1. Introduction
The free energy principle (FEP) has emerged from neuroscience as a unifying theory of the brain [
1] and has begun to guide the search for a brain-inspired learning algorithm for robots. Many attempts have been made in this direction, including the state and input observer [
2,
3], the adaptive controller for robot manipulators [
4,
5,
6], the body perception and action scheme for humanoid robots [
7], the robot navigation of ground robots [
8] etc. However, the design of a parameter estimation algorithm for linear systems with colored noise remains unexplored. Since the design of an accurate parameter estimator for dynamic systems sits at the core of control systems and robotics, the reformulation of FEP into a brain-inspired estimation algorithm has an influential impact on the industry and applied robotics.
A wide range of estimators have been proposed in the literature for linear time-invariant (LTI) systems [
9], including the blind system identification [
10,
11,
12]. However, most of them assume the noises to be temporally uncorrelated (white noise), which is often violated in practice. This results in biased estimation for the least-square (LS)-based methods [
13], and an inaccurate convergence for the iterative methods [
14]. Although many attempts have been made to solve this problem, mainly through bias compensation methods [
15,
16], none of them perform state, input, parameter, and noise estimation for systems with colored noises [
17]. The only method that does it is the Dynamic Expectation Maximization (DEM) [
18] algorithm, which uses FEP to invert a highly nonlinear and hierarchical brain model from sensory data. However, the disconnect between neuroscience and control system literature hinders the wide use of this method for practical robotics applications. Although FEP-based tools have already been applied to practical robotics applications [
2,
3,
4,
5,
6,
7,
8,
19,
20], there is a gap in the literature on the applications of DEM owing to the mathematical formidability of the theory and its lack of formalism in the control systems domain. Therefore, it is important to reformulate DEM for the control systems audience. While DEM from computational neuroscience focuses on emulating the brain’s perception through the hierarchical abstraction of a number of interacting non-linear dynamic systems, our work focuses on reformulating it into a blind system-identification algorithm for an LTI system with colored noise, which is a well-known challenge in robotics. In this attempt, we keep all the brain-related approximations intact, thereby aiming for a biologically plausible parameter estimation algorithm.
According to an FEP proposed by Karl Friston, the brain’s inference mechanism is a gradient ascent over its free energy, where free energy is the information-theoretic measure that bounds the brain’s sensory surprisal [
21]. FEP emerges as a unified brain theory [
22] by providing a mathematical description of brain functions [
23]; unifying action and perception [
24]; connecting physiological constructs like memory, attention, value, reinforcement, and salience [
23]; and remaining consistent with Freudian ideas [
25]. Similarities of FEP with reinforcement learning [
26], neural networks [
21,
27], PID controller [
28], Kalman Filter [
2] and active learning [
24] open up possibilities for biologically plausible parameter estimation algorithms. Although FEP emerged as a brain theory, the recent works have pushed the boundaries towards systems that survive over time, such as social and cultural dynamics. Notable works include the variational approach to culture [
29], collective intelligence [
30], cumulative cultural evolution [
31], etc.
Numerous methods have been proposed based on the FEP framework. Predictive coding [
32] models perception through a hierarchy of dynamical systems [
27] with the brain’s priors at the top, minimizing the prediction error at each level of the hierarchy. Bayesian message passing algorithms [
33,
34] use similar ideas for belief propagation. Active inference [
24,
35] uses FEP to model the brain’s action and perception under one framework. On the perception side, there are two main type of methods to deal with dynamic systems: variational filtering and generalized filtering. Variational filtering [
18,
36] uses mean-field approximation (conditional independence between densities), whereas generalized filtering [
37] does not. DEM [
18] is a type of variational filtering that uses a Laplace approximation [
38] (a fixed-form assumption for the conditional density of variables), whereas [
36] uses ensemble dynamics to model the free form of the conditional densities. We focus on DEM for this work.
DEM is an FEP-based variational inference algorithm that models the brain’s inference process as a maximization of its free energy for state, input, parameter, and noise estimation from data. Although the method shows high similarity to the variational inference [
39], the key difference is in the use of generalized coordinates, which enables DEM to track the evolution of the trajectory of states instead of just the point estimates. This renders DEM with the capability of gracefully handling colored noises, a feature that conventional point estimators such as the Kalman Filter (KF) lacks. The modeling of noise color as analytic using generalized coordinates results in an improved state estimation under colored noise for LTI systems [
2,
3] and for nonlinear filtering [
40], which directly improves the parameter estimation accuracy, making DEM a topic of interest [
20]. This work directly impacts various sub-domains of robotics community: input estimation to the industrial automation community for fault detection systems, state estimation to the control systems community, parameter estimation to the system identification community, and hyperparameter estimation to the signal processing community.
With this paper, we aim to present DEM to the robotics audience as a robot learning algorithm for the blind system identification of LTI systems with colored noise. We elaborate on various components of DEM that are most relevant to the robotics community: (1) the derivation of the free energy objectives from Bayesian principles, (2) the modeling of colored noise using generalized coordinates, and (3) the simplification of update rules for LTI systems with colored noise. We reformulate DEM for LTI systems into a form that is widely used in the robotics domain and use this mathematical formulations to prove that the estimation steps of DEM have theoretical guarantees of convergence [
41]. In our prior work, we have discussed the stability conditions of our DEM-based linear state and input observer design [
2]. This convergence guarantees and stability criteria are essential for robot safety while in operation and is of high relevance to the robotics community. Through extensive simulations on a range of random systems, we show that DEM is a competitive estimator when compared to other benchmarks in the control systems domain. The core contributions of the paper are:
Reformulating DEM into an estimation algorithm for LTI systems with colored noise (
Section 12).
Proving that the estimator has theoretical guarantees of convergence for the estimation steps (
Section 14).
Proving through rigorous simulation that DEM outperforms the state-of-the-art system identification methods for parameter estimation under colored noise (
Section 16).
4. Free Energy Objectives
With the preliminaries in place, we can build up towards the complete DEM algorithm. Eventually, in
Section 8 and
Section 12, we will see that it is an optimization algorithm that finds the best estimates for states, inputs, parameters, and hyperparameters for given measurement data. This result is achieved by optimizing two objective functions, which are the core objectives under the entire Free Energy Principle: the free energy and the free action [
1]. Here we derive and simplify this objective.
The derivation starts from the fundamentals of Variational Inference (VI) [
39]. In VI, the posterior distribution
of parameter
, given the measurement
y, is expressed as:
However, the marginalization over
to calculate
is often intractable because the search space of
is large. A widely used technique is to introduce a variational distribution
known as the recognition density, which acts as an approximate representation of the posterior distribution with
. A common method used among variational Bayes algorithms is to minimize the Kullback–Leibler (KL) divergence between both the distributions, defined as:
where
represents the expectation over
. Substituting Equation (
10) in Equation (
11) and using
yields:
The rearrangement of terms yield:
where
is the log-evidence,
is the internal energy and
is the entropy of the density. The free energy term in Equation (
13) is defined as the sum of an energy term and its entropy. It acts as the lower bound on the log-evidence because the KL divergence term
is always positive. The maximization of free energy minimizes the divergence term in Equation (
13) because the log-evidence is independent of
, thereby rendering the variational density
as a close approximation of
. Therefore, the difficult evaluation of an intractable integral term in Equation (
10) is converted into a much simpler optimization problem of maximizing the free energy. This reduces the problem of inference to a direct optimization of its free energy objectives and is the fundamental idea behind variation inference. The free energy term in Equation (
13) is equivalent to the Evidence Lower Bound (ELBO) [
39]. It can be simplified as:
However, when the parameter set to be estimated includes both the time-variant and the time-invariant parameters, the free action is used as the objective function to be maximized. The free action is defined as the time integral of the free energy and is given by:
where
is called the variational free energy (VFE).
The next sections will deal with two main assumptions used in DEM to simplify the free energy objectives, namely the Laplace approximation and the mean-field assumption. The aim is to derive the simplified free energy objectives for an LTI system under these assumptions.
5. Laplace Approximation
The first common approach to simplify the free energy objective is to assume the variational density
to be Gaussian in nature with variational parameters
and
as its mode and covariance, respectively, [
38]. Here, the inverse of
(denoted by
and known as the conditional precision), represents the confidence in estimation. The recognition density takes the following form:
There are two main advantages with this approximation:
Therefore, the main aim of this section is to simplify the expression for internal energy using the Laplace approximation, for an LTI system with its states, inputs, and outputs expressed in generalized coordinates.
The internal energy in Equation (
13) can be expressed as the sum of log-likelihood and prior terms as:
The parameter set
includes two types of parameters:
the states and inputs, which are time-varying and therefore expressed in generalized coordinates,
the parameters and hyperparameters, which are time-invariant and not expressed in generalized coordinates.
Equation (
17) can be simplified by assuming the conditional independence of
and
with
and
. This factorization separates the deterministic quantities from the stochastic ones, thereby providing a separation of temporal scales. This is one of the core ideas behind DEM, which will be detailed in
Section 6. With the redefinition of
, Equation (
17) simplifies to:
DEM combines the new sensory information
y coming from the environment with the robot brain’s priors (refer to
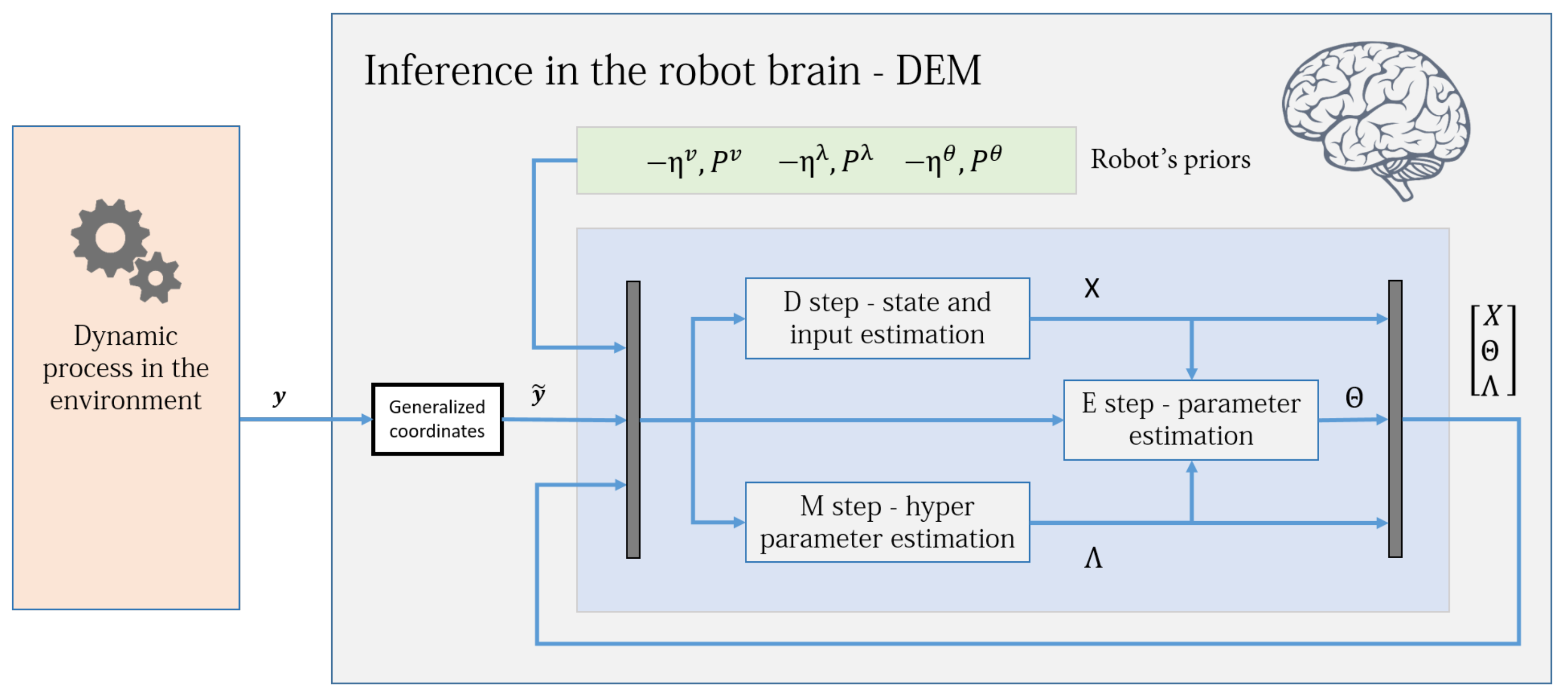
Figure 1) in a Bayesian fashion, through the internal energy
expression given in Equation (
18). The next sections will deal with simplifying
and its action
by first modeling the probability distributions for the generative model and the priors.
5.1. Generative Model
The probability distribution
, given in Equation (
18), represents the generative model that predicts the output from the current parameter estimates. This probability can be assumed to be Gaussian-distributed, centered around the model’s output prediction
(from Equation (
3)), with the same uncertainty as that of the measurement noise
. The distribution
becomes:
Since the robot cannot directly measure
in Equation (
3), we track the motion of the generalized states through the approximation
. The prediction for motion is
with an uncertainty of
. The Gaussian distribution becomes:
5.2. Prior Distributions
The remaining distributions
and
are the priors of the robot brain that can be transferred from prior (learned) experiences to the inference process. Similar to the previous section, a Gaussian prior is placed over the inputs
as well, with mean
and prior covariance
, as:
The prior distribution of parameters
is assumed to be a Gaussian-centred around the prior parameter value
, with the prior covariance
:
Similarly, a Gaussian prior is placed over the hyperparameters
:
A higher value of
and
represents the robot’s higher confidence in its prior estimates
,
, and
, respectively.
5.3. Simplification of the Internal Energy Action
This section aims at using the distributions from the previous sections to simplify
. The logarithm of a Gaussian prior after dropping constants takes the general form:
Therefore, substituting Equations (
19)–(
23) in Equation (
18) and simplifying it using the prediction error terms
and
, after dropping constants, yields:
where
, and
. Here
is the block diagonal operator. Grouping the internal energy terms of the temporal and nontemporal parameters yields:
where
Summing up the internal energy of all the temporal parameters over time yields the action of internal energy as follows:
It can be observed from Equation (
28) that the robot’s priors
enter the free energy objective through the internal energy term. Intuitively, this can be seen as the direct influence of the robot’s prior beliefs on the inference process through the mismatches in the robot’s predictions. These weighed prediction errors drive the robot’s desire to maintain an equilibrium between its internal model and the generative process in the environment. A large mismatch between the robot’s predictions and the data results in a large prediction error, which gets precision-weighted and enters the free energy objective through its internal energy.
8. Update Rules for Estimation
The Free Energy objectives (
Section 4), together with the two simplifying approximations (
Section 5 and
Section 6), will be combined with an optimization procedure to form the ultimate DEM algorithm. The optimization procedure itself consists of the following two sets of update rules:
a gradient ascent over its free action for the time invariant parameters and ,
a gradient ascent over its free energy F for the time varying parameters X,
where
F and
are related through
. The core idea is that the time varying parameters
and
can be estimated online from the robot’s instantaneous free energy, whereas the time-invariant parameters
and
can be estimated from its free action after observing a sequence of data. Accordingly, the update rules for both the gradient ascends are given by
for the
parameter update of the time invariant parameters and
for the time=varying parameters, where
is the learning rate. The presence of
term in Equation (
46) differentiates the update rule from the general gradient ascent equation used in machine learning. This is to accommodate the boundary condition that when
F is maximized,
and
. In other words, when the free energy is maximized, the motion of the generalized states becomes their generalized motion [
44]. However, the update equations for the time-invariant parameters,
and
, do not require the
term. Therefore, the update equations at
time,
parameter update step, and
hyperparameter update step, after regrouping the (generalized) states and inputs as
, is given by:
where
. Note that the gradient update rules are written not on the latent variables (
and
), but on their mean estimates (
and
). Since the update rules should be implemented in the discrete domain for robotics applications, Equation (
47) is discretized under local linearization with the corresponding Jacobians as
, and
. The (generalized) state and input update at time
t, parameter update at step
a and hyperparameter update at step
b are given by:
Equation (
48) shows that the update rules are dependent only on the gradients and curvatures of the free energy objectives.
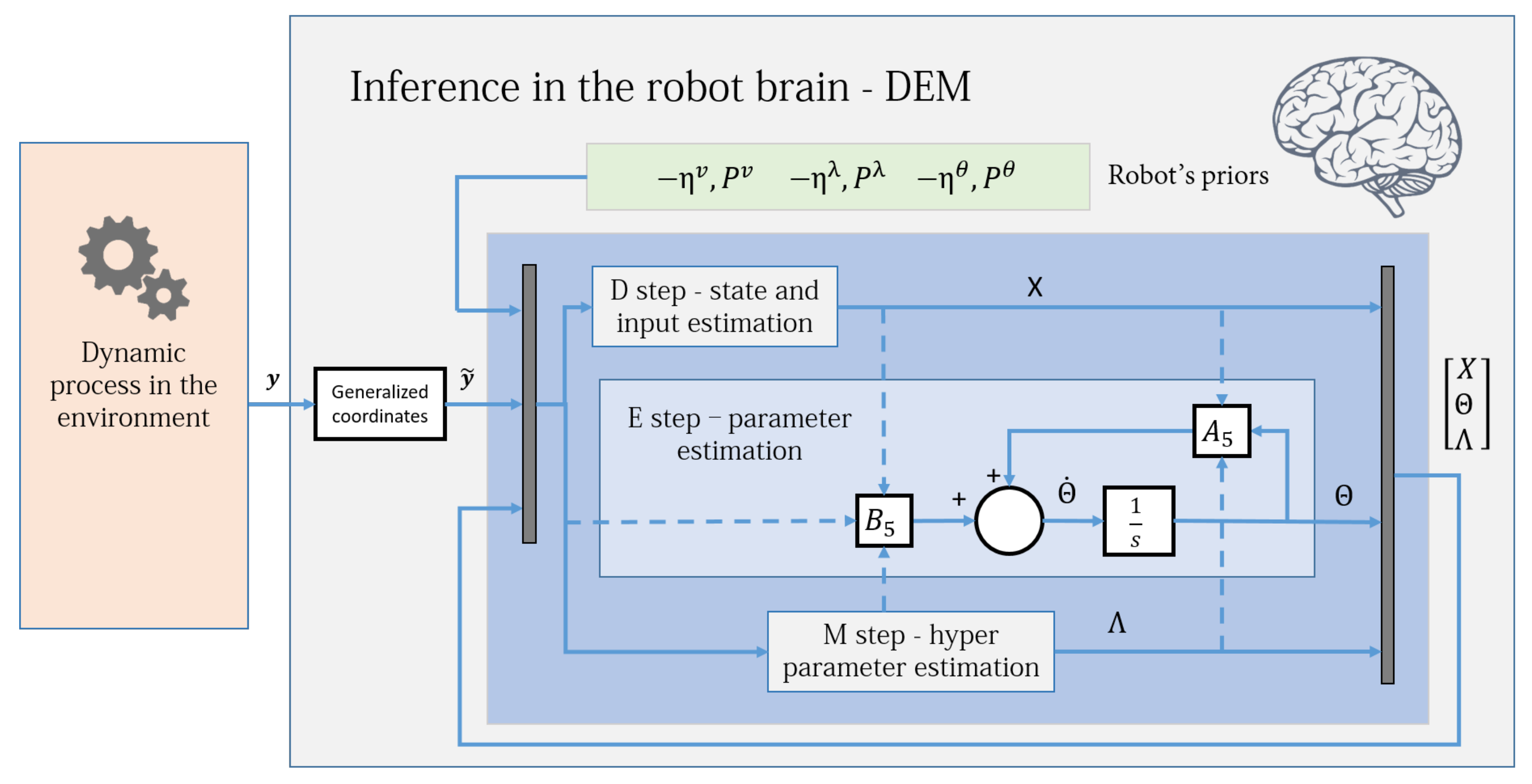
8.1. The DEM Algorithm
The DEM algorithm is an iterative model inversion algorithm that uses Equations (
42) and (
48) to perform estimation on causal dynamic systems. It can be expressed using three steps:
D step: (generalized) state and input estimation,
E step: parameter estimation,
M step: noise hyperparameter estimation,
a nomenclature that is similar to the EM algorithm.
Figure 2 shows an intuitive block diagram that demonstrates the inference process of DEM as a coupled dynamics between D, E, and M steps. The data from the environment and the robot brain’s prior distributions are used to infer the generative process. The pseudocode given in Algorithm 1 demonstrates how DEM performs estimation using only the gradient and curvatures of the free energy objectives. The next sections will focus on deriving the algebraic expressions for these quantities.
8.2. Updated Equations for Estimation
The free energy gradients in Equation (
47) can be evaluated by differentiating Equation (
40) with
. Substituting the resulting expression in Equation (
47), upon simplification yields:
where
is the gradient of the prediction error with respect to
,
is the gradient of the mean field term of
with respect to
, and
is the gradient of the log-determinant of the precision matrix with respect to
. From Equation (
49), the Jacobians that are required for the updates given in Equation (
48) can be evaluated as:
The Jacobians are employed in different loops corresponding to the D, E, and M steps in the Algorithm 1.
| Algorithm 1: Dynamics Expectation Maximization |
![Entropy 23 01306 i001]() |
8.3. Update Equation for Precision of Estimates
The uncertainty in estimation is represented by the inverse of precision matrices
. Differentiating Equations (
25) and (
28) twice and substituting it into Equation (
42) upon simplification yield:
The only unknowns in the DEM update equations given by Equations (
49)–(
51) are the gradients and curvatures of
E,
W, and
G.
Section 9,
Section 10 and
Section 11 will deal with evaluating the simplified algebraic expressions for these gradients and curvatures. Using these simplifications,
Section 12 will proceed towards expanding Algorithm 1.
9. Gradients of (Log Determinant of) Precision
This section aims at evaluating the gradients of the log determinant of noise precision (
) that are required for the hyperparameter update rules of the DEM algorithm. The precision matrix for hyperparameter estimation is modeled as:
where
S is the noise smoothness matrix given by Equation (
7) and
are the constant matrices given in Equation (
6). Here the precision matrix is parametrized using
, which is the only unknown in Equation (
52). Therefore, the log determinant of precision and its gradients can be written as:
where
is the
element in
. The gradients of precision in Equation (
53) can be evaluated by differentiating Equation (
52) as:
Substituting Equations (
52) and (
54) in Equation (
53) yields:
where
is the identity matrix of size
, which is the size of the
matrix.
and
are modeled to have an exponential relation with
, so that any updates on
would result in positive semi-definite precision matrices. However, this relation entails an infinitely differentiable precision matrix with respect to
, increasing the computational complexity of the algorithm. Therefore, an approximation is made by forcefully setting
, while maintaining the exponential relation between
and
, thereby ensuring that the optimization process proceeds along the correct gradients
. Together with Equation (
54), this approximation results in
. This assumption has two direct consequences:
It simplifies all the update rules given in Equations (
49) and (
50),
It simplifies the precision update rule for hyperparameters given in Equation (
51).
A direct consequence of this approximation is in the simplification of
in Equation (
53), expressed as:
which upon substitution of Equations (
52) and (
54) yields:
where
and
are the sizes of
and
, respectively. From Equations (
55) and (
57),
and
are constants, and can be pre-computed in Algorithm 1.
14. Convergence Proof for Parameter and Hyperparameter Estimation
In robotics, it is important that learning algorithms provide a stable solution, especially when robot safety during operation is a concern. Therefore, a proof of convergence for DEM is important for its widespread use in robotics as a learning algorithm. However, the DEM literature lacks any such mathematical proof of convergence for the estimator. Therefore, this section aims at providing one for the parameter and hyperparameter estimation step on LTI systems.
Since the update equation given by Equation (
95) is a linear differential equation, proving that
is sufficient to prove that
converges to a stable solution. Substituting the expression for
from Equation (
62) to the
in Equation (
95), yields:
Since the prior precision matrix can be chosen to be positive definite,
. It is straightforward to note from the expression for
in Equation (
62) that
, because
,
, and
. Therefore, the proof of convergence is complete if we prove that
. Simplifying the expressions for
and
from Equations (
92) and (
93), after some nontrivial linear algebra [
41], yields:
where
It is straightforward from Equation (
98) that
because
, and
. Combining all the results from this section,
,
and
. This completes the proof that the parameter estimation step of DEM converges for an LTI system. Similarly, from Equation (
81),
proves the convergence of hyperparameter estimation step. For a detailed account of the linear algebra behind the proof of convergence, readers may refer to [
41].
16. Benchmarking
This section deals with benchmarking DEM against the state-of-the-art parameter estimation methods such as Expectation Maximization (EM), Subspace method (SS), and Prediction Error Minimization (PEM), for black-box estimation (fully unknown x, and ).
16.1. Evaluation Metric for Parameter Estimation
For the black box identification, with completely unknown x, , and , there are infinite solutions with accurate input–output mapping. However, for LTI systems, there exists a unique transformation for identical systems. We use the companion canonical form to check the validity of parameter estimation by transforming both the real and the estimated parameters into their companion canonical form and then using the (square of) Euclidean distance between them as the sum of squared error (SSE) in parameter estimation. This evaluation metric will be used for parameter estimation in the next section.
16.2. Simulation Setup
A total of 500 (5 × 100) different randomly generated stable systems were used with five different noise smoothness values for parameter estimation. All systems were selected with same number of parameters ( and ), with each , while ensuring that A matrix is stable. All the noises were generated with the precision of , with the embedding orders of states and inputs as and . A Gaussian bump of was used as the input signal with and . The prior parameter was randomly initialized such that all with a tight prior precision of . Both the hyperparameter priors were set to zero, with a prior precision of .
The System Identification toolbox from MATLAB was used for SS (
) and PEM methods. The solution of SS was used to initialize PEM. An implementation of EM algorithm for state space models was written in MATLAB based on [
45].
is inherently designed to handle colored noise, whereas the implemented EM algorithm is not. The code for the DEM algorithm will be openly available at:
https://github.com/ajitham123/DEM_LTI.
16.3. Results
The results shown in
Figure 7 demonstrate the superior performance of DEM in comparison with EM, PEM, and SS, with minimum SSE during parameter estimation across different noise smoothness. Additionally, EM and PEM exploded occasionally (
times), resulting in outliers in SSE, which were removed for better visualization. DEM demonstrated a consistent performance without generating any such outliers or exploding solutions, which could be explained by DEM’s convergence guarantees for parameter estimation under colored noise [
41], as proved in
Section 14. In summary, DEM is a competitive parameter estimator for LTI systems with colored noise.
17. Discussion
The quest for a brain-inspired learning algorithm for robots has culminated in the free energy principle that postulates biological brain’s perception as an optimization over its free energy objectives. FEP is of prime importance to robotics because of the use of generalized coordinates that enables it to gracefully handle colored noises. Colored noises appear in real robotics systems through the unmodeled dynamics and the non-linearity errors in the model, thereby providing an advantage for DEM during estimation when compared to other estimators. An example could be the unmodeled wind disturbances acting on an unmanned aerial vehicle while in flight, or the non linearity errors in the dynamic model of a robotic manipulator arm involved in a pick and place operation. The scope of this work spans across the blind system identification of such linear dynamic systems with colored noise.
The fundamental difference between this work and the prior work is in the reformulation of DEM for an LTI system. While DEM from computational neuroscience focuses on emulating the biological brain’s perception through the hierarchical abstraction of a number of non-linear dynamic systems that interact with each other, our work focuses on reducing this method into an algorithm for the system identification of an LTI system with colored noise, which is a well-known problem in robotics. This reformulation enables the standard analysis for convergence, stability and unbiased estimation, which is an essential analysis in practical robotics. It also enables DEM to be compared with other existing estimation algorithms in a control systems domain. The widespread use of DEM in robotics necessitates these mathematical analyses, especially when concerning the stable and safe operation of robots in industry and during human–robot interaction.
An algorithm with proved convergence for estimation is preferred for safe robotic applications. Therefore, one of the main contribution of this work was the reduction of the estimation algorithm into a coupled augmented system to prove the convergence of parameter and hyperparameter estimation steps. This work also demonstrated the successful applicability of DEM for the estimation of a randomly selected LTI system. Furthermore, we showed through rigorous simulations on a wide range of randomly generated LTI systems that DEM is a competitive algorithm for system identification under colored noise, thereby widening the scope of DEM to a large number of LTI systems in robotics.
One of the main drawbacks of the algorithm is its higher computational complexity when compared to the estimation algorithms that do not keep track of the trajectory of states. Therefore, future work can focus on the online estimation using DEM with reduced computational load. Future work can also focus on extending this algorithm for linear time varying systems to deal with robots with changing system parameters while in operation—a delivery drone dropping deliveries in mid-flight, for example. From a practical robotics point of view, DEM’s parameter estimation module can be directly applied to a wide range of robots such as quadrotors, robotic arms, wheeled robots, etc. for black-box system identification, the input estimation module can be employed for fault-detection systems, and the hyperparameter estimation module can be used for online noise estimation for robust control. DEM can also be extended with a control loop for active inference to perform simultaneous perception and action on robots. This would result in the development of cognitive robots that can learn the generative model in the environment by interacting with it and actively seeking new information (active learning) for uncertainty resolution. This would influence multiple domains in robotics such as human–robot interaction for task learning, swarm robotics for collective learning and distributed control, informative path planning of aerial robots for environment monitoring, etc. The development of such brain-inspired autonomous agents sits at the core of cognitive robotics research. In summary, DEM has a huge potential to be the bioinspired learning algorithm for future robots.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}