Analysis of Factors Contributing to the Severity of Large Truck Crashes


Abstract
:1. Introduction
2. Collection and Processing
2.1. Data Description
2.2. Dependent and Independent Variables
3. Methodology
3.1. Mixed Logit Model
3.2. Random Forest (RF)
3.3. Adaptive Boosting (AdaBoost)
3.4. Gradient Boosting Decision Tree (GBDT)
3.5. Mean Decrease Impurity (MDI)
4. Result Analysis
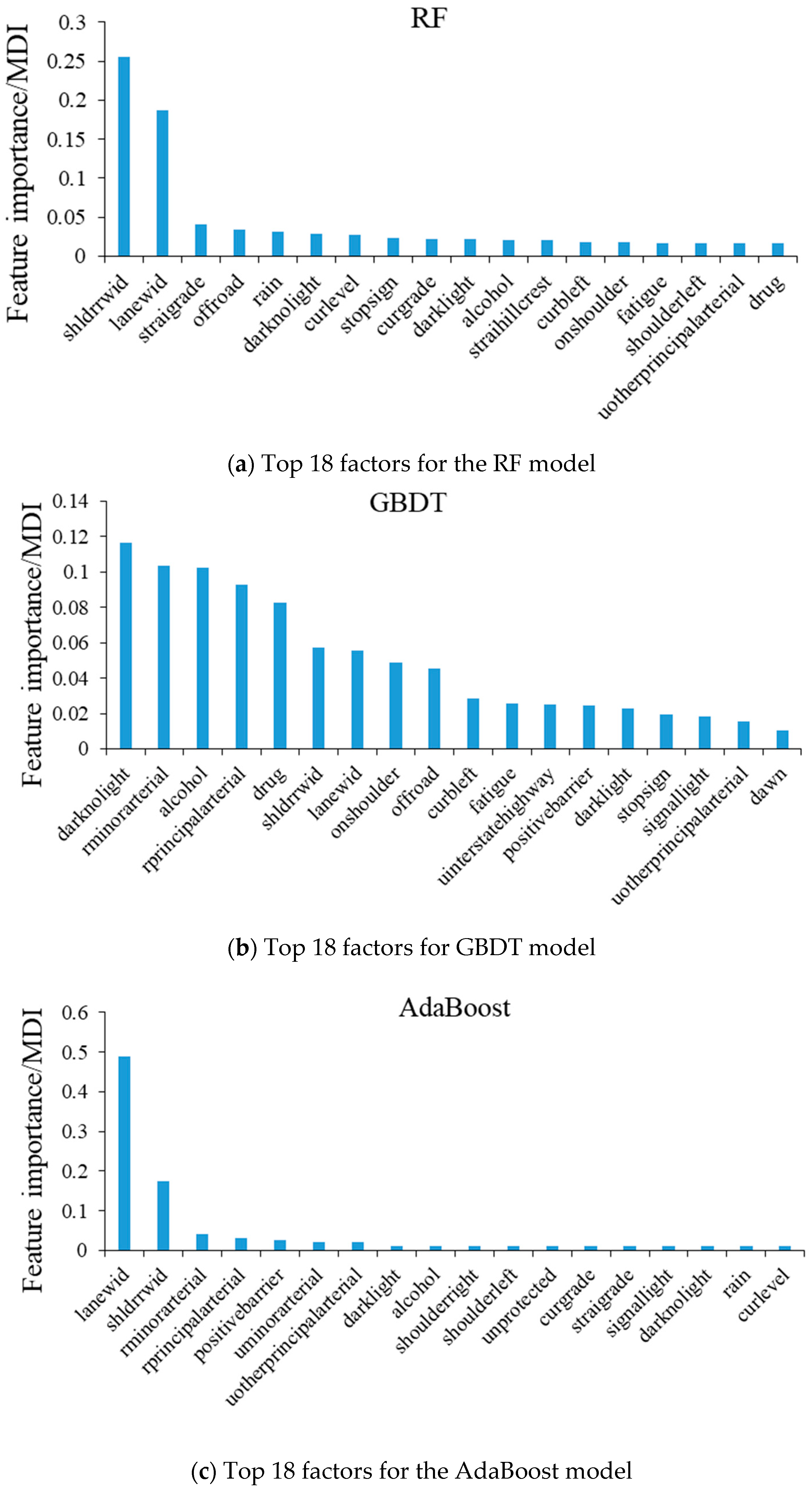
4.1. Identified AK Crash Contributing Factors
4.2. Analysis of the Impacts of the Identified Crash Contributing Factors
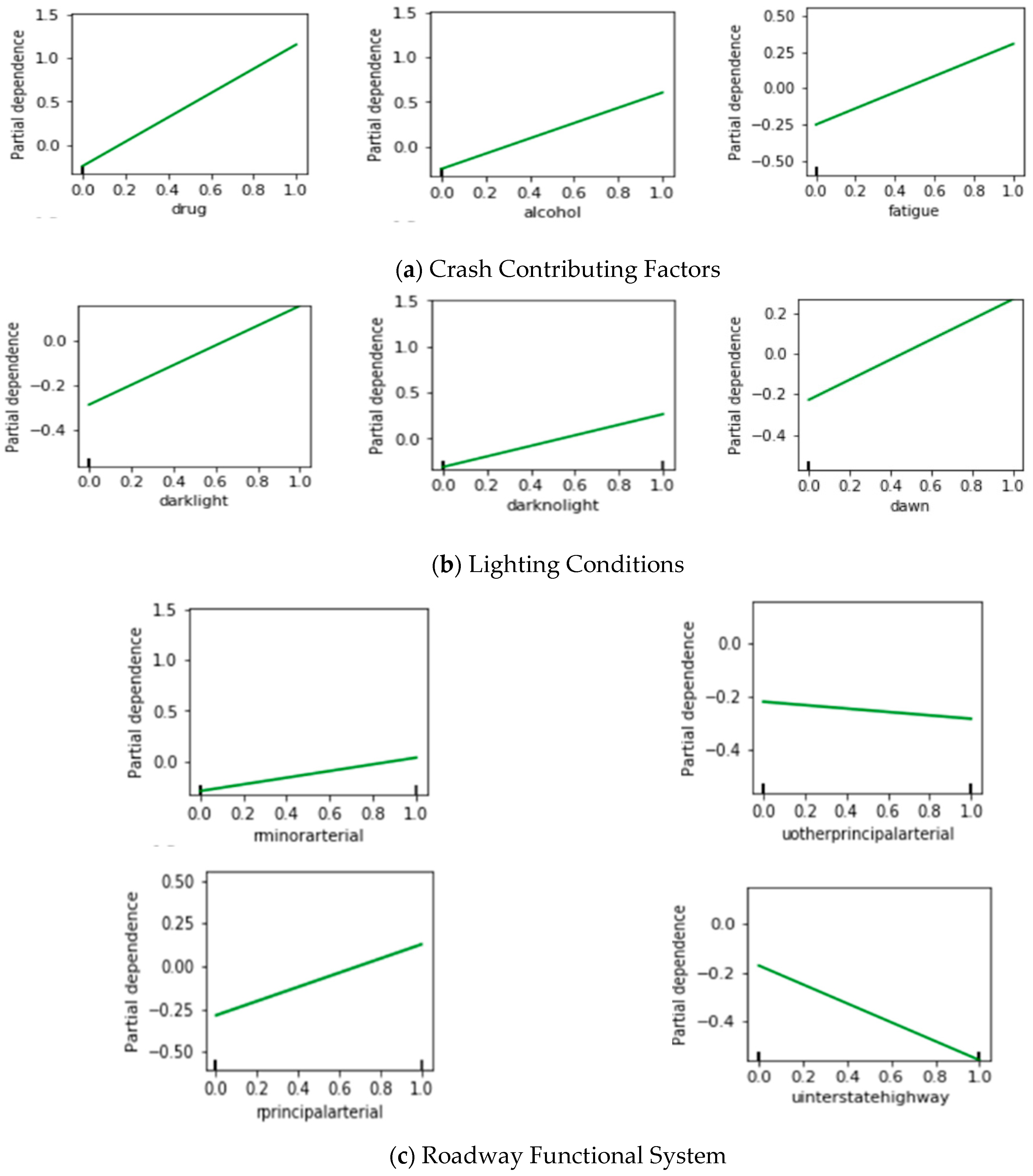
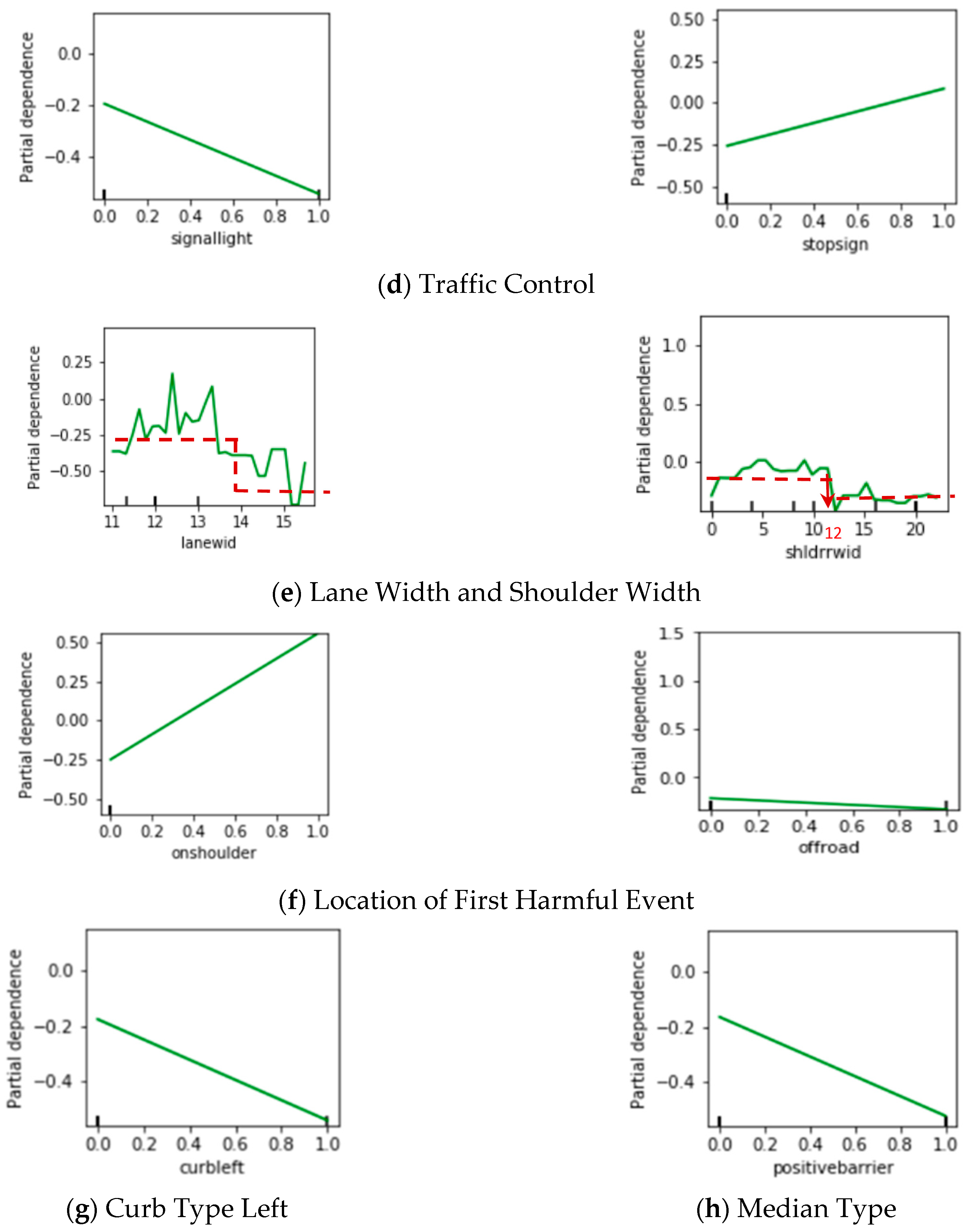
4.3. Partial Dependence Plots of GBDT Model
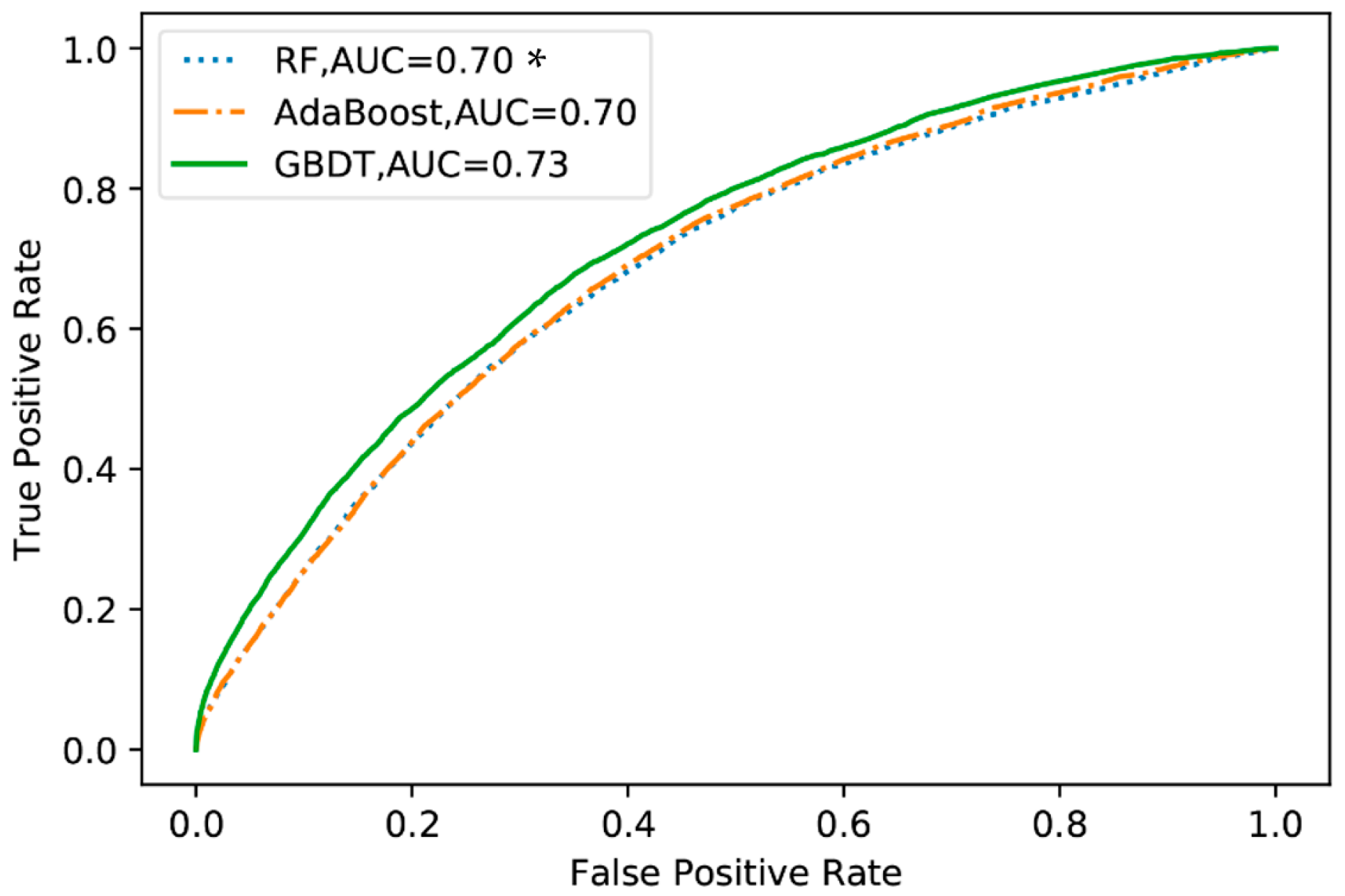
4.4. Comparison of the Mixed Logit Model and GBDT Model
4.5. The Impacts of the Identified Contributing Factors
- (1)
- Crash Contributing Factors
- (2)
- Lighting Conditions
- (3)
- Roadway Functional System
- (4)
- Traffic Control
- (5)
- Lane Width and Shoulder Width
- (6)
- Types of Curbs
- (7)
- Location of First Harmful Event
- (8)
- Median Type
- (9)
- Weather Characteristics
- (10)
- Road Alignment
5. Conclusions and Recommendations
- (1)
- The importance rank of the factors identified by the GBDT model is more correlated with the significant level of the factors identified by the mixed logit model than those of the RF and AdaBoost models. This result indicates that the GBDT model is a better choice for preselecting the variables for the mixed logit model.
- (2)
- The partial dependence plots of the GBDT model can be used effectively in deriving the direction and magnitude of the impacts of the identified factors.
- (3)
- For the factors that are identified by both GBDT and mixed logit models, the directions of the impacts of these factors are consistent according to the results of both models.
- (4)
- For the factors that are only identified by the GBDT model, the directions and magnitudes of their impacts are all reasonable and explainable according to the partial dependence plots of the GBDT model.
- (5)
- For the factors only identified by the mixed logit model, it is found that influencing directions of the weather characteristic factors are not reasonable.
- (6)
- All the factors identified by the mixed model are categorical variables, while the GBDT model can also identify numerical factors like lane width (lanwid) and right shoulder width (shldrrwid), which have nonlinear impacts on the dependent variable.
- (7)
- According to the partial dependence plots of GBDT, driving under the influence of drugs, alcohol, and fatigue are important contributing factors to the severity of large truck crashes. In addition, the existence of curbs, medians, and lanes and shoulders with sufficient width can effectively prevent severe large truck crashes.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhao, Q.; Goodman, T.; Azimi, M.; Qi, Y. Roadway-related truck crash risk analysis: Case studies in Texas. Transp. Res. Rec. 2018, 2672, 20–28. [Google Scholar] [CrossRef]
- Bezwada, N.N.K. Characteristics and Contributory Causes Associated with Fatal Large Truck Crashes. Ph.D. Thesis, Kansas State University, Manhattan, KS, USA, 2010. [Google Scholar]
- Moonesinghe, R.; Longthorne, A.; Shankar, U.; Singh, S.; Subramanian, R.; Tessmer, J. An Analysis of Fatal Large Truck Crashes (No. HS-809 569); National Highway Traffic Safety Administration: Washington, DC, USA, 2003.
- Chang, L.Y.; Mannering, F. Analysis of injury severity and vehicle occupancy in truck- and non-truck-involved accidents. Accid. Anal. Prev. 1999, 31, 579–592. [Google Scholar] [CrossRef]
- Khattak, A.; Schneider, R.; Targa, F. Risk factors in large truck rollovers and injury severity: Analysis of single-vehicle collisions. Transp. Res. Board 2003. Available online: http://www.ltrc.lsu.edu/TRB_82/TRB2003-000331.pdf (accessed on 20 October 2020).
- Xie, Y.; Zhang, Y.; Liang, F. Crash Injury Severity Analysis Using Bayesian Ordered Probit Models. J. Transp. Eng. ASCE 2009, 135, 18–25. [Google Scholar] [CrossRef] [Green Version]
- Pahukula, J.; Hernandez, S.; Unnikrishnan, A. A time of day analysis of crashes involving large trucks in urban areas. Accid. Anal. Prev. 2015, 75, 155–163. [Google Scholar] [CrossRef]
- Al-Bdairi, N.S.S.; Hernandez, S. An empirical analysis of run-off-road injury severity crashes involving large trucks. Accid. Anal. Prev. 2017, 102, 93–100. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.M.; Franke, R.; Ksaibati, K.; Shinstine, D.S. Effects of truck traffic on crash injury severity on rural highways in Wyoming using Bayesian binary logit models. Accid. Anal. Prev. 2018, 117, 106–113. [Google Scholar] [CrossRef]
- Lu, P.; Zheng, Z.; Ren, Y.; Zhou, X.; Keramati, A.; Tolliver, D.; Huang, Y. A gradient boosting crash prediction approach for highway-rail grade crossing crash analysis. J. Adv. Transp. 2020, 2020, 6751728. [Google Scholar] [CrossRef]
- Zhou, X.; Lu, P.; Zheng, Z.; Tolliver, D.; Keramati, A. Accident Prediction Accuracy Assessment for Highway-Rail Grade Crossings Using Random Forest Algorithm Compared with Decision Tree. Reliab. Eng. Syst. Saf. 2020, 200, 106931. [Google Scholar] [CrossRef]
- Chang, L.Y.; Chien, J.T. Analysis of driver injury severity in truck-involved accidents using a non-parametric classification tree model. Saf. Sci. 2013, 51, 17–22. [Google Scholar] [CrossRef]
- Yu, R.; Abdel-Aty, M. Analyzing crash injury severity for a mountainous freeway incorporating real-time traffic and weather data. Saf. Sci. 2014, 63, 50–56. [Google Scholar] [CrossRef]
- Haleem, K.; Gan, A. Effect of driver’s age and side of impact on crash severity along urban freeways: A mixed logit approach. J. Saf. 2013, 46, 67–76. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Liu, P.; Wang, W.; Li, Z. Identification of freeway crash-prone traffic conditions for traffic flow at different levels of service. Transp. Res. Part A Policy Pract. 2014, 69, 58–70. [Google Scholar] [CrossRef]
- Zeng, Q.; Huang, H. A stable and optimized neural network model for crash injury severity prediction. Accid. Anal. Prev. 2014, 73, 351–358. [Google Scholar] [CrossRef] [PubMed]
- Tang, J.; Liang, J.; Han, C.; Li, Z.; Huang, H. Crash injury severity analysis using a two-layer Stacking framework. Accid. Anal. Prev. 2019, 122, 226–238. [Google Scholar] [CrossRef]
- Su, X.; Zhou, T.; Yan, X.; Fan, J.; Yang, S. Interaction trees with censored survival data. Int. J. Biostat. 2008, 4, 1–28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, R.; Abdel-Aty, M. Utilizing support vector machine in real-time crash risk evaluation. Accid. Anal. Prev. 2013, 51, 252–259. [Google Scholar] [CrossRef] [PubMed]
- Mannering, F.L.; Bhat, C.R. Analytic methods in accident research: Methodological frontier and future directions. Anal. Methods Accid. Res. 2014, 1, 1–22. [Google Scholar] [CrossRef]
- Greene, W.H. Econometric Analysis, 4th ed.; Pentice Hall International: Upper Freehold, NJ, USA, 2000. [Google Scholar]
- Duncan, G.J.; Magnuson, K.A.; Ludwig, J. The endogeneity problem in developmental studies. Res. Hum. Dev. 2004, 1, 59–80. [Google Scholar]
- Weiss, H.B.; Kaplan, S.; Prato, C.G. Analysis of factors associated with injury severity in crashes involving young New Zealand drivers. Accid. Anal. Prev. 2014, 65, 142–155. [Google Scholar] [CrossRef]
- Liu, P.; Fan, W. Exploring injury severity in head-on crashes using latent class clustering analysis and mixed logit model: A case study of North Carolina. Accid. Anal. Prev. 2020, 135, 105388. [Google Scholar] [CrossRef]
- Jiang, X.; Abdel-Aty, M.; Hu, J.; Lee, J. Investigating macro-level hotzone identification and variable importance using big data: A random forest models approach. Neurocomputing 2016, 181, 53–63. [Google Scholar] [CrossRef]
- Train, K.E. Discrete Choice Methods with Simulation; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Ho, S.H.; Boon, K.S. Spatial distribution of flying Tribolium castaneum (Coleoptera: Tenebrionidae) in a rice warehouse. Bull. Entomol. Res. 1995, 85, 355–359. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; Wadsworth Int. Group: New York, NY, USA, 1984; Volume 37, pp. 237–251. [Google Scholar]
- Chen, S.H.; Pan, J.S.; Lu, K. Driving behavior analysis based on vehicle OBD information and adaboost algorithms. In Proceedings of the International Multiconference of Engineers and Computer Scientists, Hong Kong, China, 18–20 March 2015; Volume 1, pp. 18–20. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Breiman and Cutler’s Random Forests for Classification and Regression Version (4.6–12). CRAN 2015. Available online: https://cran.rproject.org/web/packages/randomForest (accessed on 20 October 2020).
- Malin, F.; Norros, I.; Innamaa, S. Accident risk of road and weather conditions on different road types. Accid. Anal. Prev. 2019, 122, 181–188. [Google Scholar] [CrossRef]
- Mercer, G.W.; Jeffery, W.K. Alcohol, drugs, and impairment in fatal traffic accidents in British Columbia. Accid. Anal. Prev. 1995, 27, 335–343. [Google Scholar] [CrossRef]
- Zegeer, C.V.; Deen, R.C.; Mayes, J.G. The Effect of Lane and Shoulder Widths on Accident Reductions on Rural, Two-Lane Roads; Kentucky Transportation Center: Lexington, KY, USA, 1980; Available online: https://uknowledge.uky.edu/ktc_researchreports/811/ (accessed on 20 October 2020).
- Stein, W.J.; Neuman, T.R. Mitigation Strategies for Design Exceptions (No. FHWA-SA-07-011); Federal Highway Administration, Office of Safety: Washington, DC, USA, 2007.
- Liu, S.; Wang, J.; Fu, T. Effects of lane width, lane position and edge shoulder width on driving behavior in underground urban expressways: A driving simulator study. Int. J. Environ. Res. Public Health 2016, 13, 1010. [Google Scholar] [CrossRef] [Green Version]
- Garrido, R.; Bastos, A.; De Almeida, A.; Elvas, J.P. Prediction of road accident severity using the ordered probit model. Transp. Res. Procedia 2014, 3, 214–223. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Traffic Control | Lighting Conditions | ||
| none * | 1 if no traffic control, 0 otherwise (baseline) | daylight * | 1 if incident occurred when daylight, 0 otherwise (baseline) |
| stopsign | 1 if traffic control is stop sign, 0 otherwise | darknolight | 1 if incident occurred when dark not lighted, 0 otherwise |
| signallight | 1 if traffic control is signal light, 0 otherwise | dawn | 1 if incident occurred when dawn, 0 otherwise |
| yieldsign | 1 if traffic control is yield sign, 0 otherwise | darklight | 1 if incident occurred when dark but lighted, 0 otherwise |
| flashinglight | 1 if traffic control is flashing light, 0 otherwise | dusk | 1 if incident occurred when dusk, 0 otherwise |
| Roadway Functional System | Road Alignment | ||
| rintersatehighway * | 1 if rural interstate highway, 0 otherwise (baseline) | strailevel * | 1 if road alignment is straight level, 0 otherwise (baseline) |
| uinterstatehighway | 1 if urban interstate highway, 0 otherwise | straigrade | 1 if road alignment is straight grade, 0 otherwise |
| rprincipalarterial | 1 if rural principal arterial, 0 otherwise | straihillcrest | 1 if road alignment is straight hillcrest, 0 otherwise |
| uotherprincipalarterial | 1 if urban other principal arterial, 0 otherwise | curlevel | 1 if road alignment is curve level, 0 otherwise |
| uminorarterial | 1 if urban minor arterial, 0 otherwise | curgrade | 1 if road alignment is curve grade, 0 otherwise |
| rminorarterial | 1 if rural minor arterial, 0 otherwise | curhillcrest | 1 if road alignment is curve hillcrest, 0 otherwise |
| Median Type | Location of First Harmful Event | ||
| mediannone * | 1 if no median, 0 otherwise (baseline) | onroad * | 1 if crash occurred on road, 0 otherwise (baseline) |
| unprotected | 1 if median type is unprotected, 0 otherwise | onshoulder | 1 if crash occurred on shoulder, 0 otherwise |
| positivebarrier | 1 if median type is positive barrier, 0 otherwise | onmedian | 1 if crash occurred on median, 0 otherwise |
| onewaypair | 1 if median type is one-way pair, 0 otherwise | offroad | 1 if crash occurred off-road, 0 otherwise |
| Shoulder Type Left | Shoulder Type Right | ||
| shoulderlnone * | 1 if no left shoulder, 0 otherwise (baseline) | shoulderrnone * | 1 if no right shoulder, 0 otherwise (baseline) |
| shoulderleft | 1 if left shoulder exists, 0 otherwise | shoulderright | 1 if right shoulder exists, 0 otherwise |
| Curb Type Left | Curb Type Right | ||
| curblnone * | 1 if no left curb, 0 otherwise (baseline) | curbrnone * | 1 if no right curb, 0 otherwise (baseline) |
| curbleft | 1 if left curb exists, 0 otherwise | curbright | 1 if right curb exists, 0 otherwise |
| Weather Characteristics | Crash Contributing Factors | ||
| clear * | 1 if clear, 0 otherwise (baseline) | fatigue | 1 if driver under the influence of fatigue, 0 otherwise |
| rain | 1 if raining, 0 otherwise | drug | 1 if driver under the influence of a drug, 0 otherwise |
| snow | 1 if snowing, 0 otherwise | alcohol | 1 if driver under the influence of alcohol, 0 otherwise |
| blowing | 1 if blowing sand, 0 otherwise | ||
| fog sleet severcrosswinds | 1 if fog, 0 otherwise 1 if sleet, 0 otherwise 1 if severe crosswinds, 0 otherwise | Lane Width and Shoulder Width | |
| lanewid shldrrwid | The width of travel lanes in feet The width of the right shoulder in feet | ||
| Variable | Crash Injury Severity | Total | Percent | Variable | Crash Injury Severity | Total | Percent | ||
|---|---|---|---|---|---|---|---|---|---|
| Non-AK Crash | AK Crash | Non-AK Crash | AK Crash | ||||||
| Traffic Control | Light Characteristics | ||||||||
| none | 9275 | 395 | 9670 | 11.35% | daylight | 59,034 | 3324 | 62,358 | 73.20% |
| stopsign | 4392 | 452 | 4844 | 5.69% | darknolight | 11,129 | 1383 | 12,512 | 14.69% |
| signallight | 10,952 | 373 | 11,325 | 13.29% | dawn | 1085 | 124 | 1209 | 1.42% |
| yieldsign | 2016 | 123 | 2139 | 2.51% | darklight | 7455 | 542 | 7997 | 9.39% |
| flashinglight | 509 | 51 | 560 | 0.66% | dusk | 708 | 42 | 750 | 0.88% |
| Location of First Harmful Event | Median Type | ||||||||
| onroad | 65,535 | 4344 | 69,879 | 82.03% | mediannone | 29,965 | 2816 | 32,781 | 38.48% |
| onshoulder | 1015 | 169 | 1184 | 1.39% | unprotected | 21,286 | 1482 | 22,768 | 26.73% |
| onmedian | 2818 | 180 | 2998 | 3.52% | positivebarrier | 24,565 | 1014 | 25,579 | 30.03% |
| offroad | 10,345 | 747 | 11,092 | 13.02% | onewaypair | 483 | 11 | 494 | 0.58% |
| Roadway Functional System | Weather Characteristics | ||||||||
| uinterstatehighway | 21,666 | 851 | 22,517 | 26.43% | clear | 69,592 | 4853 | 74,445 | 87.39% |
| rprincipalarterial | 9642 | 1159 | 10,801 | 12.68% | rain | 7470 | 410 | 7880 | 9.25% |
| uotherprincipalarterial | 23,084 | 1050 | 24,134 | 28.33% | snow | 752 | 19 | 771 | 0.91% |
| uminorarterial | 4615 | 296 | 4911 | 5.77% | blowing | 124 | 16 | 140 | 0.16% |
| rminorarterial | 12,058 | 1453 | 13,511 | 15.86% | fog | 738 | 97 | 835 | 0.98% |
| rintersatehighway | 8679 | 631 | 9310 | 10.93% | sleet | 675 | 25 | 700 | 0.82% |
| Road Alignment | severcrosswinds | 368 | 18 | 386 | 0.45% | ||||
| strailevel | 58,853 | 3742 | 62,595 | 73.48% | Crash Contributing Factors | ||||
| straigrade | 9424 | 715 | 10,139 | 11.90% | fatigue | 1618 | 240 | 1858 | 2.18% |
| straihillcrest | 2669 | 217 | 2886 | 3.39% | drug | 206 | 99 | 305 | 0.36% |
| curlevel | 4757 | 428 | 5185 | 6.09% | alcohol | 862 | 241 | 1103 | 1.29% |
| curgrade | 3191 | 291 | 3482 | 4.09% | |||||
| curhillcrest | 615 | 37 | 652 | 0.77% | |||||
| Shoulder Type Left | Curb Type Left | ||||||||
| shoulderlnone | 12,463 | 559 | 13,022 | 15.29% | curblnone | 66,710 | 4971 | 71,681 | 84.15% |
| shoulderleft | 63,903 | 4543 | 68,446 | 80.35% | curbleft | 9307 | 339 | 9646 | 11.32% |
| Shoulder Type Right | Curb Type Right | ||||||||
| shoulderrnone | 9576 | 433 | 10,009 | 11.75% | curbrnone | 66,427 | 4960 | 71,387 | 83.80% |
| shoulderright | 66,732 | 4660 | 71,392 | 83.81% | curbright | 8188 | 300 | 8488 | 9.96% |
| Variable | Coeff. * | Std. Error | t | p-Value ** | |
|---|---|---|---|---|---|
| traffic control | signallight | −0.5801 | 0.0644 | −9.01 | <0.0001 |
| stopsign | 0.2037 | 0.0587 | 3.47 | 0.0005 | |
| location | Offroad *a | −2.5980 (2.9134) | 0.5779 | −4.50 | <0.0001(<0.0001) |
| weather | Rain *a | −1.2411 (1.7131) | 0.3592 | −3.45 | 0.0006(<0.0001) |
| sleet | −0.8620 | 0.2479 | −3.48 | 0.0005 | |
| snow | −1.4201 | 0.2880 | −4.93 | <0.0001 | |
| severcrosswinds | −0.7184 | 0.3243 | −2.22 | 0.0267 | |
| road alignment | straigrade | 0.1569 | 0.0488 | 3.21 | 0.0013 |
| curlevel | 0.2380 | 0.0669 | 3.56 | 0.0004 | |
| curgrade | 0.3068 | 0.0800 | 3.83 | 0.0001 | |
| functional system | uinterstatehighway | −0.7046 | 0.0618 | −11.40 | <0.0001 |
| uotherprincipalarterial | −0.5464 | 0.0480 | −11.39 | <0.0001 | |
| curb left | curbleft | −0.6472 | 0.0581 | −11.13 | <0.0001 |
| median | positivebarrier | −0.5434 | 0.0548 | −9.91 | <0.0001 |
| Unprotected *a | −1.8760 (−2.2862) | 0.3472 | −5.40 | <0.0001(<0.0001) | |
| onewaypair | −0.6444 | 0.3111 | −2.07 | 0.0383 | |
| factors | drug | 2.0215 | 0.1466 | 13.79 | <0.0001 |
| fatigue | 0.7642 | 0.0935 | 8.18 | <0.0001 | |
| Intercept | −2.1065 | 0.0278 | −75.85 | <0.0001 | |
| Log likelihood | −19,352 (df = 22) | ||||
| Sample size | 85,184 | ||||
| Importance Ranks Based on the MDI *2 Measures of the ML *3 Models | |||
|---|---|---|---|
| Importance ranks based on the p-values of the mixed logit model | RF *4 model | GBDT *5 model | AdaBoost *6 model |
| −0.059 (0.817 *1) | 0.738 (0.001 *1) | 0.152 (0.548 *1) | |
| Variable Category | Variables’ Descriptions | Mixed Logit | GBDT | ||||
|---|---|---|---|---|---|---|---|
| Significant Factors (p-Value <5%) | Signs of β | Ranked by p-Value | Important Factors (Top 18) | Direction of Partial Dependence | Ranked by MDI | ||
| Crash contributing factors | 1 if driver under the influence of a drug, 0 otherwise | drug | + | 1 | drug | + | 5 |
| 1 if driver under the influence of fatigue, 0 otherwise | fatigue | + | 7 | fatigue | + | 11 | |
| Roadway functional system | 1 if urban interstate highway, 0 otherwise | uinterstatehighway | – | 2 | uinterstatehighway | – | 12 |
| 1 if urban other principal arterial, 0 otherwise | uotherprincipalarterial | – | 3 | uotherprincipalarterial | – | 17 | |
| Traffic control | 1 if traffic control is stop sign, 0 otherwise | stopsign | + | 14 | stopsign | + | 15 |
| 1 if traffic control is signal light, 0 otherwise | signallight | – | 6 | signallight | – | 16 | |
| Curb type left | 1 if left curb exists, 0 otherwise | curbleft | – | 4 | curbleft | – | 10 |
| Median type | 1 if median type is positive barrier, 0 otherwise | positivebarrier | – | 5 | positivebarrier | – | 13 |
| Location of first harmful event | 1 if crash occurred off-road, 0 otherwise | offroad | – | 10 | offroad | – | 9 |
| Weather characteristics | 1 if snowing, 0 otherwise | snow | – | 9 | |||
| 1 if sleet, 0 otherwise | sleet | – | 13 | ||||
| 1 if raining, 0 otherwise | rain | – | 15 | ||||
| 1 if severe crosswinds, 0 otherwise | severcrosswinds | – | 17 | ||||
| Road alignment | 1 if road alignment is straight grade, 0 otherwise | straigrade | + | 16 | |||
| 1 if road alignment is curve level, 0 otherwise | curlevel | + | 12 | ||||
| 1 if road alignment is curve grade, 0 otherwise | curgrade | + | 11 | ||||
| Median type | 1 if median type is one-way pair, 0 otherwise | onewaypair | – | 18 | |||
| 1 if median type is unprotected, 0 otherwise | unprotected | – | 8 | ||||
| Lighting conditions | 1 if incident occurred when dark not lighted, 0 otherwise | darknolight | + | 1 | |||
| 1 if incident occurred when dark but lighted, 0 otherwise | darklight | + | 14 | ||||
| 1 if incident occurred when dawn, 0 otherwise | dawn | + | 18 | ||||
| Crash contributing factors | 1 if driver under the influence of alcohol, 0 otherwise | alcohol | + | 3 | |||
| Lane width and shoulder width | The width of the right shoulder in feet | shldrrwid | – | 6 | |||
| The width of travel lanes in feet | lanewid | – | 7 | ||||
| Location of first harmful event | 1 if crash occurred on shoulder, 0 otherwise | onshoulder | + | 8 | |||
| Roadway functional system | 1 if rural minor arterial, 0 otherwise | rminorarterial | + | 2 | |||
| 1 if rural principal arterial, 0 otherwise | rprincipalarterial | + | 4 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Liu, J.; Liu, P.; Qi, Y. Analysis of Factors Contributing to the Severity of Large Truck Crashes. Entropy 2020, 22, 1191. https://doi.org/10.3390/e22111191
Li J, Liu J, Liu P, Qi Y. Analysis of Factors Contributing to the Severity of Large Truck Crashes. Entropy. 2020; 22(11):1191. https://doi.org/10.3390/e22111191
Chicago/Turabian StyleLi, Jinhong, Jinli Liu, Pengfei Liu, and Yi Qi. 2020. "Analysis of Factors Contributing to the Severity of Large Truck Crashes" Entropy 22, no. 11: 1191. https://doi.org/10.3390/e22111191