropy 24, no. 1: 30. https://doi.org/10.3390/e24010030