1. Introduction
With the increasing popularity of artificial intelligence, agent technology has become a hot topic in the field of distributed artificial intelligence. Agents with autonomy and collaboration can deal with complex, collaborative, and unpredictable problems. They can modify their goals with changes in the environment, expand their knowledge, and improve their ability. Due to the constraints of ability and relationships with other agents, it is impossible to solve complex problems using a single agent. Artificial intelligence is maturing. It is committed to solving more complex, more realistic, and larger scale problems. These problems are beyond the capability of a single agent. Therefore, the multi-agent system (MAS) [
1] has emerged as an important tool. It is a collection of agents, and its purpose is to solve the problems of large-scale, complex, real-time, and uncertain information. Its theoretical research value lies in two aspects: one is the development of a closed and isolated knowledge system into a distributed and open intelligent knowledge system, and the other is the development of a centralized intelligent system into a non-independent distributed intelligent system. The key point of MAS research is to enable independent agents to complete complex control tasks or solve complex problems through negotiation, coordination, and cooperation. However, uncertainty is the biggest challenge for MAS research. In many problems, the state of the environment will be uncertain due to the limitation of noise or sensor capacity. An agent can only observe the state of the environment through its own sensors. Therefore, the ability of an agent to predict the trend of other agents is limited. As a result, cooperation becomes complicated, and, therefore, conflicting information may appear in MAS.
Information fusion [
2] is an application field that combines data from multiple sources to support decision analysis. Applying information fusion technology to MAS can process the information and provide more complete judgment, evaluation, and decision making. Using the appropriate information fusion method, the local information perceived by an agent is fused in space, time, and function. Therefore, identifying the way by which to fuse conflicting information and make correct judgments represents the main challenge in multi-agent information fusion (MAIF).
As an uncertain reasoning method, Dempster–Shafer evidence theory (D-S theory) has a strong ability to express and process uncertain information. It serves as a powerful tool in the representation and fusion of decision making with uncertain information. It has been widely used in the fields of information fusion [
3], target recognition [
4,
5], risk analysis [
6], classification [
7,
8,
9], and decision making [
10,
11,
12].
1.1. Motivation
In modern engineering applications, electronic information systems tend to be highly integrated, multi-component, and complex functions. Therefore, concurrency, suddenness, and complexity are the three major problems that may occur when the equipment fails [
13,
14,
15]. In many information systems, multi-source information systems occupy a certain proportion, and they are usually used to represent complex information from multiple sources [
16]. However, in the process of information fusion and diagnosis, many scholars have begun to focus on identifying methods of effectively integrating multi-source information [
3] and measuring its uncertainty to ensure correctness and anti-interference [
17,
18].
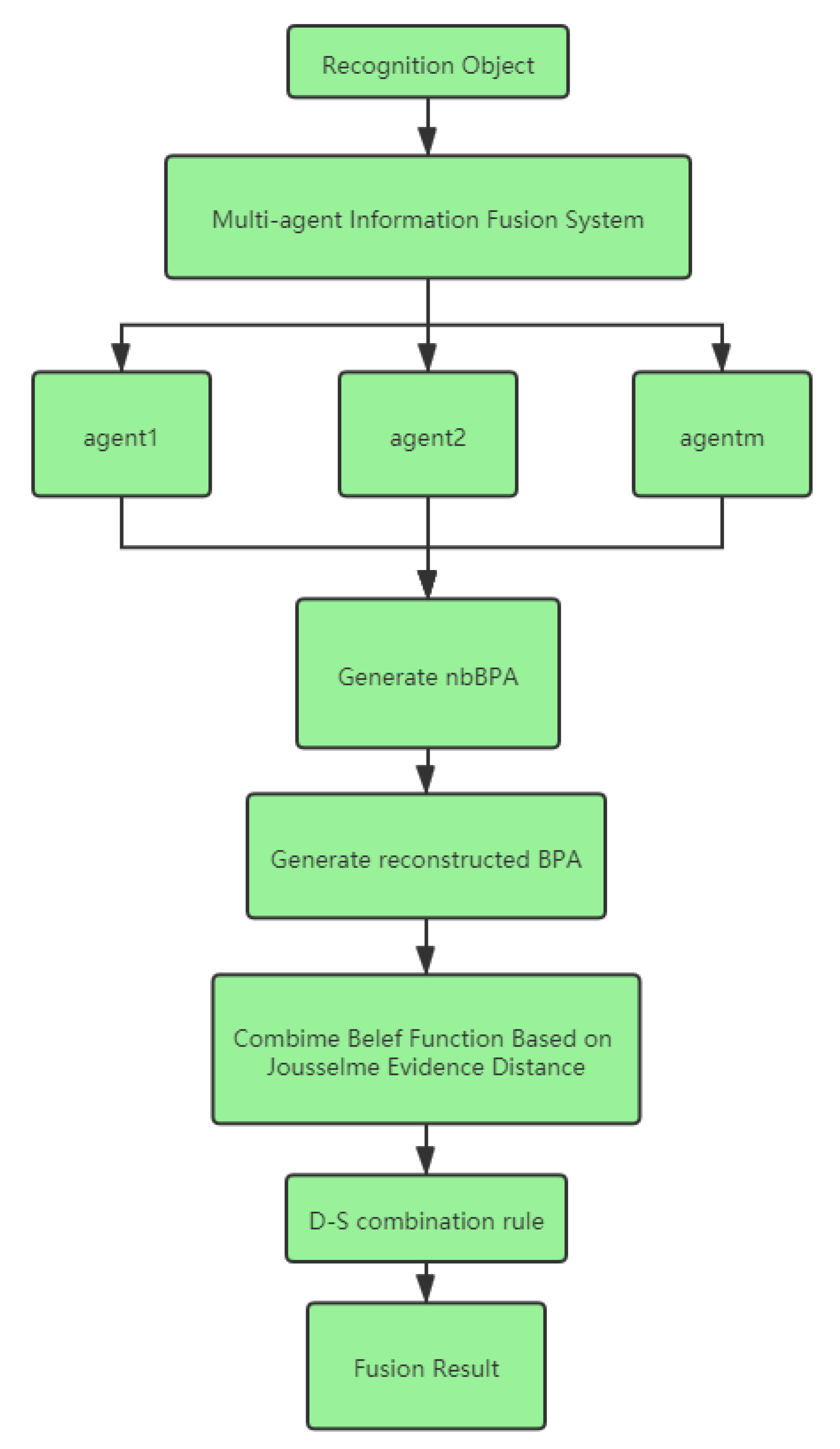
The MAIF system mainly studies the communication, coordination, and conflict resolution between multiple agents. It is an autonomous solution to the problem of information fusion among agents in MAS. It focuses on the analysis of information fusion between multiple agents rather than the autonomy and development of a single agent. In the process of MAIF, even if all agents use the same original detection data, the conclusions given may be inconsistent, because the reasoning model used by each agent is not necessarily the same. There have been many attempts to improve performance, such as distributed weighting [
19] and relative reliability evaluation [
20,
21]. However, they do not focus on the measurement of uncertainty between information sources from different institutions. Moreover, the methods somewhat struggle to combine conclusions in the process of MAIF.
D-S theory is a good choice for uncertain information processing in MAIF. However, D-S theory may fail in highly conflicting situations, which makes it difficult to guarantee the fusion result. This may lead to unreasonable results [
22]. Two methods to improve the performance of MAIF are proposed: modifying the fusion rules and preprocessing the uncertain information before data fusion. Previous studies have proposed preprocessing strategies. They provided distance measurement to effectively measure the uncertainty of MAIF. However, the measurement object is mainly based on multiple data sources as a whole, and there is no specific distinction between the two data sources. Therefore, this paper proposes a new method for better data preprocessing. In this study, we add a new base basic probability assignment(nbBPA) based on base basic probability assignment (bBPA) [
23,
24] and reconstructed BPA [
25] to preprocess the data, and we combine it with evidence distance to prove its effectiveness in the application of MAIF system.
1.2. Contributions
The main contributions of this method are different from those of a large number of existing methods and are summarized as follows:
It is feasible and extensible to integrate evidence theory into the MAIF system. However, D-S theory may result in counterintuitive results in highly conflicting situations. In order to address D-S conflicting information fusion in MAIF, the method based on nbBPA and evidence distance is proposed.
In the improved MAIF method, nbBPA provides a kind of prior information to preprocess the data. The evidence distance is used to judge the difference between the bodies of evidence. The weight of each belief function is calculated according to the evidence distance so as to recalculate the revised BPA.
1.3. Organization
The following remainder this paper are organized as follows:
Section 2 investigates previous work related to this study. In
Section 3, we review some basic concepts. Then, in
Section 4, we propose a new preprocessing method, nbBPA, which is based on bBPA, and we propose an improved method using nbBPA. In
Section 5, we show the performance of our proposed method based on three numerical examples. Finally, conclusions of the proposed method are given in
Section 6.
2. Related Work
D-S theory was first proposed by Dempster in 1967 [
26] and then further extended by Shafer [
27]. Due to its strong ability to express and process uncertain information, the theory is widely used in information fusion systems, such as target recognition and remote sensing [
28]. Although the application of D-S theory has made some progress, the D-S combination rule often obtains results contrary to common sense when it fuse highly conflicting evidence [
29]. In view of these paradoxes, scholars have proposed some solutions that can be divided into two categories: one is based on modifying the D-S combination rule [
30,
31,
32]; the other is based on modifying evidence sources [
33,
34]. The methods of relevant evidence fusion based on the modified evidence source can be divided into two types: one is based on the correlation source evidence model [
35], and the other is based on the discount correction model.
The perspective of the discount correction model is the overestimation of the composite result. Because the D-S combination rule is used to fuse the relevant evidence directly, the relevant parts of the evidence are repeatedly calculated. The basic idea of this kind of method is that the relevant evidence should be discounted. The discount coefficient depends on the degree of correlation. Compared with independent evidence, relevant evidence has overlapping information that cannot be given the same weight in the fusion process.
Yager proposed a weighted fusion method of relevant evidence with the relative independence degree set as weight [
36]. The so-called degree of relative independence refers to the degree of independence of the latter evidence relative to all previous evidence. The evidence uses the relative independence degree as a means of discounting the factors to process. In doing so, it can be regarded as independent of the previous evidence, and, thus, D-S combination rule can be used for fusion. The method depends on the order of evidence fusion. The evidence in the front has a great impact on the fusion results. Therefore, a method based on the information quantity of evidence is proposed in [
36] to reduce the loss of information as much as possible. However, this method does not provide the basis for determining the degree of relative independence. When the amount of evidence is large, the computational complexity of the method greatly increases. In order to determine the correlation degree of the discount model, a method to solve the correlation discount coefficient based on the network analysis method is proposed in [
37]. This method needs to rely on expert opinion for modeling, which has certain subjectivity.
Tessem [
38] designed the pignistic probability distance to describe evidence similarity based on pignistic probability. The distance was used to evaluate the effectiveness of the approximate calculation algorithm of evidence combination. Bauer [
39] also conducted a similar study. Pignistic probability distance has been widely used. However, there remain misunderstandings regarding its definition, and it is misused. Liu et al. [
40] indirectly defined evidence distance based on DSMP probability. Cuzzolin [
41] designed and proposed a geometric interpretation of evidence theory. On this basis, Jousselme et al. [
42] defined the evidence distance. Then, many studies of evidence distance applications emerged. Deng et al. [
43] defined the similarity between evidence volume using Jousselme evidence distance, and then the weight correction evidence to be combined was generated. Liu [
44] used pignistic probability distance and Dempster combination conflict coefficient K to form a binary, which was used to describe the conflict between evidence bodies. Ristic et al. [
45] realized target identity association based on multiple uncertain information sources in a TBM framework by using evidence distance. Zouhal et al. [
46] introduced a mean square deviation distance based on pignistic probability, which corresponds to BPA. The distance effectively improved the accuracy rate of evidence of the k-nearest neighbor classifier. Schubert [
47] used evidence distance for clustering analysis, and an ideal clustering performance was observed.
In addition, in order to solve the conflicting data in uncertain information, some methods attempt to assign initial belief to events in the frame of discernment (FOD). A new strategy to consider the initial belief degree of propositions in the power set of FOD is proposed in [
23], but it may lead to decentralized belief allocation. An improved base basic probability assignment approach is proposed in [
24]. These methods can introduce additional information to uncertain information modeling and processing.
6. Conclusions
Due to the variability and interference of multi-source information, it is very important to consider the uncertainty relationship in the process of multi-source fusion. When processing information of multiple sources, it is easy to cause data conflicts due to various external factors, such as equipment damage. At the same time, the traditional D-S combination rule may produce counterintuitive results when addressing highly conflicting data. The nbBPA can be used as a method to solve this problem. nbBPA is based on the basic event. Other uncertain events in the power set of the FOD may not help in the process of decision making. Therefore, we only specify the initial base beliefs regarding the basic events. In this study, we improve the modeling of the uncertain relationship between the recognition objects in the MAIF system, and in this paper, an uncertainty model is established by adding nbBPA before reconstructing the BPA, combining it with the evidence distance factor and using the uncertainty relationship in evidence theory. The experimental results show that the method is effective and reasonable, especially when the multi-agent is faced with a highly unfavorable situation. This method can obtain correct results more accurately and quickly than other methods can, even in the case of equipment failure. Thus, it can be stated that this method improves the accuracy of the identification process of the MAIF system.
The following abbreviations are used in this manuscript:





{kind=link}