
Multi-Label Feature Selection Combining Three Types of Conditional Relevance

Abstract
:1. Introduction
- Analyze and discuss the indispensability of the three key aspects (candidate features, selected features and label correlations) for feature relevance evaluation;
- Three incremental information terms taking three key aspects into account are used to express three types of conditional relevance. Then, FR combining the three incremental information terms is designed;
- A designed multi-label feature selection method that integrates FR with LR is proposed, namely TCRFS;
- TCRFS is compared to 6 state-of-the-art multi-label feature selection methods on 13 benchmark multi-label data sets using 4 evaluation criteria and certified the efficacy in numerous experiments.
2. Preliminaries
2.1. Information Theory for Multi-Label Feature Selection
2.2. Evaluation Criteria for Multi-Label Feature Selection
3. Related Work
4. TCRFS: Feature Selection Combining Three Types of Conditional Relevance
4.1. The Three Key Aspects of Feature Relevance We Consider
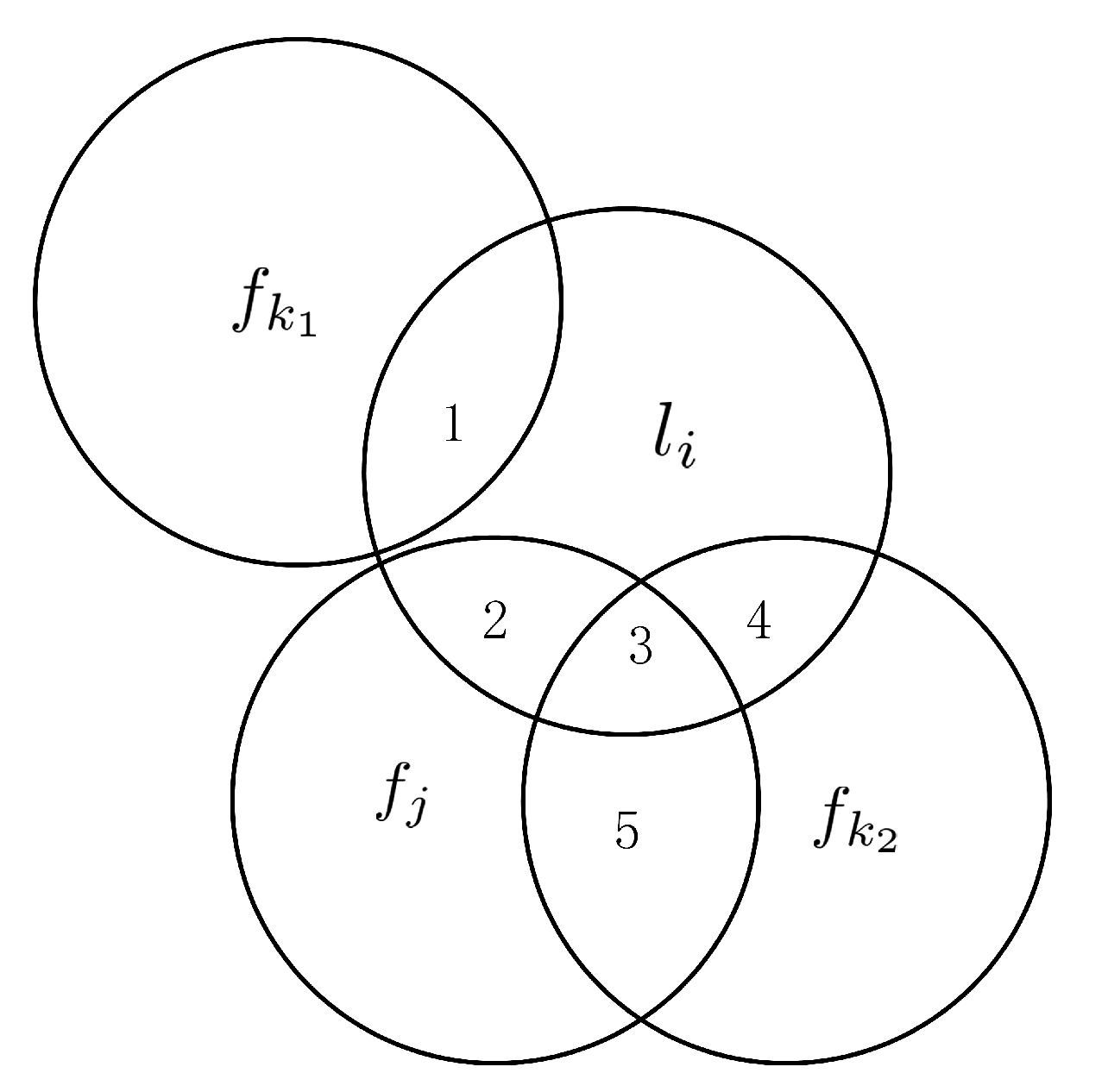
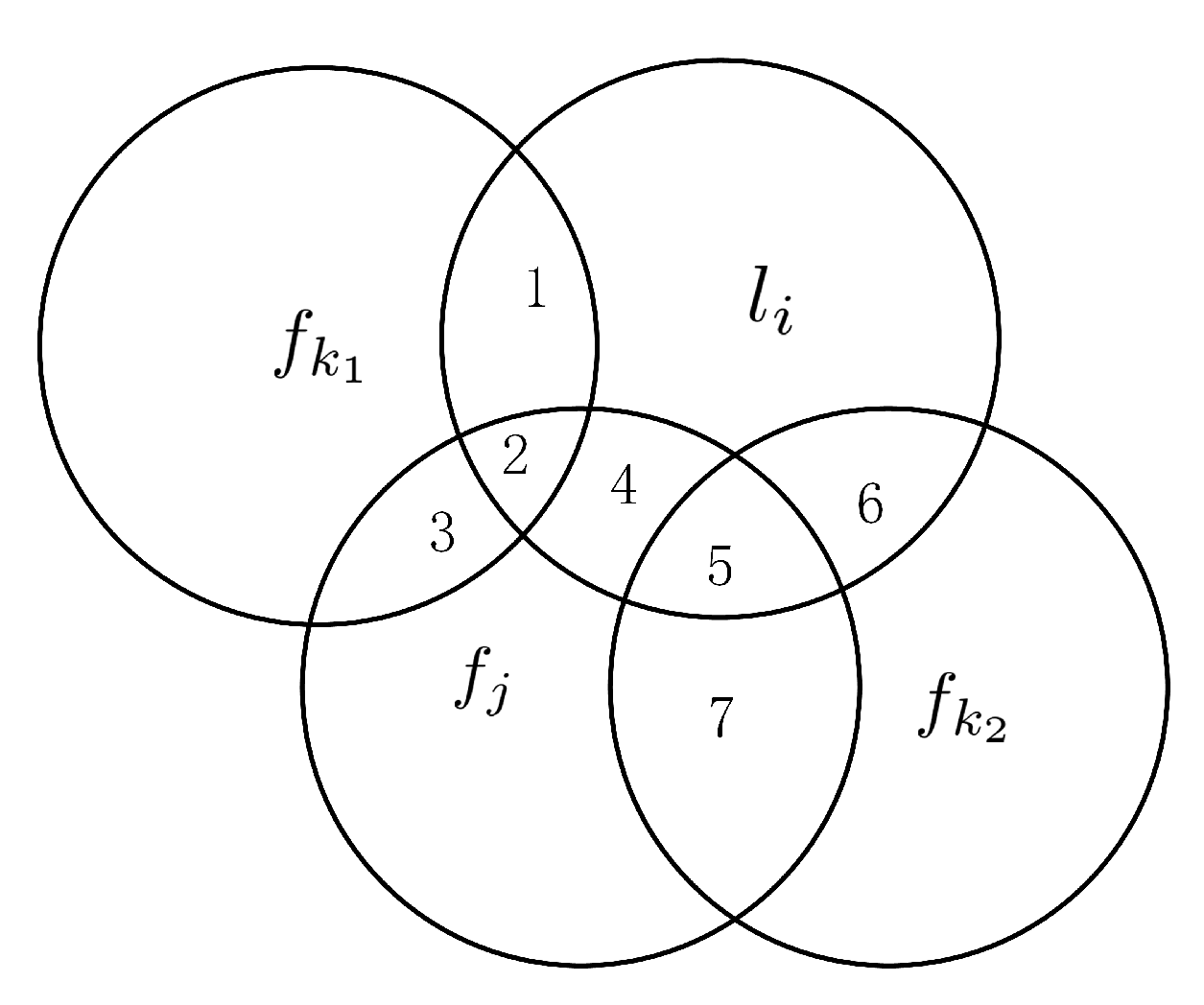
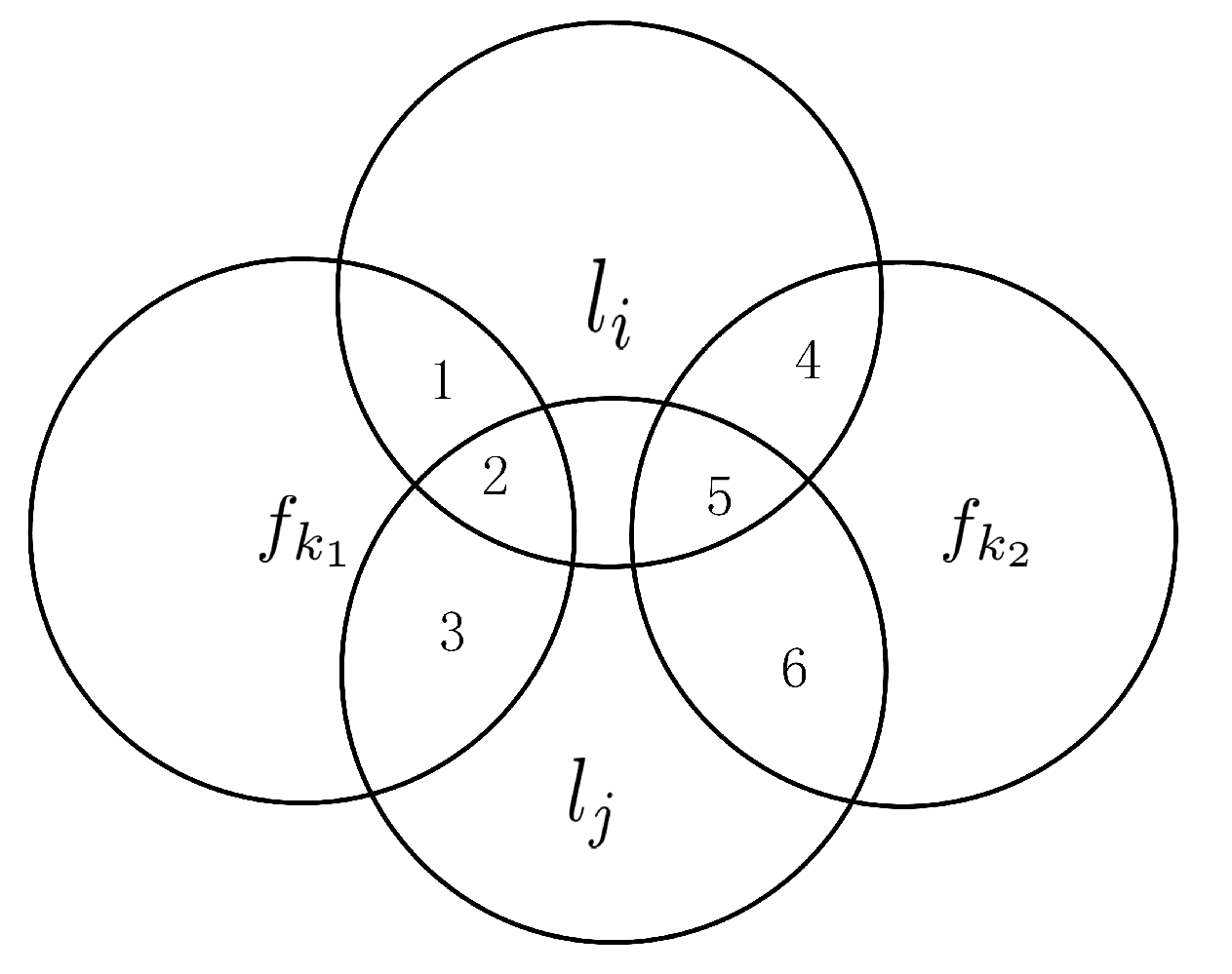
4.1.1. Candidate Features
4.1.2. Selected Features
4.1.3. Label Correlations
4.2. Evaluation Function of TCRFS
4.2.1. Definitions of FR and LR
4.2.2. Proposed Method
| Algorithm 1. TCRFS. |
|
4.3. Time Complexity
5. Experimental Evaluation
5.1. Multi-Label Data Sets
5.2. The Theoretical Justification of TCRFS on an Artificial Data Set
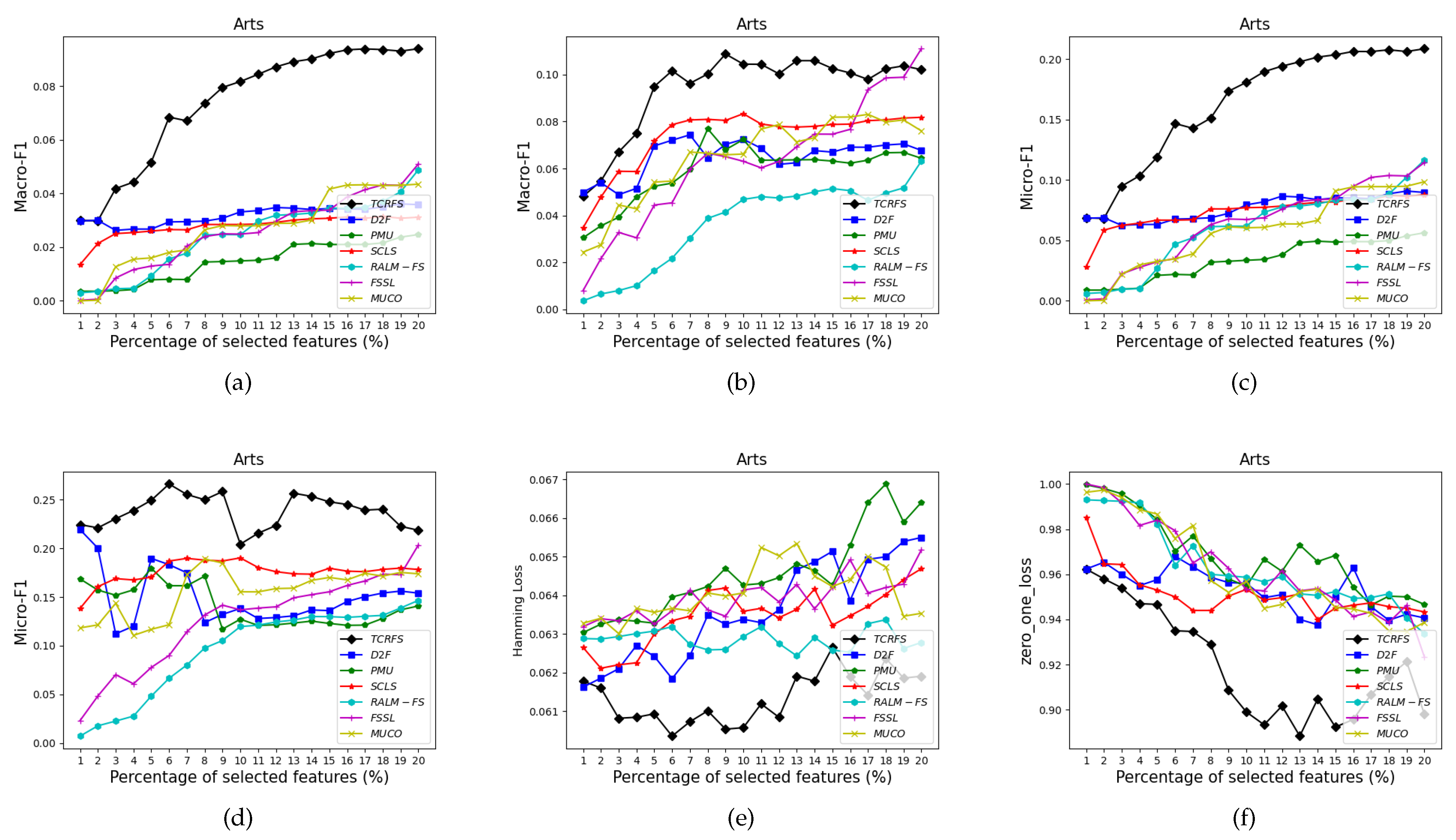
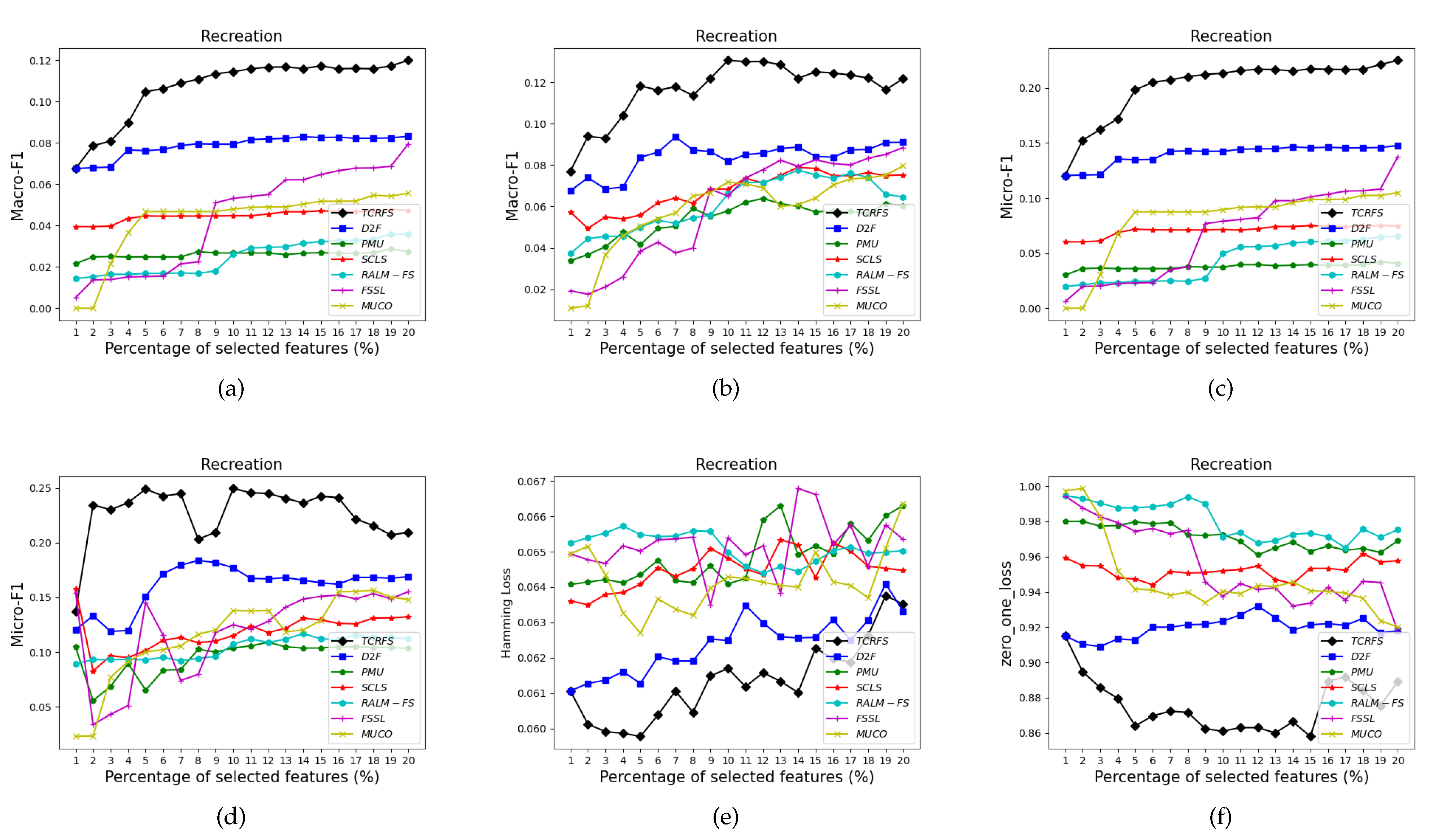
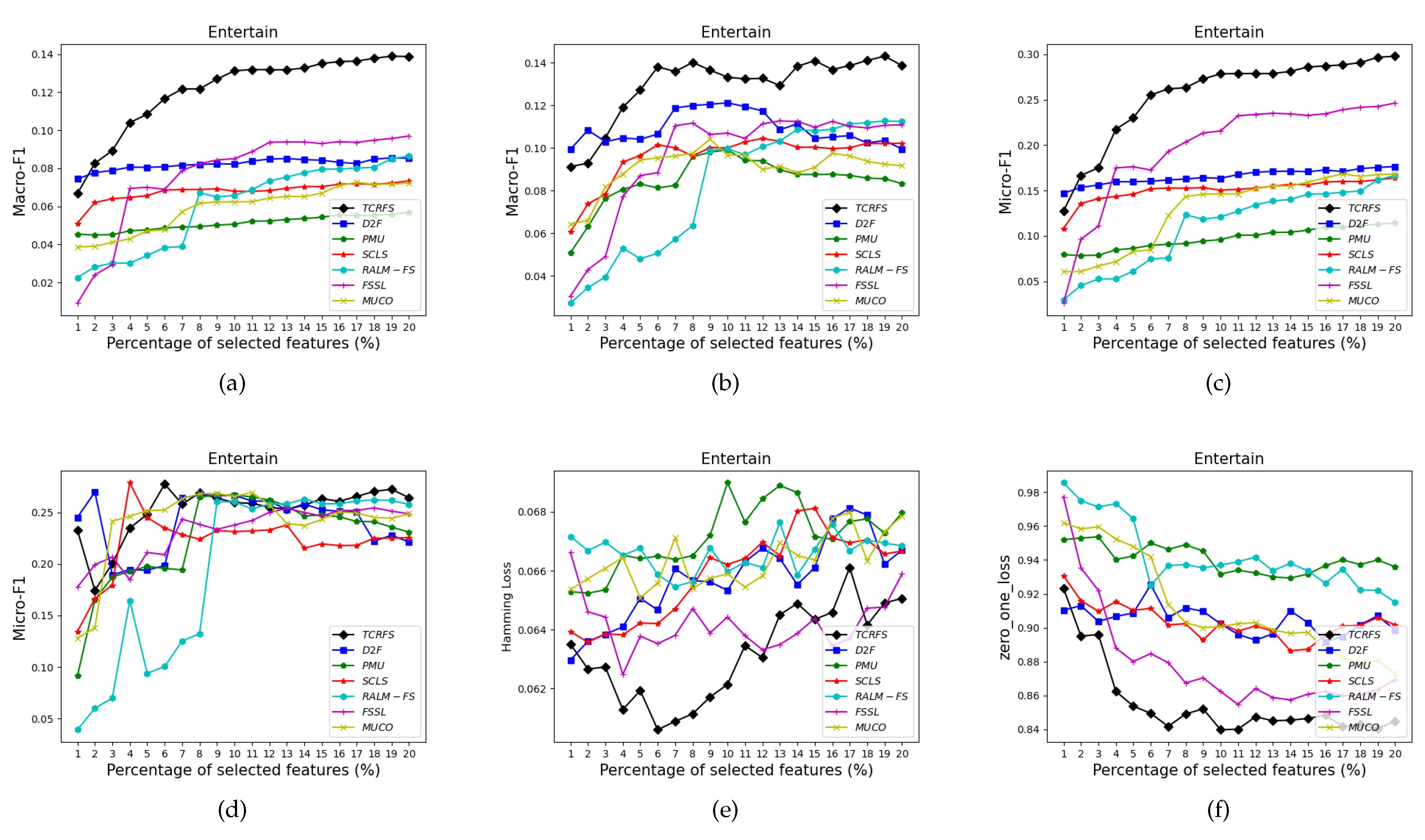
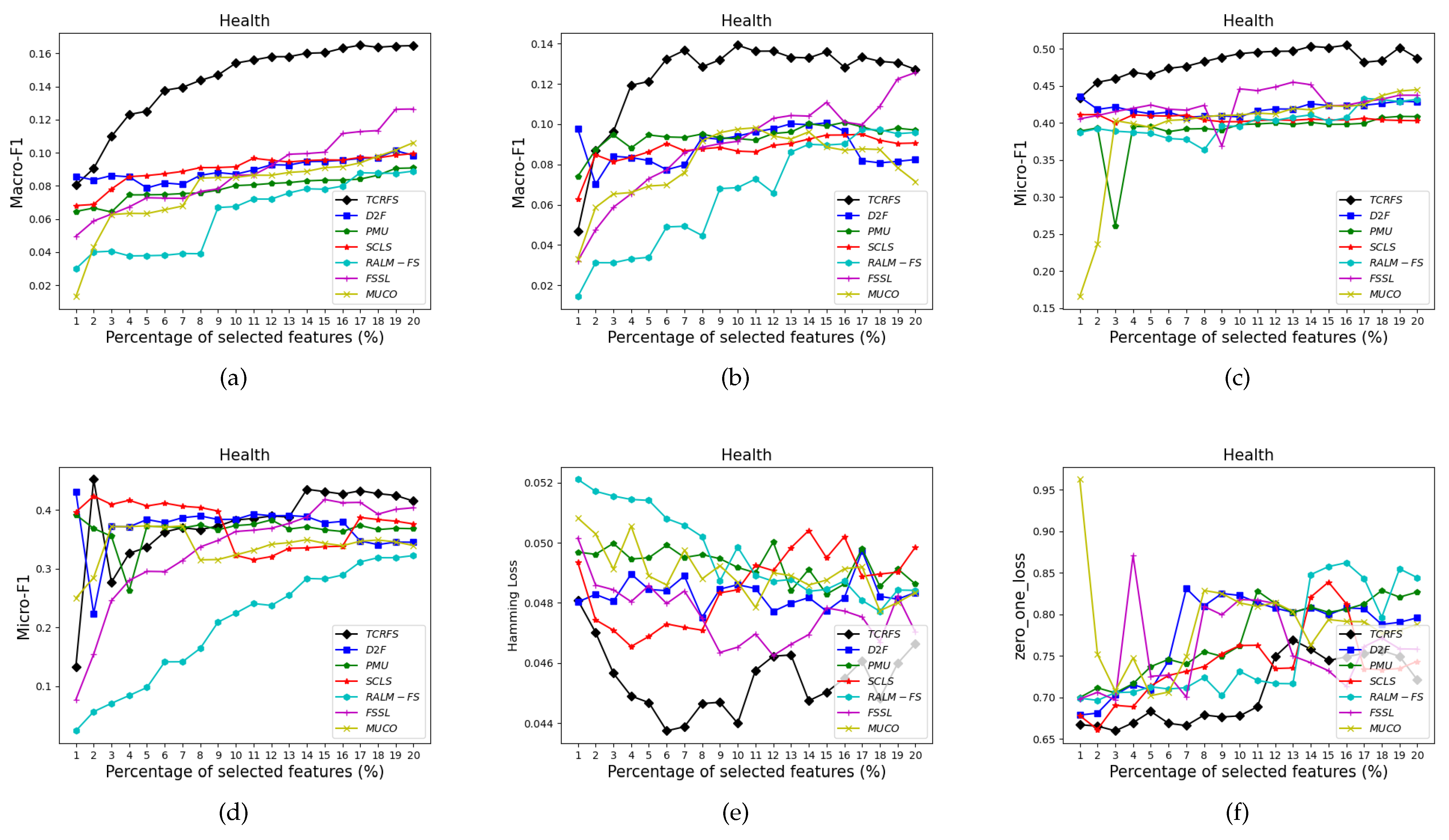
5.3. Analysis and Discussion of the Experimental Findings
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhou, Z.H.; Zhang, M.L. Multi-label Learning. 2017. Available online: https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/EncyMLDM2017.pdf (accessed on 26 November 2021).
- Kashef, S.; Nezamabadi-pour, H. A label-specific multi-label feature selection algorithm based on the Pareto dominance concept. Pattern Recognit. 2019, 88, 654–667. [Google Scholar] [CrossRef]
- Zhang, M.L.; Wu, L. Lift: Multi-label learning with label-specific features. IEEE PAMI 2014, 37, 107–120. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, M.L.; Li, Y.K.; Liu, X.Y.; Geng, X. Binary relevance for multi-label learning: An overview. Front. Comput. Sci. 2018, 12, 191–202. [Google Scholar] [CrossRef]
- Al-Salemi, B.; Ayob, M.; Noah, S.A.M. Feature ranking for enhancing boosting-based multi-label text categorization. Expert Syst. Appl. 2018, 113, 531–543. [Google Scholar] [CrossRef]
- Yu, Y.; Pedrycz, W.; Miao, D. Neighborhood rough sets based multi-label classification for automatic image annotation. Int. J. Approx. Reason. 2013, 54, 1373–1387. [Google Scholar] [CrossRef]
- Yu, G.; Rangwala, H.; Domeniconi, C.; Zhang, G.; Yu, Z. Protein function prediction with incomplete annotations. IEEE/ACM Trans. Comput. Biol. Bioinform. 2013, 11, 579–591. [Google Scholar] [CrossRef] [Green Version]
- Tran, M.Q.; Li, Y.C.; Lan, C.Y.; Liu, M.K. Wind Farm Fault Detection by Monitoring Wind Speed in the Wake Region. Energies 2020, 13, 6559. [Google Scholar] [CrossRef]
- Tran, M.Q.; Elsisi, M.; Liu, M.K. Effective feature selection with fuzzy entropy and similarity classifier for chatter vibration diagnosis. Measurement 2021, 184, 109962. [Google Scholar] [CrossRef]
- Tran, M.Q.; Liu, M.K.; Elsisi, M. Effective multi-sensor data fusion for chatter detection in milling process. ISA Trans. 2021. Available online: https://www.sciencedirect.com/science/article/abs/pii/S0019057821003724 (accessed on 26 November 2021). [CrossRef]
- Gao, W.; Hu, L.; Zhang, P.; Wang, F. Feature selection by integrating two groups of feature evaluation criteria. Expert Syst. Appl. 2018, 110, 11–19. [Google Scholar] [CrossRef]
- Huang, J.; Li, G.; Huang, Q.; Wu, X. Learning label specific features for multi-label classification. In Proceedings of the 2015 IEEE International Conference on Data Mining, Atlantic City, NJ, USA, 14–17 November 2015; pp. 181–190. [Google Scholar] [CrossRef]
- Zhang, P.; Gao, W.; Liu, G. Feature selection considering weighted relevancy. Appl. Intell. 2018, 48, 4615–4625. [Google Scholar] [CrossRef]
- Gao, W.; Hu, L.; Zhang, P. Class-specific mutual information variation for feature selection. Pattern Recognit. 2018, 79, 328–339. [Google Scholar] [CrossRef]
- Zhang, P.; Gao, W. Feature selection considering Uncertainty Change Ratio of the class label. Appl. Soft 2020, 95, 106537. [Google Scholar] [CrossRef]
- Liu, H.; Sun, J.; Liu, L.; Zhang, H. Feature selection with dynamic mutual information. Pattern Recognit. 2009, 42, 1330–1339. [Google Scholar] [CrossRef]
- Vergara, J.R.; Estévez, P.A. A review of feature selection methods based on mutual information. Neural. Comput. 2014, 24, 175–186. [Google Scholar] [CrossRef]
- Hancer, E.; Xue, B.; Zhang, M. Differential evolution for filter feature selection based on information theory and feature ranking. Knowl. Based Syst. 2018, 140, 103–119. [Google Scholar] [CrossRef]
- Brezočnik, L.; Fister, I.; Podgorelec, V. Swarm intelligence algorithms for feature selection: A review. Appl. Sci. 2018, 8, 1521. [Google Scholar] [CrossRef] [Green Version]
- Zhu, P.; Xu, Q.; Hu, Q.; Zhang, C.; Zhao, H. Multi-label feature selection with missing labels. Pattern Recognit. 2018, 74, 488–502. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Appl. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Paniri, M.; Dowlatshahi, M.B.; Nezamabadi-pour, H. MLACO: A multi-label feature selection algorithm based on ant colony optimization. Knowl. Based Syst. 2020, 192, 105285. [Google Scholar] [CrossRef]
- Blum, A.L.; Langley, P. Selection of relevant features and examples in machine learning. Appl. Intell. 1997, 97, 245–271. [Google Scholar] [CrossRef] [Green Version]
- Cherrington, M.; Thabtah, F.; Lu, J.; Xu, Q. Feature selection: Filter methods performance challenges. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 3–4 April 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Li, F.; Miao, D.; Pedrycz, W. Granular multi-label feature selection based on mutual information. Pattern Recognit. 2017, 67, 410–423. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, S.; Li, Z.; Chen, H. Multi-label feature selection algorithm based on information entropy. Comput. Sci. 2013, 50, 1177. [Google Scholar]
- Wang, J.; Wei, J.M.; Yang, Z.; Wang, S.Q. Feature selection by maximizing independent classification information. IEEE Trans. Knowl. Data Eng. 2017, 29, 828–841. [Google Scholar] [CrossRef]
- Lin, Y.; Hu, Q.; Liu, J.; Duan, J. Multi-label feature selection based on max-dependency and min-redundancy. Neurocomputing 2015, 168, 92–103. [Google Scholar] [CrossRef]
- Ramírez-Gallego, S.; Mouriño-Talín, H.; Martínez-Rego, D.; Bolón-Canedo, V.; Benítez, J.M.; Alonso-Betanzos, A.; Herrera, F. An information theory-based feature selection framework for big data under apache spark. IEEE Trans. Syst. 2017, 48, 1441–1453. [Google Scholar] [CrossRef]
- Song, X.F.; Zhang, Y.; Guo, Y.N.; Sun, X.Y.; Wang, Y.L. Variable-size cooperative coevolutionary particle swarm optimization for feature selection on high-dimensional data. IEEE Trans. Evol. Comput. 2020, 24, 882–895. [Google Scholar] [CrossRef]
- Zhang, M.L.; Zhou, Z.H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2013, 26, 1819–1837. [Google Scholar] [CrossRef]
- Hu, L.; Li, Y.; Gao, W.; Zhang, P.; Hu, J. Multi-label feature selection with shared common mode. Pattern Recognit. 2020, 104, 107344. [Google Scholar] [CrossRef]
- Zhang, P.; Gao, W.; Hu, J.; Li, Y. Multi-Label Feature Selection Based on High-Order Label Correlation Assumption. Entropy 2020, 22, 797. [Google Scholar] [CrossRef]
- Zhang, P.; Gao, W. Feature relevance term variation for multi-label feature selection. Appl. Intell. 2021, 51, 5095–5110. [Google Scholar] [CrossRef]
- Xu, S.; Yang, X.; Yu, H.; Yu, D.J.; Yang, J.; Tsang, E.C. Multi-label learning with label-specific feature reduction. Knowl. Based Syst. 2016, 104, 52–61. [Google Scholar] [CrossRef]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef] [Green Version]
- Read, J. A pruned problem transformation method for multi-label classification. In New Zealand Computer Science Research Student Conference (NZCSRS 2008); Citeseer: Princeton, NJ, USA, 2008; Volume 143150, p. 41. [Google Scholar]
- Trohidis, K.; Tsoumakas, G.; Kalliris, G.; Vlahavas, I.P. Multi-label classification of music into emotions. In Proceedings of the ISMIR, Philadelphia, PA, USA, 14–18 September 2008; Volume 8, pp. 325–330. [Google Scholar]
- Lee, J.; Kim, D.W. Memetic feature selection algorithm for multi-label classification. Inf. Sci. 2015, 293, 80–96. [Google Scholar] [CrossRef]
- Cai, X.; Nie, F.; Huang, H. Exact top-k feature selection via ℓ2,0-norm constraint. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Lee, J.; Kim, D.W. Mutual information-based multi-label feature selection using interaction information. Expert Syst. Appl. 2015, 42, 2013–2025. [Google Scholar] [CrossRef]
- Lee, J.; Kim, D.W. Feature selection for multi-label classification using multivariate mutual information. Pattern Recognit. Lett. 2013, 34, 349–357. [Google Scholar] [CrossRef]
- Lee, J.; Kim, D.W. SCLS: Multi-label feature selection based on scalable criterion for large label set. Pattern Recognit. 2017, 66, 342–352. [Google Scholar] [CrossRef]
- Liu, J.; Li, Y.; Weng, W.; Zhang, J.; Chen, B.; Wu, S. Feature selection for multi-label learning with streaming label. Neurocomputing 2020, 387, 268–278. [Google Scholar] [CrossRef]
- Lin, Y.; Hu, Q.; Liu, J.; Li, J.; Wu, X. Streaming feature selection for multilabel learning based on fuzzy mutual information. IEEE Trans. Fuzzy Syst. 2017, 25, 1491–1507. [Google Scholar] [CrossRef]
- Kong, D.; Fujimaki, R.; Liu, J.; Nie, F.; Ding, C. Exclusive Feature Learning on Arbitrary Structures via ℓ1,2-norm. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1655–1663. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef] [Green Version]
- Tsoumakas, G.; Spyromitros-Xioufis, E.; Vilcek, J.; Vlahavas, I. Mulan: A java library for multi-label learning. J. Mach. Learn Res. 2011, 12, 2411–2414. [Google Scholar]
- Zhang, P.; Gao, W.; Hu, J.; Li, Y. Multi-label feature selection based on the division of label topics. Inf. Sci. 2021, 553, 129–153. [Google Scholar] [CrossRef]
- Ueda, N.; Saito, K. Parametric mixture models for multi-labeled text. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2003; pp. 737–744. [Google Scholar]
- Zhang, Y.; Zhou, Z.H. Multilabel dimensionality reduction via dependence maximization. ACM Trans. Knowl. Discov. Data 2010, 4, 1–21. [Google Scholar] [CrossRef]
- Doquire, G.; Verleysen, M. Feature selection for multi-label classification problems. In International Work-Conference on Artificial Neural Networks; Springer: Berlin/Heidelberger, Germany, 2011; pp. 9–16. [Google Scholar]
- Szymański, P.; Kajdanowicz, T. A scikit-based Python environment for performing multi-label classification. arXiv 2017, arXiv:1702.01460. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviations | Corresponding Meanings |
|---|---|
| FR | A novel feature relevance term |
| LR | A label-related feature redundancy term |
| TCRFS | Feature Selection combining three types of Conditional Relevance |
| Methods | Feature Relevance Terms | Feature Redundancy Terms |
|---|---|---|
| D2F | ||
| PMU | ||
| SCLS | None | |
| MUCO | ||
| TCRFS |
| No. | Data Set | #Domains | #Labels | #Features | #Training | #Test | #Instance |
|---|---|---|---|---|---|---|---|
| 1 | Birds | Audio | 19 | 260 | 322 | 323 | 645 |
| 2 | Emotions | Music | 6 | 72 | 391 | 202 | 593 |
| 3 | Genbase | Biology | 27 | 1185 | 463 | 199 | 662 |
| 4 | Yeast | Biology | 14 | 103 | 1500 | 917 | 2417 |
| 5 | Medical | Text | 45 | 1449 | 333 | 645 | 978 |
| 6 | Entertain | Text | 21 | 640 | 2000 | 3000 | 5000 |
| 7 | Recreation | Text | 22 | 606 | 2000 | 3000 | 5000 |
| 8 | Arts | Text | 26 | 462 | 2000 | 3000 | 5000 |
| 9 | Health | Text | 32 | 612 | 2000 | 3000 | 5000 |
| 10 | Education | Text | 33 | 550 | 2000 | 3000 | 5000 |
| 11 | Reference | Text | 33 | 793 | 2000 | 3000 | 5000 |
| 12 | Social | Text | 39 | 1047 | 2000 | 3000 | 5000 |
| 13 | Science | Text | 40 | 743 | 2000 | 3000 | 5000 |
| 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
| 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| 1 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 1 |
| 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 |
| 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 |
| 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 |
| 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 1 |
| Methods | Feature Ranking | SVM | ML-kNN | ||||
|---|---|---|---|---|---|---|---|
| Macro- ↑ | Micro- ↑ | Macro- ↑ | Micro- ↑ | HL ↓ | ZOL ↓ | ||
| TCRFS | 0.332 | 0.457 | 0.375 | 0.435 | 0.5000 | 0.97 | |
| D2F | 0.331 | 0.455 | 0.374 | 0.431 | 0.5150 | 0.97 | |
| PMU | 0.331 | 0.455 | 0.374 | 0.431 | 0.5150 | 0.97 | |
| SCLS | 0.32 | 0.409 | 0.373 | 0.427 | 0.5025 | 0.98 | |
| MUCO | 0.331 | 0.397 | 0.334 | 0.385 | 0.5450 | 0.98 | |
| Data Set | RALM-FS | D2F | PMU | SCLS | FSSL | MUCO | TCRFS |
|---|---|---|---|---|---|---|---|
| Birds | 0.0580.024 | 0.0770.04 | 0.0750.036 | 0.0390.026 | 0.0490.027 | 0.10.051 | 0.1160.058 |
| Emotions | 0.1470.101 | 0.3150.061 | 0.2390.095 | 0.3360.055 | 0.350.085 | 0.3660.127 | 0.3810.089 |
| Genbase | 0.7380.153 | 0.7060.107 | 0.6280.093 | 0.2410.022 | 0.7620.133 | 0.7580.14 | 0.7650.129 |
| Yeast | 0.2290.036 | 0.2580.034 | 0.2620.031 | 0.2070.014 | 0.2130.037 | 0.2270.044 | 0.2760.036 |
| Medical | 0.1290.063 | 0.1910.055 | 0.1880.057 | 0.0790.013 | 0.2270.086 | 0.2540.074 | 0.3110.075 |
| Entertain | 0.0590.022 | 0.0810.006 | 0.0510.004 | 0.0670.006 | 0.0750.028 | 0.0580.013 | 0.1190.023 |
| Recreation | 0.0240.008 | 0.0770.009 | 0.0260.002 | 0.0440.004 | 0.0420.024 | 0.0410.018 | 0.1050.019 |
| Arts | 0.0240.014 | 0.0310.005 | 0.0140.007 | 0.0270.005 | 0.0250.014 | 0.0260.014 | 0.0720.024 |
| Health | 0.0620.021 | 0.0890.008 | 0.0780.008 | 0.0890.01 | 0.0870.022 | 0.0770.021 | 0.1410.028 |
| Education | 0.0240.009 | 0.0460.009 | 0.0270.008 | 0.0380.006 | 0.0410.015 | 0.0410.019 | 0.0650.013 |
| Reference | 0.0230.01 | 0.0390.004 | 0.0260.006 | 0.0240.004 | 0.030.011 | 0.040.017 | 0.0650.013 |
| Social | 0.0460.018 | 0.070.01 | 0.0520.012 | 0.0520.006 | 0.0550.02 | 0.0590.019 | 0.1010.028 |
| Science | 0.0080.006 | 0.0210.003 | 0.0090.005 | 0.0160.004 | 0.0230.013 | 0.0240.013 | 0.0490.017 |
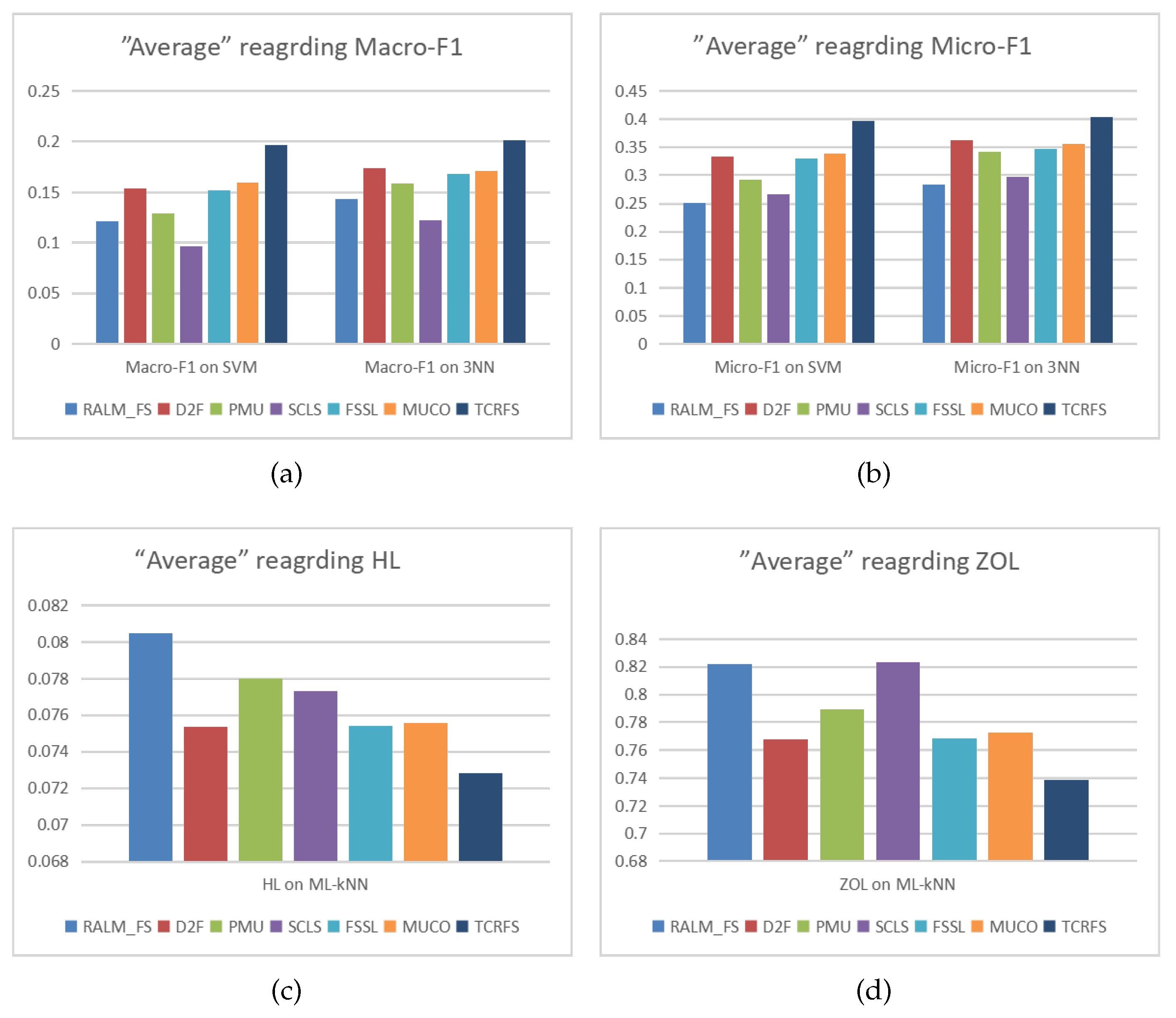
| Average | 0.121 | 0.154 | 0.129 | 0.097 | 0.152 | 0.159 | 0.197 |
| Data Set | RALM-FS | D2F | PMU | SCLS | FSSL | MUCO | TCRFS |
|---|---|---|---|---|---|---|---|
| Birds | 0.0960.046 | 0.1350.075 | 0.1290.055 | 0.060.04 | 0.0840.049 | 0.1970.078 | 0.2070.086 |
| Emotions | 0.1780.113 | 0.3720.038 | 0.2950.099 | 0.4220.038 | 0.4340.06 | 0.4250.118 | 0.450.07 |
| Genbase | 0.9580.136 | 0.9680.066 | 0.9460.066 | 0.5410.014 | 0.9690.108 | 0.9770.071 | 0.9790.067 |
| Yeast | 0.5520.027 | 0.5650.023 | 0.5710.021 | 0.5320.008 | 0.540.026 | 0.5490.031 | 0.5840.027 |
| Medical | 0.3630.147 | 0.6290.07 | 0.6250.075 | 0.370.009 | 0.6610.168 | 0.7110.087 | 0.7530.058 |
| Entertain | 0.1080.043 | 0.1630.015 | 0.0960.013 | 0.1490.016 | 0.1920.062 | 0.1270.041 | 0.2510.054 |
| Recreation | 0.0430.018 | 0.1380.016 | 0.0380.003 | 0.070.007 | 0.0650.038 | 0.0770.034 | 0.1980.035 |
| Arts | 0.0590.033 | 0.0750.013 | 0.0330.016 | 0.0720.015 | 0.0620.033 | 0.0560.031 | 0.160.051 |
| Health | 0.4010.018 | 0.4180.012 | 0.3910.029 | 0.4060.004 | 0.4260.02 | 0.3960.061 | 0.4790.026 |
| Education | 0.0730.024 | 0.1170.017 | 0.0770.014 | 0.1380.023 | 0.1420.056 | 0.1320.06 | 0.2030.045 |
| Reference | 0.1530.077 | 0.3050.039 | 0.2650.05 | 0.2590.039 | 0.2860.062 | 0.3140.093 | 0.3440.058 |
| Social | 0.2520.107 | 0.3960.072 | 0.310.07 | 0.3840.049 | 0.3570.105 | 0.3560.082 | 0.4260.073 |
| Science | 0.0290.015 | 0.0530.01 | 0.0240.016 | 0.0580.014 | 0.0710.034 | 0.0740.037 | 0.1220.032 |
| Average | 0.251 | 0.333 | 0.292 | 0.266 | 0.33 | 0.338 | 0.397 |
| Data Set | RALM-FS | D2F | PMU | SCLS | FSSL | MUCO | TCRFS |
|---|---|---|---|---|---|---|---|
| Birds | 0.0930.036 | 0.150.066 | 0.1220.036 | 0.0780.028 | 0.0750.037 | 0.1310.038 | 0.170.048 |
| Emotions | 0.3120.074 | 0.4340.033 | 0.4130.046 | 0.4260.042 | 0.4420.124 | 0.4340.101 | 0.4680.068 |
| Genbase | 0.6890.132 | 0.650.086 | 0.6040.089 | 0.2240.018 | 0.7020.12 | 0.70.123 | 0.710.103 |
| Yeast | 0.30.027 | 0.3480.038 | 0.340.03 | 0.3010.026 | 0.3090.041 | 0.3140.033 | 0.3340.039 |
| Medical | 0.0690.029 | 0.1210.019 | 0.1140.018 | 0.0630.006 | 0.1490.04 | 0.1550.03 | 0.1840.025 |
| Entertain | 0.0790.031 | 0.1080.011 | 0.0830.014 | 0.0950.013 | 0.0940.028 | 0.0890.014 | 0.1280.019 |
| Recreation | 0.060.014 | 0.0820.011 | 0.0530.01 | 0.0660.011 | 0.0570.026 | 0.0570.021 | 0.1140.019 |
| Arts | 0.0360.018 | 0.0640.01 | 0.0580.014 | 0.0720.016 | 0.0610.026 | 0.0640.019 | 0.0920.02 |
| Health | 0.0640.027 | 0.0870.011 | 0.0930.008 | 0.0870.011 | 0.0870.024 | 0.080.018 | 0.1220.022 |
| Education | 0.0470.011 | 0.0650.009 | 0.0570.009 | 0.0590.01 | 0.0630.015 | 0.060.019 | 0.0740.012 |
| Reference | 0.0320.01 | 0.0440.004 | 0.0340.007 | 0.0360.005 | 0.0410.01 | 0.0460.015 | 0.070.011 |
| Social | 0.0520.013 | 0.0640.006 | 0.0540.006 | 0.0510.004 | 0.0640.024 | 0.0580.016 | 0.0910.011 |
| Science | 0.0240.008 | 0.040.005 | 0.0280.008 | 0.030.004 | 0.0390.019 | 0.0360.011 | 0.0570.012 |
| Average | 0.143 | 0.174 | 0.158 | 0.122 | 0.168 | 0.171 | 0.201 |
| Data Set | RALM-FS | D2F | PMU | SCLS | FSSL | MUCO | TCRFS |
|---|---|---|---|---|---|---|---|
| Birds | 0.1710.066 | 0.2310.072 | 0.2030.05 | 0.1440.043 | 0.1590.054 | 0.2270.057 | 0.2730.061 |
| Emotions | 0.3530.051 | 0.4690.02 | 0.4450.022 | 0.460.028 | 0.4780.114 | 0.4710.079 | 0.5030.05 |
| Genbase | 0.9560.134 | 0.950.061 | 0.9190.064 | 0.5180.012 | 0.9590.126 | 0.9740.074 | 0.9770.065 |
| Yeast | 0.5290.019 | 0.5490.041 | 0.5530.014 | 0.5180.035 | 0.5260.049 | 0.5230.041 | 0.5520.041 |
| Medical | 0.2940.108 | 0.530.038 | 0.5220.037 | 0.3530.013 | 0.5580.121 | 0.5910.053 | 0.6380.032 |
| Entertain | 0.1870.085 | 0.2410.032 | 0.220.053 | 0.2170.031 | 0.2290.037 | 0.2340.048 | 0.2490.032 |
| Recreation | 0.1020.014 | 0.1590.024 | 0.0940.02 | 0.1150.017 | 0.1110.045 | 0.1120.041 | 0.2240.033 |
| Arts | 0.0950.045 | 0.150.031 | 0.1370.028 | 0.1720.028 | 0.1260.044 | 0.1550.029 | 0.2370.028 |
| Health | 0.20.097 | 0.3670.05 | 0.3610.038 | 0.3660.064 | 0.330.092 | 0.3390.038 | 0.380.063 |
| Education | 0.2540.026 | 0.190.032 | 0.180.04 | 0.190.033 | 0.2380.032 | 0.1910.054 | 0.220.036 |
| Reference | 0.1640.073 | 0.3640.048 | 0.350.043 | 0.2940.048 | 0.3340.049 | 0.3190.085 | 0.420.046 |
| Social | 0.3020.04 | 0.390.051 | 0.3630.051 | 0.3680.04 | 0.3540.069 | 0.3490.056 | 0.4320.045 |
| Science | 0.080.037 | 0.1230.019 | 0.0990.018 | 0.1470.034 | 0.1120.041 | 0.1360.037 | 0.1530.031 |
| Average | 0.284 | 0.363 | 0.342 | 0.297 | 0.347 | 0.355 | 0.404 |
| Data Set | RALM-FS | D2F | PMU | SCLS | FSSL | MUCO | TCRFS |
|---|---|---|---|---|---|---|---|
| Birds | 0.050810.00106 | 0.052690.00164 | 0.052270.0017 | 0.05440.00188 | 0.05260.00143 | 0.051380.00133 | 0.051470.00103 |
| Emotions | 0.337520.01318 | 0.294080.01324 | 0.318540.00914 | 0.279470.00716 | 0.29220.01356 | 0.288780.02079 | 0.280120.01018 |
| Genbase | 0.003770.0068 | 0.003150.00391 | 0.004690.00405 | 0.030930.00042 | 0.003010.00585 | 0.002960.00433 | 0.002690.00396 |
| Yeast | 0.237060.00434 | 0.227840.00287 | 0.227930.00356 | 0.23320.00431 | 0.231820.00293 | 0.233410.00377 | 0.225650.00404 |
| Medical | 0.027020.0007 | 0.019550.00105 | 0.019720.00107 | 0.023320.00018 | 0.018420.00237 | 0.018520.00108 | 0.017740.0009 |
| Entertain | 0.066520.00057 | 0.065680.00133 | 0.067080.00112 | 0.065870.00144 | 0.064150.00103 | 0.066310.00085 | 0.063150.00145 |
| Recreation | 0.065130.00038 | 0.062390.00077 | 0.064840.00068 | 0.064440.0006 | 0.065130.00069 | 0.064190.0007 | 0.061440.00111 |
| Arts | 0.062850.00023 | 0.06350.00122 | 0.064410.00104 | 0.063390.00074 | 0.063890.00057 | 0.064120.00075 | 0.061350.00063 |
| Health | 0.049690.00132 | 0.048310.00051 | 0.049340.00059 | 0.048480.00114 | 0.047640.00101 | 0.048980.00068 | 0.045450.00111 |
| Education | 0.044140.00034 | 0.044270.00073 | 0.044530.00082 | 0.044080.00101 | 0.044030.0006 | 0.04440.00054 | 0.043030.00069 |
| Reference | 0.035030.00035 | 0.032230.00117 | 0.033570.00095 | 0.03290.00021 | 0.032620.00068 | 0.033320.00061 | 0.031330.00075 |
| Social | 0.030610.00122 | 0.030320.00046 | 0.030910.00031 | 0.028660.0007 | 0.029060.00092 | 0.029670.00055 | 0.027660.00077 |
| Science | 0.036150.00028 | 0.035790.0004 | 0.036260.00036 | 0.035830.00041 | 0.035670.00027 | 0.03610.00058 | 0.035430.00042 |
| Average | 0.08048 | 0.07537 | 0.07801 | 0.07731 | 0.0754 | 0.07555 | 0.07281 |
| Data Set | RALM-FS | D2F | PMU | SCLS | FSSL | MUCO | TCRFS |
|---|---|---|---|---|---|---|---|
| Birds | 0.532390.00619 | 0.533520.01484 | 0.550130.02117 | 0.535430.00551 | 0.527450.00789 | 0.530070.00864 | 0.540190.01396 |
| Emotions | 0.924680.03724 | 0.828150.02803 | 0.883310.05054 | 0.855020.03048 | 0.854310.03856 | 0.839820.03592 | 0.835220.02541 |
| Genbase | 0.079090.15179 | 0.069760.07896 | 0.092360.07004 | 0.563790.01154 | 0.062850.12667 | 0.060580.07839 | 0.057950.0815 |
| Yeast | 0.947290.02727 | 0.886020.02723 | 0.891680.02807 | 0.916710.01147 | 0.92330.03139 | 0.916130.03483 | 0.885860.01848 |
| Medical | 0.866040.07297 | 0.656110.03702 | 0.662570.04058 | 0.826170.00642 | 0.620480.0981 | 0.615370.0484 | 0.589320.0373 |
| Entertain | 0.944470.01955 | 0.905650.01002 | 0.941360.00863 | 0.903450.01303 | 0.883090.03407 | 0.914410.02957 | 0.857520.02652 |
| Recreation | 0.979550.01057 | 0.920660.00898 | 0.971220.00609 | 0.953270.00543 | 0.956810.02178 | 0.94930.02212 | 0.877960.01967 |
| Arts | 0.963990.0181 | 0.95480.01101 | 0.970610.0167 | 0.95290.01086 | 0.963640.02175 | 0.962340.02165 | 0.921960.02549 |
| Health | 0.75610.0662 | 0.771590.05271 | 0.771520.04486 | 0.736610.0437 | 0.748910.05006 | 0.78760.05694 | 0.708670.04394 |
| Education | 0.952810.0162 | 0.948330.00936 | 0.954890.01428 | 0.93390.01388 | 0.941760.02666 | 0.938680.02975 | 0.901710.02493 |
| Reference | 0.907760.05755 | 0.803130.03802 | 0.810680.05208 | 0.82840.0372 | 0.808290.04754 | 0.804330.0658 | 0.75910.06182 |
| Social | 0.847350.07255 | 0.732360.08727 | 0.774990.06847 | 0.744630.04251 | 0.751380.08065 | 0.762430.052 | 0.723140.05028 |
| Science | 0.986630.00642 | 0.97250.00583 | 0.984770.00815 | 0.954880.01192 | 0.951390.01995 | 0.961110.02084 | 0.944410.0112 |
| Average | 0.82217 | 0.76789 | 0.78924 | 0.82347 | 0.76874 | 0.77247 | 0.73869 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, L.; Wang, Y.; Li, Y.; Zhang, P.; Hu, L. Multi-Label Feature Selection Combining Three Types of Conditional Relevance. Entropy 2021, 23, 1617. https://doi.org/10.3390/e23121617
Gao L, Wang Y, Li Y, Zhang P, Hu L. Multi-Label Feature Selection Combining Three Types of Conditional Relevance. Entropy. 2021; 23(12):1617. https://doi.org/10.3390/e23121617
Chicago/Turabian StyleGao, Lingbo, Yiqiang Wang, Yonghao Li, Ping Zhang, and Liang Hu. 2021. "Multi-Label Feature Selection Combining Three Types of Conditional Relevance" Entropy 23, no. 12: 1617. https://doi.org/10.3390/e23121617