
Automatic Representative View Selection of a 3D Cultural Relic Using Depth Variation Entropy and Depth Distribution Entropy


Abstract
:1. Introduction
2. Related Work
2.1. Selection of the Best View of 3D Objects
2.2. View-Based 3D Model Retrieval and Classification
3. The Proposed Method
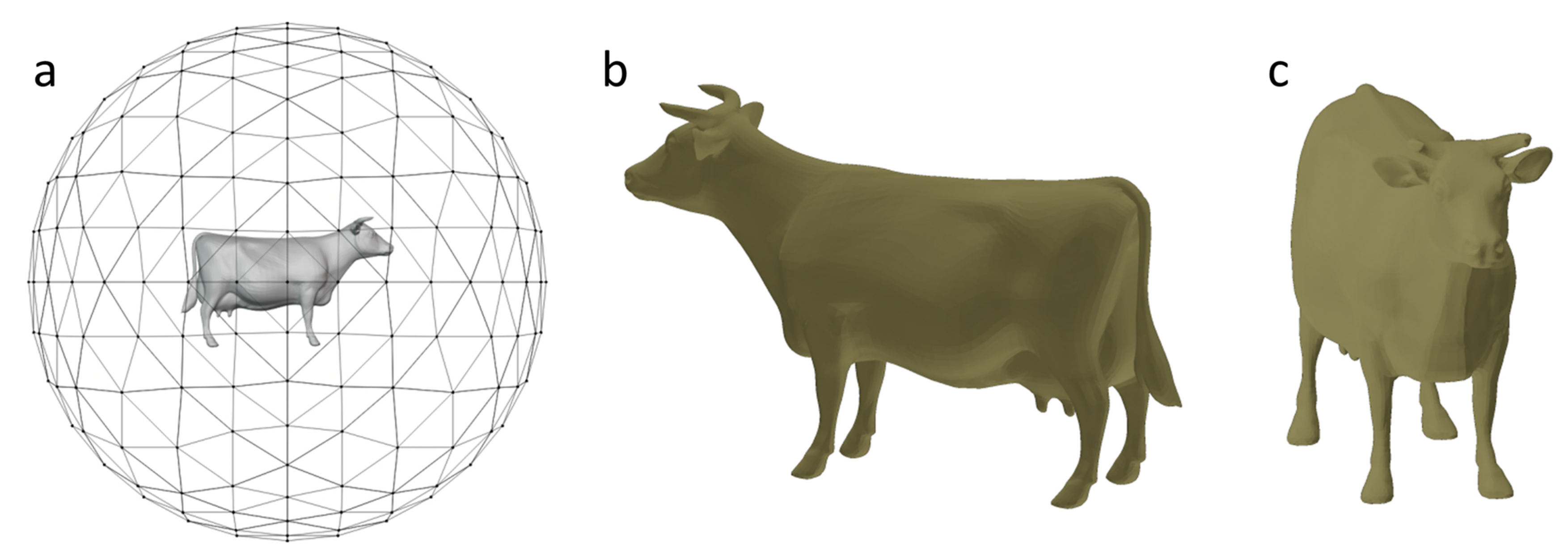
3.1. Depth Variation Entropy and Depth Distribution Entropy
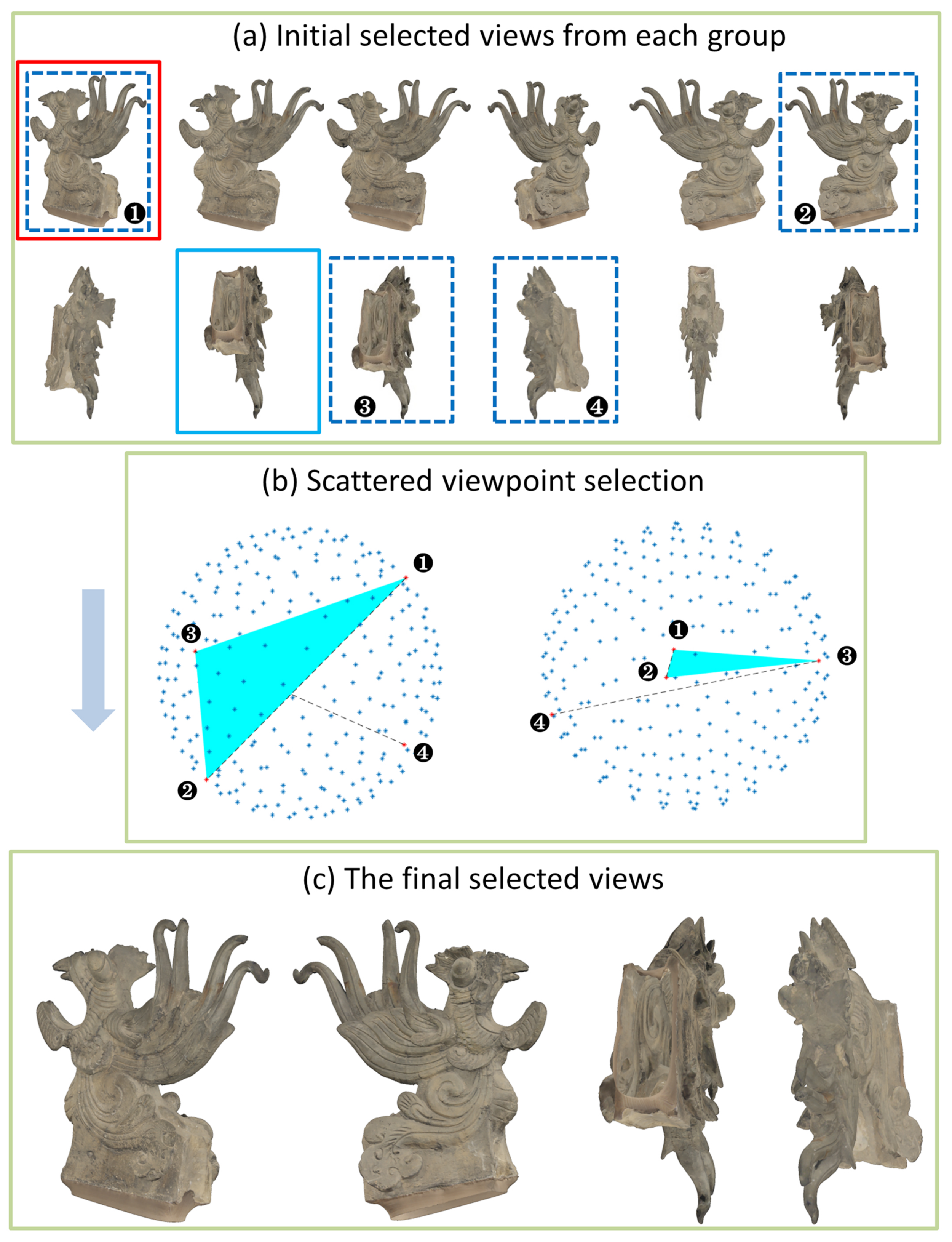
3.2. Multi-View Selection
- Step 1.
- Remove the duplicate views in the acquired view; there will be at least four views after this step.
- Step 2.
- Calculate the direction vector from the spherical center point to each viewpoint position and find the two viewpoint positions belonging to with the largest included angle between their direction vectors.
- Step 3.
- In , calculate the triangle area composed of each viewpoint position and the two determined viewpoints’ positions. The vertex that maximizes the area of the triangle is the third choice.
- Step 4.
- Find the fourth viewpoint position in with the largest angle for the third selected viewpoint position.
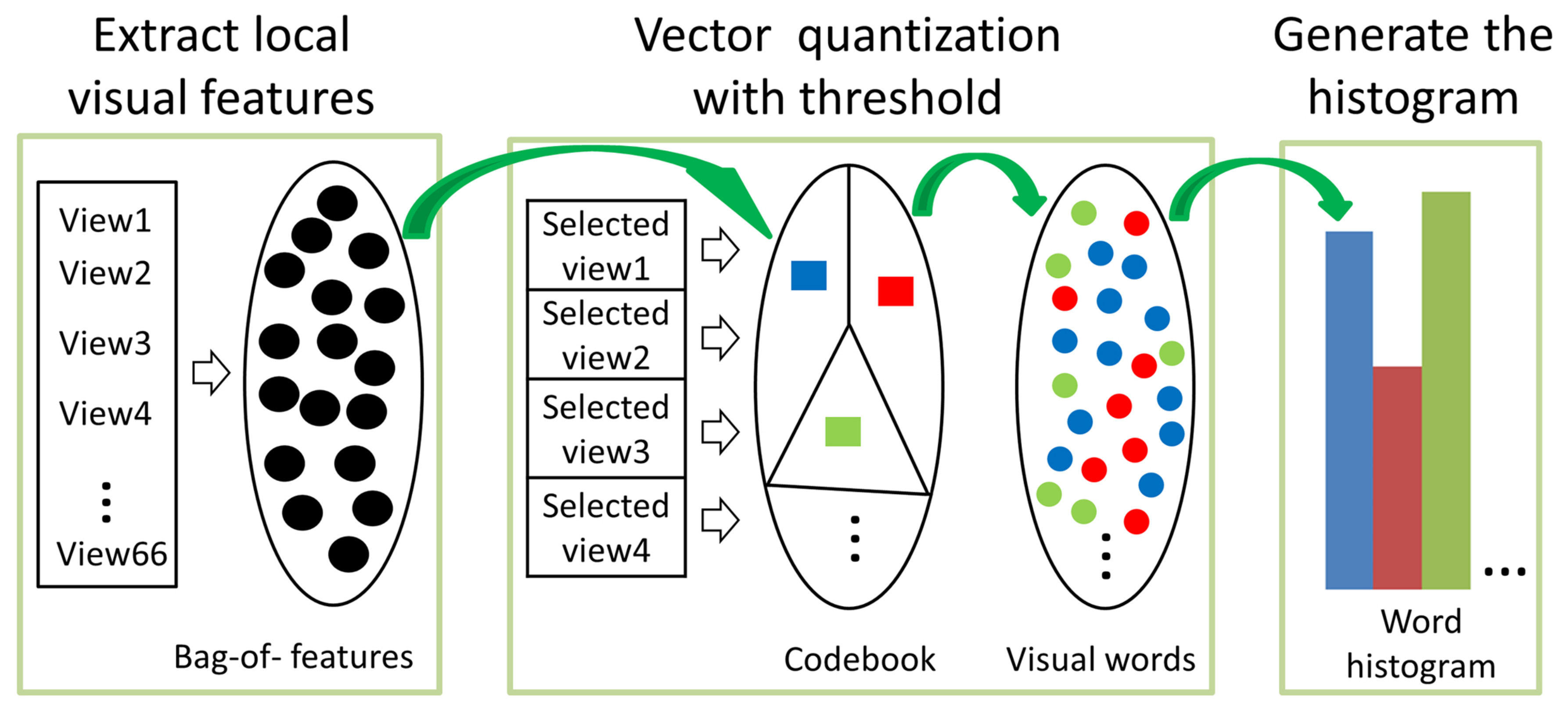
3.3. Threshold Word Histogram Method for Representative Analysis
4. Experiment Results and Analysis
4.1. Generally Applicability of Multi-View Selection
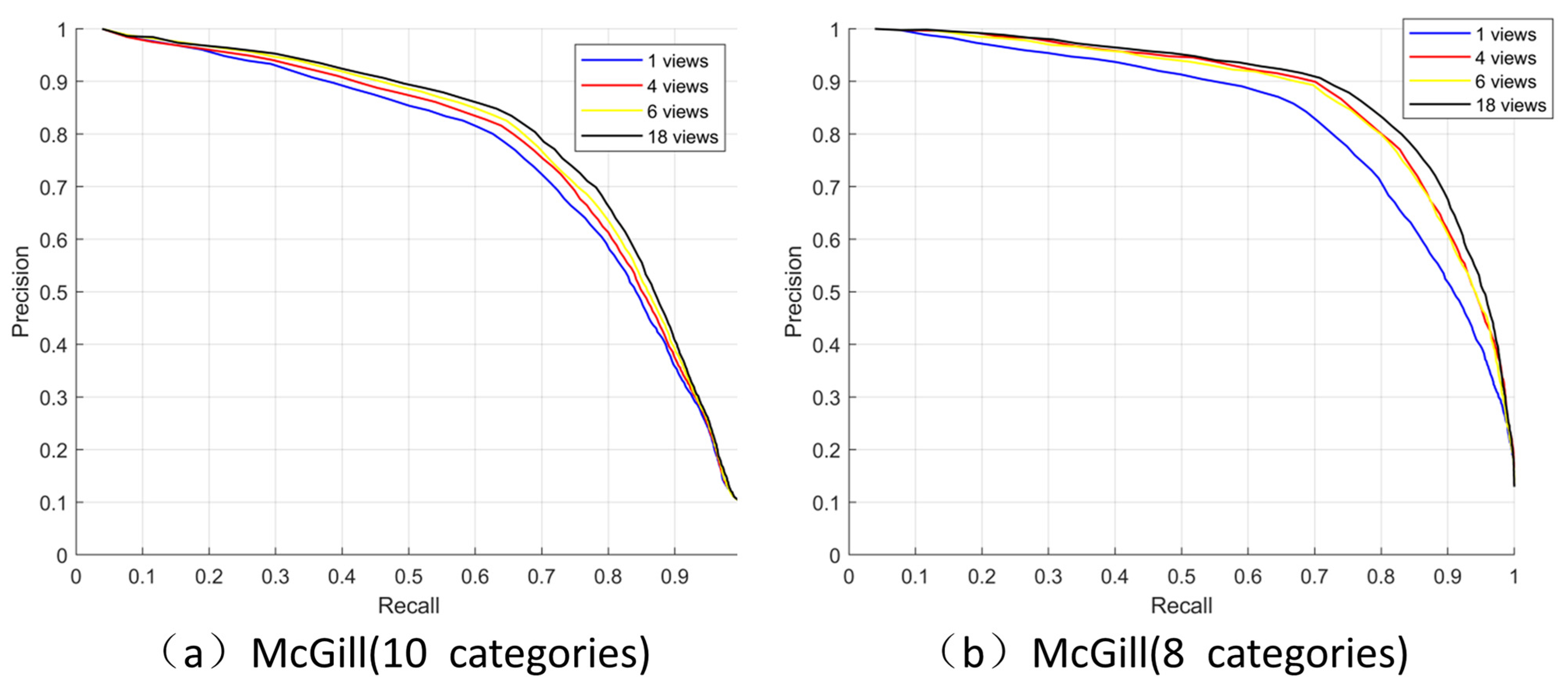
4.2. Evaluation of Small Number Views to Represent a 3D Model
4.2.1. Evaluation of the Threshold Word Histogram Method
4.2.2. Applicability of a Small Number of Views
4.2.3. Classification Using a Small Number of Views Based on Deep Learning
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- O’Rourke, J. Art Gallery Theorems and Algorithms; Oxford University Press: Oxford, UK, 1987. [Google Scholar]
- Papadimitriou, F. Spatial Complexity. Theory, Mathematical Methods and Applications; Springer: Genoa, Italy, 2020. [Google Scholar]
- Zhang, M.; Geng, G.; Zeng, S.; Jia, H. Knowledge Graph Completion for the Chinese Text of Cultural Relics Based on Bidirectional Encoder Representations from Transformers with Entity-Type Information. Entropy 2020, 22, 1168. [Google Scholar] [CrossRef] [PubMed]
- Bonaventura, X.; Feixas, M.; Sbert, M.; Chuang, L.; Wallraven, C. A Survey of Viewpoint Selection Methods for Polygonal Models. Entropy 2018, 20, 370. [Google Scholar] [CrossRef] [Green Version]
- Dutagaci, H.; Cheung, C.P.; Godil, A. A benchmark for best view selection of 3D objects. In Proceedings of the 3DOR’10—2010 ACM Workshop on 3D Object Retrieval, Co-Located with ACM Multimedia 2010, Firenze, Italy, 25 October 2010; pp. 45–50. [Google Scholar]
- Vazquez, P.P.; Feixas, M.; Sbert, M.; Heidrich, W. Automatic view selection using viewpoint entropy and its application to image-based modelling. Comput. Graph. Forum 2003, 22, 689–700. [Google Scholar] [CrossRef]
- Sbert, M.; Plemenos, D.; Feixas, M.; González, F. Viewpoint quality: Measures and applications. In Proceedings of the First Eurographics Conference on Computational Aesthetics in Graphics, Visualization and Imaging, Girona, Spain, 18–20 May 2005; pp. 185–192. [Google Scholar]
- Feixas, M.; Sbert, M.; Gonzalez, F. A Unified Information-Theoretic Framework for Viewpoint Selection and Mesh Saliency. ACM Trans. Appl. Percept. 2009, 6, 1–23. [Google Scholar] [CrossRef]
- Secord; Lu, J.; Finkelstein, A.; Singh, M.; Nealen, A. Perceptual Models of Viewpoint Preference. ACM Trans. Graph. 2011, 30, 1–12. [Google Scholar]
- Siddiqi, K.; Zhang, J.; Macrini, D.; Shokoufandeh, A.; Bouix, S.; Dickinson, S. Retrieving articulated 3-D models using medial surfaces. Mach. Vis. Appl. 2008, 19, 261–275. [Google Scholar] [CrossRef] [Green Version]
- Shilane, P.; Min, P.; Kazhdan, M.; Funkhouser, T. The Princeton shape benchmark. In Proceedings of the Shape Modeling International 2004, Genova, Italy, 7–9 June 2004; pp. 167–178. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Plemenos, D.; Benayada, M. New Techniques to Automatically Compute Good Views. In Proceedings of the International Conference GraphiCon’96, St. Petersbourg, Russia, 22–25 September 2020. [Google Scholar]
- Vázquez, P.-P.; Feixas, M.; Sbert, M.; Heidrich, W. Viewpoint selection using viewpoint entropy. In Proceedings of the Vision Modeling and Visualization Conference (VMV-01), Stuttgart, Germany, 21–23 November 2001; pp. 273–280. [Google Scholar]
- Stoev, S.L.; Strasser, W. A case study on automatic camera placement and motion for visualizing historical data. In Proceedings of the IEEE Visualization 2002 Conference, Boston, MA, USA, 30 October–1 November 2002; pp. 545–548. [Google Scholar]
- Page, D.L.; Koschan, A.F.; Sukumar, S.R.; Roui-Abidi, B.; Abidi, M.A. Shape analysis algorithm based on information theory. In Proceedings of the IEEE International Conference on Image Processing, Barcelona, Spain, 14–17 September 2003; pp. 229–232. [Google Scholar]
- Lee, C.H.; Varshney, A.; Jacobs, D.W. Mesh saliency. ACM Trans. Graph. 2005, 24, 659–666. [Google Scholar] [CrossRef]
- Polonsky; Patane, G.; Biasotti, S.; Gotsman, C.; Spagnuolo, M. What’s in an image? Towards the computation of the "best” view of an object. Vis. Comput. 2005, 21, 840–847. [Google Scholar]
- Vazquez, P.-P. Automatic view selection through depth-based view stability analysis. Vis. Comput. 2009, 25, 441–449. [Google Scholar] [CrossRef] [Green Version]
- Vieira, T.; Bordignon, A.; Peixoto, A.; Tavares, G.; Lopes, H.; Velho, L.; Lewiner, T. Learning good views through intelligent galleries. Comput. Graph. Forum 2009, 28, 717–726. [Google Scholar] [CrossRef]
- Bonaventura, X.; Guo, J.; Meng, W.; Feixas, M.; Zhang, X.; Sbert, M. Viewpoint information-theoretic measures for 3D shape similarity. In Proceedings of the 12th ACM SIGGRAPH International Conference on Virtual-Reality Continuum and Its Applications in Industry, Hong Kong, China, 17–19 November 2013; pp. 183–190. [Google Scholar]
- Song, J.-J.; Golshani, F. 3D object retrieval by shape similarity. In Proceedings of the DEXA ’02: International Conference on Database and Expert Systems Applications, London, UK, 4–8 September 2002; pp. 851–860. [Google Scholar]
- Chen, D.Y.; Tian, X.P.; Shen, Y.T.; Ouhyoung, M. On visual similarity based 3D model retrieval. Comput. Graph. Forum 2003, 22, 223–232. [Google Scholar] [CrossRef]
- Shih, J.-L.; Lee, C.-H.; Wang, J.T. A new 3D model retrieval approach based on the elevation descriptor. Pattern Recognit. 2007, 40, 283–295. [Google Scholar] [CrossRef]
- Chaouch, M.; Verroust-Blondet, A. A new descriptor for 2D depth image indexing and 3D model retrieval. In Proceedings of the IEEE International Conference on Image Processing (ICIP 2007), San Antonio, TX, USA, 16–19 September 2007; pp. 3169–3172. [Google Scholar]
- Ohbuchi, R.; Osada, K.; Furuya, T.; Banno, T. Salient local visual features for shape-based 3D model retrieval. In Proceedings of the 2008 IEEE International Conference on Shape Modeling and Applications, Stony Brook, NY, USA, 4–6 June 2008; pp. 93–102. [Google Scholar]
- Daras, P.; Axenopoulos, A. A 3D Shape Retrieval Framework Supporting Multimodal Queries. Int. J. Comput. Vis. 2010, 89, 229–247. [Google Scholar] [CrossRef]
- Lian, Z.; Godil, A.; Sun, X.; Xiao, J. CM-BOF: Visual similarity-based 3D shape retrieval using Clock Matching and Bag-of-Features. Mach. Vis. Appl. 2013, 24, 1685–1704. [Google Scholar] [CrossRef]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Feng, Y.; Zhang, Z.; Zhao, X.; Ji, R.; Gao, Y. GVCNN: Group-View Convolutional Neural Networks for 3D Shape Recognition. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 264–272. [Google Scholar]
- Yu, Q.; Yang, C.; Fan, H.; Wei, H. Latent-MVCNN: 3D Shape Recognition Using Multiple Views from Pre-defined or Random Viewpoints. Neural Process. Lett. 2020, 52, 581–602. [Google Scholar] [CrossRef]
- Hristov, V.; Agre, G. A software system for classification of archaeological artefacts represented by 2D plans. Cybern. Inf. Technol. 2013, 13, 82–96. [Google Scholar] [CrossRef]
- Gao, H.; Geng, G.; Zeng, S. Approach for 3D Cultural Relic Classification Based on a Low-Dimensional Descriptor and Unsupervised Learning. Entropy 2020, 22, 1290. [Google Scholar] [CrossRef]
- Desai, P.; Pujari, J.; Ayachit, N.H.; Prasad, V.K. Classification of Archaeological Monuments for Different Art forms with an Application to CBIR. In Proceedings of the 2nd International Conference on Advances in Computing, Communications and Informatics (ICACCI), Sri Jayachamarajendra Coll Engn, Mysore, India, 22–25 August 2013; pp. 1108–1112. [Google Scholar]
- Manferdini; Remondino, F.; Baldissini, S.; Gaiani, M.; Benedetti, B. 3D modeling and semantic classification of archaeological finds for management and visualization in 3D archaeological databases. In Proceedings of the 14th International Conference on Virtual Systems and Multimedia, Limassol, Cyprus, 20–25 October 2008; pp. 221–228. [Google Scholar]
- Philipp-Foliguet, S.; Jordan, M.; Najman, L.; Cousty, J.J.P.R. Artwork 3D model database indexing and classification. Pattern Recognit. 2011, 44, 588–597. [Google Scholar] [CrossRef] [Green Version]
- Contreras-Reyes, J.E. Lerch distribution based on maximum nonsymmetric entropy principle: Application to Conway’s Game of Life cellular automaton. Chaos Solitons Fractals 2021, 151, 111272. [Google Scholar] [CrossRef]
- Zhao, X.; Shang, P.; Huang, J. Mutual-information matrix analysis for nonlinear interactions of multivariate time series. Nonlinear Dyn. 2021, 88, 477–487. [Google Scholar] [CrossRef]
- Vranic, D.V.; Saupe, D.; Richter, J. Tools for 3D-object retrieval: Karhunen-Loeve transform and spherical harmonics. In Proceedings of the 2001 IEEE Fourth Workshop on Multimedia Signal Processing, Cannes, France, 3–5 October 2001; pp. 293–298. [Google Scholar]
- Pharr, M.; Jakob, W.; Humphreys, G. Physically Based Rendering: From Theory to Implementation; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- VLFeat: An Open and Portable Library of Computer Vision Algorithms. 2008. Available online: http://www.vlfeat.org/ (accessed on 1 March 2021).
- Vranic, D.V.; Ieee, I. An improvement of rotation invariant 3D-shape descriptor based on functions on concentric spheres. In Proceedings of the IEEE International Conference on Image Processing, Barcelona, Spain, 14–17 September 2003; pp. 757–760. [Google Scholar]
- Kazhdan, M.; Funkhouser, T.; Rusinkiewicz, S. Rotation invariant spherical harmonic representation of 3D shape descriptors. In Proceedings of the 2003 Eurographics/ACM SIGGRAPH Symposium on Geometry Processing, Aachen, Germany, 23–25 June 2003; pp. 156–164. [Google Scholar]
- Osada, R.; Funkhouser, T.; Chazelle, B.; Dobkin, D. Matching 3D models with shape distributions. In Proceedings of the 3rd International Conference on Shape Modeling and Applications (SMI 2001), Genoa, Italy, 7–11 May 2001; pp. 154–166. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CM-BOF | LFD | Ours | REXT | SHD | GEDT | I2 | D2 | |
|---|---|---|---|---|---|---|---|---|
| 1-NN (%) | 73.1 | 65.7 | 65.3 | 60.2 | 55.6 | 60.3 | 39.4 | 31.1 |
| 1-Tier (%) | 47.0 | 38.0 | 36.0 | 32.7 | 30.9 | 31.3 | 20.8 | 15.8 |
| 2-Tier (%) | 59.8 | 48.7 | 46.9 | 43.2 | 41.1 | 40.7 | 27.9 | 23.5 |
| DCG (%) | 72.0 | 64.3 | 56.0 | 60.1 | 58.4 | 23.7 | 45.3 | 43.4 |
| McGill (10 Class) | McGill (8 Class) | |||||||
|---|---|---|---|---|---|---|---|---|
| Number of views | 1 | 4 | 6 | 18 | 1 | 4 | 6 | 18 |
| 1-Tier (%) | 68.9 | 70.7 | 71.8 | 73.0 | 74.1 | 78.6 | 78.6 | 80.5 |
| 2-Tier (%) | 83.2 | 83.8 | 84.2 | 84.7 | 88.7 | 91.5 | 91.4 | 92.3 |
| DCG (%) | 83.4 | 83.9 | 84.3 | 84.7 | 85.8 | 87.1 | 87.0 | 87.5 |
| Number of Views | 4 | 8 | 12 |
|---|---|---|---|
| Classification (Overall accuracy) | 85.1% | 86.3% | 92.5% |
| Classification (Mean accuracy) | 81.7% | 83.1% | 88.9% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, S.; Geng, G.; Zhou, M. Automatic Representative View Selection of a 3D Cultural Relic Using Depth Variation Entropy and Depth Distribution Entropy. Entropy 2021, 23, 1561. https://doi.org/10.3390/e23121561
Zeng S, Geng G, Zhou M. Automatic Representative View Selection of a 3D Cultural Relic Using Depth Variation Entropy and Depth Distribution Entropy. Entropy. 2021; 23(12):1561. https://doi.org/10.3390/e23121561
Chicago/Turabian StyleZeng, Sheng, Guohua Geng, and Mingquan Zhou. 2021. "Automatic Representative View Selection of a 3D Cultural Relic Using Depth Variation Entropy and Depth Distribution Entropy" Entropy 23, no. 12: 1561. https://doi.org/10.3390/e23121561