
A New Overdispersed Integer-Valued Moving Average Model with Dependent Counting Series

Abstract
:1. Introduction
2. The Model and Basic Properties
2.1. The Model Construction
2.2. The Numerical Properties for DCINMA(q) Model
- (i)
- (ii)
- (iii)
2.3. The Probability Generating Functions for DCINMA Model
2.4. Compare with the INMA(q) Model
2.5. Compare the Entropy with INMA(1) Model
3. Parameter Estimation
4. Simulation Study
4.1. Estimation of the Model Parameters
4.2. Testing for Dependence between Counting Series
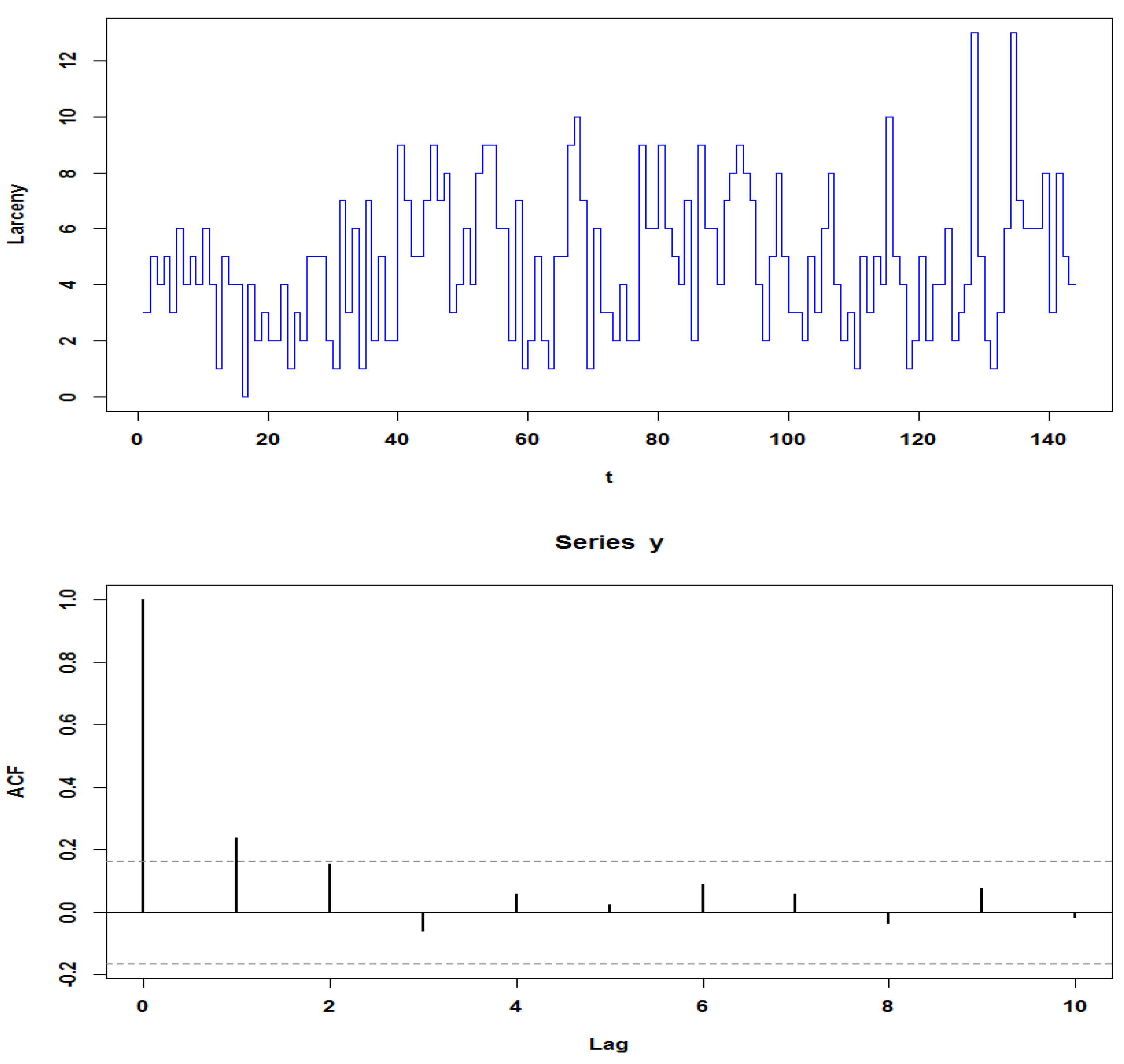
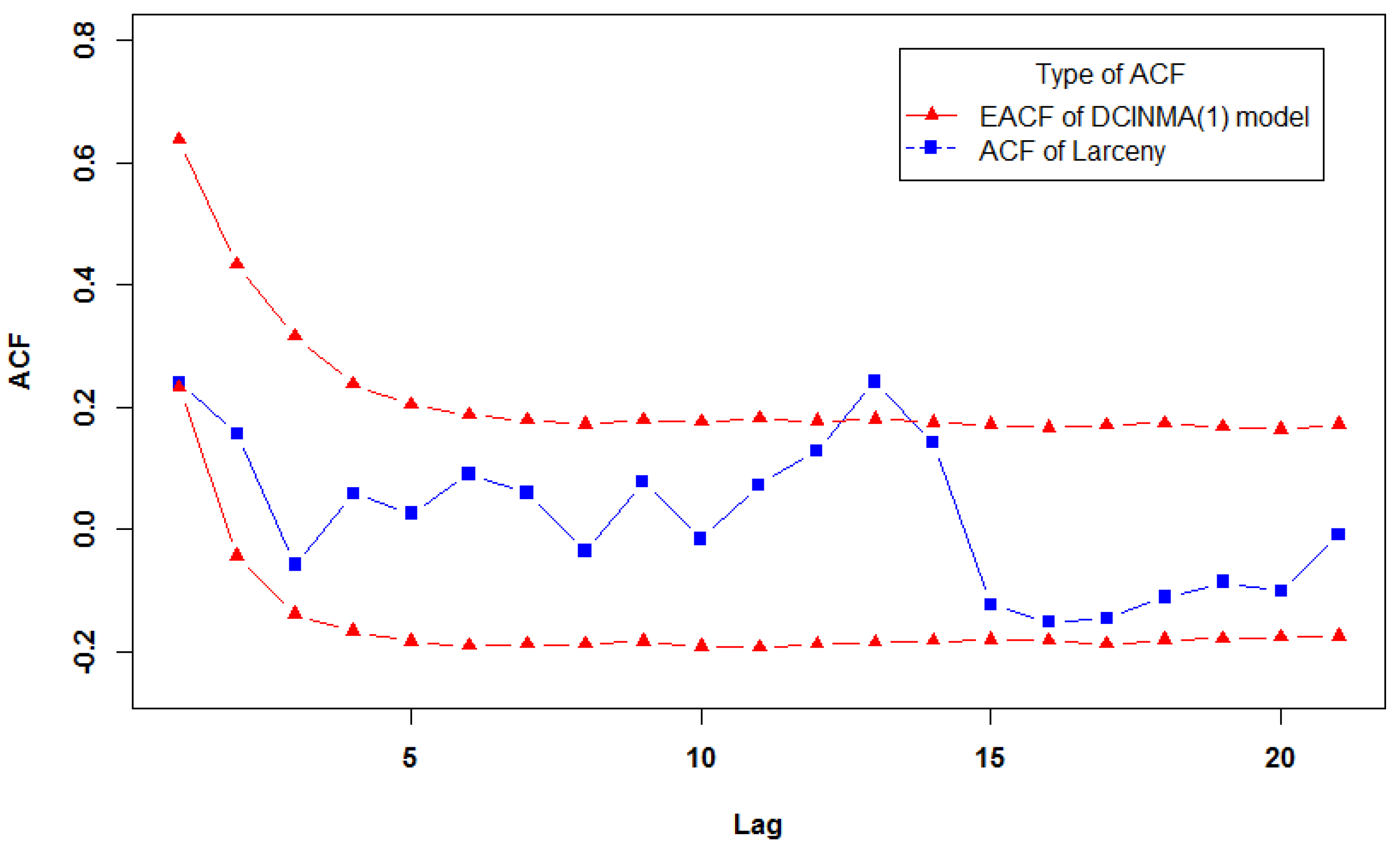
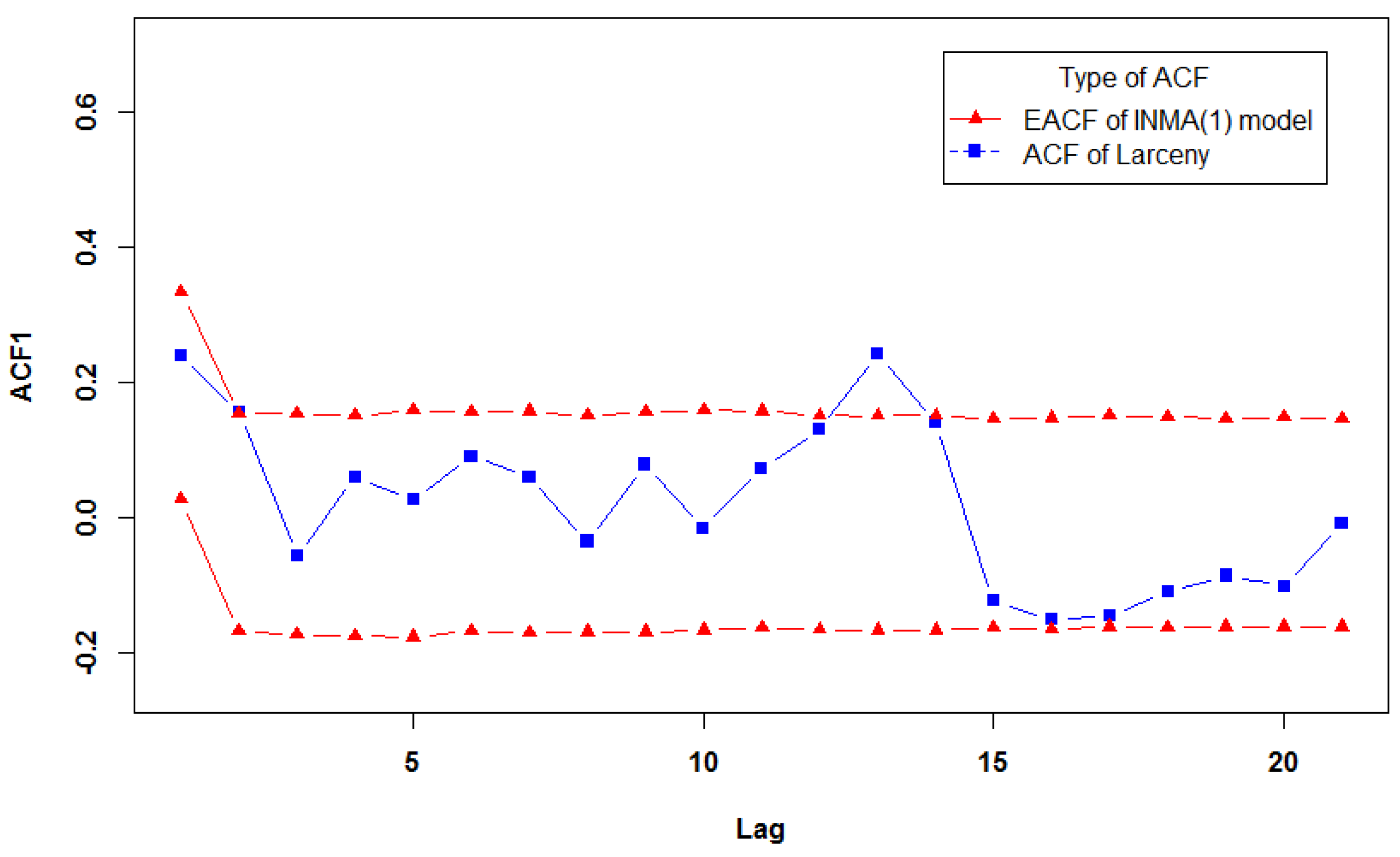
5. Real Data Example
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Alzaid, A.A.; Al-Osh, M.A. An integer-valued pth-order autoregressive structure (INAR(p)) process. J. Appl. Probab. 1990, 27, 314–324. [Google Scholar] [CrossRef]
- Du, J.; Li, Y. The integer-valued autoregressive (INAR(p)) model. J. Time Ser. Anal. 1991, 12, 129–142. [Google Scholar]
- Al-Osh, M.A.; Alzaid, A.A. Integer-valued moving average (INMA) process. Stat. Pap. 1988, 29, 281–300. [Google Scholar] [CrossRef]
- McKenzie, E. Some ARMA models for dependent sequences of Poisson count. Adv. Appl. Probab. 1988, 20, 822–835. [Google Scholar] [CrossRef]
- Weiß, C.H. The combined INAR(p) models for time series of counts. Stat. Probab. Lett. 2008, 78, 1817–1822. [Google Scholar] [CrossRef]
- Monteiro, M.; Scotto, M.G.; Pereira, I. Integer-valued autoregressive processes with periodic structure. J. Stat. Plan. Infer. 2010, 140, 1529–1541. [Google Scholar] [CrossRef] [Green Version]
- Weiß, C.H. A Poisson INAR(1) model with serially dependent innovations. Metrika 2015, 78, 829–851. [Google Scholar] [CrossRef]
- Zhu, F. Modeling time series of counts with com-poisson INGARCH models. Math. Comput. Model. 2012, 56, 191–203. [Google Scholar] [CrossRef]
- Möller, T.; Weiß, C.H. Threshold models for integer-valued time series with infinite or finite range. In Stochastic Models, Statistics and Their Applications; Steland, A., Rafajłowicz, E., Szajowski, K., Eds.; Springer: Geneva, Switzerland, 2015; pp. 327–334. [Google Scholar]
- Yao, K.; Wang, D. A new INAR(1) process with bounded support for counts showing equidispersion, underdispersion and overdispersion. Stat. Pap. 2019, 62, 745–767. [Google Scholar]
- Li, C.; Wang, D. First-order mixed integer-valued autoregressive processes with zero-inflated generalized power series innovations. J. Korean Stat. Soc. 2015, 44, 232–246. [Google Scholar] [CrossRef]
- Kim, H.Y.; Park, Y. A non-stationary integer-valued autoregressive model. Stat. Pap. 2008, 49, 485. [Google Scholar] [CrossRef]
- Zheng, H.; Basawa, I.V. Inference for pth-order random coefficient integer-valued autoregressive processes. J. Time Ser. Anal. 2006, 27, 411–440. [Google Scholar] [CrossRef]
- Ristić, M.M.; Bakouch, H.S. A new geometric first-order integer-valued autoregressive (NGINAR(1)) process. J. Stat. Plan. Infer. 2009, 139, 2218–2226. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, D.; Zhu, F. Inference for INAR(p) processes with signed generalized power series thinning operator. J. Stat. Plan. Infer. 2010, 140, 667–683. [Google Scholar] [CrossRef]
- Ristić, M.M.; Nastić, A.S.; Miletić Ilić, A.V. A geometric time series model with dependent Bernoulli counting series. J. Time Ser. Anal. 2013, 34, 466–476. [Google Scholar] [CrossRef]
- Miletić Ilić, A.V.; Ristić, M.M.; Nastić, A.S.; Bakouch, H.S. An INAR(1) model based on a mixed dependent and independent counting series. J. Stat. Comput. Simul. 2018, 88, 290–304. [Google Scholar] [CrossRef]
- Weiß, C.H. Thinning operations for modeling time series of counts—A survey. Adv. Appl. Probab. 2008, 92, 319. [Google Scholar] [CrossRef]
- Winters, P.R. Forecasting sales by exponentially weighted moving averages. Manag. Sci. 1960, 6, 231–362. [Google Scholar] [CrossRef]
- Cox, D.R. Prediction by exponentially weighted moving averages and related methods. J. R. Stat. Soc. Ser. B-Stat. Methodol. 1961, 23, 414–422. [Google Scholar] [CrossRef]
- Landauskas, M.; Navickas, Z.; Vainoras, A.; Ragulskis, M. Weighted moving averaging revisited—An algebraic approach. Comput. Appl. Math. 2017, 36, 1545–1558. [Google Scholar] [CrossRef]
- Nan, X.; Li, Q.; Qiu, D.; Zhao, Y.; Guo, X. Short-term wind speed syntheses correcting forecasting model and its application. Int. J. Electr. Power Energy Syst. 2013, 49, 264–268. [Google Scholar] [CrossRef]
- Alevizakos, V.; Chatterjee, K.; Koukouvinos, C. The triple exponentially weighted moving average control chart. Qual. Technol. Quant. Manag. 2021, 18, 326–354. [Google Scholar] [CrossRef]
- Capizzi, G.; Masarotto, G. An adaptive exponentially weighted moving average control chart. Technometrics 2003, 45, 199–207. [Google Scholar] [CrossRef] [Green Version]
- Adegoke, N.A.; Abbasi, S.A.; Smith, A.N.H.; Anderson, M.J.; Pawley, M.D.M. A multivariate homogeneously weighted moving average control chart. IEEE Access 2019, 7, 9586–9597. [Google Scholar] [CrossRef]
- Brännäs, K.; Quoreshi, A.M.M.S. Integer-valued moving average modelling of the number of transactions in stocks. Appl. Financ. Econ. 2010, 20, 1429–1440. [Google Scholar] [CrossRef]
- Brännäs, K.; Hall, A. Estimation in integer-valued moving average models. Appl. Stoch. Models. Bus. Ind. 2001, 17, 277–291. [Google Scholar] [CrossRef]
- Aleksandrov, B.; Weiß, C.H. Parameter estimation and diagnostic tests for INMA(1) processes. Test 2019, 29, 196–232. [Google Scholar] [CrossRef]
- Jung, R.C.; McCabe, P.M.; Tremayne, A.R. Model validation and diagnostics. In Handbook of Discrete-Valued Time; Davis, R.A., Holan, S.H., Lund, R., Ravishanker, N., Eds.; Chapman & Hall/CRC Press: Boca Raton, FL, USA, 2015; pp. 189–218. [Google Scholar]
- Liberzon, D.; Morse, A.S. Basic problems in stability and design of switched systems. IEEE Control Syst. Mag. 1999, 19, 59–70. [Google Scholar]
- Blanchini, F.; Miani, S. Set-Theoretic Methods in Control, 2nd ed.; Birkhäuser: Basle, Switzerland, 2015. [Google Scholar]
- Jin, C.; Wang, R.; Wang, Q. Stabilization of switched systems with time-dependent switching signal. J. Frankl. Inst.-Eng. Appl. Math. 2020, 357, 13552–13568. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Sample Size | |||
|---|---|---|---|
| (a) True values: = 1, = 0.6, = 0.2 | |||
| 100 | 0.9875 | 0.5999 | 0.2641 |
| Bias | 0.0124 | 0.0001 | −0.0641 |
| Standard Error | 0.1755 | 0.2065 | 0.1705 |
| 300 | 0.9858 | 0.6192 | 0.2627 |
| Bias | 0.0141 | −0.0192 | −0.0627 |
| Standard Error | 0.1082 | 0.2049 | 0.1085 |
| 700 | 0.9831 | 0.6489 | 0.2663 |
| Bias | 0.0168 | −0.0489 | −0.0663 |
| Standard Error | 0.0699 | 0.1922 | 0.0717 |
| 1000 | 0.9817 | 0.6718 | 0.2684 |
| Bias | 0.0182 | −0.0718 | −0.0684 |
| Standard Error | 0.0597 | 0.1829 | 0.0600 |
| (b) True values: = 4, = 0.7, = 0.1 | |||
| 100 | 3.7816 | 0.6173 | 0.1690 |
| Bias | 0.2183 | 0.0826 | −0.0690 |
| Standard Error | 0.5296 | 0.2031 | 0.1353 |
| 300 | 3.8872 | 0.6611 | 0.1394 |
| Bias | 0.1127 | 0.0388 | −0.0394 |
| Standard Error | 0.3364 | 0.1767 | 0.0855 |
| 700 | 3.9123 | 0.7208 | 0.1324 |
| Bias | 0.0876 | −0.0208 | −0.0324 |
| Standard Error | 0.2337 | 0.1353 | 0.0599 |
| 1000 | 3.9144 | 0.7430 | 0.1322 |
| Bias | 0.0855 | −0.0430 | −0.0322 |
| Standard Error | 0.2012 | 0.1142 | 0.0514 |
| (c) True values: = 5, = 0.5, = 0.1 | |||
| 100 | 4.7799 | 0.5709 | 0.1556 |
| Bias | 0.2200 | −0.0709 | −0.0556 |
| Standard Error | 0.5777 | 0.2059 | 0.1142 |
| 300 | 4.9129 | 0.5703 | 0.1279 |
| Bias | 0.0870 | −0.0703 | −0.0279 |
| Standard Error | 0.3715 | 0.1852 | 0.0730 |
| 700 | 4.9343 | 0.5688 | 0.1243 |
| Bias | 0.0656 | −0.0688 | −0.0243 |
| Standard Error | 0.2615 | 0.1529 | 0.0520 |
| 1000 | 4.9340 | 0.5738 | 0.1245 |
| Bias | 0.0659 | −0.0738 | −0.0245 |
| Standard Error | 0.2211 | 0.1330 | 0.0442 |
| n | |||||
|---|---|---|---|---|---|
| 100 | 250 | 500 | |||
| 3 | 0.4 | 0 | 0.054 | 0.057 | 0.058 |
| 0.5 | 0.431 | 0.877 | 0.937 | ||
| 5 | 0.4 | 0 | 0.053 | 0.057 | 0.047 |
| 0.3 | 0.447 | 0.824 | 0.901 | ||
| 6 | 0.3 | 0 | 0.052 | 0.055 | 0.047 |
| 0.4 | 0.63 | 0.8 | 0.99 | ||
| 7 | 0.7 | 0 | 0.052 | 0.046 | 0.053 |
| 0.8 | 0.998 | 1 | 1 | ||
| DCINMA(1) | 3.21 | 0.47 | 0.80 |
| INMA(1) | 3.82 | 0.24 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, K.; Wang, H. A New Overdispersed Integer-Valued Moving Average Model with Dependent Counting Series. Entropy 2021, 23, 706. https://doi.org/10.3390/e23060706
Yu K, Wang H. A New Overdispersed Integer-Valued Moving Average Model with Dependent Counting Series. Entropy. 2021; 23(6):706. https://doi.org/10.3390/e23060706
Chicago/Turabian StyleYu, Kaizhi, and Huiqiao Wang. 2021. "A New Overdispersed Integer-Valued Moving Average Model with Dependent Counting Series" Entropy 23, no. 6: 706. https://doi.org/10.3390/e23060706