Mimicking Anti-Viruses with Machine Learning and Entropy Profiles


Abstract
:1. Introduction
- We introduce MimickAV, the first general purpose method that can mimic almost any current commercial anti-virus engine by using entropy profiles, a feature that every single binary file has (Section 2).
- We apply this methodology using 20 state of the art machine learning classifiers from 10 different paradigms with the aim of mimicking 57 commercial anti-viruses from VirusTotal (Section 3).
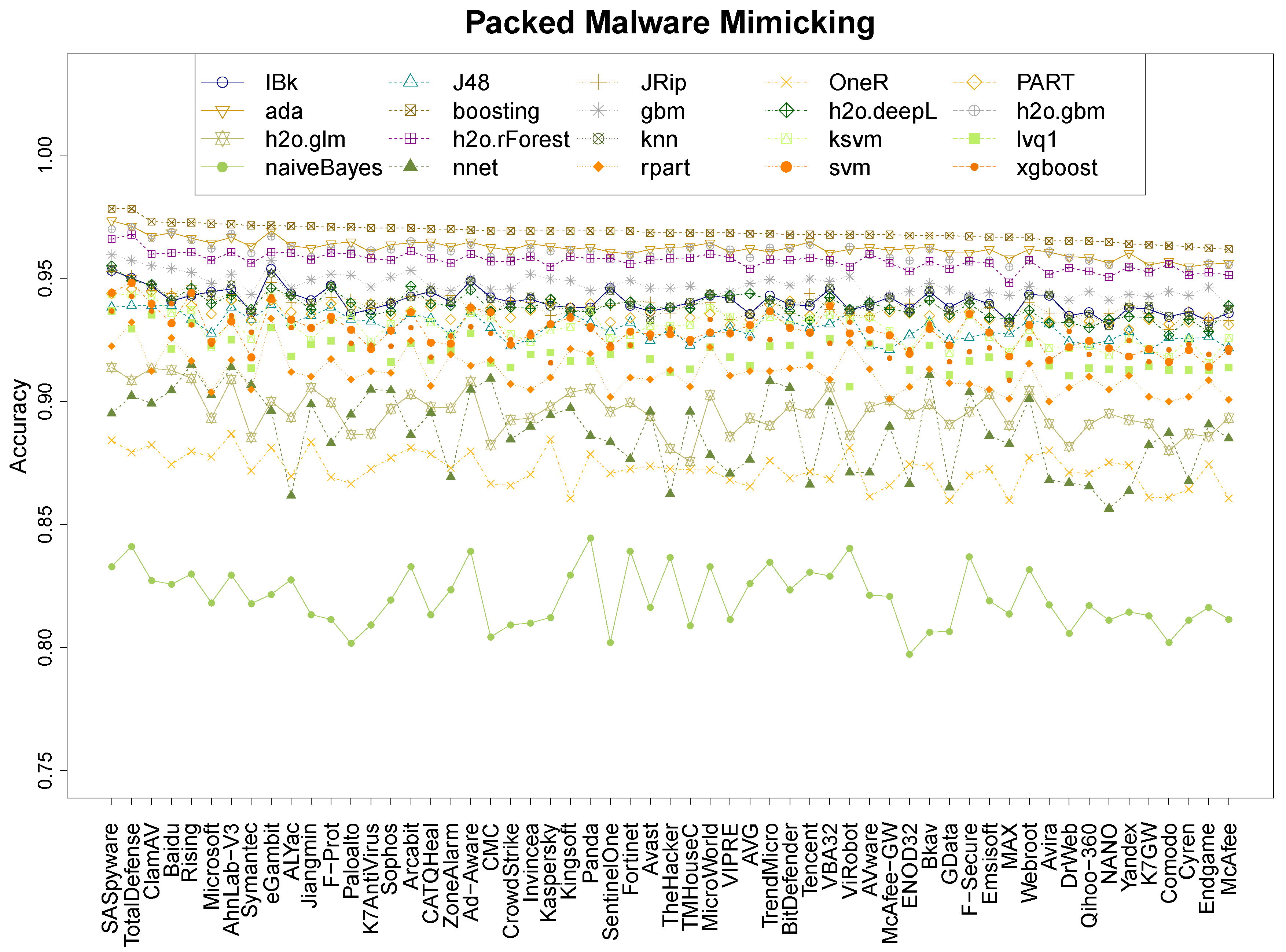
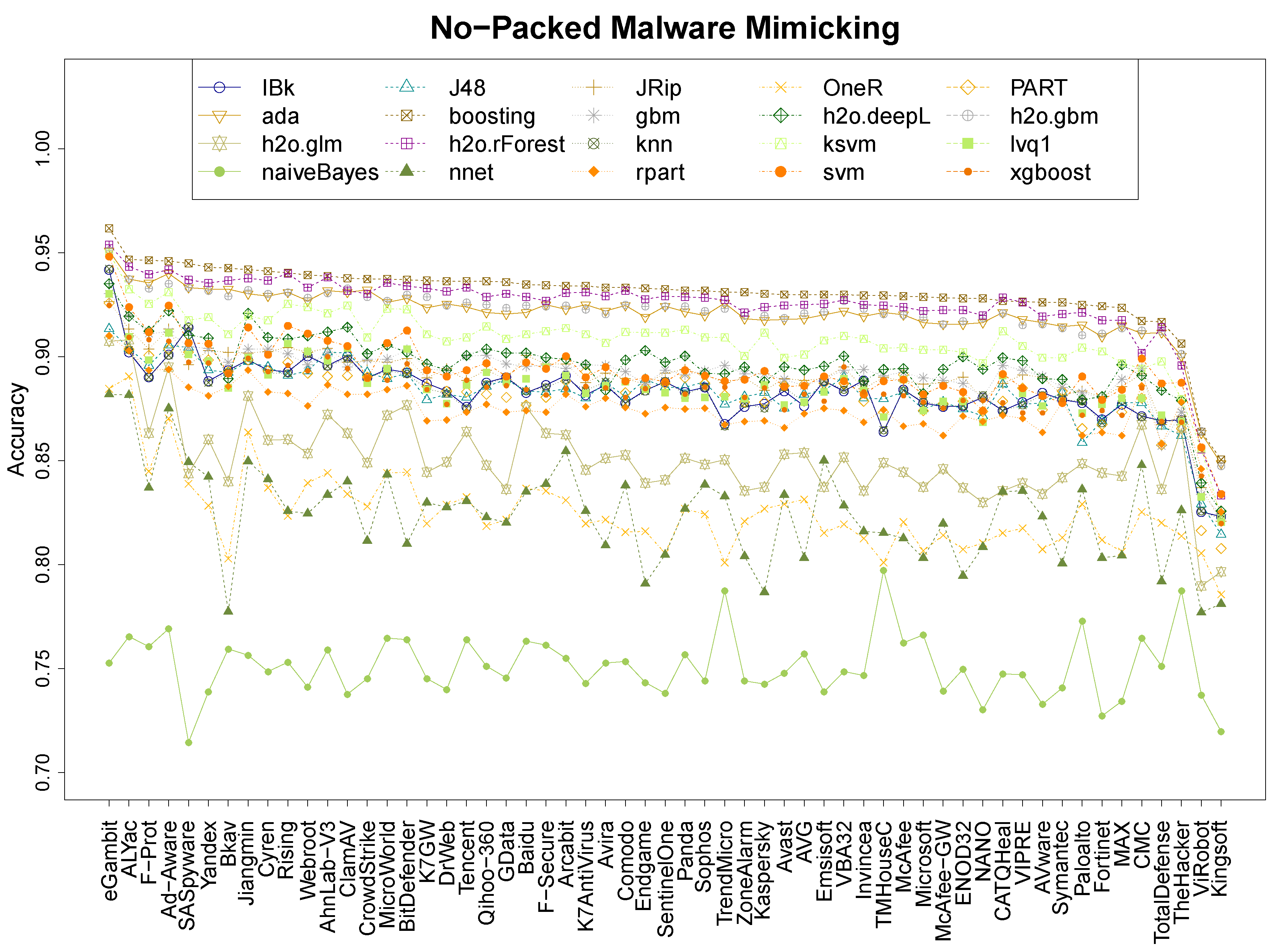
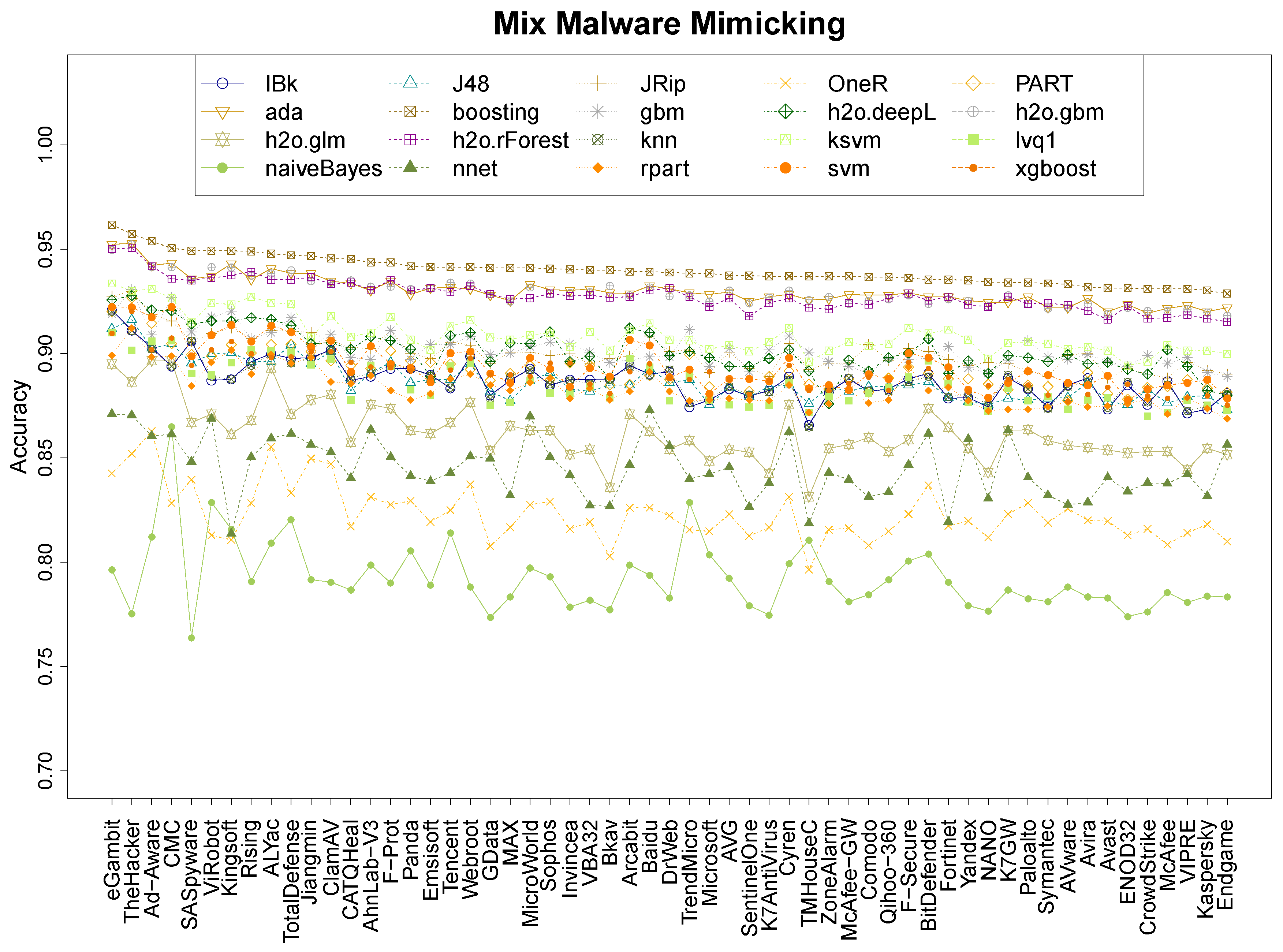
- From the 20 machine learning algorithms, we proved that boosting is the strongest, reaching an accuracy between 96% and 98% for packed malware, 93% and 96% on mix malware, and 85% and 96% on non-packed malware (Section 4.1 and Section 4.2).
- We show which anti-virus are more resistant to our method, and which specific concealment strategies make harder to apply entropy to mimic the anti-viruses responses (Section 4.3 and Section 4.4).
2. MimickAV: Mimicking Anti-Virus Software
2.1. Entropy Profiles
- Partition the file in chunks, i.e., small parts of the same size, and calculate their entropy to generate an entropy sequence.
- Shrink or extend the entropy sequence to a specific length, which normalizes the approach to different file lengths.
- Clean the noise of the sequence using the Harr wavelet. The cleaned sequence is the entropy profile.
2.2. Classification
- Tree-based classification [11]: these classifiers divide the data in a linear fashion, defining a tree of decisions on their features. This division is chosen by a metric, normally the entropy.
- K-nearest neighbourhood [12]: the k-NN algorithm decides the classification on an instance based on its k-nearest neighbours. Normally, this decision is the majority of the neighbours classes.
- Support Vector Machines [13]: SVM creates a hyperplane to separate the data into classes. This hyperplane maximizes its margin with the frontier of each data class, defined by specific instances called support vectors. It normally applies kernels to work with non-linear separations.
- Rules-based classification [14]: these classifiers create a set of rules that aim to generalize the classification decision of each instance based on its features.
- Naïve Bayes [15]: this classifier learns a probability distribution for each feature, considering each one independent, and applies Bayesian probability on the features distribution to decide when an instance is assigned to a class.
- Random Forest [16]: this method combines different tree-based classifiers into a voting system. Normally the algorithm splits the feature space and train each tree in different combinations of features.
- Boosting [17]: following the same logic than random forest, this algorithm is a multi-learning approach where several weak classifiers are combined to learn different areas of the feature space and aggregate them to provide a final classification decision.
- Generalised Linear models [18]: this algorithm generalizes linear regression to different probability distributions. The aim is to separate the data by learning the parameters of specific probability distributions that work as an estimator.
- Artificial Neural Networks [19]: an artificial neural network is a hierarchical structure of nodes connected by layers, where the top one is the input and the bottom one is the output. Between these layers there are hidden layers that aim to reproduce the behaviour of the human brain.
- Deep Learning [20]: deep learning algorithms are a generalization of neural network where the algorithm combines unsupervised learning and supervised learning in its hidden layers.
3. Experimental Setup
3.1. Research Goals
3.2. Evaluation Data
- Pck data. Composed of 2000 samples from VirusShare selected uniformly at random without repetition from the 10,000 described in Table 1, and the 2000 samples from the packed benign-ware.
- NPck data. Composed of 2000 samples from the non-packed data of VirusShare selected uniformly at random without repetition from the 6000 malware, and the 2000 samples from the non-packed benign-ware.
- Mix data. It is a mix of the previous dataset with the aim of generalising the mimicking abilities of the system. These data contains 4000 samples, of packed malware and benign-ware, and 1/2 non-packed malware and benign-ware. It aggregates the Pck and NPck data.
3.3. Anti-Virus Selection
3.4. Classification Algorithms
- Naïve Bayes: we apply the classical naiveBayes algorithm from package e1071 [15].
- Random Forest: we applied one of the current state of the art implementations from the H2O package: h2o.rForest [16].
- Boosting: since boosting is one of the current strongest classifiers for entropy profile discrimination [10], we applied several versions of it. First, we use the original boosting [17], that we used in our previous work [9] leveraging rpart from the multi-learning approach. Then, we apply adaptive boosting (ada) [30], from the homonym package [31], which adapts the learners weight in favour of those instances misclassified by previous classifiers. We also applied two modern versions of gradient boosting [32], an adaptation of adaptive boosting with the ability of optimizing a cost function. We consider the implementation of gbm package and the parallel version of the algorithm from the H2O package (h2o.gbm), which also includes an automatic detection system for different loss functions. Finally, we consider the extreme gradient boosting algorithm, xgboost, which reduces feature splits in order to reduce the search space [33].
- Generalized Linear Model: for GLM we use the implementation from H2O package, h2o.glm [18].
- Deep Learning: for deep learning, we also apply the H2O implementation of deep learning algorithms, h2o.deepL [20].
4. Experiments
4.1. Performance of MimickAV
| Research question 1 asked about the accuracy performance of MimickAV. It can, indeed, mimic the behaviour of any anti-virus of VirusTotal reaching an accuracy up to 98% on packed data, and 96% on non-packed and mix data, using a boosting classifier. |
4.2. Precision of MimickAV
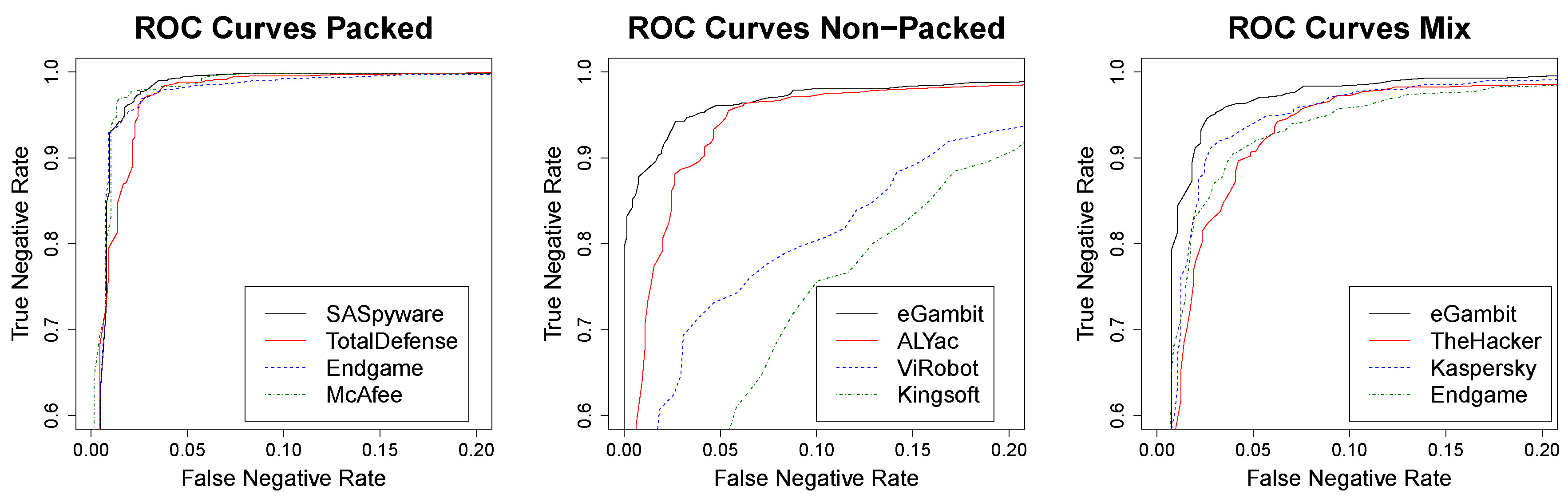
| Research question 2 asked about the negative predictive value of MimickAV. MimickAV shows a really strong confidence when it provides a negative prediction, especially relevant on packed malware, where it can predict 98% of variants with 5% error. |
4.3. Detection by Packers
| Research question 3 asked about the influence of packers systems on the accuracy. Packers do not affect the accuracy significantly, except for ASPack, as their accuracy is always above 90%. |
4.4. Anti-Virus Quality
| Research question 4 asked about the accuracy of the most and less resistant anti-viruses. Although it is clear from the accuracy results that eGambit, SUPERAntiSpyware, and Ad-Aware are the most sensitive anti-viruses and ViRobot and Kingsoft the most resistant, our results show that some anti-viruses might share information, as their behaviours are similar according to the top classifiers. |
5. Related Work
5.1. The Malware Arms Race
5.2. Entropy on Malware Detection
5.3. Anti-Viruses and VirusTotal
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Meng, G.; Patrick, M.; Xue, Y.; Liu, Y.; Zhang, J. Securing Android App Markets via Modelling and Predicting Malware Spread between Markets. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1944–1959. [Google Scholar] [CrossRef]
- Bertino, E.; Islam, N. Botnets and internet of things security. Computer 2017, 50, 76–79. [Google Scholar] [CrossRef]
- Sikorski, M.; Honig, A. Practical Malware Analysis: The Hands-on Guide to Dissecting Malicious Software; No Starch Press: San Francisco, CA, USA, 2012. [Google Scholar]
- Oktavianto, D.; Muhardianto, I. Cuckoo Malware Analysis; Packt Publishing Ltd.: Birmingham, UK, 2013. [Google Scholar]
- Calleja, A.; Martín, A.; Menéndez, H.D.; Tapiador, J.; Clark, D. Picking on the family: Disrupting android malware triage by forcing misclassification. Expert Syst. Appl. 2018, 95, 113–126. [Google Scholar] [CrossRef]
- Total, V. Virustotal-Free Online Virus, Malware and Url Scanner. 2012. Available online: https://www.virustotal.com/en (accessed on 1 March 2019).
- Gandotra, E.; Bansal, D.; Sofat, S. Malware analysis and classification: A survey. J. Inf. Secur. 2014, 5, 56–64. [Google Scholar] [CrossRef]
- Sorokin, I. Comparing files using structural entropy. J. Comput. Virol. 2011, 7, 259–265. [Google Scholar] [CrossRef]
- Menéndez, H.D.; Bhattacharya, S.; Clark, D.; Barr, E.T. The arms race: Adversarial search defeats entropy used to detect malware. Expert Syst. Appl. 2019, 118, 246–260. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Menéndez, H.D.; Barr, E.; Clark, D. Itect: Scalable information theoretic similarity for malware detection. arXiv Preprint 2016, arXiv:1609.02404. [Google Scholar]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann: Burlington, MA, USA, 2014. [Google Scholar]
- Cover, T.M.; Hart, P.E. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef] [Green Version]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Cohen, W.W. Fast Effective Rule Induction. In Twelfth International Conference on Machine Learning; Morgan Kaufmann: Burlington, MA, USA, 1995; pp. 115–123. [Google Scholar] [Green Version]
- Domingos, P.; Pazzani, M. On the optimality of the simple Bayesian classifier under zero-one loss. Mach. Learn. 1997, 29, 103–130. [Google Scholar] [CrossRef]
- Barandiaran, I. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the Thirteenth International Conference on International Conference on Machine Learning, Bari, Italy, 3–6 July 1996; pp. 148–156. [Google Scholar]
- Nelder, J.A.; Wedderburn, R.W. Generalized linear models. J. R. Stat. Soc. Ser. A Gen. 1972, 135, 370–384. [Google Scholar] [CrossRef]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002; ISBN 0-387-95457-0. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Bischl, B.; Lang, M.; Kotthoff, L.; Schiffner, J.; Richter, J.; Studerus, E.; Casalicchio, G.; Jones, Z.M. mlr: Machine Learning in R. J. Mach. Learn. Res. 2016, 17, 1–5. [Google Scholar]
- Hornik, K.; Buchta, C.; Zeileis, A. Open-Source Machine Learning: R Meets Weka. Comput. Stat. 2009, 24, 225–232. [Google Scholar] [CrossRef]
- Frank, E.; Witten, I.H. Generating Accurate Rule Sets Without Global Optimization. In Fifteenth International Conference on Machine Learning; Shavlik, J., Ed.; Morgan Kaufmann: Burlington, MA, USA, 1998; pp. 144–151. [Google Scholar]
- Breiman, L. Classification and Regression Trees; Routledge: New York, NY, USA, 2017. [Google Scholar]
- Aha, D.; Kibler, D. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Karatzoglou, A.; Smola, A.; Hornik, K.; Zeileis, A. kernlab—An S4 Package for Kernel Methods in R. J. Stat. Softw. 2004, 11, 1–20. [Google Scholar] [CrossRef]
- Holte, R. Very simple classification rules perform well on most commonly used datasets. Mach. Learn. 1993, 11, 63–91. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Culp, M.; Johnson, K.; Michailidis, G. ada: An r package for stochastic boosting. J. Stat. Softw. 2006, 17, 9. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ripley, B.D. Pattern Recognition and Neural Networks; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Santos, I.; Brezo, F.; Nieves, J.; Penya, Y.K.; Sanz, B.; Laorden, C.; Bringas, P.G. Idea: Opcode-sequence-based malware detection. In Proceedings of the International Symposium on Engineering Secure Software and Systems, Pisa, Italy, 3–4 February 2010; pp. 35–43. [Google Scholar]
- Martín, A.; Menéndez, H.D.; Camacho, D. MOCDroid: Multi-objective evolutionary classifier for Android malware detection. Soft Comput. 2017, 21, 7405–7415. [Google Scholar] [CrossRef]
- Shijo, P.; Salim, A. Integrated static and dynamic analysis for malware detection. Procedia Comput. Sci. 2015, 46, 804–811. [Google Scholar] [CrossRef]
- Vasilescu, M.; Gheorghe, L.; Tapus, N. Practical malware analysis based on sandboxing. In Proceedings of the 2014 RoEduNet Conference 13th Edition: Networking in Education and Research Joint Event RENAM 8th Conference, Chisinau, Moldova, 11–13 September 2014; pp. 1–6. [Google Scholar]
- Bellard, F. QEMU, a fast and portable dynamic translator. In Proceedings of the USENIX Annual Technical Conference, FREENIX Track, Anaheim, CA, USA, 10–15 April 2005; Volume 41, p. 46. [Google Scholar]
- Kang, M.G.; Yin, H.; Hanna, S.; McCamant, S.; Song, D. Emulating emulation-resistant malware. In Proceedings of the 1st ACM Workshop on Virtual Machine Security, Chicago, IL, USA, 9 November 2009; pp. 11–22. [Google Scholar]
- Kawakoya, Y.; Iwamura, M.; Itoh, M. Memory behavior-based automatic malware unpacking in stealth debugging environment. In Proceedings of the 2010 5th International Conference on Malicious and Unwanted Software, Nancy, France, 19–20 October 2010; pp. 39–46. [Google Scholar]
- Laskov, P.; Šrndić, N. Static detection of malicious JavaScript-bearing PDF documents. In Proceedings of the 27th Annual Computer Security Applications Conference, Orlando, FL, USA, 5–9 December 2011; pp. 373–382. [Google Scholar]
- Curtsinger, C.; Livshits, B.; Zorn, B.G.; Seifert, C. ZOZZLE: Fast and Precise In-Browser JavaScript Malware Detection. In Proceedings of the USENIX Security Symposium, San Francisco, CA, USA, 8–12 August 2011; pp. 33–48. [Google Scholar]
- Zhou, Y.; Jiang, X. Dissecting android malware: Characterization and evolution. In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 95–109. [Google Scholar]
- Suarez-Tangil, G.; Tapiador, J.E.; Peris-Lopez, P.; Ribagorda, A. Evolution, detection and analysis of malware for smart devices. IEEE Commun. Surv. Tutor. 2014, 16, 961–987. [Google Scholar] [CrossRef]
- Suarez-Tangil, G.; Tapiador, J.E.; Peris-Lopez, P.; Blasco, J. Dendroid: A text mining approach to analyzing and classifying code structures in android malware families. Expert Syst. Appl. 2014, 41, 1104–1117. [Google Scholar] [CrossRef]
- Martín, A.; Calleja, A.; Menéndez, H.D.; Tapiador, J.; Camacho, D. ADROIT: Android malware detection using meta-information. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–8. [Google Scholar]
- Arzt, S.; Rasthofer, S.; Fritz, C.; Bodden, E.; Bartel, A.; Klein, J.; Le Traon, Y.; Octeau, D.; McDaniel, P. Flowdroid: Precise context, flow, field, object-sensitive and lifecycle-aware taint analysis for android apps. ACM Sigplan Not. 2014, 49, 259–269. [Google Scholar] [CrossRef]
- Tam, K.; Khan, S.J.; Fattori, A.; Cavallaro, L. CopperDroid: Automatic Reconstruction of Android Malware Behaviors. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 8–11 February 2015. [Google Scholar]
- Chio, C.; Freeman, D. Machine Learning and Security: Protecting Systems with Data and Algorithms; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Saxe, J.; Sanders, H. Malware Data Science: Attack Detection and Attribution; No Starch Press: San Francisco, CA, USA, 2018. [Google Scholar]
- Martín, A.; Menéndez, H.D.; Camacho, D. String-based malware detection for android environments. In Proceedings of the International Symposium on Intelligent and Distributed Computing, Paris, France, 10–12 October 2016; pp. 99–108. [Google Scholar]
- Garcia, J.; Hammad, M.; Malek, S. Lightweight, obfuscation-resilient detection and family identification of Android malware. ACM Trans. Softw. Eng. Methodol. 2018, 26, 11. [Google Scholar] [CrossRef]
- Nari, S.; Ghorbani, A.A. Automated malware classification based on network behavior. In Proceedings of the 2013 International Conference on Computing, Networking and Communications, San Diego, CA, USA, 28–31 January 2013; pp. 642–647. [Google Scholar]
- Leder, F.; Steinbock, B.; Martini, P. Classification and detection of metamorphic malware using value set analysis. In Proceedings of the 2009 4th International Conference on Malicious and Unwanted Software (MALWARE), Montréal, QC, Canada, 13–14 October 2009; pp. 39–46. [Google Scholar]
- Kolosnjaji, B.; Zarras, A.; Webster, G.; Eckert, C. Deep learning for classification of malware system call sequences. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Hobart, Tasmania, Australia, 5–9 December 2016; pp. 137–149. [Google Scholar]
- Santos, I.; Devesa, J.; Brezo, F.; Nieves, J.; Bringas, P.G. Opem: A static-dynamic approach for machine-learning-based malware detection. In International Joint Conference CISIS’12-ICEUTE 12-SOCO 12 Special Sessions; Springer: Berlin/Heidelberg, Germany, 2013; pp. 271–280. [Google Scholar]
- Biggio, B.; Roli, F. Wild patterns: Ten years after the rise of adversarial machine learning. Pattern Recognit. 2018, 84, 317–331. [Google Scholar] [CrossRef]
- Xu, W.; Qi, Y.; Evans, D. Automatically evading classifiers. In Proceedings of the 2016 Network and Distributed Systems Symposium, San Diego, CA, USA, 21–24 February 2016; pp. 21–24. [Google Scholar]
- Goodfellow, I.; McDaniel, P.; Papernot, N. Making machine learning robust against adversarial inputs. Commun. ACM 2018, 61, 56–66. [Google Scholar] [CrossRef]
- Zhou, Y.; Kantarcioglu, M.; Xi, B. A survey of game theoretic approach for adversarial machine learning. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 9, e1259. [Google Scholar] [CrossRef]
- Lyda, R.; Hamrock, J. Using entropy analysis to find encrypted and packed malware. IEEE Secur. Privacy 2007, 5, 40–45. [Google Scholar] [CrossRef]
- Alshahwan, N.; Barr, E.T.; Clark, D.; Danezis, G. Detecting Malware with Information Complexity. arXiv Preprint 2015, arXiv:1502.07661. [Google Scholar]
- Lin, D.; Stamp, M. Hunting for undetectable metamorphic viruses. J. Comput. Virol. 2011, 7, 201–214. [Google Scholar] [CrossRef]
- Sanz, B.; Santos, I.; Laorden, C.; Ugarte-Pedrero, X.; Nieves, J.; Bringas, P.G.; Álvarez Marañón, G. MAMA: Manifest analysis for malware detection in Android. Cybern. Syst. 2013, 44, 469–488. [Google Scholar] [CrossRef]
- Sebastián, M.; Rivera, R.; Kotzias, P.; Caballero, J. Avclass: A tool for massive malware labeling. In International Symposium on Research in Attacks, Intrusions, and Defenses; Springer: Cham, Switzerland, 2016; pp. 230–253. [Google Scholar]
- Meng, G.; Xue, Y.; Mahinthan, C.; Narayanan, A.; Liu, Y.; Zhang, J.; Chen, T. Mystique: Evolving android malware for auditing anti-malware tools. In Proceedings of the 11th ACM on Asia Conference on Computer and Communications Security, Xi’an, China, 30 May–3 June 2016; pp. 365–376. [Google Scholar]
- Rastogi, V.; Chen, Y.; Jiang, X. Droidchameleon: Evaluating android anti-malware against transformation attacks. In Proceedings of the 8th ACM SIGSAC Symposium on Information, Computer and Communications Security, Hangzhou, China, 8–10 May 2013; pp. 329–334. [Google Scholar]
- Hammad, M.; Garcia, J.; Malek, S. A large-scale empirical study on the effects of code obfuscations on Android apps and anti-malware products. In Proceedings of the 40th International Conference on Software Engineering, Gothenburg, Sweden, 27 May–3 June 2018; pp. 421–431. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Packer | Malware | Benign-Ware |
|---|---|---|
| Armadillo | 542 | 101 |
| ASPack | 186 | 32 |
| ASProtect | 54 | 10 |
| Borland | 2123 | 417 |
| NET | 2351 | 476 |
| PECompact | 445 | 88 |
| UPX | 3175 | 641 |
| Rest | 1124 | 235 |
| Total | 10,000 | 2000 |
| Model | Top 2 MimickAV | Bottom 2 MimickAV | ||
|---|---|---|---|---|
| Pck boosting | SASpyware (97.8) | TotalDefense (97.8) | Endgame (96.2) | McAfee (96.2) |
| NPck boosting | eGambit (96.2) | ALYac (94.7) | ViRobot (86.4) | Kingsoft (85.0) |
| Mix boosting | eGambit (96.2) | TheHacker (95.7) | Kaspersky (93.0) | Endgame (92.9) |
| Pck ada | SASpyware (97.3) | TotalDefense (97.1) | K7GW (95.5) | Cyren (95.5) |
| NPck ada | eGambit (95.1) | Ad-Aware (94.0) | ViRobot (86.3) | Kingsoft (84.9) |
| Mix ada | TheHacker (95.3) | eGambit (95.2) | Avast (92.0) | CrowdStrike (91.9) |
| Pck h2o.gbm | TotalDefense (97.1) | SASpyware (97.0) | K7GW (95.4) | Cyren (95.4) |
| NPck h2o.gbm | eGambit (95.1) | ALYac (93.7) | ViRobot (86.4) | Kingsoft (84.7) |
| Mix h2o.gbm | TheHacker (95.2) | eGambit (95.0) | Avast (91.9) | Endgame (91.8) |
| Pck OneR | AhnLab-V3 (88.7) | Kaspersky (88.5) | GData (86.0) | MAX (86.0) |
| NPck OneR | ALYac (89.1) | eGambit (88.5) | TrendMicro (80.1) | Kingsoft (78.6) |
| Mix OneR | Ad-Aware (86.3) | ALYac (85.5) | Bkav (80.3) | TMHouseC (79.6) |
| Pck nnet | Rising (91.5) | AhnLab-V3 (91.4) | ALYac (86.2) | NANO (85.6) |
| NPck nnet | eGambit (88.2) | ALYac (88.2) | Bkav (77.7) | ViRobot (77.7) |
| Mix nnet | Baidu (87.3) | eGambit (87.1) | TMHouseC (81.9) | Kingsoft (81.4) |
| Pck NBayes | Panda (84.4) | TotalDefense (84.1) | Paloalto (80.2) | ENOD32 (79.7) |
| NPck NBayes | TMHouseC (79.7) | TheHacker (78.7) | Kingsoft (72.0) | SASpyware (71.4) |
| Mix NBayes | CMC (86.5) | TrendMicro (82.9) | GData (77.3) | SASpyware (76.4) |
| TNR/FNR | 0 | 0.002 | 0.01 | 0.05 | 0.1 | 0.15 |
| Pck SASpyware | 0.04 | 0.11 | 0.93 | 0.99 | 1.0 | 1.0 |
| Pck TotalDefense | 0.05 | 0.26 | 0.80 | 0.99 | 1.0 | 1.0 |
| Pck Endgame | 0.01 | 0.03 | 0.93 | 0.98 | 0.99 | 1.0 |
| Pck McAfee | 0.20 | 0.64 | 0.81 | 0.99 | 1.0 | 1.0 |
| NPck eGambit | 0.80 | 0.83 | 0.88 | 0.96 | 0.98 | 0.98 |
| NPck ALYac | 0.06 | 0.26 | 0.64 | 0.94 | 0.97 | 0.98 |
| NPck ViRobot | 0.18 | 0.24 | 0.48 | 0.73 | 0.80 | 0.88 |
| NPck Kingsoft | 0.09 | 0.12 | 0.25 | 0.54 | 0.72 | 0.82 |
| Mix eGambit | 0.08 | 0.14 | 0.79 | 0.96 | 0.98 | 0.99 |
| Mix TheHacker | 0.01 | 0.13 | 0.58 | 0.91 | 0.97 | 0.98 |
| Mix Kaspersky | 0.13 | 0.51 | 0.60 | 0.94 | 0.97 | 0.99 |
| Mix Endgame | 0.11 | 0.19 | 0.68 | 0.92 | 0.96 | 0.98 |
| Packer | SASpyware | TotalDefense | Endgame | McAfee |
|---|---|---|---|---|
| Armadillo | 97.30% | 94.87% | 95.12% | 96.88% |
| ASPack | 75.00% | 100.0% | 80.00% | 93.33% |
| ASProtect | 100.0% | 100.0% | 100.0% | 100.0% |
| Borland | 97.20% | 93.66% | 92.16% | 94.48% |
| NET | 97.96% | 96.51% | 95.49% | 96.64% |
| PEComp | 100.0% | 100.0% | 93.55% | 97.30% |
| UPX | 98.22% | 97.98% | 97.69% | 97.35% |
| Rest | 98.43% | 98.22% | 96.23% | 98.09% |
| Anti-Virus | Accuracy | Anti-Virus | Accuracy | Anti-Virus | Accuracy |
|---|---|---|---|---|---|
| eGambit | 96.50% | TotalDefense | 94.74% | K7GW | 94.48% |
| SASpyware | 95.75% | CATQHeal | 94.74% | Comodo | 94.44% |
| Ad-Aware | 95.65% | K7AntiVirus | 94.71% | McAfee-GW | 94.44% |
| ALYac | 95.53% | Cyren | 94.70% | TheHacker | 94.41% |
| Rising | 95.40% | BitDefender | 94.68% | Symantec | 94.38% |
| F-Prot | 95.36% | DrWeb | 94.68% | MAX | 94.38% |
| Jiangmin | 95.33% | Microsoft | 94.65% | Avira | 94.34% |
| ClamAV | 95.21% | Invincea | 94.64% | Avast | 94.33% |
| AhnLab-V3 | 95.15% | SentinelOne | 94.64% | Paloalto | 94.33% |
| Bkav | 95.00% | ZoneAlarm | 94.60% | Kaspersky | 94.33% |
| Webroot | 94.92% | Qihoo-360 | 94.60% | Fortinet | 94.30% |
| MicroWorld | 94.90% | Emsisoft | 94.60% | NANO | 94.24% |
| Baidu | 94.89% | TrendMicro | 94.59% | AVware | 94.24% |
| Tencent | 94.85% | CrowdStrike | 94.59% | ENOD32 | 94.23% |
| GData | 94.82% | F-Secure | 94.59% | VIPRE | 94.20% |
| Arcabit | 94.79% | VBA32 | 94.59% | Endgame | 94.13% |
| Sophos | 94.77% | CMC | 94.57% | McAfee | 94.07% |
| Panda | 94.77% | AVG | 94.52% | ViRobot | 92.70% |
| Yandex | 94.74% | TMHouseC | 94.50% | Kingsoft | 92.30% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Menéndez, H.D.; Llorente, J.L. Mimicking Anti-Viruses with Machine Learning and Entropy Profiles. Entropy 2019, 21, 513. https://doi.org/10.3390/e21050513
Menéndez HD, Llorente JL. Mimicking Anti-Viruses with Machine Learning and Entropy Profiles. Entropy. 2019; 21(5):513. https://doi.org/10.3390/e21050513
Chicago/Turabian StyleMenéndez, Héctor D., and José Luis Llorente. 2019. "Mimicking Anti-Viruses with Machine Learning and Entropy Profiles" Entropy 21, no. 5: 513. https://doi.org/10.3390/e21050513