1. Introduction
With the development of computer technology, image editing software is becoming more and more popular, such as Photoshop, CorelDRAW and Fireworks. After simple operations, you can create any images you want. We cannot deny that the popularity of image editing tools has brought convenience to our life, but at the same time, the threshold of tampering has been greatly reduced. Through the Internet and newspaper, a large number of tampered images are used to spread rumors, fabricate fake news and obtain illegal benefits. Therefore, digital image forensics emerges as the times require.
After more than ten years of development, image forensics technology has been widely used in news, justice, criminal investigation and other fields. Techniques used to identify image authenticity can be divided into two groups: active methods [
1,
2] and passive methods [
3,
4]. In active methods, the embedded watermark is regarded as an image fingerprint. The authenticity can be confirmed if the retrieved information is consistent with the original one. Passive methods locate the tampered area by analyzing features left by manipulations rather than the extrinsic information of test image. Due to the wider application of passive techniques, they are playing a constructive role in image forensics.
Up to now, many passive forensics techniques have been reported. Among these methods, copy-move [
5,
6], splicing [
7,
8], removal [
9], enhancement [
10], face anti-spoofing [
11] and deepfake [
12] are hot topics. Copy-move forgery is solved by searching two identical regions in an image. Splicing, removal and enhancement detection depend on distinguishing the abrupt spliced boundary and verifying a unique manipulation that is existed in tampered area. Depth and temporal information play vital roles in face anti-spoofing tasks. Deepfake is a hotspot in recent years. Color cues, fingerprint of GAN and head pose estimation are key properties for deepfake detection.
It is worth noting that during the COVID-19, some people tampered the nucleic acid detection report to illegally obtain the freedom of movement, which brought great hidden danger to public safety. However, the current forensics research is more focused on natural content images. To promote the application of image forensics technology in broader areas, in this paper, we identify the authenticity of certificate images, which can directly represent people’s rights and interests. In order to make the dataset closer to those in the real world, the tampered images in our experiments include arbitrary operations, such as splicing, copy-move and object removal. Examples of tampered certificate images are illustrated in
Figure 1.
Obviously, fake certificate images have two remarkable characteristics. The first one is the variable tampered region scales. The tampered region will be very small if only a single word or number is modified, whereas the tampered area of the stamp can be much larger. The second one is the diversity of manipulation types. Each fake certificate image in our experiments contains at least one type of manipulation.
In order to identify the authenticity of certificate images, variable tampered area scales and diverse manipulations are two important issues to be solved. For the first problem, Atrous Spatial Pyramid Pooling (ASPP) [
13] is a common technique for multi-scale features extraction in deep learning based methods. A recent work [
14] made use of ASPP on the last attention module and fused features by element-wise product. DOA-GAN [
15] applied two ASPP operations with different parameters on a concatenated feature to capture two types of information on different scales. In terms of the second problem, each type of manipulation leaves its own unique traces. Copy-move forgery could be distinguished by finding at least two similar objects in the image [
15]. The differences of features between host image and spliced region were exploited in splicing detection [
16,
17]. Object removal detection depends on the similarity among image patches’ features [
9,
18,
19]. However, the exiting forensic methods have two drawbacks: (1) The local information would become very weak with the increase of network layers, making the discriminative features especially in small targets difficult to retain. As a result, small tampered region would be hard to discover. (2) Most methods don’t work well when identifying image which contains more than one type of manipulation.
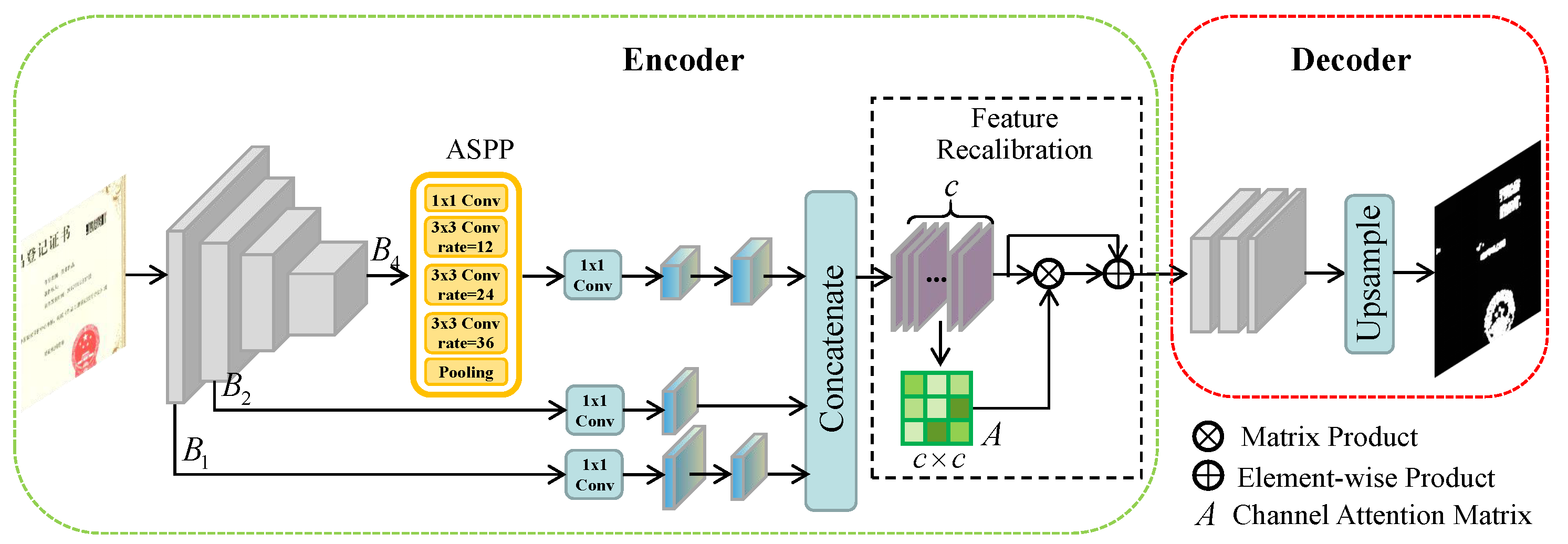
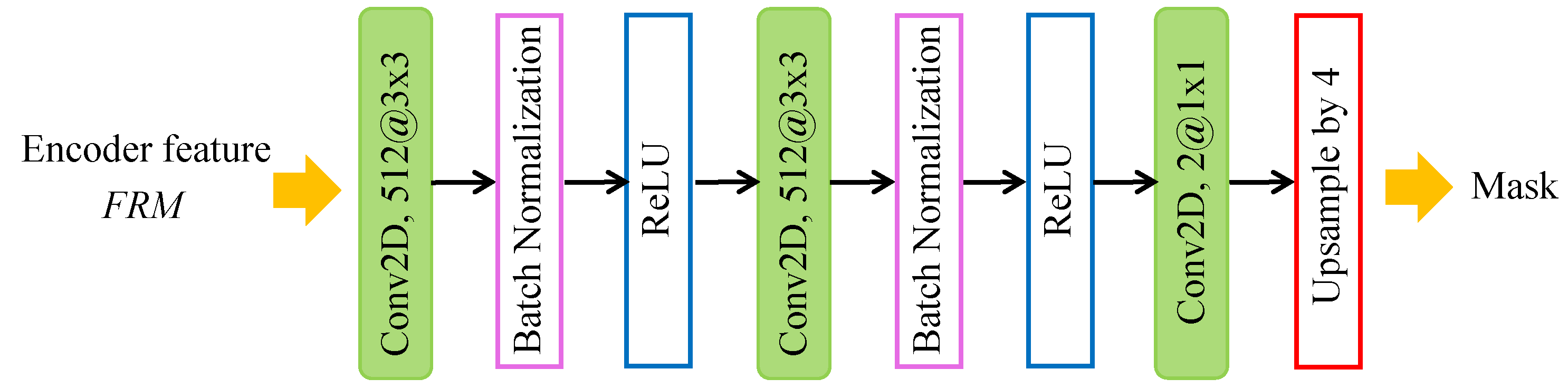
In this paper, we address the above issues and propose a multi-level features attention network for fake certificate image detection. We employ a pre-trained residual network to obtain rich features by three steps. Firstly, ASPP module is applied to capture the contextual information at different scales. Secondly, high-level semantic features are concatenated with low-level features to prevent the properties of a small target from losing after pooling. Finally, we recalibrate the weights of feature map channels to make the network more discriminative for variable manipulation traces. Experimental results verify that the proposed method outperforms the state-of-the-art image forensics methods.
Our contributions are summarized in three-fold. (1) To preserve more information and avoid failures in localizing small tampered objects, low-level convolution layers are made use of to fuse the final feature map. (2) We implement recalibration on feature channels to effectively capture traces of different types of manipulations. (3) We propose a novel network called MFAN for fake certificate images detection, which outperforms some state-of-the-art detection methods.
The rest of the paper is organized as follows.
Section 2 presents a brief review of forensics technology and attention mechanism. The proposed method for fake certificate image detection is described in
Section 3.
Section 4 shows our experimental results, and we conclude this paper in
Section 5.
4. Experimental Results
In this section, extensive experiments are conducted to evaluate the performance of the proposed method for fake certificate image detection. We first introduce the dataset and evaluation metrics. Afterward, the demonstration of effectiveness on multi-features fusion and feature recalibration is described in ablation study. Moreover, MFAN is compared with some state-of-the-art forgery detection methods under different cases. Finally, we also carry out experiments on image splicing benchmark datasets to evaluate the universality of MFAN on natural content images.
4.1. Dataset and Evaluation Metrics
In 2020, a security AI challenger program called
Forgery Detection on Certificate Image was co-sponsored by Alibaba Security and Tsinghua University [
39]. This competition provided a TIANCHI dataset that contains tampered certificate images and their corresponding ground truth masks, where part of the data comes from real business scenarios. The image sizes range from
to
, and we make use of 1000 images from TIANCHI for the experiments. There are seven types of certificate images in TIANCHI dataset: copyright declaration, contract, business license, trademark registration, book cover, honorary certificate and work registration. Tampering manipulations are composed of splicing, copy-move, object removal and text insertion. The challenging thing is that each fake certificate image contains more than one type of manipulation.
The details of experimental data are listed in
Table 1. We randomly select 800 images as training data, 100 images as validation data and 100 images for plain testing. What is more, in order to evaluate the robustness of the proposed method, four attacks including JPEG compression, Gaussian noise, resize and median blur are considered on plain testing set. The quality factor of JPEG compression ranges from 60 to 100 with step 10; the Gaussian noise varies in standard deviation from 0.02 to 0.1 with step 0.02; the resize scale ranges from 0.8 to 1.2 with step 0.1 and blur kernel sizes are
,
,
. Thus, 1800 images are generated for robustness evaluation.
To comprehensively evaluate the performance of MFAN, we also conduct experiments on CASIA [
40], Columbia [
41] and NC2016 [
42] to show the universality of our method on natural content images. CASIA is an image forgery benchmark dataset that has two versions, i.e., CASIA v1.0 and CASIA v2.0. In CASIA v1.0, there are 921 compressed images with size
. CASIA v2.0 contains 5123 images. Forgeries from both versions are manipulated by splicing or copy-move operations. Columbia consists 180 uncompressed spliced images. In NC2016, images in an average resolution
are with finely and fine-grained detailed editing.
To evaluate the performance of our method for certificate image forensics, and score are applied as evaluation metrics in measuring the accuracy of tampered regions localization.
4.2. Ablation Study
In this subsection, a series of experiments are conducted to explore the effectiveness of some essential components.
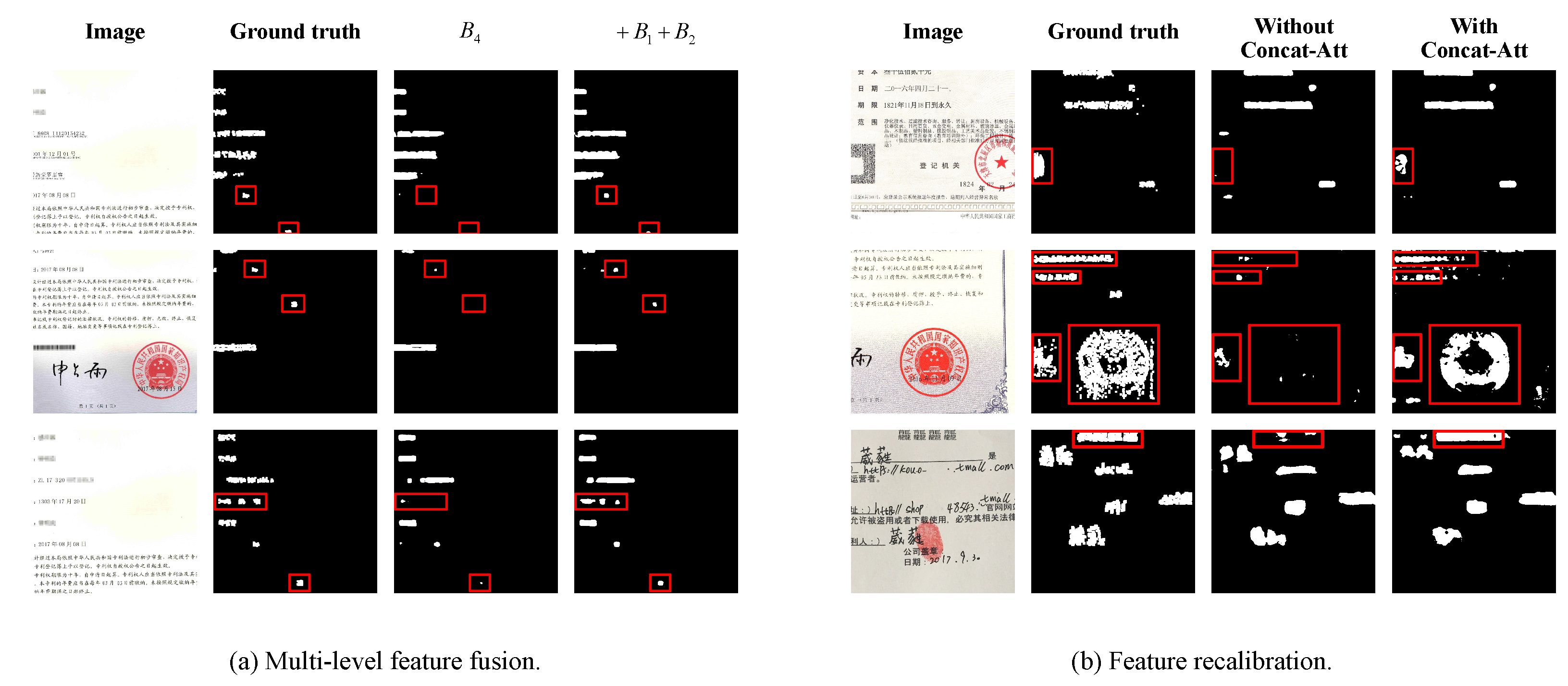
Table 2 summarizes the localization results by employing multi-level feature fusion, feature recalibration and auxiliary loss, respectively. For multi-level feature fusion, we create a baseline named “
” by only feeding the feature map of the fourth block of ResNet-50 into decoder network. For simplicity, “
” and “
” indicate that low-level features
,
and
are concatenated to “
” in different ways of combination, respectively. We can see that “
” achieves 0.6274
and 0.7710
score, which is the best way for multi-level feature fusion. The visualization results of “
” and “
” are shown in
Figure 5a. We can see that “
” performs better than “
” in locating small targets. Furthermore, a quantitative analysis of small targets localization is given in
Table 3. We calculate the localization accuracy of “
” and “
” for different scales of tamper regions. Obviously, “
” overcomes “
” from “
” to “
”.
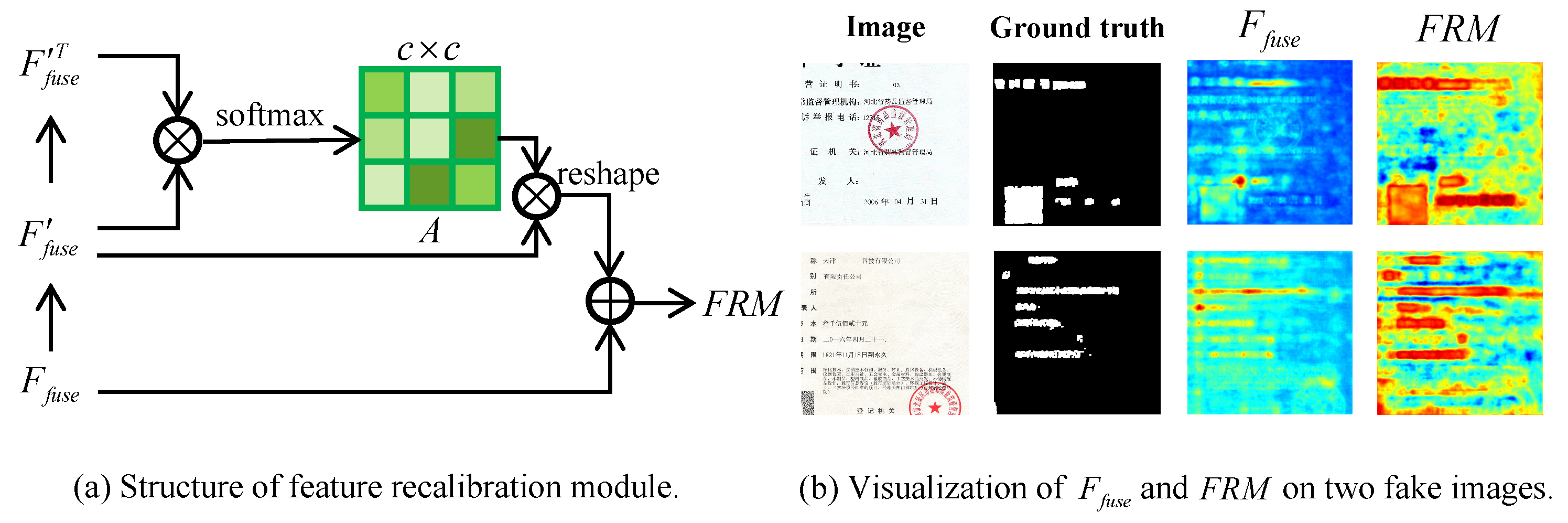
One of the remarkable characteristics of fake certificate images is a mixture of various manipulations. Channels on the feature maps have different emphases for different types of manipulations. Therefore, we recalibrate feature maps on channels on the basis of “
”. “ASPP-Att” represents employing attention mechanism after ASPP module. “Concat-Att” means applying attention mechanism on the fusion feature
. From
Table 2, it is obvious that the performance of “
+ Concat-Att” is better than that of “
+ ASPP-Att”. Since some channels of feature maps can be regarded as responses to one or more specific types of manipulations, whereas some are noise, “Concat-Att” can benefit from capturing richer manipulations-related features. The effectiveness of the feature recalibration module is demonstrated in
Figure 5b. It can be clearly seen that the localization performance of “With Concat-Att” is better than that of “Without Concat-Att”, especially in the bounding boxes.
Furthermore, we investigate the effect of auxiliary loss weight on the result. “aux-0.1”, “aux-0.2” and “aux-0.3” indicate the auxiliary loss weight , and , respectively. Obviously, “ + Concat-Att+aux-0.2” gets the best result with 0.6360 and 0.7775 score. As a result, we use it as the proposed method in the following experiments.
4.3. Comparison against Other Methods
To evaluate the performance of the proposed method, we compare it with a number of state-of-the-art methods, which are listed in
Table 4. We select three kinds of competing algorithms. The first one is traditional forensics including CFA [
16] and NOI [
43]. The second one is deep learning based forensics including RRU-Net [
36], ManTra-Net [
8], MVSS-Net [
44] and a top solution TianchiRank-3 [
45] in the Tianchi competition, where the ManTra-Net model is pretrained on a private large scale dataset, the MVSS-Net model is pretrained on CASIA v2.0, and TianchiRank-3 is trained with a batch size of 10 and 300 epochs. The last one is semantic segmentation method EncNet [
46].
Table 5 lists the localization results on TIANCHI dataset compared with CFA [
16], NOI [
43], RRU-Net [
36], ManTra-Net [
8], MVSS-Net [
44], TianchiRank-3 [
45] and EncNet [
46]. It can be seen that the proposed algorithm achieves the highest score in
and
compared with other detection methods, outperforming the second best approach EncNet [
46] by
and
. Some detection results are shown in
Figure 6. It is clear that our proposed MFAN can localize tampered regions more accurately than other detection methods.
The good performance of our method in fake certificate image detection is benefited from two main factors. (1) In the feature extraction step, we not only take advantage of the last layer of backbone, but also concatenate it with other low-level features to form a richer feature. (2) The fusion feature was applied by attention mechanism on channels to pay more attention to channels that are associated with the tampered traces of manipulations.
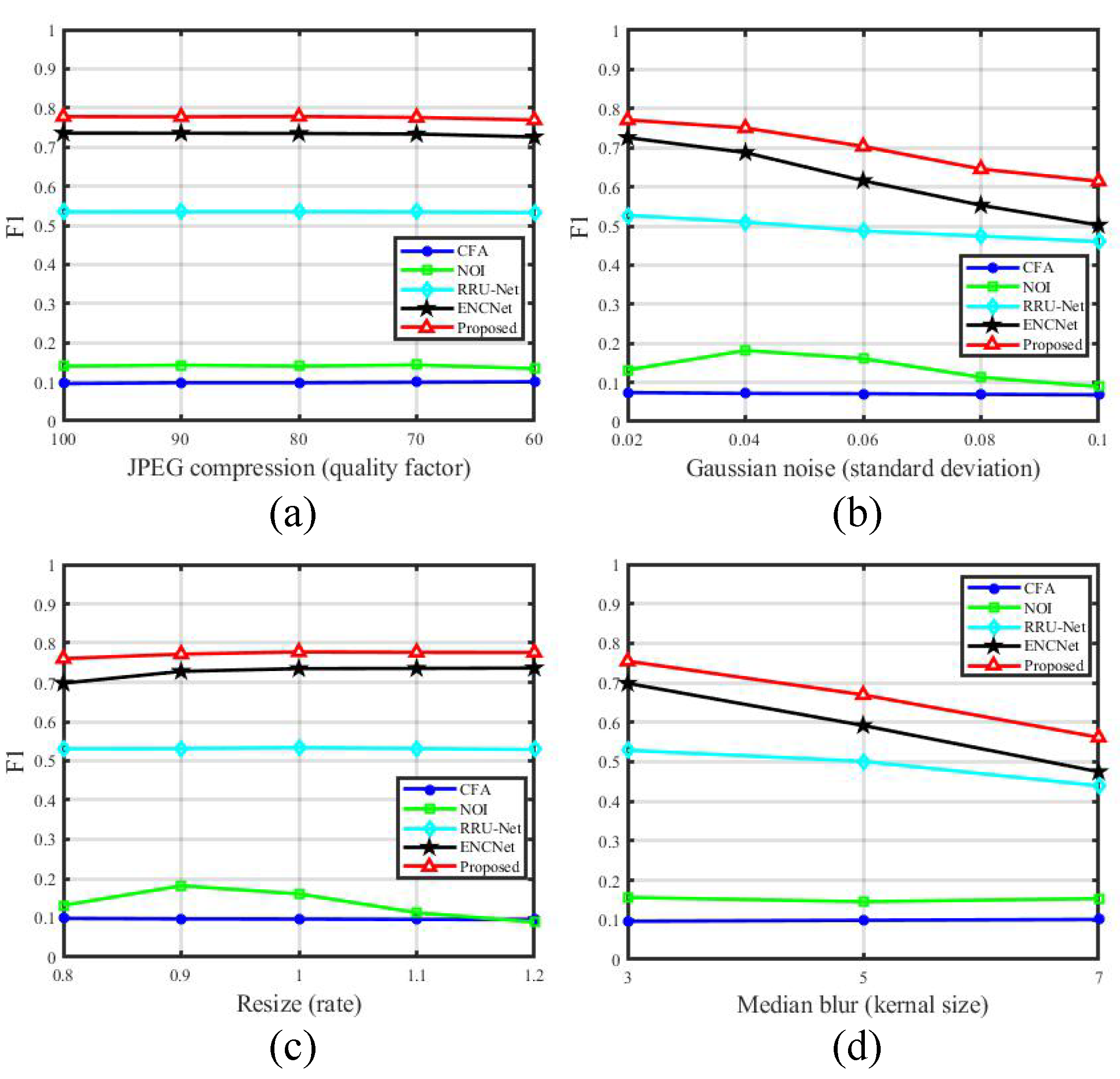
In order to verify the robustness of the proposed method, experiments are carried out and compared with two hand-crafted methods (CFA [
16], NOI [
43]) and two best performing CNN-based methods (RRU-Net [
36], EncNet [
46]) under four common attacks including JPEG compression, Gaussian noise, resize and median blur. The details of attacking parameters are illuminated in
Table 1. The comparative experiment results under different attacks are shown in
Figure 7. Ordinates in
Figure 7 represent the
score. From all subfigures in
Figure 7, we can clearly see that the proposed method has the best localization performance under different attacks.
Figure 7a is the result under JPEG compression. It can be observed that the slopes of all lines are very small, which indicates that these approaches are robust against JPEG compression with quality factors varying from 60 to 100.
Figure 7b exhibits the performance under Gaussian noise. With the increase of standard deviation, the
scores of the proposed MFAN and EncNet [
46] drop down gradually, and EncNet [
46] degrades more rapidly than the proposed method.
Figure 7c is the experiment result under resize. All approaches except for NOI [
43] show small slopes. The localization result under median blur is demonstrated in
Figure 7d. The performances of RRU-Net [
36], EncNet [
46] and the proposed method get worse when the kernel size becomes larger, among which RRU-Net [
36] is less sensitive. The performance of CFA [
16] in the
Figure 7a–d is relatively stable. We consider that this is because CFA [
16] is almost invalid for fake certificate detection, so the interferential influence on CFA [
16] is very limited. From the above analysis, it can be found that the proposed MFAN has better and robust performance.
4.4. Performance on Natural Content Image
In addition, more experiments are conducted in this subsection to evaluate the universality of our method on natural content images. Three image forgery benchmark datasets including CASIA v1.0, CASIA v2.0 and Columbia are used. Some examples of detection results are shown in
Figure 8. From a subjective perspective, the proposed algorithm localizes tampered areas better than the other four detection approaches.
In order to accurately evaluate the effectiveness of algorithms, experimental results compared with CFA [
16], NOI [
43], ManTra-Net [
8], MVSS-Net [
44] and EncNet [
46] on
and
score are listed in
Table 6,
Table 7,
Table 8 and
Table 9.
Table 6,
Table 7,
Table 8 and
Table 9 report the detection performance on CASIA v1.0, CASIA v2.0, Columbia and NC2016, respectively. As illustrated in
Table 6,
Table 7,
Table 8 and
Table 9, it can be observed that the proposed method performs better than others in terms of
and
score. The traces of splicing areas in Columbia dataset are very obvious, and all images are uncompressed. As a result, forgery detection on Columbia is easier than other datasets. To identify tampered regions, CFA [
16] employs CFA artifacts, and NOI [
43] takes advantages of noise consistency. Both of them are based on hand-crafted methods that are hard to generate discriminative features. From the above analysis, it can be clearly seen that the proposed MFAN can detect not only fake certificate images well, but also be effective for natural content images. In the future work, we will consider applying our algorithm to images manipulated from GANs and extend it for detecting manipulation in videos.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}