A Note on Wavelet-Based Estimator of the Hurst Parameter

Center of Statistical Research, School of Statistics, Southwestern University of Finance and Economics, Chengdu 611130, China
Entropy 2020, 22(3), 349; https://doi.org/10.3390/e22030349
Submission received: 7 February 2020
/
Revised: 15 March 2020
/
Accepted: 15 March 2020
/
Published: 18 March 2020
Abstract
:The signals in numerous fields usually have scaling behaviors (long-range dependence and self-similarity) which is characterized by the Hurst parameter H. Fractal Brownian motion (FBM) plays an important role in modeling signals with self-similarity and long-range dependence. Wavelet analysis is a common method for signal processing, and has been used for estimation of Hurst parameter. This paper conducts a detailed numerical simulation study in the case of FBM on the selection of parameters and the empirical bias in the wavelet-based estimator which have not been studied comprehensively in previous studies, especially for the empirical bias. The results show that the empirical bias is due to the initialization errors caused by discrete sampling, and is not related to simulation methods. When choosing an appropriate orthogonal compact supported wavelet, the empirical bias is almost not related to the inaccurate bias correction caused by correlations of wavelet coefficients. The latter two causes are studied via comparison of estimators and comparison of simulation methods. These results could be a reference for future studies and applications in the scaling behavior of signals. Some preliminary results of this study have provided a reference for my previous studies.
1. Introduction
The signals in numerous fields usually have scaling behavior (long-range dependence and self-similarity) which has been recognized as a key property for data characterization and decision making (see e.g., [1,2,3,4,5]). It is usually characterized by the Hurst parameter H [6]. The key point for detecting the scaling behavior is the estimation of the Hurst parameter H. The Hurst parameter was first computed via R/S statistic by Hurst [7] for the study of hydrological properties of Nile river. Hurst found that R/S statistic on the Nile data grew approximately as . n is the number of observations. This phenomenon is called the Hurst phenomenon. To study the Hurst phenomenon, Mandelbrot introduced the concept of self-similar and explained the Hurst phenomenon successfully using self-similar fractional Brownian motion (FBM) [8]. A continuous process is said to be self-similar, if for , , H is the self-similar parameter. When , the increments of FBM are long-range dependent, i.e., the summation of their auto-covariances is divergent. Thus, fractal Brownian motion and its increments (fractional Gaussian noise (FGN)) play important roles in modeling signals with self-similarity and long-range dependence. Most studies on this issue are based on FBM.
Wavelet analysis is a common method for signal processing (see e.g., [9,10]) and has been widely used for the fractal analysis of signals due to its multiresolution. Nicolis et al. [11] defined three kinds of wavelet-based entropy for studying the two-dimensional fractional Brownian field. Li et al. [12] used wavelet fractal and twin support vector machine to study the classification of heart sound signals. Ramírez-Pacheco et al. [13] studied fractal signal classification using non-extensive wavelet-based entropy.
The wavelet-based estimator of the Hurst parameter was well-established by Abry et al. (see [14,15,16,17,18,19,20,21]). Compared with other estimators, such as the R/S method, the periodogram, the variogram (semi-parametric or nonparametric estimator) and the parametric method, the wavelet-based estimator performs well in both the statistical and computational sense, and is superior in robustness (see [18,19] and the references therein). Besides, the wavelet-based method can also eliminate some trends (linear trends, polynomial trend, or more) by the property of its vanishing moments [17], which makes the estimator robust to some nonstationarities. More simulation studies for the estimation of Hurst parameter can be seen in [22]. Based on the standard wavelet-based estimator, some robust estimators are proposed. Soltani et al. [23] proposed an improved wavelet-based estimator via the average of two wavelet coefficients of half length apart and taking the logarithm first. Shen et al. [24] proposed a robust estimator of self-similar parameter using wavelet transform, which was less sensitive to some non-stationary traffic conditions. Park & Park [25] introduced a robust wavelet-based estimator which took the logarithm of wavelet coefficients first and averaged them later. Feng & Vidakovic [26] estimated the Hurst parameter via a general trimean estimator on nondecimated wavelet coefficients Kang & Vidakovic [27] proposed a robust estimator of Hurst parameter via medians of log-squared nondecimated wavelet coefficients.
Despite extensive studies of standard wavelet-based estimator proposed by Abry et al., there is still a lack of comprehensive and detailed numerical simulation study on fractal Brownian motion, especially for the selection of parameters and the empirical bias. I have not seen studies on the changes of bias and variance with all different Hs and with different data lengths, which I think is important for the selection of the lower octave bound , especially at small values of H. is selected via the minimum mean square error. Thus, this paper conducts a detailed numerical simulation study on the selection of parameters including the following contents.
- The changes of bias and variance with all different Hs, different data lengths, different s and different wavelets;
- The relations of selected with data length and H;
For the causes of the empirical bias which exist in standard wavelet-based estimator, the following three causes in the case of FBM are concluded.
- The initialization for initial approximation wavelet coefficients which introduces errors in used detailed wavelet coefficients.
- The inaccurate bias correction caused by correlations of wavelet coefficients.
- The method of simulation for FBM is not enough exact that the empirical bias is caused.
There exist many studies on the reduction of empirical bias caused by the first two reasons, but lack of study on determining which is the main cause of empirical bias. It is important for reducing empirical bias via appropriate techniques. Combining with results of parameters selection, this paper analyzes the above three causes of empirical bias in the case of FBM via comparison of estimators and comparison of simulation methods. The results obtained from above numerical simulations can be a reference for future studies and applications in the scaling behavior of signals. Some preliminary results of this study have provided a reference for my previous studies on wavelet-based estimation of Hurst parameters [28,29,30].
This paper is organized as follows. In Section 2, this paper introduces two available estimators for the Hurst parameter, and the initialization methods for the initial approximation wavelet coefficients. The simulation methods of FBM are described in Section 3. The main results are reported and discussed in Section 4 and my works are concluded in Section 5.
2. Wavelet-Based Estimator
2.1. Definitions and Properties
Fractional Brownian motion with Hurst parameter is a real-valued mean-zero Gaussian process with the following covariance structure:
It is a self-similar process with stationary increment. Its wavelet coefficient is defined by
is the mother wavelet, which is defined through a scaling function . Usually we choose as a base function, and we can change it to . The factors and j are called the scale and octave respectively.
Please note that FBM is usually denoted by . this paper uses the symbol X instead of since the methods in this section for FBM can be applicable to a more general process named self-similar process with stationary increment and finite variance [20].
Some key properties of the wavelet coefficient of X are given in the following lemma. The proof of this lemma can be found in [19,20,31,32,33].
Lemma 1.
Let be a fractional Brownian motion. is an orthonormal wavelet with compact support and have vanishing moments. The wavelet coefficients of given in (2) have these properties below,
(1) and is Gaussian, for any .
(2) For fixed ,
(3) For fixed ,
(4) For ,
In the above, means equality in distribution.
Remark 1.
In view of Equation (5), to avoid long-range dependence for , i.e., to ensure that , one needs to choose
that is, have at least . Under this condition, the correlation of tends rapidly to 0 at large lags.
According to Remark 1 and Equation (5), let the number of vanishing moments . It is reasonable to impose the following assumptions.
- For fixed j, the are independent and identically distributed;
- The processes and , , are independent.
2.2. Two Wavelet-Based Estimators
The First Estimator
The first estimator is the standard wavelet-based estimator of Hurst parameter which is proposed by Abry et al and commonly used in applications of various fields. In view of Equations (3) and (4), I can check the following formula.
Take the logarithm:
So the estimation of H can be conducted by a linear regression in the left part versus j diagram. The is estimated by
where stands for the number of actually available at octave j.
Due to different variances of at different js, the weighted least squares for this regression model is needed. The weight is the reciprocal of the variance of .
Please note that
This can lead to the bias of estimator.
Define the variables s as
where is calculated such that . To ensure the unbiasedness of the estimator, I use as the response variable instead of . Moreover, .
The Second Estimator
As mentioned above, since , the first estimator needs to correct bias. For avoiding this case, the second least squares estimator for Hurst parameter is proposed. This estimator is also originally proposed by Abry et al. [34] and then studied by Park & Park [25] for the purpose of robustness.
Now take the logarithm first and then the expectation, obtain the following new equation.
So the estimation of H can be conducted by a weighted linear regression in the left part versus j diagram. The is estimated by
where stands for the number of actually available at octave j.
Compared with the first estimator, the second estimator changes the order of expectation and logarithmic. The idea of this estimator is first proposed for analyzing the -stable self-similar processes with infinite second-order statistics and long-range dependence [34].
Define the variables as
We can check that . Let be the response variable of weighted linear regression. The unbiasedness of the estimator follows from the unbiasedness of .
Similar to the calculation shown in [18,19,20], the variance of can be calculated for the weight of regression.
The is estimated using its sample variance at each octave.
Explicit Formula of theTwo Estimators
Let denote the lower bound of j, and denote the upper bound of j, i.e., the values of j are chosen . According to the weighted least squares, the explicit formula of estimators can be obtained as follows,
where , , , .
When using the first method, and , let denote the first estimator. When using the second method, and , let denote the second estimator.
Variance Comparison
The variances of and can be compared via a simple theoretical analysis. In view of Equation (19), the variance of can be calculated by
When is large, recall that the asymptotic form of (see [19]).
Also recall Equation (17),
So when is large, the asymptotic form of ratio can be obtained,
The variance of is smaller than that of .
Please note that the nondecimated wavelet coefficients have been used in wavelet-based estimator since they can decrease the variance due to their redundancy [26,27]. However, they can also increase the correlations in wavelet coefficients. Then when using nondecimated wavelet coefficients, we should take logarithm first. It is suitable to reduce the variance of the second estimator via nondecimated wavelet coefficients. For further considering the possible outliers caused by logarithmic transform, Kang & Vidakovic [27] suggest using medians for estimation of Hurst parameter in this case. This method is denoted by MEDL.
2.3. Calculation of Wavelet Coefficients
According to the multiresolution analysis (MRA), the wavelet coefficients can be calculated by fast pyramidal algorithm. The scaling function and the wavelet satisfy so-called two-scale equation:
where and are two existing sequences belonging to .
Define the approximation coefficients :
where .
So can be calculated by fast pyramidal algorithm.
In view of above formulas, the are obtained via integral. However, in practice, the data we obtained are always discrete and finite. The cannot be obtained by integral in continuous time. When sampling frequency is high and the scale of wavelet transform is small, the typical approach is to set [35,36,37]
where is discrete and finite FBM.
In view of Equations (25) and (26), the number of available wavelet coefficients decreases by half. Then .
Remark 2.
For a wavelet which has time support (finite or decreases very fast as ), an increase in the number of vanishing moments N comes with an enlargement of the time support [20]. In the case of finite data, because of the boundary effects of wavelet transform, this will lead to the decrease of the number of available wavelet coefficients at each octave.
2.4. The Initialization Method
The discrete sampling for a continuous process usually implies an irrevocable loss of information on [35]. So the approach shown in Equation (27) introduces errors in s. It is known [14,18] that these initialization errors are significant on small octaves but quickly decrease with increasing j. For large j, the initialization issue can be ignored. Veitch et al. [35] introduce an initialization method for discrete time series, which has been proved meaningful for correction of the initialization errors in the case of long-range dependent process.
This initialization method is based on the stochastic version of the Shannon sampling theorem [35,38]. Consider the bandlimited stationary stochastic process , construct by
The is bandlimited, and has the same spectral density as that of in the frequency band (otherwise is zero). It is easy to check
Furthermore,
where . The sequence is calculated in [35].
Please note that because of the boundary effects, the initialization will lead to the decrease of the number of available wavelet coefficients .
3. Simulation of FBM
For studying the statistical performance of the two estimators in the case of FBM, the numerical simulation of FBM is conducted. Here, this section briefly introduces two simulation methods of FBM [39,40,41,42]. Let be a mean-zero fractional Brownian motion with Hurst parameter .
The Cholesky Method
The Cholesky method uses the Cholesky decomposition of the covariance matrix. The FBM generated by this method is exact in the sense of covariance structure, but this method is slow.
Let be the covariance matrix of FBM, where , . Conduct the Cholesky decomposition .
At last, is the generated FBM, where , are independent and identically distributed .
The Circulant Embedding Method
The simulation procedure is based on the method of circulant embedding. The algorithm of circulant embedding was originally proposed by Davies and Harte [39], and was later simultaneously generalized by Dietrich and Newsam (see [40,41,42] and the references therein). It has been regarded as a fast and exact simulation of stationary Gaussian processes [42]. I use this method to generate a fractional Gaussian noise, and construct a fractional Brownian motion via the cumulative sum of generated fractional Gaussian noise [41].
First consider the fractional Gaussian noise, which is a zero-mean stationary Gaussian process with covariance
4. Simulation Results and Discussions
This section focuses on the numerical study of commonly used wavelet-based estimator (the first estimator) which still lacks of comprehensive and detailed numerical study on estimation of fractal Brownian motion, especially on its empirical bias and the selection of parameters. The second estimator was also compared with the commonly used estimator in this section for the purpose of empirical bias analysis. If not specified, the sample trajectory of FBM used in this section is generated by the circulant embedding method.
4.1. Selection of Parameters
It is a key step to select octaves js and the number of vanishing moments N (or wavelet) before estimation. First this subsection studies the selection of these parameters for later estimations. For octaves js, the lower bound and the upper bound need to be determined. The is chosen as the largest possible. In practice, it is set equal to
where n denotes the data length and C is a constant (with value corresponding to the length of the support of the wavelet [20]). As the discussion in Section 2, the initialization for given in (27) introduces errors in the . It is known [14,18] that initialization errors are significant on small octaves but decrease with increasing j. So small octave cannot be chosen as . Based on prior studies [18,20], and this paper selects by the minimum mean square error (MSE), where the MSE is defined as
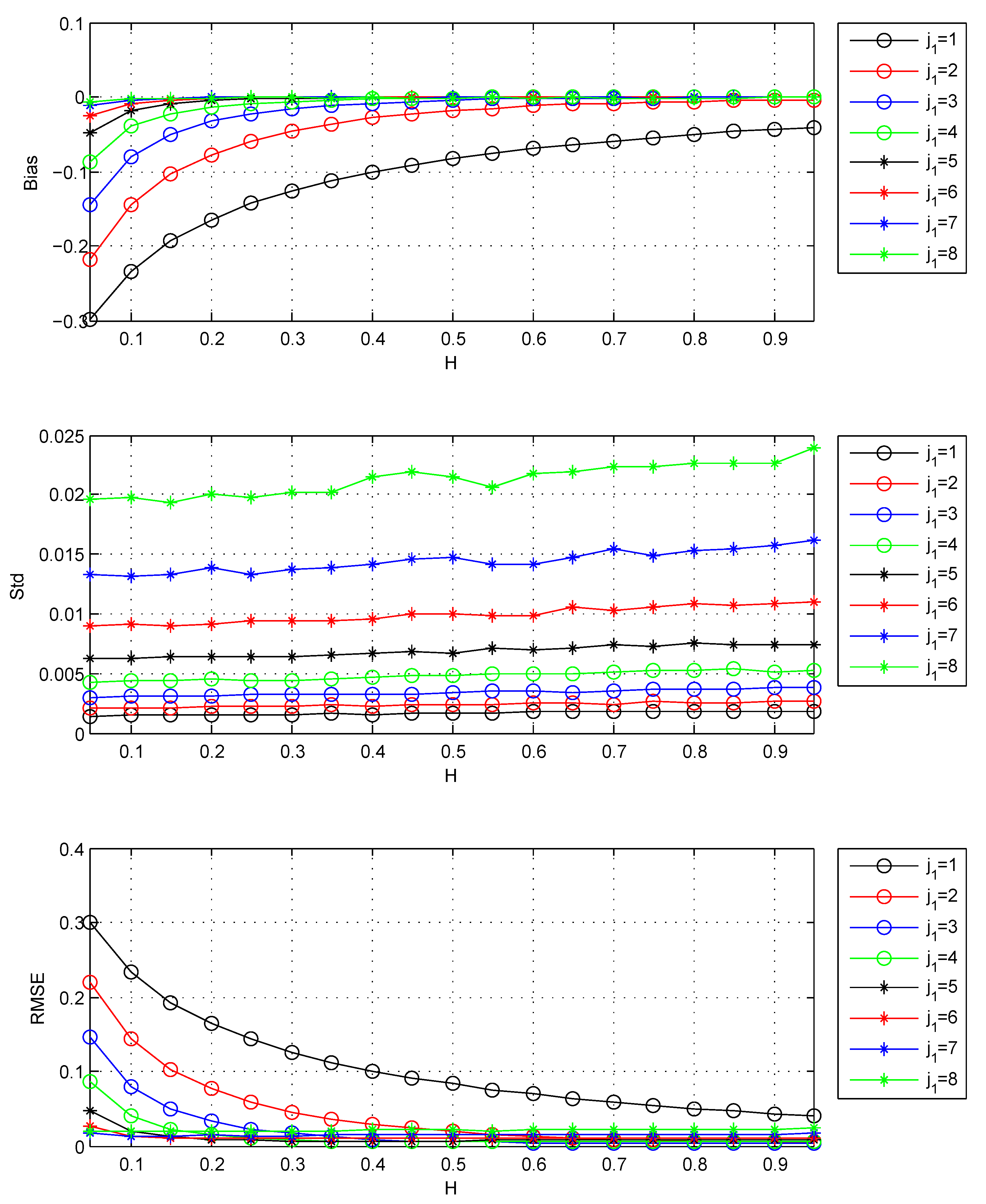
It allows the tradeoff between variance and bias. The results for the selection of are shown in Table 1 and Figure 1.
Figure 1 shows that the increase of causes the decrease of bias and the increase of standard deviation for all Hs. So it is suitable to choose the by the minimum of MSE. From Table 1, when , is chosen by minimum MSE. When , the RMSE of is close to that of chosen . So considering most Hs, should be chosen in the case of FBM.
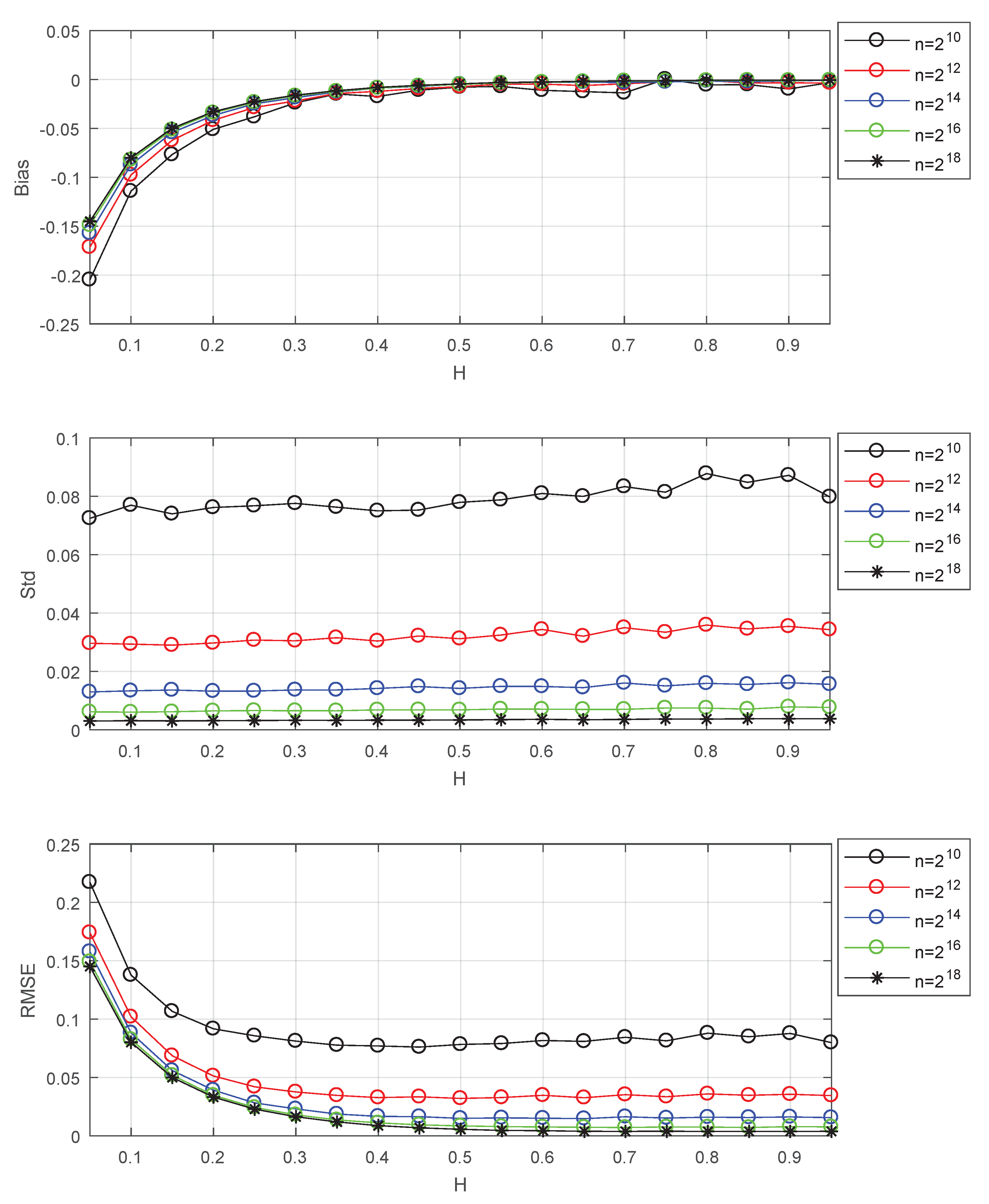
Please note that the results of Figure 1 and Table 1 are based on long series. In this case, the variances of all Hs are small. For small values of H, the bias is large, and the MSE is mainly determined by the bias. So the estimator of small H trends to select large which can lead to small bias. Now I study the effects of data length and the selection of at different data lengths. The results of this issue are shown in Figure 2 and Table 2.
Figure 2 shows that the data length has little effect on the bias, but its decrease causes the increase of standard deviation for all Hs. The increase of standard deviation may affect the selection of . Thus, continue to use the minimum MSE to select at different data lengths for the tradeoff between variance and bias. The results of selection are shown in Table 2. From Table 2, it can be seen that the selected increases with the increase of data length, and the smaller the value of H, the faster the increase. Based on simulation results, the following formula is given for explanation.
where denotes the bias of estimator which decreases with the increase of H and the increase of . denotes the variance which decreases with the decrease of and the increase of n. When n increases, the variance becomes smaller, the selected trends to increase for the tradeoff between variance and bias. The smaller the value of H, the larger the bias, and the more the selected increase.
For the wavelet, this paper chooses the classical Daubechies wavelets, which are orthonormal and have compact support. According to Remark 1, the number of vanishing moments must be chosen . For analyzing the effect of N, I use to estimate the Hurst parameter of FBM. The results are shown in Figure 3.
From Figure 3, when , the increase of N makes no improvements to the performance of the estimator. Besides, according to Remark 2, large N will cause the loss of available wavelet coefficients. So appropriately we should choose .
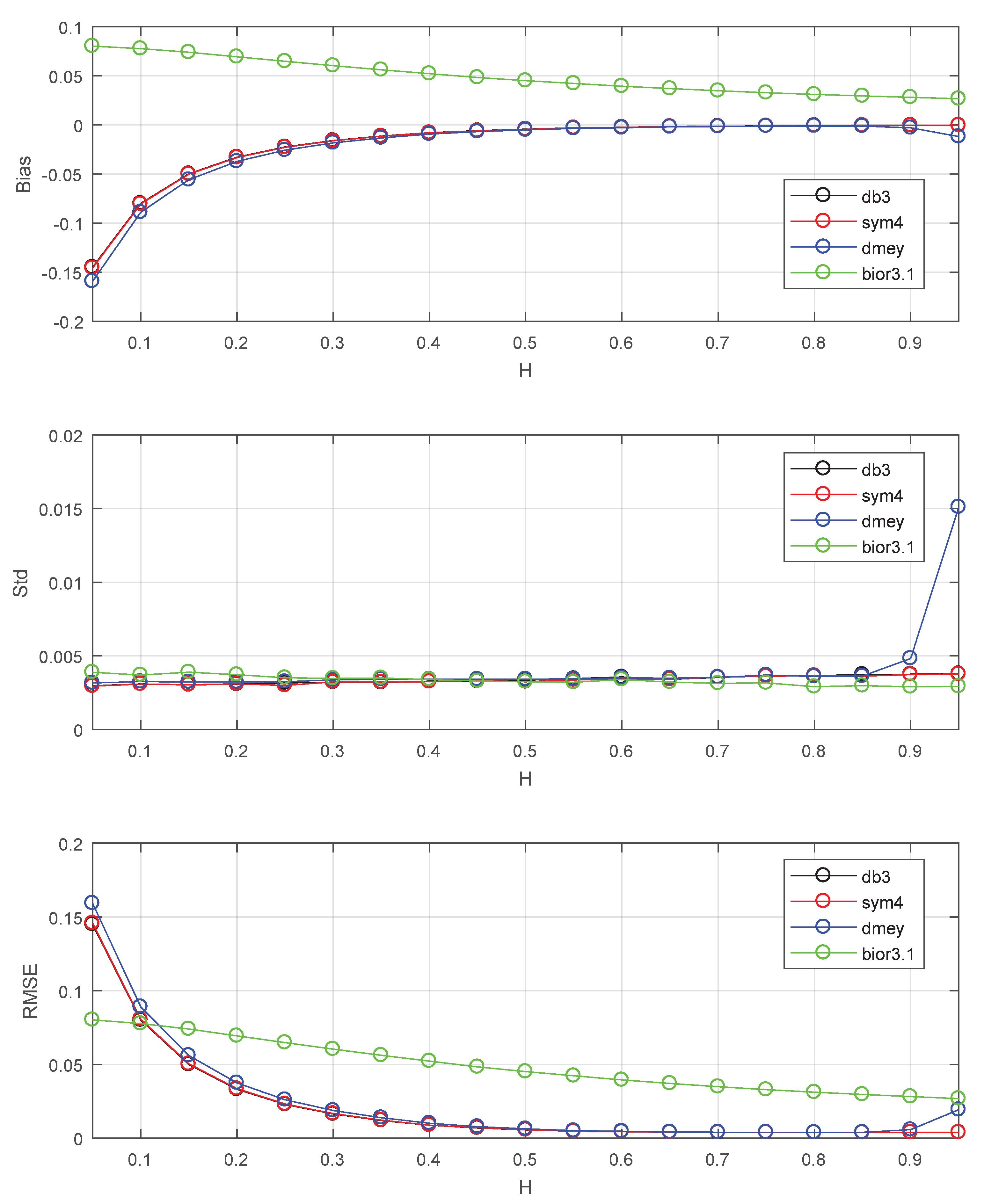
Finally, this subsection studies the performance of this estimator using various wavelets for further chosen of wavelet. The results are shown in Figure 4. db3 stands for Daubechies wavelet with three vanishing moments. sym4 stands for Symlets wavelet with four vanishing moments. dmey stands for discrete Meyer wavelet. bior3.1 stands for biorthogonal spline wavelets with orders (vanishing moments) and . Since the Symlets wavelet with three vanishing moments has the same filters as db3, this part uses this kind of wavelet with four vanishing moments. The first three wavelets are orthogonal and have compact support. The last wavelet is biorthogonal. It can be seen in Figure 4 that performance using the first three wavelets are almost the same except for the standard deviation of dmey at . The biorthogonal spline wavelet performs worse than orthogonal wavelets except at . This is due to the large bias caused by strong correlations of biorthogonal wavelet coefficients, and is consistent with the conclusion of Lemma 1. We need to use orthogonal compact supported wavelet to control these correlations via vanishing moments.
4.2. Results and Discussions on Empirical Bias
This subsection conducts a detailed numerical analysis on the empirical bias exits in the commonly used wavelet-based estimator (the first estimator). Based on previous analysis, the following three possible causes of empirical bias are concluded.
- The initialization for given in (27) introduces errors in , and the initialization errors are significant on small octaves but decrease with increasing j.
- The inaccurate bias correction for (under independent assumptions) caused by correlations of wavelet coefficients.
- The method of simulation for FBM is not enough exact that the empirical bias is caused.
From results of Section 4.1, I have the following information on empirical bias
- The increase of N and change of wavelet made no improvements to the empirical bias. The chosen of biorthogonal wavelet makes the empirical bias worse.
- The increase of leads to the decrease of empirical bias.
- The empirical bias increases with the decrease of H. when choosing and , the empirical bias of estimator can be ignored for . So the estimator is suitable to detect the long-range dependence (can be described by ).
The fact that increase of leads to decrease of empirical bias is consistent with the first cause. As we know, the larger the value of H is, the smoother the sample path of FBM is, and the more exact the initialization given in (27) is. It is consistent with the fact that the empirical bias increases with the decrease of H. So I conclude that the initialization errors caused by (27) contribute to the empirical bias.
The first information indicates the empirical bias is related to correlations of wavelet coefficients. However, this effects can be fixed (maybe eliminated) via the selection of orthogonal compact supported wavelet.
Next, after choosing the orthogonal compact supported wavelet (db3) and fixing , this study analyzes the latter two causes via comparing with the second estimator and comparison of simulation methods respectively.
Comparison of Estimators
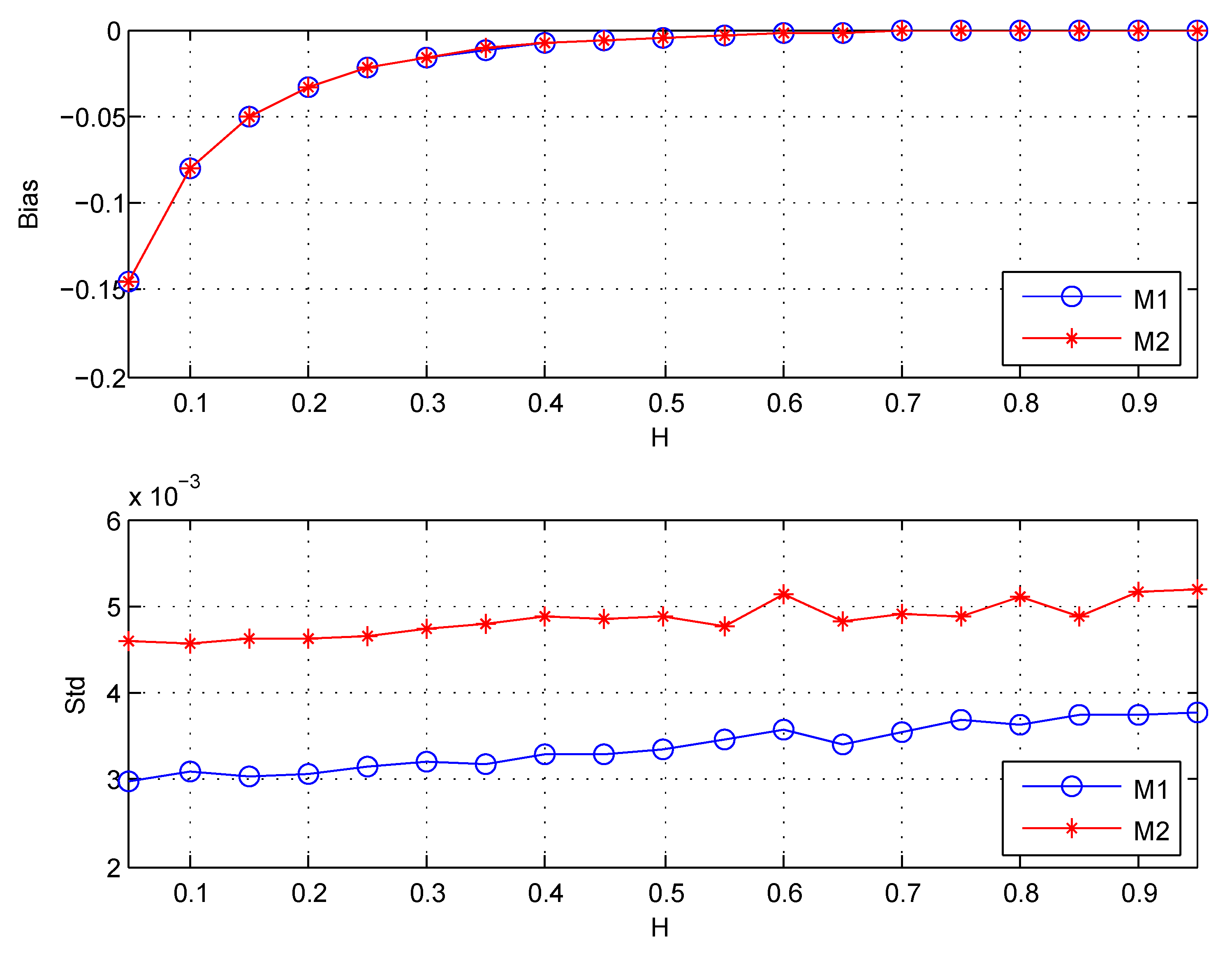
Since the unbiasedness of the second estimator is get naturally without independence assumptions of wavelet coefficients. This part compares with for studying its empirical bias. The length of simulation data is . are chosen . The wavelet coefficients are computed using the classical Daubechies wavelet with vanishing moments. The results are shown in Figure 5 and Table 3.
Table 3 shows the results for the estimator of ratio given in Equation (22). It indicates that the variance of is about twice that of , which roughly satisfy the theoretical results given in (22). From Figure 5, it can be seen that when , both and have the same obvious bias despite the theoretical unbiasedness of the two estimators under independence assumptions of wavelet coefficients. Besides, the same as the results shown in Table 3, the standard deviation (Std) of is larger than that of .
Because the empirical bias also exists in whose unbiasedness is get naturally, and is the same as that of . I conclude that the empirical bias of is not due to the inaccurate bias correction for caused by correlations of wavelet coefficients.
Besides, considering the variances of the two estimators, we should choose the first estimator for the estimation of Hurst parameter.
Comparison of Simulation Methods
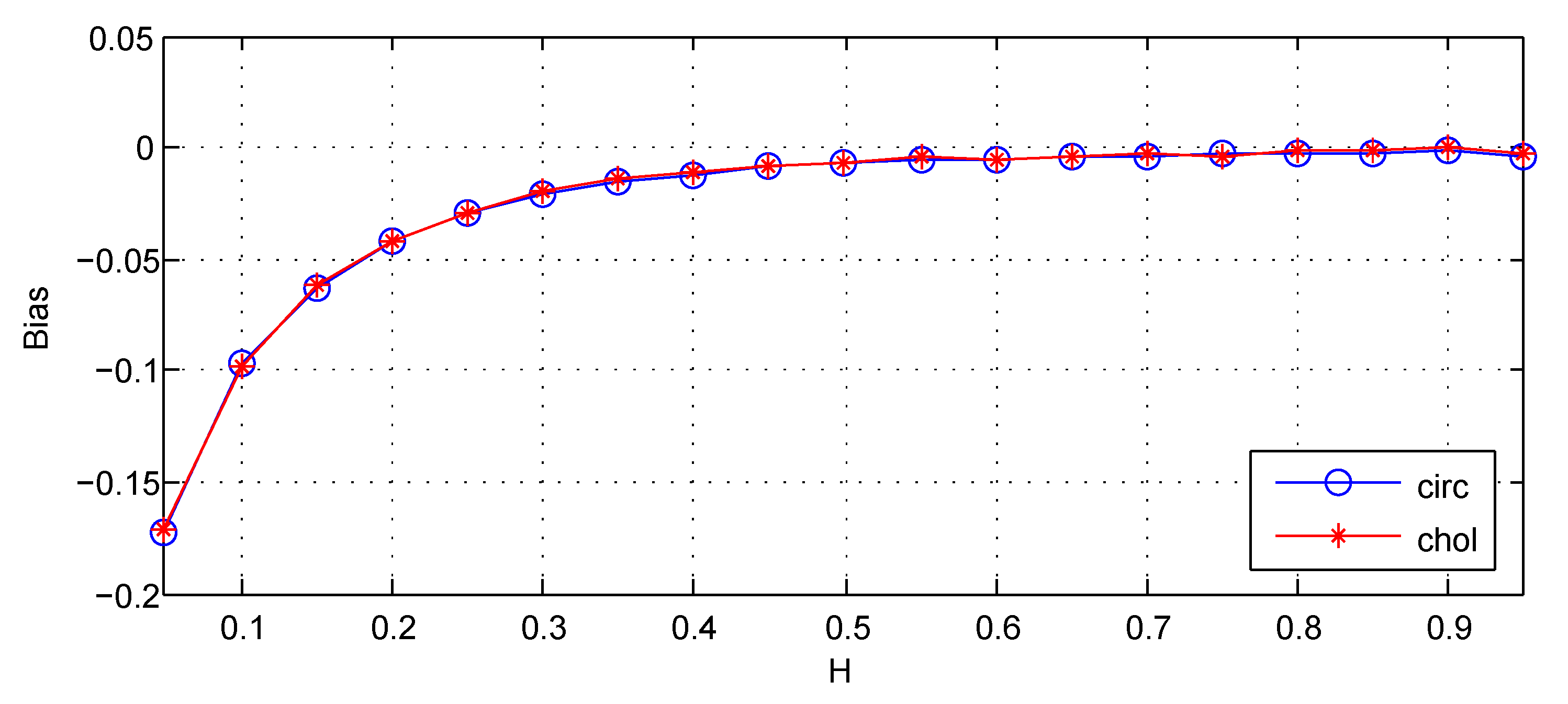
For the third cause, this part applies to the FBM that is exactly generated by the Cholesky method for comparison. The results are shown in Figure 6.
From Figure 6, it can be seen that estimations for the FBM respectively generated by the Cholesky method and the circulant embedding method has almost the same empirical bias. I conclude that the method of simulation is not the cause of empirical bias.
4.3. Analysis of the Initialization Method
It has been shown above that the empirical bias of is due to the initialization errors caused by (27). The initialization method given in (29) has proved effective for errors in the case of long-range dependent process [35]. Although FBM is not a bandlimited stationary stochastic process, I tend to check whether this method is suitable for FBM.
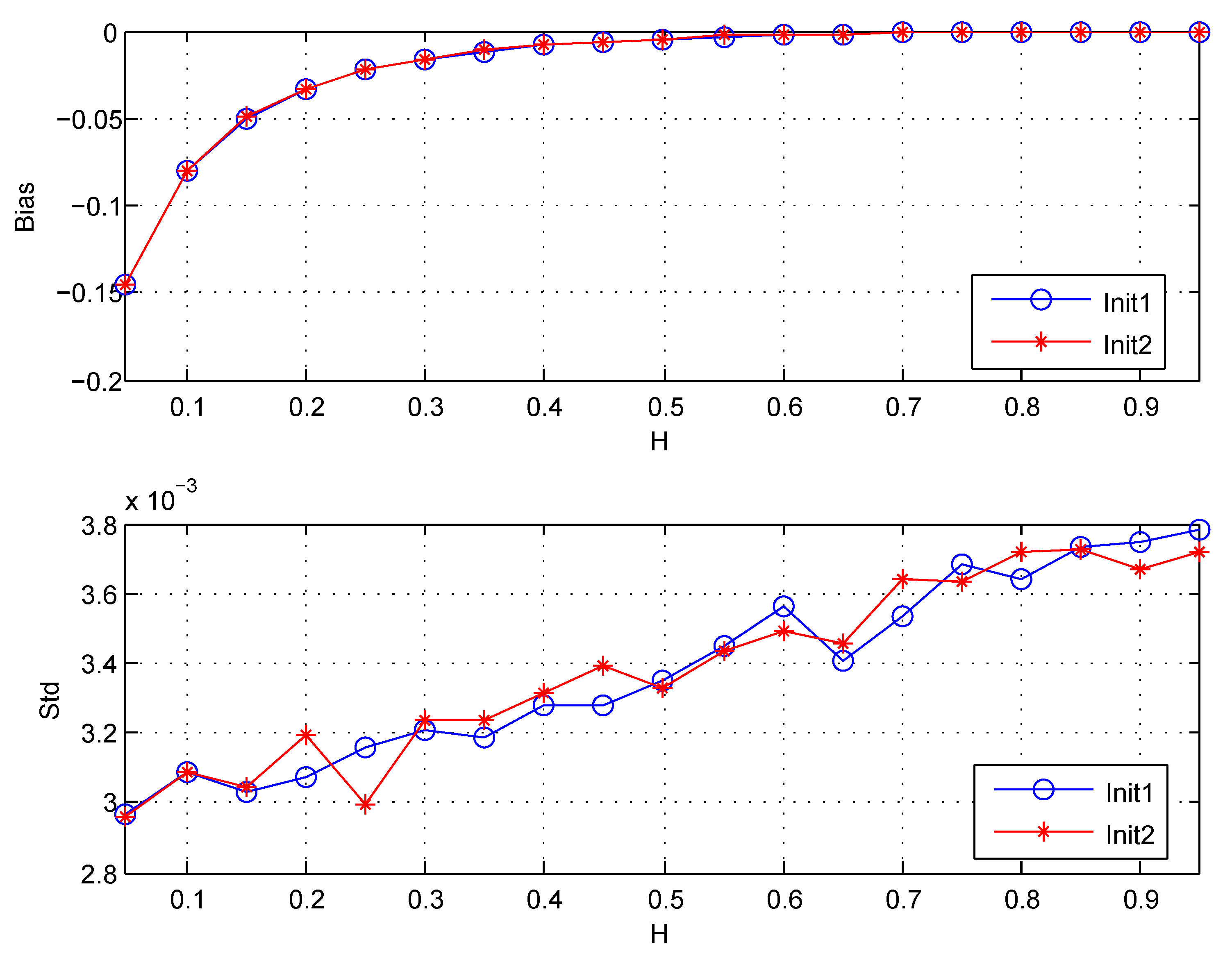
This subsection applies the estimator with this initialization to FBM for analysis, and compares it with the initialization by itself (or by Equation (27)). The length of simulation data is . are chosen . The wavelet coefficients are computed using the classical Daubechies wavelet with vanishing moments. The results are shown in Figure 7.
Figure 7 shows that both Biases and Stds for the two initializations are almost the same. It indicates that the initialization method given in (29) is inefficient in the case of FBM. Beside, it is known that the method Init2 will lead to the decrease of the number of available wavelet coefficients for the boundary effects, which may result in the increase of the variance of estimator. So I suggest choosing the initialization for given in (27) in the future work.
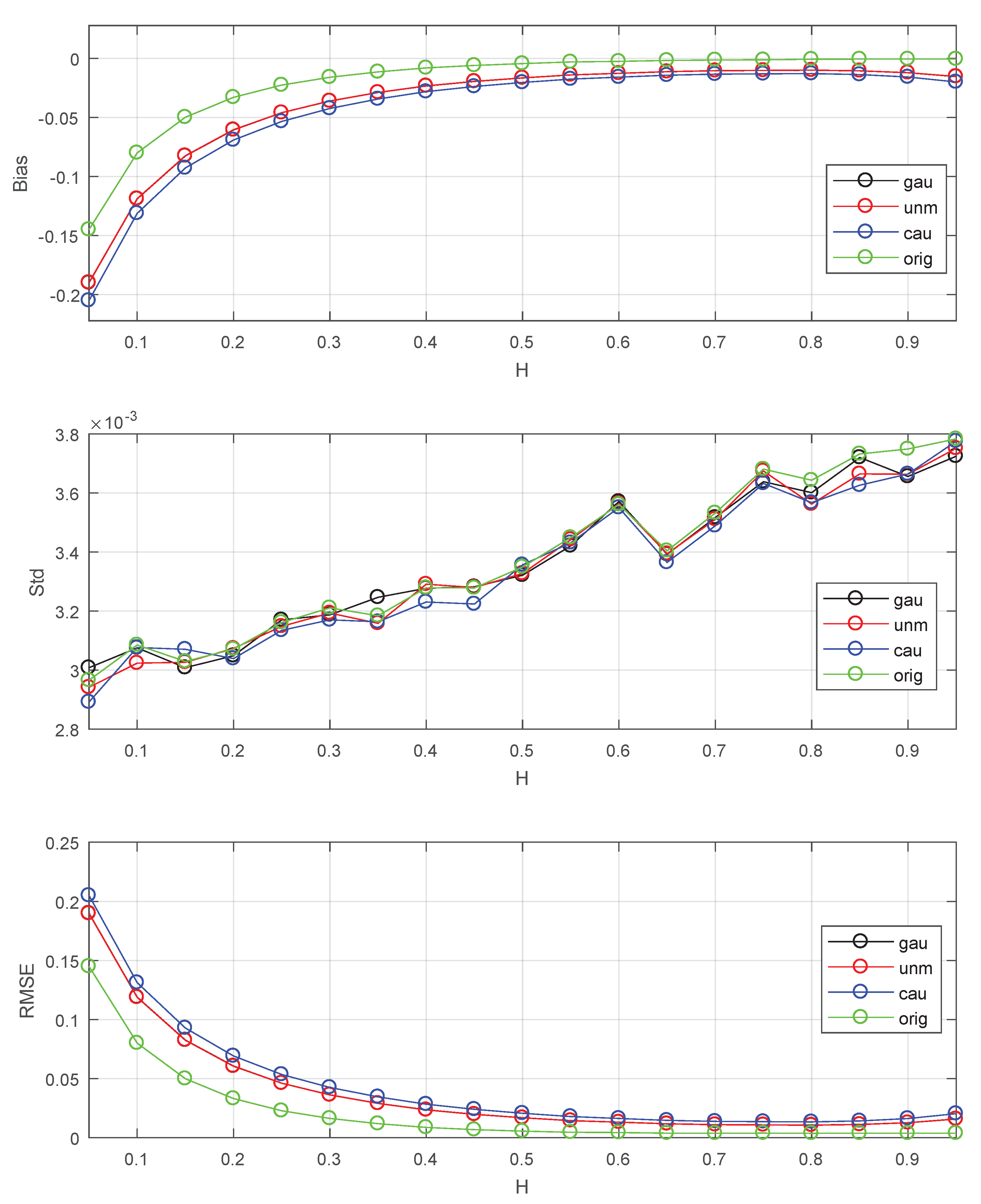
4.4. Analysis of Noise Effects
At last, this paper adds this subsection for analysis of noise effects on the first estimator, which possibly happen in the real data. Various independent and identically distributed noises are added to the generated FBM for this issue. The signal-to-noise ratio (SNR) is defined as follows.
where means noise. Set in this subsection.
5. Conclusions
This paper focuses on the numerical simulation study of wavelet-based estimators in the case of FBM concluding the selection of parameters and the analysis of empirical bias which have not been studied comprehensively in previous studies. This study adds to previous numerical simulation studies of wavelet-based estimators which are not comprehensive in the case of FBM.
Results of the parameter selection showed that the increase of lower bound causes the decrease of bias and the increase of standard deviation for all Hs, and suggested via the minimum mean square error at a long data length . In addition, it was also found that the empirical bias increased with the decrease of H and could be ignored for when and . The effects of n on performance and relations of selected with n were also concluded via simulation studies. It was shown that the data length had little effect on the bias, but its decrease caused the increase of standard deviation for all Hs. The selected increased with the increase of data length, and the smaller the value of H, the faster the increase. For the vanishing moments N, when , the increase of N made no improvements to the performance of estimator. The change of orthogonal wavelets made no improvements to the empirical bias. The chosen of biorthogonal wavelet made empirical bias worse.
The analysis of empirical bias was conducted first via comparison of two available estimators and comparison of simulation methods. The results showed that the empirical bias was due to the initialization errors caused by discrete sampling, and was not related to simulation methods. When choosing an appropriate orthogonal compact supported wavelet, the empirical bias was almost not related to the inaccurate bias correction caused by correlations of wavelet coefficients. I regret to note that the initialization method given in (29), which has proved effective in the case of long-range dependent process, made no improvements to the empirical bias. All these results will be a guide for my future studies.
Funding
This research was funded by the National Natural Science Foundation of China grant number 61903309, the Major Project for New Generation of AI grant number 2018AAA0100400, the National Natural Science Foundation of Hunan grant number 2018JJ2098 and the Fundamental Research Funds for the Central Universities grant number JBK1806002.
Acknowledgments
The author is grateful to the anonymous reviewers for their time reviewing my paper and their valuable comments and suggestions, which helped improve this paper.
Conflicts of Interest
The author declares no conflict of interest.
References
- Li, Q.; Liang, S.Y.; Yang, J.; Li, B. Long range dependence prognostics for bearing vibration intensity chaotic time series. Entropy 2016, 18, 23. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Yang, Z.; Shi, Z.; Ma, J.; Cao, J. A gyroscope signal denoising method based on empirical mode decomposition and signal reconstruction. Sensors 2019, 19, 5064. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Chen, W.; Chan, C.; Li, B.; Song, X. Multi-sensor fusion methodology for enhanced land vehicle positioning. Inform. Fusion 2019, 46, 51–62. [Google Scholar] [CrossRef]
- Dou, C.; Wei, X.; Lin, J. Fault diagnosis of gearboxes using nonlinearity and determinism by generalized Hurst exponents of shuffle and surrogate data. Entropy 2018, 20, 364. [Google Scholar] [CrossRef] [Green Version]
- Wu, L.; Chen, L.; Ding, Y.; Zhao, T. Testing for the source of multifractality in water level records. Physica A 2018, 508, 824–839. [Google Scholar] [CrossRef]
- Graves, T.; Gramacy, R.; Watkins, N.; Franzke, C. A brief history of long memory: Hurst, Mandelbrot and the road to ARFIMA, 1951–1980. Entropy 2017, 19, 437. [Google Scholar] [CrossRef] [Green Version]
- Hurst, H.E. Long-term storage capacity of reservoirs. Trans. Am. Soc. Civ. Eng. 1951, 116, 770–799. [Google Scholar]
- Mandelbrot, B.; Van Ness, J. Fractional Brownian Motions, Fractional Noises and Applications. SIAM Rev. 1968, 10, 422–437. [Google Scholar] [CrossRef]
- Deng, Z.; Wang, J.; Liang, X.; Liu, N. Function extension based real-time wavelet de-noising method for projectile attitude measurement. Sensors 2020, 20, 200. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Xia, Z.; Si, Y.; Lu, Q.; Peng, Y. Noise reduction of welding crack AE signal based on EMD and wavelet packet. Sensors 2020, 20, 761. [Google Scholar] [CrossRef] [Green Version]
- Nicolis, O.; Mateu, J.; Contreras-Reyes, J.E. Wavelet-based entropy measures to characterize two-dimensional fractional Brownian fields. Entropy 2020, 22, 196. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Ke, L.; Du, Q. Classification of heart sounds based on the wavelet fractal and twin support vector machine. Entropy 2019, 21, 472. [Google Scholar] [CrossRef] [Green Version]
- Ramírez-Pacheco, J.C.; Trejo-Sánchez, J.A.; Cortez-González, J.; Palacio, R.R. Classification of fractal signals using two-parameter non-extensive wavelet entropy. Entropy 2017, 19, 224. [Google Scholar] [CrossRef] [Green Version]
- Flandrin, P. Wavelet analysis and synthesis of fractional Brownian motion. IEEE Trans. Inf. Theory 1992, 38, 910–917. [Google Scholar] [CrossRef]
- Abry, P.; Gonçalvès, P.; Flandrin, P. Wavelets, spectrum analysis and 1/f processes. In Wavelets and Statistics; Antoniadis, A., Oppenheim, G., Eds.; Springer: New York, NY, USA, 1995; Section 2; Volume 103, pp. 15–29. [Google Scholar] [CrossRef]
- Delbeke, L.; Van Assche, W. A wavelet based estimator for the parameter of self-similarity of fractional Brownian motion. In Proceedings of the 3rd International Conference on Approximation and Optimization in the Caribbean (Puebla, 1995), Puebla, Mexico, 8–13 October 1995; Volume 24, pp. 65–76. [Google Scholar]
- Abry, P.; Veitch, D. Wavelet analysis of long-range-dependent traffic. IEEE Trans. Inf. Theory 1998, 44, 2–15. [Google Scholar] [CrossRef]
- Veitch, D.; Abry, P. A wavelet-based joint estimator of the parameters of long-range dependence. IEEE Trans. Inf. Theory 1999, 45, 878–897. [Google Scholar] [CrossRef]
- Abry, P.; Flandrin, P.; Taqqu, M.; Veitch, D. Wavelets for the analysis, estimation and synthesis of scaling data. In Self-Similar Network Traffic and Performance Evaluation; Park, K., Willinger, W., Eds.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2000; pp. 39–88. [Google Scholar]
- Abry, P.; Flandrin, P.; Taqqu, M.S.; Veitch, D. Self-similarity and long-range dependence through the wavelet lens. In Theory and Applications of Long-Range Dependence; Doukhan, P., Oppenheim, G., Taqqu, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 527–556. [Google Scholar]
- Abry, P.; Helgason, H.; Pipiras, V. Wavelet-based analysis of non-Gaussian long-range dependent processes and estimation of the Hurst parameter. Lith. Math. J. 2011, 51, 287–302. [Google Scholar] [CrossRef]
- Rea, W.; Oxley, L.; Reale, M.; Brown, J. Estimators for long range dependence: An empirical study. arXiv 2009, arXiv:0901.0762. [Google Scholar]
- Soltani, S.; Simard, P.; Boichu, D. Estimation of the self-similarity parameter using the wavelet transform. Signal Process. 2004, 84, 117–123. [Google Scholar] [CrossRef]
- Shen, H.; Zhu, Z.; Lee, T.C. Robust estimation of the self-similarity parameter in network traffic using wavelet transform. Signal Process. 2007, 87, 2111–2124. [Google Scholar] [CrossRef]
- Park, J.; Park, C. Robust estimation of the Hurst parameter and selection of an onset scaling. Stat. Sin. 2009, 19, 1531–1555. [Google Scholar]
- Feng, C.; Vidakovic, B. Estimation of the Hurst exponent using trimean estimators on nondecimated wavelet coefficients. arXiv 2017, arXiv:1709.08775. [Google Scholar]
- Kang, M.; Vidakovic, B. MEDL and MEDLA: Methods for assessment of scaling by medians of log-squared nondecimated wavelet coefficients. arXiv 2017, arXiv:1703.04180. [Google Scholar]
- Wu, L.; Ding, Y. Estimation of self-similar Gaussian fields using wavelet transform. Int. J. Wavelets Multiresolut. Inf. Process. 2015, 13, 1550044. [Google Scholar] [CrossRef]
- Wu, L.; Ding, Y. Wavelet-based estimator for the Hurst parameters of fractional Brownian sheet. Acta Math. Sci. 2017, 37B, 205–222. [Google Scholar] [CrossRef] [Green Version]
- Wu, L.; Ding, Y. Wavelet-based estimations of fractional Brownian sheet: Least squares versus maximum likelihood. J. Comput. Appl. Math. 2020, 371, 112609. [Google Scholar] [CrossRef]
- Bardet, J.M.; Lang, G.; Oppenheim, G.; Philippe, A.; Stoev, S.; Taqqu, M.S. Semi-parametric estimation of the long-range dependence parameter: A survey. In Theory and Applications of Long-Range Dependence; Doukhan, P., Oppenheim, G., Taqqu, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 557–577. [Google Scholar]
- Tewfik, A.H.; Kim, M. Correlation structure of the discrete wavelet coefficients of fractional Brownian motion. IEEE Trans. Inf. Theory 1992, 38, 904–909. [Google Scholar] [CrossRef]
- Dijkerman, R.W.; Mazumdar, R.R. On the correlation structure of the wavelet coefficients of fractional Brownian motion. IEEE Trans. Inf. Theory 1994, 40, 1609–1612. [Google Scholar] [CrossRef]
- Abry, P.; Delbeke, L.; Flandrin, P. Wavelet based estimator for the self-similarity parameter of α-stable processes. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Phoenix, AZ, USA, 15–19 March 1999; Volume 3, pp. 1729–1732. [Google Scholar] [CrossRef]
- Veitch, D.; Taqqu, M.S.; Abry, P. Meaningful MRA initialization for discrete time series. Signal Process. 2000, 80, 1971–1983. [Google Scholar] [CrossRef]
- Abry, P.; Flandrin, P. On the initialization of the discrete wavelet transform algorithm. IEEE Signal Process. Lett. 1994, 1, 32–34. [Google Scholar] [CrossRef] [Green Version]
- Veitch, D.; Abry, P.; Taqqu, M.S. On the automatic selection of the onset of scaling. Fractals 2003, 11, 377–390. [Google Scholar] [CrossRef]
- Papoulis, A.; Pillai, S.U. Probability, Random Variables and Stochastic Processes; Tata McGraw-Hill Education: New York, NY, USA, 2002. [Google Scholar]
- Davies, R.B.; Harte, D.S. Tests for Hurst effect. Biometrika 1987, 74, 95–101. [Google Scholar] [CrossRef]
- Dieker, T. Simulation of Fractional Brownian Motion. Master’s Thesis, University of Twente, Amsterdam, The Netherlands, 2004. [Google Scholar]
- Kroese, D.P.; Botev, Z.I. Spatial process simulation. In Stochastic Geometry, Spatial Statistics and Random Fields; Spodarev, E., Ed.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 369–404. [Google Scholar] [CrossRef]
- Dietrich, C.; Newsam, G.N. Fast and exact simulation of stationary Gaussian processes through circulant embedding of the covariance matrix. SIAM J. Sci. Comput. 1997, 18, 1088–1107. [Google Scholar] [CrossRef]
Figure 1.
The Bias, Std, RMSE for estimators: is the lower bound of octaves js. Std is the standard deviation, Bias , RMSE is the square root of MSE. The values of Std, Bias, and RMSE are the estimated versions of those for 1000 independent copies of FBM with length . The used wavelet is the Daubechies wavelet with vanishing moments.
Figure 1.
The Bias, Std, RMSE for estimators: is the lower bound of octaves js. Std is the standard deviation, Bias , RMSE is the square root of MSE. The values of Std, Bias, and RMSE are the estimated versions of those for 1000 independent copies of FBM with length . The used wavelet is the Daubechies wavelet with vanishing moments.

Figure 2.
The Bias, Std, RMSE for estimators: n is the data length. Std is the standard deviation, Bias , RMSE is the square root of MSE. The values of Std, Bias, and RMSE are the estimated versions of those for 1000 independent copies of FBM with length n. The lower bound of octaves js is chosen . The used wavelet is the Daubechies wavelet with vanishing moments.
Figure 2.
The Bias, Std, RMSE for estimators: n is the data length. Std is the standard deviation, Bias , RMSE is the square root of MSE. The values of Std, Bias, and RMSE are the estimated versions of those for 1000 independent copies of FBM with length n. The lower bound of octaves js is chosen . The used wavelet is the Daubechies wavelet with vanishing moments.

Figure 3.
The Bias, Std, RMSE for estimators: N is the number of vanishing moments of Daubechies wavelet. Std is the standard deviation, Bias , RMSE is the square root of MSE. The values of Std, Bias and RMSE are the estimated versions of those for 1000 independent copies of FBM with length . The lower bound of octaves js is chosen .
Figure 3.
The Bias, Std, RMSE for estimators: N is the number of vanishing moments of Daubechies wavelet. Std is the standard deviation, Bias , RMSE is the square root of MSE. The values of Std, Bias and RMSE are the estimated versions of those for 1000 independent copies of FBM with length . The lower bound of octaves js is chosen .

Figure 4.
The Bias, Std, RMSE for estimators: db3 stands for Daubechies wavelet with three vanishing moments, sym4 stands for Symlets wavelet with four vanishing moments, dmey stands for discrete Meyer wavelet, bior3.1 stands for biorthogonal spline wavelets with orders (vanishing moments) and . The values of Std, Bias and RMSE are the estimated versions of those for 1000 independent copies of FBM with length . The lower bound of octaves js is chosen .
Figure 4.
The Bias, Std, RMSE for estimators: db3 stands for Daubechies wavelet with three vanishing moments, sym4 stands for Symlets wavelet with four vanishing moments, dmey stands for discrete Meyer wavelet, bior3.1 stands for biorthogonal spline wavelets with orders (vanishing moments) and . The values of Std, Bias and RMSE are the estimated versions of those for 1000 independent copies of FBM with length . The lower bound of octaves js is chosen .

Figure 5.
The Bias and Std for estimators: M1 denotes the first estimator, M2 denotes the second estimator. Std is the standard deviation, Bias . The values of Std and Bias are the estimated versions of those for 1000 independent copies of FBM with length .
Figure 5.
The Bias and Std for estimators: M1 denotes the first estimator, M2 denotes the second estimator. Std is the standard deviation, Bias . The values of Std and Bias are the estimated versions of those for 1000 independent copies of FBM with length .

Figure 6.
The Bias for estimators: circ denotes the circulant embedding method for simulation of FBM, chol denotes the Cholesky method for simulation of FBM. Bias . The values of Bias are the estimated versions of those for 1000 independent copies of FBM with length . The lower bound of octaves js is chosen . The used wavelet is the Daubechies wavelet with vanishing moments.
Figure 6.
The Bias for estimators: circ denotes the circulant embedding method for simulation of FBM, chol denotes the Cholesky method for simulation of FBM. Bias . The values of Bias are the estimated versions of those for 1000 independent copies of FBM with length . The lower bound of octaves js is chosen . The used wavelet is the Daubechies wavelet with vanishing moments.

Figure 7.
The Bias and Std for estimators: Init1 denotes the initialization by itself (or by (27)), Init2 denotes the initialization denoted by (29). Std is the standard deviation, Bias . The values of Std and Bias are the estimated versions of those for 1000 independent copies of FBM with length .

Figure 8.
The Bias, Std, RMSE for estimators: orig stands for original series without noise, gau stands for Gaussian noise, unm stands for uniform noise, cau stands for Cauchy noise. The values of Std, Bias and RMSE are the estimated versions of those for 1000 independent copies of FBM with noise. The data length . The lower bound of octaves js is chosen . The used wavelet is the Daubechies wavelet with vanishing moments
Figure 8.
The Bias, Std, RMSE for estimators: orig stands for original series without noise, gau stands for Gaussian noise, unm stands for uniform noise, cau stands for Cauchy noise. The values of Std, Bias and RMSE are the estimated versions of those for 1000 independent copies of FBM with noise. The data length . The lower bound of octaves js is chosen . The used wavelet is the Daubechies wavelet with vanishing moments


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Estimation quality for FBM series. On the left, the for minimum MSE and its Bias, Std, RMSE is given. On the right, the same quantities with are also given for comparison. RMSE is the square root of MSE. All the results are the estimated versions of Bias, Std, RMSE for 1000 independent copies of FBM with length . The used wavelet is the Daubechies wavelet with vanishing moments.
Table 1.
Estimation quality for FBM series. On the left, the for minimum MSE and its Bias, Std, RMSE is given. On the right, the same quantities with are also given for comparison. RMSE is the square root of MSE. All the results are the estimated versions of Bias, Std, RMSE for 1000 independent copies of FBM with length . The used wavelet is the Daubechies wavelet with vanishing moments.
| H | Bias | Std | RMSE | Bias | Std | RMSE | ||
|---|---|---|---|---|---|---|---|---|
| 0.05 | 7 | −0.0122 | 0.0133 | 0.0180 | 3 | −0.1450 | 0.0030 | 0.1451 |
| 0.10 | 6 | −0.0087 | 0.0091 | 0.0126 | 3 | −0.0801 | 0.0031 | 0.0801 |
| 0.15 | 6 | −0.0046 | 0.0090 | 0.0101 | 3 | −0.0499 | 0.0030 | 0.0500 |
| 0.20 | 5 | −0.0056 | 0.0064 | 0.0085 | 3 | −0.0330 | 0.0031 | 0.0331 |
| 0.25 | 5 | −0.0032 | 0.0063 | 0.0071 | 3 | −0.0226 | 0.0032 | 0.0228 |
| 0.30 | 5 | −0.0019 | 0.0063 | 0.0066 | 3 | −0.0160 | 0.0032 | 0.0163 |
| 0.35 | 4 | −0.0038 | 0.0045 | 0.0059 | 3 | −0.0115 | 0.0032 | 0.0119 |
| 0.40 | 4 | −0.0023 | 0.0047 | 0.0052 | 3 | −0.0081 | 0.0033 | 0.0087 |
| 0.45 | 4 | −0.0019 | 0.0048 | 0.0052 | 3 | −0.0060 | 0.0033 | 0.0068 |
| 0.50 | 4 | −0.0012 | 0.0048 | 0.0049 | 3 | −0.0044 | 0.0033 | 0.0056 |
| 0.55 | 3 | −0.0030 | 0.0034 | 0.0046 | 3 | −0.0030 | 0.0034 | 0.0046 |
| 0.60 | 3 | −0.0025 | 0.0036 | 0.0044 | 3 | −0.0025 | 0.0036 | 0.0044 |
| 0.65 | 3 | −0.0018 | 0.0034 | 0.0038 | 3 | −0.0018 | 0.0034 | 0.0038 |
| 0.70 | 3 | −0.0014 | 0.0035 | 0.0038 | 3 | −0.0014 | 0.0035 | 0.0038 |
| 0.75 | 3 | −0.0013 | 0.0037 | 0.0039 | 3 | −0.0013 | 0.0037 | 0.0039 |
| 0.80 | 3 | −0.0008 | 0.0036 | 0.0037 | 3 | −0.0008 | 0.0036 | 0.0037 |
| 0.85 | 3 | −0.0006 | 0.0037 | 0.0038 | 3 | −0.0006 | 0.0037 | 0.0038 |
| 0.90 | 3 | −0.0006 | 0.0037 | 0.0038 | 3 | −0.0006 | 0.0037 | 0.0038 |
| 0.95 | 3 | −0.0006 | 0.0038 | 0.0038 | 3 | −0.0006 | 0.0038 | 0.0038 |
Table 2.
Estimation quality for FBM series. On the left, the for minimum MSE and its Bias, Std, RMSE is given. On the right, the same quantities with are also given for comparison. RMSE is the square root of MSE. All the results are the estimated versions of Bias, Std, RMSE for 1000 independent copies of FBM. The used wavelet is the Daubechies wavelet with vanishing moments.
Table 2.
Estimation quality for FBM series. On the left, the for minimum MSE and its Bias, Std, RMSE is given. On the right, the same quantities with are also given for comparison. RMSE is the square root of MSE. All the results are the estimated versions of Bias, Std, RMSE for 1000 independent copies of FBM. The used wavelet is the Daubechies wavelet with vanishing moments.
| H | n | Bias | Std | RMSE | Bias | Std | RMSE | ||
|---|---|---|---|---|---|---|---|---|---|
| 2 | −0.0632 | 0.0473 | 0.0789 | 3 | −0.0239 | 0.0776 | 0.0811 | ||
| 3 | −0.0220 | 0.0305 | 0.0376 | 3 | −0.0220 | 0.0305 | 0.0376 | ||
| 0.3 | 4 | −0.0080 | 0.0202 | 0.0217 | 3 | −0.0186 | 0.0136 | 0.0231 | |
| 4 | −0.0063 | 0.0096 | 0.0115 | 3 | −0.0167 | 0.0065 | 0.0179 | ||
| 5 | −0.0019 | 0.0063 | 0.0066 | 3 | −0.0160 | 0.0032 | 0.0163 | ||
| 2 | −0.0276 | 0.0479 | 0.0553 | 3 | −0.0078 | 0.0779 | 0.0783 | ||
| 2 | −0.0231 | 0.0202 | 0.0307 | 3 | −0.0073 | 0.0312 | 0.0320 | ||
| 0.5 | 3 | −0.0048 | 0.0142 | 0.0149 | 3 | −0.0048 | 0.0142 | 0.0149 | |
| 3 | −0.0050 | 0.0068 | 0.0085 | 3 | −0.0050 | 0.0068 | 0.0085 | ||
| 4 | −0.0012 | 0.0048 | 0.0049 | 3 | −0.0044 | 0.0033 | 0.0056 | ||
| 2 | −0.0109 | 0.0526 | 0.0537 | 3 | −0.0056 | 0.0878 | 0.0879 | ||
| 2 | −0.0061 | 0.0233 | 0.0241 | 3 | −0.0010 | 0.0359 | 0.0359 | ||
| 0.8 | 2 | −0.0062 | 0.0106 | 0.0123 | 3 | −0.0015 | 0.0159 | 0.0160 | |
| 3 | −0.0010 | 0.0074 | 0.0075 | 3 | −0.0010 | 0.0074 | 0.0075 | ||
| 3 | −0.0008 | 0.0036 | 0.0037 | 3 | −0.0008 | 0.0036 | 0.0037 |
Table 3.
Estimations of ratio of variance.
| H | 0.05 | 0.10 | 0.15 | 0.20 | 0.25 | 0.30 | 0.35 | 0.40 | 0.45 | 0.50 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2.41 | 2.18 | 2.32 | 2.27 | 2.16 | 2.19 | 2.27 | 2.22 | 2.18 | 2.13 | |
| H | 0.55 | 0.60 | 0.65 | 0.70 | 0.75 | 0.80 | 0.85 | 0.90 | 0.95 | |
| 1.92 | 2.08 | 2.00 | 1.94 | 1.76 | 1.95 | 1.71 | 1.89 | 1.88 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wu, L. A Note on Wavelet-Based Estimator of the Hurst Parameter. Entropy 2020, 22, 349. https://doi.org/10.3390/e22030349
AMA Style
Wu L. A Note on Wavelet-Based Estimator of the Hurst Parameter. Entropy. 2020; 22(3):349. https://doi.org/10.3390/e22030349
Chicago/Turabian StyleWu, Liang. 2020. "A Note on Wavelet-Based Estimator of the Hurst Parameter" Entropy 22, no. 3: 349. https://doi.org/10.3390/e22030349
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.