Convolutional Neural Network Approach for Multispectral Facial Presentation Attack Detection in Automated Border Control Systems

 , ,
, ,  and
and 
Abstract
: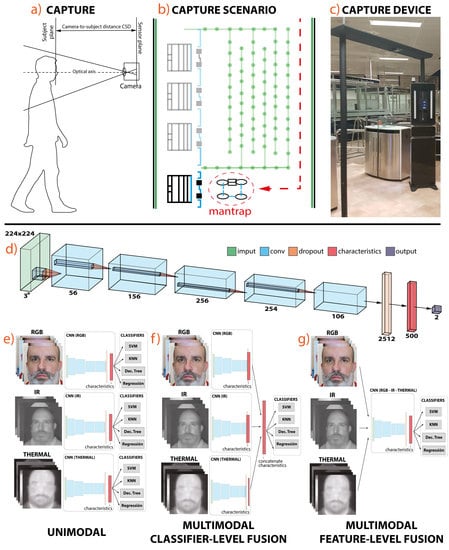
1. Introduction
2. Related Work
3. Database Description
- Printed photo attacks with a high resolution
- Printed photomask
- Printed eyeless photomask (simulating a real human being performing eye blinking)
- A high-resolution image displayed on a tablet
4. Method and Experimental Description
4.1. Method
4.1.1. CNN Architecture
- Convolutional Layer (11 × 11) + MaxPool layer (2 × 2) + Normalization layer
- Convolutional Layer (4 × 4)
- Convolutional Layer (3 × 3)
- Convolutional Layer (3 × 3)
- Convolutional Layer (3 × 3) + MaxPool layer (2 × 2)
- Dropout Layer
- Dropout Layer
- Fully connected Layer
4.1.2. Classification
4.2. Experimental Description
- Attack Presentation Classification Error Rate (APCER) is defined as the proportion of presentation attacks that were classified incorrectly (as bona fide) [46] (Equation (1)).where is the number of presentation attack instruments (PAI) and takes the value 1 if the presentation is assessed as an attack and 0 if it is evaluated as bona fide. A PAI is defined as an object or biometric trait used in a presentation attack.
- Bona fide Presentation Classification Error Rate (BPCER) is defined as the proportion of bona fide presentation incorrectly classified as presentation attacks [46] (Equation (2)).where is the cardinal of bona fide presentations and returns the value 1 if the presentation is allocated as ab attack and 0 if it is analyzed as bona fide.
- Average Classification Error Rate (ACER): is weighted average between APCER and BPCER
4.2.1. First Case of Study—Unimodal Evaluation
4.2.2. Second Case of Study—Classifier-Level Multimodal Fusion
4.2.3. Third Case of Study—Feature-Level Multimodal Fusion
5. Results and Discussion
5.1. Results for Unimodal Evaluation
5.2. Results for Classifier-Level Fusion
5.3. Results for Feature-Level Fusion
5.4. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Delac, K.; Grgic, M. A survey of biometric recognition methods. In Proceedings of the Elmar-2004, 46th International Symposium on Electronics in Marine, Zadar, Croatia, 18 June 2004; pp. 184–193. [Google Scholar]
- del Campo, D.O.; Conde, C.; Serrano, Á.; de Diego, I.M.; Cabello, E. Face Recognition-based Presentation Attack Detection in a Two-step Segregated Automated Border Control e-Gate—Results of a Pilot Experience at Adolfo Suárez Madrid-Barajas Airport. In Proceedings of the 14th International Joint Conference on e-Business and Telecommunications—Volume 4: SECRYPT, (ICETE 2017), Madrid, Spain, 24–26 July 2017; pp. 129–138. [Google Scholar] [CrossRef]
- Robertson, J.J.; Guest, R.M.; Elliott, S.J.; O’Connor, K. A Framework for Biometric and Interaction Performance Assessment of Automated Border Control Processes. IEEE Trans. Hum. Mach. Syst. 2017, 47, 983–993. [Google Scholar] [CrossRef]
- Sanchez del Rio, J.; Moctezuma, D.; Conde, C.; Martin de Diego, I.; Cabello, E. Automated border control e-gates and facial recognition systems. Comput. Secur. 2016, 62, 49–72. [Google Scholar] [CrossRef] [Green Version]
- Labati, R.; Genovese, A.; Muñoz, E.; Piuri, V.; Scotti, F.; Sforza, G. Automated Border Control Systems: Biometric Challenges and Research Trends; Springer: Berlin, Germany, 2015; Volume 9478, pp. 11–20. [Google Scholar]
- Frontex. Best Practice Operational Guidelines for Automated Border Control (ABC) Systems; Technical Report; Frontex: Warsaw, Poland, 2016. [Google Scholar]
- Frontex. Best Practice Technical Guidelines for Automated Border Control (ABC) Systems; Technical Report; Frontex: Warsaw, Poland, 2016. [Google Scholar]
- ABC4EU. Automated Border Control Gates for Europe Project, 2014–2018. In European Union’s Seventh Framework Programme for Research, Technological Development and Demonstration under Grant Agreement No 312797; ABC4EU: Geneva, Switzerland, 2020. [Google Scholar]
- BIOinPAD. Bio-inspired face recognition from multiple viewpoints. Evaluation in a presentation attack detection environment Project, 2016–2020. In Funded by Spanish National Research Agency with Reference TIN2016-80644-P; BIOinPAD: Geneva, Switzerland, 2020. [Google Scholar]
- Anjos, A.; Komulainen, J.; Marcel, S.; Hadid, A.; Pietikäinen, M. Face anti-spoofing: Visual approach. In Handbook of Biometric Anti-Spoofing; Springer: Berlin, Germany, 2014; pp. 65–82. [Google Scholar]
- Galbally, J.; Marcel, S.; Fiérrez, J. Biometric Antispoofing Methods: A Survey in Face Recognition. IEEE Access 2014, 2, 1530–1552. [Google Scholar] [CrossRef]
- International Organization for Standardization. Information technology—Biometric Presentation Attack Detection—Part 1: Framework; ISO: Geneva, Switzerland, 2016. [Google Scholar]
- The Management of Operational Cooperation at the External Borders of the Member States of the European Union; Fergusson, J. Twelve Seconds to Decide: In Search of Excellence: Frontex and the Principile of Best Practice; Publications Office of the European Union: Brussels, Belgium, 2014. [Google Scholar]
- Wen, D.; Han, H.; Jain, A. Face Spoof Detection with Image Distortion Analysis. IEEE Trans. Inf. Forensic Secur. 2015, 10, 746–761. [Google Scholar] [CrossRef]
- De Freitas Pereira, T.; Anjos, A.; De Martino, J.; Marcel, S. LBP-TOP Based Countermeasure Against Face Spoofing Attacks; Springer: Berlin, Germany, 2013; Volume 7728, pp. 121–132. [Google Scholar]
- Liu, Y.; Jourabloo, A.; Liu, X. Learning Deep Models for Face Anti-Spoofing: Binary or Auxiliary Supervision. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Górriz, J.M.; Ramírez, J.; Ortíz, A.; Martínez-Murcia, F.J.; Segovia, F.; Suckling, J.; Leming, M.; Zhang, Y.D.; Álvarez Sánchez, J.R.; Bologna, G.; et al. Artificial intelligence within the interplay between natural and artificial computation: Advances in data science, trends and applications. Neurocomputing 2020, 410, 237–270. [Google Scholar] [CrossRef]
- Gomez-Barrero, M.; Busch, C. Multi-Spectral Convolutional Neural Networks for Biometric Presentation Attack Detection. NISK J. 2019, 12, 209528032. [Google Scholar]
- Tolosana, R.; Gomez-Barrero, M.; Busch, C.; Ortega-Garcia, J. Biometric Presentation Attack Detection: Beyond the Visible Spectrum. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1261–1275. [Google Scholar] [CrossRef] [Green Version]
- Rathgeb, C.; Drozdowski, P.; Fischer, D.; Busch, C. Vulnerability Assessment and Detection of Makeup Presentation Attacks. In Proceedings of the 2020 8th International Workshop on Biometrics and Forensics (IWBF), Porto, Portugal, 29–30 April 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Ortega-Delcampo, D.; Conde, C.; Palacios-Alonso, D.; Cabello, E. Border Control Morphing Attack Detection With a Convolutional Neural Network De-Morphing Approach. IEEE Access 2020, 8, 92301–92313. [Google Scholar] [CrossRef]
- Ferrara, M.; Franco, A.; Maltoni, D. Face demorphing in the presence of facial appearance variations. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2365–2369, ISSN 2076-1465. [Google Scholar] [CrossRef]
- Gao, W.; Cao, B.; Shan, S.; Chen, X.; Zhou, D.; Zhang, X.; Zhao, D. The CAS-PEAL Large-Scale Chinese Face Database and Baseline Evaluations. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2007, 38, 149–161. [Google Scholar] [CrossRef] [Green Version]
- Akhtar, Z.; Kale, S. Security Analysis of Multimodal Biometric Systems against Spoof Attacks. In Proceedings of the Advances in Computing and Communications: First International Conference, ACC 2011, Kochi, India, 22–24 July 2011; Volume 191, pp. 604–611. [Google Scholar]
- Kotwal, K.; Bhattacharjee, S.; Marcel, S. Multispectral Deep Embeddings as a Countermeasure to Custom Silicone Mask Presentation Attacks. IEEE Trans. Biom. Behav. Identity Sci. 2019, 1, 238–251. [Google Scholar] [CrossRef]
- George, A. Biometric Face Presentation Attack Detection with Multi-Channel Convolutional Neural Network. IEEE Trans. Inf. Forensics Secur. 2020, 15, 42–56. [Google Scholar] [CrossRef] [Green Version]
- Lai, C.; Tai, C. A smart spoofing face detector by display features analysis. Sensors 2016, 16, 1136. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Albakri, G.; Alghowinem, S. The effectiveness of depth data in liveness face authentication using 3D sensor cameras. Sensors 2019, 19, 1928. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yi, D.; Lei, Z.; Zhang, Z.; Li, S.Z. Face Anti-spoofing: Multi-spectral Approach. In Handbook of Biometric Anti-Spoofing; Advances in Computer Vision and Pattern Recognition; Springer: Berlin, Germany, 2014; pp. 83–102. [Google Scholar]
- Zhang, Z.; Yi, D.; Lei, Z.; Li, S.Z. Face liveness detection by learning multispectral reflectance distributions. In Proceedings of the 2011 IEEE International Conference on Automatic Face and Gesture Recognition (FG), Santa Barbara, CA, USA, 21–25 March 2011; pp. 436–441. [Google Scholar]
- Hou, Y.L.; Hao, X.; Wang, Y.; Guo, C. Multispectral face liveness detection method based on gradient features. Opt. Eng. 2013, 52, 113102. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simard, P.Y.; Steinkraus, D.; Platt, J.C. Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis. In Proceedings of the ICDAR, Edinburgh, UK, 3–6 August 2003; Volume 3, pp. 958–962. [Google Scholar]
- Cireşan, D.; Meier, U.; Masci, J.; Gambardella, L.; Schmidhuber, J. Flexible, High Performance Convolutional Neural Networks for Image Classification. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 1237–1242. [Google Scholar]
- Yang, J.; Lei, Z.; Li, S.Z. Learn Convolutional Neural Network for Face Anti-Spoofing. arXiv 2014, arXiv:1408.5601. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; ACM: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Xu, Z.; Li, S.; Deng, W. Learning temporal features using LSTM-CNN architecture for face anti-spoofing. In Proceedings of the 3rd IAPR Asian Conference on Pattern Recognition, ACPR, Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 141–145. [Google Scholar] [CrossRef]
- Lucena, O.; Junior, A.; Moia, V.; Souza, R.; Valle, E.; Lotufo, R. Transfer learning using convolutional neural networks for face anti-spoofing. In International Conference Image Analysis and Recognition; Springer: Berlin, Germany, 2017; pp. 27–34. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ramachandra, R.; Busch, C. Presentation Attack Detection Methods for Face Recognition Systems: A Comprehensive Survey. ACM Comput. Surv. 2017, 50, 1–37. [Google Scholar] [CrossRef]
- Zhang, Z.; Yan, J.; Liu, S.; Lei, Z.; Yi, D.; Li, S.Z. A face antispoofing database with diverse attacks. In Proceedings of the 2012 5th IAPR International Conference on Biometrics (ICB), New Delhi, India, 29 March–1 April 2012; pp. 26–31. [Google Scholar] [CrossRef]
- Chingovska, I.; Anjos, A.; Marcel, S. On the Effectiveness of Local Binary Patterns in Face Anti-Spoofing. In Proceedings of the International Conference of Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 6–7 September 2012. [Google Scholar]
- Doc, I. Machine Readable Travel Documents, Part; ICAO: Montreal, QC, Canada, 2006. [Google Scholar]
- Team, T.D. Theano: A Python framework for fast computation of mathematical expressions. arXiv 2016, arXiv:1605.02688. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: New York, NY, USA, 2009. [Google Scholar]
- International Organization for Standardization. Information Technology—Biometric Presentation Attack Detection— Part 3: Testing and Reporting; ISO: Geneva, Switzerland, 2016. [Google Scholar]
- Zhang, S.; Liu, A.; Wan, J.; Liang, Y.; Guo, G.; Escalera, S.; Escalante, H.J.; Li, S.Z. Casia-surf: A large-scale multi-modal benchmark for face anti-spoofing. IEEE Trans. Biom. Behav. Identity Sci. 2020, 2, 182–193. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Visible | NIR | Thermal | |||||||
|---|---|---|---|---|---|---|---|---|---|
| APCER (%) | BPCER (%) | ACER (%) | APCER (%) | BPCER (%) | ACER (%) | APCER (%) | BPCER (%) | ACER (%) | |
| SVM RBF | 2.45 | 23.40 | 12.9 | 1.23 | 0 | 0.61 | 0 | 6.38 | 3.19 |
| SVM Linear | 2.45 | 21.27 | 11.8 | 1.23 | 0 | 0.61 | 0 | 6.38 | 3.19 |
| KNN | 2.45 | 21.27 | 11.8 | 1.23 | 0 | 0.61 | 1.84 | 6.38 | 4.11 |
| Dec. Tree | 4.29 | 21.27 | 12.7 | 18.4 | 0 | 9.2 | 0 | 8.51 | 4.25 |
| Log. Regression | 3.06 | 7.41 | 5.23 | 18.4 | 0 | 9.2 | 0 | 4.26 | 2.13 |
| APCER (%) | BPCER (%) | ACER (%) | |
|---|---|---|---|
| SVM RBF | 0 | 6.38 | 3.19 |
| SVM Linear | 0 | 2.13 | 1.06 |
| KNN | 0 | 4.26 | 2.13 |
| Dec. Tree | 1.84 | 0 | 0.92 |
| Log. Regression | 0 | 2.13 | 1.06 |
| APCER (%) | BPCER (%) | ACER (%) | |
|---|---|---|---|
| SVM RBF | 1.23 | 0 | 0.61 |
| SVM Linear | 1.23 | 0 | 0.61 |
| KNN | 1.23 | 0 | 0.61 |
| Dec. Tree | 1.84 | 0 | 0.92 |
| Log. Regression | 0.61 | 0 | 0.31 |
| Database | #Subjects/#Attacks | Algorithm | Sensor | APCER(%) | BPCER(%) | ACER(%) |
|---|---|---|---|---|---|---|
| CASIA-SURF [47] | 1000/Pictures and masks | based RESNET-18 | RGB | 40.3 | 1.6 | 21.0 |
| Depth | 6.0 | 1.2 | 3.6 | |||
| IR | 38.6 | 0.4 | 19.4 | |||
| RGB + Depth | 5.8 | 0.8 | 3.3 | |||
| RGB + IR | 36.5 | 0.005 | 18.3 | |||
| Depth + IR | 2.0 | 0.3 | 1.1 | |||
| RGB + Depth + IR | 1.9 | 0.1 | 1.0 | |||
| WMCA [26] | 72/Pictures, glasses, replay, and masks | MC-CNN (Multi-Channel Convolutional Neural Network) | Grayscale + Depth + IR + Thermal | 0.6 | 0 | 0.3 |
| Grayscale + Depth + IR | 2.07 | 0 | 1.04 | |||
| Grayscale | 65.65 | 0 | 32.82 | |||
| Depth | 11.77 | 0.31 | 6.04 | |||
| IR | 5.03 | 0 | 2.51 | |||
| Thermal | 3.14 | 0.56 | 1.85 | |||
| FRAV-ATTACK | Current study | SVM RBF | RGB | 2.45 | 23.4 | 12.9 |
| SVM RBF | IR | 1.23 | 0 | 0.61 | ||
| SVM RBF | Thermal | 0 | 6.38 | 3.19 | ||
| SVM RBF (Classifier-Level Fusion) | RGB + IR + Thermal | 0 | 6.38 | 3.19 | ||
| SVM RBF (Feature-Level Fusion) | RGB + IR + Thermal | 1.23 | 0 | 0.61 | ||
| SVM Linear | RGB | 2.45 | 21.27 | 11.8 | ||
| SVM Linear | IR | 1.23 | 0 | 0.61 | ||
| SVM Linear | Thermal | 0 | 6.38 | 3.19 | ||
| SVM Linear (Classifier-Level Fusion) | RGB + IR + Thermal | 0 | 2.13 | 1.06 | ||
| SVM Linear (Feature-Level Fusion) | RGB + IR + Thermal | 1.23 | 0 | 0.61 | ||
| KNN | RGB | 2.45 | 21.27 | 11.8 | ||
| KNN | IR | 1.23 | 0 | 0.61 | ||
| KNN | Thermal | 1.84 | 6.38 | 4.11 | ||
| KNN (Classifier-Level Fusion) | RGB + IR + Thermal | 0 | 4.26 | 2.13 | ||
| KNN (Feature-Level Fusion) | RGB + IR + Thermal | 1.23 | 0 | 0.61 | ||
| Dec. Tree | RGB | 4.29 | 21.27 | 12.7 | ||
| Dec. Tree | IR | 18.4 | 0 | 9.2 | ||
| Dec. Tree | Thermal | 0 | 8.51 | 4.25 | ||
| Dec. Tree (Classifier-Level Fusion) | RGB + IR + Thermal | 1.84 | 0 | 0.92 | ||
| Dec. Tree (Feature-Level Fusion) | RGB + IR + Thermal | 1.84 | 0 | 0.92 | ||
| Log. Regression | RGB | 3.06 | 7.41 | 5.23 | ||
| Log. Regression | IR | 18.4 | 0 | 9.2 | ||
| Log. Regression | Thermal | 0 | 4.26 | 2.13 | ||
| Log. Regression (Classifier-Level Fusion) | RGB + IR + Thermal | 0 | 2.13 | 1.06 | ||
| Log. Regression (Feature-Level Fusion) | RGB + IR + Thermal | 0.61 | 0 | 0.31 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sánchez-Sánchez, M.A.; Conde, C.; Gómez-Ayllón, B.; Ortega-DelCampo, D.; Tsitiridis, A.; Palacios-Alonso, D.; Cabello, E. Convolutional Neural Network Approach for Multispectral Facial Presentation Attack Detection in Automated Border Control Systems. Entropy 2020, 22, 1296. https://doi.org/10.3390/e22111296
Sánchez-Sánchez MA, Conde C, Gómez-Ayllón B, Ortega-DelCampo D, Tsitiridis A, Palacios-Alonso D, Cabello E. Convolutional Neural Network Approach for Multispectral Facial Presentation Attack Detection in Automated Border Control Systems. Entropy. 2020; 22(11):1296. https://doi.org/10.3390/e22111296
Chicago/Turabian StyleSánchez-Sánchez, M. Araceli, Cristina Conde, Beatriz Gómez-Ayllón, David Ortega-DelCampo, Aristeidis Tsitiridis, Daniel Palacios-Alonso, and Enrique Cabello. 2020. "Convolutional Neural Network Approach for Multispectral Facial Presentation Attack Detection in Automated Border Control Systems" Entropy 22, no. 11: 1296. https://doi.org/10.3390/e22111296