Semi-Supervised Bidirectional Long Short-Term Memory and Conditional Random Fields Model for Named-Entity Recognition Using Embeddings from Language Models Representations

Abstract
:1. Introduction
- We propose a semi-supervised model named SCRNER which is composed by the bidirectional long short-term memory (BiLSTM) and conditional random fields (CRF) to recognize cultural relic entities;
- We propose a sample selection strategy named the relabeled strategy, which selects samples of high confidence iteratively, aiming to improve the performance of the proposed semi-supervised model with limited hand-labeled data;
- We pretrain the ELMo model to generate the context word embedding, which makes our proposed model capable of capturing not only the features of the focal character but also the contextual information of the related word.
2. Related Work
2.1. Embeddings for NER
2.1.1. Word-Level Embedding
2.1.2. Character-Level Embedding
2.1.3. Character and Word-Level Embedding
2.1.4. ELMo Embeddings
2.2. Model for NER
2.2.1. CRF Model for NER
2.2.2. LSTM Model for NER
2.2.3. BiLSTM_CRF Model for NER
2.3. Semi-Supervised Learning for NER
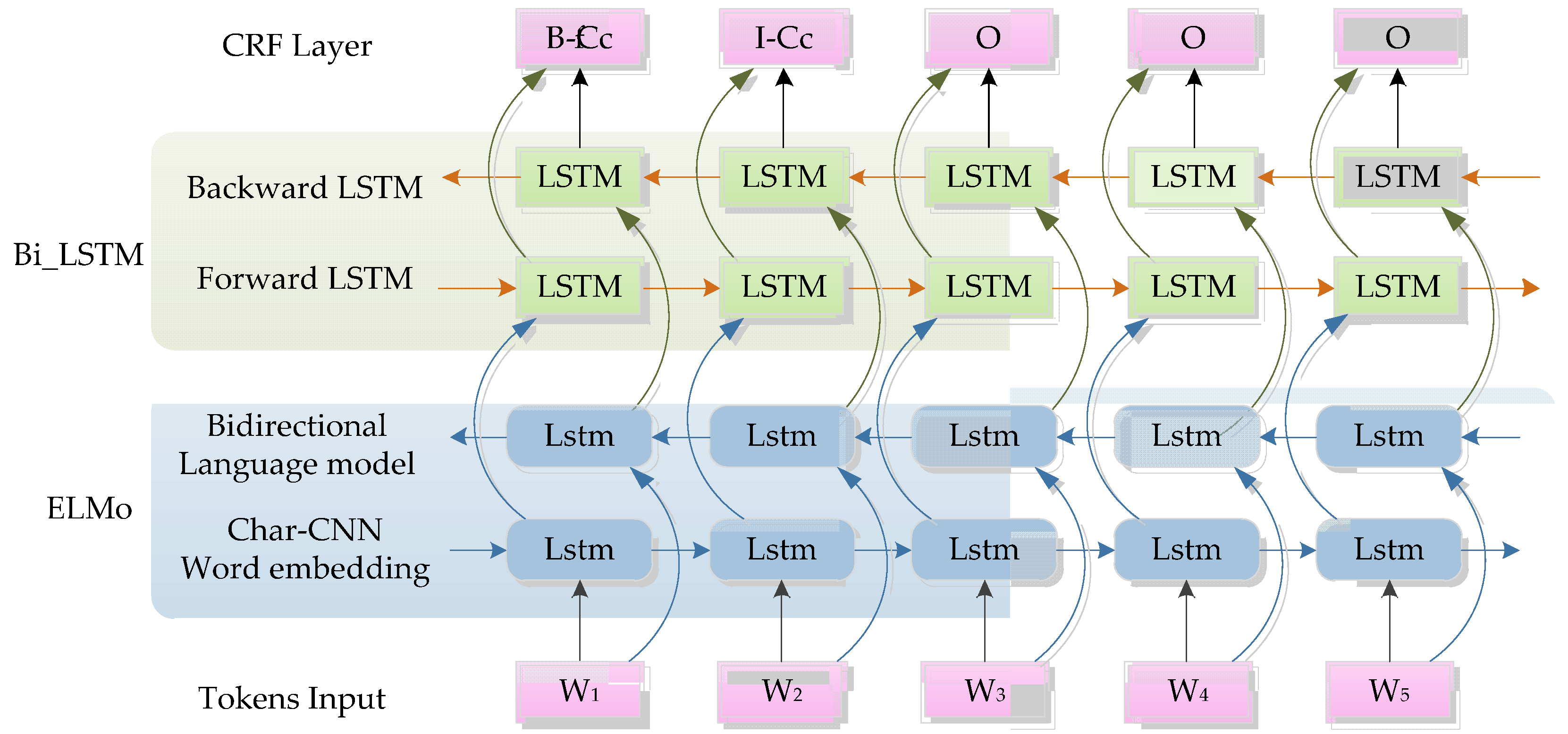
3. Methods
3.1. ELMo Contextual Word Embedding
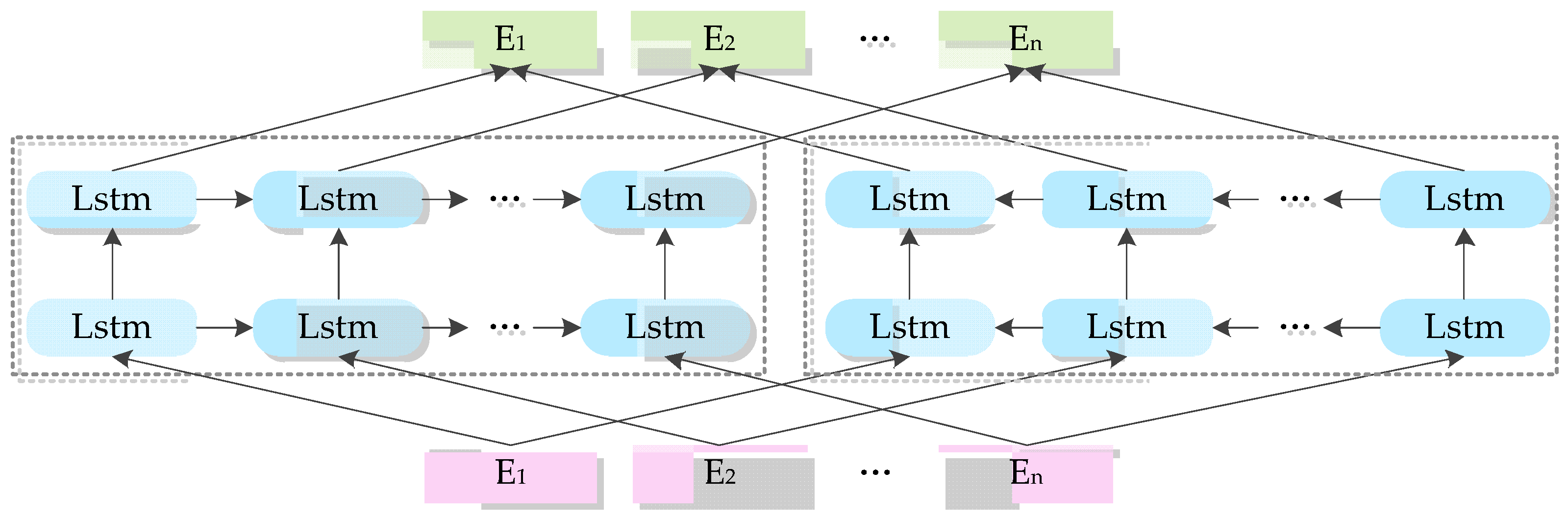
3.2. Neural Network Architecture
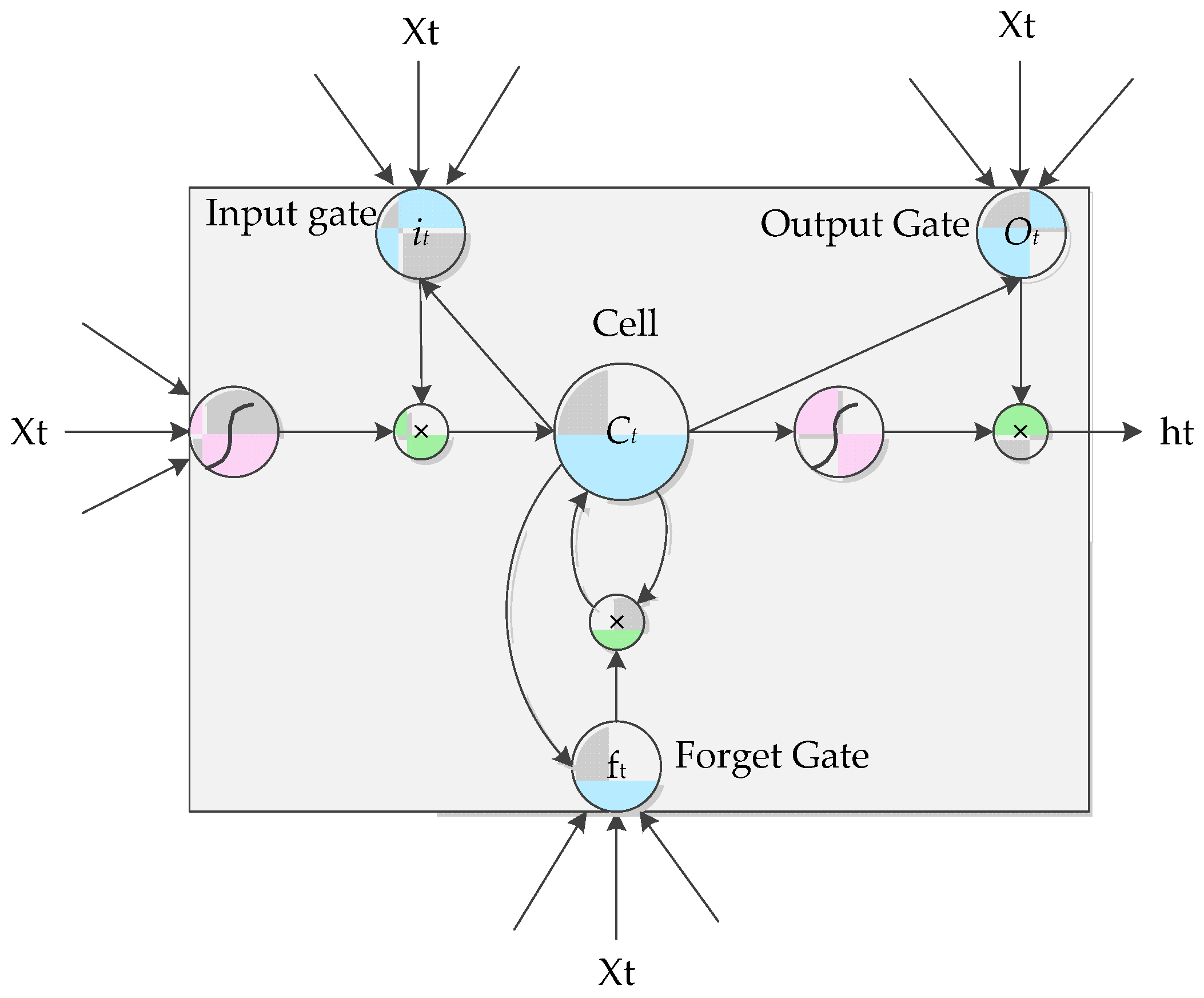
3.2.1. LSTM Layer
3.2.2. CRF Layer
3.3. Semi-Supervised Method
3.3.1. Self-Learning Algorithm
| Algorithm 1: The self-learning algorithm using relabeled strategy |
| Input: is the set of labeled data. is the set of unlabeled data. is the base model. is the Confidence level. Output: Trained classifier. |
| Step 1: Pretrain the model with labeled data and obtain the pre-trained model . |
| Repeat: |
| Step 2: Predict the unlabeled data using . |
| Step 3: Select the instances with the predicted probability more than per iteration () using relabeled strategy. |
| Step 4: Expand with i.e., and remove from U. |
| Step 5: Train the model with L. |
| Until: some stopping criterion is met or U is empty. |
3.3.2. Relabeled Strategy
4. Experimental Results
4.1. Data Preprocessing and Annotation
4.1.1. Data Sets
4.1.2. Data Preprocessing
4.1.3. Data Annotation
4.2. Evaluation
4.2.1. Model Evaluation
4.2.2. Baseline Models
- A unified model in which semi-supervised learning can learn in-domain unlabeled information by self-training, proposed by Xu et al. [36];
- A semi-supervised learning based on the CRFs model for named-entity recognition, proposed by Liao et al. [37];
- A semi-supervised neural tagging that extended the self-training algorithm proposed by Luan et al. [39];
- A combination framework of LSTM and CRF models to complete our NER task, proposed by Yang et al. [11];
- A semi-supervised algorithm that utilized the classical self-training based on our framework named CSCRNER.
4.3. Evaluation Results
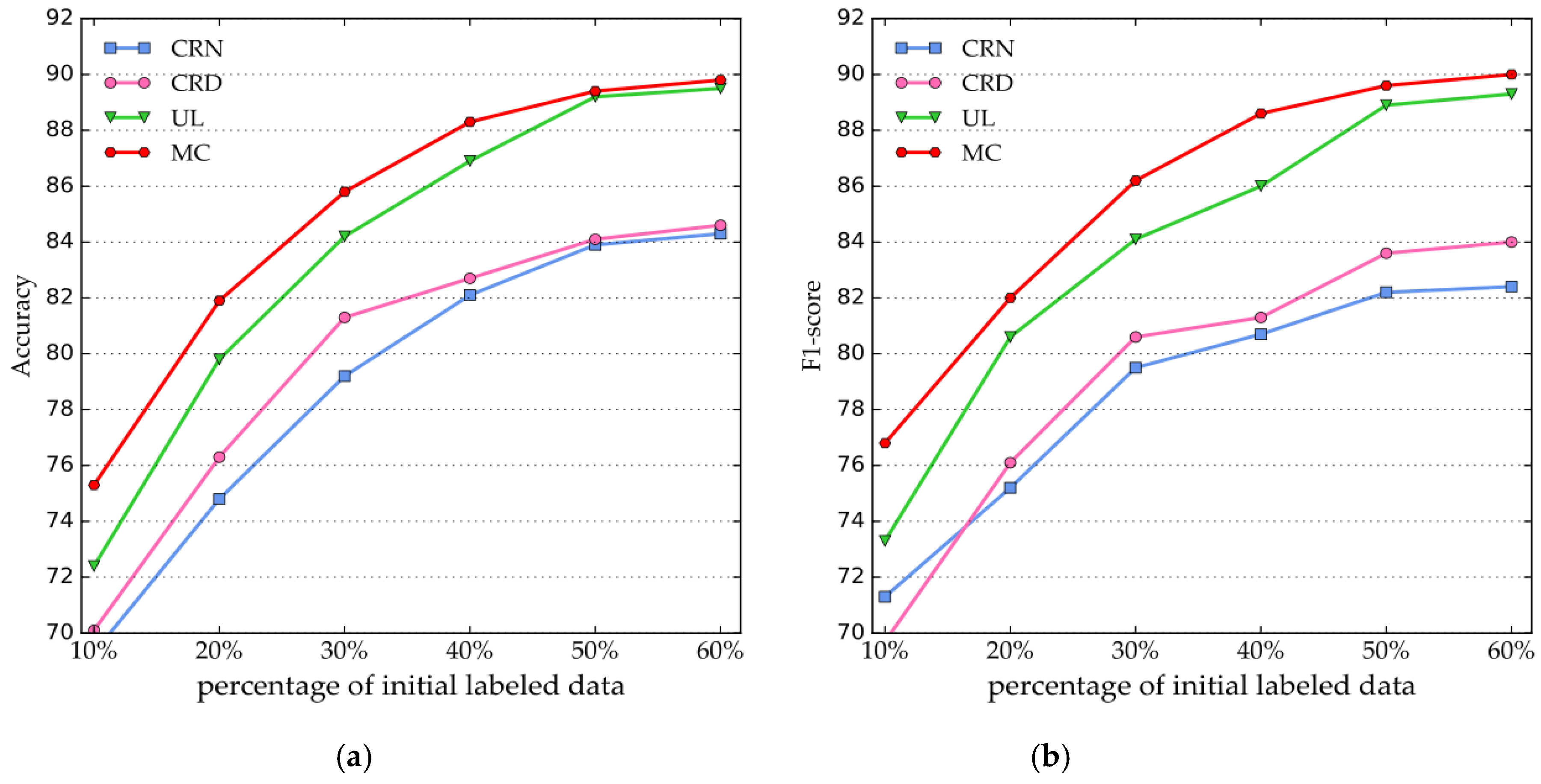
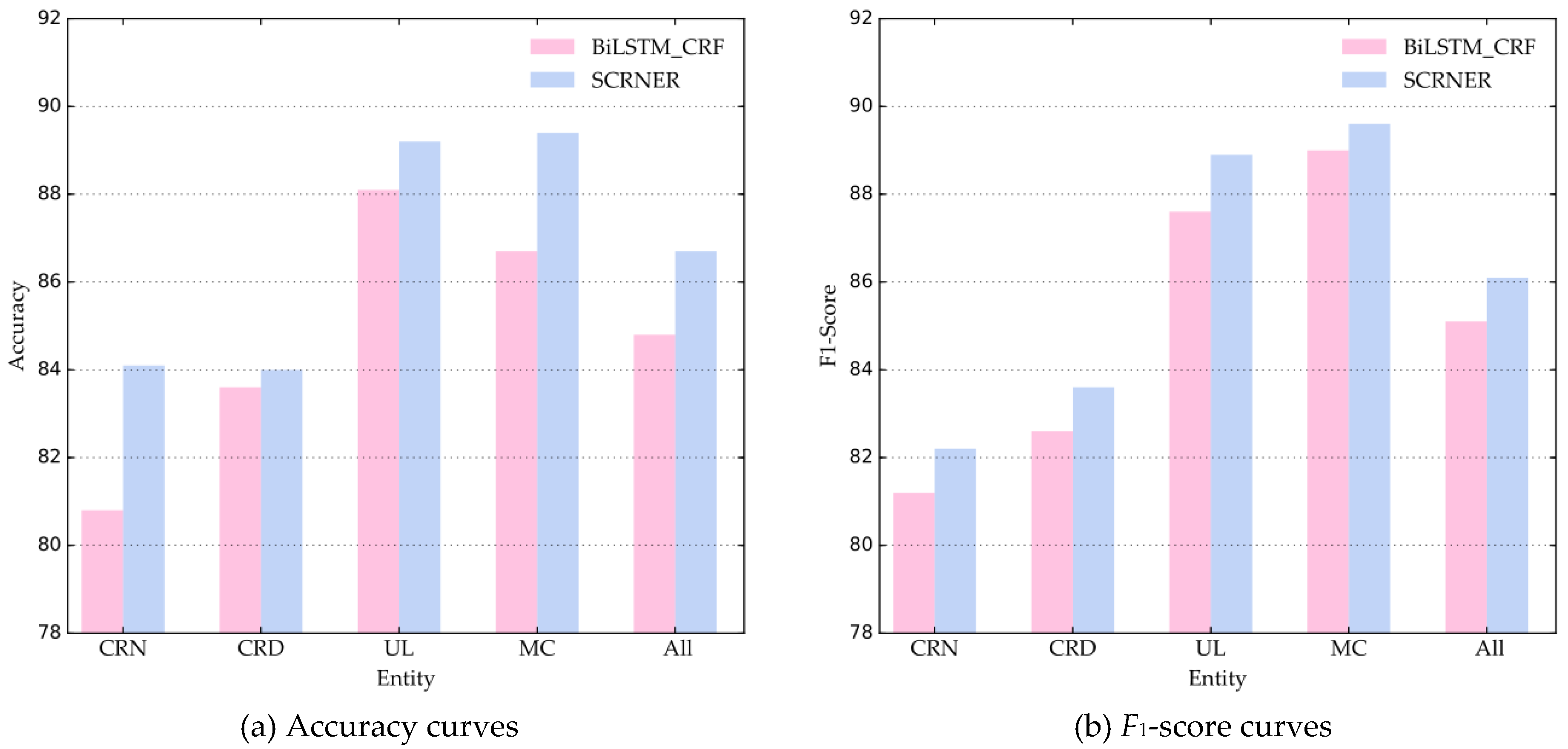
4.3.1. Performance Comparison of SCRNER and Semi-Supervised Baseline Methods
4.3.2. Performance Comparison of Percentage of Initial Labeled Data
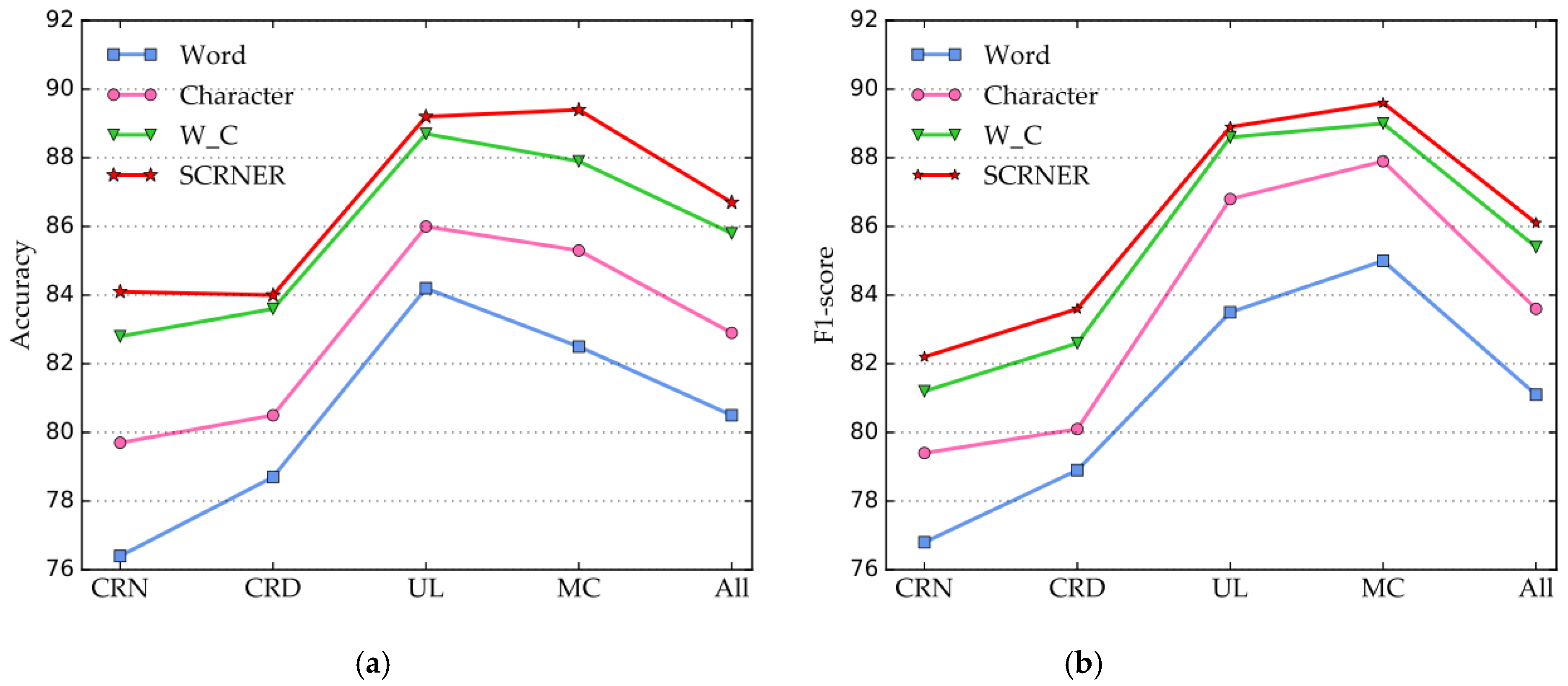
4.3.3. Performance Comparison of SCNER and Word Representations
4.3.4. Performance Comparison of SCRNER in Four Entities
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Schreiber, G.; Amin, A.; Aroyo, L.; van Assem, M.; de Boer, V.; Hardman, L.; Hildebrand, M.; Omelayenko, B.; van Osenbruggen, J.; Wielemaker, J.; et al. Semantic annotation and search of cultural-heritage collections: The MultimediaN E-Culture demonstrator. J. Web Semant. 2008, 6, 243–249. [Google Scholar] [CrossRef] [Green Version]
- Brando, C.; Frontini, F.; Ganascia, J.G. Disambiguation of named entities in cultural heritage texts using linked data sets. In Proceedings of the East European Conference on Advances in Databases and Information Systems, Poitiers, France, 8–11 September 2015; pp. 505–514. [Google Scholar]
- Ardissono, L.; Lucenteforte, M.; Mauro, N.; Savoca, A.; Voghera, A.; La Riccia, L. Exploration of cultural heritage information via textual search queries. In Proceedings of the 18th International Conference on Human-Computer Interaction with Mobile Devices and Services Adjunct, Florence, Italy, 6–9 September 2016; pp. 992–1001. [Google Scholar]
- Hyvönen, E.; Rantala, H. Knowledge-based Relation Discovery in Cultural Heritage Knowledge Graphs; CEUR-WS: Darmstadt, Germany, 2019; pp. 230–239. [Google Scholar]
- White, M.; Patoli, Z.; Pascu, T. Knowledge networking through social media for a digital heritage resource. In Proceedings of the 2013 Digital Heritage International Congress (DigitalHeritage), Marseille, France, 28 October–1 November 2013. [Google Scholar] [CrossRef]
- Yadav, V.; Bethard, S. A survey on recent advances in named entity recognition from deep learning models. arXiv 2019, arXiv:1910.11470. [Google Scholar]
- Peng, N.; Dredze, M. Named entity recognition for Chinese social media with jointly trained embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 548–554. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Li, K.; Ai, W.; Tang, Z.; Zhang, F.; Jiang, L.; Li, K.; Hwang, K. Hadoop recognition of biomedical named entity using conditional random fields. IEEE Trans. Parallel Distrib. 2014, 26, 3040–3051. [Google Scholar] [CrossRef]
- Saha, S.K.; Sarkar, S.; Mitra, P. Feature selection techniques for maximum entropy based biomedical named entity recognition. J. Biomed. Inf. 2009, 42, 905–911. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, H.; Gao, H. Toward sustainable virtualized healthcare: Extracting medical entities from Chinese online health consultations using deep neural networks. Sustainability 2018, 10, 3292. [Google Scholar] [CrossRef] [Green Version]
- Chapelle, O.; Scholkopf, B.; Zien, A. Semi-supervised learning (chapelle, o. et al., eds.; 2006) [book reviews]. IEEE Trans. Neural Netw. 2009, 20, 542. [Google Scholar] [CrossRef]
- Triguero, I.; García, S.; Herrera, F. Self-labeled techniques for semi-supervised learning: Taxonomy, software and empirical study. Knowled. Inf. Syst. 2015, 42, 245–284. [Google Scholar] [CrossRef]
- Veselý, K.; Hannemann, M.; Burget, L. Semi-supervised training of deep neural networks. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 267–272. [Google Scholar]
- Livieris, I.E.; Drakopoulou, K.; Mikropoulos, T.A.; Tampakas, V.; Pintelas, P. An ensemble-based semi-supervised approach for predicting students’ performance. In Research on e-Learning and ICT in Education; Springer: Cham, Switzerland, 2018; pp. 25–42. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Wu, Y.; Xu, J.; Jiang, M.; Zhang, Y.; Xu, H. A study of neural word embeddings for named entity recognition in clinical text. AMIA 2015, 2015, 1326–1333. [Google Scholar]
- Kim, Y.; Jernite, Y.; Sontag, D.; Rush, A.M. Character-Aware neural language models. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; AAAI Press: Palo Alto, CA, USA, 2016; Volume 3, pp. 2741–2749. [Google Scholar]
- Dong, C.; Zhang, J.; Zong, C.; Hattori, M.; Di, H. Character-based LSTM-CRF with radical-level features for Chinese named entity recognition. In Natural Language Understanding and Intelligent Applications; Springer: Cham, Switzerland, 2016; pp. 239–250. [Google Scholar]
- Xu, C.; Wang, F.; Han, J.; Li, C. Exploiting Multiple Embeddings for Chinese Named Entity Recognition. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2269–2272. [Google Scholar]
- Chen, X.; Xu, L.; Liu, Z.; Sun, M.; Luan, H. Joint learning of character and word embeddings. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25 July–1 August 2015. [Google Scholar]
- Zeng, D.; Sun, C.; Lin, L.; Liu, B. LSTM-CRF for drug-named entity recognition. Entropy 2017, 19, 283. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Liu, Y.; Qian, M.; Guan, C.; Yuan, X. Information Extraction from Electronic Medical Records Using Multitask Recurrent Neural Network with Contextual Word Embedding. Appl. Sci. 2019, 9, 3658. [Google Scholar] [CrossRef] [Green Version]
- Straková, J.; Straka, M.; Hajič, J. Neural architectures for nested NER through linearization. arXiv 2019, arXiv:1908.06926. [Google Scholar]
- Dogan, C.; Dutra, A.; Gara, A.; Gemma, A.; Shi, L.; Sigamani, M.; Walters, E. Fine-Grained Named Entity Recognition using ELMo and Wikidata. arXiv 2019, arXiv:1904.10503. [Google Scholar]
- Isozaki, H.; Kazawa, H. Efficient support vector classifiers for named entity recognition. In Proceedings of the 19th International Conference on Computational Linguistics-Volume 1. Association for Computational Linguistics, Taipei, Taiwan, 24 August–1 September 2002; pp. 1–7. [Google Scholar] [CrossRef]
- Bender, O.; Och, F.J.; Ney, H. Maximum entropy models for named entity recognition. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003-Volume 4, Association for Computational Linguistics, Edmonton, AB, Canada, 31 May–1 June 2003; pp. 148–151. [Google Scholar]
- Chen, W.; Zhang, Y.; Isahara, H. Chinese Named Entity Recognition with Conditional Random Fields. Available online: https://www.aclweb.org/anthology/W06-0100 (accessed on 22 February 2020).
- Sobhana, N.; Mitra, P.; Ghosh, S.K. Conditional random field based named entity recognition in geological text. IJCA 2010, 1, 143–147. [Google Scholar] [CrossRef]
- Limsopatham, N.; Collier, N. Bidirectional LSTM for Named Entity Recognition in Twitter Messages. In Proceedings of the 2nd Workshop on Noisy User-generated Text (WNUT), Osaka, Japan, 11 December 2016; pp. 145–152. [Google Scholar]
- Hammerton, J. Named entity recognition with long short-term memory. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003-Volume 4, Association for Computational Linguistics, Edmonton, AB, Canada, 31 May–1 June 2003; pp. 172–175. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Xu, K.; Zhou, Z.; Hao, T.; Liu, W. A bidirectional LSTM and conditional random fields approach to medical named entity recognition. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics, Cairo, Egypt, 9–11 September 2017; Springer: Cham, Switzerland, 2017; pp. 355–365. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Ji, H.; Grishman, R. Data selection in semi-supervised learning for name tagging. In Proceedings of the Workshop on Information Extraction Beyond the Document, Association for Computational Linguistics, Sydney, Australia, 22 July 2006; pp. 48–55. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; He, H.; Sun, X.; Ren, X.; Li, S. Cross-domain and semisupervised named entity recognition in Chinese social media: A unified model. IEEE-ACM Trans. Audio Speech Lang. Process. 2018, 26, 2142–2152. [Google Scholar] [CrossRef]
- Liao, W.; Veeramachaneni, S. A Simple Semi-Supervised Algorithm for Named Entity Recognition. Available online: https://www.aclweb.org/anthology/W09-2208 (accessed on 22 February 2020).
- Liu, X.; Zhang, S.; Wei, F.; Zhou, M. Recognizing named entities in tweets. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1, Association for Computational Linguistics, Portland, Oregon, 19–24 June 2011; pp. 359–367. [Google Scholar]
- Luan, Y.; Ostendorf, M.; Hajishirzi, H. Scientific Information Extraction with Semi-supervised Neural Tagging. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2641–2651. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neur. Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Mesnil, G.; He, X.; Deng, L.; Bengio, Y. Investigation of recurrent-neural-network architectures and learning methods for spoken language understanding. Interspeech 2013, 8, 3771–3775. [Google Scholar]
- Ekbal, A.; Haque, R.; Bandyopadhyay, S. Named entity recognition in Bengali: A conditional random field approach. In Proceedings of the Third International Joint Conference on Natural Language Processing: Volume-II, Hyderabad, India, 7–12 January 2008. [Google Scholar]
- Zhang, Q.; Fu, J.; Liu, X.; Huang, X. Adaptive co-attention network for named entity recognition in tweets. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv 2016, arXiv:1603.01354. [Google Scholar]
- Lafferty, J.D.; McCallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Zhu, X.J. Semi-Supervised Learning Literature Survey; University of Wisconsin-Madison: Madison, WI, USA, 2005; pp. 11–13. [Google Scholar]
- Livieris, I. A new ensemble semi-supervised self-labeled algorithm. Informatica 2019, 43, 221–234. [Google Scholar] [CrossRef] [Green Version]
- Yarowsky, D. Unsupervised word sense disambiguation rivaling supervised methods. In Proceedings of the 33rd Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 1995; pp. 189–196. [Google Scholar]
- Didaci, L.; Roli, F. Using co-training and self-training in semi-supervised multiple classifier systems. In Proceedings of the Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR), Hong Kong, China, 17–19 August 2006; pp. 522–530. [Google Scholar]
- Rustam, F.; Ashraf, I.; Mehmood, A.; Ullah, S.; Choi, G.S. Tweets Classification on the Base of Sentiments for US Airline Companies. Entropy 2019, 21, 1078. [Google Scholar] [CrossRef] [Green Version]
- Nikfarjam, A.; Sarker, A.; O’Connor, K.; Ginn, R.; Gonzalez, G. Pharmacovigilance from social media: Mining adverse drug reaction mentions using sequence labeling with word embedding cluster features. J. Am. Med. Inform. Assoc. 2015, 22, 671–681. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, J.; Liu, X.; Dajun, Z.D. Mining e-cigarette adverse events in social media using Bi-LSTM recurrent neural network with word embedding representation. J. Am. Med. Inform. Assoc. 2017, 25, 72–80. [Google Scholar] [CrossRef] [PubMed]
- Luan, Y.; Wadden, D.; He, L.; Shah, A.; Ostendorf, M.; Hajishirzi, H. A general framework for information extraction using dynamic span graphs. arXiv 2019, arXiv:1904.03296. [Google Scholar]
- Salazar, A.; Safont, G.; Vergara, L. Semi-supervised learning for imbalanced classification of credit card transactions. In Proceedings of the 2018 IEEE International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar] [CrossRef]
- Zhu, X.; Goldberg, A.B. Introduction to Semi-Supervised Learning: Synthesis Lectures on Artificial Intelligence and Machine Learning; Morgan & Claypool Publisher: San Rafael, CL, USA, 2009; pp. 1–130. [Google Scholar]
- Livieris, I.E.; Drakopoulou, K.; Tampakas, V.T.; Mikropoulos, T.A.; Pintelas, P. Predicting secondary school students’ performance utilizing a semi-supervised learning approach. J. Educ. Comput. Res. 2019, 57, 448–470. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | CRN(%) | CRD(%) | UL(%) | MC(%) | All(%) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | |
| Xu et al. [36] | 76.7 | 76.2 | 78.5 | 76.8 | 84.8 | 83.1 | 82.5 | 83.4 | 80.6 | 79.9 |
| Liao et.al. [37] | 79.2 | 77.1 | 81.9 | 79.5 | 87.5 | 84.9 | 85.2 | 85.6 | 83.5 | 81.8 |
| CSCRNER | 82.6 | 80.3 | 82.0 | 80.4 | 88.3 | 87.1 | 87.4 | 86.8 | 85.1 | 83.7 |
| Luan et al. [39] | 83.4 | 81.1 | 83.6 | 81.3 | 88.7 | 87.6 | 88.1 | 88.7 | 86.0 | 84.7 |
| SCRNER | 84.1 | 82.2 | 84.0 | 83.6 | 89.2 | 88.9 | 89.4 | 89.6 | 86.7 | 86.1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Geng, G.; Chen, J. Semi-Supervised Bidirectional Long Short-Term Memory and Conditional Random Fields Model for Named-Entity Recognition Using Embeddings from Language Models Representations. Entropy 2020, 22, 252. https://doi.org/10.3390/e22020252
Zhang M, Geng G, Chen J. Semi-Supervised Bidirectional Long Short-Term Memory and Conditional Random Fields Model for Named-Entity Recognition Using Embeddings from Language Models Representations. Entropy. 2020; 22(2):252. https://doi.org/10.3390/e22020252
Chicago/Turabian StyleZhang, Min, Guohua Geng, and Jing Chen. 2020. "Semi-Supervised Bidirectional Long Short-Term Memory and Conditional Random Fields Model for Named-Entity Recognition Using Embeddings from Language Models Representations" Entropy 22, no. 2: 252. https://doi.org/10.3390/e22020252