Support Vector Machine-Based Transmit Antenna Allocation for Multiuser Communication Systems



Abstract
:1. Introduction
1.1. Related Work
1.2. Motivations and Contributions
- We interpret the antenna allocation system for multiuser communication as a multiclass classification learning system. For the components of the learning system, such as the training data and the corresponding class labels, we first model the counterparts in the conventional communication system, and we then construct them with a proper format for the learning system.
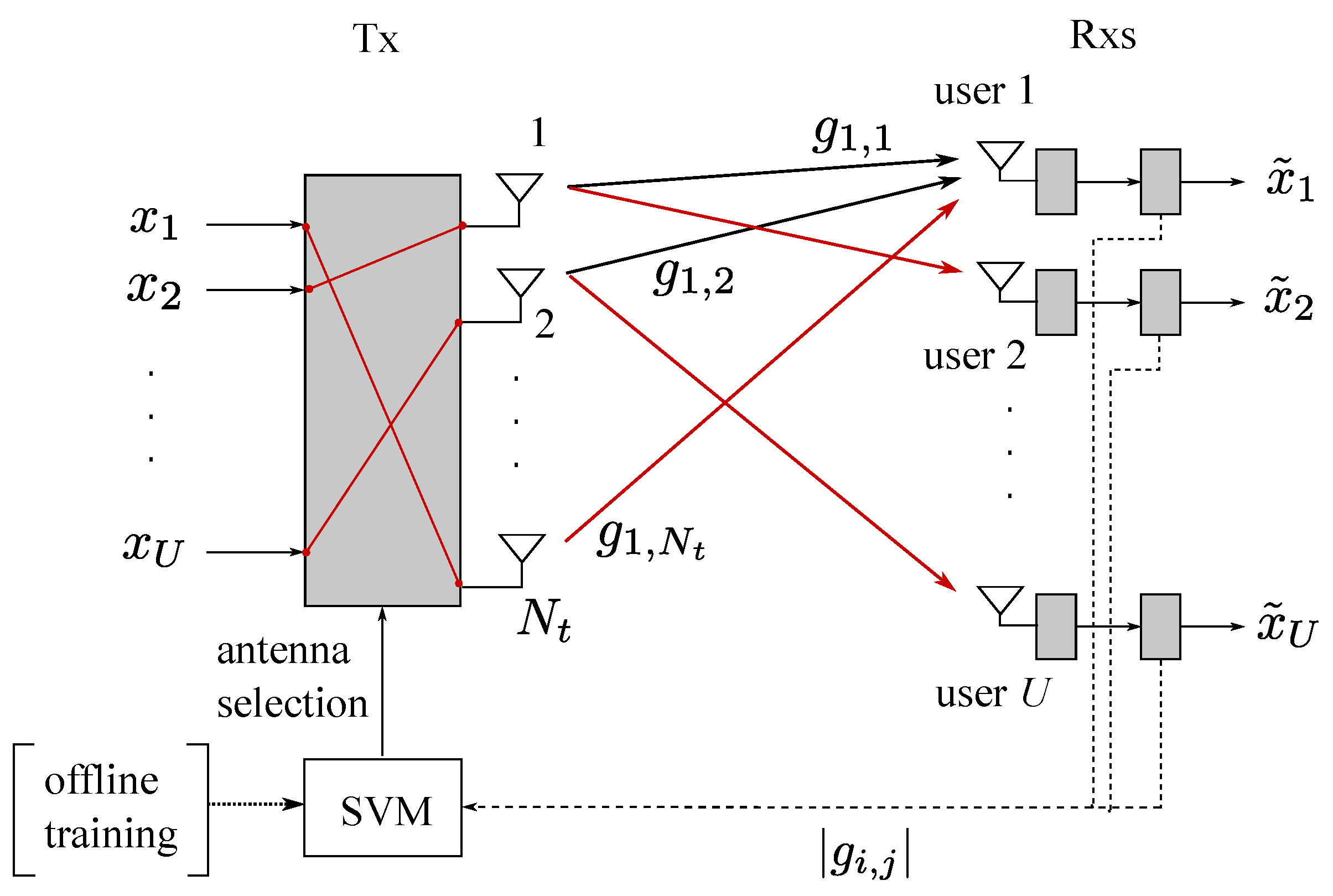
- We establish a communication system with an SVM module that allocates transmit antennas to each user in multiuser communication networks with partial channel state information at the transmitter (CSIT), as shown in Figure 1. The antenna allocation method is designed for a frequency-division duplex (FDD) system, where only quantized channel gain information is available.
- The parameters of the designed SVM are tuned based on extensive numerical experiments in order to improve the sum-rate performance of the communication system. For the designed SVM, we find that a Gaussian function is a good choice for the kernel function, which is one of the most important parameters for tuning SVMs. (Artificial neural networks (ANNs) can also be employed in our learning system, which may result in a slightly better sum-rate performance at the expense of both higher computational complexity and a larger training dataset than for k-NN and SVM. Thus, ANNs are not considered in this study as our main focus is on the design of learning systems showing a significant reduction in complexity from the optimization-based approach with marginal sum rate reduction.) From our rigorous simulation, the variance (kernel scale) and penalty parameter (box constraint) of an SVM kernel function are determined by 21.56 and 7.67, respectively.
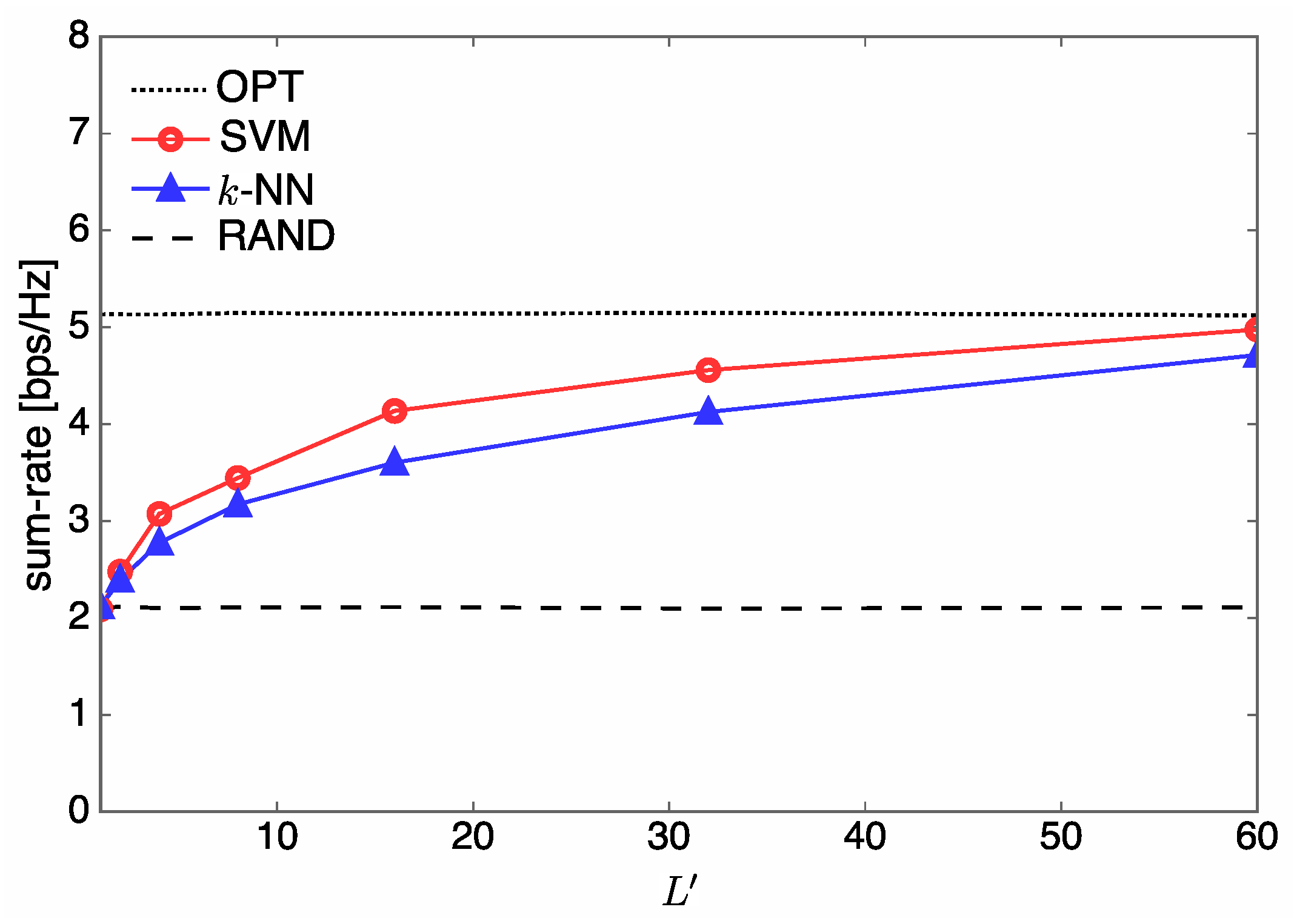
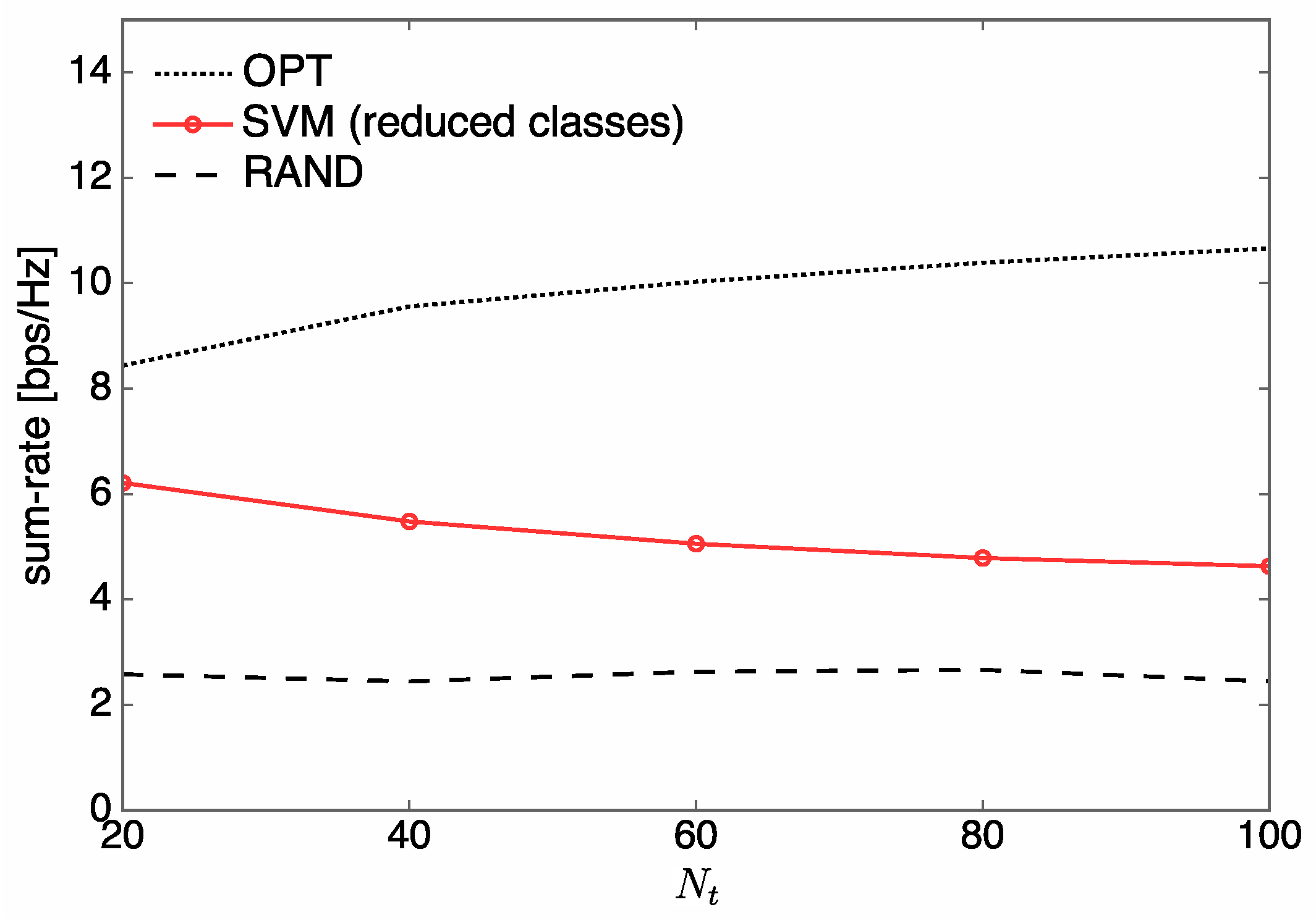
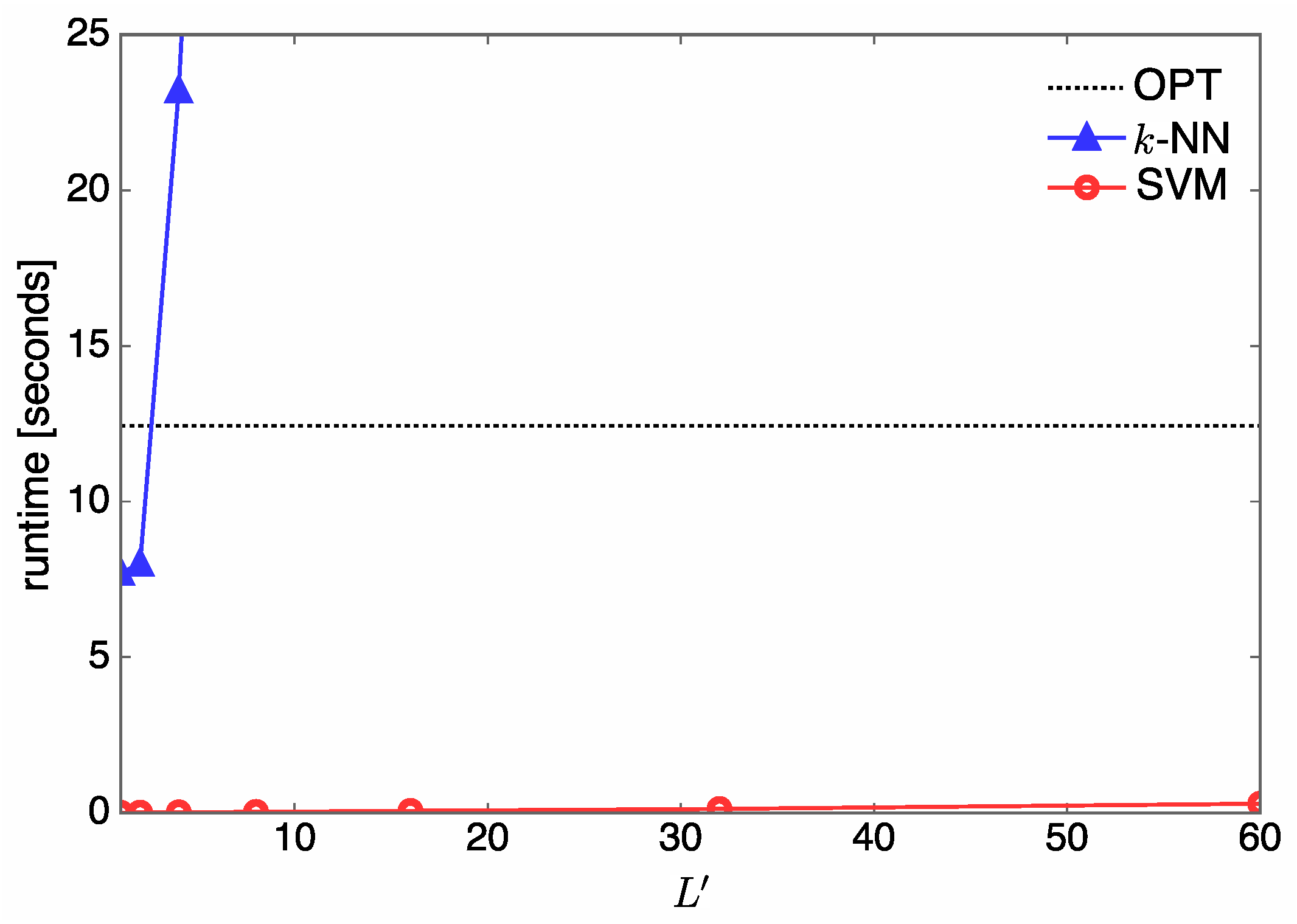
- Numerical experiments are extensively performed for various configurations of communication systems in order to evaluate the proposed SVM-based antenna allocation method. We find that with lower online computational complexity, the designed SVM method achieves near-optimal performance, as is obtained from the conventional optimization approach. Compared to the k-NN method, the SVM method is superior not only in terms of sum-rate performance but also prediction complexity performance.
1.3. Organization
2. System Model and Conventional Optimization Approach
2.1. System Model
2.2. Optimization Problem Formulation
2.3. Optimization-Driven Solutions
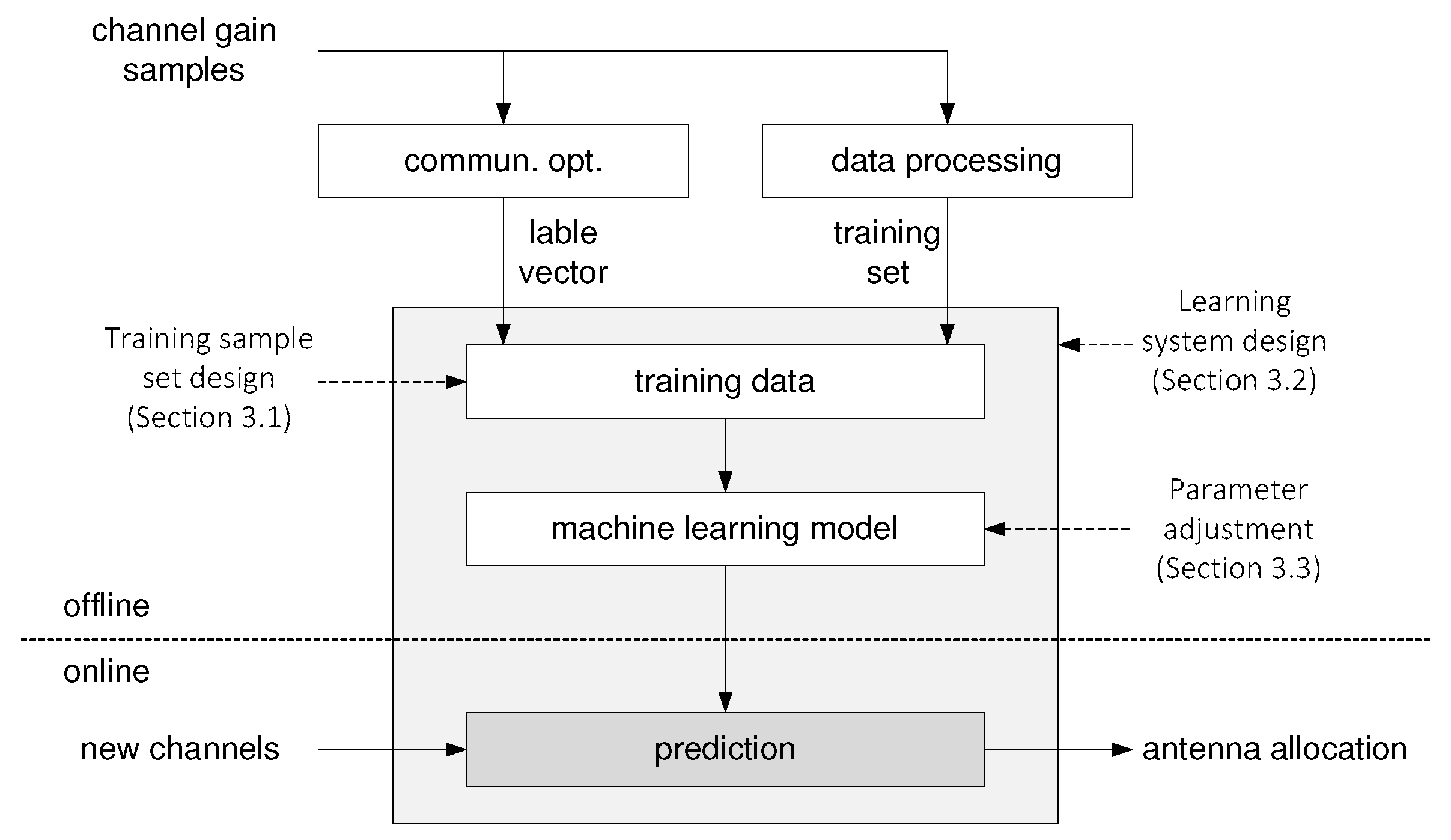
3. SVM-Based Antenna Allocation
3.1. Task 1: Designing a Training Sample Set
3.1.1. Subtask 1-1: KPI Design
3.1.2. Subtask 1-2. Training Set Design
3.1.3. Subtask 1-3. Class Design and Labeling
- Evaluate the target KPI, , for the dth channel gain sample with a particular antenna allocation corresponding to label .
- Assign the dth element of , , with , which stands for the best choice among all the antenna allocation schemes.
- Repeat the previous two steps for D times to go through all D training set.
3.2. Task 2: Designing Learning Systems
3.3. Task 3. Parameter Adjustment
4. Numerical Evaluation
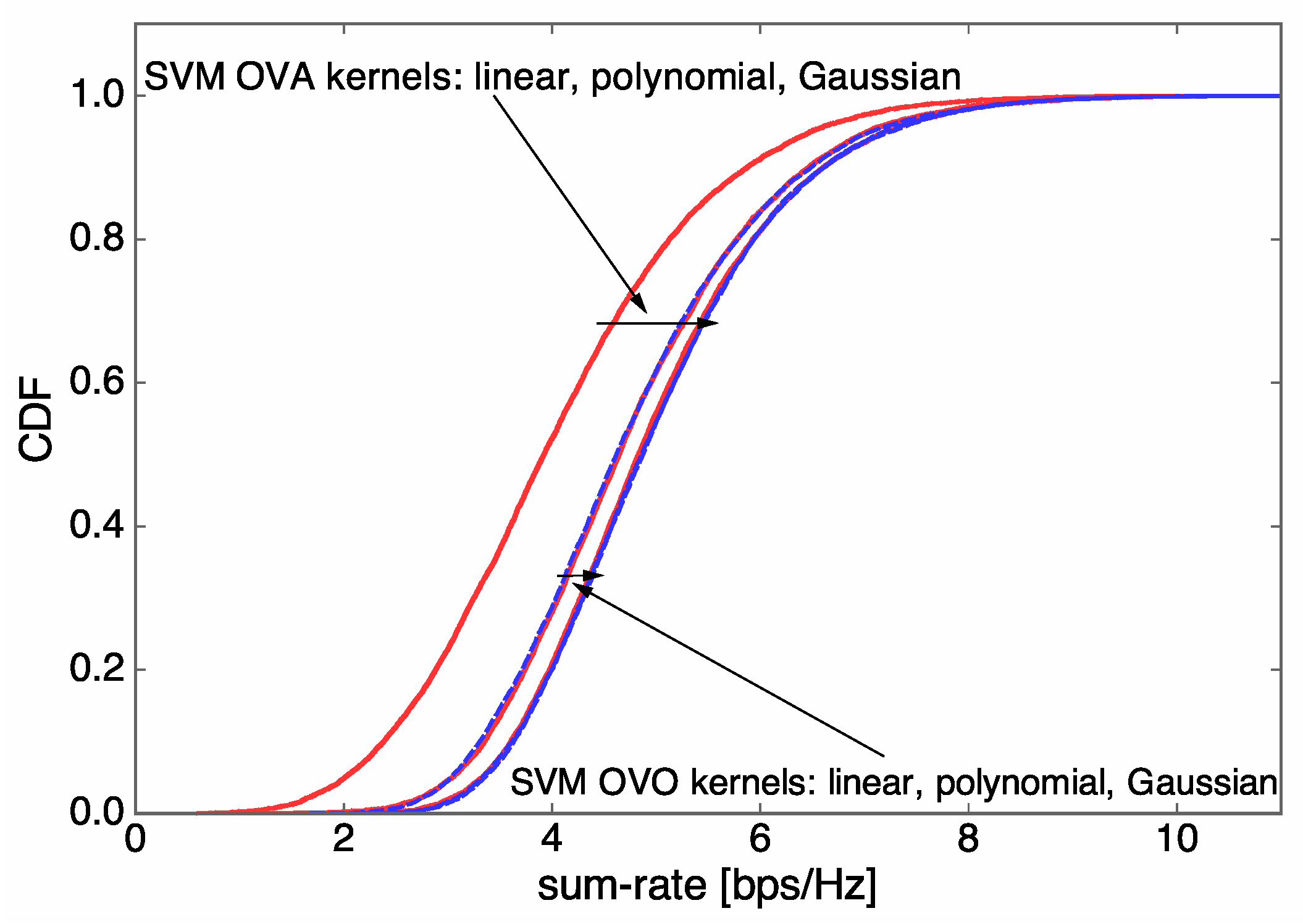
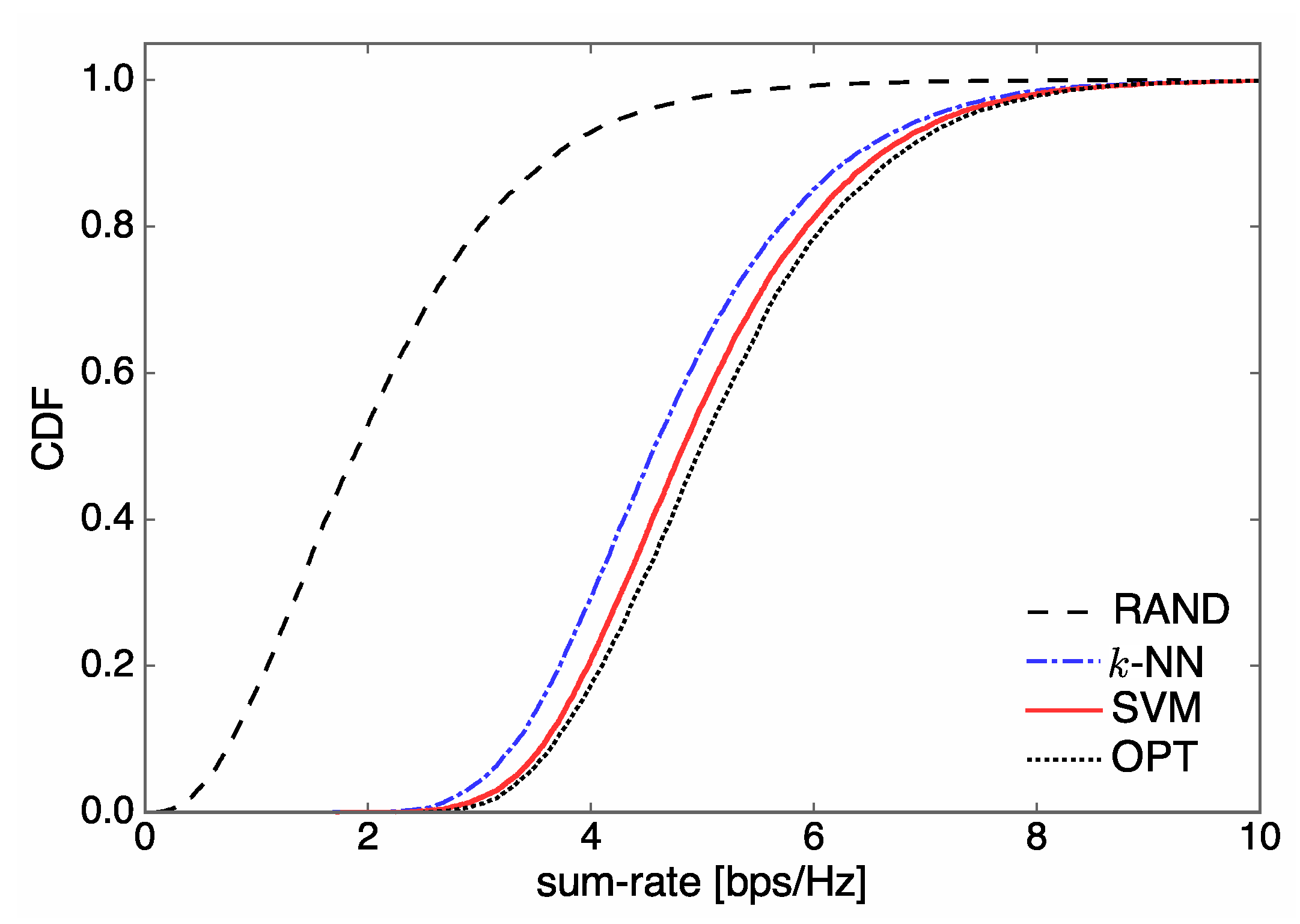
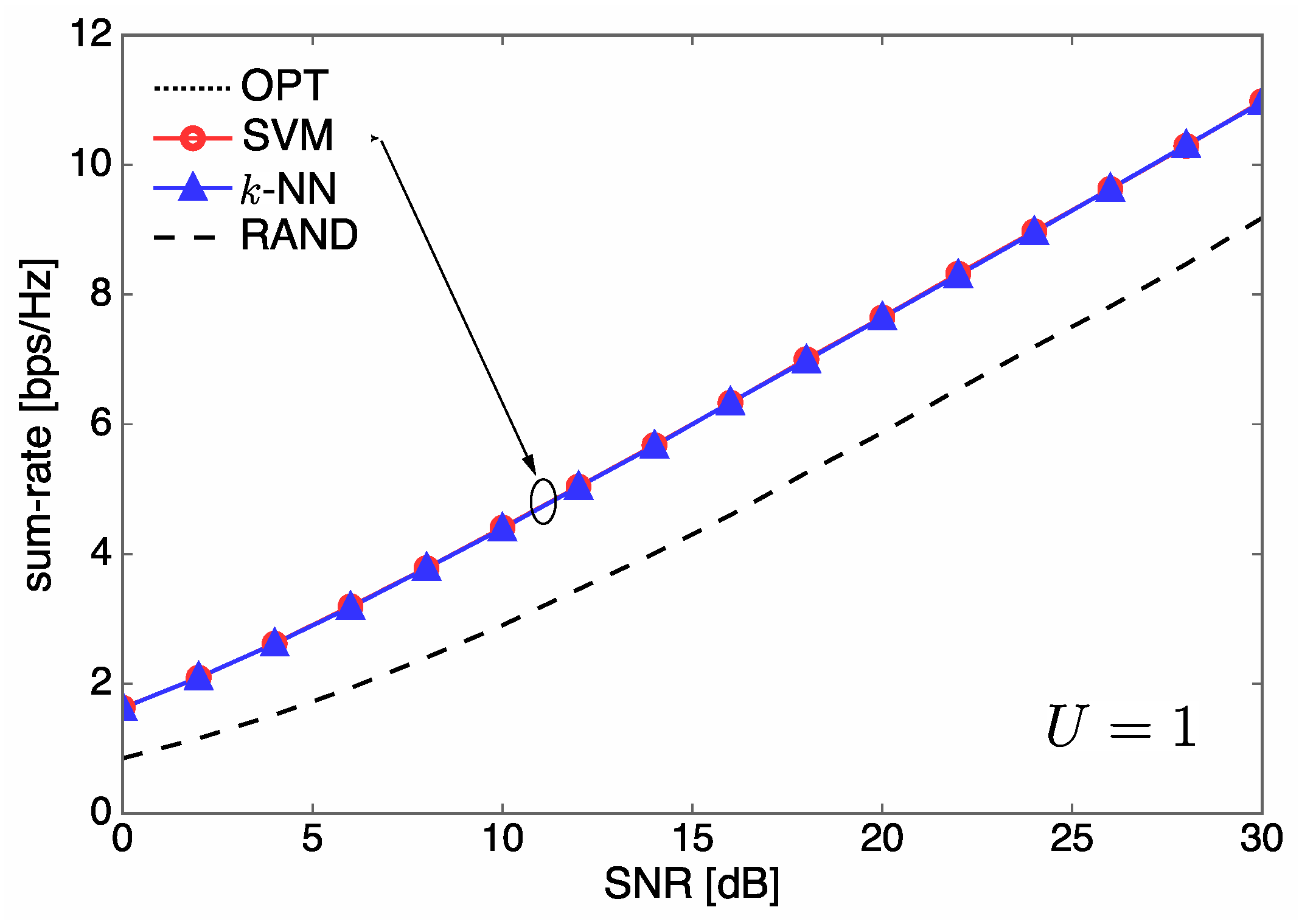
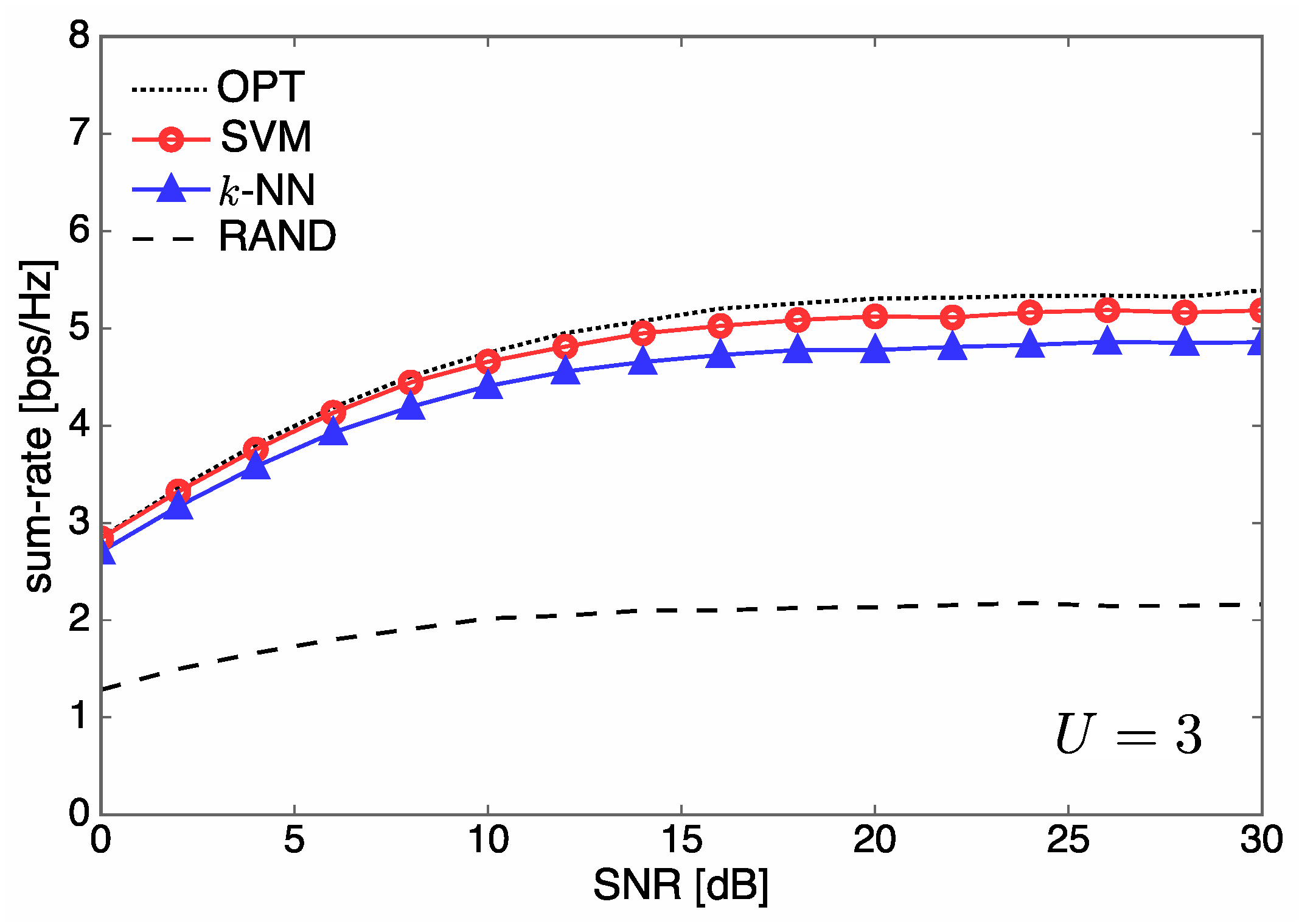
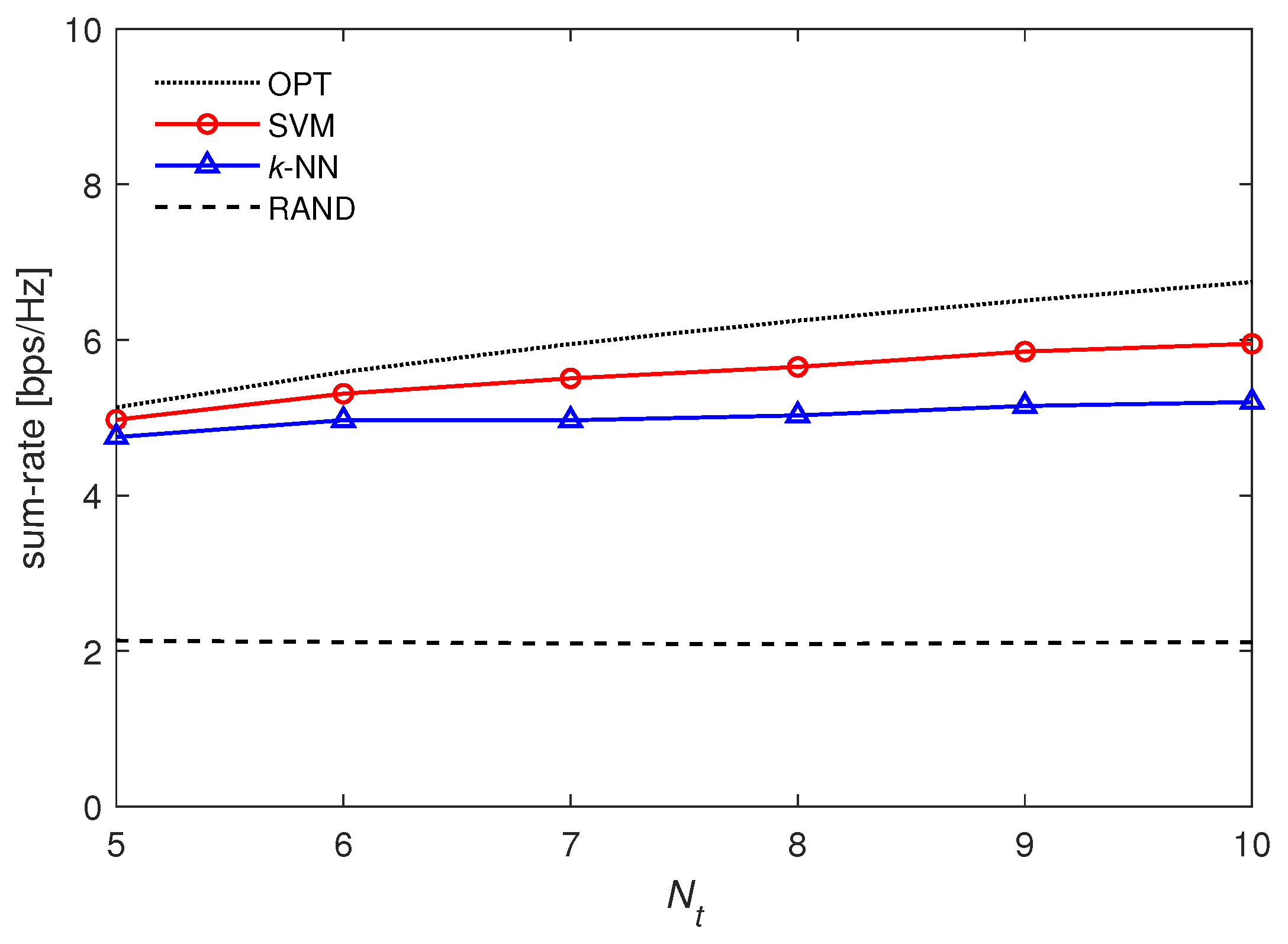
4.1. Sum-Rate Performance
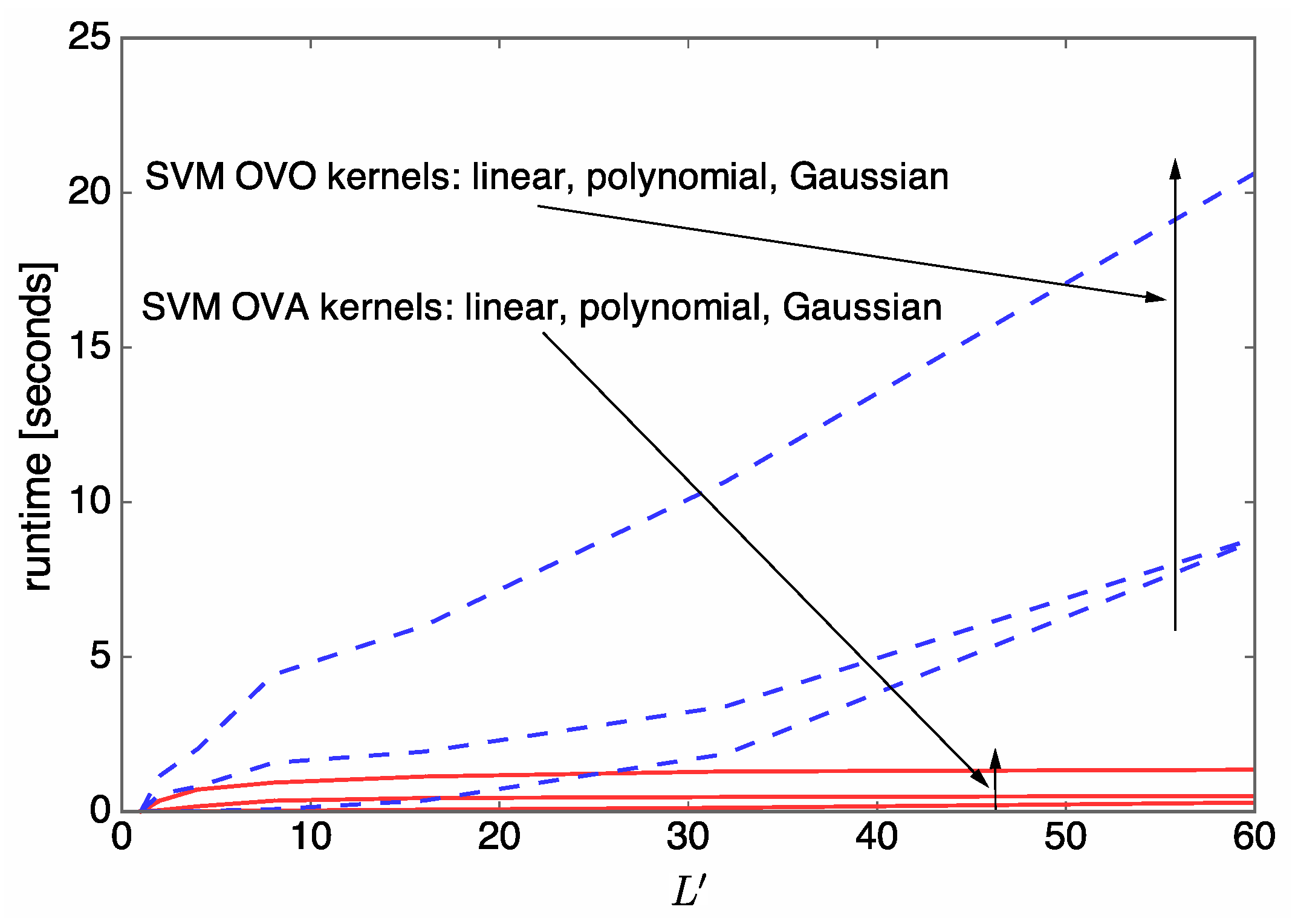
4.2. Complexity Analysis and Runtime Evaluation
5. Concluding Remarks and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Er, M.J.; Zhou, Y. Theory and Novel Applications of Machine Learning; InTech.: London, UK, 2009. [Google Scholar]
- Michalski, R.S.; Carbonell, J.G.; Mitchell, T.M. Machine Learning: An Artificial Intelligence Approach; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Zhang, Z.; Chong, E.K.P.; Pezeshki, A.; Moran, W.; Howard, S.D. Learning in hierarchical social networks. IEEE J. Sel. Topics Signal Process. 2013, 7, 305–317. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Xu, J.; Song, L.; Xu, J.Y.; Pottie, G.J.; Van der Schaar, M. Personalized active learning for activity classification using wireless wearable sensors. IEEE J. Sel. Topics Signal Process. 2016, 10, 865–876. [Google Scholar] [CrossRef]
- Chen, X.; Kopsaftopoulos, F.; Wu, Q.; Ren, H.; Chang, F.K. Flight state identification of a self-sensing wing via an improved feature selection method and machine learning approaches. Sensors 2018, 18, 1379. [Google Scholar] [CrossRef]
- Liu, D.; Liu, X.; Wu, Y. Depth reconstruction from single images using a convolutional neural network and a condition random field model. Sensors 2018, 18, 1318. [Google Scholar] [CrossRef] [PubMed]
- Hosseinyalamdary, S. Deep Kalman filter: Simultaneous multi-sensor integration and modelling; A GNSS/IMU case study. Sensors 2018, 18, 1316. [Google Scholar] [CrossRef] [PubMed]
- Woo, W.L.; Gao, B.; Bouridane, A.; Ling, B.W.; Chin, C.S. Unsupervised learning for monaural source separation using maximization-mMinimization algorithm with time-frequency deconvolution. Sensors 2018, 18, 1371. [Google Scholar] [CrossRef]
- Yang, G.; Yang, J.; Sheng, W.; Junior, F.; Li, S. Convolutional neural network-based embarrassing situation detection under camera for social robot in smart homes. Sensors 2018, 18, 1530. [Google Scholar] [CrossRef]
- Coutinho, M.; de Oliveira Albuquerque, R.; Borges, F.; García Villalba, L.J.; Kim, T.H. Learning perfectly secure cryptography to protect communications with adversarial neural cryptography. Sensors 2018, 18, 1306. [Google Scholar] [CrossRef] [PubMed]
- Heath, R.W.; Sandhu, S.; Paulraj, A. Antenna selection for spatial multiplexing systems with linear receivers. IEEE Commun. Lett. 2001, 5, 142–144. [Google Scholar] [CrossRef]
- Sanayei, S.; Nosratinia, A. Antenna selection in MIMO systems. IEEE Commun. Mag. 2004, 42, 68–73. [Google Scholar] [CrossRef]
- Molisch, A.F.; Win, M.Z.; Choi, Y.-S.; Winters, J.H. Capacity of MIMO systems with antenna selection. IEEE Trans. Wirel. Commun. 2005, 4, 1759–1772. [Google Scholar] [CrossRef] [Green Version]
- Chen, R.; Heath, R.W.; Andrews, J.G. Transmit selection diversity for unitary precoded multiuser spatial multiplexing systems with linear receivers. IEEE Trans. Signal Process. 2007, 55, 1159–1171. [Google Scholar] [CrossRef]
- Samek, W.; Stanczak, S.; Wiegand, T. The convergence of machine learning and communications. arXiv 2017, arXiv:1708.08299. [Google Scholar]
- Jiang, C.; Zhang, H.; Ren, Y.; Han, Z.; Chen, K.-C.; Hanzo, L. Machine learning paradigms for next-generation wireless networks. IEEE Wireless Commun. 2017, 24, 98–105. [Google Scholar] [CrossRef]
- Bi, S.; Zhang, R.; Ding, Z.; Cui, S. Wireless communications in the era of big data. IEEE Commun. Mag. 2015, 53, 190–199. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.T.; Armitage, G. A survey of techniques for internet traffic classification using machine learning. IEEE Commun. Surveys Tuts. 2008, 10, 56–76. [Google Scholar] [CrossRef] [Green Version]
- Molisch, A.F.; Win, M.Z. MIMO systems with antenna selection. IEEE Microw. Mag. 2004, 5, 46–56. [Google Scholar] [CrossRef]
- Gorokhov, A.; Gore, D.A.; Paulraj, A.J. Receive antenna selection for MIMO spatial multiplexing: Theory and algorithms. IEEE Trans. Signal Process. 2003, 51, 2796–2807. [Google Scholar] [CrossRef]
- Choi, Y.; Molisch, A.; Win, M.; Winters, J. Fast antenna selection algorithms for MIMO systems. In Proceedings of the IEEE Vehicular Technology Conference, Orlando, FL, USA, 6–9 October 2003; pp. 1733–1737. [Google Scholar]
- Lin, P.-H.; Tsai, S.-H. Performance analysis and algorithm designs for transmit antenna selection in linearly precoded multiuser MIMO systems. IEEE Trans. Veh. Technol. 2012, 61, 1698–1708. [Google Scholar] [CrossRef]
- Patcharamaneepakorn, P.; Doufexi, A.; Armour, S. Reduced complexity joint user and receive antenna selection algorithms for SLNR-based precoding in MU-MIMO systems. In Proceedings of the 2012 IEEE 75th Vehicular Technology Conference (VTC Spring), Yokohama, Japan, 6–9 May 2012; pp. 1–5. [Google Scholar]
- Jeong, M.-W.; Ban, T.-W.; Jung, B.C. User and antenna joint selection in multi-user large-scale MIMO downlink networks. IEICE Trans. Commun. 2017, 100, 529–535. [Google Scholar] [CrossRef]
- Chan, P.T.; Palaniswami, M.; Everitt, D. Neural network-based dynamic channel assignment for cellular mobile communication systems. IEEE Trans. Veh. Technol. 1994, 43, 279–288. [Google Scholar] [CrossRef]
- Xia, M.; Owada, Y.; Inoue, M.; Harai, H. Optical and wireless hybrid access networks: Design and optimization. J. Opt. Commun. Netw. 2012, 4, 749–759. [Google Scholar] [CrossRef]
- Joung, J.; Chia, Y.K.; Sun, S. Energy-efficient, large-scale distributed-antenna system (L-DAS) for multiple users. IEEE J. Sel. Top. Signal Process. 2014, 8, 954–965. [Google Scholar] [CrossRef]
- Joung, J.; Jung, B.C. Machine learning based blind decoding for space-time line code (STLC) systems. IEEE Trans. Veh. Technol. 2019, 1, 1–4. [Google Scholar]
- Sharma, D.K.; Dhurandher, S.K.; Woungang, I.; Srivastava, R.K.; Mohananey, A.; Rodrigues, J.J.P.C. A machine learning-based protocol for efficient routing in opportunistic networks. IEEE Syst. J. 2018, 12, 2207–2213. [Google Scholar] [CrossRef]
- Maghsudi, S.; Stańczak, S. Channel selection for network-assisted D2D communication via no-regret bandit learning with calibrated forecasting. IEEE Trans. Wireless Commun. 2015, 14, 1309–1322. [Google Scholar] [CrossRef]
- Tekin, C.; Liu, M. Online learning methods for networking. Found. Trends. Network. 2015, 8, 281–409. [Google Scholar] [CrossRef]
- Yun, S.; Caramanis, C. Reinforcement learning for link adaptation in MIMO-OFDM wireless systems. In Proceedings of the 2010 IEEE Global Telecommunications Conference GLOBECOM 2010, Miami, FL, USA, 6–10 December 2010; pp. 1–5. [Google Scholar]
- Iacoboaiea, O.-C.; Sayrac, B.; Jemaa, S.B.; Bianchi, P. SON coordination in heterogeneous networks: A reinforcement learning framework. IEEE Trans. Wirel. Commun. 2016, 15, 5835–5847. [Google Scholar]
- Aprem, A.; Murthy, C.R.; Mehta, N.B. Transmit power control policies for energy harvesting sensors with retransmissions. IEEE J. Sel. Top. Signal Process. 2013, 7, 895–906. [Google Scholar] [CrossRef]
- Lundén, J.; Kulkarni, S.R.; Koivunen, V.; Poor, H.V. Multiagent reinforcement learning based spectrum sensing policies for cognitive radio networks. IEEE J. Sel. Top. Signal Process. 2013, 7, 858–868. [Google Scholar] [CrossRef]
- Alnwaimi, G.; Vahid, S.; Moessner, K. Dynamic heterogeneous learning games for opportunistic access in LTE-based macro/femtocell deployments. IEEE Trans. Wirel. Commun. 2015, 14, 2294–2308. [Google Scholar] [CrossRef]
- Tsiligkaridis, T.; Romero, D. Accelerated reinforcement learning algorithms with nonparametric function approximation for opportunistic spectrum access. arXiv 2017, arXiv:1706.04546. [Google Scholar]
- Daniels, R.; Heath, R. An online learning framework for link adaptation in wireless networks. In Proceedings of the 2009 Information Theory and Applications Workshop, San Diego, CA, USA, 8–13 February 2009; pp. 138–140. [Google Scholar]
- Yun, S.; Caramanis, C. Multiclass support vector machines for adaptation in MIMO-OFDM wireless systems. In Proceedings of the 2009 47th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 30 Septmber–2 October 2009; pp. 1145–1152. [Google Scholar]
- Rico-Alvarino, A.; Heath, R.W. Learning-based adaptive transmission for limited feedback multiuser MIMO-OFDM. IEEE Trans. Wirel. Commun. 2014, 13, 3806–3820. [Google Scholar] [CrossRef]
- Feng, C.; Liao, S. Scalable Gaussian kernel support vector machines with sublinear training time complexity. Inf. Sci. 2017, 418, 480–494. [Google Scholar] [CrossRef]
- Yuan, Y.; Zhang, M.; Luo, P.; Ghassemlooy, Z.; Lang, L.; Wang, D.; Zhang, B.; Han, D. SVM-based detection in visible light communications. Optik 2017, 151, 55–64. [Google Scholar] [CrossRef]
- Wang, J.-B.; Wang, J.; Wu, Y.; Wang, J.-Y.; Zhu, H.; Lin, M.; Wang, J. A machine learning framework for resource allocation assisted by cloud computing. IEEE Netw. 2018, 32, 144–151. [Google Scholar] [CrossRef]
- Al Rahhal, M.M.; Bazi, Y.; Alhichri, H.; Alajlan, N.; Melgani, F.; Yager, R.R. Deep learning approach for active classification of electrocardiogram signals. Inf. Sci. 2016, 345, 340–354. [Google Scholar] [CrossRef]
- O’Shea, T.; Hoydis, J. An introduction to deep learning for the physical layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning. MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Joung, J. Machine learning-based antenna selection in wireless communications. IEEE Commun. Lett. 2016, 20, 2241–2244. [Google Scholar] [CrossRef]
- Asadi, A.; Mancuso, V. A survey on opportunistic scheduling in wireless communications. IEEE Commun. Surv. Tuts. 2013, 15, 1671–1688. [Google Scholar] [CrossRef]
- Kurniawan, E.; Joung, J.; Sun, S. Limited feedback scheme for massive MIMO in mobile multiuser FDD systems. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 1710–1715. [Google Scholar]
- Zhang, H.; Berg, A.C.; Maire, M.; Malik, J. SVM-KNN: Discriminative nearest neighbor classification for visual category recognition. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 2126–2136. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Osseiran, A.; Boccardi, F.; Braun, V.; Kusume, K.; Marsch, P.; Maternia, M.; Queseth, O.; Schellmann, M.; Schotten, H.; Taoka, H.; et al. Scenarios for 5G mobile and wireless communications: The vision of the METIS project. IEEE Commun. Mag. 2014, 52, 26–35. [Google Scholar] [CrossRef]
- Joung, J.; Sun, S. Two-step transmit antenna selection algorithms for massive MIMO. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6. [Google Scholar]
- Cariou, C.; Chehdi, K. Unsupervised nearest neighbors clustering with application to hyperspectral images. IEEE J. Sel. Top. Signal Process. 2015, 9, 1105–1116. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef] [Green Version]
- Escalera, S.; Pujol, O.; Radeva, P. On the decoding process in ternary error-correcting output codes. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 120–134. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| number of antennas at the transmitter | |
| U | number of users |
| channel coefficient vector to device i | |
| overall channel coefficient matrix | |
| overall channel gain matrix | |
| index vector of the allocated antenna with label l | |
| set of labels for all the available antennas allocated | |
| L | number of labels in |
| transmit power per antenna | |
| sum rate of the system in bps/Hz |
| Algorithm | OPT | RAND | k-NN | SVM |
|---|---|---|---|---|
| Sum-rate performance | Best | Worst | Close to SVM | Second-best |
| Allocation complexity | for OVO and for OVA |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, H.; Shin, W.-Y.; Joung, J. Support Vector Machine-Based Transmit Antenna Allocation for Multiuser Communication Systems. Entropy 2019, 21, 471. https://doi.org/10.3390/e21050471
Lin H, Shin W-Y, Joung J. Support Vector Machine-Based Transmit Antenna Allocation for Multiuser Communication Systems. Entropy. 2019; 21(5):471. https://doi.org/10.3390/e21050471
Chicago/Turabian StyleLin, Huifa, Won-Yong Shin, and Jingon Joung. 2019. "Support Vector Machine-Based Transmit Antenna Allocation for Multiuser Communication Systems" Entropy 21, no. 5: 471. https://doi.org/10.3390/e21050471