
Dynamical Analysis of the Dow Jones Index Using Dimensionality Reduction and Visualization



Abstract
:1. Introduction
2. Mathematical Concepts and Tools
2.1. Distances
2.2. Dimensionality Reduction and Visualization
2.2.1. The Hierarchical Clustering
2.2.2. The Multidimensional Scaling
2.2.3. The t-Distributed Stochastic Neighbor Embedding
2.2.4. The Uniform Manifold Approximation and Projection
3. Description of the Dataset
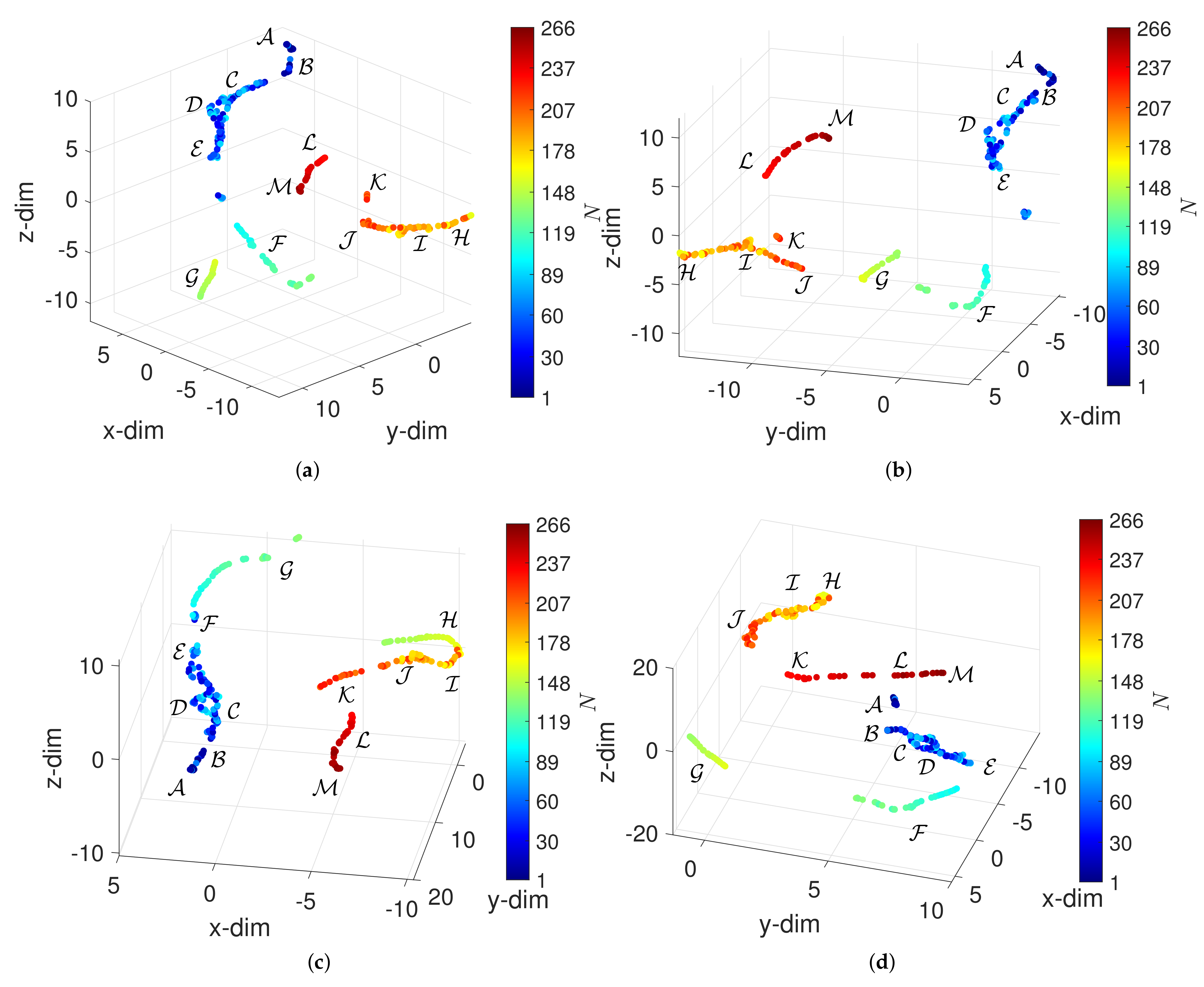
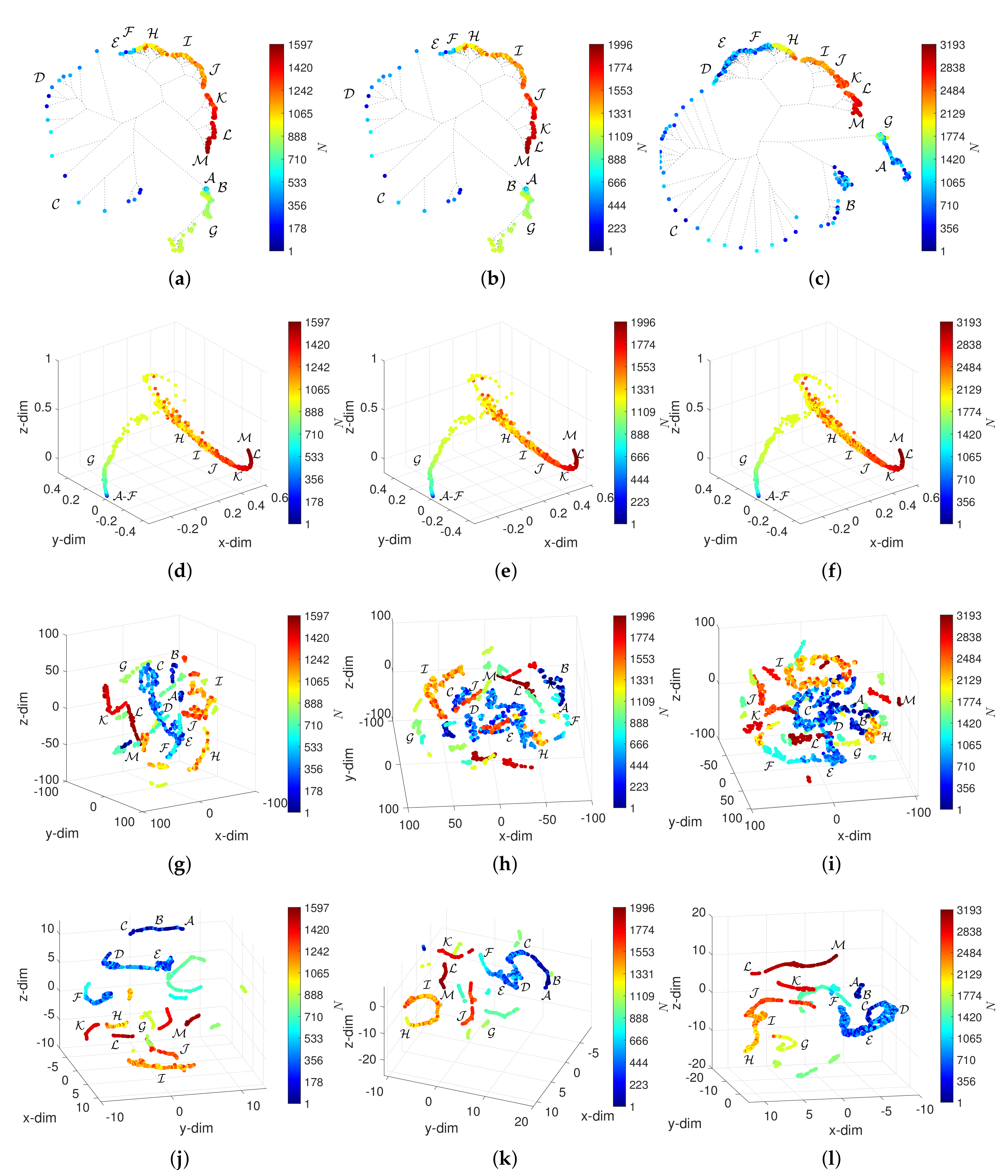
4. Analysis and Visualization of the DJIA
4.1. The HC Analysis and Visualization of the DJIA
4.2. The MDS Analysis and Visualization of the DJIA
4.3. The t-SNE Analysis and Visualization of the DJIA
4.4. The UMAP Analysis and Visualization of the DJIA
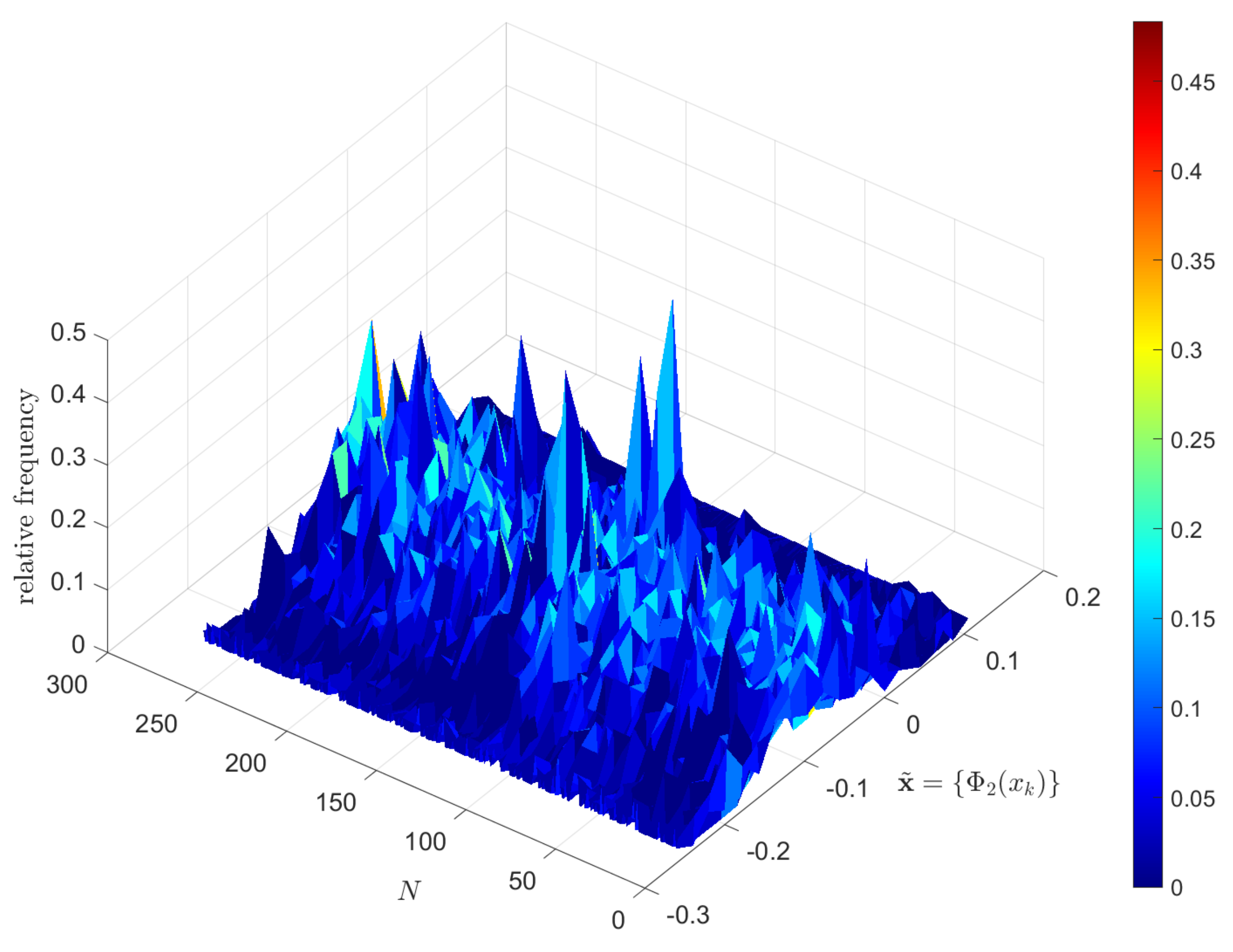
5. Assessing the Effect of and in the Visualization of the DJIA Dynamics
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pinto, C.; Mendes Lopes, A.; Machado, J. A review of power laws in real life phenomena. Commun. Nonlinear Sci. Numer. Simul. 2012, 17, 3558–3578. [Google Scholar] [CrossRef] [Green Version]
- Tarasova, V.V.; Tarasov, V.E. Concept of dynamic memory in economics. Commun. Nonlinear Sci. Numer. Simul. 2018, 55, 127–145. [Google Scholar] [CrossRef] [Green Version]
- Tarasov, V.E. Fractional econophysics: Market price dynamics with memory effects. Phys. A Stat. Mech. Its Appl. 2020, 557, 124865. [Google Scholar] [CrossRef]
- Tarasov, V.E.; Tarasova, V.V. Economic Dynamics with Memory: Fractional Calculus Approach; Walter de Gruyter GmbH & Co KG: Berlin, Germany; Boston, MA, USA, 2021; Volume 8. [Google Scholar]
- Lopes, A.M.; Tenreiro Machado, J.; Huffstot, J.S.; Mata, M.E. Dynamical analysis of the global business-cycle synchronization. PLoS ONE 2018, 13, e0191491. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lopes, A.M.; Tenreiro Machado, J.; Galhano, A.M. Multidimensional scaling visualization using parametric entropy. Int. J. Bifurc. Chaos 2015, 25, 1540017. [Google Scholar] [CrossRef] [Green Version]
- Meyers, R.A. Complex Systems in Finance and Econometrics; Springer Science & Business Media: New York, NY, USA, 2010. [Google Scholar]
- Xia, P.; Lopes, A.M.; Restivo, M.T. A review of virtual reality and haptics for product assembly: From rigid parts to soft cables. Assem. Autom. 2013. [Google Scholar] [CrossRef]
- Li, J.; Shang, P.; Zhang, X. Financial time series analysis based on fractional and multiscale permutation entropy. Commun. Nonlinear Sci. Numer. Simul. 2019, 78, 104880. [Google Scholar] [CrossRef]
- Machado, J.T.; Lopes, A.M. Fractional state space analysis of temperature time series. Fract. Calc. Appl. Anal. 2015, 18, 1518. [Google Scholar] [CrossRef] [Green Version]
- Lopes, A.M.; Machado, J.T. Dynamical analysis and visualization of tornadoes time series. PLoS ONE 2015, 10, e0120260. [Google Scholar] [CrossRef] [Green Version]
- Lopes, A.M.; Tenreiro Machado, J. Power law behavior and self-similarity in modern industrial accidents. Int. J. Bifurc. Chaos 2015, 25, 1550004. [Google Scholar] [CrossRef] [Green Version]
- Nigmatullin, R.R.; Lino, P.; Maione, G. New Digital Signal Processing Methods: Applications to Measurement and Diagnostics; Springer Nature: Cham, Switzerland, 2020. [Google Scholar]
- Ware, C. Information Visualization: Perception for Design; Elsevier: Waltham, MA, USA, 2012. [Google Scholar]
- Spence, R. Information Visualization: An Introduction; Springer: Cham, Switzerland, 2001; Volume 1. [Google Scholar]
- Van Der Maaten, L.; Postma, E.; Van den Herik, J. Dimensionality reduction: A comparative. J. Mach. Learn. Res. 2009, 10, 66–71. [Google Scholar]
- Tenreiro Machado, J.; Lopes, A.M.; Galhano, A.M. Multidimensional scaling visualization using parametric similarity indices. Entropy 2015, 17, 1775–1794. [Google Scholar] [CrossRef] [Green Version]
- Dunteman, G.H. Principal Components Analysis; Number 69; Sage: Newbury Park, CA, USA, 1989. [Google Scholar]
- Thompson, B. Canonical correlation analysis. In Encyclopedia of Statistics in Behavioral Science; John Wiley & Sons: Chichester, UK, 2005. [Google Scholar]
- Tharwat, A.; Gaber, T.; Ibrahim, A.; Hassanien, A.E. Linear discriminant analysis: A detailed tutorial. AI Commun. 2017, 30, 169–190. [Google Scholar] [CrossRef] [Green Version]
- Child, D. The Essentials of Factor Analysis; Cassell Educational: London, UK, 1990. [Google Scholar]
- France, S.L.; Carroll, J.D. Two-way multidimensional scaling: A review. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2010, 41, 644–661. [Google Scholar] [CrossRef]
- Lee, J.A.; Lendasse, A.; Verleysen, M. Nonlinear projection with curvilinear distances: Isomap versus curvilinear distance analysis. Neurocomputing 2004, 57, 49–76. [Google Scholar] [CrossRef]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps for dimensionality reduction and data representation. Neural Comput. 2003, 15, 1373–1396. [Google Scholar] [CrossRef] [Green Version]
- Coifman, R.R.; Lafon, S. Diffusion maps. Appl. Comput. Harmon. Anal. 2006, 21, 5–30. [Google Scholar] [CrossRef] [Green Version]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- Deza, M.M.; Deza, E. Encyclopedia of Distances; Springer: New York, NY, USA, 2009. [Google Scholar]
- Nigmatullin, R.R. Discrete Geometrical Invariants in 3D Space: How Three Random Sequences Can Be Compared in Terms of “Universal” Statistical Parameters. Front. Phys. 2020, 8, 76. [Google Scholar] [CrossRef]
- Hartigan, J.A. Clustering Algorithms; John Wiley & Sons: New York, NY, USA, 1975. [Google Scholar]
- Aggarwal, C.C.; Hinneburg, A.; Keim, D.A. On the Surprising Behavior of Distance Metrics in High Dimensional Space; Springer: Berlin, Germany, 2001. [Google Scholar]
- Sokal, R.R.; Rohlf, F.J. The comparison of dendrograms by objective methods. Taxon 1962, 11, 33–40. [Google Scholar] [CrossRef]
- Hamid, Y.; Sugumaran, M. A t-SNE based non linear dimension reduction for network intrusion detection. Int. J. Inf. Technol. 2020, 12, 125–134. [Google Scholar] [CrossRef]
- Rao, A.; Aditya, A.; Adarsh, B.; Tripathi, S. Supervised Feature Learning for Music Recommendation. In Communications in Computer and Information Science, Proceedings of the International Symposium on Signal Processing and Intelligent Recognition Systems, Chennai, India, 14–17 October 2020; Springer: Singapore, 2020; pp. 122–130. [Google Scholar]
- Li, W.; Cerise, J.E.; Yang, Y.; Han, H. Application of t-SNE to human genetic data. J. Bioinform. Comput. Biol. 2017, 15, 1750017. [Google Scholar] [CrossRef]
- Kobak, D.; Berens, P. The art of using t-SNE for single-cell transcriptomics. Nat. Commun. 2019, 10, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cieslak, M.C.; Castelfranco, A.M.; Roncalli, V.; Lenz, P.H.; Hartline, D.K. t-Distributed Stochastic Neighbor Embedding (t-SNE): A tool for eco-physiological transcriptomic analysis. Mar. Genom. 2020, 51, 100723. [Google Scholar] [CrossRef] [PubMed]
- Becht, E.; McInnes, L.; Healy, J.; Dutertre, C.A.; Kwok, I.W.; Ng, L.G.; Ginhoux, F.; Newell, E.W. Dimensionality reduction for visualizing single-cell data using UMAP. Nat. Biotechnol. 2019, 37, 38–44. [Google Scholar] [CrossRef] [PubMed]
- Dorrity, M.W.; Saunders, L.M.; Queitsch, C.; Fields, S.; Trapnell, C. Dimensionality reduction by UMAP to visualize physical and genetic interactions. Nat. Commun. 2020, 11, 1–6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Papoulis, A. Signal Analysis; McGraw-Hill: New York, NY, USA, 1977. [Google Scholar]
- Saitou, N.; Nei, M. The neighbor-joining method: A new method for reconstructing phylogenetic trees. Mol. Biol. Evol. 1987, 4, 406–425. [Google Scholar]
- Felsenstein, J. PHYLIP (Phylogeny Inference Package), Version 3.5 c; University of Washington: Seattle, WA, USA, 1993. [Google Scholar]
- Meehan, C.; Ebrahimian, J.; Moore, W.; Meehan, S. Uniform Manifold Approximation and Projection (UMAP). 2021. Available online: https://www.mathworks.com/matlabcentral/fileexchange/71902 (accessed on 12 February 2021).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Period | Interval, k | Start Date | End Date | Main Events |
|---|---|---|---|---|
| 28 December 1959 | 30 September 1960 | 1961 Berlin Wall; Bay of Pigs | ||
| 30 September 1960 | 8 June 1962 | |||
| 8 June 1962 | 10 December 1965 | 1962 Cuban Missile Crisis; 1963 John F. Kennedy Assassination; 1964 Vietnam War Begins; 1965 The Great Inflation Begins | ||
| 10 December 1965 | 29 May 1970 | 1967 The Six Day War | ||
| 29 May 1970 | 6 November 1974 | 1972 Watergate; Munich Olympics Massacre; 1973 U.S. Involvement in Vietnam Ends; Arab Oil Embargo; 1974 President Nixon Resigns | ||
| 6 November 1974 | 23 July 1982 | 1977 Panama Canal Treaty; 1979 Iran Hostage Crisis; 1980 Iraq - Iran War; 1981 President Reagan Shot; 1982 Falkland Islands War | ||
| 23 July 1982 | 22 September 1987 | 1983 Grenada Invasion; 1986 U.S. Attacks Libya; Chernobyl Accident; 1987 Financial Panic; Stock Market Crash | ||
| [7237, 10,340] | 22 September 1987 | 13 August 1999 | 1989 U.S. Invades Panama; German Unification; 1991 The Golf War; Soviet Union Collapse; 1992 Civil War in Bosnia; 1993 World Trade Center Terrorist Attack; 1995 Oklahoma Terrorist Attack; 1997 Asian Currency Crisis; Global Stock Market Rout | |
| [10,340, 11,240] | 13 August 1999 | 24 January 2003 | 2000 Bush - Gore Election Crisis; 2001 Terrorist Attack on World Trade Center & Pentagon; Enron Crisis; 2003 War in Iraq | |
| [11,240, 12,500] | 24 January 2003 | 23 November 2007 | 2004 Global War on Terror; 2005 Record High Oil Prices; 2007 Subprime Mortgage; Credit Debacle | |
| [12,500, 12,840] | 23 November 2007 | 13 March 2009 | 2008 Credit Crisis; Financial institution Failures | |
| [12,840, 15,690] | 13 March 2009 | 14 February 2020 | 2010 European Union Crisis; Massive Debt; 2011 U.S. Credit Downgrade; 2012 European Debt; 2013 U.S. Government Shutdown; 2014 Oil Price Decline; 2015 Refugee Crisis; 2016 Brexit Referendum; 2017 Trump Administration; 2018 Warnings About Climate Change; U.S. - China Trade War; President Trump Impeachment Process | |
| [15,690, 15,970] | 14 February 2020 | 12 March 2021 | 2020 COVID19 Pandemics; Black Lives Matter |
| W | N | W | N | ||||
|---|---|---|---|---|---|---|---|
| 90 | 0 | 177 | 30 | 0 | 532 | ||
| 90 | 0.2 | 221 | 30 | 0.2 | 665 | ||
| 90 | 0.5 | 353 | 30 | 0.5 | 1063 | ||
| 60 | 0 | 266 | 10 | 0 | 1597 | ||
| 60 | 0.2 | 332 | 10 | 0.2 | 1996 | ||
| 60 | 0.5 | 531 | 10 | 0.5 | 3193 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lopes, A.M.; Tenreiro Machado, J.A. Dynamical Analysis of the Dow Jones Index Using Dimensionality Reduction and Visualization. Entropy 2021, 23, 600. https://doi.org/10.3390/e23050600
Lopes AM, Tenreiro Machado JA. Dynamical Analysis of the Dow Jones Index Using Dimensionality Reduction and Visualization. Entropy. 2021; 23(5):600. https://doi.org/10.3390/e23050600
Chicago/Turabian StyleLopes, António M., and Jóse A. Tenreiro Machado. 2021. "Dynamical Analysis of the Dow Jones Index Using Dimensionality Reduction and Visualization" Entropy 23, no. 5: 600. https://doi.org/10.3390/e23050600