1. Introduction
Image fusion is a significant technology to enhance images, aiming to synthesize images by integrating complementary information from several source images captured by different sensors [
1,
2]. It has been applied in many fields, including computer vision, medical image processing, and remote sensing [
3]. Especially for object detection or tracking tasks, infrared and visible image fusion can highlight the object and offer more details. Infrared images can retain thermal radiation; thus, the thermal targets can be distinguished from their backgrounds based on thermal radiation differences, even in poor lighting conditions. Relatively, reflected light captured by visible light sensors could be represented in visible images; hence, visible images can provide texture details with high spatial resolution and definition, in a manner consistent with the human visual system [
4,
5]. Therefore, fused images can simultaneously preserve the texture details of visible images and the contrast of infrared images, benefiting subsequent tasks [
6,
7,
8].
Over the past few years, increasingly, infrared and visible image fusion methods have been proposed. The methods can be classified as multi-scale transform-, sparse representation-, neural network-, subspace-, saliency-, and deep learning-based methods and hybrid methods. The existing fusion methods have three key points: image transformation, activity level measurement, and fusion rule designing. Based on these three points, a large number of successful fusion methods have emerged.
Although existing fusion methods can achieve good results, several aspects can be improved. First, artificial rule designing makes the hand-crafted methods more and more complex and time consuming [
9]. Second, GAN-based infrared and visible image fusion lack a ground-truth; thus, it is difficult to design a comprehensive input for the discriminator to specify high-level tasks. There are two existing solutions to this problem, either taking visible images as references or learning a generative model via the dual-discriminator using both infrared and visible images as the input [
10,
11]. However, The first solution leads to thermal prominence, gradually reducing as the adversarial game proceeds. The dual-discriminator leads to a more complex network, and it is hard to keep the balance between the generator and dual-discriminator. Third, existing methods ignore the high-level semantic information of the source images. They carry a unified method to extract features from the source images, while source images are manifestations from the different aspects in different semantic regions. Therefore, their fusion results either partially lose the texture details of the visible image or the contrast of the infrared image. It is difficult for the whole image to retain the thermal radiation information of the infrared image and the texture details of the visible image at the same time.
To address these challenges, a generative adversarial network is proposed for infrared and visible image fusion based on semantic segmentation (SSGAN). Firstly, the proposed method is a deep learning-based method without artificial rule designing, which is an end-to-end fusion network with high efficiency. Secondly, the semantic information of the source image is taken into account. The source images are divided into the foregrounds and the backgrounds by utilizing the masks obtained by semantic segmentation. The foregrounds represent the salient semantic object, while the backgrounds represent the target with finer texture details. Thirdly, the generator is divided into the foreground- and the background-path to extract the corresponding information in source images, respectively. Finally, to overcome the lack of a ground-truth, the input images of the discriminator are designed by combining the foregrounds of the infrared images with the backgrounds of the visible images. This can promote the fusion images to preserve more texture details and the thermal radiation information concurrently. Qualitative and quantitative results reveal the advantages of the proposed SSGAN compared to other methods.
The contributions of the current work include the following aspects:
First of all, in order to extract the features of source images better, semantic segmentation is introduced into fusion tasks to divide the source images into the foregrounds and backgrounds. It is convenient to adopt a more targeted feature extraction strategy for the foregrounds and backgrounds.
Secondly, to extract various semantic information, a generator is designed with a dual-encoder-single-decoder model, encoding the corresponding features for different semantic regions by the dual-encoder and fusing different semantic features by the decoder.
Then, the image obtained by combining the foregrounds of the infrared images with the backgrounds of the visible ones is applied as the reference data to make the fused images retain abundant information.
Finally, in order to get the semantic information, the infrared and visible image fusion dataset is annotated, including 60 typical infrared and visible image pairs with labeled images. The dataset is available at
https://github.com/Jilei-Hou/FusionDataset, accessed on 20 March 2021.
The rest of the paper is organized as follows.
Section 2 briefly reviews the related research on infrared and visible image fusion, semantic segmentation, and generative adversarial networks. In
Section 3, we describe the problem formulation, loss function, and network architecture of the proposed SSGAN. In
Section 4, the proposed SSGAN is demonstrated for fusion on publicly available datasets (TNOand INO) with comparisons to five state-of-the-art approaches, followed by some concluding remarks in
Section 5.
3. The Proposed Method
In this section, the proposed SSGAN for infrared and visible image fusion is presented. We begin with a formulation of the infrared and visible image fusion problem as image generation with GAN, and then, the loss function is discussed. Finally, the network architectures of the generator and the discriminator are described.
3.1. Problem Formulation
Infrared images can distinguish targets from their backgrounds due to the difference in thermal radiation even in poor lighting conditions. Visible images can represent texture details with a high spatial resolution. Meanwhile, both preserve the corresponding semantic information. Therefore, infrared and visible image fusion should keep both the radiation information of the infrared images and the texture details of the visible images. The fused images also need to reserve the high-level semantic information of both source images. Additionally, for different semantic targets, the information that fusion images want to retain from infrared and visible images is different. Specifically, the semantic object with thermal radiation information in infrared images takes precedence over the object’s information in visible images. In contrast, the semantic object with texture details in visible images takes precedence over the object’s information in infrared images.
In order to take semantic information into account in the fusion task, this paper proposes a generative adversarial network based on semantic segmentation, named SSGAN. According to the difference of thermal radiation information and texture details, each source image can be divided into a foreground and a background by the mask. The foreground is mainly composed of semantic targets that contain rich thermal radiation information in the infrared image, such as a person and a car. The background is mainly made up of semantic objects with rich texture details in the visible image. The proposed SSGAN can use different feature extraction methods for the foreground and background to better retain the information of the source image. The procedure of the proposed SSGAN is shown in
Figure 1.
In the beginning, the mask with the infrared image’s semantic information is obtained by deeplabv3+, which is a successful model used for semantic segmentation. Then, we take the infrared image
, mask
, and visible image
as the input of the generator
G, whose output is a fused image
. However, It is hard to generate an informative fused image only by the generator. Thus, the discriminator
D is employed to establish an adversarial game with the generator. Specifically, the generator aims to generate an image that can fool the discriminator. The discriminator is committed to distinguishing the generated image from the real image. As the adversarial game proceeds, a better fusion image can be generated by the generator. Moreover, in order to make the discriminator work better, we redesign the discriminator’s input based on semantic segmentation. This is obtained by blending the foreground of the infrared image and the background of the visible image. The production process of the real image
can be formulated as in Equation (
1).
where
,
, and
represent the infrared image, mask, and visible image, respectively. ∘ means the Hadamard operator.
The ultimate goal of SSGAN is to learn a generator network
G conditioned on a visible image
and an infrared image
. The fused image
, generated by the generator
G, is encouraged to be realistic and informative enough to fool the discriminator. By establishing an adversarial game between the generator
G and discriminator
D, the fused image
will gradually contain more and more thermal radiation information of infrared image
and the texture details of visible image
. Mathematically, the adversarial game between the generator
G and discriminator
D can be formulated as in Equation (
2).
where
denotes the reference image that we want the generated image to be close to and
denotes the classification results of the image
.
denotes the fused image generated by the generator, and
represents the classification results of generated data
. Through the adversarial process of the generator and discriminator, the divergence between the distribution of
and
will become smaller.
3.2. Loss Function
Due to the instability of the training process, the original GAN’s success was limited only by the game between the generator and discriminator. To alleviate this shortcoming, this paper introduces content loss
, which is tasked to constrain the similarity between the fused image and source images in the content. Moreover, structural similarity loss is adopted to ensure the structural similarity between the generated image and source images. Thus, the loss function of the generator
G consists of three parts: adversarial loss
, content loss
, and structural similarity loss
. The whole loss function can be defined as in Equation (
3).
where
denotes the total loss of the generator
G,
,
, and
are used to control the trade-off, and the first item
means the typical adversarial loss between generator
G and discriminator
D, which is defined as in Equation (
4).
where
N denotes the number of fused image patches,
the
n-th fused image patch, and
a the value of whether the generator can fool the discriminator.
The second item
represents the content loss. Each source image can be decomposed into thermal radiation information and the texture details in the infrared and visible image fusion task. Its pixel intensities characterize thermal radiation information, while its gradients can characterize texture details. Thus, we can gain an informative fused image by enforcing the fused image
to have similar intensities and gradients to the source images. In a word, the content loss
can be defined as in Equation (
5).
where
H and
W represent the height and width of the source images, respectively.
stands for the two-norm, and ∇ means the gradient operator. The first two terms of
aim to keep the thermal radiation information and texture details of infrared image
. the last two terms of
aim to preserve the thermal radiation information and texture details contained in the visible image
.
,
,
, and
control the trade-off.
It is worth noting that the texture details of visible images and the thermal radiation information of infrared images should be mainly preserved in the fused results, while the thermal radiation information of visible images and the texture detail of infrared images are of secondary importance. Therefore, , .
The last term
denotes the structural similarity loss of
, which can enforce the generated image and source images to have a similar structure.
can be formulated as in Equation (
6).
where
denotes the structural similarity operation. It can be used to measure the structural similarity of two images, which models the loss and distortion according to the similarities in light, contrast, and structure information.
is used to control the trade-off. Mathematically,
between images
x and
y can be defined as in Equation (
7) [
45].
where
denotes the mean value,
represents the standard deviation/covariance, and
,
, and
are the parameters to make the metric stable.
To maintain the game between the generator
G and the discriminator
D, the discriminator is essential for distinguishing the real data and the generated data, the loss function of discriminator
is defined as in Equation (
8).
where
b and
c denote the value for whether the discriminator will trust and
and
represent the classification results of the real data and fused images, respectively.
3.3. Network Architecture
3.3.1. Generator Architecture
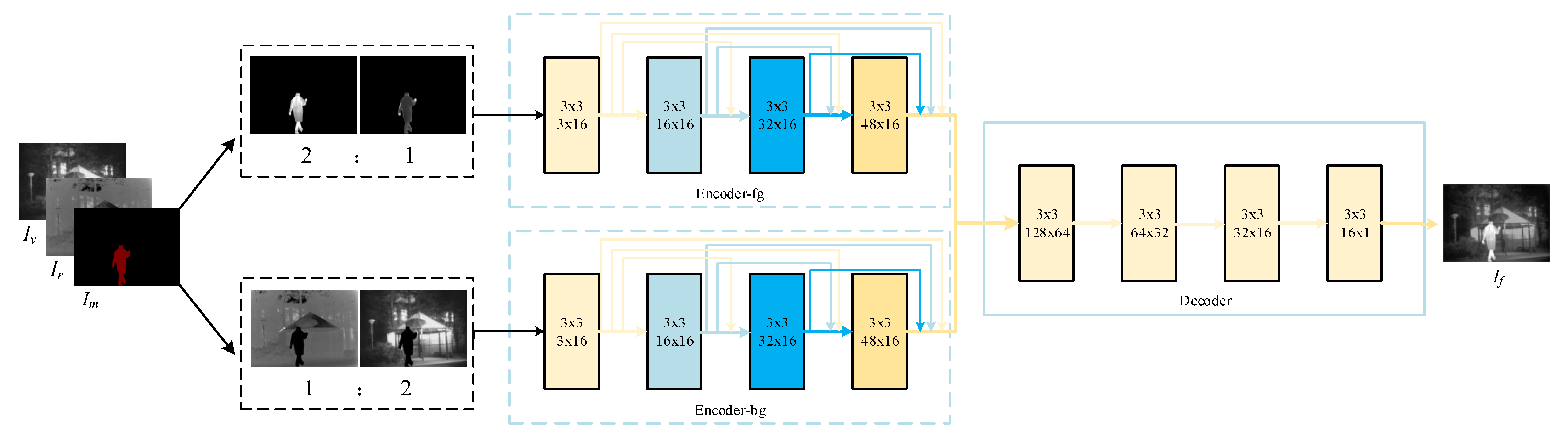
As shown in
Figure 2, the generator adopts a dual-encoder-single-decoder structure. It takes the infrared image
, visible image
, and mask
as the input. Using the mask with semantic information, source images can be divided into the foreground and background. The feature characterization between foreground and background is distinct; therefore, two encoding paths are employed to extract their feature maps, respectively. Moreover, in the ideal foreground, the thermal radiation target is remarkable, and the texture details in the ideal background are rich. In order to achieve the effect as much as possible, two times the infrared image’s foregrounds and one time the visible image’s foreground are input to the foreground encoding path, while the background encoding path takes one time the infrared image’s background and two times the visible image’s backgrounds as the input. Finally, the feature maps of the foreground and background are concatenated as the decoder’s input to generate a fused image.
For each encoder path, four layers with 3 × 3 filters are adopted for feature extraction. Meanwhile, inspired by DenseNet [
46], the dense connection is employed to realize feature reuse in each encoder path. Each layer’s output is cascaded as the input of the next layer. The decoder is a simple framework that contains four convolutional layers with 3 × 3 filters. We concat the outputs of the dual-encoder as the input of the decoder to reconstruct the fused image.
The specific settings of all layers are shown in
Table 1. All kernel sizes were set as 3 × 3, and all strides were set as one with no pooling layers. To avoid exploding/vanishing gradients and speed up training and convergence, batch normalization (BN) and LReLUactivation function were applied.
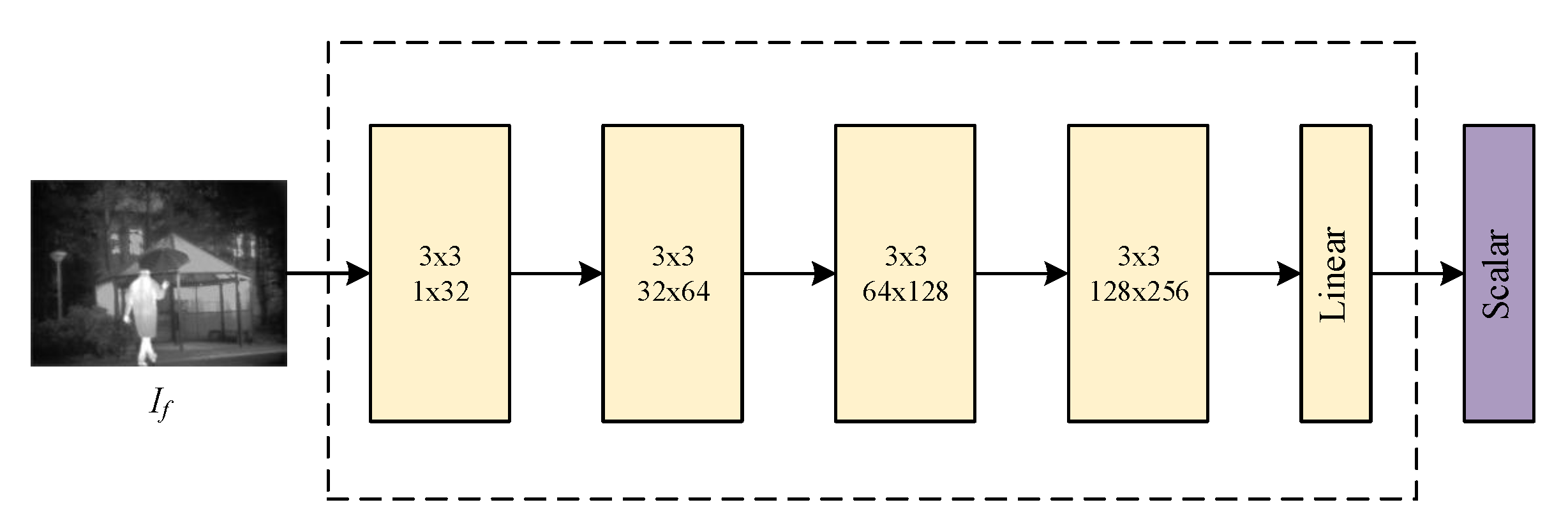
3.3.2. Discriminator Architecture
The discriminator plays an adversarial role against the generator to make the generator’s fused image more realistic and visual. Unlike the traditional single discriminator, it takes only one source image as real data or the dual-discriminator takes the infrared image and visible image as real data at the same time. The discriminator
D of the proposed SSGAN is a simple and effective five-layer convolution neural network with well-designed real data. The discriminator architecture is shown in
Figure 3. The front four layers are all 3 × 3 convolution layers with batch normalization (BN) and the LReLU activation function. In the last layer, the tanh activation function is employed to generate a scalar to estimate the input image’s probability from source images rather than generated by the generator
G. The stride of all convolutional layers was set as two.
4. Experiments
This section focus on verifying the effectiveness of the proposed algorithm through a large number of qualitative and quantitative experiments on the TNO dataset (
https://figshare.com/articles/TNOImageFusionDataset/1008029, accessed on 20 March 2021) and the INO dataset (
https://www.ino.ca/en/technologies/video-analytics-dataset/, accessed on 20 March 2021). First, the experimental datasets and training details are introduced. Second, the parameters used in the proposed method are discussed. Third, a series of recent state-of-the-art methods for comparison and commonly used evaluation indicators are described in detail. Then, the experimental results on the TNO dataset and INO dataset are analyzed. Next, the time complexity is also considered. Finally, the ablation experiments related to the mask and discriminator are illustrated.
4.1. Dataset and Training Details
Dataset: To evaluate the proposed SSGAN, a set of experiments were produced. Different from existing methods, the proposed approach requires the masks with the infrared image’s semantic information. To obtain the masks, the model named deeplabv3+ needs to train on the infrared image dataset with the labeled image. Therefore, our datasets contain two parts: the dataset for semantic segmentation and the dataset for image fusion.
The dataset for semantic segmentation comes from the publicly available dataset for infrared and visible image fusion, which is well matched and does not require image registration [
47,
48,
49,
50]. We selected 136 pairs of infrared and visible images and labeled 60 infrared images to obtain 60 pieces of data that could be used to train deeplabv3+. However, 60 images were insufficient to train a satisfactory model. Therefore, the dataset was extended by flipping and mirroring to gain 180 images, of which 100 images were used for training and 80 images for verification. The remaining 76 images without labels were used for testing. Finally, we got 76 infrared images with the mask, which could be used to extract the foregrounds and backgrounds of source images.
The image fusion dataset was selected from these 76 pairs of infrared and visible images with the masks. Thirty-four infrared and visible image pairs with masks from the TNO dataset were selected to train our SSGAN. Through the mask with semantic information, training data can be divided into foreground and background regions. The expansion strategy of tailoring was adopted to obtain more training data; we set the stride as 14 and cropped each image into image patches with the size of 120 × 120. Eventually, the number of patch pairs for training was 10,168. The remaining 42 image pairs were used to test the performance of the proposed SSGAN.
Training details: In the training process, thirty-two pairs of infrared and visible image patches from the training data were selected to send to the generator. For the discriminator, thirty-two pairs of or fused image patches were used as the input. We first trained the discriminator k times with the optimizer solver Adam, then we trained the generator until reaching the maximum number of training iterations. In the testing process, we cropped the testing data without overlapping and input them into the generator G as a batch. Finally, the results of the generator were connected according to the sequence of cropping to get the final fused image.
4.2. Parameter Settings
The training parameters were crucial to make the network achieve the best fused results. The training parameters of SSGAN were set as follows: The batch size was 32, and the epoch was set as 20. The training step k of the discriminator was set to 2. The learning rate was set as 1 × 10 with exponentially decaying. Parameters a, b, and c are not specific numbers: a and b range from 0.7 to 1.2; c ranges from 0 to 0.3. For the other parameters: , , , , , , , and , they were used to control the trade-off. , = 4, , , , , , .
4.3. Compared Methods and Objective Indexes
As is known to all, the superiority of a method often needs to be proven from qualitative and quantitative perspectives. For a qualitative comparison, the proposed SSGAN was compared to five state-of-the-art methods, including three traditional methods, i.e., GTF [
51], DTCWT [
15], and wavelet [
14], and two deep learning-based methods, i.e., FusionGAN [
10] and DenseFuse [
29]. All these competitors were implemented based on publicly available codes, and the parameters were the default. It is worth noting that all deep learning-based methods ran on the same GPU GTX 1080Ti, while other traditional methods ran on the same CPU i5-6300HQ.
Although qualitative comparisons can evaluate the quality of fused images according to the human visual system, this will be affected by human subjective emotion. To evaluate the performance of fused images more comprehensively, quantitative experiments were also conducted based on the mathematical model’s evaluation index. Moreover, an objective evaluation index cannot fully reflect the quality of the fused images. Therefore, this paper uses four typical quantitative comparison indicators, namely entropy (EN), the standard deviation (SD), mutual information (MI), and visual information fidelity (VIF).
Entropy (EN) is a common method for statistical image features, reflecting the amount of information obtained from infrared and visible images. The mathematical definition of entropy is defined as in Equation (
9) [
52].
where
L denotes the gray level of the image and
is the normalized histogram with the gray value of
i in the fused image.
The standard deviation (SD) represents the dispersion of image gray value relative to the average gray value. The definition of the standard deviation can be defined as in Equation (
10) [
53].
where
is the pixel value of the fused image
F in the
i-th row and the
j-th column, the size of the fused image
F is
, and
is the average pixel value of the fused images.
Mutual information (MI) is a basic concept in information theory, which can measure the correlation between two random variables. In image fusion, mutual information is used to measure the correlation between the source images and the fused images. The definition of mutual information in infrared and visible image fusion is defined as in Equation (
11) [
54].
where
denotes the correlation between infrared images and fused images and
represents the correlation between visible images and fused images. Mutual information between any one source image
X and fused image
F can be defined as in Equation (
12).
where
and
represent the edge histograms of the source image
X and the fused image
F, respectively.
represents the joint histograms of the source image
X and the fused image
F.
The visual information fidelity (VIF) [
55] metric measures the information fidelity of the fused images, which is consistent with the human visual system. VIF aims to build a model to compute the distortion between the fused images and source images.
4.4. Results on the TNO Dataset
4.4.1. Qualitative Comparisons
Qualitative comparisons can evaluate the quality of the fusion image based on the human visual system. Since visible images conform to human visual habits, the fused results of the infrared and visible images should conform to human visual habits to a certain extent. To give some intuitive results on the fusion performance, we selected four typical image pairs from the TNO dataset for qualitative evaluation. The fusion results of the proposed SSGAN and the other five comparison methods are shown in
Figure 4.
The first two columns in
Figure 4 present the original infrared images and visible images. The third column is the semantic masks of the infrared images. The last column is the fusion results of the proposed SSGAN, and the remaining columns correspond to the fusion results of five comparison methods. From the results, we can find that all the methods can obtain satisfactory performance in preserving texture details and thermal radiation information, which can help maintain useful information as much as possible.
However, different fusion methods have their own unique performance, and the infrared thermal target is very obvious in the fused results of GTF and FusionGAN. In other words, the thermal radiation information of the infrared images is preserved successfully. On the other hand, although the salient target information in the fused results obtained by GTF and FusionGAN is well preserved, some of the texture details in visible images are missing. In contrast, for other comparison methods like DTCWT, wavelet, and DenseFuse, the targets (e.g., the human or the building) in the fused images are not as obvious as those in the infrared images. This means that the thermal radiation information in the infrared images is not well preserved, but their texture details are well preserved.
In general, all the comparison methods exploit the information in the source images, either thermal radiation information or texture details. Different from all the comparison methods, the proposed SSGAN is devoted to preserving both thermal radiation information and texture details at the same time. For example, in the second column, the fused images of SSGAN highlight people while retaining the texture of the ground. A similar phenomenon can also be observed in other examples. This demonstrates that the proposed SSGAN has better performance than the other state-of-the-art methods in terms of simultaneously preserving thermal radiation information and texture detail information.
4.4.2. Quantitative Comparisons
The proposed SSGAN was further compared with the five state-of-the-art methods quantitatively on 26 image pairs. The results are summarized in
Figure 5. The proposed SSGAN can generate the largest average values on the four metrics. It is worth mentioning that the larger the EN, the more information is contained in the fused images. Thus, the largest EN means that the proposed SSGAN preserves the most information compared to the other methods. The largest SD demonstrates that the fused images of SSGAN have the highest contrast between the thermal targets and their backgrounds. The largest MI means that considerable information is transferred from source images to the fused image, which indicates a good fusion performance. The largest VIF means that the fused results of SSGAN are more consistent with the human visual system. These results demonstrate that the proposed method can reserve the most information and have the largest image contrast; meanwhile, the results of the proposed method are consistent with the human visual system.
4.5. Results on the INO Dataset
The proposed method and the other five comparison methods were further evaluated on the INO dataset, which is also a dataset commonly used for infrared and visible image fusion. Sixteen visible and infrared image pairs were selected from the video named for both qualitative and quantitative comparisons.
4.5.1. Qualitative Comparisons
The qualitative fused results of the proposed SSGAN and the other five comparison methods are shown in
Figure 6. We can see that the infrared image contains rich thermal radiation information, which helps distinguish the target from the background. In contrast, the visible image preserves rich texture details, which is convenient for human observation. Considering the fusion results, the texture information can be well retained by all six methods, but SSGAN is more like a visible image in overall brightness. Moreover, compared with the other methods, the proposed method has obvious advantages in retaining the thermal radiation information, which can be proven by the fact that the people in the image are better highlighted.
4.5.2. Quantitative Comparisons
In addition to qualitative experiments, the proposed SSGAN was further compared with the above-mentioned competitors quantitatively on 16 image pairs from the INO dataset with four metrics, i.e., entropy (EN), standard deviation (SD), mutual information (MI), and visual information fidelity (VIF). The results are summarized in
Figure 7. We can find that the proposed SSGAN produced the largest averages on all four metrics, and SSGAN had obvious advantages with respect to the MI and VIF metrics. For the EN and SD metrics, only GTF was equivalent to SSGAN in some fused results. These results prove the superiority of the proposed method in quantitative indexes.
The runtime comparison of six methods is also provided in
Table 2. From the results, the conclusion can be drawn that the proposed SSGAN can achieve comparable efficiency compared with the other five methods.
4.6. Ablation Experiments
4.6.1. Experiment Related to the Mask
In order to generate a high quality fused image and overcome the shortcoming of lacking of a ground-truth, we designed the input image of the discriminator based on semantic segmentation. The masks were used to divide the infrared and visible images into foregrounds and backgrounds, respectively. Then, we added the foregrounds of the infrared image and backgrounds of the visible one to get . Since the generation of was closely related to the mask, the role of was verified, and the benefit of the mask was also verified to a certain extent. Therefore, we compared the fused results of SSGAN with the results by replacing with infrared image and visible image , respectively.
The comparison results are given in
Figure 8. We can see that the proposed SSGAN preserved more background details than replacing
with the infrared image
. In the first row, the fused result of SSGAN keep the texture of the tree better. In the second row, the sky’s color is more realistic, and the texture on the ground is clearer. Compared to the results of replacing
with the visible image
, SSGAN has higher contrast in the foreground. In both two rows, the proposed SSGAN can highlight persons better, which is conducive to target detection. These results demonstrate that
, which is designed based on the mask, does improve the quality of the fused image. Therefore, the conclusion can be drawn that the mask obtained by semantic segmentation is indeed useful for fusion tasks.
4.6.2. Experiment without the Discriminator
To verify the effect of the game between the generator and discriminator in GAN, we removed the discriminator, and the whole network merely contained the generator. Thus, the adversarial relationship no longer existed. The training goal was to minimize the content loss
and SSIMloss
. As shown in
Figure 9, compared to the fused results using the network without discriminator, the results of SSGAN have a clear advantage in that it retains more texture details and the results more consistent with the human visual system.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}