
Experimental Study and Comparison of Imbalance Ensemble Classifiers with Dynamic Selection Strategy


Abstract
:1. Introduction
2. Imbalanced Datasets and Evaluation Measures
2.1. Sources of Imbalanced Datasets
2.2. Evaluation of Imbalanced Classification
- (I)
- MAvA:where is the accuracy of the i-th class;
- (II)
- G-mean:
- (III)
- Precision:where denotes the number of correctly classified samples in the i-th class, and is the number of instances misclassified into the i-th class;
- (IV)
- F-measure:where , denotes the number of samples in the i-th class which are misclassified into the other class label.
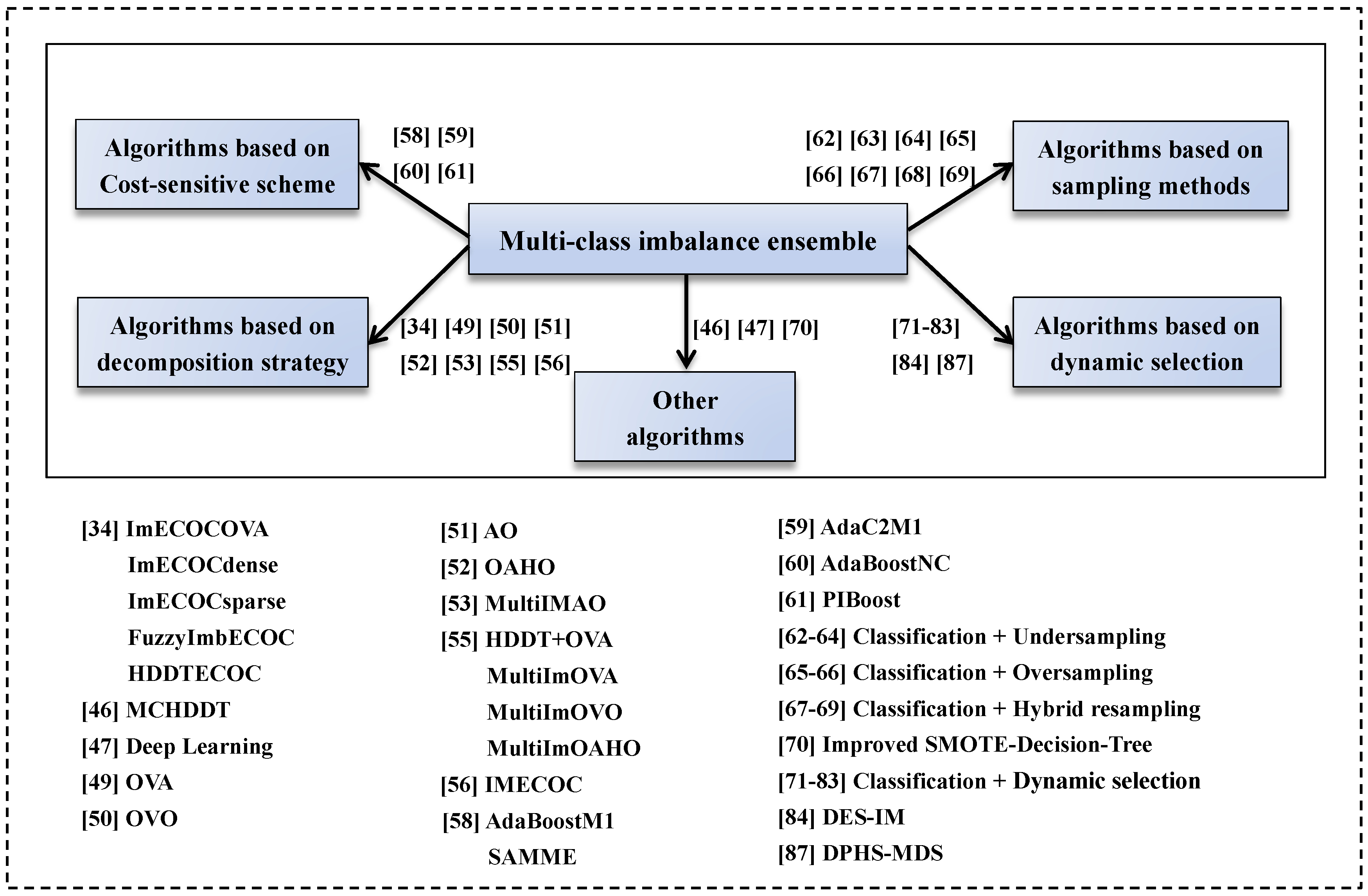
3. Ensemble Approaches for Imbalanced Classification
3.1. Imbalanced Learning Based on Ensemble Classification and a Decomposition Strategy
3.2. Imbalanced Learning Based on Ensemble Classification and Cost-Sensitive Scheme
3.3. Imbalanced Learning Based on Ensemble Classification and Sampling Methods
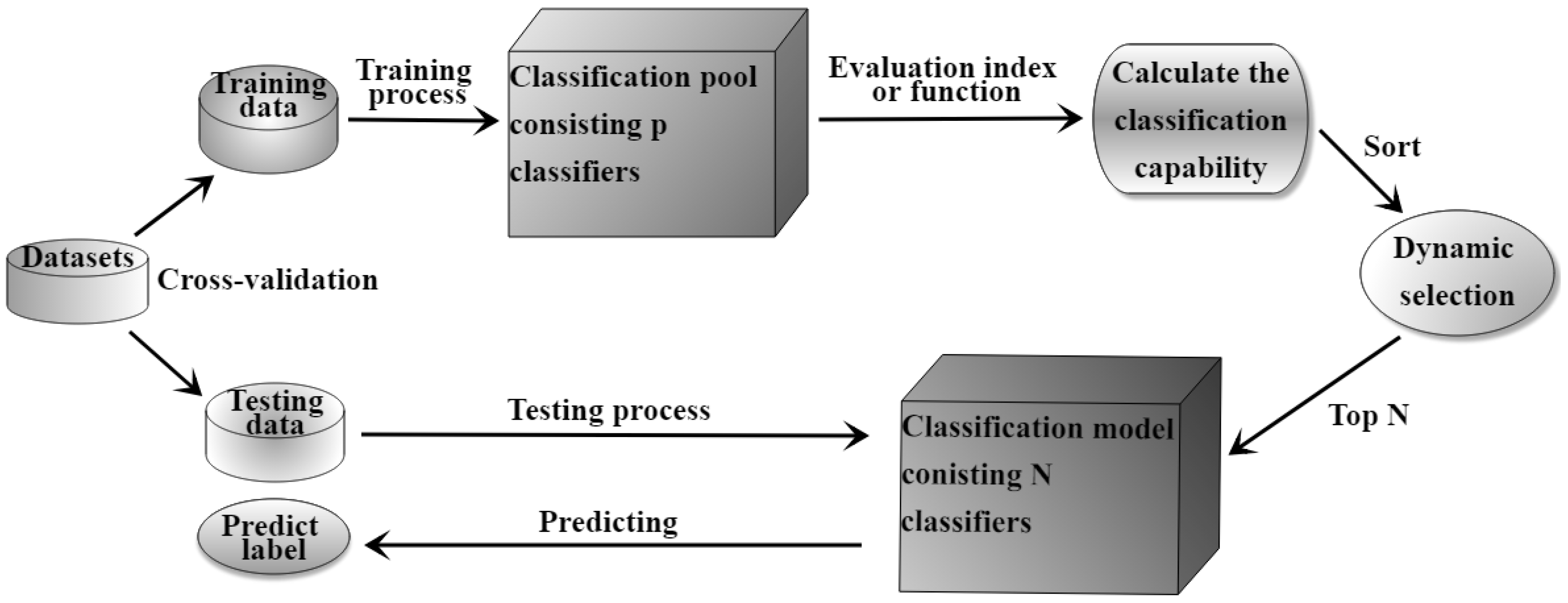
3.4. Imbalanced Learning Based on Ensemble Classification and Dynamic Selection
4. Experimental Comparison of Multi-Class Imbalanced Classifiers by Incorporating Dynamic Selection
4.1. Experimental Procedure
| Algorithm 1: Dynamic AdaBoostNC classifier. |
 |
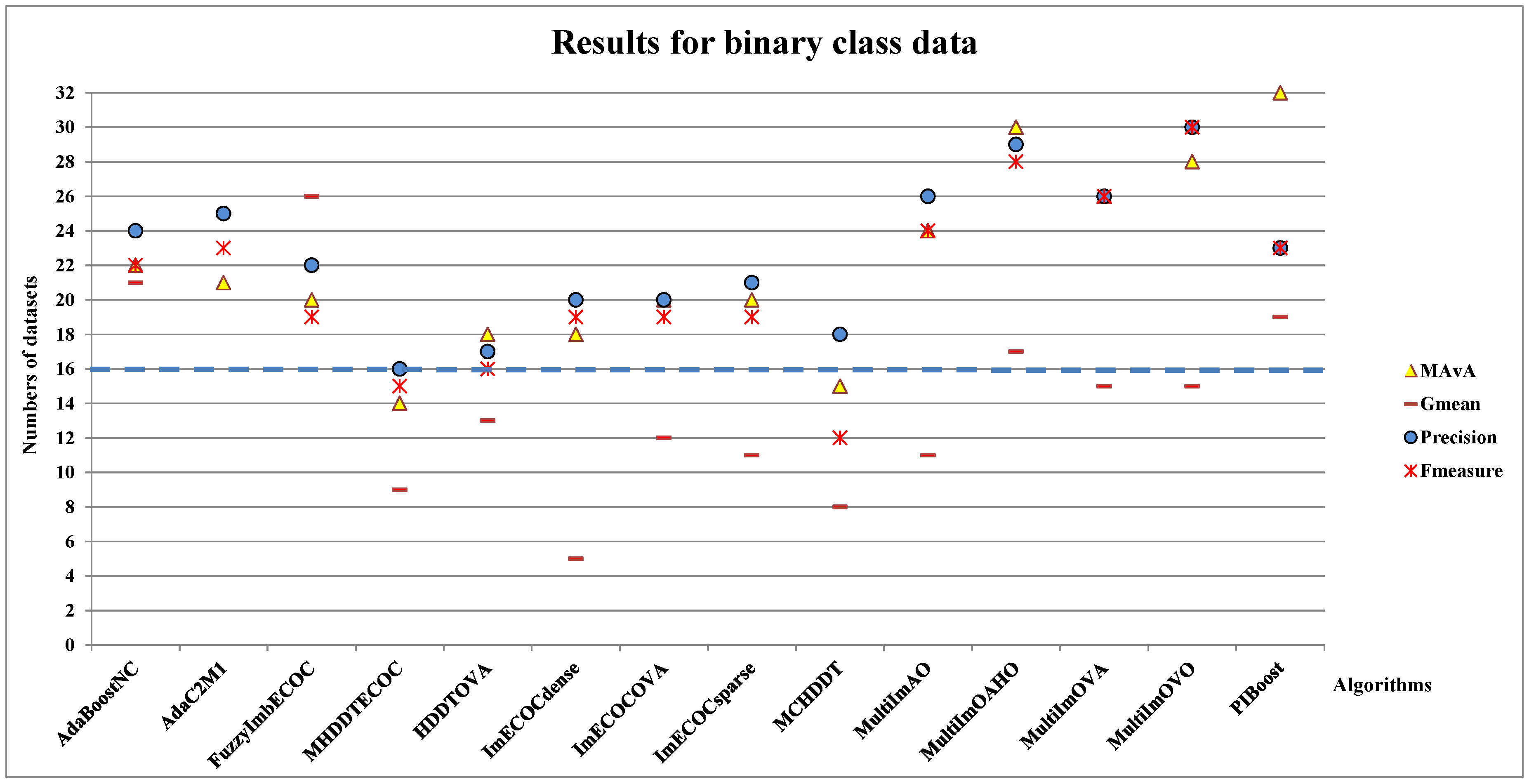
4.2. Experiments Results for Binary Class Datasets
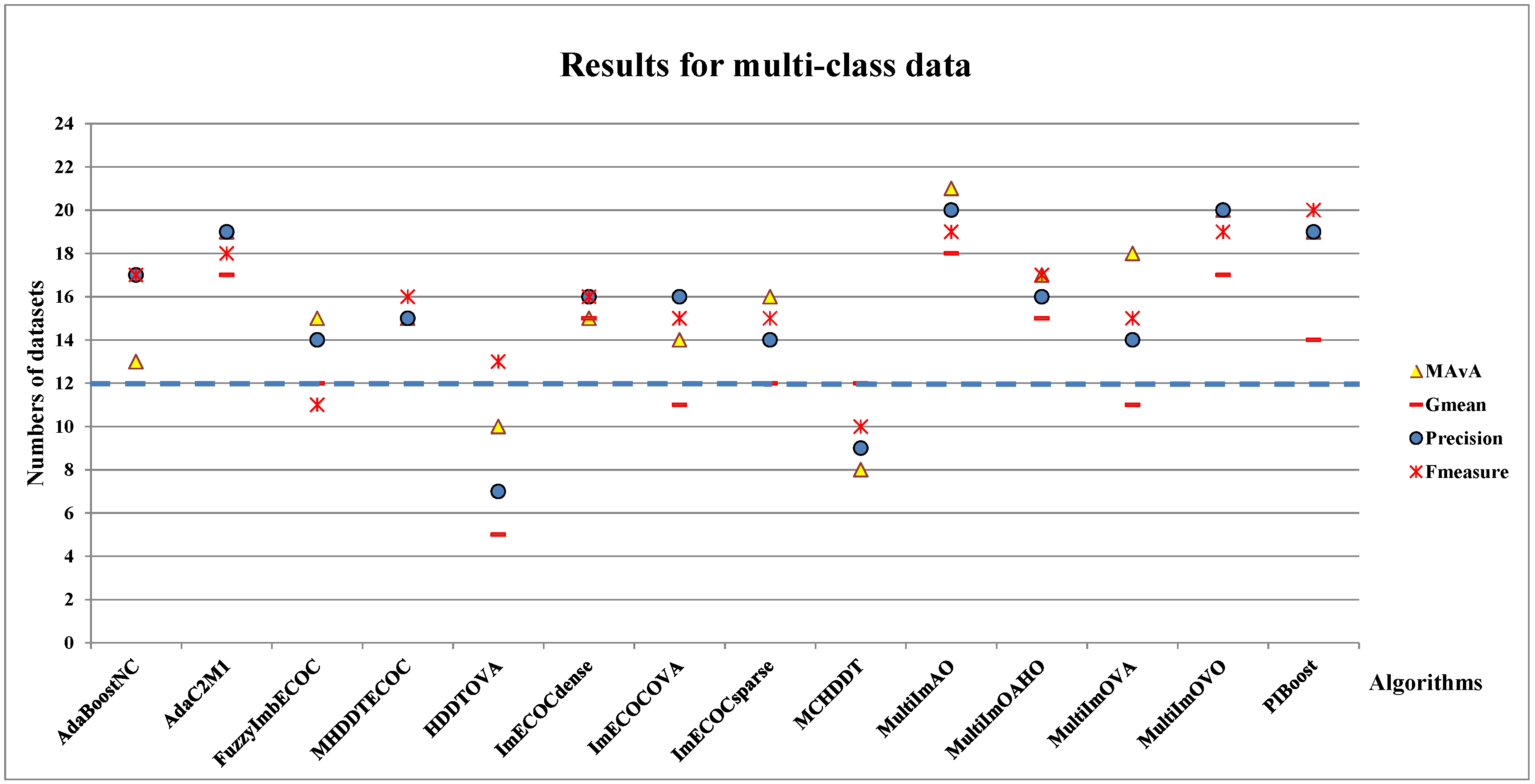
4.3. Experiments Results for Multi-Class Imbalanced Datasets
- (I)
- The effect of dynamic selection for MCHDDT and HDDTOVA are not satisfactory (the points of 3 indicators are below the dashed line), and the performance of the other 12 dynamic selection ensemble classifiers are better than the original algorithms. The MAvA, precision, and F-measure indicators of the improved classifiers have been distinctly improved after dynamic selection. However, due to the extremely low representation of the minority samples, the recognition rate for the minority category may drop sharply, resulting in a lower G-mean value. In fact, 11 of the classifiers demonstrate favorable G-mean results on more than half of the multi-class datasets after syncretizing with dynamic selection. In this regard, it is obvious that dynamic selection models for multi-class imbalanced datasets showed superior characteristics compared to those for binary data.
- (II)
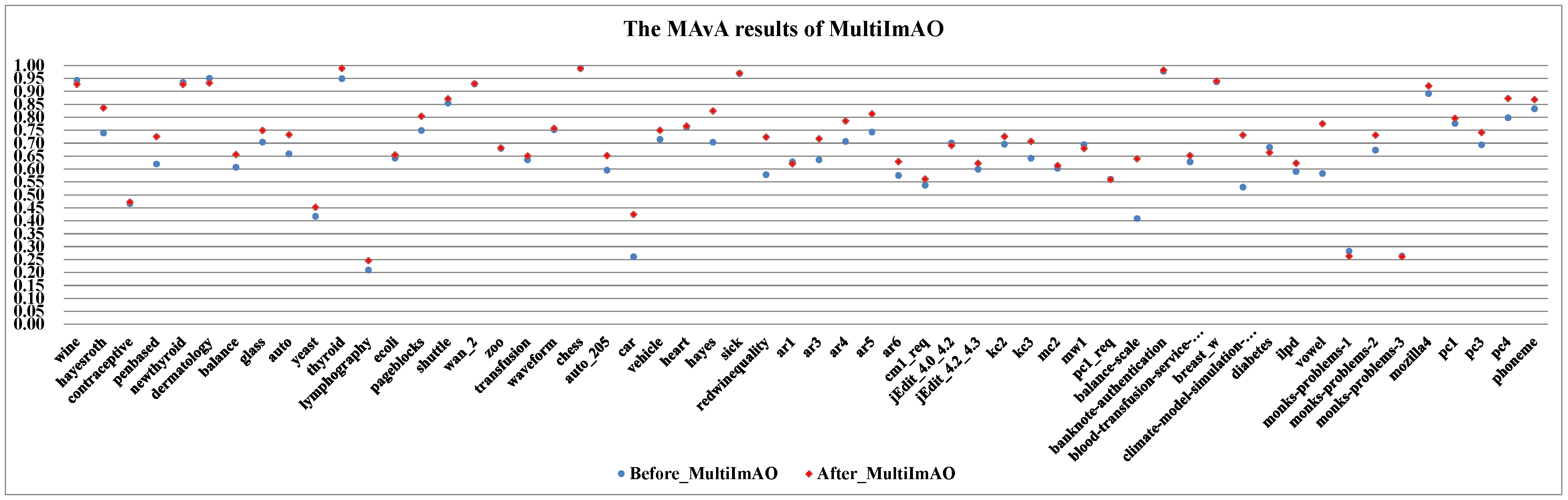
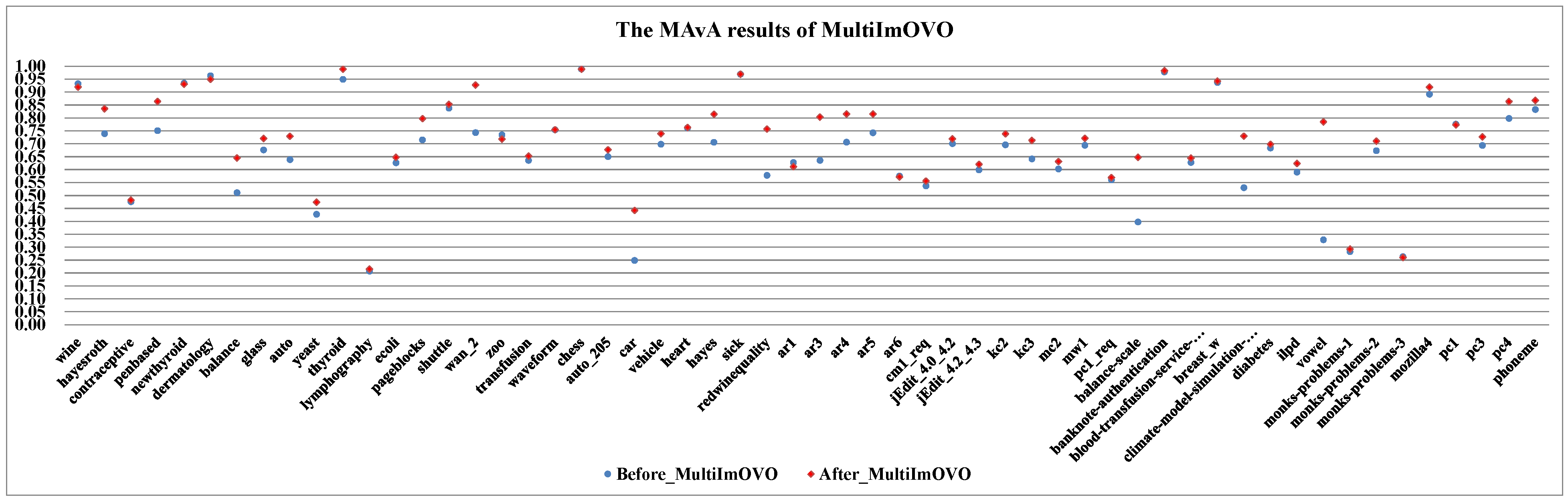
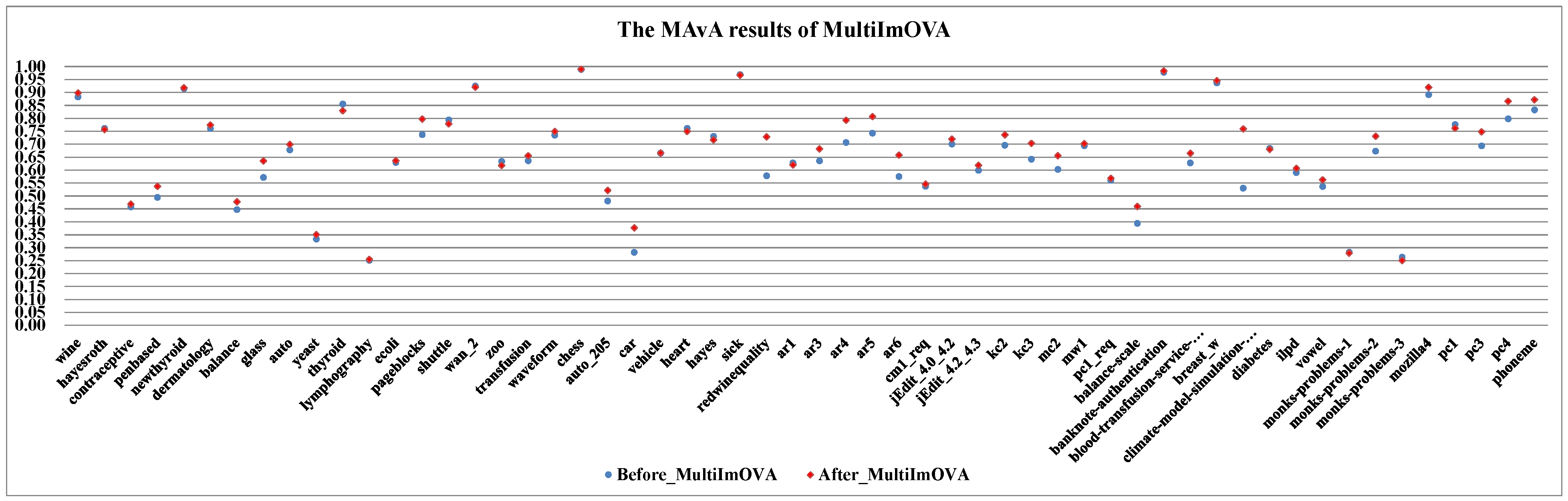
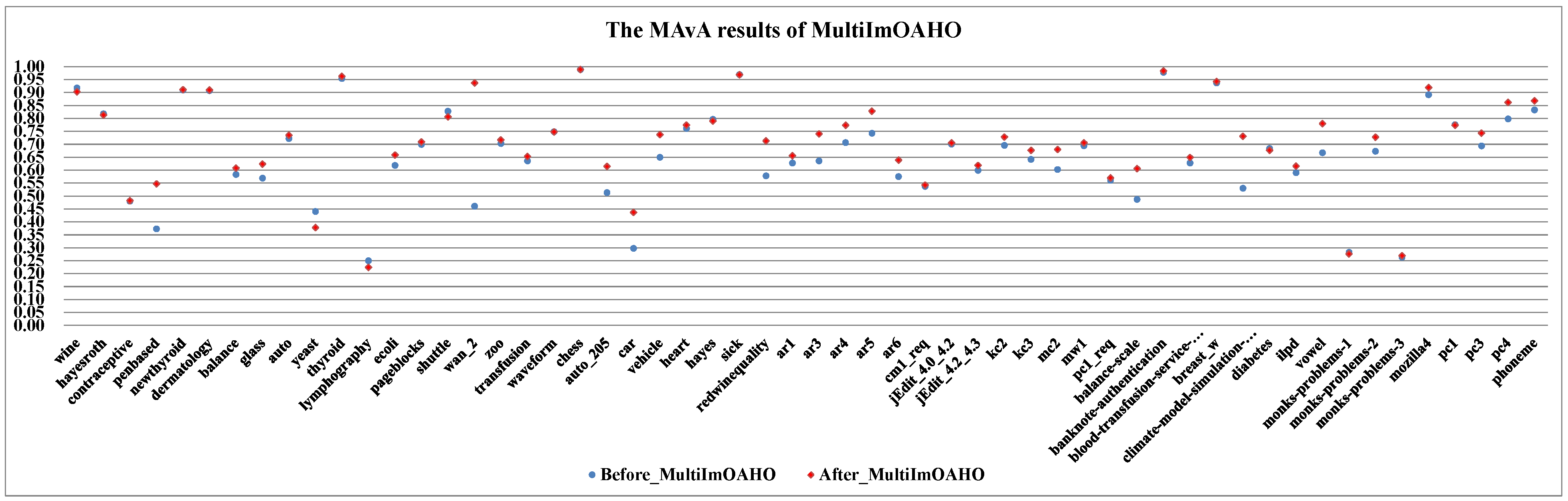
- By combining dynamic selection algorithms, MultiImOVA, MultiImOVO, MultiImOAHO, and MultiImAO have exceptional performance, on which predictive performances are effectively improved compared to using a single classification algorithm, on the whole. Therefore, we further validate the conclusion that data decomposition techniques and dynamic selection have a positive synergy during classification [86]. In particular, the classification MAvA values of the above four algorithms on all 56 datasets are shown in Figure 5, Figure 6, Figure 7 and Figure 8.The results indicate that dynamic selection provides potential strategies for dealing with imbalanced datasets covering binary class and multi-class imbalanced datasets. Moreover, for the same dataset, we have counted the number of classification algorithms with improved classification results after dynamic selection. As shown in Table 4, Table 5, Table 6 and Table 7, regardless of the structure of the data (both binary class and multi-class imbalanced data), the classification algorithms, for the most part, can better classify imbalanced data after employing dynamic selection. The results reveal that incorporating dynamic selection can relieve the impact of imbalanced training data on the classifier performance. Therefore, a dynamic selection ensemble algorithm can be a potential solution for the imbalanced classification problem.
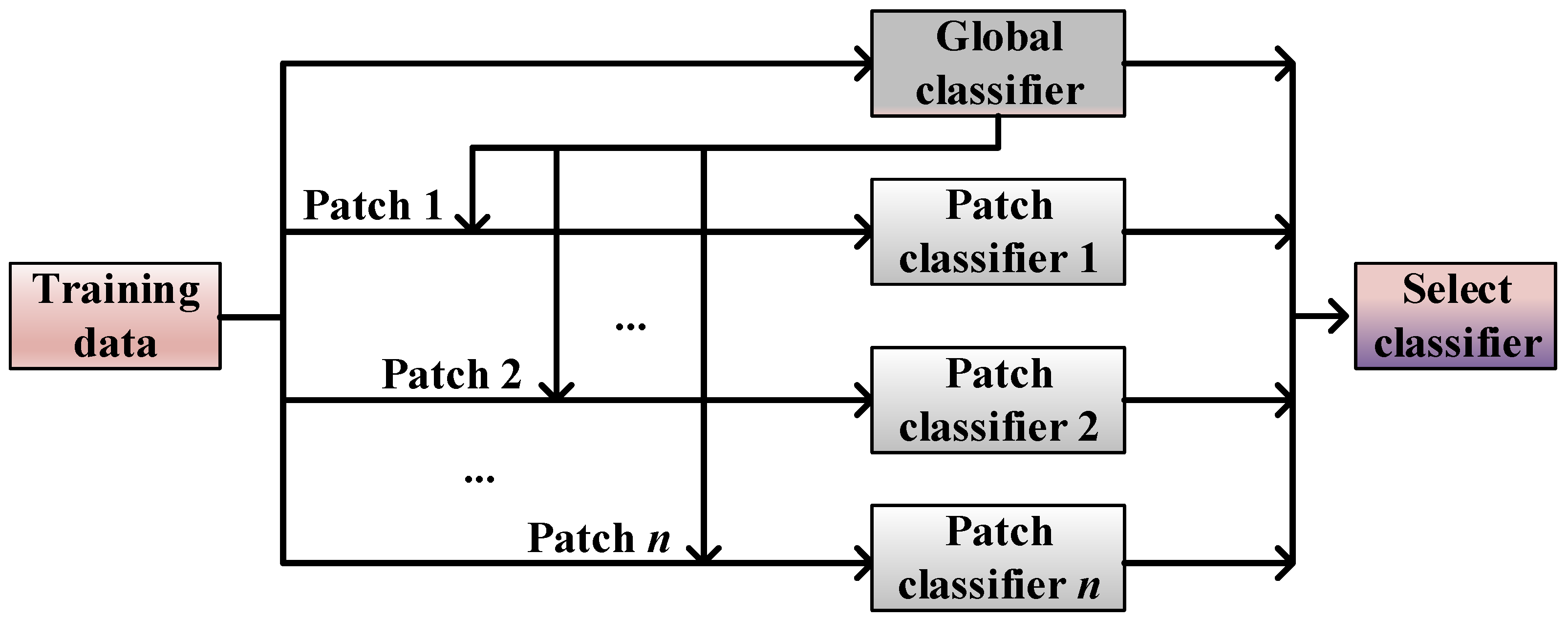
5. Patch-Ensemble Classification for Imbalanced Data
5.1. Patch Learning
- (I)
- Train an initial global model using all the training data;
- (II)
- Select the incorrectly classified training data to construct several local patch models;
- (III)
- The correctly classified training samples are utilized to update the global model.
5.2. Patch-Ensemble Classifier
5.3. Experiments and Analysis
| Algorithm 2: Patch ensemble classifier. |
 |
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fasihi, M.; Nadimi-Shahraki, M.H.; Jannesari, A. Multi-Class cardiovascular diseases diagnosis from electrocardiogram signals using 1-D convolution neural network. In Proceedings of the 2020 IEEE 21st International Conference on Information Reuse and Integration for Data Science (IRI), IEEE Computer Society, Las Vegas, NV, USA, 11–13 August 2020; pp. 372–378. [Google Scholar] [CrossRef]
- Kuo, K.M.; Talley, P.; Kao, Y.; Huang, C.H. A multi-class classification model for supporting the diagnosis of type II diabetes mellitus. PeerJ 2020, 8, 9920. [Google Scholar] [CrossRef] [PubMed]
- Hosni, M.; García-Mateos, G.; Gea, J.M.C.; Idri, A.; Fernández-Alemán, J.L. A mapping study of ensemble classification methods in lung cancer decision support systems. Med Biol. Eng. Comput. 2020, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Elkin, M.E.; Zhu, X. Imbalanced learning for hospital readmission prediction using national readmission database. In Proceedings of the 2020 IEEE International Conference on Knowledge Graph (ICKG), Nanjing, China, 9–11 August 2020; pp. 116–122. [Google Scholar] [CrossRef]
- Piir, G.; Sild, S.; Maran, U. Binary and multi-class classification for androgen receptor agonists, antagonists and binders. Chemosphere 2020, 128313. [Google Scholar] [CrossRef] [PubMed]
- Sah, A.K.; Mishra, A.; Reddy, U.S. Machine learning approach for feature interpretation and classification of genetic mutations leading to tumor and cancer. In Advances in Electrical and Computer Technologies; Springer: Berlin/Heidelberg, Germany, 2020; pp. 387–395. [Google Scholar] [CrossRef]
- García-Mendoza, C.V.; Gambino, O.J.; Villarreal-Cervantes, M.G.; Calvo, H. Evolutionary optimization of ensemble learning to determine sentiment polarity in an unbalanced multiclass corpus. Entropy 2020, 22, 1020. [Google Scholar] [CrossRef] [PubMed]
- Bargshady, G.; Zhou, X.; Deo, R.C.; Soar, J.; Whittaker, F.; Wang, H. Ensemble neural network approach detecting pain intensity from facial expressions. Artif. Intell. Med. 2020, 109, 101954. [Google Scholar] [CrossRef]
- Yilmaz, I.; Masum, R.; Siraj, A. Addressing imbalanced data problem with generative adversarial network for intrusion detection. In Proceedings of the 2020 IEEE 21st International Conference on Information Reuse and Integration for Data Science (IRI), Las Vegas, NV, USA, 11–13 August 2020; pp. 25–30. [Google Scholar] [CrossRef]
- Ducharlet, K.; Travé-Massuyès, L.; Lann, M.V.L.; Miloudi, Y. A multi-phase iterative approach for anomaly detection and its agnostic evaluation. In International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2020; pp. 505–517. [Google Scholar] [CrossRef]
- Shi, Z. Improving k-nearest neighbors algorithm for imbalanced data classification. IOP Conf. Ser. Mater. Sci. Eng. 2020, 719, 12072. [Google Scholar] [CrossRef]
- Wang, C.; Yang, Y. Nearest neighbor with double neighborhoods algorithm for imbalanced classification. Int. J. Appl. Math. 2020, 50, 1–13. Available online: http://www.iaeng.org/IJAM/issues_v50/issue_1/IJAM_50_1_21.pdf (accessed on 3 November 2020).
- Fu, G.H.; Wu, Y.J.; Zong, M.J.; Yi, L.Z. Feature selection and classification by minimizing overlap degree for class-imbalanced data in metabolomics. Chemom. Intell. Lab. Syst. 2020, 196, 103906. [Google Scholar] [CrossRef]
- Peng, Y.; Li, C.; Wang, K.; Gao, Z.; Yu, R. Examining imbalanced classification algorithms in predicting real-time traffic crash risk. Accid. Anal. Prev. 2020, 144, 105610. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Zhang, X.; Chen, H.; Zhou, Y.; Cheng, F. A sintering state recognition eramework to integrate prior knowledge and hidden information considering class imbalance. IEEE Trans. Ind. Electron. 2020, 1. [Google Scholar] [CrossRef]
- Charte, F.; Rivera, A.J.; del Jesus, M.J.; Herrera, F. Addressing imbalance in multilabel classification: Measures and random resampling algorithms. Neurocomputing 2015, 163, 3–16. [Google Scholar] [CrossRef]
- Tao, X.; Li, Q.; Ren, C.; Guo, W.; He, Q.; Liu, R.; Zou, J. Affinity and class probability-based fuzzy support vector machine for imbalanced data sets. Neural Netw. 2020, 122, 289–307. [Google Scholar] [CrossRef]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. 2011, 42, 463–484. [Google Scholar] [CrossRef]
- Herrera, F.; Charte, F.; Rivera, A.J.; del Jesus, M.J. Ensemble-based classifiers. In Multilabel Classification; Springer: Berlin/Heidelberg, Germany, 2016; pp. 101–113. [Google Scholar] [CrossRef]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 2020, 14, 1–18. [Google Scholar] [CrossRef]
- Vranjković, V.S.; Struharik, R.J.; Novak, L.A. Hardware acceleration of homogeneous and heterogeneous ensemble classifiers. Microprocess. Microsyst. 2015, 39, 782–795. [Google Scholar] [CrossRef]
- Guan, H.; Zhang, Y.; Cheng, H.D.; Tang, X. Bounded–abstaining classification for breast tumors in imbalanced ultrasound images. Int. J. Appl. Math. Comput. Sci. 2020, 30, 325–336. [Google Scholar] [CrossRef]
- Sun, J.; Li, H.; Fujita, H.; Fu, B.; Ai, W. Class-imbalanced dynamic financial distress prediction based on Adaboost-SVM ensemble combined with SMOTE and time weighting. Inf. Fusion 2020, 54, 128–144. [Google Scholar] [CrossRef]
- Jiang, X.; Ge, Z. Data augmentation classifier for imbalanced fault classification. IEEE Trans. Autom. Sci. Eng. 2020, 1–12. [Google Scholar] [CrossRef]
- Korkmaz, S. Deep learning-based imbalanced data classification for drug discovery. J. Chem. Inf. Model. 2020, 60, 4180–4190. [Google Scholar] [CrossRef]
- Ho, T.K.; Hull, J.J.; Srihari, S.N. Decision combination in multiple classifier systems. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 66–75. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.T.; Dang, M.T.; Baghel, V.A.; Luong, A.V.; McCall, J.; Liew, A.W. Evolving interval-based representation for multiple classifier fusion. Knowl.-Based Syst. 2020, 106034. [Google Scholar] [CrossRef]
- Yuan, P.; Wang, B.; Mao, Z. Using multiple classifier behavior to develop a dynamic outlier ensemble. Int. J. Mach. Learn. Cybern. 2020, 1–13. [Google Scholar] [CrossRef]
- Huang, C.; Li, Y.; Chen, C.L.; Tang, X. Deep imbalanced learning for face recognition and attribute prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2781–2794. [Google Scholar] [CrossRef] [Green Version]
- Ma, S.; Xu, J.; Zhang, C. Automatic identification of cited text spans: A multi-classifier approach over imbalanced dataset. Scientometrics 2018, 116, 1303–1330. [Google Scholar] [CrossRef]
- Kubat, M.; Holte, R.; Matwin, S. Learning when negative examples abound. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 1997; pp. 146–153. [Google Scholar] [CrossRef] [Green Version]
- Hripcsak, G.; Rothschild, A.S. Agreement, the f-measure, and reliability in information retrieval. J. Am. Med. Inform. Assoc. 2005, 12, 296–298. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Bi, J.; Xu, S.; Ramentol, E.; Fan, G.; Qiao, B.; Fujita, H. Multi-imbalance: An open-source software for multi-class imbalance learning. Knowl.-Based Syst. 2019, 174, 137–143. [Google Scholar] [CrossRef]
- Vong, C.M.; Du, J. Accurate and efficient sequential ensemble learning for highly imbalanced multi-class data. Neural Netw. 2020, 128, 268–278. [Google Scholar] [CrossRef]
- Ramentol, E.; Vluymans, S.; Verbiest, N.; Caballero, Y.; Bello, R.; Cornelis, C.; Herrera, F. IFROWANN: Imbalanced fuzzy-rough ordered weighted average nearest neighbor classification. IEEE Trans. Fuzzy Syst. 2014, 23, 1622–1637. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G. Semi-supervised learning algorithm based on linear lie group for imbalanced multi-class classification. Neural Process. Lett. 2020, 52, 1–21. [Google Scholar] [CrossRef]
- Zhang, Z.L.; Luo, X.G.; González, S.; García, S.; Herrera, F. DRCW-ASEG: One-versus-one distance-based relative competence weighting with adaptive synthetic example generation for multi-class imbalanced datasets. Neurocomputing 2018, 285, 176–187. [Google Scholar] [CrossRef]
- Hoens, T.R.; Qian, Q.; Chawla, N.V.; Zhou, Z.H. Building decision trees for the multi-class imbalance problem. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2012; pp. 122–134. [Google Scholar] [CrossRef] [Green Version]
- Duan, H.; Wei, Y.; Liu, P.; Yin, H. A novel ensemble framework based on k-means and resampling for imbalanced data. Appl. Sci. 2020, 10, 1684. [Google Scholar] [CrossRef] [Green Version]
- Kunakorntum, I.; Hinthong, W.; Phunchongharn, P. A synthetic minority based on probabilistic distribution (SyMProD) oversampling for imbalanced datasets. IEEE Access 2020, 8, 114692–114704. [Google Scholar] [CrossRef]
- Guo, H.; Zhou, J.; Wu, C.A. Ensemble learning via constraint projection and undersampling technique for class-imbalance problem. Soft Comput. 2019, 1–17. [Google Scholar] [CrossRef]
- Abdi, L.; Hashemi, S. To combat multi-class imbalanced problems by means of over-sampling techniques. IEEE Trans. Knowl. Data Eng. 2015, 28, 238–251. [Google Scholar] [CrossRef]
- Li, Y.J.; Guo, H.X.; Liu, X.; Li, Y.; Li, J.L. Adapted ensemble classification algorithm based on multiple classifier system and feature selection for classifying multi-class imbalanced data. Knowl.-Based Syst. 2016, 94, 88–104. [Google Scholar] [CrossRef]
- Sahare, M.; Gupta, H. A review of multi-class classification for imbalanced data. Int. J. Adv. Comput. Res. 2012, 2, 160–164. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.300.8687&rep=rep1&type=pdf (accessed on 7 February 2020).
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Dietterich, T.G.; Bakiri, G. Error-correcting output codes: A general method for improving multiclass inductive learning programs. In The Ninth National Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 1991; pp. 572–577. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.53.9478&rep=rep1&type=pdf (accessed on 10 March 2020).
- Rifkin, R.; Klautau, A. In defense of one-vs-all classification. J. Mach. Learn. Res. 2004, 5, 101–141. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R. Classification by pairwise coupling. Adv. Neural Inf. Process. Syst. 1998, 507–513. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.7.572&rep=rep1&type=pdf (accessed on 15 January 2020). [CrossRef]
- Garcia-Pedrajas, N.; Ortiz-Boyer, D. Improving multiclass pattern recognition by the combination of two strategies. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1001–1006. [Google Scholar] [CrossRef] [PubMed]
- Murphey, Y.L.; Wang, H.; Ou, G.; Feldkamp, L.A. OAHO: An effective algorithm for multi-class learning from imbalanced data. In Proceedings of the 2007 International Joint Conference on Neural Networks, Orlando, FL, USA, 12–17 August 2007; pp. 406–411. [Google Scholar] [CrossRef]
- Ghanem, A.S.; Venkatesh, S.; West, G. Multi-class pattern classification in imbalanced data. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2881–2884. [Google Scholar] [CrossRef] [Green Version]
- Ghanem, A.S.; Venkatesh, S.; West, G. Learning in imbalanced relational data. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Bi, J.; Zhang, C. An empirical comparison on state-of-the-art multi-class imbalance learning algorithms and a new diversified ensemble learning scheme. Knowl.-Based Syst. 2018, 158, 81–93. [Google Scholar] [CrossRef]
- Liu, X.Y.; Li, Q.Q.; Zhou, Z.H. Learning imbalanced multi-class data with optimal dichotomy weights. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; pp. 478–487. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Zhu, Y. A composite cost-sensitive neural network for imbalanced classification. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 7264–7268. [Google Scholar] [CrossRef]
- Hastie, T.; Rosset, S.; Zhu, J.; Zou, H. Multi-class adaboost. Stat. Its Interface 2009, 2, 349–360. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Kamel, M.S.; Wang, Y. Boosting for learning multiple classes with imbalanced class distribution. In Proceedings of the Sixth International Conference on Data Mining (ICDM’06), Hong Kong, China, 18–22 December 2006; pp. 592–602. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Chen, H.; Yao, X. Negative correlation learning for classification ensembles. In Proceedings of the The 2010 International Joint Conference on Neural Networks, Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar] [CrossRef]
- Fernández-Baldera, A.; Baumela, L. Multi-class boosting with asymmetric binary weak-learners. Pattern Recognit. 2014, 47, 2080–2090. [Google Scholar] [CrossRef]
- Seiffert, C.; Khoshgoftaar, T.M.; Hulse, J.V.; Napolitano, A. RUSBoost: A hybrid approach to alleviating class imbalance. IEEE Trans. Syst. 2010, 40, 185–197. [Google Scholar] [CrossRef]
- Galar, M.; Fernández, A.; Barrenechea, E.; Herrera, F. EUSBoost: Enhancing ensembles for highly imbalanced data-sets by evolutionary undersampling. Pattern Recognit. 2013, 46, 3460–3471. [Google Scholar] [CrossRef]
- Luo, R.S.; Dian, S.Y.; Wang, C.; Cheng, P.; Tang, Z.D.; Yu, Y.M.; Wang, S.X. Bagging of xgboost classifiers with random under-sampling and tomek link for noisy label-imbalanced data. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2018; p. 012004. [Google Scholar] [CrossRef] [Green Version]
- Ramentol, E.; Caballero, Y.; Bello, R.; Herrera, F. SMOTE-RSB*: A hybrid preprocessing approach based on oversampling and undersampling for high imbalanced data-sets using SMOTE and rough sets theory. Knowl. Inf. Syst. 2012, 33, 245–265. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F.; Last, F. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE. Inf. Sci. 2018, 465, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Cheung, Y.M.; Tang, Y.Y. Hybrid sampling with bagging for class imbalance learning. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2016; pp. 14–26. [Google Scholar] [CrossRef]
- Ahmed, S.; Mahbub, A.; Rayhan, F.; Jani, R.; Shatabda, S.; Farid, D.M. Hybrid methods for class imbalance learning employing bagging with sampling techniques. In Proceedings of the 2017 2nd International Conference on Computational Systems and Information Technology for Sustainable Solution (CSITSS), Bengaluru, India, 21–23 December 2017; pp. 1–5. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE World Congress on Computational Intelligence, Bengaluru, India, 21–23 December 2017; pp. 1322–1328. [Google Scholar] [CrossRef] [Green Version]
- Feng, W.; Dauphin, G.; Huang, W.; Quan, Y.; Bao, W.; Wu, M.; Li, Q. Dynamic synthetic minority over-sampling technique-based rotation forest for the classification of imbalanced hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2159–2169. [Google Scholar] [CrossRef]
- Roy, A.; Cruz, R.M.; Sabourin, R.; Cavalcanti, G.D. A study on combining dynamic selection and data preprocessing for imbalance learning. Neurocomputing 2018, 286, 179–192. [Google Scholar] [CrossRef]
- Cruz, R.M.; Souza, M.A.; Sabourin, R.; Cavalcanti, G.D. Dynamic ensemble selection and data preprocessing for multi-class imbalance learning. Int. J. Pattern Recognit. Artif. Intell. 2019, 33, 1940009. [Google Scholar] [CrossRef] [Green Version]
- Britto, A.S., Jr.; Sabourin, R.; Oliveira, L.E. Dynamic selection of classifiers–A comprehensive review. Pattern Recognit. 2014, 47, 3665–3680. [Google Scholar] [CrossRef]
- Du, H.; Zhang, Y. Network anomaly detection based on selective ensemble algorithm. J. Supercomput. 2020, 1–22. [Google Scholar] [CrossRef]
- Cruz, R.M.; Sabourin, R.; Cavalcanti, G.D. Dynamic classifier selection: Recent advances and perspectives. Inf. Fusion 2018, 41, 195–216. [Google Scholar] [CrossRef]
- Gao, X.; Ren, B.; Zhang, H.; Sun, B.; Li, J.; Xu, J.; He, Y.; Li, K. An ensemble imbalanced classification method based on model dynamic selection driven by data partition hybrid sampling. Expert Syst. Appl. 2020, 160, 113660. [Google Scholar] [CrossRef]
- Cruz, R.M.; Oliveira, D.V.; Cavalcanti, G.D.; Sabourin, R. FIRE-DES++: Enhanced online pruning of base classifiers for dynamic ensemble selection. Pattern Recognit. 2019, 85, 149–160. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, D.V.; Cavalcanti, G.D.; Sabourin, R. Online pruning of base classifiers for dynamic ensemble selection. Pattern Recognit. 2017, 72, 44–58. [Google Scholar] [CrossRef]
- Oliveira, D.V.; Cavalcanti, G.D.; Porpino, T.N.; Cruz, R.M.; Sabourin, R. K-nearest oracles borderline dynamic classifier ensemble selection. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Cruz, R.M.; Hafemann, L.G.; Sabourin, R.; Cavalcanti, G.D. DESlib: A dynamic ensemble selection library in Python. J. Mach. Learn. Res. 2020, 21, 1–5. Available online: https://www.jmlr.org/papers/volume21/18-144/18-144.pdf (accessed on 20 June 2020).
- Junior, L.M.; Nardini, F.M.; Renso, C.; Trani, R.; Macedo, J.A. A novel approach to define the local region of dynamic selection techniques in imbalanced credit scoring problems. Expert Syst. Appl. 2020, 152, 113351. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Luong, A.V.; Dang, M.T.; Liew, A.W.C.; McCall, J. Ensemble selection based on classifier’s confidence in prediction. Pattern Recognit. 2020, 100, 107104. [Google Scholar] [CrossRef]
- Pinagé, F.; dos Santos, E.M.; Gama, J. A drift detection method based on dynamic classifier selection. Data Min. Knowl. Discov. 2020, 34, 50–74. [Google Scholar] [CrossRef]
- García, S.; Zhang, Z.L.; Altalhi, A.; Alshomrani, S.; Herrera, F. Dynamic ensemble selection for multi-class imbalanced datasets. Inf. Sci. 2018, 445, 22–37. [Google Scholar] [CrossRef]
- Lin, C.; Chen, W.; Qiu, C.; Wu, Y.; Krishnan, S.; Zou, Q. LibD3C: Ensemble classifiers with a clustering and dynamic selection strategy. Neurocomputing 2014, 123, 424–435. [Google Scholar] [CrossRef]
- Mendialdua, I.; Martínez-Otzeta, J.M.; Rodriguez, I.; Ruiz-Vazquez, T.; Sierra, B. Dynamic selection of the best base classifier in one versus one. Knowl.-Based Syst. 2015, 85, 298–306. [Google Scholar] [CrossRef]
- Woloszynski, T.; Kurzynski, M. A probabilistic model of classifier competence for dynamic ensemble selection. Pattern Recognit. 2011, 44, 2656–2668. [Google Scholar] [CrossRef]
- Cruz, R.M.; Sabourin, R.; Cavalcanti, G.D. Prototype selection for dynamic classifier and ensemble selection. Neural Comput. Appl. 2018, 29, 447–457. [Google Scholar] [CrossRef]
- Brun, A.L.; Britto, A.S.; Oliveira, L.S.; Enembreck, F.; Sabourin, R. Contribution of data complexity features on dynamic classifier selection. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 4396–4403. [Google Scholar] [CrossRef]
- Cruz, R.M.; Sabourin, R.; Cavalcanti, G.D.; Ren, T.I. META-DES: A dynamic ensemble selection framework using meta-learning. Pattern Recognit. 2015, 48, 1925–1935. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.R.; Mendel, J. Patch learning. IEEE Trans. Fuzzy Syst. 2019, 28, 1996–2008. [Google Scholar] [CrossRef]
- Scholkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Source |
|---|---|
| UCI | https://archive.ics.uci.edu/ml/index.php (accessed on 9 November 2019) |
| OpenML | https://www.openml.org (accessed on 20 March 2020) |
| KEEL | https://sci2s.ugr.es/keel/imbalanced.php (accessed on 7 January 2020) |
| DefectPrediction | http://tunedit.org/repo/PROMISE/DefectPrediction (accessed on 10 April 2020) |
| Datasets | Number of Data | Number of Attribute | Continuous Attribute | Discrete Attribute | Classes Distribution | Classes | Imbalance Ratio |
|---|---|---|---|---|---|---|---|
| transfusion | 748 | 4 | 4 | 0 | 178, 570 | 2 | 3.202 |
| heart | 270 | 13 | 13 | 0 | 150, 120 | 2 | 1.250 |
| chess | 3196 | 35 | 35 | 0 | 1669, 1527 | 2 | 1.093 |
| sick | 2800 | 27 | 27 | 0 | 2629, 171 | 2 | 15.374 |
| redwinequality | 691 | 11 | 11 | 0 | 681, 10 | 2 | 68.100 |
| ar1 | 121 | 29 | 9 | 20 | 112, 9 | 2 | 12.444 |
| ar3 | 63 | 29 | 9 | 20 | 55, 8 | 2 | 6.875 |
| ar4 | 107 | 29 | 9 | 20 | 87, 20 | 2 | 4.350 |
| ar5 | 36 | 29 | 9 | 20 | 28, 8 | 2 | 3.500 |
| ar6 | 101 | 29 | 9 | 20 | 86, 15 | 2 | 5.733 |
| cm1_req | 89 | 8 | 0 | 8 | 69, 20 | 2 | 3.450 |
| jEdit_4.0_4.2 | 274 | 8 | 0 | 8 | 140, 134 | 2 | 1.045 |
| jEdit_4.2_4.3 | 369 | 8 | 0 | 8 | 165, 204 | 2 | 1.236 |
| kc2 | 522 | 21 | 7 | 14 | 415, 107 | 2 | 3.879 |
| kc3 | 458 | 39 | 14 | 25 | 415, 43 | 2 | 9.651 |
| mc2 | 161 | 39 | 15 | 24 | 109, 52 | 2 | 2.096 |
| mw1 | 403 | 37 | 13 | 24 | 372, 31 | 2 | 12.000 |
| pc1_req | 320 | 8 | 0 | 8 | 213, 107 | 2 | 1.991 |
| banknote-authentication | 1372 | 4 | 4 | 0 | 762, 610 | 2 | 1.249 |
| blood-transfusion-service-center | 748 | 4 | 0 | 4 | 570, 178 | 2 | 3.202 |
| breast_w | 699 | 9 | 0 | 9 | 458, 241 | 2 | 1.900 |
| climate-model-simulation-crashes | 540 | 20 | 17 | 3 | 46, 494 | 2 | 10.739 |
| diabetes | 768 | 8 | 2 | 6 | 268, 500 | 2 | 1.866 |
| ilpd | 583 | 9 | 5 | 4 | 416, 167 | 2 | 2.491 |
| monks-problems1 | 556 | 6 | 0 | 6 | 272, 284 | 2 | 1.044 |
| monks-problems2 | 601 | 6 | 0 | 6 | 300, 301 | 2 | 1.003 |
| monks-problems3 | 554 | 6 | 0 | 6 | 275, 279 | 2 | 1.015 |
| mozilla4 | 15,545 | 4 | 0 | 4 | 10,437, 5108 | 2 | 2.043 |
| pc1 | 1109 | 21 | 17 | 4 | 77, 1032 | 2 | 13.403 |
| pc3 | 1563 | 37 | 14 | 23 | 160, 1403 | 2 | 8.769 |
| pc4 | 1458 | 37 | 12 | 25 | 178, 1280 | 2 | 7.191 |
| phoneme | 5404 | 5 | 5 | 0 | 3818, 1586 | 2 | 2.407 |
| Datasets | Number of Data | Number of Attribute | Continuous Attribute | Discrete Attribute | Classes Distribution | Classes | Imbalance Ratio |
|---|---|---|---|---|---|---|---|
| wine | 178 | 13 | 11 | 2 | 59, 71, 48 | 3 | 1.479 |
| hayesroth | 132 | 4 | 0 | 4 | 51, 51, 30 | 3 | 1.700 |
| contraceptive | 1473 | 9 | 0 | 9 | 629, 333, 511 | 3 | 1.889 |
| penbased | 1100 | 16 | 0 | 16 | 114, 114, 106, 114, 106, 105, 115, 105, 106, 115 | 10 | 1.095 |
| newthyroid | 215 | 5 | 4 | 1 | 150, 35, 30 | 3 | 5.000 |
| dermatology | 366 | 34 | 0 | 34 | 112, 61, 72, 49, 52, 20 | 6 | 5.600 |
| balance | 625 | 4 | 0 | 4 | 49, 288, 288 | 3 | 5.878 |
| glass | 214 | 9 | 9 | 0 | 70, 76, 17, 13, 9, 29 | 6 | 8.444 |
| auto | 406 | 7 | 1 | 6 | 254, 73, 79 | 3 | 3.479 |
| yeast | 1484 | 9 | 9 | 0 | 288, 480, 626, 35, 30, 20, 5 | 7 | 125.200 |
| thyroid | 720 | 21 | 6 | 15 | 17, 37, 666 | 3 | 39.176 |
| lymphography | 148 | 18 | 0 | 18 | 57, 37, 18, 10, 8, 8, 8, 2 | 8 | 28.500 |
| ecoli | 336 | 7 | 7 | 0 | 143, 77, 2, 2, 35, 20, 5, 52 | 8 | 71.500 |
| pageblocks | 548 | 10 | 4 | 6 | 492, 33, 3, 8, 12 | 5 | 164.000 |
| shuttle | 2175 | 9 | 0 | 9 | 1706, 2, 6, 338, 123 | 5 | 853.000 |
| wan_2 | 750 | 2 | 2 | 0 | 100, 150, 250, 250 | 4 | 2.500 |
| zoo | 101 | 16 | 0 | 16 | 41, 20, 5, 13, 4, 8, 10 | 7 | 10.250 |
| hayes | 132 | 5 | 0 | 5 | 51, 51, 30 | 3 | 1.700 |
| waveform | 5000 | 40 | 40 | 0 | 169, 1653, 1655 | 3 | 1.024 |
| auto_205 | 205 | 25 | 18 | 7 | 54, 32, 27, 67, 22, 3 | 6 | 22.333 |
| car | 1728 | 6 | 6 | 0 | 1210, 384, 69, 65 | 4 | 18.615 |
| vehicle | 846 | 18 | 18 | 0 | 217, 217, 216, 196 | 4 | 1.107 |
| balance-scale | 625 | 4 | 0 | 4 | 49, 288, 288 | 3 | 5.878 |
| vowel | 990 | 10 | 10 | 0 | 180, 180, 180, 90, 180, 180 | 6 | 2.000 |
| Datasets | Number | Datasets | Number | Datasets | Number |
|---|---|---|---|---|---|
| wine | 4 | ar3 | 8 | shuttle | 6 |
| hayesroth | 7 | ar4 | 10 | wan_2 | 7 |
| contraceptive | 10 | ar5 | 9 | zoo | 14 |
| penbased | 12 | ar6 | 12 | transfusion | 14 |
| newthyroid | 10 | cm1_req | 10 | waveform | 14 |
| dermatology | 10 | jEdit_4.0_4.2 | 6 | chess | 13 |
| balance | 6 | jEdit_4.0_4.3 | 11 | auto_205 | 13 |
| glass | 12 | kc2 | 7 | car | 11 |
| auto | 9 | kc3 | 9 | vehicle | 9 |
| yeast | 8 | mc2 | 13 | heart | 13 |
| thyroid | 12 | mw1 | 9 | hayes | 11 |
| lymphography | 10 | pc1_req | 5 | sick | 13 |
| ecoli | 11 | balance-scale | 7 | redwinequality | 8 |
| pageblocks | 7 | banknote-authentication | 2 | ar1 | 12 |
| blood-transfusion-service-center | 9 | breast_w | 9 | climate-model-simulation-crashes | 14 |
| diabetes | 7 | ilpd | 10 | vowel | 14 |
| monks-problems1 | 2 | monks-problems2 | 10 | monks-problems3 | 2 |
| mozilla4 | 10 | pc1 | 9 | pc3 | 6 |
| pc4 | 10 | phoneme | 12 |
| Datasets | Number | Datasets | Number | Datasets | Number |
|---|---|---|---|---|---|
| wine | 8 | ar3 | 11 | shuttle | 10 |
| hayesroth | 9 | ar4 | 11 | wan_2 | 7 |
| contraceptive | 10 | ar5 | 5 | zoo | 14 |
| penbased | 12 | ar6 | 13 | transfusion | 11 |
| newthyroid | 11 | cm1_req | 12 | waveform | 13 |
| dermatology | 11 | jEdit_4.0_4.2 | 6 | chess | 12 |
| balance | 8 | jEdit_4.0_4.3 | 13 | auto_205 | 13 |
| glass | 9 | kc2 | 10 | car | 10 |
| auto | 9 | kc3 | 10 | vehicle | 9 |
| yeast | 9 | mc2 | 14 | heart | 8 |
| thyroid | 13 | mw1 | 11 | hayes | 12 |
| lymphography | 0 | pc1_req | 8 | sick | 11 |
| ecoli | 8 | balance-scale | 8 | redwinequality | 12 |
| pageblocks | 12 | banknote-authentication | 5 | ar1 | 12 |
| blood-transfusion-service-center | 9 | breast_w | 9 | climate-model-simulation-crashes | 13 |
| diabetes | 7 | ilpd | 10 | vowel | 14 |
| monks-problems1 | 2 | monks-problems2 | 10 | monks-problems3 | 2 |
| mozilla4 | 10 | pc1 | 9 | pc3 | 7 |
| pc4 | 10 | phoneme | 12 |
| Datasets | Number | Datasets | Number | Datasets | Number |
|---|---|---|---|---|---|
| wine | 4 | ar3 | 7 | shuttle | 7 |
| hayesroth | 7 | ar4 | 11 | wan_2 | 9 |
| contraceptive | 10 | ar5 | 6 | zoo | 14 |
| penbased | 13 | ar6 | 13 | transfusion | 11 |
| newthyroid | 9 | cm1_req | 10 | waveform | 10 |
| dermatology | 5 | jEdit_4.0_4.2 | 5 | chess | 11 |
| balance | 4 | jEdit_4.0_4.3 | 11 | auto_205 | 12 |
| glass | 11 | kc2 | 8 | car | 13 |
| auto | 9 | kc3 | 8 | vehicle | 9 |
| yeast | 10 | mc2 | 12 | heart | 13 |
| thyroid | 10 | mw1 | 9 | hayes | 13 |
| lymphography | 11 | pc1_req | 7 | sick | 11 |
| ecoli | 11 | balance-scale | 6 | redwinequality | 9 |
| pageblocks | 5 | banknote-authentication | 7 | ar1 | 11 |
| blood-transfusion-service-center | 9 | breast_w | 9 | climate-model-simulation-crashes | 13 |
| diabetes | 6 | ilpd | 10 | vowel | 14 |
| monks-problems1 | 2 | monks-problems2 | 10 | monks-problems3 | 2 |
| mozilla4 | 10 | pc1 | 8 | pc3 | 5 |
| pc4 | 9 | phoneme | 12 |
| Datasets | Number | Datasets | Number | Datasets | Number |
|---|---|---|---|---|---|
| wine | 4 | ar3 | 7 | shuttle | 7 |
| hayesroth | 7 | ar4 | 9 | wan_2 | 7 |
| contraceptive | 9 | ar5 | 8 | zoo | 9 |
| penbased | 13 | ar6 | 11 | transfusion | 12 |
| newthyroid | 10 | cm1_req | 10 | waveform | 5 |
| dermatology | 5 | jEdit_4.0_4.2 | 4 | chess | 12 |
| balance | 10 | jEdit_4.0_4.3 | 12 | auto_205 | 11 |
| glass | 11 | kc2 | 9 | car | 12 |
| auto | 9 | kc3 | 8 | vehicle | 9 |
| yeast | 10 | mc2 | 11 | heart | 12 |
| thyroid | 11 | mw1 | 8 | hayes | 8 |
| lymphography | 7 | pc1_req | 5 | sick | 10 |
| ecoli | 13 | balance-scale | 11 | redwinequality | 11 |
| pageblocks | 7 | banknote-authentication | 11 | ar1 | 11 |
| blood-transfusion-service-center | 9 | breast_w | 9 | climate-model-simulation-crashes | 12 |
| diabetes | 7 | ilpd | 10 | vowel | 14 |
| monks-problems1 | 2 | monks-problems2 | 10 | monks-problems3 | 2 |
| mozilla4 | 10 | pc1 | 9 | pc3 | 6 |
| pc4 | 10 | phoneme | 12 |
| Patch Ensemble | A | B | C | D | E | F | G | H | I | G | K | L | M | N | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Times of the optimal MAvA | 7 | 1 | 3 | 8 | 1 | 1 | 3 | 2 | 4 | 3 | 7 | 8 | 8 | 7 | 5 |
| Times of the second MAvA | 7 | 3 | 8 | 3 | 8 | 1 | 4 | 3 | 6 | 2 | 5 | 4 | 3 | 5 | 1 |
| Times of the third MAvA | 7 | 1 | 12 | 1 | 4 | 4 | 7 | 4 | 6 | 4 | 2 | 2 | 3 | 2 | 1 |
| Total | 21 | 5 | 23 | 12 | 13 | 6 | 14 | 9 | 16 | 9 | 14 | 14 | 14 | 14 | 7 |
| Patch Ensemble | A | B | C | D | E | F | G | H | I | G | K | L | M | N | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Times of the optimal MAvA | 6 | 3 | 5 | 8 | 0 | 0 | 2 | 2 | 3 | 1 | 10 | 10 | 9 | 9 | 3 |
| Times of the second MAvA | 6 | 3 | 5 | 3 | 7 | 1 | 6 | 5 | 8 | 3 | 7 | 5 | 5 | 7 | 0 |
| Times of the third MAvA | 6 | 1 | 9 | 1 | 6 | 4 | 11 | 7 | 8 | 5 | 4 | 5 | 4 | 4 | 2 |
| Total | 18 | 7 | 19 | 12 | 13 | 5 | 19 | 14 | 19 | 9 | 21 | 20 | 18 | 20 | 5 |
| Patch Ensemble | A | B | C | D | E | F | G | H | I | G | K | L | M | N | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Times of the optimal MAvA | 4 | 2 | 4 | 3 | 4 | 2 | 0 | 0 | 0 | 3 | 0 | 1 | 0 | 0 | 8 |
| Times of the second MAvA | 10 | 2 | 6 | 3 | 2 | 0 | 3 | 0 | 1 | 2 | 0 | 0 | 0 | 0 | 1 |
| Times of the third MAvA | 8 | 4 | 8 | 0 | 4 | 4 | 2 | 1 | 5 | 3 | 0 | 0 | 2 | 0 | 1 |
| Total | 22 | 8 | 18 | 6 | 10 | 6 | 5 | 1 | 6 | 8 | 0 | 1 | 2 | 0 | 10 |
| Patch Ensemble | A | B | C | D | E | F | G | H | I | G | K | L | M | N | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Times of the optimal MAvA | 3 | 3 | 2 | 4 | 3 | 5 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 12 |
| Times of the second MAvA | 7 | 2 | 7 | 2 | 8 | 2 | 3 | 1 | 2 | 3 | 0 | 0 | 0 | 0 | 1 |
| Times of the third MAvA | 9 | 2 | 10 | 1 | 7 | 4 | 0 | 0 | 2 | 6 | 1 | 0 | 0 | 1 | 0 |
| Total | 19 | 7 | 19 | 7 | 18 | 11 | 3 | 1 | 4 | 14 | 1 | 0 | 0 | 1 | 13 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, D.; Wang, X.; Mu, Y.; Wang, L. Experimental Study and Comparison of Imbalance Ensemble Classifiers with Dynamic Selection Strategy. Entropy 2021, 23, 822. https://doi.org/10.3390/e23070822
Zhao D, Wang X, Mu Y, Wang L. Experimental Study and Comparison of Imbalance Ensemble Classifiers with Dynamic Selection Strategy. Entropy. 2021; 23(7):822. https://doi.org/10.3390/e23070822
Chicago/Turabian StyleZhao, Dongxue, Xin Wang, Yashuang Mu, and Lidong Wang. 2021. "Experimental Study and Comparison of Imbalance Ensemble Classifiers with Dynamic Selection Strategy" Entropy 23, no. 7: 822. https://doi.org/10.3390/e23070822