3.1. Risk Measures
The purpose of this subsection is to indicate the financial context, in which the geometric problem discussed in this paper appears. A portfolio is the weighted sum of financial assets. The weights represent the parts of the total wealth invested in the various assets. Some of the weights are allowed to be negative (short positions), but the weights sum to 1; this is called the budget constraint. Investment carries risk, and higher returns usually carry higher risk. Portfolio optimization seeks a trade-off between risk and return by the appropriate choice of the portfolio weights. Markowitz was the first to formulate the portfolio choice as a risk-reward problem [
12]. Reward is normally regarded as the expected return on the portfolio. Assuming return fluctuations to be Gaussian-distributed random variables, portfolio variance offered itself as the natural risk measure. This setup made the optimization of portfolios a quadratic programming problem, which, especially in the case of large institutional portfolios, posed a serious numerical difficulty in its time. Another critical point concerning variance as a risk measure was that variance is symmetric in gains and losses, whereas investors are believed not to be afraid of big gains, only big losses. This consideration led to the introduction of downside risk measures, starting already with the semivariance [
13]. Later it was recognized that the Gaussian assumption was not realistic, and alternative risk measures were sought to grasp the risk of rare but large events, and also to allow risk to be aggregated across the ever-increasing and increasingly heterogeneous institutional portfolios. Around the end of the 1980s, Value at Risk (VaR) was introduced by JP Morgan [
14], and subsequently it was widely spread over the industry by their RiskMetrics methodology [
15]. VaR is a high quantile, a downside risk measure (note that in the literature, the profit and loss axis is often reflected, so that losses are assigned a positive sign. It is under this convention that VaR is a high quantile, rather than a low one). It soon came under academic criticism for its insensitivity to the details of the distribution beyond the quantile, and for its lack of sub-additivity. Expected Shortfall (ES), the average loss above the VaR quantile, appeared around the turn of the century [
16]. An axiomatic approach to risk measures was proposed by Artzner et al. [
17] who introduced a set of postulates which any coherent risk measure was required to satisfy. ES turned out to be coherent [
18,
19] and was strongly advocated by academics. After a long debate, international regulation embraced it as the official risk measure in 2016 [
20].
The various risk measures discussed all involved averages. Since the distributions of financial data are not known, the relative price movements of assets are observed at a number
T of time points, and the true averages are replaced by empirical averages from these data. This works well if
T is sufficiently large; however, in addition to all the aforementioned problems, a general difficulty of portfolio optimization lies in the fact that the dimension
N of institutional portfolios (the number of different assets) is large, but the number
T of observed data per asset is never large enough, due to lack of stationarity of the time series and the natural limits (transaction costs, technical difficulties of rebalancing) on the sampling frequency. Therefore, portfolio optimization in large dimensions suffers from a high degree of estimation error, which renders the exercise more or less illusory (see e.g., [
21]). Estimation of returns is even more error-prone than the risk part, so several authors disregard the return completely, and seek the minimum risk portfolio (e.g., [
22,
23,
24]). We follow the same approach here.
In the two subsections that follow, we also assume that the returns are independent, symmetrically distributed random variables. This is, of course, not meant to be a realistic market model, but it allows us to make an explicit connection between the optimization of the portfolio variance under a constraint excluding short positions and the geometric problem of dichotomies discussed in
Section 2. This is all the more noteworthy because analytic results are notoriously scarce for portfolio optimization with no short positions. We note that similar simplifying assumptions (Gaussian fluctuations, independence) were built into the original JP Morgan methodology, which was industry standard in its time, and influences the thinking of practitioners even today.
3.2. Vanishing of the Estimated Variance
We consider a portfolio of
N assets with weights
. The observations
of the corresponding returns at various times
are assumed to be independent, symmetrically distributed random variables. Correspondingly, the average value of the portfolio is zero. Its variance is given by
where
denotes the covariance matrix of the observations. Note that the variance of a portfolio optimized in a given sample depends on the sample, so it is itself a random variable.
The variance of a portfolio obviously vanishes if the returns are fixed quantities that do not fluctuate. This subsection is not about such a trivial case. We shall see, however, that the variance optimized under a no-short constraint can vanish with a certain probability if the dimension N is larger than the number of observations T.
The rank of the covariance matrix is the smaller of
N and
T, and for
the estimated variance is positive with the probability one. Thus, the optimization of variance can always be carried out as long as the number of observations
T is larger than the dimension
N, albeit with an increasingly larger error as
decreases. For large
N and
T and fixed
, the estimation error increases as
with decreasing
and diverges at
[
25,
26]. The divergence of the estimation error can be regarded as a phase transition. Below the critical value
, the optimization of variance becomes impossible. Of course, in practice, one never has such an optimization task without some additional constraints. Note that because of the possibility of short-selling (negative portfolio weights), the budget constraint (a hyperplane) in itself is not sufficient to forbid the appearance of large positive and negative positions, which then destabilize the optimization. In contrast, any constraint that makes the allowed weights finite can act as a regularizer. The usual regularizers are constraints on the norm of the portfolio vector. It was shown in [
27,
28] how liquidity considerations naturally lead to regularization. Ridge regression (a constraint on the
norm of the portfolio vector) prevents the covariance matrix from developing zero eigenvalues, and, especially in its nonlinear form [
29], results in very satisfactory out-of-sample performance.
An alternative is the regularizer, of which the exclusion of short positions is a special case. Together with the budget constraint, it prevents large sample fluctuations of the weights. Let us then impose the no-short ban, as it is indeed imposed in practice on a number of special portfolios (e.g., on pension funds), or, in episodes of crisis, on the whole industry. The ban on short-selling extends the region where the variance can be optimized, but below the optimization acquires a probabilistic character in that the regularized variance vanishes with a certain probability, and the optimization can only be carried out when it is positive. (Otherwise, there is a continuum of solutions, namely any combination of the eigenvectors belonging to zero eigenvalues, which makes the optimized variance zero).
Interestingly, the probability of the variance vanishing is related to the problem of random dichotomies in the following way. For the portfolio variance (
19) to become zero, we need to have
for all
t. If we interchange
t and
i, we see that according to (
11), this is possible as long as the
N points in
with position vectors
do not form a dichotomy. Hence, the probability for zero variance is from (
2)
Therefore, the probability of the variance vanishing is almost 1 for small
, decreases to the value 1/2 at
, decreases further to 0 as
increases to 1, and remains identically zero for
[
30,
31]. This is similar but also somewhat complementary to the curve shown in
Figure 2. Equation (
21) for the vanishing of the variance was first written up in [
30,
31] on the basis of analogy with the minimax problem to be considered below, and it was also verified by extended numerical simulations. The above link to the Cover problem is a new result, and it is rewarding to see how a geometric proof establishes a bridge between the two problems.
In [
30,
31], an intriguing analogy with, for example, the condensed phase of an ideal Bose gas was pointed out. The analogous features are the vanishing of the chemical potential in the Bose gas, resp. the vanishing of the Lagrange multiplier enforcing the budget constraint in the portfolio problem; the onset of Bose condensation, resp. the appearance of zero weights (“condensation” of the solutions on the coordinate planes) due to the no-short constraint; the divergence of the transverse susceptibility, and the emergence of zero modes in both models.
3.3. The Maximal Loss
The introduction of the Maximal Loss (ML) or minimax risk measure by Young [
32] in 1998 was motivated by numerical expediency. In contrast to the variance whose optimization demands a quadratic program, ML is constructed such that it can be optimized by linear programming, which could be performed very efficiently even on large datasets already at the end of the last century. Maximal Loss combines the worst outcomes of each asset and seeks the best combination of them. This may seem to be an over-pessimistic risk measure, but there are occasions when considering the worst outcomes is justifiable (think of an insurance portfolio in the time of climate change), and, as will be seen, the present regulatory market risk measure is not very far from ML.
Omitting the portfolio’s return again and focusing on the risk part, the maximal loss of a portfolio is given by
with the constraint
We are interested in the probability
that this minimax problem is feasible, that is, ML does not diverge to
. To this end, we first eliminate the constraint (
23) by putting
This results in
with
and
. For ML to stay finite for all choices of
, the
T random hyperplanes with normal vectors
have to form a bounded cone. If the points
form a dichotomy, then according to (
6), there is a vector
with
for all
t. Since there is no constraint on the norm of
, the maximal loss (
25) can become arbitrarily small for
and
. The cone then is not bounded. We therefore find
for the probability that ML cannot be optimized.
In the limit
with
kept finite, (
25) displays the same abrupt change as in the problem of dichotomies, a phase transition at
. Note that this is larger than the critical point
of the unregularized variance, which is quite natural, since the ML uses only the extremal values in the data set. The probability for the feasibility of ML was first written up without proof in [
1], where a comparative study of the noise sensitivity of four risk measures, including ML, was performed. There are two important remarks we can make at this point. First, the geometric consideration above does not require any assumption about the data generating process; as long as the the returns are independent, they can be drawn from any symmetric distribution without changing the value of the critical point. This is a special case of the universality of critical points discovered by Donoho and Tanner [
33].
The second remark is that the problem of bounded cones is closely related to that of bounded polytopes [
34]. The difference is just the additional dimension of the ML itself. If the random hyperplanes perpendicular to the vectors
form a bounded cone for ML according to (
25), then they will trace out a bounded polytope on hyperplanes perpendicular to the ML axis at sufficiently high values of ML. In fact, after the replacement
Equation (
26) coincides with the result in Theorem 4 of [
34] for the probability of
T random hyperplanes forming a bounded polytope in
N dimensions (there is a typo in Theorem 4 in [
34]; the summation has to start at
). The close relationship between the ML problem and the bounded polytope problem, on the one hand, and the Cover problem on the other hand, was apparently not clarified before.
If we spell out the financial meaning of the above result, we are led to interesting ramifications. To gain an intuition, let us consider just two assets,
. If asset 1 produces a return sometimes above, sometimes below that of asset 2, then the minimax problem will have a finite solution. If, however, asset 1 dominates asset 2 (i.e., yields a return which is at least as large, and, at least at one time point, larger, than the return on asset 2 in a given sample), then, with unlimited short positions allowed, the investor will be induced to take an arbitrarily large long position in asset 1 and go correspondingly short in asset 2. This means that the solution of the minimax problem will run away to infinity, and the risk of ML will be equal to minus infinity [
1]. The generalization to
N assets is immediate: if among the assets there is one that dominates the rest, or there is a combination of assets that dominates some of the rest, the solution will run away to infinity, and ML will take the value of
. This scenario corresponds to an arbitrage, and the investor gains an arbitrarily large profit without risk [
35]. Of course, if such a dominance is realized in one given sample, it may disappear in the next time interval, or the dominance relations can rearrange to display another mirage of an arbitrage.
Clearly, the ML risk measure is unstable against these fluctuations. In practice, such a brutal instability can never be observed, because there are always some constraints on the short positions, or groups of assets corresponding to branches of industries, geographic regions, and so forth. These constraints will prevent instabilities from taking place, and the solution cannot run away to infinity, but will go as far as allowed by the constraints and then stick to the boundary of the allowed region. Note, however, that in such a case, the solution will be determined more by the constraints (and ultimately by the risk manager imposing the constraints) rather than by the structure of the market. In addition, in the next period, a different configuration can be realized, so the solution will jump around on the boundary defined by the constraints.
We may illustrate the role of short positions for the instability of ML further by investigating the case of portfolio weights
that have to be larger than a threshold
. For
, there are no restrictions on short positions, whereas
corresponds to a complete ban on them. For
with fixed
, the problem may be solved within the framework of statistical mechanics. The minimax problem for ML is equivalent to the following problem in linear programming: minimize the threshold variable
under the constraints (
23),
, and
Similarly to (
14), the central quantity of interest is
giving the fractional volume of points on the simplex defined by (
23) that fulfill all constraints (
27). For given
and
, we decrease
down to the point
, where the typical value of this fractional volume vanishes. The ML is then given by
.
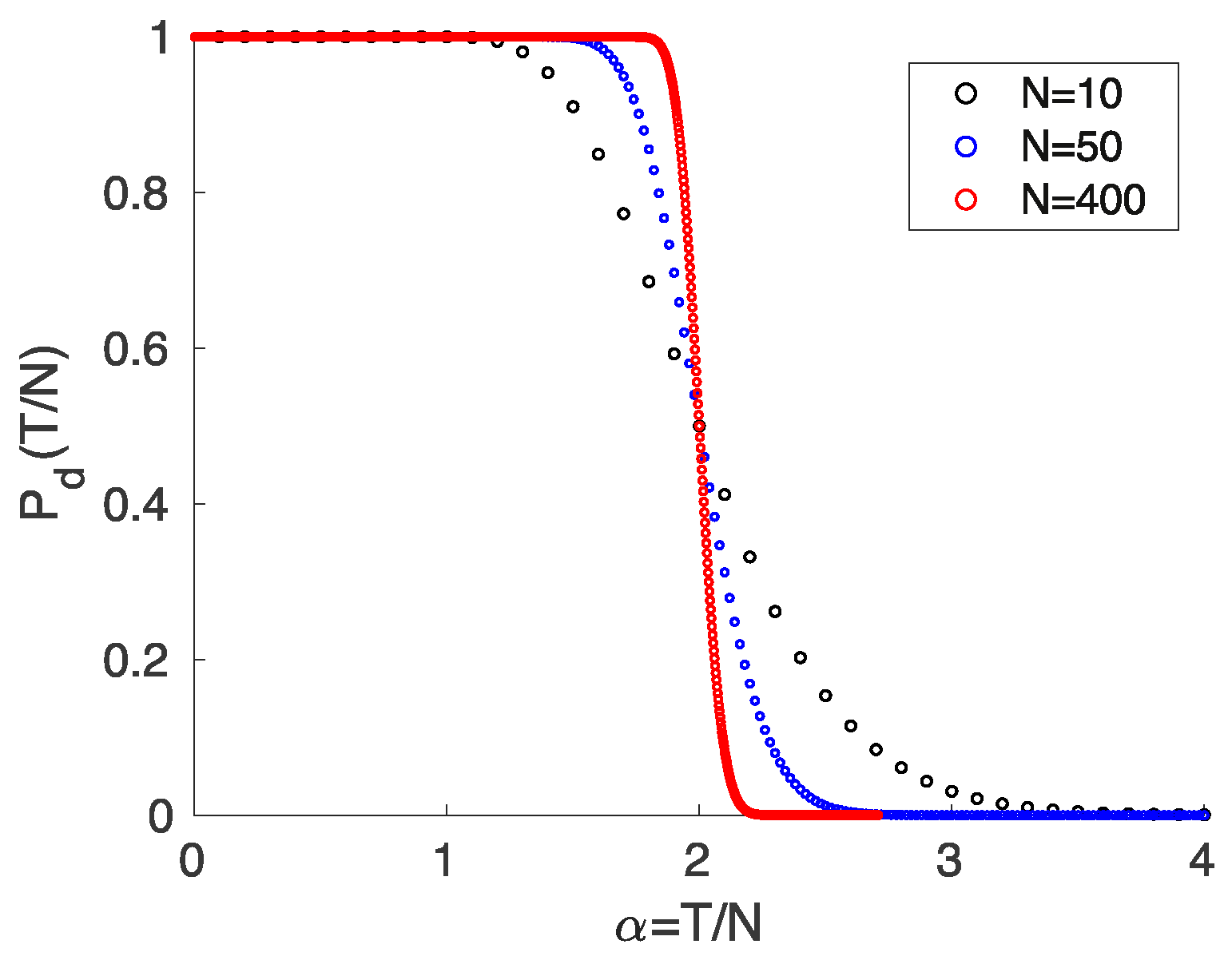
Some details of the corresponding calculations are given in the
Appendix A. In
Figure 3, we show some results. As discussed above, the divergence of ML for
is indeed formally eliminated for all
, and the functions
smoothly interpolate between the cases
and
. However, the situation is now even more dangerous, since the unreliability of ML as a risk measure for small
remains without being deducible from its divergence.
The recognition of the instability of ML as a dominance problem has proved very fruitful and led to a series of generalizations. First, it was realized [
1] that the instability of the expected shortfall, of which ML is an extreme special case, has a very similar geometric origin. (The current regulatory ES is the expected loss above a 97.5% quantile, whereas ML corresponds to 100%.) Both ES and ML are so-called coherent risk measures [
17], and it was proved [
35] that the root of this instability lies in the coherence axioms themselves, so every coherent risk measure suffers from a similar instability. Furthermore, it was proved [
35] that the existence of a dominant/dominated pair of assets in the portfolio was a necessary and sufficient condition for the instability of ML, whereas it was only sufficient for other coherent risk measures. It follows that in terms of the variable
used in this paper (which is the reciprocal of the aspect ratio
used in some earlier works, such as [
35,
36,
37]), the critical point of ML is a lower bound for the critical points of other coherent measures. Indeed, the critical line of ES was found to lie above the ML critical value of
[
36]. Value at Risk is not a coherent measure and can violate convexity, so it is not amenable to a similar study of its critical point. However, parametric VaR (that is, the quantile where the underlying distribution is given, only its expectation value and variance is determined from empirical data)
is convex, and it was shown to possess a critical line that runs above that of ES [
37]. The investigation of the semi-variance yielded similar results [
37]. It seems, then, that the geometrical analysis of ML provides important information for a variety of risk measures, including some of the most widely used measures in the industry (VaR and ES), and also other downside risk measures.


{kind=link}
{kind=link}
{kind=link}


