2.1. Spectral Catalogs
At the beginning of our research, we mainly worked in the study of a large set of observed sources, candidates to be classified as stars in the post-AGB phase of evolution [
18]. In this first approach, we chose as templates the spectra of luminosity level I from the reference catalog used at that time in the manual MK classification method [
19].
The results of this initial development showed that, to deal with the whole problem of MK classification of stars, it is highly advisable to compile a solid and robust catalog that provides good resolution for all target spectral types and as many classes of luminosity as possible. Consequently, to design and develop intelligent tools for the rationalization of the manual classification process, we have built a digital database that includes a large sample of optical spectra from public online catalogs: The D. Silva and M. Cornell optical spectral library, now extended to all luminosity levels [
19], the catalog of observations of G. Jacoby, D. Hunter and C. Christian [
20], and the digital spectra collected by A. Pickles [
21].
We decided to add a broader set of spectra to facilitate the optimal convergence and generalization of the artificial neural networks, since the training patterns sets notably influence the performance of the models. For this purpose, we selected an additional database of 908 spectra obtained with the ELODIE spectrograph at the French observatory in Haute-Provence; these spectra present greater coverage of MK spectral subtypes and luminosity levels for metallicities ([Fe/H]) from −3.0 to 0.8 [
22].
Before applying this final database to the design of automatic classification systems, the classification experts who collaborate in this research visually studied, morphologically analyzed, and contrasted the values of the spectral parameters for the four above-mentioned catalogs; for that purpose, they used the information available in public databases such as SIMBAD [
23]. In this way, those spectra that did not satisfy our quality criteria were eliminated: a lot of noise, significant gaps in regions with an abundance of classification indices (e.g., some early types from Pickles), very high or very low levels of metallicity (e.g., some spectra from Silva library with values of [Fe/H] inferior to −1), spectra where MK classifications widely differ from one source to another (e.g., several Jacoby’s spectra), and the spectral subtypes and/or luminosity levels with very few representatives (e.g., the entire spectral type O, unfortunately).
Afterwards, the remaining spectra were analyzed by means of statistical clustering techniques, also discarding those that could not be placed into one of the groups obtained with the different implemented algorithms (K-means, ISODATA, etc.). Because of this complete selection process, we obtained a main catalog with 258 spectra from the libraries of Silva (27), Pickles (97) and Jacoby (134), and a secondary catalog with 500 spectra extracted from the Prugniel database.
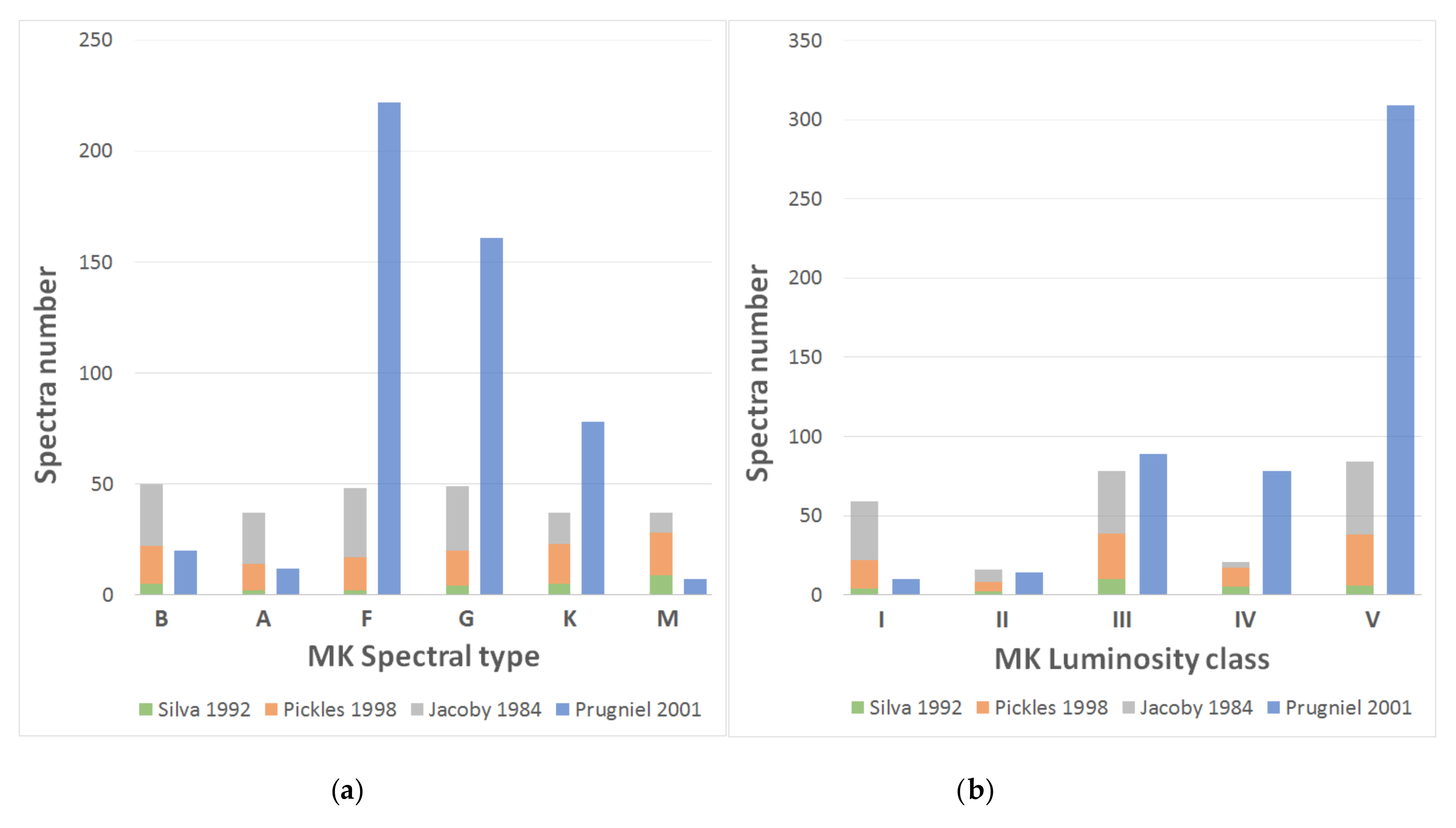
Figure 1 shows the final distribution of spectral types and luminosity classes of the reference catalog. The main catalog (Silva, Pickles, and Jacoby) is quite homogeneous in relation to the number of spectra of each type, but it presents some deficiencies in the luminosity classes (II and IV); in the secondary final catalog (Prugniel), most spectra belong to intermediate spectral types (F–K) and to luminosity class V.
All the spectra of our final database were analyzed, obtaining the measurement of some representative parameters such as spectral lines of absorption or molecular bands, so that for each spectral type the typical values were delimited. In most of our implementations, the unclassified spectra that are supplied to the system will be compared with this numerical characterization of the reference spectra; moreover, they are useful to determine the rules of the expert systems as well as to train and validate the neural models.
More than ten years ago, our research group started working on the Gaia Project, the astrometric cornerstone mission of the European Space Agency (ESA) that was successfully launched and set into orbit in December 2013. Gaia is an astrometric mission that measures parallaxes and movements of the stars in the Milky Way, and also includes a spectrophotometric survey of all objects in the sky up to a visible magnitude of approximately 20.5. The scientific work to prepare the mission archive is organized around the Data Processing and Analysis Consortium (DPAC) where we lead the Outlier Analysis Working Package (WP) and collaborate in others [
24,
25,
26]. In the context of DPAC, we have been testing the performance of different ANNs, both unsupervised and supervised, for classification and parameterization of astrophysical properties of the sources. In particular, we have gained experience in the problem of parameterization of stellar atmospheric properties using the spectra of Gaia RVS instrument [
27]. This instrument was mainly built to measure the radial velocity of stars in the near infrared CaII spectral region, but it is also a most helpful tool to estimate the most important stellar APs: effective temperature (Teff), logarithm of surface gravity (log g), abundance of metal elements with respect to hydrogen ([Fe/H]), and abundance of alpha elements with respect to iron ([alpha/Fe]). The results obtained have encouraged us to try those same techniques by applying them to the stellar classification problem in the classic MK system.
2.2. Spectral Indices and Sensitivity Analysis
The different types of stars have different observable peculiarities in their spectrum, which are commonly studied to determine the MK classification and also to collect relevant information about stellar properties such us temperature, pressure, density, or radial velocity. Most of these typical spectral features can be isolated by the definition of spectral classification indices [
3].
Although there are some classical indices included in the most important classification bibliographical sources, the set of spectral parameters used in this project corresponds to the main features that the spectroscopic experts of our group visually study when trying to obtain the manual classification of the spectra. Most of these spectral indices are grouped into three general types, Intensity (I), Equivalent Width (EW), or Full Width at Half Maximum (FWHM) of absorption and emission spectral lines (He, H, Fe, Ca, K, Mg, etc.); depth (B) of molecular absorption bands (TiO, CH, etc.); and relations between the different measures of the absorption/emission lines (H/He, CaII/ H ratios, etc.).
Once the set of spectral indices for each particular classification scenario is determined, their values are obtained by applying specific morphological processing algorithms primarily based on the calculation of the molecular bands energy and on the estimation of the local spectral continuum for the absorption/emission lines. These algorithms allow for the extraction of a large number of relevant spectral markers that can be included as classification criteria, although only a small subset of them will be in the final selection of indices. To carry out a study as exhaustive as possible, we initially measured some peculiar parameters that are not normally included in the rules used in the traditional classification process. Likewise, the equivalent width, intensity, and width at half maximum are measured for each spectral line, even when they are not included in the typical classification criteria for a particular context.
Among all the classification criteria collected in the preliminary study of the problem (those indicated by the classification experts as well as those found in the bibliography), a set of 33 morphological features was initially selected. We have contrasted our own classification criteria with those included in the different bibliographic sources, with special emphasis on the study of Lick indices [
28].
The suitability of this selected subset of spectral indices was verified by performing a complete sensitivity analysis through the spectra included in the chosen reference catalogs. Thus, the value of each chosen morphological feature was estimated for each spectrum of the reference main catalog (Silva 1992, Pickles 1998, Jacoby 1984); then, these values were ordered so that we can examine their variation with the spectral type and luminosity class. Thanks to this meticulous study, it was possible to establish the real resolution of each index, while delimiting the different types of spectra that it is able to discriminate.
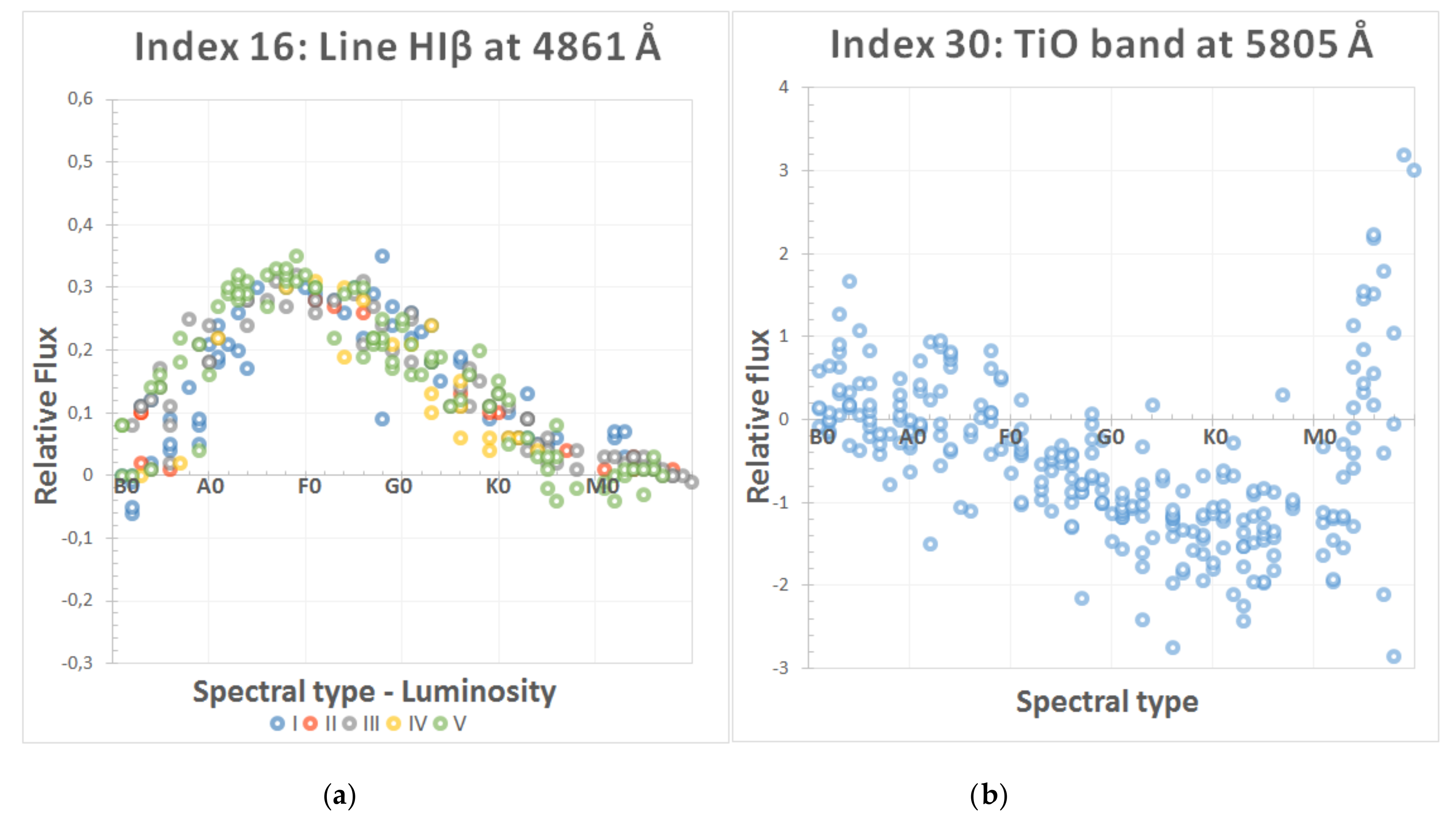
Figure 2 shows two examples of the methodology followed to evaluate the behavior of some of the most significant spectral indices. First, a spectral index (intensity of line Hiβ at 4861 Å) is included in the final selection of parameters for the MK classification because of its excellent performance in the template spectra. Second, we also include an index that was discarded (depth of molecular band TiO at 5805 Å) because its real behavior was not completely congruent with the theoretical one (in fact, it presents similar values for very different spectral types, such as B and M). A more detailed description of this analysis procedure can be found in [
29].
Table 1 lists the most relevant results of our sensitivity study, contrasting them with the theoretical classification capability indicated by the experts. Parameters 1–25 constitute the final set of proper indices that are considered to be able to address the MK classification, as they present a clear and reproducible pattern of discrimination between spectral types and/or luminosity classes in the analysis on the 258 spectra from the main reference catalog. The first column contains the definition of each index (an asterisk indicates parameters that are not usually contemplated in the manual classification); the second column shows the types, subtypes, and levels of luminosity that each parameter could potentially discriminate; and the third column specifies the types/classes that it is actually able to delimit, according to the performance achieved in the reference catalogs. The indices highlighted in blue have necessarily been excluded in the processing of the spectra of the secondary database (Prugniel 2001), since they correspond to morphological characteristics that are out of the spectral range of this catalog (4100–6800 Å) and are, therefore, impossible to estimate; unfortunately, this limitation has an unavoidable impact on the performance of some of the implemented techniques.
During the successive tuning processes carried out at this stage, eight indices were excluded from the 33 morphological characteristics of the initial selection. In some cases, as shown in
Table 1, the actual found resolution and the theoretical one differed significantly, since they cannot separate the spectral types that, according to experts and bibliographic sources, they should be able to.
The final set of selected spectral indices is included in the classification criteria implemented by means of rules for the expert systems, and in the elaboration of the training and validation patterns for neural models. However, in some specific cases, we have also used certain interesting spectral regions or even the full range of wavelengths for that purpose. Besides, in some implementations, this set of parameters has been reduced by means of another adjustment process based on techniques that allow us to minimize and optimize the number of indices necessary to obtain the MK classification, such as principal component analysis (PCA) or clustering algorithms (K-means, Max-Min, etc.).
2.4. Artificial Neural Networks
Neural networks are an ideal technique for solving classification problems, especially for their ability to learn by induction and their capability to discover the intrinsic relationships that underlie the data processed during their learning (training phase). One of the major advantages of this AI technique is its generalization capability, which means that a trained network could classify data of a similar nature to those in the training set without any previous presentation.
At this point in our development, we again used spectra from the main guiding catalog, originating from the same libraries that were applied to design and implement the knowledge-based systems’ reasoning rules [
4,
5,
29]. By following this design strategy, the applied techniques could easily be compared, since their design principles and bases are the same.
Although it is possible to use all the available data for the learning phase, our experience in previous works advise us to split the available spectra into three sets, dedicating approximately 50% of them to the training, 10% to validating the learning, and 40% to testing the implemented networks. In the design of some of the neural networks, the spectra of the secondary catalog have also been used, because they allow us to evaluate the behavior of the networks in a sample with a greater variety of spectral features; these spectra are real, not estimations, and are affected by factors such as interstellar reddening or atmosphere distortion effects. The detailed distribution of the spectra sets is shown in
Table 2.
The spectral analyzer, designed according to the knowledge-based system approach, is equipped with functions that allow it to obtain automatically the training, testing, and validation patterns presented to the neural networks. In most cases, neural networks designed for spectral classification have been trained and tested primarily with input patterns that include the measurement of the 25 spectral features obtained after performing the sensitivity analysis (Indices 1–25 in
Table 1).
Since we did not previously select the relevant parameters per spectral type or luminosity class, most neural models that were implemented count 26 units in the input layer (25 for the selected indices and 1 additional neuron, the so-called teaching input, for the supervised training models). On the other hand, all networks that use spectra from the secondary catalog (Prugniel 2001) only have 16 input patterns, since this database does not cover the entire spectral range in which the 25 selected indices are located. However, in some cases, we have also implemented networks that use a subset of spectral characteristics, with the objective of analyzing the influence of different sets of parameters in obtaining the MK classification. Furthermore, in some particular designs, we have used input patterns representing the real spectral flux in specific regions of wavelengths, which means that full spectral areas are provided to the neural network so that it is capable of extracting the relevant information on its own.
We started our development by scaling the spectra of every catalog to 100 at wavelength 5450 Å to obtain normalized values that are adapted to fluxes of the reference catalogs. We then calculated the value of the 25 spectral parameters in order to build the pattern sets. There was no need to cover the full spectral range, merely the range 3900–7150 Å, which is why the applied template spectra cover several spectral ranges. It is perfectly possible for the sampling frequency to differ according to the catalog. What happens is that the analyzer searches the lines and bands in a determined spectral area and then calculates the catalog resolution by means of a computational algorithm.
As soon as the spectral analyzer has gathered the input values, these values should be normalized and presented to the neural networks. The inputs were standardized by means of a contextualized normalization, which allows us to normalize the values in the [0, 1] interval and adequately scale and center each parameter’s distribution function. We assigned a lowest (
X1) and a highest value (
X2) to each classification index, establishing that 95% of the values lie between these two values; this provides us with constants
a and
b, which can be determined for each spectral parameter, according to values
X1 and
X2:
At the present day, there are many models of artificial neural networks with different design, learning rules, and outputs. We have selected different architectures to address the automatic classification of optical spectra, carrying out the training process with both supervised and unsupervised learning algorithms.
In particular, we have designed backpropagation networks (multi-layer architecture with supervised learning), SOM networks (self-organized maps with grid architecture and unsupervised learning) [
24,
25,
33,
34], and RBF networks (architecture in layers and hybrid learning) [
35]. We have also analyzed some variants of these general network types (e.g., BP momentum), to decide the networks with a best performance in determining the MK classification. In the same way, we have studied each network behavior when using the different possible topologies (number of layers, nodes of the intermediate layers, etc.). As a preliminary step, we analyzed the ability of each of these three models to discriminate between consecutive types individually, corresponding to early, intermediate, and late stars. This initial experimentation certainly makes it easier to determine which network best fits each couple of successive spectral types.
We have used the SNNS v4.3 simulator (Stuttgart Neural Network Simulator) [
36] for the design and training of classification networks. This software tool incorporates an option to convert directly the trained networks to C-code, which has been used in our work to incorporate the implemented networks into the global analysis and classification system for stars.
2.4.1. Learning Algorithms
Our research has applied three different backpropagation (BP) learning algorithms for its initial developments: standard backpropagation, enhanced backpropagation (with a momentum term and flat spot elimination), and batch backpropagation (the weight changes are summed over each full presentation of all the training patterns).
In a first phase of experimentation, we have designed neural networks using the above-mentioned BP algorithms for the spectral types from B to M (type O was previously discarded due to its lack of presence in the reference catalogs). As for topology, classification networks have an input layer with 25 neurons (1 per each spectral index), one or more hidden layers, and an output layer with six units (1 for each MK spectral type). Since the backpropagation learning algorithm is a supervised one, it is necessary to provide the network with an extra unit (the teaching input) for each input pattern so that it can calculate the error vector and appropriately update the synaptic weights of its connections.
In simulated systems, the most commonly used design strategy for configuring intermediate layers is to try to simplify them as much as possible, including the smallest number of neurons in each hidden layer, since each extra layer would involve a higher processing load in the software simulation. Thus, following this strategy, we have designed networks with different topologies, starting with simple structures and progressively increasing both the number of hidden layers and the number of units included in them (25 × 3 × 6, 25 × 5 × 6, 25 × 10 × 6, 25 × 2 × 2 × 6, 25 × 5 × 3 × 6, 25 × 5 × 5 × 6, 25 × 10 × 10 × 6, 25 × 3 × 2 × 1 × 6, 25 × 5 × 3 × 2 × 6, and 25 × 10 × 5 × 3 × 6). During the training, we updated the weights in topological order (input, hidden, and output layers). We opted for a random initiation of the weights with values from −1 to 1. We also modified the total training cycles, the validation frequency, and the learning parameters values (η, μ and flat) through the learning stage of the various implemented topologies.
Kohonen self-organized map unsupervised networks are unique in that they build preservation maps of the training data topology, where semantic information is transmitted by the location of a unit [
33].
With a similar strategy to that of feed-forward nets, we have tested several Kohonen maps by grouping the MK spectral types into the same three sets (B-A, F-G, K-M). The SOM neural models do not validate the learning progress, so the validation patterns were added to the training dataset. In these networks, we have deliberately introduced another spectral type for every pair of consecutive types, in order to make it easier for the network to cluster the data more efficiently, contrasting the target spectra with very different ones in terms of morphology. Hence, this extra spectral type was selected to be as separate as possible from the spectra of each group, that is, we chose type M for early types and type B spectra for late and intermediate ones.
The input patterns of the Kohonen networks were also built by using the 25 essential spectral features shown in
Table 1. In the learning phase of the designed networks, the total cycles and the learning parameters were adjusted (h(t), r(t), decrease factor for h(t), and decrease factor for r(t)).
The calculation of the chemical compositions or abundances of stellar spectra, and by extension MK classifications, could be also considered as a nonlinear approximation problem in which there are data affected by noise, and even the absence of data in the series occurs in some situations. The classical resolution strategy consists in performing a functional regression, which implies the determination of the specific function that best expresses the relation between the dependent and independent variables. In the case of RBF neural networks, it is not necessary to make any assumptions about the functions that relate outputs to inputs, since their basic principle is to center radial-based functions around the data that need to be approximated. Unlike MLP networks, the typical architecture of RBF networks is based on a feed-forward model composed strictly of three layers: an input layer with n neurons, a single hidden layer with k processing units, and a layer of output neurons [
35].
We have designed RBF networks to obtain the different levels of classification in the MK system and, using again the simplification strategy of the network structure, we have considered the configurations 25 × 2 × 6, 25 × 4 × 6, 25 × 6 × 6, and 25 × 8 × 6.
After repeatedly trying the three described neural schemes for all the spectral types, we carefully chose the best network of each type so as to contrast their performance and determine which would be the best choice at the different scenarios of classification. The best implemented networks were studied by analyzing their results for the spectra of the test set.
The backpropagation (trained with enhanced learning algorithm) and RBF networks obtain a similar overall performance, 96% (0.96 ± 0.050) and 95% (0.95 ± 0.056), respectively (both intervals calculated for a statistical confidence level of 0.99). The BP network solves the problem better for some spectral types (F, K, M), whereas for other types (A) the RBF is a preferable option. However, the SOM maps obtained an inferior performance, about 68% (0.68 ± 0.117), in the best situations (networks trained with small decrease factors). These results are probably a consequence of the size and distribution of the training spectra, as these are not supervised networks and they need to make the clustering autonomously, so that they require a training dataset that is large enough to be able to abstract similarities and properly group the inputs.
As for the validation set, BP and RBF networks trained with a validation set of spectra present a higher success rate than the same networks trained without it. It is clear that the cross-validation technique influences the weights and allows the network to correct the weights dynamically during the training process and, therefore, improve the learning process.
Finally, the different topologies that were tested for each supervised learning algorithm (feed-forward and RBF) do not significantly affect the final performance of the network. However, we obtained the best results with a 25 × 5 × 3 × 6 backpropagation momentum network and with a 25 × 4 × 6 RBF network. SOM networks with a higher number of units in their competitive layer present a higher success rate; in fact, the networks designed with few units in the competitive layer (fewer than 12) are not capable of clustering the data properly.
Once we know the network with the best performance for each pair of spectral types, we are better able to propose neural models to undertake the complete MK classification process.
2.4.2. ANN Models for Two-Dimensional MK Classification
The whole MK spectral classification includes the estimation of the spectral subtype and the luminosity class of the stars. Therefore, to carry it out completely, we here propose the implementation of several neural models based on two different design philosophies: classification based on a global network and classification structured in levels.
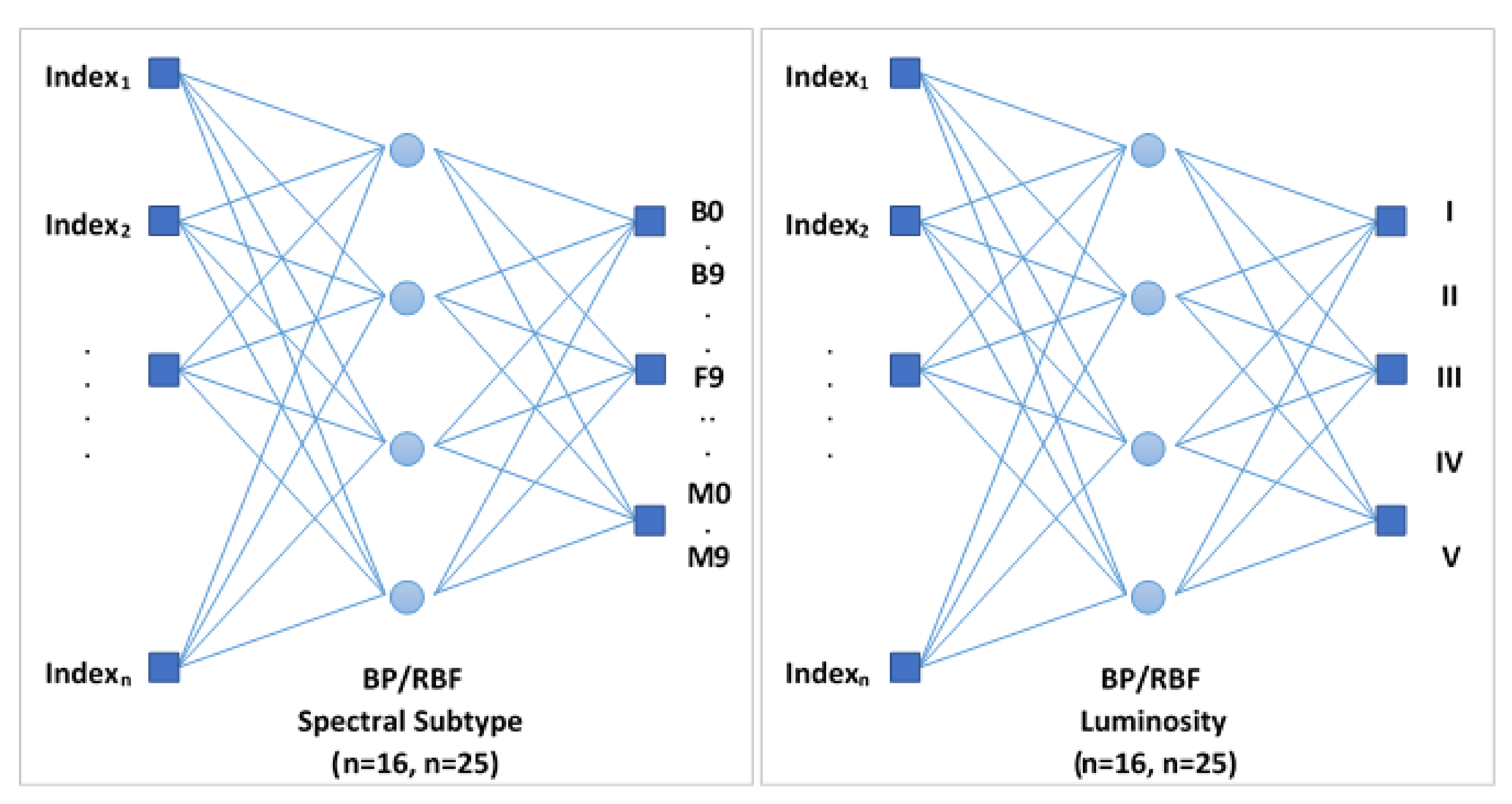
The first method proposed to obtain the whole MK classification is based on the design of two global artificial neural networks that estimate simultaneously and independently the spectral subtype and the luminosity class of the stars.
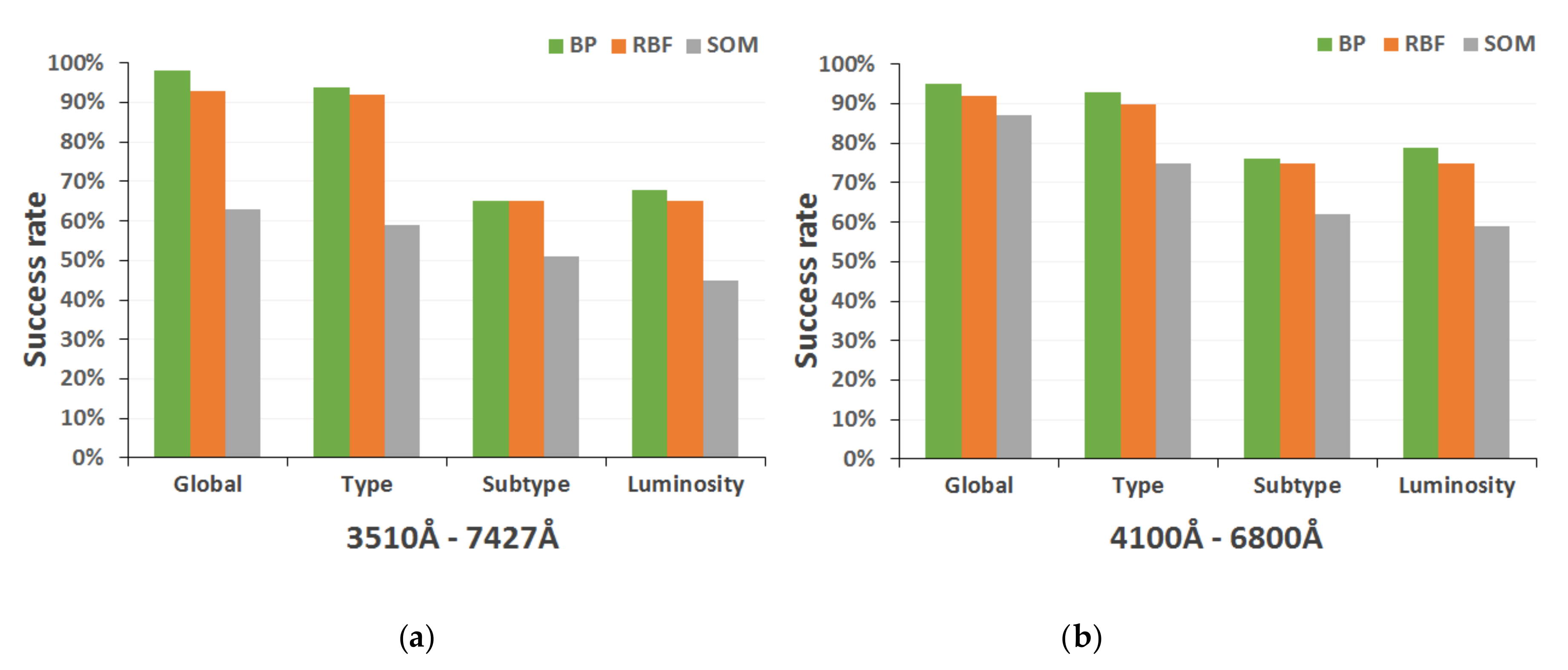
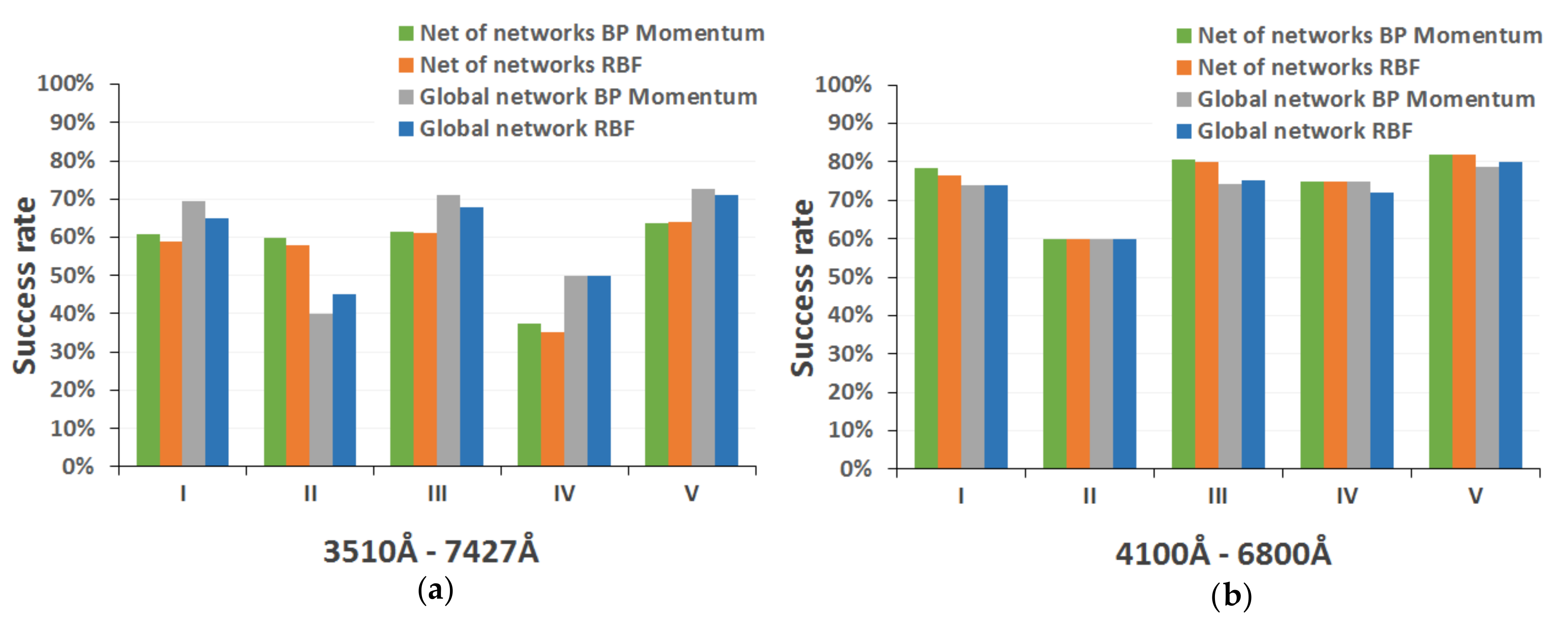
In this way, this global networks include only BP and RBF neural structures, since SOM architectures were discarded because they obtained more modest results during previous experimentation. In the design of the networks, we implemented models that only support the 16 spectral indices present in the range 4100–6800 Å of the secondary catalog, and another alternative networks that accept as input the 25 spectral parameters of the full range (3510–7427 Å, corresponding to the main guiding catalog).
Figure 4 illustrates the conceptual design of this first proposed model.
Our second strategy to accomplish the whole MK classification is based on a combination of the networks described in the previous sections, properly interconnected; specifically, we use those that have obtained a higher performance for each level of spectral classification (global, spectral type, spectral subtype, and luminosity) during the previous evaluation phase of the different neural configurations. These networks are now organized in a tree-like composition similar to the reasoning scheme of the previous designed knowledge-based systems [
29].
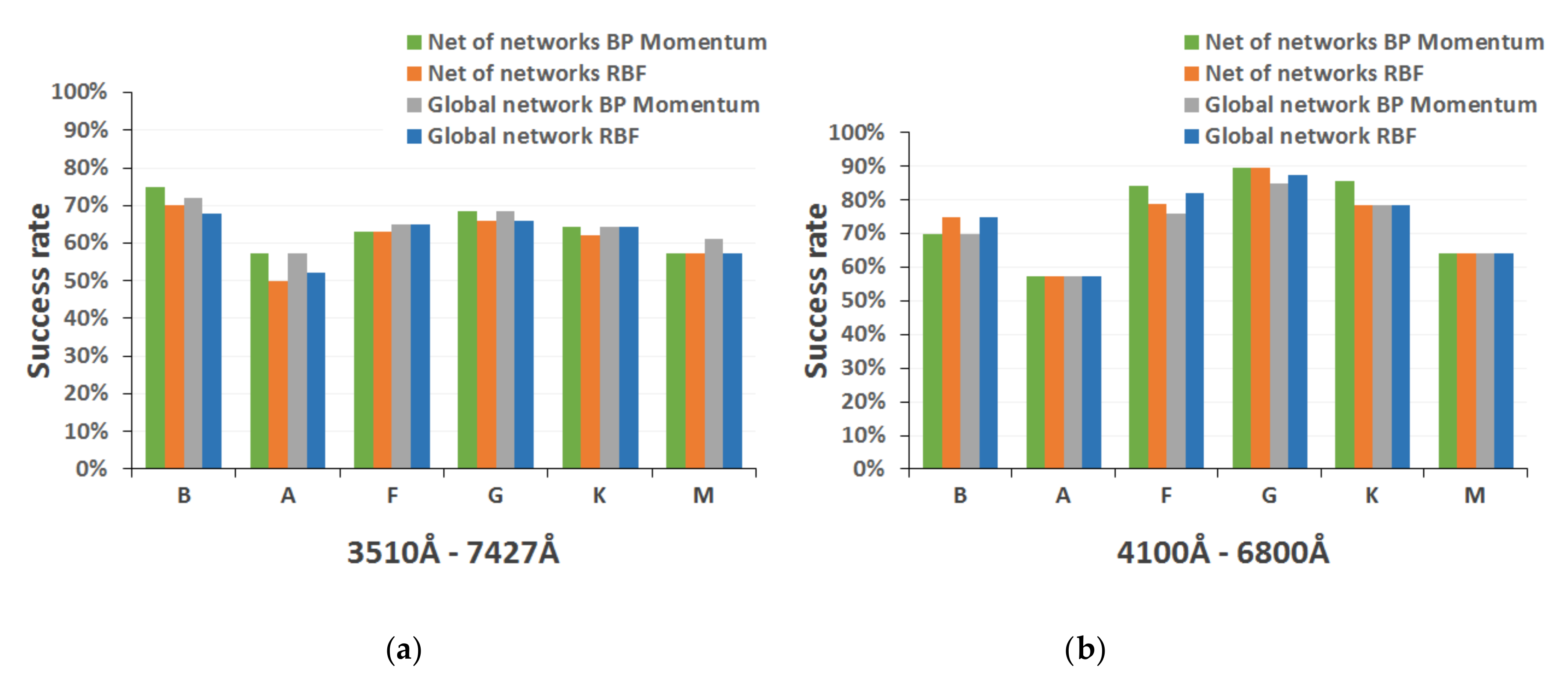
In this way, BP (specifically networks trained with the backpropagation momentum algorithm) and RBF are implemented again, and they also accept as input both the 25 spectral indices belonging to the range of the main reference catalog and the 16 included in the most restrictive range of the secondary catalog.
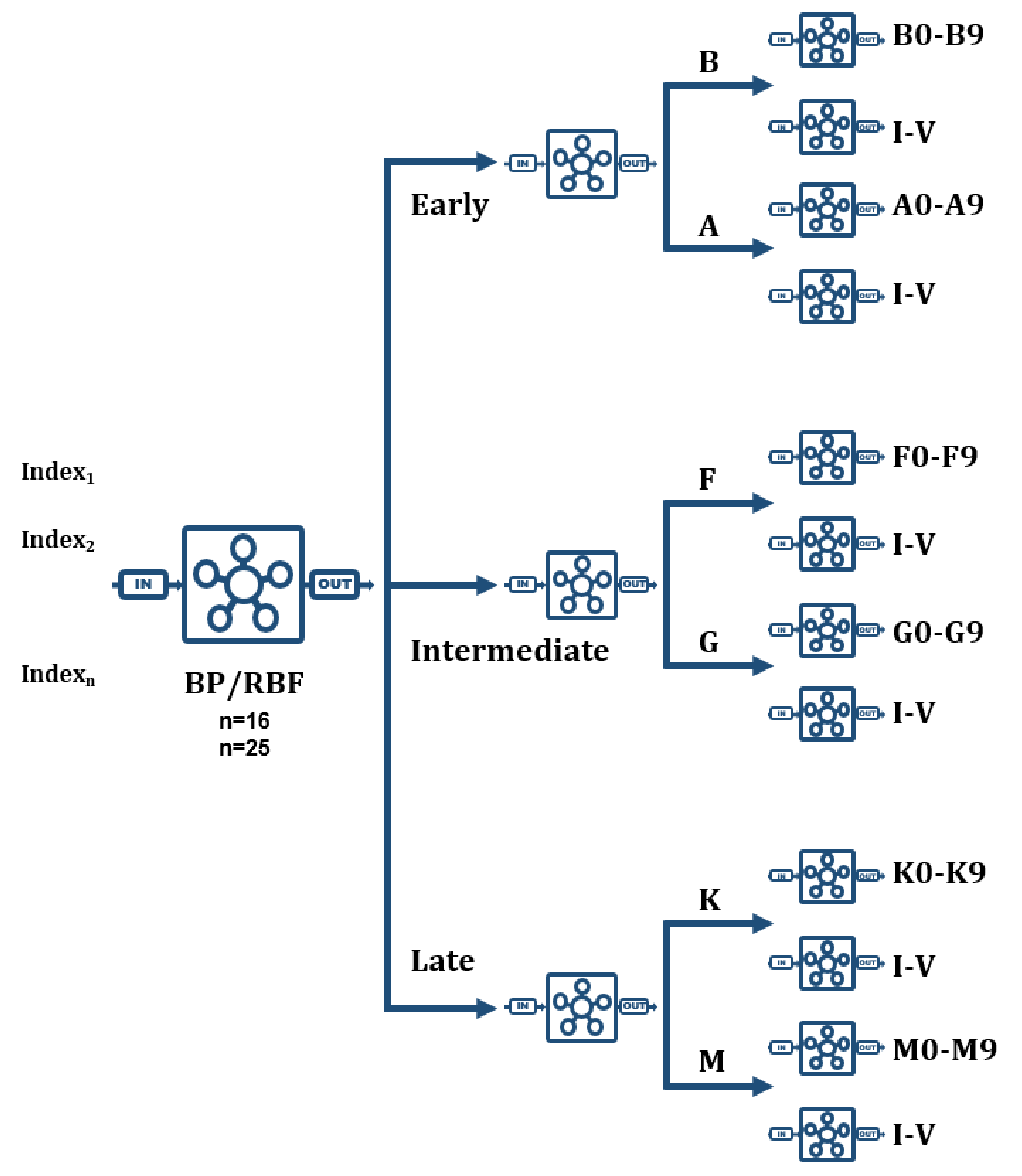
Regardless of the learning algorithm and the spectral range, the MK classification net of networks is formed by a first level BP/RBF network that decides the global classification, that is early, intermediate, or late star; a second level made up by three different networks that classify each previous pair of spectral types; and a third level formed by twelve networks, two for each spectral type (B, A, F, G, K, and M), so that one of them is responsible for establishing the specific subtype (0–9) and the other one appropriately determines the luminosity class (I–V) depending on the specific estimated spectral type.
When implementing this tree structure in C++, the communication between the different classification levels was arranged appropriately, so that the networks at each level can decide which network in the next level send the spectra to and direct them towards it accompanied by a partial classification and a probability estimation. In some specific cases, it will be necessary to send them to two different networks, especially with spectra at the boundary between two consecutive spectral types, for example B9A0 or G9K0.
Figure 5 shows a conceptual scheme of this second strategy.
Table 3 lists the different topologies selected in the two alternative strategies formulated to obtain the complete MK classification, as well as their performance for test spectra.
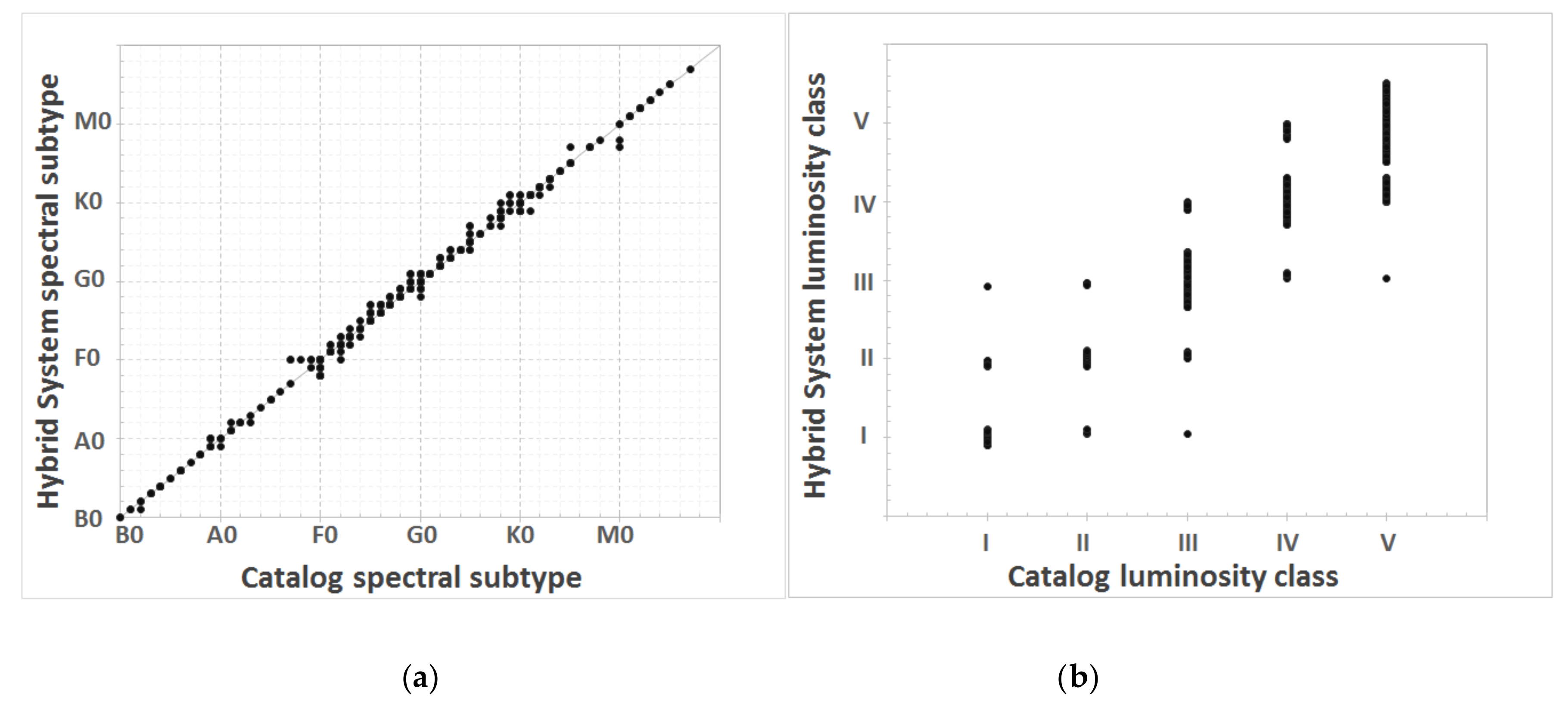
The classification results obtained with the different implemented methods will be now shown through the interface of the spectral analysis application. In the case of neural networks, besides the two-dimensional MK classification in spectral subtype and luminosity class, we also provide a probability that somehow informs about the quality of the offered answers, i.e., the network confidence in its own conclusions. In those cases, where the network output is ambiguous, falling within the range of non-resolution ([0.45–0.55]), two alternative classifications will be provided, each of them supported by their corresponding probability.
2.5. Final Approach: Hybrid System
The increasing complexity and sophistication of modern information systems clearly indicates that it is necessary to study the suitability of each technique at our disposal to develop adequate and efficient solutions, as we have done in the analysis presented in this paper.
The hybrid strategies are mainly based on the integration of different intelligent methods (fuzzy logic, evolutionary computation, artificial neural networks, knowledge-based systems, genetic algorithms, probabilistic computation, chaos theory, automatic learning, etc.), in a single robust system that explores their complementarities with the objective of achieving an optimal result in the resolution of a specific problem [
37]. In this way, hybrid systems combine different methods of knowledge representation and reasoning strategies in order to overcome the possible limitations of their integrated individual AI techniques, and increase their performance in terms of exploiting all available knowledge in an application field (symbolic, numerical, inaccurate, inexact, etc.) and, ultimately, offer a more powerful search for answers and/or solutions.
Although there are several possibilities for the integration and cooperation between the different components of the hybrid systems, the conclusions of our previous experience with the different individual techniques, naturally point to a hybrid modular architecture for the automation of the MK classification. Our proposal would be made up of both symbolic (knowledge-based systems) and connectionist (neural networks) components, combined in a single functional hybrid system that operates in co-processing mode.
The methods with a more satisfactory performance during the previous experimentation stage were directly transferred from their respective development environments to a single hybrid system developed in language C ++.
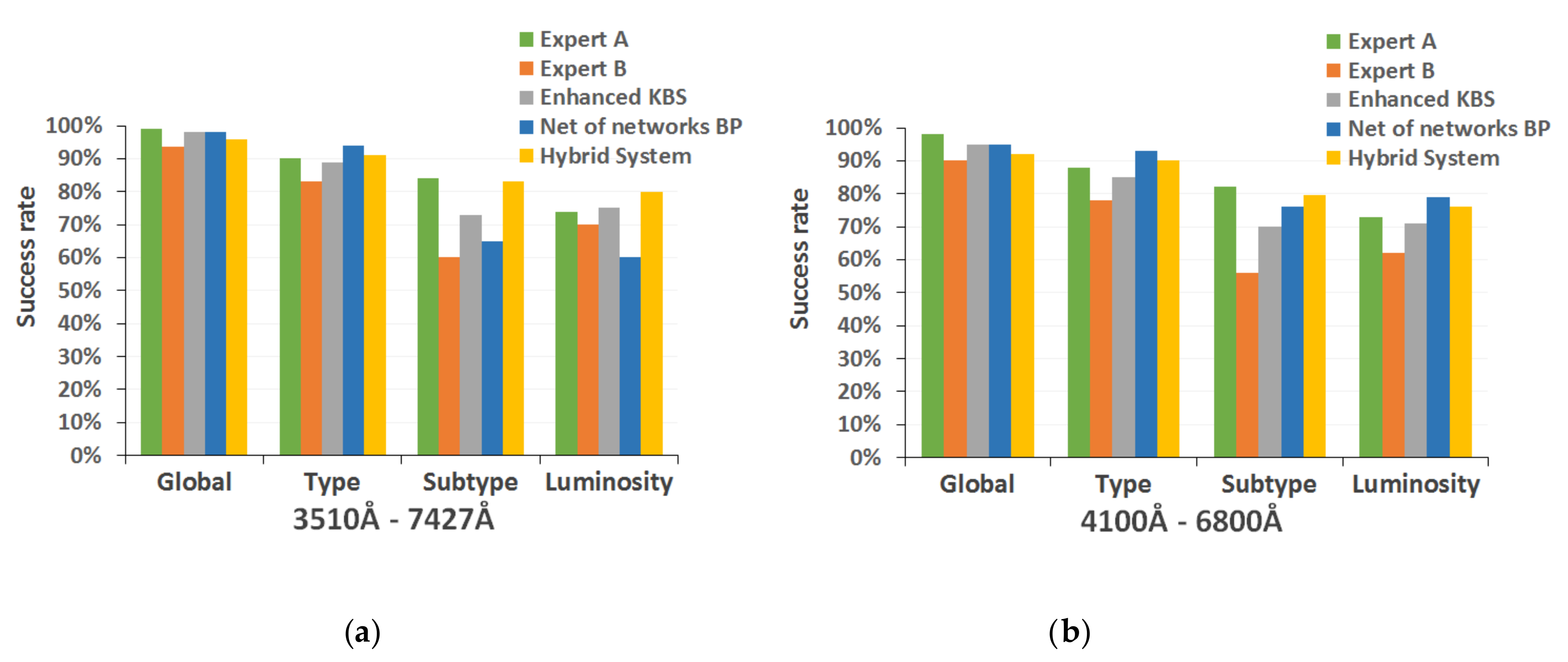
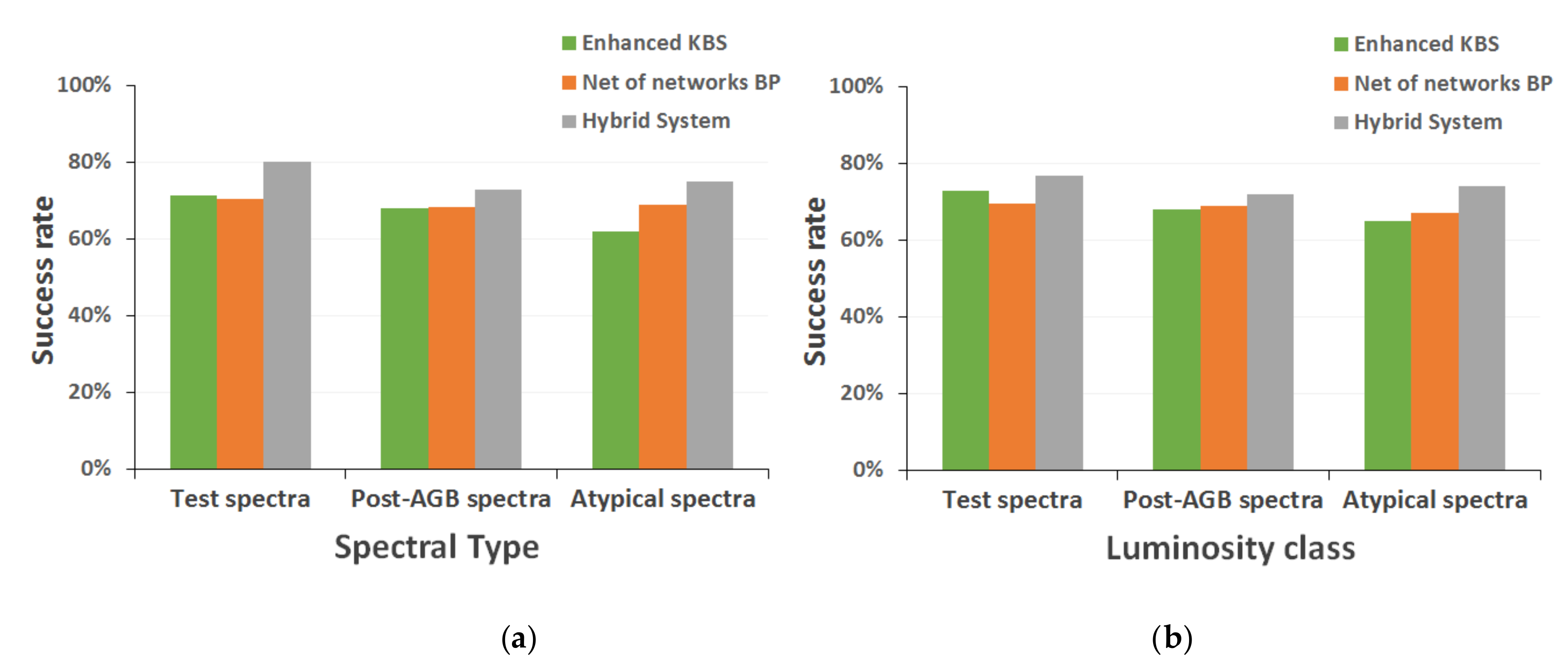
In this global system, it will now be possible to perform the spectral classification from two different perspectives: separately with each of the individual techniques, obtaining a set of isolated predictions that the user will be responsible for analyzing to arrive at a compromise solution; or initiating a combined classification process that automatically invokes the most efficient methods of each implemented technique (expert systems, backpropagation net of networks, RBF global network, etc.) and finally presents the user a set of answers accompanied by an associated probability, making possible a quick evaluation of the conclusions quality. In this second classification strategy, the system itself is responsible for analyzing the results of each technique, grouping them together and providing a summary, so that it is possible to offer better conclusions at the same time that we grant the automatic procedure of some degree of self-explanation.
Based on the experience acquired during the study phase, the experts assigned to each different technique a set of probability values according to its resolution capacity in the classification of the spectra belonging to each spectral type or luminosity class. Then, when the hybrid strategy is launched, the different optimal classifiers must combine the probability of their respective conclusions (derived from the stellar classification process) with the numerical value that they have associated by default, and which is indicative of the grade of confidence of their estimations for a specific spectral type or luminosity class.
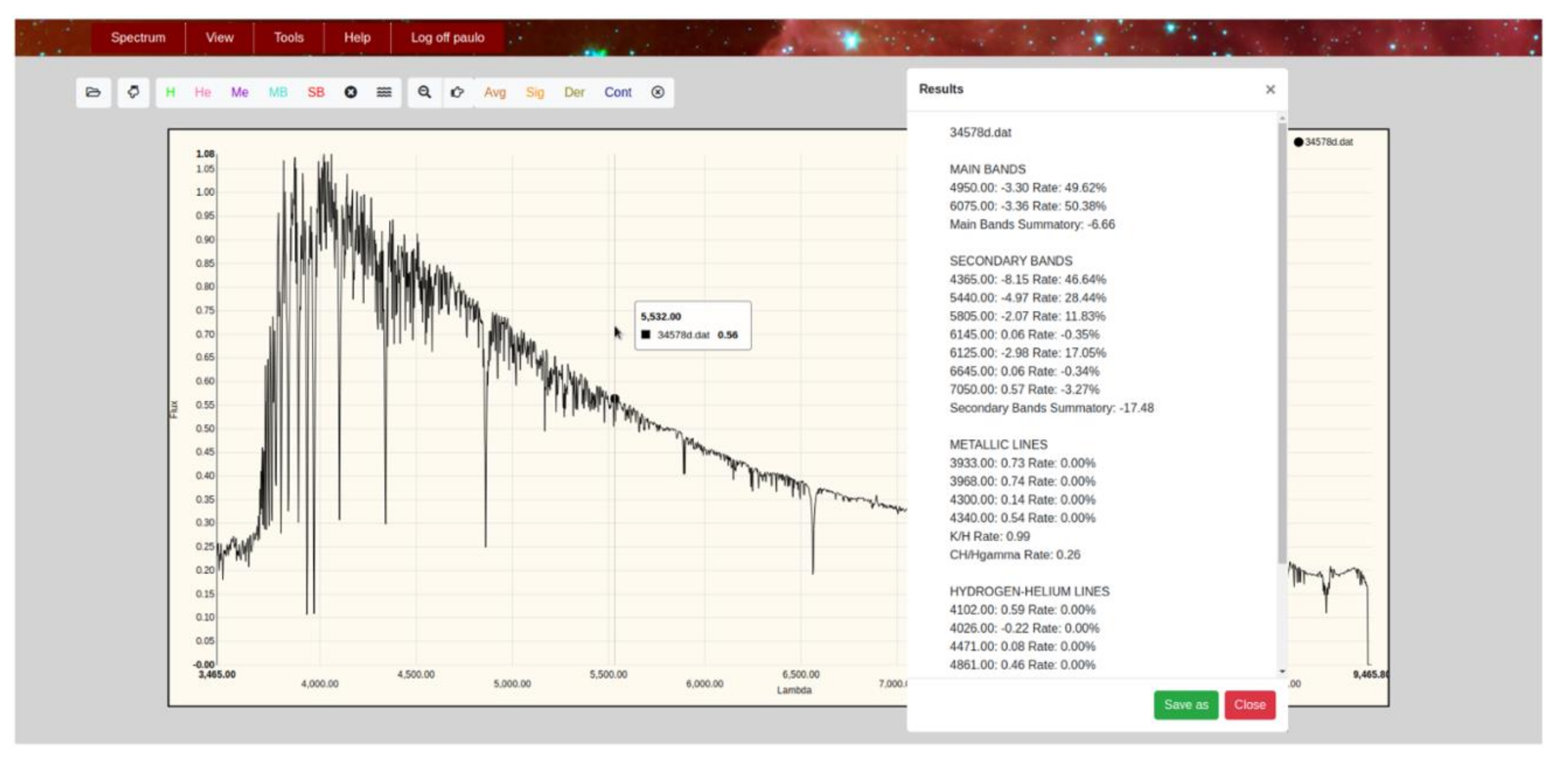
Figure 6 shows in the hybrid system interface the results obtained in a specific classification assumption when selecting the option based on the described hybrid approach.
The integration of the two described types of classification into a single hybrid system allows this computational implementation to emulate, in a more satisfactory way, the classical methods of analysis and classification of stellar spectra that we describe in previous sections. The option that combines the optimal implementations of each technique obtains a classification based on solid foundations that result in clear and resumed conclusions for each classification level. At the same time, it is possible to carry out a detailed analysis of each individual spectrum with all the methods implemented and to study the discrepancies or coincidences between the estimations provided by each of them.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}