
Malicious URL Detection Based on Associative Classification


Abstract
:1. Introduction
2. Related Work
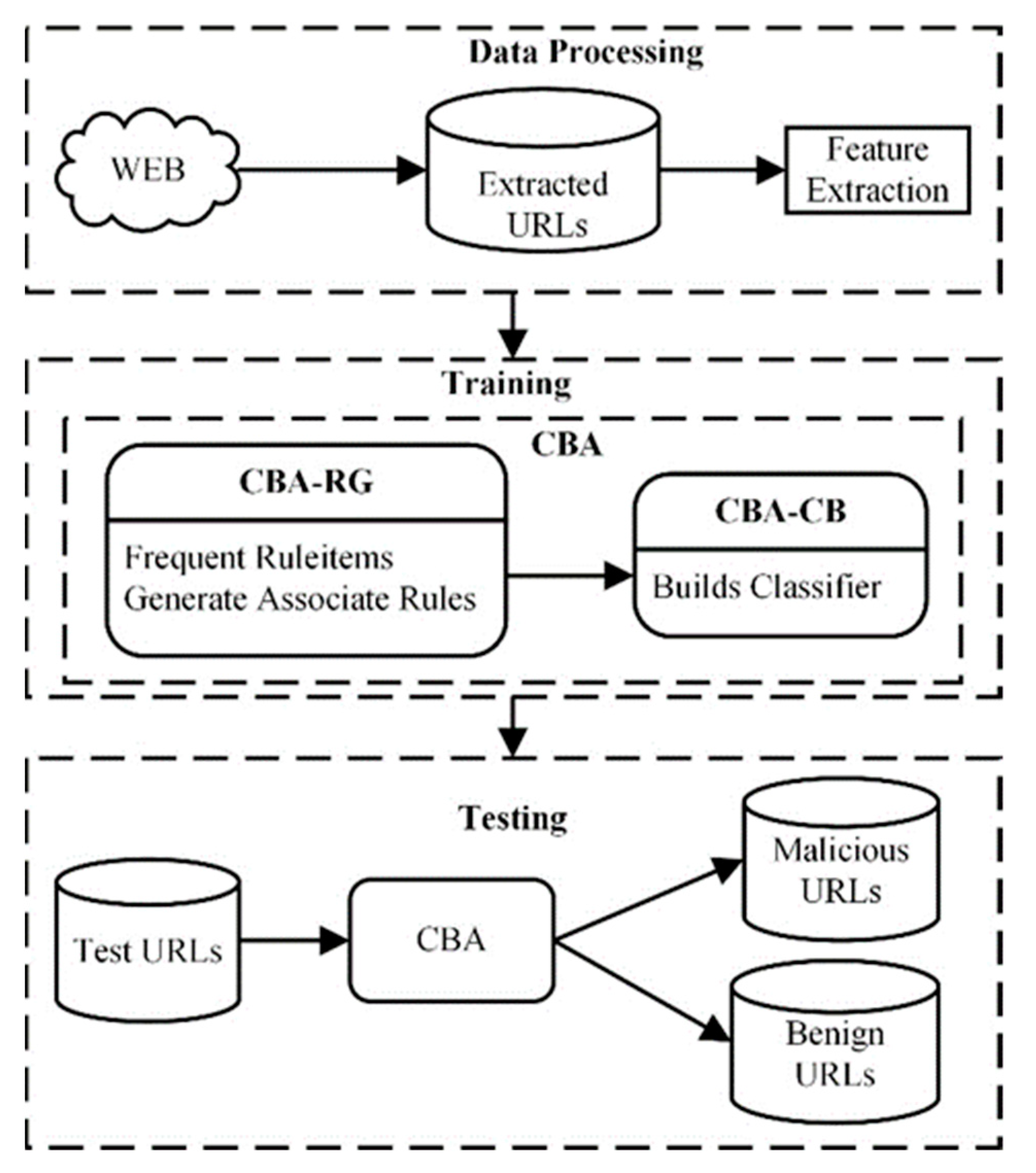
3. Proposed Methodology
3.1. Feature Extraction
3.1.1. URL Features
- (1)
- Special Characters: Attackers use special characters for URL encoded attacks to bypass validation logic. We count the number of special characters (‘;’, ‘+=’, ‘_’, ‘?’, ‘=’, ‘&’, ‘[‘, ‘]’, ‘#’, ‘~’, ‘%’, ‘@’, ‘$’, ‘*’, ‘+’, ‘!’, ‘|’) found in a URL.
- (2)
- Entropy of domain name: Entropy measures the randomness factor or uncertainty in URLs; the higher the entropy, the higher the randomness factor in the URL. Entropy is used to detect randomized domain names. Some malicious URLs use domain generation algorithms (DGA) to change domains frequently, hence blacklisting these URLs is not efficient. DGA is a program that provides malware with new domains on-demand or on the fly [21]. URLs with high entropy are significant indicators of malicious behavior. Entropy can help detect malicious URLs by setting thresholds based on the entropies of legitimate URLs. We calculate the entropy of domain names, using the Shannon entropy formula:where H(x) is the Shannon entropy of string x, b is the base of the logarithm used, and p(x) is the probability mass function.
- (3)
- Sensitive words: Sensitive words are mostly used in phishing URLs. We tokenize a URL to count the number of sensitive words in it, i.e., (’confirm’, ’account’, ’secure’, ’webscr’, ’banking’, ’login’, ‘signin’). Currently, our work only handles sensitive words in English Language.
3.1.2. Webpage Content Features
- (1)
- Webpage size-based features: We extract two features under webpage size-based features; line counts and maximum line length. Malicious webpages are likely to have a long single line of code. In our dataset, we identified that 25% of malicious URLs with unique domain names had the same total number of lines of code. Benign webpages with a single line of code have a maximum line length of 6-469 characters. Hence, if the total number of line counts of code is 1 and the maximum line length is greater than 500 characters, the webpage is considered highly malicious.
- (2)
- Iframes: Attackers use iframe tags to inject and load malicious code into webpages.
- (3)
- Elements with small area: Attackers use high or low values for the height and width of tags to make attacks invisible to users.
- (4)
- JavaScript tags: Webpage content is analyzed statistically for the presence of internal and external script tags on a webpage. Hackers embed malicious JavaScript code into websites to access sensitive user information. Injection of malicious JavaScript code can lead to CSRF vulnerability that allows the attacker to exploit the user’s browser cookies and permissions to perform malicious actions on a separate website. Benign websites mostly include external JavaScript for advertisement and analytics purposes. A malicious website with external JavaScript has the intention of redirecting users to compromised websites.
- (5)
- DOM functions: Attackers use JavaScript to manipulate elements in a webpage’s DOM tree. DOM-modifying functions are used by hackers to tamper with data provided by users. We analyze source content to check for the presence of DOM functions such as appendChild, createElement, getElementByTagName and getElementById in a webpage.
- (6)
- Obfuscation and suspicious functions: Attackers use obfuscation functions to evade detection, making code analysis difficult. They also include malicious JavaScript attachment, which runs through the Windows program, e.g., WScript.Shell. Suspicious functions such as ActiveXObject, CreateObject, CreateTextFile, FileSystemObject, and FileExists to create or access files and folders or create a backdoor to monitor activities on a computer.
- (7)
- Frequency of var and functions in JavaScript: We check the frequency of var and function used in the JavaScript statement of webpages. var and function keywords occurrence is lower in malicious URLs since JavaScript code with these keywords is obfuscated or has a link attribute.
- (8)
- Whitespace ratio: Whitespace obfuscation is the simplest obfuscation technique. Attackers include random whitespace inside source code to confuse static or automated analysis tools.
3.2. Detection of Malicious URLs using Classification Based on Association (CBA)
- (1)
- The Rule generator (CBA-RG) is based on the a priori algorithm to find all CARs that meet user-defined minimum support (minsup) and minimum confidence (minconf) thresholds. Support measures how frequent an itemset is in all transactions. Confidence is defined as the measure of certainty associated with each discovered itemset. Support and confidence can be calculated using the equations below. The a priori algorithm proposed by Agrawal et al. [11] is for mining frequent itemsets for Boolean association rules. In this work, CBA-RG iterates over historical extracted features of URLs (training dataset) to discover all frequent ruleitems, from which CARs are generated:Equation (2) expresses the support of ruleitems A as the ratio between the number of transactions containing A by the total number of transactions. Equation (3) expresses the confidence of a rule, where A is the antecedent, B is the consequence, is the number of transactions containing the ruleitems , and is the number of transactions containing the rule items A.A rule item is of the form:, represents a rule: , where condset is a set of items, is a class label (malicious or benign). For example, the following is a ruleitem to classify a URL:where A and B are attributes (features). Rules are interpreted as “if-then” statements. In the example above, if A is 1 and B is 1, then the URL is classified as benign.
- (2)
- The classifier builder (CBA-CB) builds a classifier using generated CARs. To build an accurate classifier, CBA-CB uses rule sorting and data coverage pruning procedure to discard redundant rules. Rules are selected to build a classifier based on ranking order, i.e., rules with high confidence and support are selected first. M1, a direct version of the CBA algorithm, and M2 are the pruning procedures used. M1 algorithm traverses the database multiple times to find the optimum number of rules to build an accurate classifier. The authors of CBA presented an improved version of the M1 algorithm (called M2) to reduce data access when the data is too large to be stored in the main memory. The available main memory and performance of computers have increased since the original paper was published, making the M2 algorithm less relevant [23]. Performance analysis by Jiří and Kliegr [24] showed that the M1 version of CBA is faster than M2 in most benchmarked combinations. In this study, we select the M1 algorithm as the pruning method to discard redundant rules. M1 algorithm, as shown in Algorithm 1, has three steps:
- Step 1:
- Sort the generated rules R according to precedence operator (>).
- Step 2:
- Select rules for the classifier according to the sorted sequence. The rules are iterated over the database, D to find instances that satisfy the rules. If a rule correctly classifies an instance in the database, it is marked and inserted at the end of the classifier, C. Instances that are correctly classified by selected rules are then removed from the database. A default class is selected, i.e., the majority class in the remaining instances to ensure that an instance is classified even if any other rule does not match it in the classifier.
- Step 3:
- Discard rules in C that do not improve the accuracy of the classifier. These rules are discarded because they generated more errors.
| Algorithm 1. Pseudocode of M1 algorithm [22]. |
| Let R be the set of generated rules (CARs), and D is the training data. Input: Set of generated rules, R, Training data, D Output: Classifier, C |
|
| Algorithm 2. Malicious URLs detection using CBA model. |
| Input: Training data D, minsup, and minconf thresholds Preprocess Data: Discretize continuous features if any Output: Classification Results (Benign and Malicious URLs) |
Step 1: Rule Generator
|
Step 2: Build Classifier
|
Step 3: Classification of URLs
|
4. Experimental Setup and Evaluation
4.1. Evaluation Metrics
- (1)
- Confusion Matrix (C). It is used to evaluate the accuracy of a classifier. The confusion matrix contains predicted and actual classifications done by a classifier.
- True Positives (TP): correct malicious URLs prediction.
- True Negatives (TN): correct benign URLs prediction.
- False Positives (FP): incorrect malicious URLs prediction.
- False Negatives (FN): incorrect benign URLs prediction.
- (2)
- Accuracy. This is the ratio of correct predictions to the total number of samples:
- (3)
- Precision. This is defined as the number of true positives over the number of true positives plus the number of false positives:
- (4)
- Recall. This is defined as the number of true positives over the number of true positives plus the number of false negatives.
4.2. Evaluation of Proposed Approach
4.3. Performance Comparison with Existing Works
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
| CARs | Support (%) | Confidence (%) |
|---|---|---|
| {Entropy = [3.78, inf]}{Label = M} | 48.51 | 100 |
| {special characters = [0.00336, 0.0619]}{Label = M} | 24.62 | 100 |
| {var_function frequency = [59.5,904), DOM functions = [12.5,148)}{Label =B} | 13.79 | 100 |
| {line counts = [570,688), maximum line length = [888, 1.16e+03)}{Label =M} | 12.22 | 100 |
| {whitespace %= [1.0258,1.1005), DOM functions = [-Inf,1.5)}{Label = M} | 11.85 | 100 |
| {JavaScript tags= [2.5,27.5), Entropy= [-Inf,3.03)}{Label =B} | 11.48 | 100 |
| {DOM functions = [12.5,148), Entropy= [-Inf,3.03)}{Label =B} | 9.25 | 100 |
| {whitespace %= [1.0258,1.1005), Entropy = [3.03,3.66)}{Label = B} | 9.07 | 100 |
| {line counts = [11.5,570), Entropy = [-Inf,3.03)}{Label =B} | 6.75 | 100 |
| {Elements with small area = [0.5,Inf), var_function frequency = [59.5,904) }{Label =B} | 5.46 | 100 |
| {iframe counts = [3.5,Inf), Entropy = [3.03,3.66)}{Label =B} | 5.73 | 100 |
| {line counts = [11.5,570), var_function frequency = [59.5,904) }{Label =B} | 4.81 | 100 |
| {maximum line length = [4.01e+03,4.09e+03]}{Label =M} | 3.88 | 100 |
| {maximum line length = [1.16e+03, 4.01e+03), Entropy = [-Inf,3.03)}{Label =B} | 3.42 | 100 |
| {Obfuscation and suspicious functions = [10.5,Inf),var_function frequency = [2.5,59.5)}{Label =M} | 2.50 | 100 |
| {whitespace %= [0.99362,1.0047), DOM functions = [1.5,7.5)}{Label = B} | 2.31 | 100 |
| {Elements with small area = [-Inf,-0.5)}{Label =M} | 1.94 | 100 |
| {iframe counts = [-Inf,0.5), Obfuscation and suspicious functions = [10.5,Inf),}{Label =M} | 1.75 | 100 |
| {maximum line length = [-Inf,141), JavaScript tags = [2.5,4.5)}{Label =B} | 1.67 | 100 |
| {whitespace %= [1.1487,Inf), sensitive word = [-Inf,0.5)}{Label =B} | 1.48 | 100 |
| {whitespace %= [-Inf,0.17415), special characters = [-Inf,0.00336)}{Label =M} | 1.48 | 100 |
| {iframe counts = [-Inf,0.5), whitespace % = [1.0322,1.1487)}{Label =M} | 12.12 | 99.24 |
| {iframe counts = [3.5,Inf),special characters = [-Inf,0.00336)}{Label =B} | 9.90 | 99.07 |
| {whitespace % = [1.0322,1.1487), special characters = [-Inf,0.00336]}{Label =M} | 8.51 | 98.92 |
| {whitespace % = [0.99362,1.0047), Entropy = [-Inf,3.03)}{Label =B} | 6.94 | 98.62 |
| {DOM functions = [12.5,148),special characters = [-Inf,0.00336)}{Label =B} | 18.61 | 98.52 |
| {maximum line length = [5.27e+03,1.83e+04), JavaScript tags = [-Inf,0.5)}{Label =M} | 3.79 | 97.61 |
References
- Kaspersky. Malware Variety Grows by 13.7% in 2019 Due to Web Skimmers. Available online: https://www.kaspersky.com/about/press-releases/2019_malware-variety-grows-by-137-in-2019-due-to-web-skimmers (accessed on 20 January 2020).
- Canali, D.; Cova, M.; Vigna, G.; Kruegel, C. Prophiler: A Fast Filter for the Large-Scale Detection of Malicious Web Pages. In Proceedings of the 20th International Conference on World Wide Web, WWW 2011, Hyderabad, India, 28 March–1 April 2011; pp. 197–206. [Google Scholar]
- Micro, T. 10 Scary Tricks Cybercriminals Use to Lure Unsuspecting Users. Available online: https://www.trendmicro.com/vinfo/us/security/news/cybercrime-and-digital-threats/10-scary-tricks-cybercriminals-use-to-lure-unsuspecting-users (accessed on 20 January 2020).
- Trustwave Global Security Report. 2019. Available online: https://www.trustwave.com/en-us/resources/library/documents/2019-trustwave-global-security-report/ (accessed on 20 January 2020).
- Eshete, B.; Villafiorita, A.; Weldemariam, K. BINSPECT: Holistic Analysis and Detection of Malicious Web Pages. In Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering; Springer: Berlin, Germany, 2013; Volume 106 LNICS, pp. 149–166. [Google Scholar]
- Ma, J.; Saul, L.K.; Savage, S.; Voelker, G.M. Beyond blacklists: Learning to detect malicious web sites from suspicious URLs. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 1245–1253. [Google Scholar]
- Curtsinger, C.; Livshits, B.; Zorn, B.; Seifert, C. ZOZZLE: Fast and precise in-browser JavaScript Malware detection. In Proceedings of the 20th USENIX Security Symposium, San Francisco, CA, USA, 8–12 August 2011; pp. 33–48. [Google Scholar]
- Cuckoo Sandbox. Available online: https://cuckoosandbox.org/ (accessed on 20 January 2020).
- Moshchuk, A.; Bragin, T.; Deville, D.; Gribble, S.D.; Levy, H.M. SpyProxy: Execution-based detection of malicious web content. In Proceedings of the 16th USENIX Security Symposium, Boston, MA, USA, 6–10 August 2007; pp. 27–42. [Google Scholar]
- Salzberg, S.L. C4.5: Programs for Machine Learning by J. Ross Quinlan. Morgan Kaufmann Publishers, Inc., 1993. Mach. Learn. 1994, 16, 235–240. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, R.; Srikant, R. Fast Algorithms for Mining Association Rules. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago de Chile, Chile, 12–15 September 1994; pp. 487–499. [Google Scholar]
- Padillo, F.; Luna, J.M.; Ventura, S. Evaluating associative classification algorithms for Big Data. Big Data Anal. 2019. [Google Scholar] [CrossRef]
- Thabtah, F. A review of associative classification mining. Knowl. Eng. Rev. 2007, 22. [Google Scholar] [CrossRef] [Green Version]
- Abdelhamid, N.; Ayesh, A.; Thabtah, F. Phishing detection based Associative Classification data mining. Expert Syst. Appl. 2014, 41, 5948–5959. [Google Scholar] [CrossRef]
- Jeeva, S.C.; Rajsingh, E.B. Intelligent phishing url detection using association rule mining. Hum. Centric Comput. Inf. Sci. 2016, 6. [Google Scholar] [CrossRef] [Green Version]
- Hadi, W.; Aburub, F.; Alhawari, S. A new fast associative classification algorithm for detecting phishing websites. Appl. Soft Comput. J. 2016. [Google Scholar] [CrossRef]
- Kim, S.; Kim, J.; Nam, S.; Kim, D. WebMon: ML- and YARA-based malicious webpage detection. Comput. Netw. 2018, 137, 119–131. [Google Scholar] [CrossRef]
- Li, Y.; Yang, Z.; Chen, X.; Yuan, H.; Liu, W. A stacking model using URL and HTML features for phishing webpage detection. Future Gener. Comput. Syst. 2019, 94, 27–39. [Google Scholar] [CrossRef]
- Google Safe Browsing. Available online: https://safebrowsing.google.com/ (accessed on 20 November 2019).
- Cao, Y.; Han, W.; Le, Y. Anti-phishing based on automated individual white-list. In Proceedings of the ACM Conference on Computer and Communications Security, Alexandria VA, USA, 27–31 October 2008; pp. 51–59. [Google Scholar]
- Arntz, P. Explained: Domain Generating Algorithm. Available online: https://blog.malwarebytes.com/security-world/2016/12/explained-domain-generating-algorithm/ (accessed on 6 April 2020).
- Liu, B.; Hsu, W.; Ma, Y.; Ma, B. Integrating Classification and Association Rule Mining. In Proceedings of the Fourth International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 27–31 August 1998. [Google Scholar]
- Hahsler, M.; Johnson, I.; Kliegr, T.; Kuchař, J. Associative Classification in R: Arc, arulesCBA, and rCBA. R J. 2019, 9, 254–267. [Google Scholar] [CrossRef]
- Jiří, F.; Kliegr, T. Classification based on associations (CBA)—A performance analysis. In Proceedings of the CEUR Workshop Proceedings, Luxembourg, 20–26 September 2018; Volume 2204. [Google Scholar]
- Alexa. Available online: https://www.alexa.com/topsites (accessed on 20 February 2020).
- OpenPhish. Available online: https://openphish.com/ (accessed on 20 February 2020).
- VxVault. Available online: http://vxvault.net/ViriList.php (accessed on 20 February 2020).
- URLhaus. Available online: https://urlhaus.abuse.ch/ (accessed on 20 February 2020).
- Johnson, I.; Hahsler, M. arulesCBA v1. 2.0: Classification Based on Association Rules. 2020. Available online: https://github.com/ianjjohnson/arulesCBA (accessed on 21 April 2020).
- Fayyad, U.M.; Irani, K.B. Multi-interval discretization of continuous-valued attributes for classification learning. In Proceedings of the 13th International Joint Conference on Artificial Intelligence, Chambéry, France, 28 August–3 September 1993; Volume 2. [Google Scholar]
- University of Waikato. WEKA. Available online: https://www.cs.waikato.ac.nz/ml/weka/ (accessed on 10 April 2020).

| Support (minsup) % | Confidence (minconf) % | |||||
|---|---|---|---|---|---|---|
| 50 | 60 | 70 | 80 | 90 | 100 | |
| 1 | 91.67 | 91.67 | 91.67 | 91.67 | 95.8 | 83.33 |
| 2 | 92.5 | 92.5 | 92.5 | 92.5 | 92.5 | 68.33 |
| 3 | 90 | 90 | 90 | 90 | 90 | 60 |
| 4 | 90 | 90 | 90 | 90 | 90 | 60 |
| 5 | 86.67 | 85 | 84.17 | 88.33 | 90 | 60 |
| Feature | Score |
|---|---|
| Entropy of domain name | 0.419320 |
| JavaScript Tags | 0.190276 |
| DOM functions | 0.075120 |
| Whitespace percentage | 0.073060 |
| Frequency of var, function keyword | 0.065900 |
| Special character ratio | 0.042401 |
| Line counts | 0.040867 |
| Iframe counts | 0.040005 |
| Maximum line length | 0.024783 |
| Obfuscation and suspicious functions | 0.019935 |
| Elements with small area | 0.007263 |
| Sensitive words | 0.001088 |
| Approach | Accuracy | Precision | Recall | False Negative Rate |
|---|---|---|---|---|
| Jeeva et al. [15] | 95.8 | 96.2 | 95.8 | 7.57 |
| Our Method | 95.8 | 91.3 | 97.67 | 1.35 |
| Classifier | Precision (%) | Recall (%) | ROC Area (%) | False Positive Rate (%) |
|---|---|---|---|---|
| SVM | 83.4 | 80 | 81.9 | 16.2 |
| Naive Bayes | 90.9 | 90.3 | 95.2 | 8.4 |
| Logistic | 85.9 | 84.8 | 94.1 | 19.7 |
| Our Approach (CBA) | 91.30 | 97.67 | 96.2 | 8.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumi, S.; Lim, C.; Lee, S.-G. Malicious URL Detection Based on Associative Classification. Entropy 2021, 23, 182. https://doi.org/10.3390/e23020182
Kumi S, Lim C, Lee S-G. Malicious URL Detection Based on Associative Classification. Entropy. 2021; 23(2):182. https://doi.org/10.3390/e23020182
Chicago/Turabian StyleKumi, Sandra, ChaeHo Lim, and Sang-Gon Lee. 2021. "Malicious URL Detection Based on Associative Classification" Entropy 23, no. 2: 182. https://doi.org/10.3390/e23020182