Improving the Accuracy of Nearest-Neighbor Classification Using Principled Construction and Stochastic Sampling of Training-Set Centroids


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Image Recognition via Nearest-Neighbor Classification
2.1. Unaltered Training Set
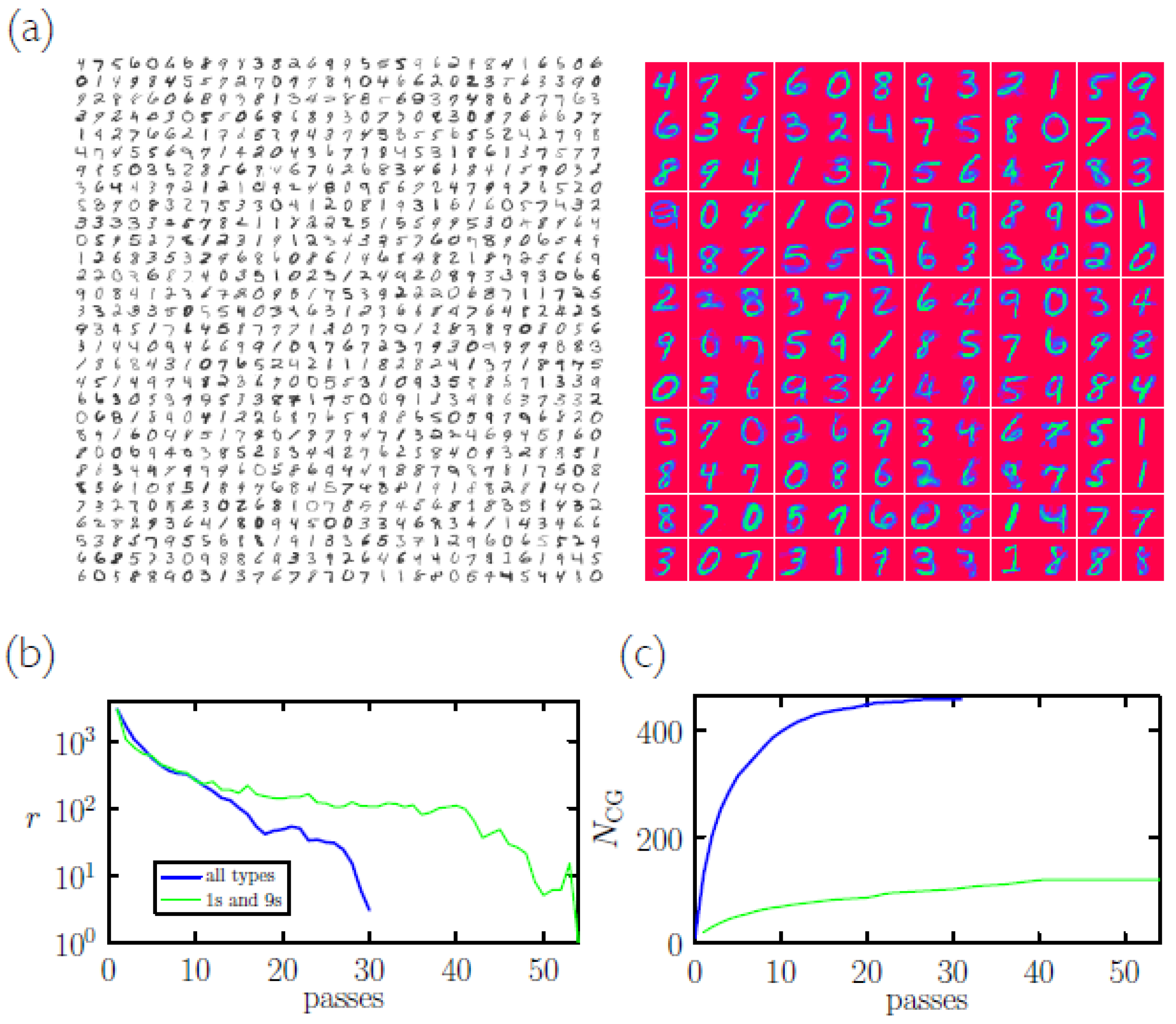
2.2. Coarse-Graining Training-Set Symbols
- Consider a batch, an ordered collection of B symbols , , taken from the training set. Create a new memory that is equal to the first symbol from this batch and is of the same type:Record the fact that symbol 1 is now stored in memory 1. Create one memory for each additional type of symbol in the batch (with each memory consisting of one symbol), giving up to ten initial memories. Record the memory in which each symbol is stored (here and subsequently).
- Return to the start of the batch of symbols and pass through the batch in order. For each symbol, compute its virtual overlap with all existing memories. If the symbol and memory are of the same type, and if the symbol is not currently stored in that memory, then the virtual overlap is [see Equation (3)]. Here is the vector that results if symbol is added to memory ; it has components . Otherwise (i.e., if the symbol is currently stored in the memory, or if symbol and memory are of distinct type) the virtual overlap is .
- Let the largest virtual overlap between symbol and any memory be with memory .
- (a)
- If is currently stored in then no action is necessary.
- (b)
- If is not currently stored in , and is of the same type as , then add to :If is currently stored in a different memory then remove from :If is not yet stored in a memory then (7) is not necessary.
- (c)
- If and are of different type then has been misclassified. Create a new memory equal to the symbol and of the same type:
- Continue until we have considered all symbols in the batch. Return to 2 and pass through the batch in order again. Note the number of memory increases or symbol relocations that occur on each pass. If the number of each is zero then the algorithm is finished; if not, return to 2 and pass through the batch in order again.
2.3. Sampling
2.4. Coarse-Graining as a Genetic Algorithm
3. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Nasrabadi, N.M. Pattern recognition and machine learning. J. Electron. Imaging 2007, 16, 049901. [Google Scholar]
- LeCun, Y.; Boser, B.E.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.E.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 26–29 November 1990; pp. 396–404. [Google Scholar]
- Hinton, G.E.; Dayan, P.; Revow, M. Modeling the manifolds of images of handwritten digits. IEEE Trans. Neural Netw. 1997, 8, 65–74. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Quinlan, J.R. Learning efficient classification procedures and their application to chess end games. In Machine Learning; Springer: Berlin/Heidelberg, Germany, 1983; pp. 463–482. [Google Scholar]
- Samuel, A.L. Some studies in machine learning using the game of checkers. IBM J. Res. Dev. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Ferguson, A.L.; Hachmann, J. Machine learning and data science in materials design: A themed collection. Mol. Syst. Des. Eng. 2018, 3, 429–430. [Google Scholar] [CrossRef]
- Desgranges, C.; Delhommelle, J. A new approach for the prediction of partition functions using machine learning techniques. J. Chem. Phys. 2018, 149, 044118. [Google Scholar] [CrossRef]
- Portman, N.; Tamblyn, I. Sampling algorithms for validation of supervised learning models for Ising-like systems. J. Comput. Phys. 2017, 350, 871–890. [Google Scholar] [CrossRef] [Green Version]
- Mills, K.; Spanner, M.; Tamblyn, I. Deep learning and the Schrödinger equation. Phys. Rev. A 2017, 96, 042113. [Google Scholar] [CrossRef] [Green Version]
- Artrith, N.; Urban, A.; Ceder, G. Constructing first-principles phase diagrams of amorphous Li x Si using machine-learning-assisted sampling with an evolutionary algorithm. J. Chem. Phys. 2018, 148, 241711. [Google Scholar] [CrossRef] [Green Version]
- Singraber, A.; Morawietz, T.; Behler, J.; Dellago, C. Density anomaly of water at negative pressures from first principles. J. Phys. Condens. Matter 2018, 30, 254005. [Google Scholar] [CrossRef]
- Thurston, B.; Ferguson, A. Machine learning and molecular design of self-assembling-conjugated oligopeptides. Mol. Simul. 2018, 44, 930–945. [Google Scholar] [CrossRef]
- Whitelam, S.; Tamblyn, I. Learning to grow: Control of material self-assembly using evolutionary reinforcement learning. Phys. Rev. E 2020, 101, 052604. [Google Scholar] [CrossRef] [PubMed]
- Kossio, F.Y.K.; Goedeke, S.; van den Akker, B.; Ibarz, B.; Memmesheimer, R.M. Growing Critical: Self-Organized Criticality in a Developing Neural System. Phys. Rev. Lett. 2018, 121, 058301. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, M.L.; Zhou, Z.H. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef] [Green Version]
- Bhatia, N. Survey of nearest neighbor techniques. arXiv 2010, arXiv:1007.0085. [Google Scholar]
- Fritzke, B. A growing neural gas network learns topologies. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 27–30 November 1995; pp. 625–632. [Google Scholar]
- Nova, D.; Estévez, P.A. A review of learning vector quantization classifiers. Neural Comput. Appl. 2014, 25, 511–524. [Google Scholar] [CrossRef] [Green Version]
- Marsland, S.; Shapiro, J.; Nehmzow, U. A self-organising network that grows when required. Neural Netw. 2002, 15, 1041–1058. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Wolff, U. Collective Monte Carlo updating for spin systems. Phys. Rev. Lett. 1989, 62, 361. [Google Scholar] [CrossRef]
- Liu, J.; Luijten, E. Rejection-free geometric cluster algorithm for complex fluids. Phys. Rev. Lett. 2004, 92, 035504. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Whitelam, S. Approximating the dynamical evolution of systems of strongly interacting overdamped particles. Mol. Simul. 2011, 37, 606–612. [Google Scholar] [CrossRef] [Green Version]
- Wagstaff, K.; Cardie, C.; Rogers, S.; Schrödl, S. Constrained k-means clustering with background knowledge. In Proceedings of the ICML, Williamstown, MA, USA, 28 June–1 July 2001; Volume 1, pp. 577–584. [Google Scholar]
- Skalak, D.B. Prototype Selection for Composite Nearest Neighbor Classifiers. Ph.D. Thesis, University of Massachusetts at Amherst, Amherst, MA, USA, 1997. [Google Scholar]
- A MNIST-Like Fashion Product Database. Benchmark. Available online: https://github.com/zalandoresearch/fashion-mnist (accessed on 15 January 2020).
- Simard, P.; LeCun, Y.; Denker, J.S. Efficient pattern recognition using a new transformation distance. Adv. Neural. Inform. Process Syst. 1993, 1, 50. [Google Scholar]
- Belongie, S. Shape Matching and Object Recognition Using Shape Contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 509–522. [Google Scholar] [CrossRef] [Green Version]
- What Is the Class of This Image? Available online: http://rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html (accessed on 15 January 2020).
- Garcia, S.; Derrac, J.; Cano, J.; Herrera, F. Prototype selection for nearest neighbor classification: Taxonomy and empirical study. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 417–435. [Google Scholar] [CrossRef]
- Hart, P. The condensed nearest neighbor rule (Corresp.). IEEE Trans. Inf. Theory 1968, 14, 515–516. [Google Scholar] [CrossRef]
- Angiulli, F. Fast condensed nearest neighbor rule. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 25–32. [Google Scholar]
- Weinberger, K.Q.; Blitzer, J.; Saul, L.K. Distance metric learning for large margin nearest neighbor classification. J. Mach. Learn. Res. 2006, 10, 1473–1480. [Google Scholar]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Whitelam, S. Improving the Accuracy of Nearest-Neighbor Classification Using Principled Construction and Stochastic Sampling of Training-Set Centroids. Entropy 2021, 23, 149. https://doi.org/10.3390/e23020149
Whitelam S. Improving the Accuracy of Nearest-Neighbor Classification Using Principled Construction and Stochastic Sampling of Training-Set Centroids. Entropy. 2021; 23(2):149. https://doi.org/10.3390/e23020149
Chicago/Turabian StyleWhitelam, Stephen. 2021. "Improving the Accuracy of Nearest-Neighbor Classification Using Principled Construction and Stochastic Sampling of Training-Set Centroids" Entropy 23, no. 2: 149. https://doi.org/10.3390/e23020149