
Minimum Message Length Inference of the Exponential Distribution with Type I Censoring


Abstract
:1. Introduction
2. Exponential Distribution
2.1. Maximum Likelihood Estimation
3. Minimum Message Length
- the assertion: an encoding of the model structure and the associated model parameters .
- the detail: a description of the data D using the model that was specified in the assertion.
4. Minimum Message Length Inference of Type I Censored Exponential Data
- Transmit the censoring indicators first and then transmit the lifetime survival data given the receiver now knows which of the n data points are censored (see Section 4.1);
- Transmit the censoring indicators and the lifetime data simultaneously (see Section 4.2).
4.1. Conditional Encoding of the Data
4.2. Joint Encoding of the Data
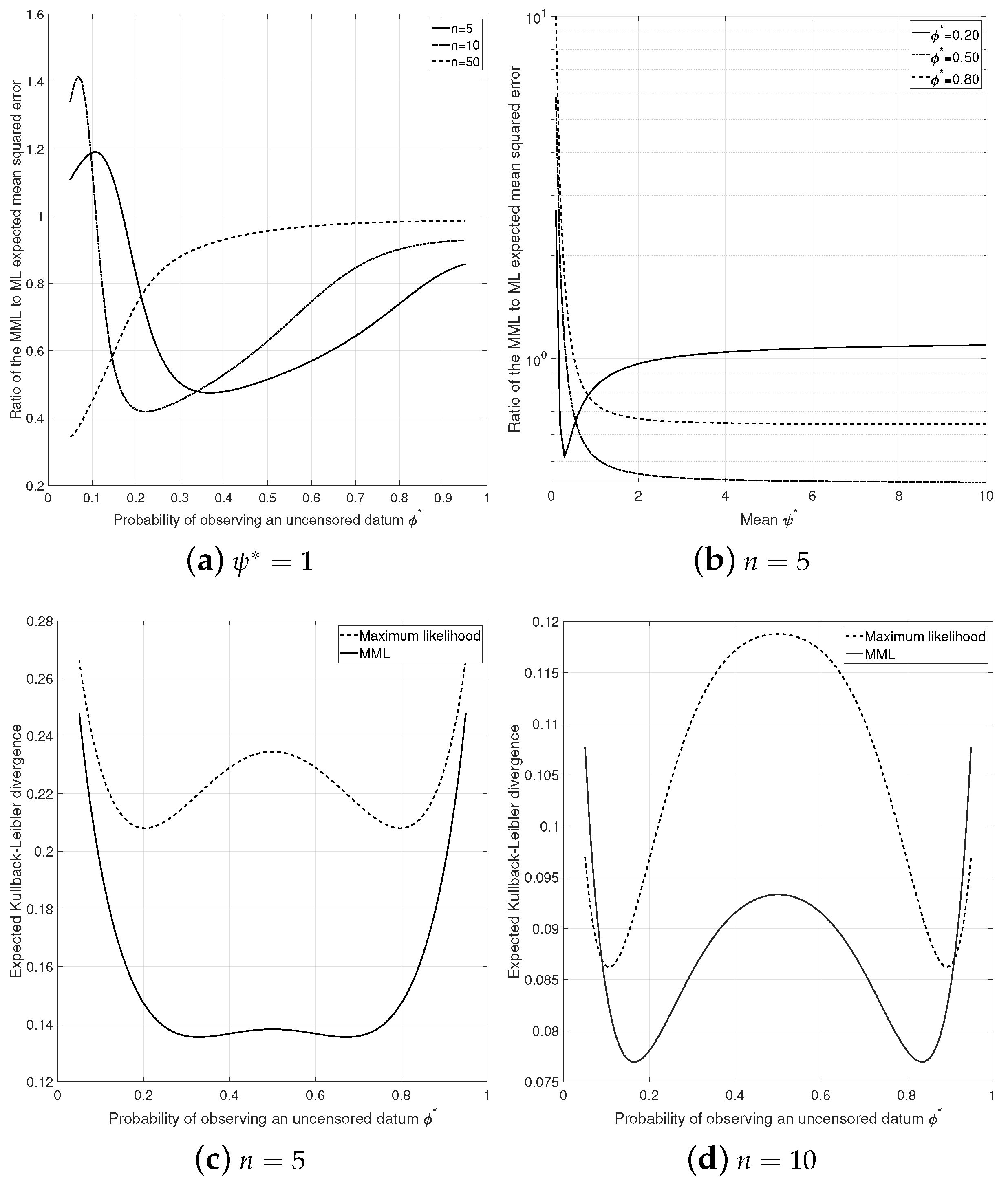
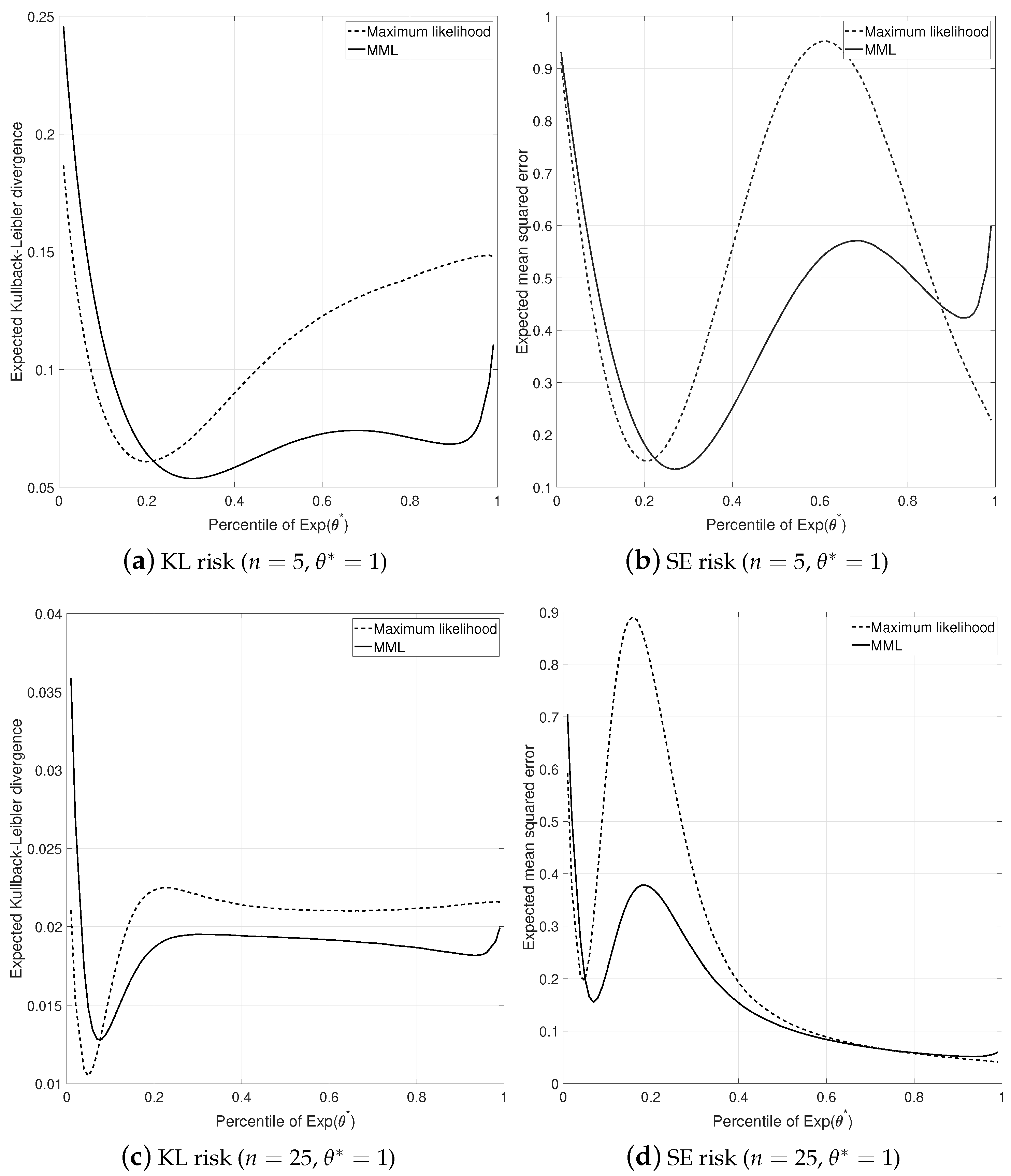
4.3. Properties
5. Minimum Message Length Inference with Fixed Censoring
5.1. Example
5.2. Properties
6. Discussion
6.1. Clustering Survival Data
6.2. Minimum Message Length and Minimum Description Length
- MDL relies on the maximum likelihood estimator and does not offer new means for parameter estimation;
- MDL is decidedly non-Bayesian avoiding the use of any (subjective or objective) prior information;
- MDL nominates the model class that would result in the shortest encoding of the data and does not does not infer a fully specified model;
- while MML minimises the expected (average) codelength of the data with respect to the marginal data distribution, MDL minimizes the worst-case codelength relative to the ideal code.
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AIC | Akaike information criterion |
| BIC | Bayesian information criterion |
| KL | Kullback–Leibler |
| MDL | Minimum description length |
| MML | Minimum message length |
| ML | Maximum likelihood |
| NML | Normalized maximum likelihood |
References
- Wallace, C.S. Statistical and Inductive Inference by Minimum Message Length, 1st ed.; Information Science and Statistics; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Wallace, C.S. False oracles and SMML estimators. In Proceedings of the International Conference on Information, Statistics and Induction in Science; World Scientific: Singapore, 1996; pp. 304–316. [Google Scholar]
- Wallace, C.S.; Dowe, D.L. Minimum Message Length and Kolmogorov Complexity. Comput. J. 1999, 42, 270–283. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, D.F.; Makalic, E. Universal Models for the Exponential Distribution. IEEE Trans. Inf. Theory 2009, 55, 3087–3090. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.S. Asymptotic properties of the maximum likelihood estimator of a randomly censored exponential parameter. Commun. Stat. Theory Methods 1986, 15, 3637–3646. [Google Scholar] [CrossRef]
- Bartholomew, D.J. The Sampling Distribution of an Estimate Arising in Life Testing. Technometrics 1963, 5, 3. [Google Scholar] [CrossRef]
- Mendenhall, W.; Lehman, E.H. An Approximation to the Negative Moments of the Positive Binomial Useful in Life Testing. Technometrics 1960, 2, 227–242. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Davies, K.F. Pitman closeness results for Type-I censored data from exponential distribution. Stat. Probab. Lett. 2013, 83, 2693–2698. [Google Scholar] [CrossRef]
- Wallace, C.S.; Boulton, D.M. An information measure for classification. Comput. J. 1968, 11, 185–194. [Google Scholar] [CrossRef] [Green Version]
- Wallace, C.S.; Freeman, P.R. Estimation and inference by compact coding. J. R. Stat. Soc. (Ser. B) 1987, 49, 240–252. [Google Scholar] [CrossRef]
- Wallace, C.S.; Dowe, D.L. Refinements of MDL and MML Coding. Comput. J. 1999, 42, 330–337. [Google Scholar] [CrossRef] [Green Version]
- Wallace, C.; Boulton, D. An invariant Bayes method for point estimation. Classif. Soc. Bull. 1975, 3, 11–34. [Google Scholar]
- Farr, G.E.; Wallace, C.S. The complexity of Strict Minimum Message Length inference. Comput. J. 2002, 45, 285–292. [Google Scholar] [CrossRef]
- Conway, J.H.; Sloane, N.J.A. Sphere Packing, Lattices and Groups, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 1998; p. 703. [Google Scholar]
- Agrell, E.; Eriksson, T. Optimization of lattices for quantization. IEEE Trans. Inf. Theory 1998, 44, 1814–1828. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Schmidt, D.F.; Makalic, E. Minimum message length analysis of multiple short time series. Stat. Probab. Lett. 2016, 110, 318–328. [Google Scholar] [CrossRef]
- Wallace, C.S.; Dowe, D.L. MML clustering of multi-state, Poisson, von Mises circular and Gaussian distributions. Stat. Comput. 2000, 10, 73–83. [Google Scholar] [CrossRef]
- Wong, C.K.; Makalic, E.; Schmidt, D.F. Minimum message length inference of the Poisson and geometric models using heavy-tailed prior distributions. J. Math. Psychol. 2018, 83, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Balasubramanian, V. MDL, Bayesian inference, and the geometry of the space of probability distributions. In Advances in Minimum Description Length: Theory and Applications; Grünwald, I.J.M., Pitt, M.A., Eds.; MIT Press: Cambridge, MA, USA, 2005; pp. 81–99. [Google Scholar]
- Wallace, C.S.; Patrick, J.D. Coding Decision Trees. Mach. Learn. 1993, 11, 7–22. [Google Scholar] [CrossRef] [Green Version]
- Wallace, C.S.; Freeman, P.R. Single-Factor Analysis by Minimum Message Length Estimation. J. R. Stat. Soc. (Ser. B) 1992, 54, 195–209. [Google Scholar] [CrossRef]
- Wallace, C.S.; Korb, K.B. Learning linear causal models by MML sampling. In Causal Models and Intelligent Data Management; Gammerman, A., Ed.; Springer: Berlin/Heidelberg, Germany, 1999; pp. 89–111. [Google Scholar]
- Schmidt, D.F.; Makalic, E. Minimum Message Length Inference and Mixture Modelling of Inverse Gaussian Distributions. In AI 2012: Advances in Artificial Intelligence; Lecture Notes in Computer Science; Thielscher, M., Zhang, D., Eds.; Springer: Berlin/Heidelberg, Germany; Sydney, Australia, 2012; Volume 7691, pp. 672–682. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control. 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Polson, N.G.; Scott, J.G. On the Half-Cauchy Prior for a Global Scale Parameter. Bayesian Anal. 2012, 7, 887–902. [Google Scholar] [CrossRef]
- Rossi, P.; Berk, R.A.; Lenihan, K.J. Money, Work, and Crime: Some Experimental Results; Academic Press: Cambridge, MA, USA, 1980. [Google Scholar]
- Andersen, P.K.; Borgan, Ø.; Gill, R.D.; Keiding, N. Statistical Models Based on Counting Processes; Springer: Berlin, Germany, 2012. [Google Scholar] [CrossRef]
- Kohjima, M.; Matsubayashi, T.; Toda, H. Variational Bayes for Mixture Models with Censored Data. In Machine Learning and Knowledge Discovery in Databases; Springer International Publishing: Berlin, Germany, 2019; pp. 605–620. [Google Scholar] [CrossRef]
- Bou-Hamad, I.; Larocque, D.; Ben-Ameur, H. A review of survival trees. Stat. Surv. 2011, 5, 44–71. [Google Scholar] [CrossRef]
- Dauda, K.A.; Pradhan, B.; Shankar, B.U.; Mitra, S. Decision tree for modeling survival data with competing risks. Biocybern. Biomed. Eng. 2019, 39, 697–708. [Google Scholar] [CrossRef]
- Rissanen, J. Modeling by shortest data description. Automatica 1978, 14, 465–471. [Google Scholar] [CrossRef]
- Rissanen, J. Fisher information and stochastic complexity. IEEE Trans. Inf. Theory 1996, 42, 40–47. [Google Scholar] [CrossRef]
- Rissanen, J.; Roos, T. Conditional NML Universal Models. In Proceedings of the 2007 Information Theory and Applications Workshop (ITA-07), San Diego, CA, USA, 29 January–2 February 2007; IEEE Press: Piscataway, NJ, USA, 2007; pp. 337–341, (Invited Paper). [Google Scholar]
- Rissanen, J. Optimal Estimation. Inf. Theory Newsl. 2009, 59, 1–20. [Google Scholar]
- Mera, B.; Mateus, P.; Carvalho, A.M. On the minmax regret for statistical manifolds: The role of curvature. arXiv 2020, arXiv:2007.02904. [Google Scholar]
- de Rooij, S.; Grünwald, P. An empirical study of minimum description length model selection with infinite parametric complexity. J. Math. Psychol. 2006, 50, 180–192. [Google Scholar] [CrossRef] [Green Version]
- Roos, T.; Rissanen, J. On sequentially normalized maximum likelihood models. In Proceedings of the 1st Workshop on Information Theoretic Methods in Science and Engineering (WITMSE-08), Tampere, Finland, 18–20 August 2008. (Invited Paper). [Google Scholar]
- Baxter, R.A.; Oliver, J. MDL and MML: Similarities and Differences; Technical Report TR 207; Department of Computer Science, Monash University: Clayton, Australia, 1994. [Google Scholar]



{kind=link}
{kind=link}
| Data | Class | Attributes | ||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
| Crime | 1 | (50%, 50%) | (73%, 27%) | ( 3%, 97%) | (42%, 58%) | (r: 2.0, p: 0.4) | (: 20.7, : 2.1) | (: 119.0) |
| 2 | (55%, 45%) | (15%, 85%) | (23%, 77%) | (28%, 72%) | (r: 13.4, p: 0.8) | (: 24.9, : 3.3) | (: 249.3) | |
| 3 | (40%, 60%) | (16%, 84%) | (18%, 82%) | (51%, 49%) | (r: 2.3, p: 0.5) | (: 36.3, : 4.9) | (: 345.9) | |
| Melanoma | 1 | (43%, 57%) | (17%, 83%) | (: 57.3, : 17.1) | (: 5.4, : 3.4) | (: 12.0, : 7.3) | – | – |
| 2 | (73%, 27%) | (80%, 20%) | (: 49.5, : 15.8) | (: 1.4, : 0.9) | (: 8.1, : 37.0) | – | – | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Makalic, E.; Schmidt, D.F. Minimum Message Length Inference of the Exponential Distribution with Type I Censoring. Entropy 2021, 23, 1439. https://doi.org/10.3390/e23111439
Makalic E, Schmidt DF. Minimum Message Length Inference of the Exponential Distribution with Type I Censoring. Entropy. 2021; 23(11):1439. https://doi.org/10.3390/e23111439
Chicago/Turabian StyleMakalic, Enes, and Daniel Francis Schmidt. 2021. "Minimum Message Length Inference of the Exponential Distribution with Type I Censoring" Entropy 23, no. 11: 1439. https://doi.org/10.3390/e23111439