1. Introduction
Sentiment analysis is a method to automatically classify large amounts of text into positive or negative sentiments [
1,
2,
3,
4]. With the explosive growth of social media, organizations and companies have started to use big online data for their product enhancement and proactive decision making. In recent years, social media, forums, blogs, and other forms of online communication tools have radically affected everyday life, especially how people express their opinions. The extraction of useful information (for example, people’s opinions about company brands) from the huge amount of unstructured data is important for most companies and organizations [
5,
6,
7,
8,
9]. The application of sentiment analysis is not limited to product or movie reviews. Researchers have also applied it to areas such as news, politics, sport, etc. For example, in online political debates, sentiment analysis can be used to identify people’s opinions about a certain candidate or political party [
10,
11,
12,
13,
14,
15,
16]. However, sentiment analysis has been widely used for the English language using traditional and advanced machine learning techniques, and limited research has been conducted to develop models for the Persian language [
17,
18,
19,
20].
In the literature, Sentiment analysis has been performed at both the document and sentence level. The document-level sentiment analysis has been used to classify the sentiments expressed in the document (positive or negative), whereas, at the sentence level, the models have been used to identify the sentiments expressed only in the sentence under analysis [
21,
22,
23,
24,
25,
26,
27]. For sentiment analysis, there are two widely used approaches: (1) Lexicon-based approach that uses lexicons (a dictionary of words and corresponding polarities) to assign polarity; (2) Machine learning approach which requires a large labelled dataset with manual annotation [
28,
29,
30,
31,
32]. Recently, deep-machine-learning-based automated feature engineering and classification has been shown to outperform state-of-the-art, manual-feature-engineering-based shallow classification. However, both deep and shallow machine learning algorithms have widely been applied to English Corpora, with little work being carried out to develop deep learning models for Persian sentiment analysis [
33,
34,
35,
36,
37,
38,
39,
40,
41,
42].
Persian is the official language of Iran and Afghanistan, with more than one hundred million speakers. A large amount of unstructured text is available online, including newspapers, books, web pages, movie reviews, etc. [
43,
44,
45]. In this study, a novel corpus for Persian sentiment analysis is developed and evaluated using both shallow and deep machine learning algorithms. For shallow learning, logistic regression, support vector machine (SVM), and multilayer perceptron (MLP) classifiers are used. For deep learning, 1D convolutional neural network (CNN), 2D-CNN, stacked long short-term memory (LSTM), and Bidirectional LSTM algorithms have been utilized.
To the best of our knowledge, this is the first work on exploiting deep-learning-based automated feature engineering for Persian sentiment analysis. In addition, the fastText word embedding is used to obtain a vector representation of Persian words. The contextual features are extracted using deep learning algorithms and their polarity detection performances are compared with traditional shallow classifiers.
In summary, the paper reports two major contributions, outlined below:
We proposed novel architectures for deep learning classifiers such as convolutional neural network (CNN) and long short-term memory (LSTM) to identify the polarity of the Persian text;
An ablation study of our proposed deep learning reveals the importance of individual layers in the context of the complete framework.
The rest of the paper is organized as follows: In
Section 2, related work on sentiment analysis for English, Persian, and other languages is presented.
Section 3 presents our proposed novel approach for Persian sentiment analysis. In
Section 4, experimental results are presented. Finally,
Section 5 concludes this work with suggestions for future work.
4. Experimental Results
In this section, we describe the experimental setup, followed by results and discussions. To evaluate the performance of the proposed approach, movie reviews are used. For data labelling, the PerSent lexicon is used, which assigns a polarity to individual events in the dataset. The trained and test dataset is converted into vectors to train LSTM, CNN, and SVM classifiers. The n-gram features (bigram, trigram) and POS features (noun, adjective, verb and adverb) are extracted from Persian movie reviews. The extracted features are converted into bag of words and principal component analysis is used to reduce the dimensionality of data to two hundred dimensions. The extracted features are fed into an SVM and a logistic regression classifier.
The parameters of LR, SVM, LSTM, and CNN models are as follows: word embedding dimensions are 300, the number of epochs equal to 200, and batch size is 128. The ML classifiers are trained to classify the sentences into either positive or negative. In addition, it has been shown that the size of the filter has a positive impact on the final results and model achieved a better performance when the filter size was set to a smaller number such as 3.
Table 1 presents the results of SVM using various features and combination of the features. The results shows that nouns outperformed other features. For testing with LSTM and CNN, movie reviews are converted into three hundred dimensional vectors using fasttext. Table 3 presents the results of CNN and LSTM classifiers and a comparison with MLP and autoencoder. The experimental results demonstrate the effectiveness of the autoencoder as compared to MLP. To evaluate the performance of proposed approaches, precision, recall, f-Measure, and prediction accuracy are used as performance matrices
where TP represents, TN, FP, and FN represents true positive, true negative, false positive, and false negative, respectively.
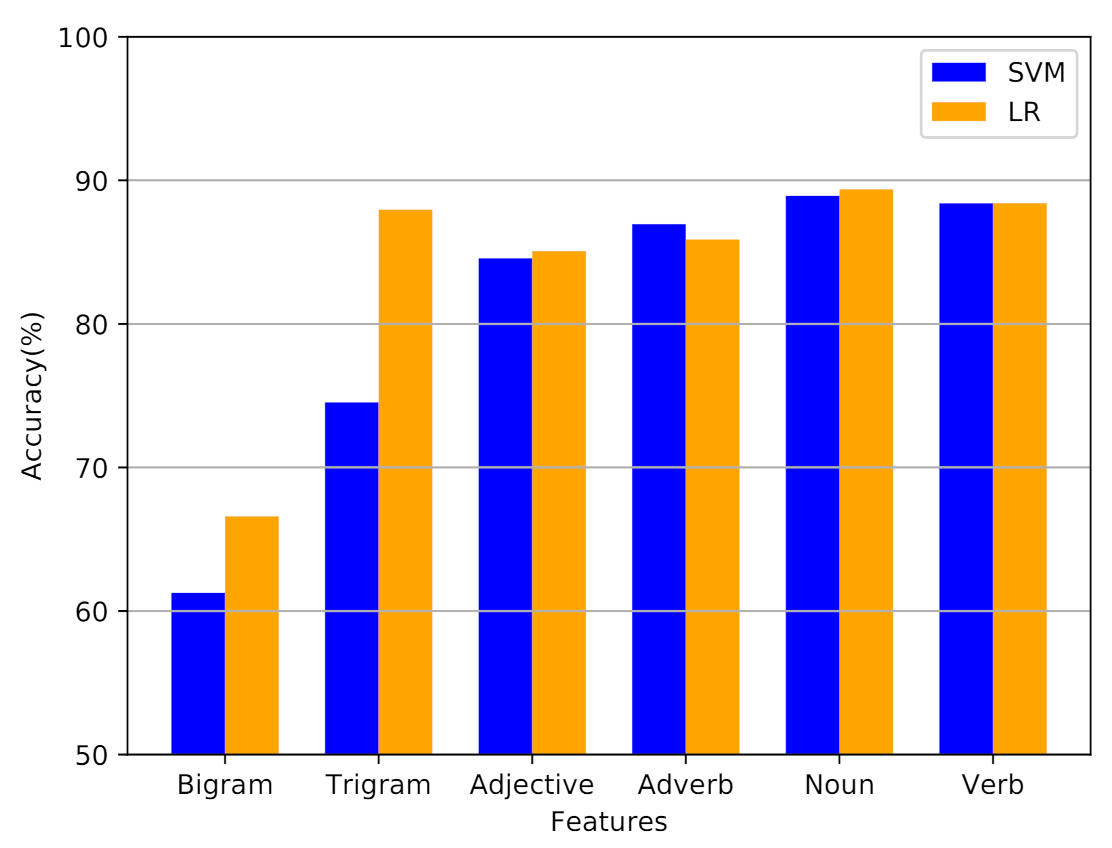
Table 2 indicates the results for SVM and logistic regression. The experimental results shows that the noun achieved better performance as compared to other features such as adjective, adverb, verb, bigram and trigram. The experimental results demonstrate that the LR achieved better accuracy, precision, recall and f-measure as compared to SVM.
The experimental results indicated that using deep learning approaches enhances the performance of sentiment analysis in Persian dataset. The proposed model does not required any feature engineering to extract special features such as n-gram, POS and concept extraction like previous approaches. It is to be noted that the deep learning approaches are based on the pre-trained word vector representation; despite the complexity of the Persian language and the simplicity of the proposed model, there are significant improvements in the BiLSTM in terms of the F-measure and the accuracy compared to traditional machine learning classifiers.
On the other hand, deep learning classifiers achieved a better performance, such as the BiLSTM and 2D-CNN, with fastText word embedding used as features. The fastText model consists of high-quality vector representation using the semantic and syntactical information from the texts; it can also cover the out-of-vocabulary words.
The deep learning approaches are black-box; we cannot understand how the sentiment polarity assigned to sentences, for example, the polarity shifters such as negation, can change the overall polarity of the sentences. However, the Persian language consists of rhetorical and sarcastic sentences which cannot be detected by black-box deep learning approaches.
The deep learning architectures trained and validated using TensorFlow library and NVIDIA Titan X GPU. The deep learning models were trained for 200 epochs using back propagation, with the Adam optimizer minimizing the categorical cross entropy loss function.
Table 3 presents the results of SVM and LR using various features on hotel reviews. Experimental results indicate that the LR achieved better accuracy as compared with SVM. The results show that the use of adjective outperformed other features. Additionally, the adverb feature achieved lower accuracy as compared with other features.
Furthermore,
Table 4 presents the results of CNN and LSTM classifiers on the hotel reviews dataset. Experimental results show the 2D-CNN achieved better accuracy as compared with other classifiers. Additionally, the stacked-BiLSTM received a lower performance as compared with other classifiers; however, it achieved better precision as compared with other classifiers.
Table 5 presents the comparison results for the proposed 1D-CNN with different layers. Experimental results show that the five-layered 1D-CNN architecture generally outperforms other layered architecture. The time to train each model is shown in the last column of
Table 5 Additionally, the recall and F-measure for five-layers outperformed other architectures compared with 2-, 3-, 4-, and 6-layered models.
Table 6 presents the comparison results for the proposed 2D-CNN with different layers. Experimental results show that the five-layer CNN generally outperforms other layers. The time to train each model is shown in the last column of
Table 6. Additionally, the recall and F-measure for layer 5 outperformed other layers.
Table 7 presents the comparison results for different layers of LSTM. Experimental results show that the two-layer LSTM achieved better results as compared with other layers. The time to train the model is shown in
Table 7. Additionally, experimental results show that the two-layer LSTM achieved better precision, recall, f-measure as compared with other layers.
Table 8 presents the comparison results for different layers of BiLSTM. Experimental results show that the two-layer BiLSTM achieved better results as compared with the one-layer BiLSTM. Additionally, experimental results show that the two-layer BiLSTM achieved better precision, recall and f-measure as compared with the one-layer BiLSTM. Experimental results show the training time is increased as the number of layers increases.
The results demonstrate that the stacked-BiLSTM model outperformed all other methods. In addition, it is observed that CNN and LSTM classifiers can effectively detect the polarity of the movie reviews. Furthermore, they also help in detecting contextual information as compared to traditional classifiers. It is shown that deep learning approaches are more optimal for sentimental analysis due to their having less over-fitting and better generalization.
The hotel reviews corpus is used to compare how our approach performs in a new domain compared to state-of-the-art approaches, including multilingual methods. The hotel reviews were collected and, after data pre-processing, the extracted features were converted into TF-IDF and the machine learning was applied to evaluate the performance of the approach. The overall accuracy of their proposed approach is 87%. However, for their experiments, a five-fold cross-validation was used [
61]. In our experiments, we used 60% for training, and the rest of the data were used for testing and to validate the performance of the trained classifiers, with 30% used for testing and 10% for the validation set.
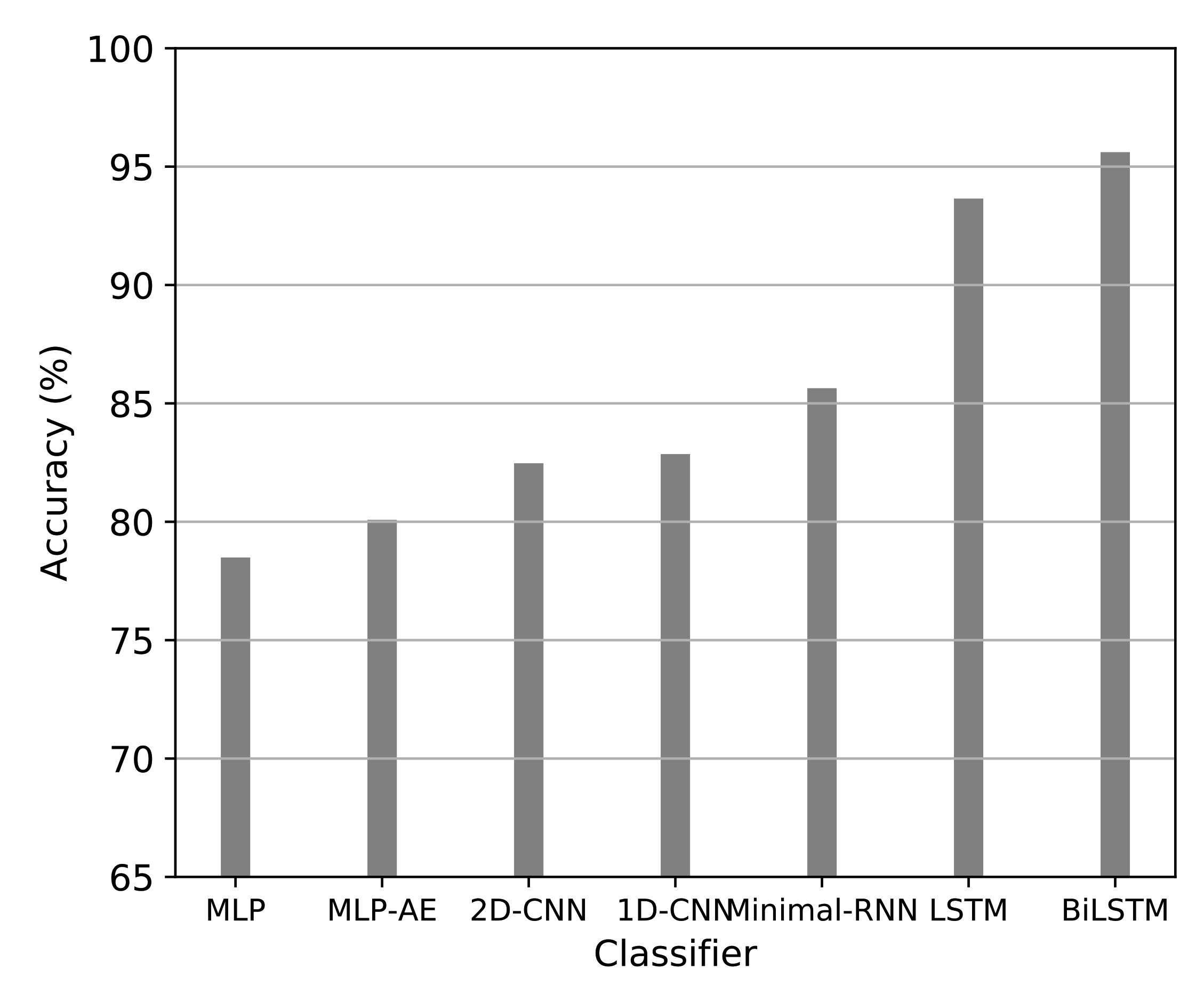
Figure 5 presents the accuracy of both shallow and deep learning classifiers. It can be seen that the stacked-bidirectional-LSTM outperformed all other machine learning algorithms.
Figure 6 depicts the classification performance of SVM and LR using different feature types. It can be seen that the noun features help in achieving a better performance as compared to other features.
The results demonstrate that the stacked-BiLSTM model outperformed all other methods. In addition, it is observed that the CNN and LSTM classifiers can effectively detect the polarity of movie reviews. Furthermore, they also help in detecting contextual information as compared to traditional classifiers. It is shown that the deep learning approaches are more optimal for sentimental analysis due to their having less over-fitting and better generalization.
The LSTM achieved a better performance than shallow learning because, in deep learning approaches, there is no requirement for feature selection. The experimental results show that the LSTM can efficiently reflects the delays and make the input more convenient, and helps the LSTM achieve a better performance by optimizing the input form and network structure based on the clearer physical meaning. However, in order to improve the performance further, there is a need to develop an additional lexicon or grammar-rule based approach to detect sarcastic and irony sentences’ polarity. For example <ĉy bgm, nmydwnm xwb bwd yA bd bwd>, “What to say, I do not know the movie was good or bad”. The experimental results indicated that the word embedding models can identify the overall sentiment polarity of the sentiment effectively. The classification performance is better for movie reviews than casual comments. This shows the feasibility of an LSTM-based approach for Persian movie sentiment classification.
The trigram performed well as compared to the bigram, as it is more informative; for example, it consists of three word combinations, making it easier for the machine learning model to identify the overall sentiment polarity. For example, <fylm xwb bwd> “movie was great” as opposite to <fylm> “movie”. However, other studies, such as [
88], showed that trigrams achieved a better performance as compared to bigrams.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}