This part uses the BONJE algorithm to select the appropriate neighborhood radius for different data sets and designs different comparative experiments to prove the efficiency of the BONJE algorithm in feature selection.
4.3. Neighborhood Radius Selection
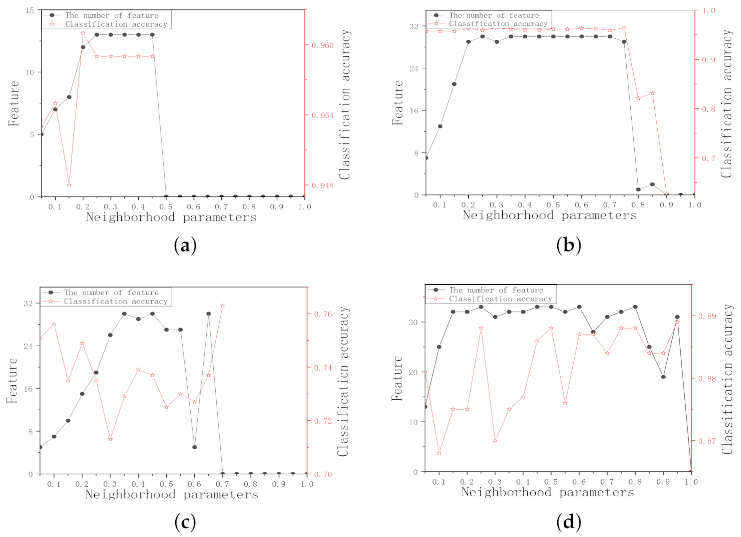
Since the neighborhood radius affects the granularity of neighborhood information, and thus neighborhood joint entropy, it is very important to choose a proper neighborhood radius. In order to unify the value of the neighborhood radius, eliminate the difference in dimensions and make each feature be treated equally by the classifier, this experiment, first, normalizes the data (
), then the neighborhood radius is set in [0.05, 1] with 0.05 as the interval. The number of selected features and the three classifiers average classification accuracy in the different neighborhood radii are shown in
Figure 1.
For Wine data set in
Figure 1a, as the neighborhood radius value increases, the number of selected features increases sharply. The number of selected features is small when the neighborhood radius value is in the interval [0.05, 0.15] and the average classification accuracy reaches the highest when
= 0.1 in this interval. Similar to Wine data set, the
values of WDBC and WPBC data sets are set to 0.05 and 0.1, respectively. For Ionosphere data set in
Figure 1d, the average classification accuracy is higher when the neighborhood radius value is in the interval [0.05, 0.2] and the number of selected features is the least when
= 0.05 in this interval. For Colon data set in
Figure 1e, the change trend of the average classification accuracy is obvious. The number of selected features is small, and the classification accuracy is higher when
= 0.25. Similar to Colon data set, the
values of SRBCT, DLBCL, Leukemia, and Lung data sets can be set to 0.15, 0.3, 0.3, and 0.45, respectively. Therefore, the neighborhood radius values of the 9 data sets should be within [0.05, 0.45].
4.4. Classification Results of Bonje Algorithm
This part of the experiment compares the classification accuracy and the number of features between the original data and the feature subset selected by the BONJE algorithm. The comparison results are shown in
Table 3. The neighborhood radius selected for different data sets are listed in the last column. In addition, the feature subsets selected by the BONJE algorithm for different data sets are shown in
Table 4. Please note that the boldface indicates the better value in the comparison data.
From the comparison of average classification accuracy in
Table 3, it can be seen that the average classification accuracy of the BONJE algorithm on the Wine, WDBC, and Ionosphere data sets is slightly lower than the original data by 0.2%, 0.2%, and 0.8%, respectively. The accuracy loss caused by the BONJE algorithm is controlled within 1%, which shows that the BONJE algorithm maintains the classification accuracy of the original data. The average classification accuracy of the BONJE algorithm on the WPBC, Colon, SRBCT, DLBCL, Leukemia, and Lung data sets is higher than the original data by 1.5%, 4.8%, 3.7%, 7.4%, 7.4%, 2.5%, respectively, which indicates that the BONJE algorithm eliminates many redundant features and improves the classification accuracy of the data set. From the comparison of feature number in
Table 3, it can be seen that BONJE algorithm can delete redundant features without reducing the classification accuracy, especially in high-dimensional data sets. In summary, the BONJE algorithm can effectively select the optimal feature subset, and the feature selection result can maintain or improve the classification ability of the data set.
4.6. The Performance of BONJE Algorithm on High-Dimensional Data Sets
This part of the experiment compares the BONJE algorithm with four other advanced entropy-based feature selection algorithms from the perspective of different high-dimensional data sets. The four entropy-based feature selection algorithms are: (1) the mutual entropy-based attribute reduction algorithm (MEAR) [
42], (2) the entropy gain-based gene selection algorithm (EGGS) [
17], (3) the EGGS algorithm combined with the Fisher score (EGES-FS) [
29], (4) feature selection algorithm with the Fisher score based on decision neighborhood entropy (FSDNE) [
18].
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12 show the experimental results of five different entropy-based feature selection algorithms.
As shown in
Table 8, the KNN classification accuracy and C4.5 classification accuracy of the BONJE algorithm are better than other algorithms. Although the SVM classification accuracy of the BONJE algorithm is slightly lower than that of the first-ranked MEAR algorithm by 0.9%, the average classification accuracy of the BONJE algorithm is much higher than the second-ranked FSDNE algorithm by 3.5%. In general, the BONJE algorithm has excellent performance on the Colon data set.
Table 9 shows that the KNN classification accuracy and C4.5 classification accuracy of the BONJE algorithm are better than other algorithms. Although the SVM classification accuracy of the BONJE algorithm is lower than that of the first-ranked FSDNE algorithm by 1.5%, the average classification accuracy of the BONJE algorithm is much higher than the second-ranked FSDNE algorithm by 4.2%. Therefore, BONJE has stable classification performance on the SRBCT data set.
According to the experimental results in
Table 10, it can be clearly seen that the KNN classification accuracy, SVM classification accuracy and C4.5 classification accuracy of the BONJE algorithm are better than other algorithms. Compared with the BONJE algorithm, the MEAR and EGGS-FS algorithms select fewer features, but the average classification accuracy of the MEAR and EGGS-FS algorithms is much lower than the BONJE algorithm. Therefore, the BONJE algorithm can delete many redundant features on the DLBCL data set without reducing the data classification ability.
According to the results in
Table 11, although the KNN classification accuracy of the BONJE algorithm is lower than that of the FSDNE algorithm, the SVM classification accuracy and C4.5 classification accuracy of the BONJE algorithm are as high as 95.8% and 94.4%, respectively. The average classification accuracy of the BONJE algorithm is 1.5% higher than that of the second-ranked FSDNE algorithm. Therefore, the BONJE algorithm can effectively select feature subsets on the Leukemia data set and improve the classification ability of the data set.
It can be seen from
Table 12 that the number of features selected by the BONJE algorithm is relatively high compared with other algorithms, but the BONJE algorithm has the highest average classification accuracy. Therefore, the BONJE algorithm can effectively reduce noise and improve classification accuracy on the Lung data set.
Based on the above experimental results and analyses, the BONJE algorithm can effectively select feature subsets under high-dimensional data, and the feature selection results can improve the classification ability of the data set.
4.7. Comparison of BONJE Algorithm and Multiple Dimensionality Reduction Algorithms
To further verify the reduction performance and classification ability of the BONJE algorithm, this part of the experiment compares the BONJE algorithm with other 10 reduction algorithms from the perspective of the number of selected features and SVM classification accuracy on 3 representative tumor data sets (Colon, Leukemia, Lung). The ten different dimensionality reduction methods are: (1) the neighborhood rough set-based reduction algorithm (NRS) [
35], (2) feature selection algorithm with Fisher linear discriminant (FLD-NRS) [
32], (3) the gene selection algorithm based on locally linear embedding (LLE-NRS) [
43], (4) the Relief algorithm [
44] combined with the NRS algorithm(Relief + NRS) [
35], (5) the fuzzy back-ward feature algorithm (FBFE) [
44], (6) the binary differential evolution algorithm (BDE) [
2], (7) the sequential forward selection algorithm (SFS) [
29], (8) the Spearman’s rank correlation coefficient algorithm (SC2) [
36], (9) the mutual information maximization algorithm (MIM) [
2], (10) feature selection algorithm with the Fisher score based on decision neighborhood entropy (FSDNE) [
18].
Table 13 and
Table 14 show the experimental results of 11 dimensionality reduction algorithms.
According to the results in
Table 13 and
Table 14, the SVM classification accuracy of the BONJE and LLE-NRS algorithms on the Colon dataset is the same and ranked second, but the number of features selected by the LLE-NRS algorithm is twice that of BONJE algorithm. The SVM classification accuracy of the BONJE algorithm on the Colon data set is lower than that of the FLD-NRS algorithm, but the SVM classification accuracy of the BONJE algorithm on the Leukemia and Lung data sets is much higher than that of the FLD-NRS algorithm by 13% and 10.5%, respectively, which shows that the classification performance of the BONJE algorithm is more stable. Although the BDE algorithm selects the least number of features on the Colon data set, its SVM classification accuracy is only 75%, which indicates that the BDE algorithm loses some important features in the process of selecting feature subsets. The SVM classification accuracy of the BONJE algorithm on the Leukemia data set is 0.1% lower than that of the first-ranked SFS algorithm, and the number of selected features the BONJE algorithm is only one more than the SFS algorithm, so these two algorithms have similar performance on the Leukemia data set. Compared with other algorithms, the number of features selected by the BONJE algorithm on the Lung data set is higher, but the SVM classification accuracy of the BONJE algorithm is the highest. In general, the BONJE algorithm is at a medium level compared to other algorithms in terms of the number of selected features, and has the highest average classification accuracy in terms of SVM classification accuracy, which is enough to show that BONJE algorithm has a stable dimension reduction performance, and can select features with important classification information in the data set.
4.8. Statistical Analyses
To systematically explore the statistical significance of algorithm classification results, this part of the experiment introduces the Friedman statistic test [
45] and Nemenyi test [
46].
The calculation formula of Friedman statistic test is as follows:
where
M is the number of algorithms,
N is the number of data sets, and
represents the average ranking of the classification accuracy of the
i-th algorithm on all data sets.
is an F-distribution with
and
degrees of freedom.
If the null hypothesis, all algorithms have the same performance, is rejected, it means that the performance of the algorithms is significantly different. Then, the Nemenyi test is used as a post-hoc test for algorithm comparison. If the average ranking difference between the algorithms is greater than the critical distance , it means that the algorithm with a high average ranking is better than the algorithm with a low average ranking.
The calculation formula of the critical distance
is as follows:
where
is the critical list value of the test,
represents the significance level of Bonferroni-Dunn.
According to the classification accuracy results of
Table 6 and
Table 7 on low-dimensional data sets, the rankings of the five feature selection algorithms under the KNN and SVM classifiers are shown in
Table 15 and
Table 16, respectively. Please note that the content in parentheses in all tables is the classification accuracy under the corresponding classifier
According to the algorithm rankings in
Table 15 and
Table 16, the two evaluation measurement values (Friedman statistics
and Iman-Davenport test
) of the five feature selection algorithms under the KNN and SVM classifiers are shown in
Table 17.
When the significance level
, the critical value of Friedman statistic test
. It can be seen from
Table 17 that the
values under the KNN and SVM classifiers are both greater than
, so the null hypothesis under the two classifiers is rejected. Then Nemenyi test is used as a post-hoc test to compare the algorithm performance, and the comparison results are shown in
Figure 2. It is worth noting that the average ranking of each algorithm is plotted along the axis in the graph, and the best ranking in the axis is on the left. In particular, when there are thick lines between the algorithms, it means that the classification capabilities of these algorithms are similar, otherwise, they will be regarded as significantly different from each other [
47].
It can be clearly seen from
Figure 2 that BONJE algorithm ranks first under the two classifiers. The classification performance of the BONJE, MDNRS, RS and NRS algorithms under the KNN classifier is similar, and the BONJE algorithm is significantly better than the CDA algorithm. Under the SVM classifier, the classification performance of BONJE, RS, CDA and MDNRS algorithms is similar, and the BONJE algorithm performs better than the NRS algorithm
According to the algorithm rankings in
Table 18,
Table 19 and
Table 20, the two evaluation measurement values of the five entropy-based feature selection algorithms under the KNN, SVM, and C4.5 classifiers are shown in
Table 21.
When the significance level
, the critical value of Friedman statistic test
, so null hypothesis under the three classifiers is rejected. The Nemenyi test is used as a post-hoc test to compare the performance of the algorithms, and the comparison results are shown in
Figure 3.
According to the results in
Figure 3, it can be seen that the ranking of BONJE algorithm is the best under the three classifiers. Under the KNN classifier, the classification performance of the BONJE, FSDNE and EGGS-FS algorithms is similar and the BONJE algorithm is significantly better than the MEAR and EGGS algorithms. Under the SVM classifier, the classification performance of the BONJE, FSDNE, EGGS-FS and FSDNE algorithms is similar, and the BONJE algorithm performs better than the EGGS algorithm. Under the C4.5 classifier, the BONJE algorithm has better classification performance than the EGGS and EGGS-FS algorithms.
According to the classification accuracy results of
Table 14 on three representative tumor data sets, the rankings of the 11 dimensionality reduction algorithms under the SVM classifier are shown in
Table 22.
According to the ranking in
Table 22, the
and
of the 11 dimensionality reduction algorithms under the SVM classifier. When the significance level
, the critical value of Friedman statistic test
.
is greater than
, so the null hypothesis under the SVM classifier is rejected. The Nemenyi test is used as a post-hoc test to compare the algorithm performance, and the comparison result is shown in
Figure 4.
Figure 4 shows that the dimensionality reduction effect of BONJE is significantly better than NRS algorithm. In addition, BONJE algorithm has the highest ranking, which shows that BONJE algorithm has stable classification performance compared to other algorithms.
In general, the classification results of BONJE algorithm under different data sets are significantly better than different algorithms, which shows that the classification performance of BONJE algorithm is more stable and efficient from a statistical point of view.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}