Improvement of Statistical Performance of Ordinal Multiscale Entropy Techniques Using Refined Composite Downsampling Permutation Entropy


{kind=link}
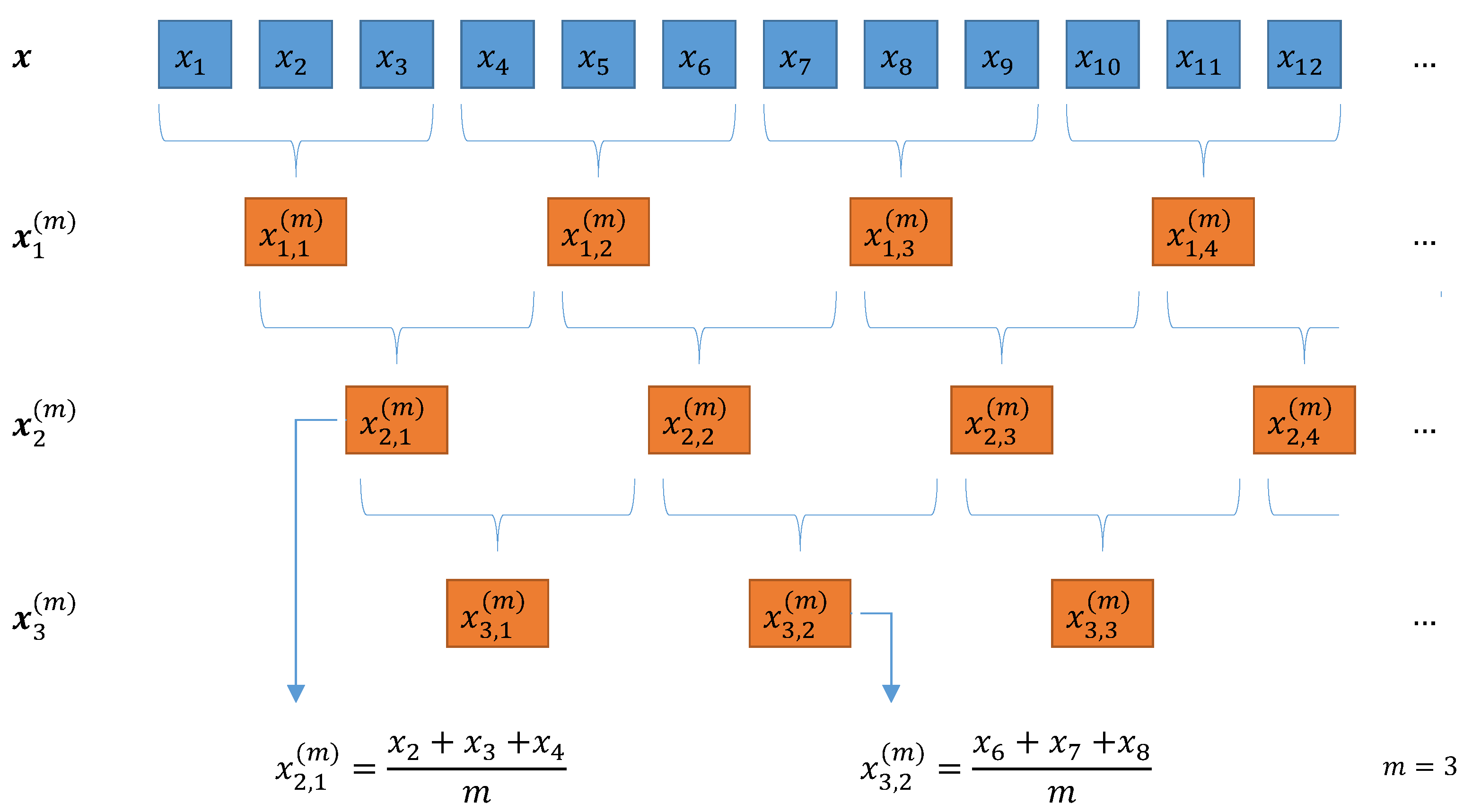{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Theoretical Framework
2.1. Permutation Entropy
2.2. Multiscale Permutation Entropy
2.3. MPE Statistics
2.4. Composite MPE Methods
2.4.1. Composite MPE
2.4.2. Refined Composite MPE
3. Methods
3.1. cMPE and rcMPE Statistics
3.1.1. cMPE Moments
3.1.2. rcMPE Moments
3.1.3. Composite MPE Statistics—Discussion
3.2. Composite Downsampling
3.2.1. Composite Downsampling PE
3.2.2. Refined Composite Downsampling PE
4. Results and Discussion
4.1. Uncorrelated Signals
4.2. Applications on Fault Bearing
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| PE | Permutation Entropy |
| MSE | Multiscale Entropy |
| MPE | Multiscale Permutation Entropy |
| cMPE | Composite Multiscale Permutation Entropy |
| rcMPE | Refined Composite Multiscale Permutation Entropy |
| cDPE | Composite Downsampling Permutation Entropy |
| rcDPE | Refined Composite Downsampling Permutation Entropy |
References
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Liang, Y.; Zhou, J.; Zang, Y. A novel bearing fault diagnosis model integrated permutation entropy, ensemble empirical mode decomposition and optimized SVM. Measurement 2015, 69, 164–179. [Google Scholar] [CrossRef]
- Yin, Y.; Shang, P. Weighted multiscale permutation entropy of financial time series. Nonlinear Dyn. 2014, 78, 2921–2939. [Google Scholar] [CrossRef]
- Chen, W.; Wang, Z.; Xie, H.; Yu, W. Characterization of Surface EMG Signal Based on Fuzzy Entropy. IEEE Trans. Neural Syst. Rehabil. Eng. 2007, 15, 266–272. [Google Scholar] [CrossRef] [PubMed]
- Bandt, C.; Pompe, B. Permutation Entropy: A Natural Complexity Measure for Time Series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef] [PubMed]
- Costa, M.; Goldberg, A.L.; Peng, C.K. Multiscale entropy analysis of biological signals. Phys. Rev. E 2005, 71, 021906. [Google Scholar] [CrossRef] [Green Version]
- Aziz, W.; Arif, M. Multiscale Permutation Entropy of Physiological Time Series. In Proceedings of the 2005 Pakistan Section Multitopic Conference, Karachi, Pakistan, 24–25 December 2005; pp. 1–6. [Google Scholar] [CrossRef]
- Azami, H.; Escudero, J. Improved multiscale permutation entropy for biomedical signal analysis: Interpretation and application to electroencephalogram recordings. Biomed. Signal Process. Control. 2016, 23, 28–41. [Google Scholar] [CrossRef] [Green Version]
- Humeau-Heurtier, A.; Wu, C.W.; Wu, S.D. Refined Composite Multiscale Permutation Entropy to Overcome Multiscale Permutation Entropy Length Dependence. IEEE Signal Process. Lett. 2015, 22, 2364–2367. [Google Scholar] [CrossRef]
- Wu, S.D.; Wu, C.W.; Lin, S.G.; Lee, K.Y.; Peng, C.K. Analysis of complex time series using refined composite multiscale entropy. Phys. Lett. A 2014, 378, 1369–1374. [Google Scholar] [CrossRef]
- Dávalos, A.; Jabloun, M.; Ravier, P.; Buttelli, O. Theoretical Study of Multiscale Permutation Entropy on Finite-Length Fractional Gaussian Noise. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1092–1096. [Google Scholar]
- Dávalos, A.; Jabloun, M.; Ravier, P.; Buttelli, O. On the Statistical Properties of Multiscale Permutation Entropy: Characterization of the Estimator’s Variance. Entropy 2019, 21, 450. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Humeau-Heurtier, A. The Multiscale Entropy Algorithm and Its Variants: A Review. Entropy 2015, 17, 3110–3123. [Google Scholar] [CrossRef] [Green Version]
- Bechhoefer, E. Fault Data Sets. Available online: https://www.mfpt.org/fault-data-sets/ (accessed on 28 December 2013).
- Zunino, L.; Olivares, F.; Scholkmann, F.; Rosso, O.A. Permutation entropy based time series analysis: Equalities in the input signal can lead to false conclusions. Phys. Lett. A 2017, 381, 1883–1892. [Google Scholar] [CrossRef] [Green Version]
- Matilla-García, M. A non-parametric test for independence based on symbolic dynamics. J. Econ. Dyn. Control. 2007, 31, 3889–3903. [Google Scholar] [CrossRef]
- Amigó, J.M.; Zambrano, S.; Sanjuán, M.A.F. True and false forbidden patterns in deterministic and random dynamics. EPL (Europhys. Lett.) 2007, 79, 50001. [Google Scholar] [CrossRef]
- Wu, S.D.; Wu, C.W.; Lee, K.Y.; Lin, S.G. Modified multiscale entropy for short-term time series analysis. Phys. Stat. Mech. Its Appl. 2013, 392, 5865–5873. [Google Scholar] [CrossRef]
- Carlton, A. On the Bias of Information Estimates. Psychol. Bull. 1969, 71, 108–109. [Google Scholar] [CrossRef]
- He, S.; Sun, K.; Wang, H. Modified multiscale permutation entropy algorithm and its application for multiscroll chaotic systems. Complexity 2016, 21, 52–58. [Google Scholar] [CrossRef]
- Berger, S.; Kravtsiv, A.; Schneider, G.; Jordan, D. Teaching Ordinal Patterns to a Computer: Efficient Encoding Algorithms Based on the Lehmer Code. Entropy 2019, 21, 1023. [Google Scholar] [CrossRef] [Green Version]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dávalos, A.; Jabloun, M.; Ravier, P.; Buttelli, O. Improvement of Statistical Performance of Ordinal Multiscale Entropy Techniques Using Refined Composite Downsampling Permutation Entropy. Entropy 2021, 23, 30. https://doi.org/10.3390/e23010030
Dávalos A, Jabloun M, Ravier P, Buttelli O. Improvement of Statistical Performance of Ordinal Multiscale Entropy Techniques Using Refined Composite Downsampling Permutation Entropy. Entropy. 2021; 23(1):30. https://doi.org/10.3390/e23010030
Chicago/Turabian StyleDávalos, Antonio, Meryem Jabloun, Philippe Ravier, and Olivier Buttelli. 2021. "Improvement of Statistical Performance of Ordinal Multiscale Entropy Techniques Using Refined Composite Downsampling Permutation Entropy" Entropy 23, no. 1: 30. https://doi.org/10.3390/e23010030