Entropy-Based Measures of Hypnopompic Heart Rate Variability Contribute to the Automatic Prediction of Cardiovascular Events

Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Signal Processing
2.3. HRV Analyses
2.4. Automatic Prediction of CVD Outcomes
2.4.1. A Brief Introduction to XGBoost Algorithm
2.4.2. K-fold Cross Validation (CV)
2.4.3. Dealing with Class-Imbalance Data in Short-Term Prediction
2.4.4. Performance Evaluation of Predictive Models
2.5. Statistical Analyses
3. Results
3.1. Clinical Characteristics
3.2. HRV Metrics
3.3. Prediction of CVD Outcomes Based on XGBoost
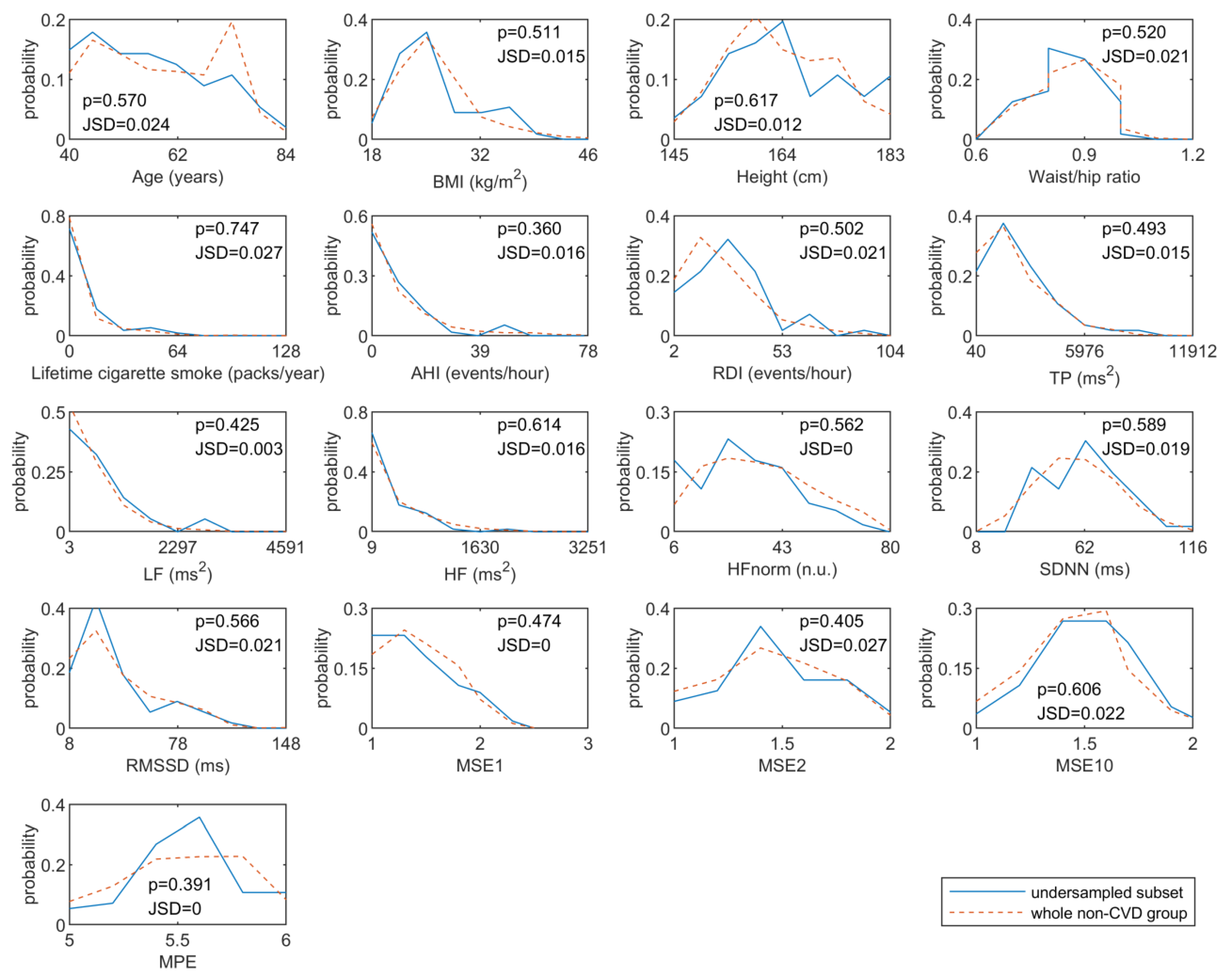
3.3.1. Results of Distribution Similarity Tests for Under-Sampling
3.3.2. Performance of CVD Outcomes Prediction
3.3.3. Independent Predictive Ability of Hypnopompic HRV
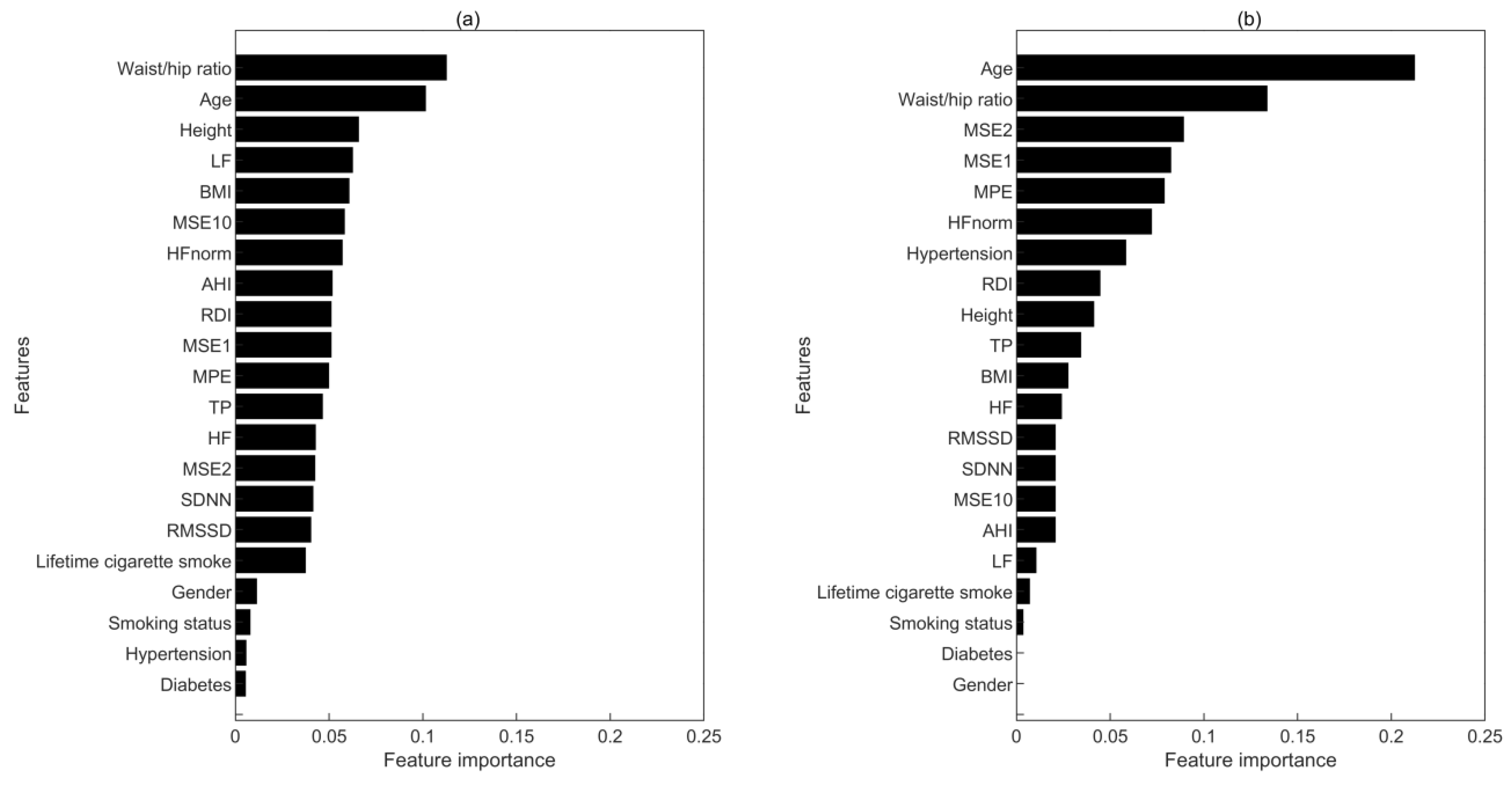
3.3.4. The Importance of Features in Prediction Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
References
- Clark, H. NCDs: A challenge to sustainable human development. Lancet 2013, 381, 510–511. [Google Scholar] [CrossRef]
- Roth, G.A.; Johnson, C.; Abajobir, A.; Abd-Allah, F.; Abera, S.F.; Abyu, G.; Ahmed, M.; Aksut, B.; Alam, T.; Alam, K.; et al. Global, Regional, and National Burden of Cardiovascular Diseases for 10 Causes, 1990 to 2015. J. Am. Coll. Cardiol. 2017, 70, 1–25. [Google Scholar] [CrossRef] [PubMed]
- Manfredini, R.; Boari, B.; Salmi, R.; Fabbian, F.; Pala, M.; Tiseo, R.; Portaluppi, F. Twenty-Four-Hour Patterns in Occurrence and Pathophysiology of Acute Cardiovascular Events and Ischemic Heart Disease. Chronobiol. Int. 2013, 30, 6–16. [Google Scholar] [CrossRef]
- Goff, E.A.; Nicholas, C.L.; Simonds, A.K.; Trinder, J.; Morrell, M.J. Differential effects of waking from non-rapid eye movement versus rapid eye movement sleep on cardiovascular activity. J. Sleep Res. 2010, 19, 201–206. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Cui, Y.; Yogendranath, P.; Wang, N. Blood pressure and heart rate variability are linked with hyperphosphatemia in chronic kidney disease patients. Chronobiol. Int. 2018, 35, 1329–1334. [Google Scholar] [CrossRef] [PubMed]
- Takeda, N.; Maemura, K. Circadian clock and the onset of cardiovascular events. Hypertens. Res. 2016, 39, 383–390. [Google Scholar] [CrossRef] [PubMed]
- Amici, A.; Cicconetti, P.; Sagrafoli, C.; Baratta, A.; Passador, P.; Pecci, T.; Tassan, G.; Verrusio, W.; Marigliano, V.; Cacciafesta, M. Exaggerated morning blood pressure surge and cardiovascular events. A 5-year longitudinal study in normotensive and well-controlled hypertensive elderly. Arch. Gerontol. Geriatr. 2009, 49, e105–e109. [Google Scholar] [CrossRef]
- Furlan, R.; Guzzetti, S.; Crivellaro, W.; Dassi, S.; Tinelli, M.; Baselli, G.; Cerutti, S.; Lombardi, F.; Pagani, M.; Malliani, A. Continuous 24-h assessment of the neural regulation of systemic arterial pressure and RR variabilities in ambulant subjects. Circulation 1990, 81, 537–547. [Google Scholar] [CrossRef] [Green Version]
- Vandeborne, P.; Nguyen, H.; Biston, P.; Linkowski, P.; Degaute, J.P. Effects of wake and sleep stages on the 24-h autonomic control of blood-pressure and heart-rate in recumbent men. Am. J. Physiol. 1994, 266, H548–H554. [Google Scholar]
- Kirizawa, J.M.; Garner, D.M.; Arab, C.; Valenti, V.E. Is heart rate variability a valuable method to investigate cardiac autonomic dysfunction in subjects with leukemia? A systematic review to evaluate its importance in clinical practice. Support. Care Cancer 2020, 28, 35–42. [Google Scholar] [CrossRef]
- Escorihuela, R.M.; Capdevila, L.; Castro, J.R.; Zaragoza, M.C.; Maurel, S.; Alegre, J.; Castro-Marrero, J. Reduced heart rate variability predicts fatigue severity in individuals with chronic fatigue syndrome/myalgic encephalomyelitis. J. Transl. Med. 2020, 18, 4. [Google Scholar] [CrossRef] [PubMed]
- Camm, A.J.; Malik, M.; Bigger, J.T.; Breithardt, G.; Cerutti, S.; Cohen, R.J.; Coumel, P.; Fallen, E.L.; Kennedy, H.L.; Kleiger, R.E.; et al. Heart rate variability—Standards of measurement, physiological interpretation, and clinical use. Circulation 1996, 93, 1043–1065. [Google Scholar]
- Stanley, H.E.; Buldyrev, S.V.; Goldberger, A.L.; Hausdorff, J.M.; Havlin, S.; Mietus, J.; Peng, C.K.; Sciortino, F.; Simons, M. Fractal landscapes in biological-systems—long-range correlations in DNA and interbeat heart intervals. Phys. A 1992, 191, 1–12. [Google Scholar] [CrossRef]
- Ma, Y.; Wu, C.-w.; Peng, C.-K.; Ahn, A.; Bertisch, S.M.; Lipsitz, L.A.; Yeh, G.Y.; Manor, B.; Novak, V.; Hausdorff, J.M.; et al. Complexity-Based Measures of Heart Rate Dynamics in Older Adults Following Long- and Short-Term Tai Chi Training: Cross-sectional and Randomized Trial Studies. Sci. Rep. 2019, 9, 7500. [Google Scholar] [CrossRef] [PubMed]
- Takase, B. Role of Heart Rate Variability in Non-Invasive Electrophysiology: Prognostic Markers of Cardiovascular Disease. J. Arrhythmia 2010, 26, 227–237. [Google Scholar] [CrossRef]
- La Rovere, M.T.; Bigger, J.T.; Marcus, F.I.; Mortara, A.; Schwartz, P.J.; Investigators, A. Baroreflex sensitivity and heart-rate variability in prediction of total cardiac mortality after myocardial infarction. Lancet 1998, 351, 478–484. [Google Scholar] [CrossRef]
- Kleiger, R.E.; Miller, J.P.; Bigger, J.T., Jr.; Moss, A.J. Decreased heart rate variability and its association with increased mortality after acute myocardial infarction. Am. J. Cardiol. 1987, 59, 256–262. [Google Scholar] [CrossRef]
- Nolan, J.; Batin, P.D.; Andrews, R.; Lindsay, S.J.; Brooksby, P.; Mullen, M.; Baig, W.; Flapan, A.D.; Cowley, A.; Prescott, R.J.; et al. Prospective study of heart rate variability and mortality in chronic heart failure—Results of the United Kingdom heart failure evaluation and assessment of risk trial (UK-Heart). Circulation 1998, 98, 1510–1516. [Google Scholar] [CrossRef] [Green Version]
- Ho, Y.L.; Lin, C.; Lin, Y.H.; Lo, M.T. The Prognostic Value of Non-Linear Analysis of Heart Rate Variability in Patients with Congestive Heart Failure—A Pilot Study of Multiscale Entropy. PLoS ONE 2011, 6, e18699. [Google Scholar] [CrossRef] [Green Version]
- Watanabe, E.; Kiyono, K.; Hayano, J.; Yamamoto, Y.; Inamasu, J.; Yamamoto, M.; Ichikawa, T.; Sobue, Y.; Harada, M.; Ozaki, M. Multiscale Entropy of the Heart Rate Variability for the Prediction of an Ischemic Stroke in Patients with Permanent Atrial Fibrillation. PLoS ONE 2015, 10, e0137144. [Google Scholar] [CrossRef]
- Graff, B.; Graff, G.; Makowiec, D.; Kaczkowska, A.; Wejer, D.; Budrejko, S.; Kozłowski, D.; Narkiewicz, K. Entropy Measures in the Assessment of Heart Rate Variability in Patients with Cardiodepressive Vasovagal Syncope. Entropy 2015, 17, 1007–1022. [Google Scholar] [CrossRef] [Green Version]
- Naranjo, C.C.; Sanchez-Rodriguez, L.M.; Martinez, M.B.; Baez, M.E.; Garcia, A.M. Permutation entropy analysis of heart rate variability for the assessment of cardiovascular autonomic neuropathy in type 1 diabetes mellitus. Comput. Biol. Med. 2017, 86, 90–97. [Google Scholar] [CrossRef] [PubMed]
- Hippisley-Cox, J.; Coupland, C.; Vinogradova, Y.; Robson, J.; Minhas, R.; Sheikh, A.; Brindle, P. Predicting cardiovascular risk in England and Wales: Prospective derivation and validation of QRISK2. Br. Med. J. 2008, 336, 1475. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marma, A.K.; Lloyd-Jones, D.M. Systematic Examination of the Updated Framingham Heart Study General Cardiovascular Risk Profile. Circulation 2009, 120, 384. [Google Scholar] [CrossRef] [Green Version]
- Ong, M.E.H.; Ng, C.H.L.; Goh, K.; Liu, N.; Koh, Z.X.; Shahidah, N.; Zhang, T.; Fook-Chong, S.; Lin, Z. Prediction of cardiac arrest in critically ill patients presenting to the emergency department using a machine learning score incorporating heart rate variability compared with the modified early warning score. Crit. Care 2012, 16, 12. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Wu, H.; Zhang, X.; Wei, X.; Hou, F.; Ma, Y. Sleep heart rate variability assists the automatic prediction of long-term cardiovascular outcomes. Sleep Med. 2020, 67, 217–224. [Google Scholar] [CrossRef]
- Quan, S.F.; Howard, B.V.; Iber, C.; Kiley, J.P.; Nieto, F.J.; O’Connor, G.T.; Rapoport, D.M.; Redline, S.; Robbins, J.; Samet, J.M.; et al. The sleep heart health study: Design, rationale, and methods. Sleep 1997, 20, 1077–1085. [Google Scholar]
- Pan, J.; Tompkins, W.J. A real-time QRS detection algorithm. IEEE Trans. Biomed. Eng. 1985, 32, 230–236. [Google Scholar] [CrossRef]
- Lippman, N.; Stein, K.M.; Lerman, B.B. Comparison of methods for removal of ectopy in measurement of heart-rate-variability. Am. J. Physiol. 1994, 267, H411–H418. [Google Scholar] [CrossRef]
- Costa, M.; Goldberger, A.L.; Peng, C.K. Multiscale entropy analysis of complex physiologic time series. Phys. Rev. Lett. 2002, 89, 4. [Google Scholar] [CrossRef] [Green Version]
- Bandt, C.; Pompe, B. Permutation entropy: A natural complexity measure for time series. Phys. Rev. Lett. 2002, 88, 4. [Google Scholar] [CrossRef] [PubMed]
- Bian, C.; Qin, C.; Ma, Q.D.Y.; Shen, Q. Modified permutation-entropy analysis of heartbeat dynamics. Phys. Rev. E 2012, 85, 021906. [Google Scholar] [CrossRef] [PubMed]
- Costa, M.; Goldberger, A.L.; Peng, C.K. Multiscale entropy to distinguish physiologic and synthetic RR time series. In Proceedings of the Computers in Cardiology, Memphis, TN, USA, 22–25 September 2002. [Google Scholar]
- Costa, M.; Goldberger, A.L.; Peng, C.K. Multiscale entropy analysis of biological signals. Phys. Rev. E 2005, 71, 021906. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17August 2016. [Google Scholar]
- Cawley, G.C.; Talbot, N.L.C. On Over-fitting in Model Selection and Subsequent Selection Bias in Performance Evaluation. J. Mach. Learn. Res. 2010, 11, 2079–2107. [Google Scholar]
- Chawla, N.V.; Japkowicz, N.; Kotcz, A. Editorial: Special issue on learning from imbalanced data sets. ACM SIGKDD Explor. Newsl. 2004, 6, 1–6. [Google Scholar] [CrossRef]
- Ong, L.D.; LeClare, P.C. The Kolmogorov-Smirnov test for the log-normality of sample cumulative frequency distributions. Health Phys. 1968, 14, 376. [Google Scholar]
- Grosse, I.; Bernaola-Galvan, P.; Carpena, P.; Roman-Roldan, R.; Oliver, J.; Stanley, H.E. Analysis of symbolic sequences using the Jensen-Shannon divergence. Phys. Rev. E 2002, 65, 041905. [Google Scholar] [CrossRef] [Green Version]
- Luque, A.; Carrasco, A.; Martin, A.; de las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Yap, B.W.; Sim, C.H. Comparisons of various types of normality tests. J. Stat. Comput. Simul. 2011, 81, 2141–2155. [Google Scholar] [CrossRef]
- Zheng, H.T.; Yuan, J.B.; Chen, L. Short-Term Load Forecasting Using EMD-LSTM Neural Networks with a Xgboost Algorithm for Feature Importance Evaluation. Energies 2017, 10, 1168. [Google Scholar] [CrossRef] [Green Version]
- Antelmi, I.; De Paula, R.S.; Shinzato, A.R.; Peres, C.A.; Mansur, A.J.; Grupi, C.J. Influence of age, gender, body mass index, and functional capacity on heart rate variability in a cohort of subjects without heart disease. Am. J. Cardiol. 2004, 93, 381–385. [Google Scholar] [CrossRef] [PubMed]
- Castelli, W.P. Epidemiology of coronary heart disease: The Framingham study. Am. J. Med. 1984, 76, 4–12. [Google Scholar] [CrossRef]
- Dalton, M.; Cameron, A.J.; Zimmet, P.Z.; Shaw, J.E.; Jolley, D.; Dunstan, D.W.; Welborn, T.A. Waist circumference, waist-hip ratio and body mass index and their correlation with cardiovascular disease risk factors in Australian adults. J. Intern. Med. 2003, 254, 555–563. [Google Scholar] [CrossRef]
- Percival, D.B.; Walden, A.T. Wavelet Methods for Time Series Analysis (Cambridge Series in Statistical and Probabilistic Mathematics); Cambridge University Press: London, UK, 2000. [Google Scholar]
- Lo, M.T.; Tsai, P.H.; Lin, P.F.; Lin, C.; Yue, L.H. The Nonlinear and nonstationary Properties in EEG Signals: Probing the Complex Fluctuations by Hilbert-Huang Transform. Adv. Adapt. Data Anal. 2009, 1, 461–482. [Google Scholar] [CrossRef]
- Peng, C.K.; Costa, M.; Goldberger, A.L. Adaptive data analysis of complex fluctuations in physiologic time series. Adv. Adapt. Data Anal. 2009, 1, 61–70. [Google Scholar] [CrossRef]
- Voss, A.; Kurths, J.; Kleiner, H.J.; Wessel, N. Improved analysis of heart rate variability by methods of nonlinear dynamics. J. Electrocardiol. 1995, 28, 81–88. [Google Scholar] [CrossRef]
- Hou, F.; Huang, X.; Chen, Y.; Huo, C.; Liu, H.; Ning, X. Combination of equiprobable symbolization and time reversal asymmetry for heartbeat interval series analysis. Phys. Rev. E 2013, 87, 012908. [Google Scholar] [CrossRef] [Green Version]
- Carney, R.M.; Blumenthal, J.A.; Stein, P.K.; Watkins, L.; Catellier, D.; Berkman, L.F.; Czajkowski, S.M.; O’Connor, C.; Stone, P.H.; Freedland, K.E. Depression, heart rate variability, and acute myocardial infarction. Circulation 2001, 104, 2024–2028. [Google Scholar] [CrossRef]
- Stys, A.; Stys, T. Current clinical applications of heart rate variability. Clin. Cardiol. 2010, 21, 719–724. [Google Scholar] [CrossRef] [PubMed]
- Casolo, G.; Balli, E.; Taddei, T.; Amuhasi, J.; Gori, C. Decreased spontaneous heart rate variability in congestive heart failure. Am. J. Cardiol. 1989, 64, 1162–1167. [Google Scholar] [CrossRef]
- Guzzetti, S.; Cogliati, C.; Mezzetti, S.; Turiel, M.; Lombardi, F.; Malliani, A. Heart rate and systolic arterial blood pressure variabilities in the progression of chronic heart failure. Clin. Sci. 1996, 91, 37–39. [Google Scholar] [CrossRef] [PubMed]
- Guzzetti, S.; Magatelli, R.; Borroni, E.; Mezzetti, S. Heart rate variability in chronic heart failure. Auton. Neurosci. 2001, 90, 102–105. [Google Scholar] [CrossRef]
- Guzzetti, S.; Mezzetti, S.; Magatelli, R.; Porta, A.; De Angelis, G.; Rovelli, G.; Malliani, A. Linear and non-linear 24 h heart rate variability in chronic heart failure. Auton. Neurosci. Basic Clin. 2000, 86, 114–119. [Google Scholar] [CrossRef]
- Stefenelli, T.; Berglerklein, J.; Globits, S.; Pacher, R.; Glogar, D. Heart-rate behavior at different stages of congestive-heart-failure. Eur. Heart J. 1992, 13, 902–907. [Google Scholar] [CrossRef] [PubMed]
- Wijbenga, J.A.M.; Balk, A.; Meij, S.H.; Simoons, M.L.; Malik, M. Heart rate variability index in congestive heart failure: Relation to clinical variables and prognosis. Eur. Heart J. 1998, 19, 1719–1724. [Google Scholar] [CrossRef] [Green Version]
- Fujita, H.; Acharya, U.R.; Sudarshan, V.K.; Ghista, D.N.; Sree, S.V.; Eugene, L.W.J.; Koh, J.E.W. Sudden cardiac death (SCD) prediction based on nonlinear heart rate variability features and SCD index. Appl. Soft Comput. 2016, 43, 510–519. [Google Scholar] [CrossRef]
- Carney, R.M.; Freedland, K.E.; Steinmeyer, B.C.; Rubin, E.H.; Stein, P.K.; Rich, M.W. Nighttime heart rate predicts response to depression treatment in patients with coronary heart disease. J. Affect. Disord. 2016, 200, 165–171. [Google Scholar] [CrossRef] [Green Version]
- Serra, A.; Galdi, P.; Tagliaferri, R. Machine learning for bioinformatics and neuroimaging. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, 33. [Google Scholar] [CrossRef]
- Torlay, L.; Perrone-Bertolotti, M.; Thomas, E.; Baciu, M. Machine learning–XGBoost analysis of language networks to classify patients with epilepsy. Brain Inform. 2017, 4, 159–169. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Usage | Metric | Units | Description |
|---|---|---|---|
| on each 5-min HRV segment | TP | ms2 | Total power in frequency range (0.003–0.4 Hz) [12]. |
| LF | ms2 | Power in low frequency range (0.04–0.15 Hz) [12] | |
| HF | ms2 | Power in high frequency range (0.15–0.4 Hz) [12]. | |
| HFnorm | n.u. | HF power in normalized units (HF/(LF + HF) × 100) [12]. | |
| on entire 1-h HRV data | SDNN | ms | Standard deviation of all RR intervals [12]. |
| RMSSD | ms | The square root of the mean of the sum of squares of differences between adjacent RR intervals [12]. | |
| MSE | Multiscale sample entropy [30] of the RR intervals on 10 time scales. To calculate the sample entropy on each scale (denoted as MSE1, MSE2, …, MSE10 sequentially), the embedding dimension was set as 2 and the tolerance as 0.15 × SD, where SD is the standard deviation of the original time series. | ||
| MPE | Modified permutation entropy of RR intervals [31,32], with an embedding dimension value of 4. |
| CVD | non-CVD | p | |
|---|---|---|---|
| Number of participants | 1219 | 998 | |
| Age (years) | 63[58,69] | 60[50,73] | <0.001 * |
| Gender (Male/Female,%) | 47.3/52.7 | 39.2/60.8 | <0.001 * |
| BMI (kg/m2) | 28.2[25.4,31.3] | 27.1[24.4,30.4] | <0.001 * |
| Height (cm) | 167[160,175] | 165[158.8,174] | <0.001 * |
| Waist/hip ratio | 95.1[90.1,99.2] | 89.9[81.5,96.2] | <0.001 * |
| Smoking status (Never/Current/Former,%) | 49.9/7.3/42.8 | 54.6/7.1/38.3 | 0.023 * |
| Lifetime cigarette smoke (packs/year) | 0[0,19] | 0[0,12] | 0.014 * |
| Diabetes (Yes/No,%) | 7.2/92.8 | 3.3/96.7 | <0.001 * |
| Hypertension (Yes/No,%) | 41.5/58.5 | 33.6/66.4 | <0.001 * |
| AHI (events/hour) | 9.9[4.2,19.1] | 8.3[3.3,16.9] | 0.025 * |
| RDI (events/hour) | 30.3[19.2,45] | 26.9[17.1,40.1] | <0.001 * |
| CVD | non-CVD | p | |
|---|---|---|---|
| TP(ms2) | 2299.4[1458.6,3410.9] | 2324.5[1412.7,3802.3] | 0.186 |
| LF(ms2) | 496.4[296,807.1] | 528.1282.7,929.9] | 0.004 * |
| HF(ms2) | 251.3[120.2,596.9] | 308.3[132,707.8] | 0.004 * |
| HFnorm(n.u.) | 35.9[24.2,50.8] | 38.2[25.4,52.1] | 0.188 |
| SDNN(ms) | 63.5[52.4,76.5] | 64.8[51.7,79.1] | 0.18 |
| RMSSD(ms) | 36.3[25.1,60.3] | 39.4[26.3,62.1] | 0.137 |
| MSE1 | 1.41[1.14,1.71] | 1.49[1.21,1.78] | 0.005 * |
| MSE2 | 1.47[1.25,1.69] | 1.51[1.3,1.73] | 0.037 * |
| MSE3 | 1.46[1.28,1.64] | 1.49[1.28,1.66] | 0.062 |
| MSE4 | 1.49[1.32,1.64] | 1.48[1.3,1.66] | 0.941 |
| MSE5 | 1.53[1.38,1.68] | 1.54[1.36,1.69] | 0.979 |
| MSE6 | 1.57[1.4,1.73] | 1.57[1.39,1.7] | 0.465 |
| MSE7 | 1.57[1.41,1.73] | 1.58[1.4,1.72] | 0.543 |
| MSE8 | 1.58[1.42,1.74] | 1.57[1.4,1.71] | 0.068 |
| MSE9 | 1.58[1.4,1.74] | 1.56[1.4,1.71] | 0.06 |
| MSE10 | 1.57[1.41,1.73] | 1.55[1.39,1.7] | 0.018 * |
| MPE | 5.69[5.49,5.84] | 5.61[5.41,5.82] | <0.001 * |
| ACC (%) | TPR (%) | TNR (%) | PPV (%) | F1 (%) | MCC | ||
|---|---|---|---|---|---|---|---|
| long-term | 1-fold | 69.7 | 80.2 | 56.8 | 69.4 | 74.4 | 0.38 |
| 2-fold | 74.4 | 84.8 | 61.8 | 73.0 | 78.5 | 0.48 | |
| 3-fold | 72.6 | 87.7 | 54.3 | 70.1 | 77.9 | 0.45 | |
| 4-fold | 73.8 | 80.7 | 65.3 | 74.0 | 77.2 | 0.47 | |
| 5-fold | 77.1 | 87.9 | 63.9 | 74.8 | 80.8 | 0.54 | |
| average | 73.5 | 84.2 | 60.4 | 72.3 | 77.8 | 0.46 | |
| short-term | 1-fold | 82.1 | 78.6 | 85.7 | 84.6 | 81.5 | 0.64 |
| 2-fold | 75.0 | 64.3 | 85.7 | 81.8 | 72.0 | 0.51 | |
| 3-fold | 85.7 | 100.0 | 71.4 | 71.4 | 87.5 | 0.75 | |
| 4-fold | 85.7 | 78.6 | 92.9 | 91.7 | 84.6 | 0.72 | |
| 5-fold | 78.6 | 85.7 | 71.4 | 75.0 | 80.0 | 0.58 | |
| average | 81.4 | 81.4 | 81.4 | 82.2 | 81.1 | 0.64 |
| Prediction Model | Components of Feature Vector | ACC (%) | TPR (%) | TNR (%) | PPV (%) | F1 (%) | MCC |
|---|---|---|---|---|---|---|---|
| long-term | clinical characteristics and HRV metrics | 73.5 | 84.2 | 60.4 | 72.3 | 77.8 | 0.46 |
| only clinical characteristics | 72.9 | 82.4 | 61.3 | 72.3 | 77.0 | 0.45 | |
| short-term | clinical characteristics and HRV metrics | 81.4 | 81.4 | 81.4 | 82.2 | 81.1 | 0.64 |
| only clinical characteristics | 76.4 | 85.7 | 67.1 | 72.8 | 78.4 | 0.55 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, X.; Zhang, L.; Li, J.; Du, D.; Hou, F. Entropy-Based Measures of Hypnopompic Heart Rate Variability Contribute to the Automatic Prediction of Cardiovascular Events. Entropy 2020, 22, 241. https://doi.org/10.3390/e22020241
Yan X, Zhang L, Li J, Du D, Hou F. Entropy-Based Measures of Hypnopompic Heart Rate Variability Contribute to the Automatic Prediction of Cardiovascular Events. Entropy. 2020; 22(2):241. https://doi.org/10.3390/e22020241
Chicago/Turabian StyleYan, Xueya, Lulu Zhang, Jinlian Li, Ding Du, and Fengzhen Hou. 2020. "Entropy-Based Measures of Hypnopompic Heart Rate Variability Contribute to the Automatic Prediction of Cardiovascular Events" Entropy 22, no. 2: 241. https://doi.org/10.3390/e22020241