Are Strategies Favoring Pattern Matching a Viable Way to Improve Complexity Estimation Based on Sample Entropy?

 ,
,  ,
,  ,
,  ,
,  , and
, and
Abstract
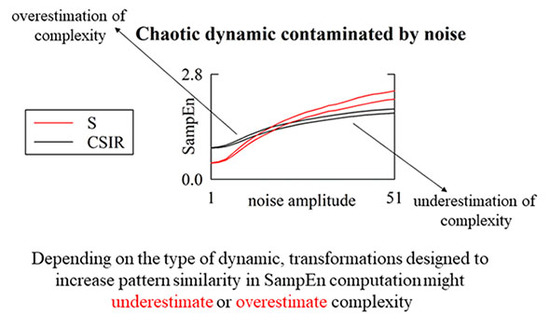
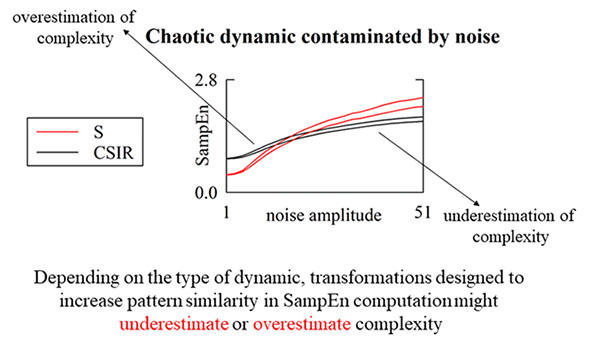
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Methods
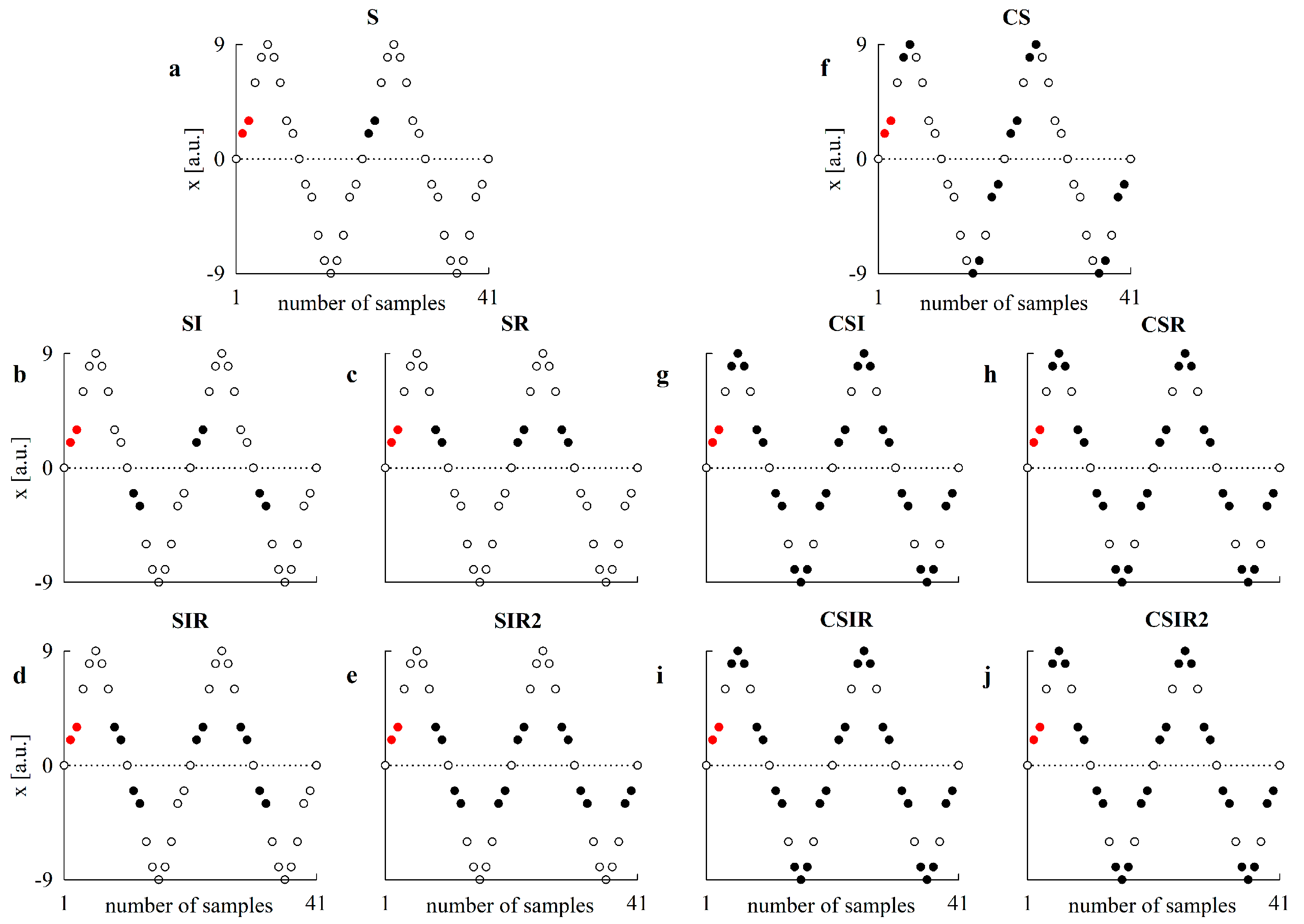
2.1. Pattern Definition, Transformations and Matching
2.2. SampEn Computation
2.3. Strategies for Increasing the Number of Matches
3. Simulated Data and Nonlinearity Test
3.1. Simulations
3.2. Surrogate Series and Detection of Nonlinear Dynamics
4. Experimental Protocol and Data Analysis
4.1. Experimental Protocol
4.2. Extraction of the Beat-to-Beat Variability and Preprocessing Techniques
4.3. Assessing Complexity Using the Different Matching Strategies
4.4. Statistical Analysis
5. Results
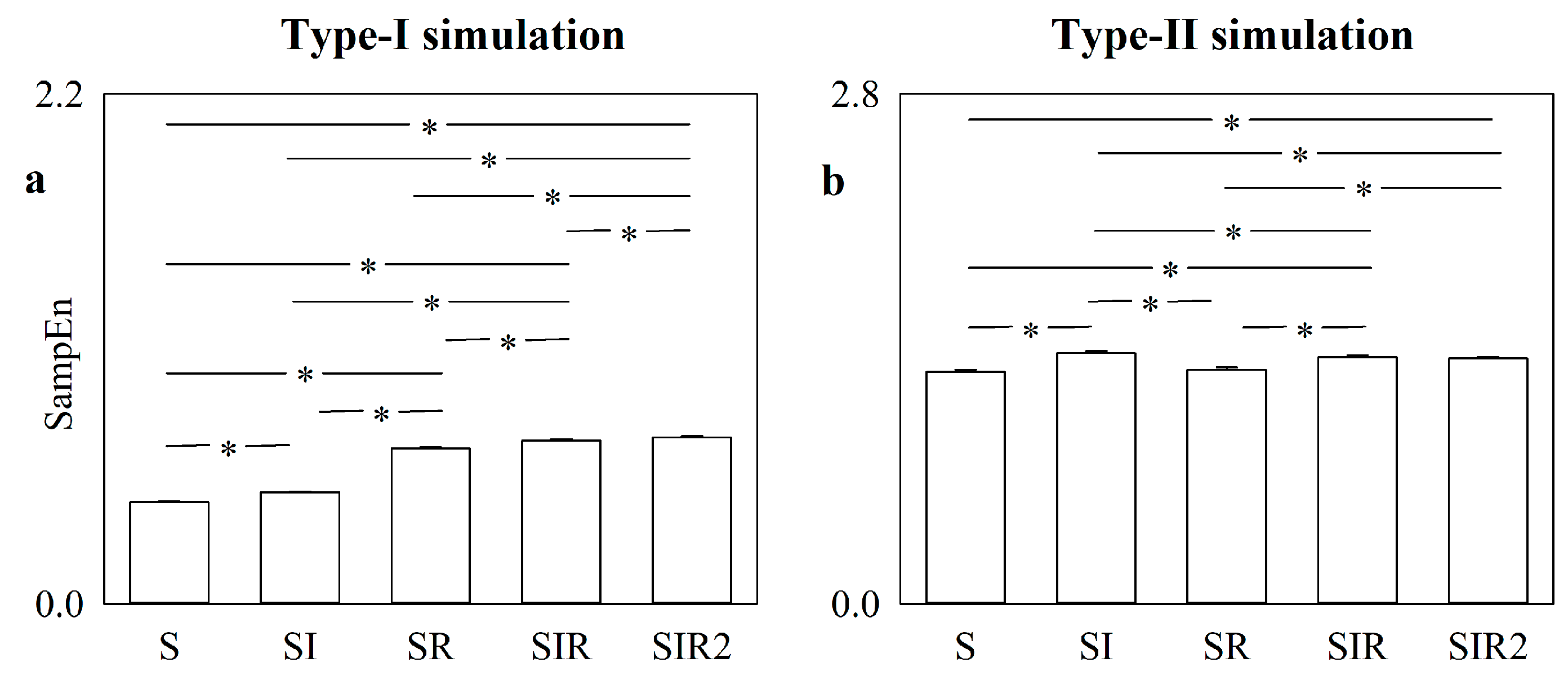
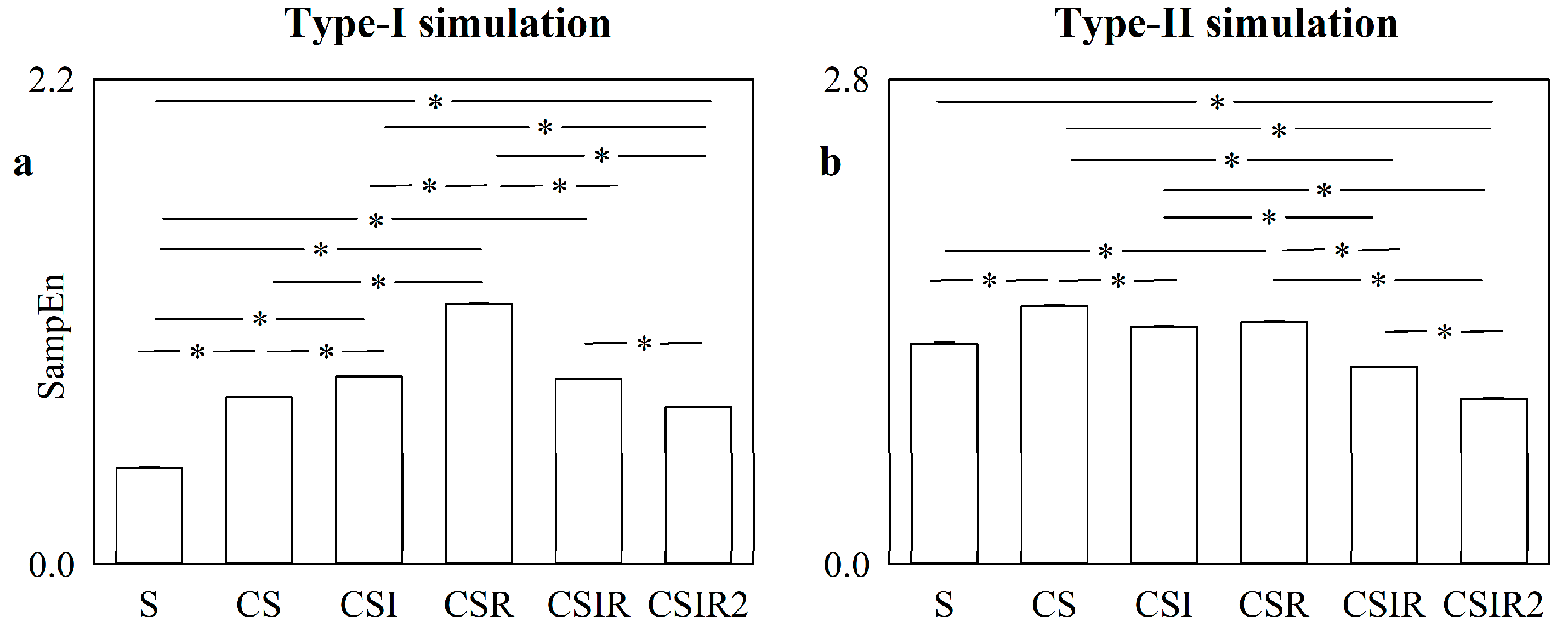
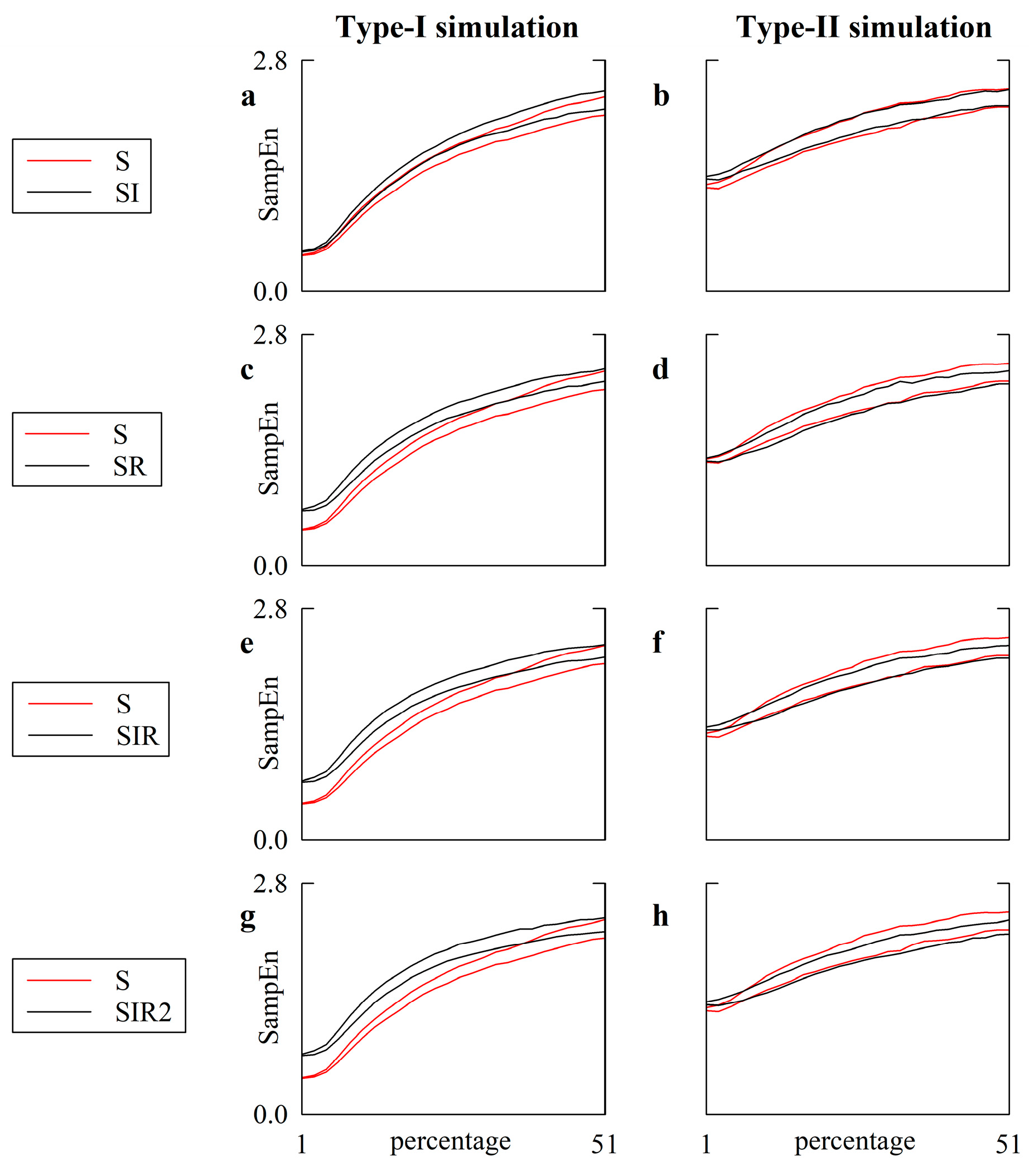
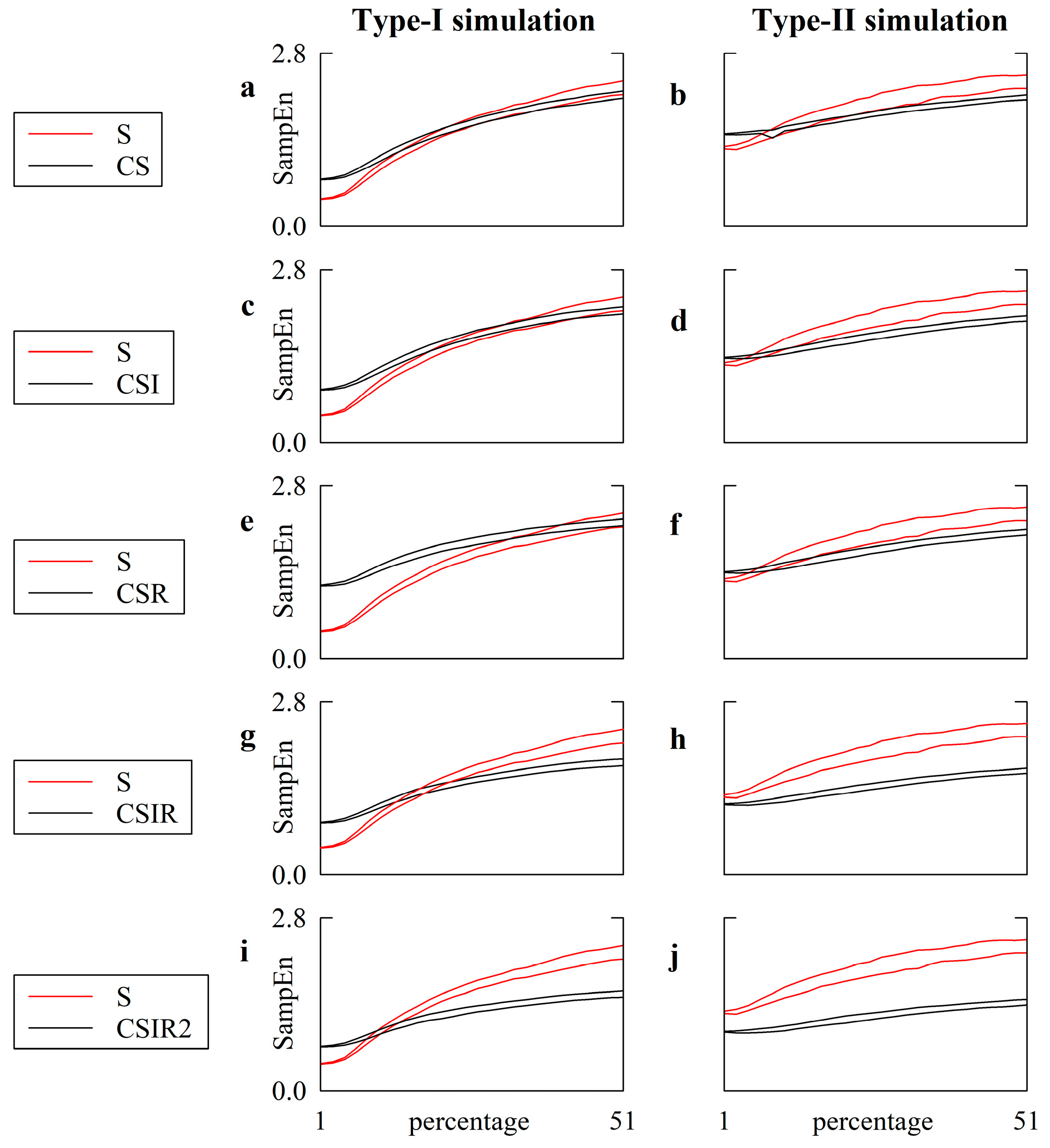
5.1. Simulated Type-I and Type-II Series: Effect of Pattern Matching Strategies on SampEn
5.2. Simulated Type-I and Type-II Series: The Effect of Pattern Matching Strategies on SampEn Depends on Noise Level
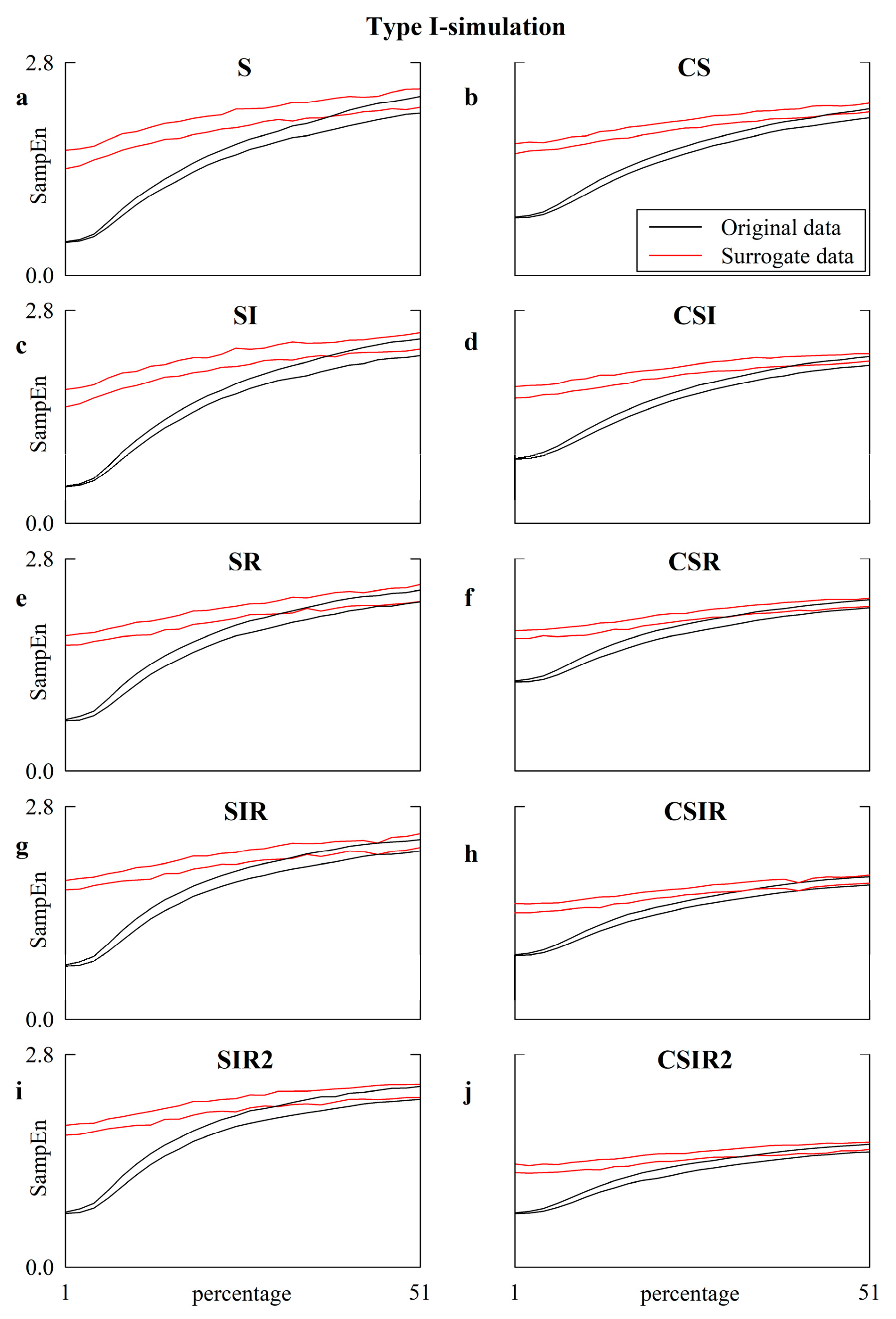
5.3. Simulated Type-I Series: Effect of Pattern Matching Strategies on the Detection of Nonlinear Dynamics
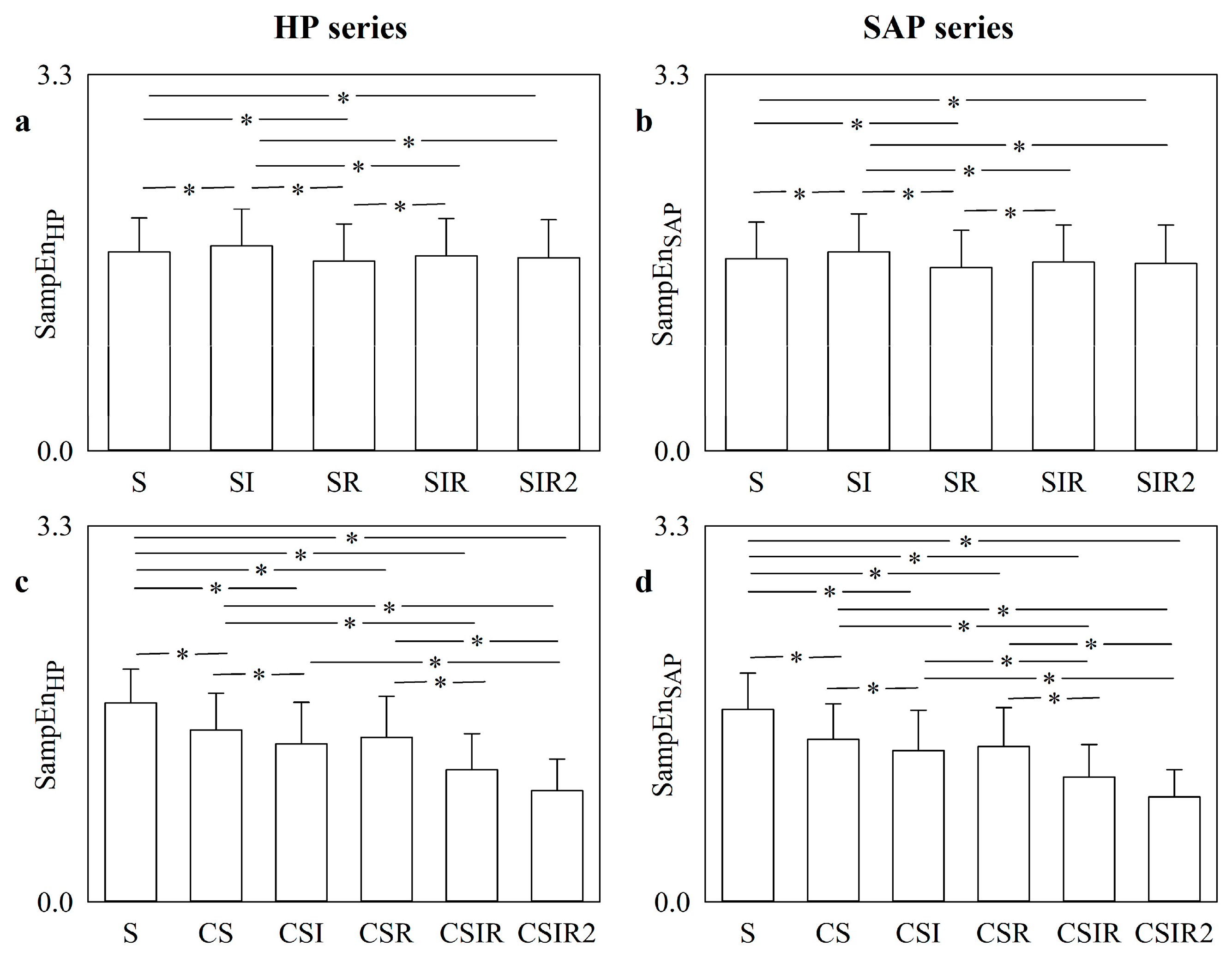
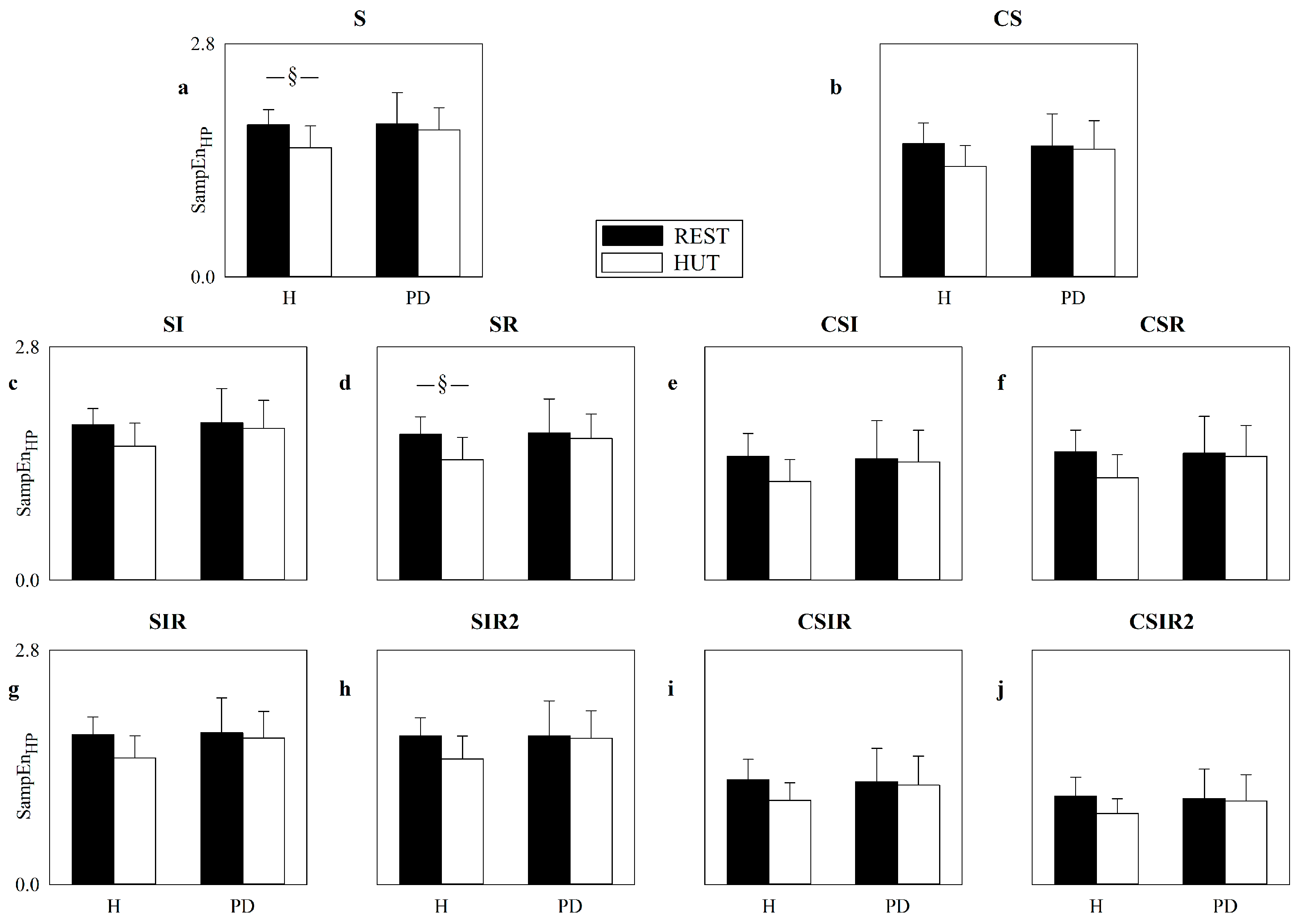
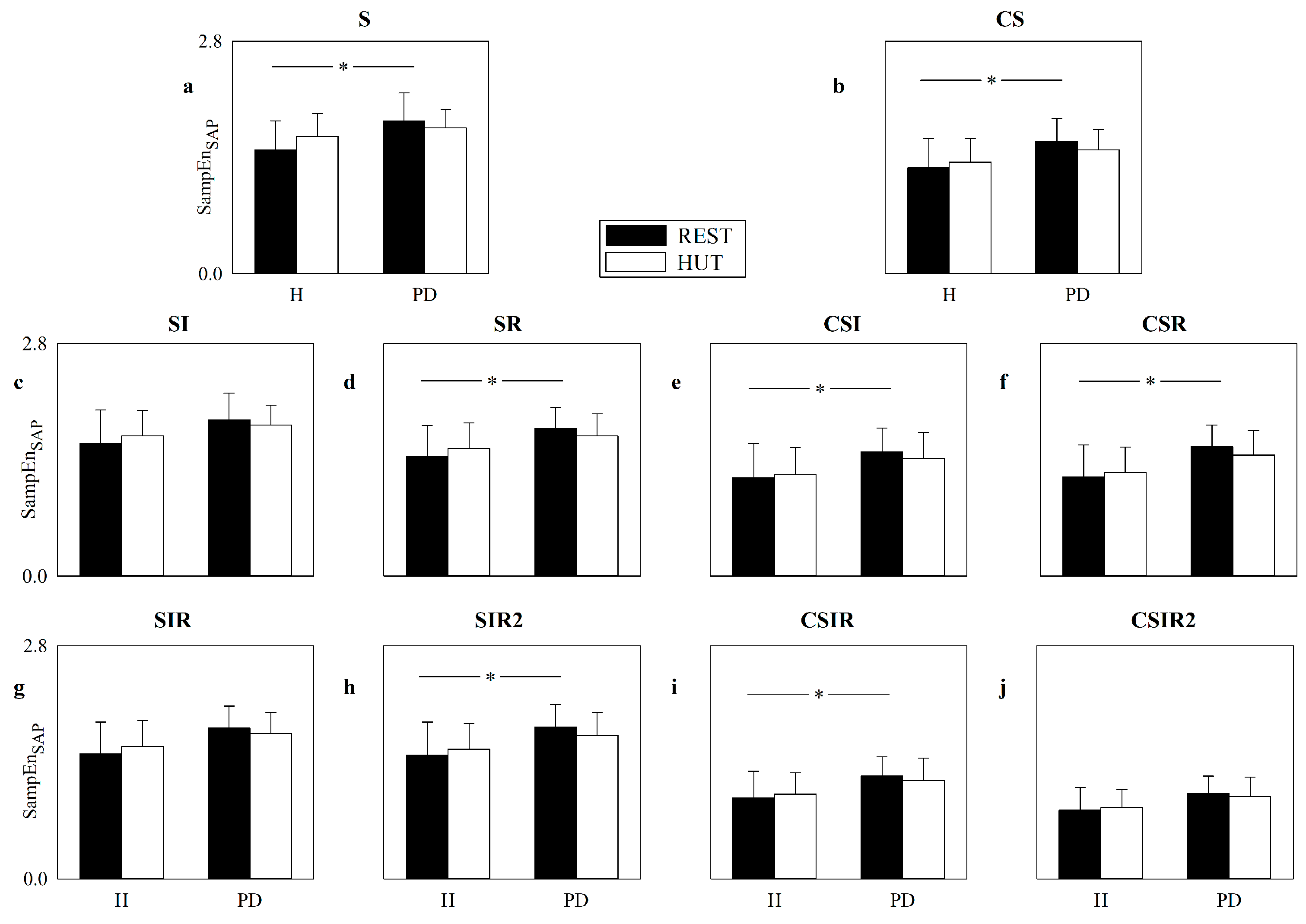
5.4. Real HP and SAP Series: Impact of Pattern Matching Strategies on SampEn
6. Discussion
6.1. On the Rationale of Transformations Favoring Pattern Matching
6.2. Strategies Increasing the Number of Matches Might Lead to Misleading Conclusions over Simulated Series
6.3. Strategies Increasing the Number of Matches Are of Limited Utility in the Assessment of Cardiac and Vascular Controls
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pomeranz, B.; Macaulay, R.J.B.; Caudill, M.A.; Kutz, I.; Adam, D.; Gordon, D.; Kilborn, K.M.; Barger, A.C.; Shannon, D.C.; Cohen, R.J.; et al. Assessment of autonomic function in humans by heart-rate spectral-analysis. Am. J. Physiol. 1985, 248, H151–H153. [Google Scholar] [CrossRef]
- Montano, N.; Gnecchi-Ruscone, T.; Porta, A.; Lombardi, F.; Pagani, M.; Malliani, A. Power spectrum analysis of heart rate variability to assess changes in sympatho-vagal balance during graded orthostatic tilt. Circulation 1994, 90, 1826–1831. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pagani, M.; Montano, N.; Porta, A.; Malliani, A.; Abboud, F.M.; Birkett, C.; Somers, V.K. Relationship between spectral components of cardiovascular variabilities and direct measures of muscle sympathetic nerve activity in humans. Circulation 1997, 95, 1441–1448. [Google Scholar] [CrossRef] [PubMed]
- Cooke, W.H.; Hoag, J.B.; Crossman, A.A.; Kuusela, T.A.; Tahvanainen, K.U.O.; Eckberg, D.L. Human responses to upright tilt: A window on central autonomic integration. J. Physiol. 1999, 517, 617–628. [Google Scholar] [CrossRef] [PubMed]
- Pincus, S.M.; Goldberger, A.L. Physiological time-seris analysis: What does regularity quantify? Am. J. Physiol. 1994, 266, H1643–H1656. [Google Scholar]
- Goldberger, A.L.; Peng, C.K.; Lipsitz, L.A. What is physiologic complexity and how does it change with aging and disease? Neurobiol. Aging 2002, 23, 23–26. [Google Scholar] [CrossRef]
- Porta, A.; Bari, V.; Ranuzzi, G.; De Maria, B.; Baselli, G. Assessing multiscale complexity of short heart rate variability series through a model-based linear approach. Chaos 2017, 27, 093901. [Google Scholar] [CrossRef] [Green Version]
- Pincus, S.M. Approximate entropy (ApEn) as a complexity measure. Chaos 1995, 5, 110–117. [Google Scholar] [CrossRef]
- Porta, A.; Baselli, G.; Liberati, D.; Montano, N.; Cogliati, C.; Gnecchi-Ruscone, T.; Malliani, A.; Cerutti, S. Measuring regularity by means of a corrected conditional entropy in sympathetic outflow. Biol. Cybern. 1998, 78, 71–78. [Google Scholar] [CrossRef]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef] [Green Version]
- Porta, A.; Gnecchi-Ruscone, T.; Tobaldini, E.; Guzzetti, S.; Furlan, R.; Montano, N. Progressive decrease of heart period variability entropy-based complexity during graded head-up tilt. J. Appl. Physiol. 2007, 103, 1143–1149. [Google Scholar] [CrossRef]
- Kaplan, D.T.; Furman, M.I.; Pincus, S.M.; Ryan, S.M.; Lipsitz, L.A.; Goldberger, A.L. Aging and the complexity of cardiovascular dynamics. Biophys. J. 1991, 59, 945–949. [Google Scholar] [CrossRef] [Green Version]
- Pincus, S.M.; Cummins, T.R.; Haddad, G.G. Heart rate control in normal and aborted-SIDS infants. Am. J. Physiol. 1993, 33, R638–R646. [Google Scholar] [CrossRef] [PubMed]
- Tulppo, M.P.; Makikallio, T.H.; Takala, T.E.S.; Seppanen, T.; Huikuri, H.V. Quantitative beat-to-beat analysis of heart rate dynamics during exercise. Am. J. Physiol. 1996, 271, H244–H252. [Google Scholar] [CrossRef]
- Porta, A.; Guzzetti, S.; Montano, N.; Pagani, M.; Somers, V.; Malliani, A.; Baselli, G.; Cerutti, S. Information domain analysis of cardiovascular variability signals: Evaluation of regularity, synchronisation and co-ordination. Med. Biol. Eng. Comput. 2000, 38, 180–188. [Google Scholar] [CrossRef] [PubMed]
- Al-Angari, H.N.; Sahakian, A.V. Use of sample entropy approach to study heart rate variability in obstructive sleep apnea syndrome. IEEE Trans. Biomed. Eng. 2007, 54, 1900–1904. [Google Scholar] [CrossRef] [PubMed]
- Lewis, M.J.; Short, A.L. Sample entropy of electrocardiographic RR and QT time-series data during rest and exercise. Physiol. Meas. 2007, 28, 731–744. [Google Scholar] [CrossRef]
- Javorka, M.; Trunkvalterova, Z.; Tonhajzerova, I.; Javorkova, J.; Javorka, K.; Baumert, M. Short-term heart rate complexity is reduced in patients with type 1 diabetes mellitus. Clin. Neurophysiol. 2008, 119, 1071–1081. [Google Scholar] [CrossRef] [PubMed]
- Viola, A.U.; Tobaldini, E.; Chellappa, S.L.; Rabello Casali, K.; Porta, A.; Montano, N. Short-term complexity of cardiac autonomic control during sleep: REM as a potential risk factor for cardiovascular system in aging. PLoS ONE 2011, 6, e19002. [Google Scholar] [CrossRef] [Green Version]
- Catai, A.M.; Takahashi, A.C.M.; Perseguini, N.M.; Milan, J.C.; Minatel, V.; Rehder-Santos, P.; Marchi, A.; Bari, V.; Porta, A. Effect of the postural challenge on the dependence of the cardiovascular control complexity on age. Entropy 2014, 16, 6686–6704. [Google Scholar] [CrossRef] [Green Version]
- Weippert, M.; Behrens, M.; Rieger, A.; Behrens, K. Sample entropy and traditional measures of heart rate dynamics reveal different modes of cardiovascular control during low intensity exercise. Entropy 2014, 16, 5698–5711. [Google Scholar] [CrossRef] [Green Version]
- Ji, J.; Li, P.; Li, K.; Wang, X.; Liu, C. Analysis of short-term heart rate and diastolic period variability using a refined fuzzy entropy method. Biomed. Eng. Online 2015, 14, 64. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Porta, A.; De Maria, B.; Bari, V.; Marchi, A.; Faes, L. Are nonlinear model-free conditional entropy approaches for the assessment of cardiac control complexity superior to the linear model-based one? IEEE Trans. Biomed. Eng. 2017, 64, 1287–1296. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Porta, A.; Bari, V.; De Maria, B.; Cairo, B.; Vaini, E.; Malacarne, M.; Pagani, M.; Lucini, D. On the relevance of computing a local version of sample entropy in cardiovascular control analysis. IEEE Trans. Biomed. Eng. 2019, 66, 623–631. [Google Scholar] [CrossRef]
- Task Force of the European Society of Cardiology and the North American Society of Pacing and Electrophysiology. Heart rate variability—Standards of measurement, physiological interpretation and clinical use. Circulation 1996, 93, 1043–1065. [Google Scholar] [CrossRef] [Green Version]
- Porta, A.; Faes, L. Wiener-Granger causality in network physiology with applications to cardiovascular control and neuroscience. Proc. IEEE 2016, 104, 282–309. [Google Scholar] [CrossRef]
- Sassi, R.; Cerutti, S.; Lombardi, F.; Malik, M.; Huikuri, H.V.; Peng, C.-K.; Schmidt, G.; Yamamoto, Y. Advances in heart rate variability signal analysis: Joint position statement by the e-Cardiology ESC Working Group and the European Heart Rhythm Association co-endorsed by the Asia Pacific Heart Rhythm Society. Europace 2015, 17, 1341–1353. [Google Scholar] [CrossRef] [PubMed]
- Magagnin, V.; Bassani, T.; Bari, V.; Turiel, M.; Maestri, R.; Pinna, G.D.; Porta, A. Non-stationarities significantly distort short-term spectral, symbolic and entropy heart rate variability indexes. Physiol. Meas. 2011, 32, 1775–1786. [Google Scholar] [CrossRef]
- Girault, J.-M.; Humeau-Heurtier, A. Centered and averaged fuzzy entropy to improve fuzzy entropy precision. Entropy 2018, 20, 287. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Zhuang, J.; Yu, W.; Wang, Z. Measuring complexity using FuzzyEn, ApEn, and SampEn. Med. Eng. Phys. 2009, 31, 61–68. [Google Scholar] [CrossRef] [PubMed]
- Shi, B.; Zhang, Y.; Yuan, C.; Wang, S.; Li, P. Entropy analysis of short-term heartbeat interval time series during regular walking. Entropy 2017, 19, 568. [Google Scholar] [CrossRef]
- Porta, A.; Castiglioni, P.; Bari, V.; Bassani, T.; Marchi, A.; Cividjian, A.; Quintin, L.; Di Rienzo, M. K-nearest-neighbor conditional entropy approach for the assessment of short-term complexity of cardiovascular control. Physiol. Meas. 2013, 34, 17–33. [Google Scholar] [CrossRef] [PubMed]
- Barbic, F.; Perego, F.; Canesi, M.; Gianni, M.; Biagiotti, S.; Costantino, G.; Pezzoli, G.; Porta, A.; Malliani, A.; Furlan, R. Early abnormalities of vascular and cardiac autonomic control in Parkinson’s disease without orthostatic hypotension. Hypertension 2007, 49, 120–126. [Google Scholar] [CrossRef] [PubMed]
- Porta, A.; Castiglioni, P.; di Rienzo, M.; Bari, V.; Bassani, T.; Marchi, A.; Takahashi, A.C.M.; Tobaldini, E.; Montano, N.; Catai, A.M.; et al. Short-term complexity indexes of heart period and systolic arterial pressure variabilities provide complementary information. J. Appl. Physiol. 2012, 113, 1810–1820. [Google Scholar] [CrossRef] [Green Version]
- Takens, F. Detecting strange attractors in turbulence. In Dynamical Systems and Turbulence; Rand, D., Young, L.S., Eds.; Springer: Berlin/Heidelberg, Germany, 1981; pp. 366–381. [Google Scholar]
- Porta, A.; Guzzetti, S.; Montano, N.; Gnecchi-Ruscone, T.; Furlan, R.; Malliani, A. Time reversibility in short-term heart period variability. Comput. Cardiol. 2006, 33, 77–80. [Google Scholar]
- Porta, A.; Casali, K.R.; Casali, A.G.; Gnecchi-Ruscone, T.; Tobaldini, E.; Montano, N.; Lange, S.; Geue, D.; Cysarz, D.; van Leeuwen, P. Temporal asymmetries of short-term heart period variability are linked to autonomic regulation. Am. J. Physiol. 2008, 295, R550–R557. [Google Scholar] [CrossRef] [Green Version]
- Porta, A.; Guzzetti, S.; Furlan, R.; Gnecchi-Ruscone, T.; Montano, N.; Malliani, A. Complexity and nonlinearity in short-term heart period variability: Comparison of methods based on local nonlinear prediction. IEEE Trans. Biomed. Eng. 2007, 54, 94–106. [Google Scholar] [CrossRef]
- Weiss, G. Time-reversibility of linear stochastic processes. J. Appl. Prob. 1975, 12, 831–836. [Google Scholar] [CrossRef]
- Theiler, J.; Eubank, S.; Longtin, A.; Galdrikian, J. Testing for nonlinearity in time series: The method of surrogate data. Phys. D 1992, 58, 77–94. [Google Scholar] [CrossRef] [Green Version]
- Schreiber, T.; Schmitz, A. Improved surrogate data for nonlinearity tests. Phys. Rev. Lett. 1996, 77, 635–638. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Liu, C.; Li, K.; Zheng, D.; Liu, C.; Hou, Y. Assessing the complexity of short-term heartbeat interval series by distribution entropy. Med. Biol. Eng. Comput. 2015, 53, 77–87. [Google Scholar] [CrossRef] [PubMed]
- Valente, M.; Javorka, M.; Porta, A.; Bari, V.; Krohova, J.; Czippelova, B.; Turianikova, Z.; Nollo, G.; Faes, L. Univariate and multivariate conditional entropy measures for the characterization of short-term cardiovascular complexity under physiological stress. Physiol. Meas. 2018, 39, 014002. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Valencia, J.F.; Bolaños, J.D.; Vallverdú, M.; Jensen, E.W.; Porta, A.; Gambus, P.L. Refined multiscale entropy using fuzzy metrics: Validation and application to nociception assessment. Entropy 2019, 21, 706. [Google Scholar] [CrossRef] [Green Version]
- Costa, M.; Goldberger, A.L.; Peng, C.K. Multiscale entropy analysis of biological signals. Phys. Rev. E 2005, 71, 021906. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Porta, A.; Faes, L.; Bari, V.; Marchi, A.; Bassani, T.; Nollo, G.; Perseguini, N.M.; Milan, J.; Minatel, V.; Borghi-Silva, A.; et al. Effect of age on complexity and causality of the cardiovascular control: Comparison between model-based and model-free approaches. PLoS ONE 2014, 9, e89463. [Google Scholar] [CrossRef]
- Faes, L.; Nollo, G.; Porta, A. Information-based detection of nonlinear Granger causality in multivariate processes via a nonuniform embedding technique. Phys. Rev. E 2011, 83, 051112. [Google Scholar] [CrossRef] [Green Version]









© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Porta, A.; Valencia, J.F.; Cairo, B.; Bari, V.; De Maria, B.; Gelpi, F.; Barbic, F.; Furlan, R. Are Strategies Favoring Pattern Matching a Viable Way to Improve Complexity Estimation Based on Sample Entropy? Entropy 2020, 22, 724. https://doi.org/10.3390/e22070724
Porta A, Valencia JF, Cairo B, Bari V, De Maria B, Gelpi F, Barbic F, Furlan R. Are Strategies Favoring Pattern Matching a Viable Way to Improve Complexity Estimation Based on Sample Entropy? Entropy. 2020; 22(7):724. https://doi.org/10.3390/e22070724
Chicago/Turabian StylePorta, Alberto, José Fernando Valencia, Beatrice Cairo, Vlasta Bari, Beatrice De Maria, Francesca Gelpi, Franca Barbic, and Raffaello Furlan. 2020. "Are Strategies Favoring Pattern Matching a Viable Way to Improve Complexity Estimation Based on Sample Entropy?" Entropy 22, no. 7: 724. https://doi.org/10.3390/e22070724