Inference for Convolutionally Observed Diffusion Processes


1
Graduate School of Engineering Science, Osaka University, 1-3 Machikaneyamacho, Toyonaka, Osaka 560-0043, Japan
2
Japanese Society for the Promotion of Science, 5 Chome-3-1 Kōjimachi, Chiyoda City, Tokyo 102-0083, Japan
3
The Ronin Institute for Independent Scholarship, 127 Haddon Place, Montclair, Montclair, NJ 07043, USA
4
Center for Mathematical Modeling and Data Science, Osaka University, 1-3 Machikaneyamacho, Toyonaka, Osaka 560-0043, Japan
*
Author to whom correspondence should be addressed.
Entropy 2020, 22(9), 1031; https://doi.org/10.3390/e22091031
Submission received: 21 August 2020
/
Revised: 10 September 2020
/
Accepted: 11 September 2020
/
Published: 15 September 2020
(This article belongs to the Special Issue Machine Learning Meets Stochastic Processes: New Trends for Understanding Complex Systems)
Abstract
:We propose a new statistical observation scheme of diffusion processes named convolutional observation, where it is possible to deal with smoother observation than ordinary diffusion processes by considering convolution of diffusion processes and some kernel functions with respect to time parameter. We discuss the estimation and test theories for the parameter determining the smoothness of the observation, as well as the least-square-type estimation for the parameters in the diffusion coefficient and the drift one of the latent diffusion process. In addition to the theoretical discussion, we also examine the performance of the estimation and the test with computational simulation, and show an example of real data analysis for one EEG data whose observation can be regarded as smoother one than ordinary diffusion processes with statistical significance.
1. Introduction
We consider a d-dimensional diffusion process defined by the following stochastic differential equation,
where , is a standard r-dimensional Wiener process, is an -valued random variable independent of , and are unknown parameters, and are compact and convex parameter spaces, and are known functions. Our concern is statistical estimation for and from observation. denotes the true value of .
We denote the observation as the discretised process with discretisation step such that and , where the convoluted process is defined as
where is an -valued kernel function whose support is a subset of , and such that . In this paper, we specify which is a parametric kernel function whose support is a subset of defined as
is the Dirac-delta function, is the smoothing parameter determining the smoothness of observation. That is to say, the observed process is defined as follows:
for all . Let us consider both the problems that (i) is a known parameter, and (ii) is an unknown one whose true value is denoted by and this is estimated by observation , and the parameter space is denoted as , where .
When assuming as a known parameter, we can find literature for parametric estimation for and/or based on observation schemes which can be represented as special cases for some specific . If , our scheme is simply equivalent to parametric inference based on discretely observed diffusion processes studied in [1,2,3,4,5,6,7,8] and references therein. If , we can regard the problem as parametric estimation for integrated diffusion processes discussed in Gloter [9], Ditlevsen and Sørensen [10], Gloter [11], Gloter and Gobet [12], Sørensen [13]. Even for the case where some axes correspond to direct observation and the others do to integrated observation, we give consistent estimators for and by considering the scheme of convolutionally observed diffusion processes and this is one of the contributions of our study.
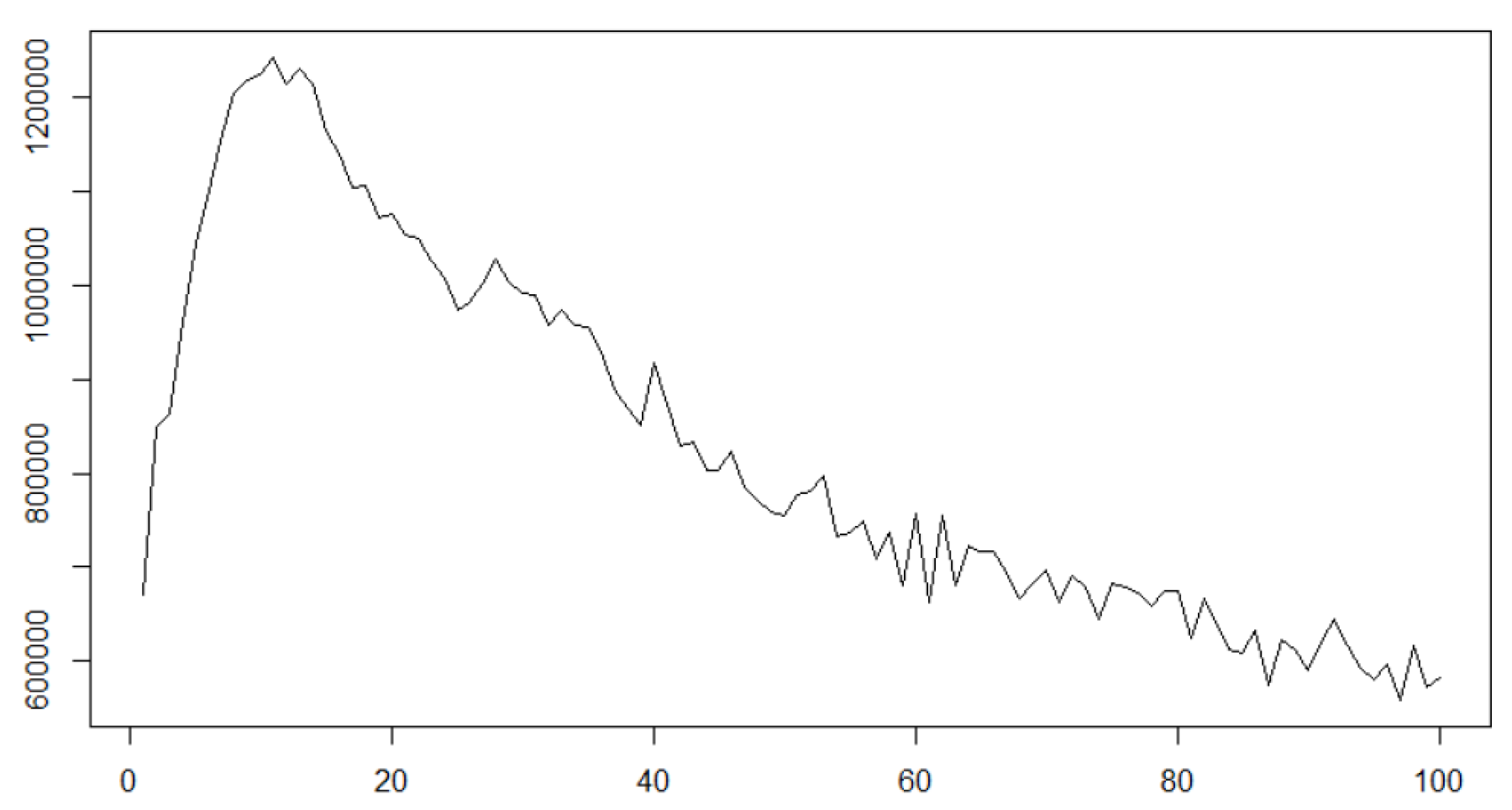
What is more, our contribution is to consider the scheme where is unknown and succeed in representation of the microstructure noise which makes the observation smoother than the latent diffusion process itself, which can be seen in some biomedical time series data. Statistical modelling of biomedical time series data with stochastic differential equations has been one of the topics eagerly studied e.g., [14,15,16,17]. As [18] states, the existence of microstructure noise in financial data affects realised volatilities to increase as the subsampling frequency gets higher, for instance, see Figure 7.1 on p. 217 in [19]. However, realised volatilities of some biomedical data such as EEG decrease as subsampling frequency increases. For instance, some time series data for the 2nd participant in the dataset named Two class motor imagery (002-2014) of BNCI Horizon 2020 [20] show clear tendency of decreasing realised volatilities as subsampling frequency increases. Figure 1 shows the path of the 2nd axis of the data S02E.mat BNCI Horizon 2020 [20] for all 222 seconds (the observation frequency is 512 Hz, and hence the entire data size is 113664) and that for the first one second; it seems to perturb like a diffusion process.
We define realised volatilities with subsampling as for a sequence of real-valued observation ,
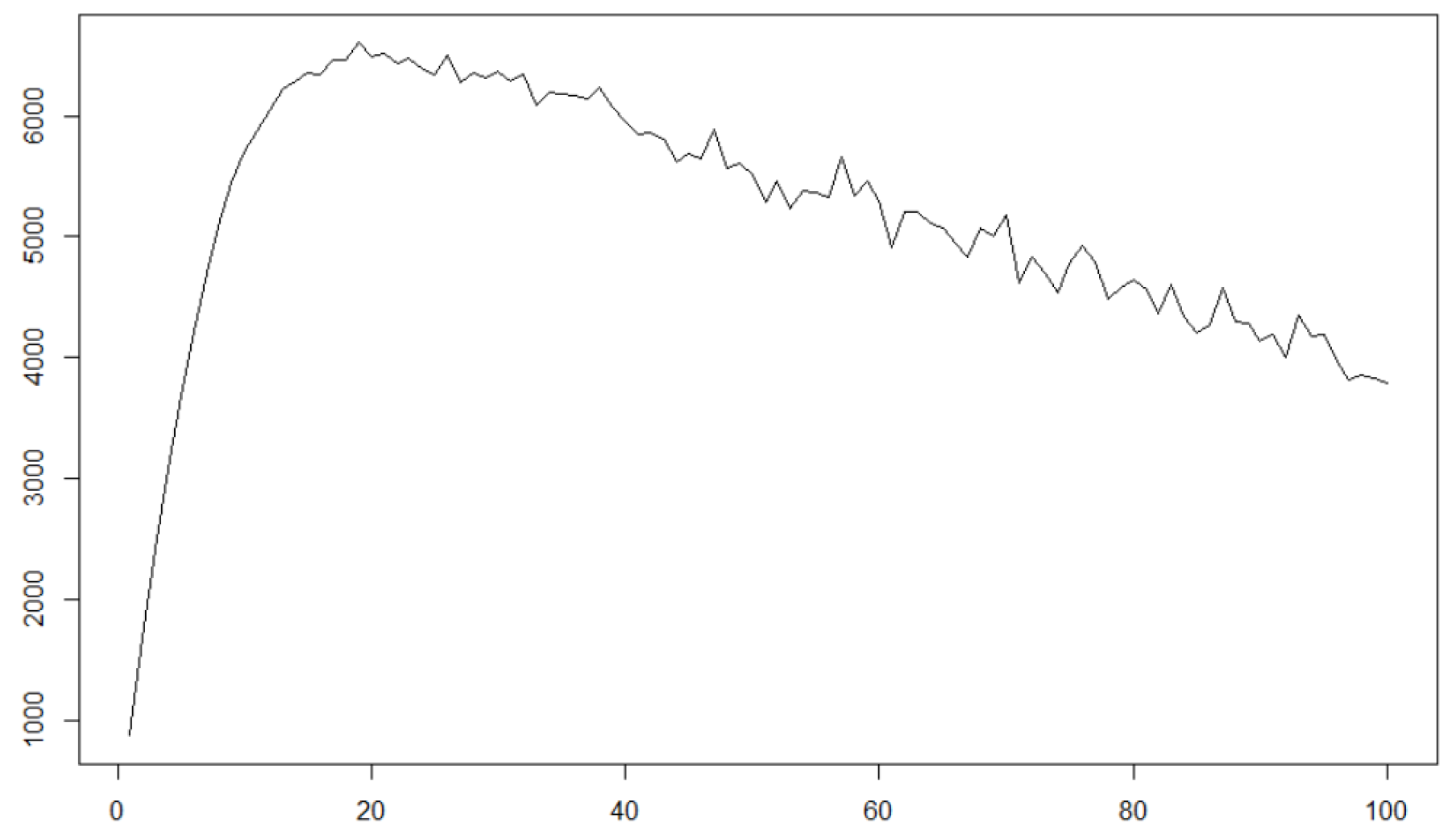
where is the subsampling frequency parameter, and provide a plot of the realised volatilities the 2nd axis of the data S02E.mat in Figure 2:
The altitudes of the graph represented in the y-axis correspond to the values of the realised volatilities with subsampling at every k observation represented in the x-axis. It is observable that the increasing subsampling frequency results in decreasing realised volatilities, which cannot be explained by the existent major microstructure noises, e.g., see [21,22,23,24,25]. To explain this phenomenon, we consider the smoother process than the latent one, though ordinarily microstructure noises make the observation rougher than the latent process, because quadratic variation of a sufficiently smooth function is zero. One way to deal with smoother observation than the latent state is convolutional observation. As a concrete example, we show a convolutionally observed diffusion process and its characteristics in realised volatilities: let us consider the following 1-dimensional stochastic differential equation defining an Ornstein–Uhlenbeck (OU) process:
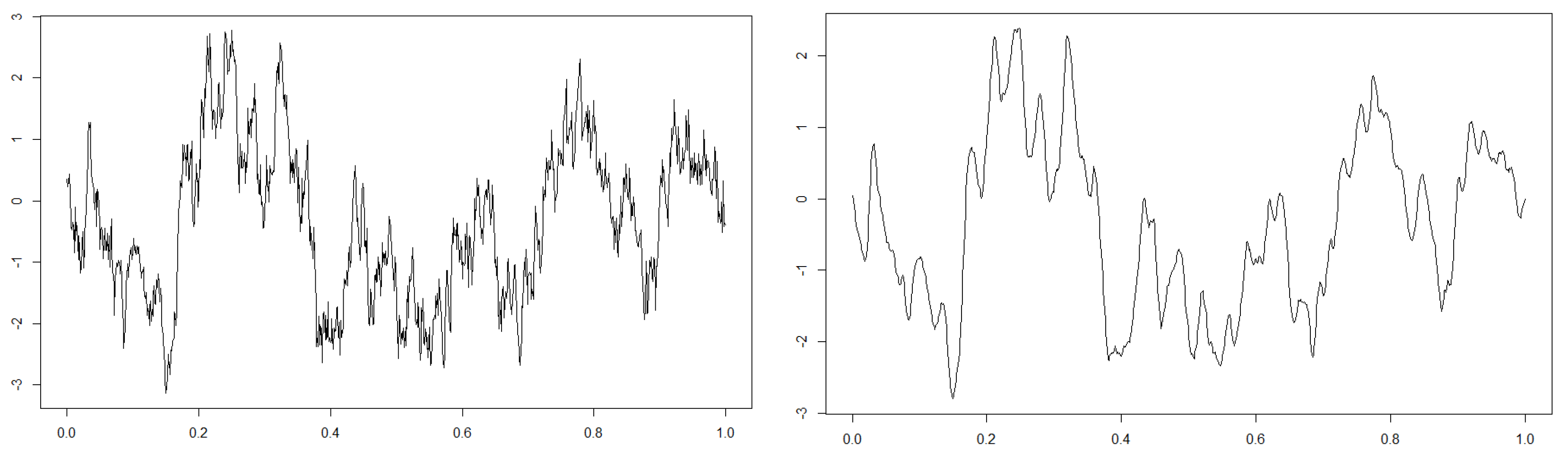
where . We simulate the stochastic differential equation by Euler–Maruyama method see [26] with parameters , , and and its convolution approximated by summation with the smoothing parameter (for details, see Section 5). Figure 3 shows the latent diffusion process and the convoluted observation on , and we can see that the observation is indeed smoothed compared to the latent state.
In Figure 4, we also give the plot of realised volatilities of the convolutionally observed process with subsampling as Figure 2.
It is seen that the convolutional observation of a diffusion process also has the characteristics of decreasing realised volatilities as subsampling frequency increases, which can bee seen in some biological data such as BNCI Horizon 2020 [20]. Of course, graphically comparing characteristics of simulation and real data is insufficient to verify the convolutional observation with smoothing parameter in 1-dimensional case; therefore, we propose statistical estimation method for unknown and hypothesis test with the null hypothesis and the alternative one from convolutional observation in Section 3. Moreover, in Section 6, we examine the real EEG data plotted in Figure 2 by the statistical hypothesis testing we propose, and see it is more appropriate to consider the data as a convolutional observation of a latent diffusion process with rather than direct observation of the latent process, which indicates the validity to deal with the problem of the convolutional observation scheme with unknown .
The paper is composed of the following sections: Section 2 gives the notations and assumptions used in this paper; Section 3 discusses the estimation and test for smoothing parameter , and the discussion provides us with the tools to examine whether we should consider the convolutional observation scheme; Section 4 proposes the quasi-likelihood functions for the parameter of diffusion processes and , and corresponding estimators with consistency; Section 5 is for the computational simulation to examine the theoretical results in the previous sections; and Section 6 shows an application of the methods we propose in real data analysis.
2. Notations and Assumptions
2.1. Notations
First of all, we set , , and . We also give the notation for a matrix-valued function such that , where
The continuity of the function is shown in the supplementary material. For the detailed discussion of the necessity of , see Remark 4.
In addition, we also give the notation used throughout this paper.
- For every matrix A, is the transpose of A, and .
- For every set of matrices A and B of the same size, . Moreover, for any , and , .
- and denote the ℓ-th element of a vector v and the -th one of a matrix A, respectively.
- For any vector v and any matrix A, and .
- denotes the stochastic basis, where .
- denotes the integral of a -integrable function f where is a measure.
2.2. Assumptions
With respect to , we assume the following conditions.
- [A1]
- (i)
- For a constant C, for all ,
- (ii)
- For all , .
- (iii)
- There exists a unique invariant measure on and for all and with polynomial growth,
Remark 1.For sufficient conditions of these regularity ones, please see [A1] and Remark 1 in Uchida and Yoshida [7].- [A2]
- There exists such that and have continuous derivatives satisfyingWith the invariant measure , , and denoting the true value of , we defineFor these functions, let us assume the following identifiability conditions hold.
- [A3]
- There exist and such that for all and , and .
3. Estimation and Test of the Smoothing Parameter
In this section, we discuss the case where the smoothing parameter of the kernel function is unknown. The estimation is significant for estimation of and since we utilise the estimate for in quasi-likelihood functions of and . The test problem for hypotheses and is also important to examine whether our framework of convolutional observation is meaningful.
3.1. Estimation of the Smoothing Parameter
For simplicity of notation, let us consider the case ; otherwise the discussion is quite parallel. We should note that for all ,
Let us consider the estimation of with using the next statistics: the full quadratic variation
because of Proposition 3 in supplementary material Appendix A, and the reduced quadratic variation defined as converges in probability as follows.
Lemma 1.
Under [A1], we have the convergence in probability such that
Then we define the ratio of those statistics such that
where R has the next property.
Lemma 2.
R is a -valued monotonically decreasing continuous function, and has a continuous inverse .
We define such that
and then continuous mapping theorem for convergence in probability verifies the next result.
Theorem 1.
Under [A1], has consistency, i.e., .
Remark 2.
We can compute by solving the following equations:
3.2. Test for Smoothed Observation
For all , we consider the next hypothesis testing:
Let us consider the following test statistic:
and we abbreviate to if . Under , we have the next result.
Theorem 2.
Under and [A1], we have the convergence in law such that
We also obtain the result to support the consistency of the test.
Theorem 3.
Under and [A1], we have convergence such that for any ,
Remark 3.
These results are intuitive since the quadratic variation and the reduced one with some appropriate scaling should converge to the same value if holds and the quadratic variation with some appropriate scaling should converge to the value which is smaller than the value which the reduced one with scaling converge to.
Hence when we set the significance level , then we have the rejection region
where is the distribution function of the standard Gaussian distribution. Theorem 3 supports the consistency of the test.
This test is essential in terms of examining the validity to consider the scheme of convolutional observation: if , then the ordinary observation scheme can be applied, but if , then we have the motivation to consider the convolutional observation scheme.
4. Least Square Estimation of the Diffusion and Drift Parameters
Let us set the least-square quasi-likelihood functions such that
and the least-square estimators and satisfying
when is known, and
when is unknown.
Theorem 4.
Under [A1]–[A3], and are consistent, i.e., and .
Remark 4.
The function and are indeed complex and confusing; hence, we can consider some alternative estimation methods with subsampling or pre-averaging. However, these methods also have the problem what size of subsampling or pre-averaging is proper and the result of the estimation can be dependent on tuning the subsampling size or pre-averaging one. Therefore, our work proposes the estimation method which uses the observation without subsampling or pre-averaging.
5. Simulations
In this simulation section, we only consider the case where is unknown and should be estimated by data with the method proposed in Section 3.
5.1. 1-Dimensional Simulation
We examine the following 1-dimensional stochastic differential equation whose solution is a 1-dimensional Ornstein–Uhlenbeck (OU) process:
, , and . The procedure of the simulation is as follows: in the first place we iterate an approximated OU process by Euler–Maruyama scheme, for example, see [26] with simulation parameters , , where is a parameter to determine the precision of approximation; secondly, we give the approximation of convolution by summation such that
where , the sampling frequency and . In this Section 5.1, we fix the true value of and as and , and change the true value of to see the corresponding changes of performance of estimation for , and test for in comparison to estimation by an existent method called local Gaussian approximation (LGA) for parametric estimation of discretely observed diffusion processes, e.g., see [4] which does not concern convolutional observation. All the numbers of iterations for different ’s are 1000.
In the first place, we see the estimation and test with small values of such that to observe how the performance of statistics changes by difference in . Table 1 summarises the results of simulation of for ’s with respective empirical means and root mean square error (RMSE).
We can see the proposed estimator works well for small . With respect to the performance of the test statistic proposed in Section 3.2, Table 2 shows the empirical ratio of the number of iterations whose is lower than some typical critical values where indicates the distribution function of 1-dimensional standard Gaussian distribution as well as the maximum value of in 1000 iterations.
Even for , the simulation result supports the theoretical discussion of the test with consistency. Because , all the iterations with result in rejection of with substantially significance level . Let us see the estimation for and by our proposal method and that by the LGA in Table 3.
Note that the biases of the estimation by LGA increase as the true value of gets larger, while the estimation by our proposal method is not influenced by the true value of . This result of the simulation supports the theoretical discussion in Section 4 stating the consistency of , and necessity to consider the convolutional observation scheme where the LGA method does not work properly.
Secondly, we consider the estimation and test with large such that = 10, 15, 20 to see if our proposal methods work even for large . We note that the maximum values of for = 10, 15, 20 in 1000 iterations are , and , and hence we can detect the smoothed observation easily. Table 4 shows the empirical means and RMSEs of for = 10, 15, 20 and we can see that the RMSEs increase as ’s increase; it indicates the difficulty to estimate accurately when is large.
Table 5 summarises the estimation for by means and RMSE, and tells us that although the large RMSE of results in increase of RMSE of , estimation by our method is substantially better than that by LGA.
5.2. 2-Dimensional Simulation
We consider the following 2-dimensional stochastic differential equation whose solution is a 2-dimensional OU process:
. The simulation is conducted with the settings as follows: firstly, we iterate the OU process by Euler–Maruyama scheme with the simulation sample size , and discretisation step , where is the precision parameter for approximation of convolution; in the second place, we approximate the convoluted process with summation such that
where , the sampling scheme for inference is defined as and ; the true value of , and are set as , , ; the parameter spaces are defined as , , and ; the total iteration number is set to 1000.
Table 6 summarises the estimation for with the method proposed in Section 3 (the inverse of r is computationally obtained) with empirical means and empirical RMSEs of in 1000 iterations. We can see that is sufficiently precise to estimate the true value of indeed in this result, which is significant to estimate the other parameters and .
We also note that the maximum values of the test statistics for smoothed observation proposed in Section 3.2 in 1000 iterations are and for each axis. The p-value for them are smaller than ; therefore, we can conclude that it is possible to detect the smoothed observation with the proposed test statistic in the case if from this result.
With respect to the estimation for and , we compare the estimates by our proposal method with that by LGA which does not concern convolutional observation. Table 7 is the summary for estimate by both the methods:
We can see that the estimation precision for by our proposal outperforms those by LGA. This results support validity of our estimation method if we have convolutional observation for diffusion processes. Regarding , the simulation result is summarised in Table 8:
Though the estimation for by our method has the smaller bias in comparison to that by LGA, the RMSE of our method is larger than that of LGA; in the estimation for other parameters, our proposal method outperforms the method by LGA. We can conclude that our proposal for estimation of and concerning convolutional observation performs better than that not considering this observation scheme.
6. Real Data Analysis
In this section, we analyse the EEG dataset named S02E.mat provided in “2. Two class motor imagery (002-2014)” of BNCI Horizon 2020 [20]. The datasets including S02E.mat are also studied by Steryl et al. [27].
6.1. Estimation and Test for the Smoothing Parameters
In the first place, we pick up the first 15 axes of the dataset and compute and proposed in Section 3.1 and Section 3.2 respectively. The results are shown in Table 9.
We can observe that all the 15 time series data have the smoothing parameter with statistical significance when we assume ordinary significance levels. These results motivate us to use our methods for parametric estimation proposed in Section 4 when we fit stochastic differential equations for these data.
6.2. Parametric Estimation for a Diffusion Process
We fit a 1-dimensional OU process for the time series data in the 2nd column of the data file S02E.mat with 512 Hz observation for 222 s (the plot of the path can be seen in Figure 1), whose is the largest among those for the 15 axes and it is larger than 0 with statistical significance. According to the simulation result shown in Section 5.1, this size of the smoothing parameter gives critical biases when we estimate and with LGA method not concerning convolutional observation scheme.
The stochastic differential equation with parameters and is defined as follows:
We set 5 s as the time unit: hence 113,664 and . If we fit the OU process with the LGA method, i.e., we do not concern convolutional observation scheme, we obtain the fitting result such that
In the next place, we fit and with the least square method proposed in Section 4, and then we have the next fitting result:
It is worth noting that this fitting result is substantially different to that by LGA as shown above: hence these results indicate the significance to examine if the observation is convoluted with the smoothing parameter and otherwise the estimation is strongly biased.
7. Summary
We have discussed the convolutional observation scheme which deals with the smoothness of observation in comparison to ordinary diffusion processes. The first contribution is to propose this new observation scheme with the statistical test to confirm whether this scheme is valid in real data. The second one is to prove consistency of the estimator for the smoothing parameter , those for parameters in diffusion and drift coefficient, i.e., and , of the latent diffusion process . Thirdly, we have examined the performance of those estimators and the test statistics in computational simulation, and verified these statistics work well in realistic settings. In the fourth place, we have shown a real example of observation where holds with statistical significance.
If we combine the test for noise detection by Nakakita and Uchida [28] and that for smoothed observation proposed in this paper, we can test if the observed process is diffusion or not in terms that the observation is noisy or smoothed. Note that the realised volatilities of the noisy observation of diffusion processes increase as observation frequency increases while those of the smoothed observation decreases as the frequency grows. On that point, the noisy observation in ordinary meaning and the smoothed one are ‘opposite’ to each other.
These contributions, especially the third one, will cultivate the motivation to study statistical approaches for convolutionally observed diffusion processes furthermore, such as estimation of kernel function V appearing in the convoluted diffusion , test theory for parameters and as likelihood-ratio-type test statistics, for example, see [29,30], large deviation inequalities for quasi-likelihood functions and associated discussion of Bayes-type estimators, e.g., [6,31,32,33]. By these future works, it is expected that the applicability of stochastic differential equations in real data analysis and contributions to the areas with high frequency observation of phenomena such as EEG will be enhanced.
8. Proofs
8.1. the Results for Some Laws of Large Numbers
In this subsection, we give the notations and statements of propositions without proofs except for Proposition 3: the detailed proofs are given in supplementary material. We assume , , and consider a class of -valued kernel functions on denoted as such that for all , it holds:
Remark 5.
Note one sufficient condition for is (i) , (ii) , (iii) and (iv) -measurable since
for the Cauchy–Schwarz inequality, and Fubini’s theorem.
It is easily checked that .
Let p denote an integer such that , . We set the sequence of the kernels such that for some , and there exist a matrix such that
a set such that there exist functions for such that
a function such that
We define
and the following random quantities such that
where , , are in -class, and their first and second derivatives and themselves are at most polynomial growth uniformly in .
Proposition 1.
Under [A1], uniformly in
Proposition 2.
If and [A1] hold, uniformly in
Proposition 3.
Under [A1], uniformly in
We set , and see the evaluation of B, and G when setting our kernel as follows (for the derivation of the evaluation, see the supplementary material): we have , , , where ,
for because of independent increments of the Wiener process, and where .
8.2. Proof of the Results in Section 3.1
Proof of Lemma 1.
By following the proof of the Proposition 3, it is sufficient to evaluate
for the asymptotic behaviour of the reduced quadratic variation by choosing
If ,
and if ,
Hence, we obtain the proof (for details, see the supplementary material). □
Proof of Lemma 2.
Continuity is obvious, and monotonicity is obtained as follows: if ,
and if ,
and if ,
The inverse can be obtained directly. □
Proof of Theorem 1.
It follows from Lemma 1, 2 and continuous mapping theorem. □
8.3. Proofs of the Results in Section 3.2
Proof of Theorem 2.
Proof of Theorem 3.
By Lemma 1, there exists a number such that
and hence it is sufficient to show that
and it is obvious that
and
by Proposition A in Gloter [9], and a parallel result holds for . Hence we obtain the result. □
8.4. Proof of the Results in Section 4
Proof of Theorem 4.
We only deal with the case where is unknown because the discussion for the case where is known is parallel. First of all, we prove the consistency of . We obtain that
because continuous mapping theorem holds. Therefore, it follows from Proposition 1 and Proposition 3 that
where indicates the term converging in probability to zero uniformly in . Then we obtain that in the same way as Kessler [4] with Assumption [A3].
In the next place, we consider the consistency of . Firstly, we consider the case for an integer . Then it is sufficient to show
due to Assumption [A3]. Because the evaluation where using independent increments of the Wiener process, Proposition 1 and Proposition 2 verify
where
In addition, the exact convergences such that
hold for all , since for all ,
Therefore, for any ,
For the case for an integer , we similarly obtain
because we have
and
and it holds that for any ,
Hence it is shown that with Assumption [A3]. □
Supplementary Materials
The following are available online at https://www.mdpi.com/1099-4300/22/9/1031/s1.
Author Contributions
Conceptualization, S.H.N. and M.U.; Methodology, S.H.N. and M.U.; Software, S.H.N.; Validation, S.N.; Formal Analysis, S.H.N.; Investigation, S.H.N.; Resources, S.H.N. and M.U.; Data Curation, S.H.N.; Writing—Original Draft Preparation, S.H.N.; Writing—Review & Editing, M.U.; Visualization, S.H.N.; Supervision, M.U.; Project Administration, M.U.; Funding Acquisition, S.H.N. and M.U. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially funded by JST CREST, JSPS KAKENHI Grant Number JP17H01100 and JP20J10058.
Acknowledgments
This work was partially supported by Cooperative Research Program of the Institute of Statistical Mathematics.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Florens-Zmirou, D. Approximate discrete time schemes for statistics of diffusion processes. Statistics 1989, 20, 547–557. [Google Scholar] [CrossRef]
- Yoshida, N. Estimation for diffusion processes from discrete observation. J. Multivar. Anal. 1992, 41, 220–242. [Google Scholar] [CrossRef] [Green Version]
- Bibby, B.M.; Sørensen, M. Martingale estimating functions for discretely observed diffusion processes. Bernoulli 1995, 1, 17–39. [Google Scholar] [CrossRef]
- Kessler, M. Estimation of an ergodic diffusion from discrete observations. Scand. J. Stat. 1997, 24, 211–229. [Google Scholar] [CrossRef]
- Kessler, M.; Sørensen, M. Estimating equations based on eigenfunctions for a discretely observed diffusion process. Bernoulli 1999, 5, 299–314. [Google Scholar] [CrossRef]
- Yoshida, N. Polynomial type large deviation inequalities and quasi-likelihood analysis for stochastic differential equations. Ann. Inst. Stat. Math. 2011, 63, 431–479. [Google Scholar] [CrossRef]
- Uchida, M.; Yoshida, N. Adaptive estimation of an ergodic diffusion process based on sampled data. Stoch. Process. Their Appl. 2012, 122, 2885–2924. [Google Scholar] [CrossRef] [Green Version]
- Uchida, M.; Yoshida, N. Adaptive Bayes type estimators of ergodic diffusion processes from discrete observations. Stat. Inference Stoch. Process. 2014, 17, 181–219. [Google Scholar] [CrossRef]
- Gloter, A. Discrete sampling of an integrated diffusion process and parameter estimation of the diffusion coefficient. ESAIM Probab. Stat. 2000, 4, 205–227. [Google Scholar] [CrossRef]
- Ditlevsen, S.; Sørensen, M. Inference for observations of integrated diffusion processes. Scand. J. Stat. 2004, 31, 417–429. [Google Scholar] [CrossRef]
- Gloter, A. Parameter estimation for a discretely observed integrated diffusion process. Scand. J. Stat. 2006, 33, 83–104. [Google Scholar] [CrossRef]
- Gloter, A.; Gobet, E. LAMN property for hidden processes: The case of integrated diffusions. Ann. l’Institut Henri Poincaré Probab. Stat. 2008, 44, 104–128. [Google Scholar] [CrossRef]
- Sørensen, M. Prediction-based estimating functions: Review and new developments. Braz. J. Probab. Stat. 2011, 25, 362–391. [Google Scholar] [CrossRef]
- Donnet, S.; Samson, A. A review on estimation of stochastic differential equations for pharmacokinetic/pharmacodynamic models. Adv. Drug Deliv. Rev. 2013, 65, 929–939. [Google Scholar] [CrossRef] [PubMed]
- Delattre, M.; Genon-Catalot, V.; Samson, A. Mixtures of stochastic differential equations with random effects: Application to data clustering. J. Stat. Plan. Inference 2016, 173, 109–124. [Google Scholar] [CrossRef]
- Picchini, U.; Forman, J.L. Bayesian inference for stochastic differential equation mixed effects models of a tumour xenography study. J. R. Stat. Soc. Ser. C Appl. Stat. 2019, 68, 887–913. [Google Scholar] [CrossRef]
- Ruse, M.G.; Samson, A.; Ditlevsen, S. Inference for biomedical data by using diffusion models with covariates and mixed effects. J. R. Stat. Soc. Ser. C Appl. Stat. 2020, 69, 167–193. [Google Scholar] [CrossRef]
- Zhang, L.; Mykland, P.A.; Aït-Sahalia, Y. A Tale of Two Time Scales: Determining Integrated Volatility with Noisy High-Frequency Data. J. Am. Stat. Assoc. 2005, 100, 1394–1411. [Google Scholar] [CrossRef]
- Aït-Sahalia, Y.; Jacod, J. High-Frequency Financial Econometrics; Princeton University Press: Princeton, NJ, USA, 2014. [Google Scholar]
- BNCI Horizon 2020. Two Class Motor Imagery. 2014. Available online: http://bnci-horizon-2020.eu/database/data-sets (accessed on 20 April 2019).
- Jacod, J.; Li, Y.; Mykland, P.A.; Podolskij, M.; Vetter, M. Microstructure noise in the continuous case: The pre-averaging approach. Stoch. Process. Their Appl. 2009, 119, 2249–2276. [Google Scholar] [CrossRef] [Green Version]
- Jacod, J.; Podolskij, M.; Vetter, M. Limit theorems for moving averages of discretized processes plus noise. Ann. Stat. 2010, 38, 1478–1545. [Google Scholar] [CrossRef]
- Bibinger, M.; Hautsch, N.; Malec, P.; Reiß, M. Estimating the quadratic covariation matrix from noisy observations: Local method of moments and efficiency. Ann. Stat. 2014, 42, 1312–1346. [Google Scholar] [CrossRef]
- Koike, Y. Quadratic covariation estimation of an irregularly observed semimartingale with jumps and noise. Bernoulli 2016, 22, 1894–1936. [Google Scholar] [CrossRef] [Green Version]
- Ogihara, T. Parametric inference for nonsynchronously observed diffusion processes in the presence of market microstructure noise. Bernoulli 2018, 24, 3318–3383. [Google Scholar] [CrossRef] [Green Version]
- Iacus, S.M. Simulation and Inference for Stochastic Differential Equations: With R Examples; Springer: New York, NY, USA, 2008. [Google Scholar]
- Steyrl, D.; Scherer, R.; Faller, J.; Müller-Putz, G.R. Random forests in non-invasive sensorimotor rhythm brain-computer interfaces: A practical and convenient non-linear classifier. Biomed. Tech. 2016, 61, 77–86. [Google Scholar] [CrossRef]
- Nakakita, S.H.; Uchida, M. Inference for ergodic diffusions plus noise. Scand. J. Stat. 2019, 46, 470–516. [Google Scholar] [CrossRef] [Green Version]
- Kitagawa, H.; Uchida, M. Adaptive test statistics for ergodic diffusion processes sampled at discrete times. J. Stat. Plan. Inference 2014, 150, 84–110. [Google Scholar] [CrossRef]
- Nakakita, S.H.; Uchida, M. Adaptive test for ergodic diffusions plus noise. J. Stat. Plan. Inference 2019, 203, 131–150. [Google Scholar] [CrossRef] [Green Version]
- Ogihara, T.; Yoshida, N. Quasi-likelihood analysis for the stochastic differential equation with jumps. Stat. Inference Stoch. Process. 2011, 14, 189–229. [Google Scholar] [CrossRef]
- Clinet, S.; Yoshida, N. Statistical inference for ergodic point processes and application to Limit Order Book. Stoch. Process. Their Appl. 2017, 127, 1800–1839. [Google Scholar] [CrossRef] [Green Version]
- Nakakita, S.H.; Uchida, M. Quasi-likelihood analysis of an ergodic diffusion plus noise. arXiv 2018, arXiv:1806.09401. [Google Scholar]
Figure 1.
The path of the second column of S02E.mat of BNCI Horizon 2020 [20] for all 222 seconds (left) and the first one second (right).
Figure 1.
The path of the second column of S02E.mat of BNCI Horizon 2020 [20] for all 222 seconds (left) and the first one second (right).

Figure 2.
Realised volatilities with subsampling of the 2nd axis of data S02E.mat in two class motor imagery (002-2014) [20].
Figure 2.
Realised volatilities with subsampling of the 2nd axis of data S02E.mat in two class motor imagery (002-2014) [20].

Figure 3.
The left figure is the plot of the latent diffusion process, and the right one is that of the convolutionally observed process on respectively.
Figure 3.
The left figure is the plot of the latent diffusion process, and the right one is that of the convolutionally observed process on respectively.

Figure 4.
The realised volatilities of the convolutionally observed diffusion process with subsampling.
Figure 4.
The realised volatilities of the convolutionally observed diffusion process with subsampling.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Estimation performance of with small .
| 0.0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 | |
| mean | |||||||||||
| RMSE |
Table 2.
Empirical ratio of test statistic less than some critical values, and the maximum value of in 1000 iterations.
Table 2.
Empirical ratio of test statistic less than some critical values, and the maximum value of in 1000 iterations.
| Empirical Ratio of Less Than… | Max. of | |||||
|---|---|---|---|---|---|---|
Table 3.
Estimation of by the proposed method and LGA with small .
| The Proposed Method | LGA | ||||||
|---|---|---|---|---|---|---|---|
| True Value | |||||||
| mean | |||||||
| RMSE | |||||||
| mean | |||||||
| RMSE | |||||||
| mean | |||||||
| RMSE | |||||||
| mean | |||||||
| RMSE | |||||||
| mean | |||||||
| RMSE | |||||||
| mean | |||||||
| RMSE | |||||||
| mean | |||||||
| RMSE | |||||||
| mean | |||||||
| RMSE | |||||||
| mean | |||||||
| RMSE | |||||||
| mean | |||||||
| RMSE | |||||||
| mean | |||||||
| RMSE | |||||||
Table 4.
The performance of for in 1000 iterations.
| mean of | |||
| RMSE of |
Table 5.
Estimation of by the proposed method with large .
| The Proposed Method | LGA | ||||||
|---|---|---|---|---|---|---|---|
| True Value | |||||||
| mean | |||||||
| RMSE | |||||||
| mean | |||||||
| RMSE | |||||||
| mean | |||||||
| RMSE | |||||||
Table 6.
Summary for estimate.
| true value | ||
| empirical mean | ||
| empirical RMSE |
Table 7.
Summary for estimate.
| True Value | ||||
| Our proposal | mean | |||
| RMSE | ||||
| LGA | mean | |||
| RMSE |
Table 8.
Summary for estimate.
| True Value | |||||||
| Our proposal | mean | ||||||
| RMSE | |||||||
| LGA | mean | ||||||
| RMSE |
Table 9.
The values of and for the first 15 axes of S02.mat by BNCI Horizon 2020 [20].
Table 9.
The values of and for the first 15 axes of S02.mat by BNCI Horizon 2020 [20].
| 1st axis | 2nd axis | 3rd axis | 4th axis | 5th axis | |
| 6th axis | 7th axis | 8th axis | 9th axis | 10th axis | |
| 11th axis | 12th axis | 13th axis | 14th axis | 15th axis | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Nakakita, S.H.; Uchida, M. Inference for Convolutionally Observed Diffusion Processes. Entropy 2020, 22, 1031. https://doi.org/10.3390/e22091031
AMA Style
Nakakita SH, Uchida M. Inference for Convolutionally Observed Diffusion Processes. Entropy. 2020; 22(9):1031. https://doi.org/10.3390/e22091031
Chicago/Turabian StyleNakakita, Shogo H, and Masayuki Uchida. 2020. "Inference for Convolutionally Observed Diffusion Processes" Entropy 22, no. 9: 1031. https://doi.org/10.3390/e22091031
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.