Upper Bound on the Joint Entropy of Correlated Sources Encoded by Good Lattices

Abstract
:
1. Introduction
1.1. Contributions
- A class of upper bounds on conditional entropy-rates of appropriately designed lattice encoded Gaussian signals.
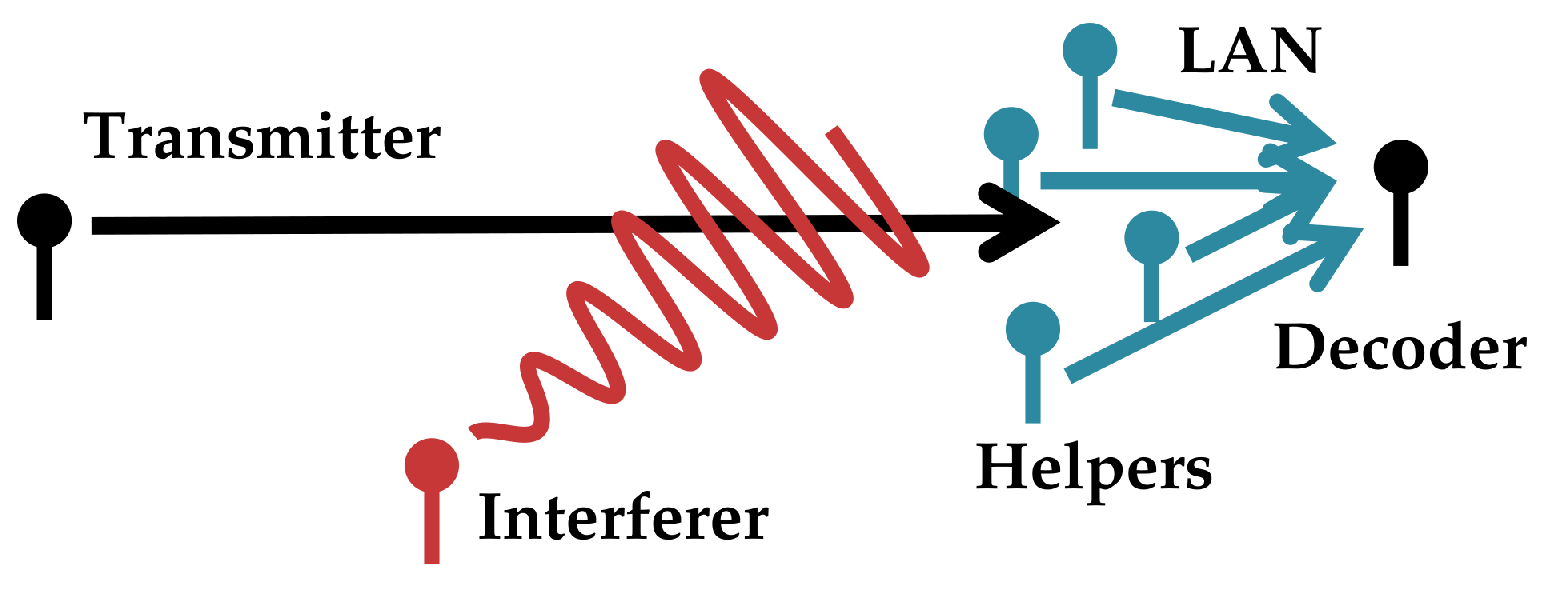
- An application of the bounds to the problem of point-to-point communication through a many-help-one network in the presence of interference. This strategy takes advantage of a specially designed transmitter codebook’s lattice structure.
- A numerical experiment demonstrating the behavior of these bounds. It is seen that a joint–compression stage can partially alleviate inefficiencies in lattice encoder design.
1.2. Background
1.3. Outline
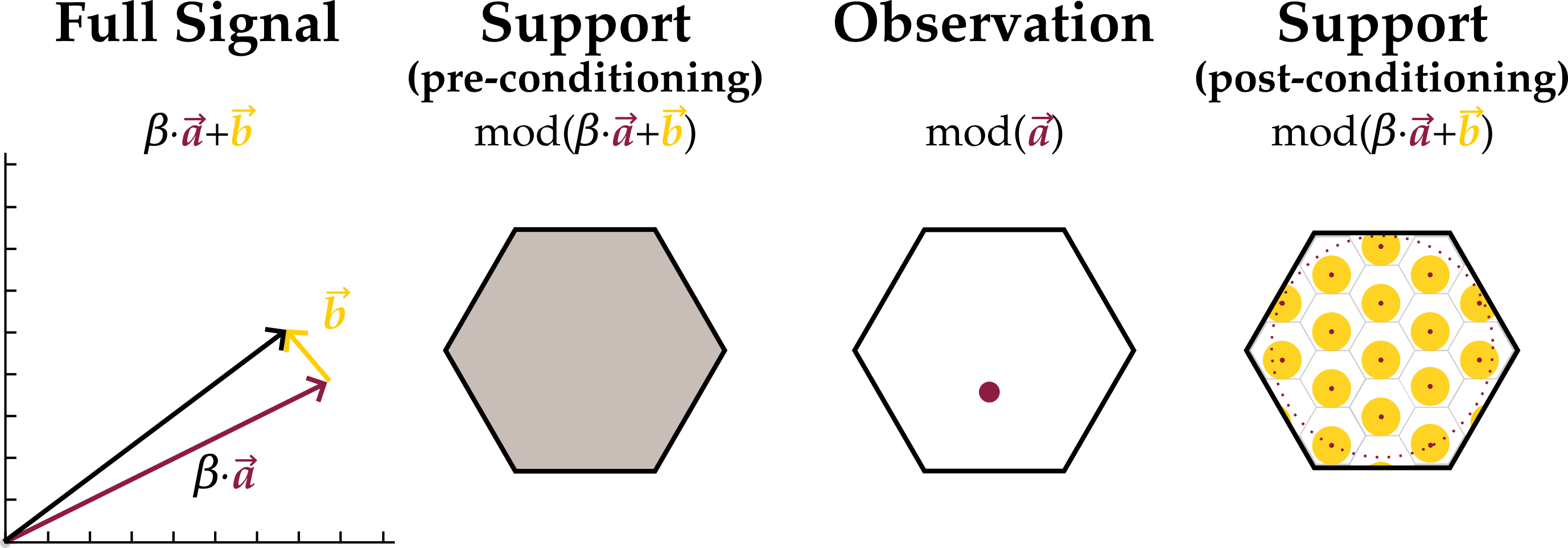
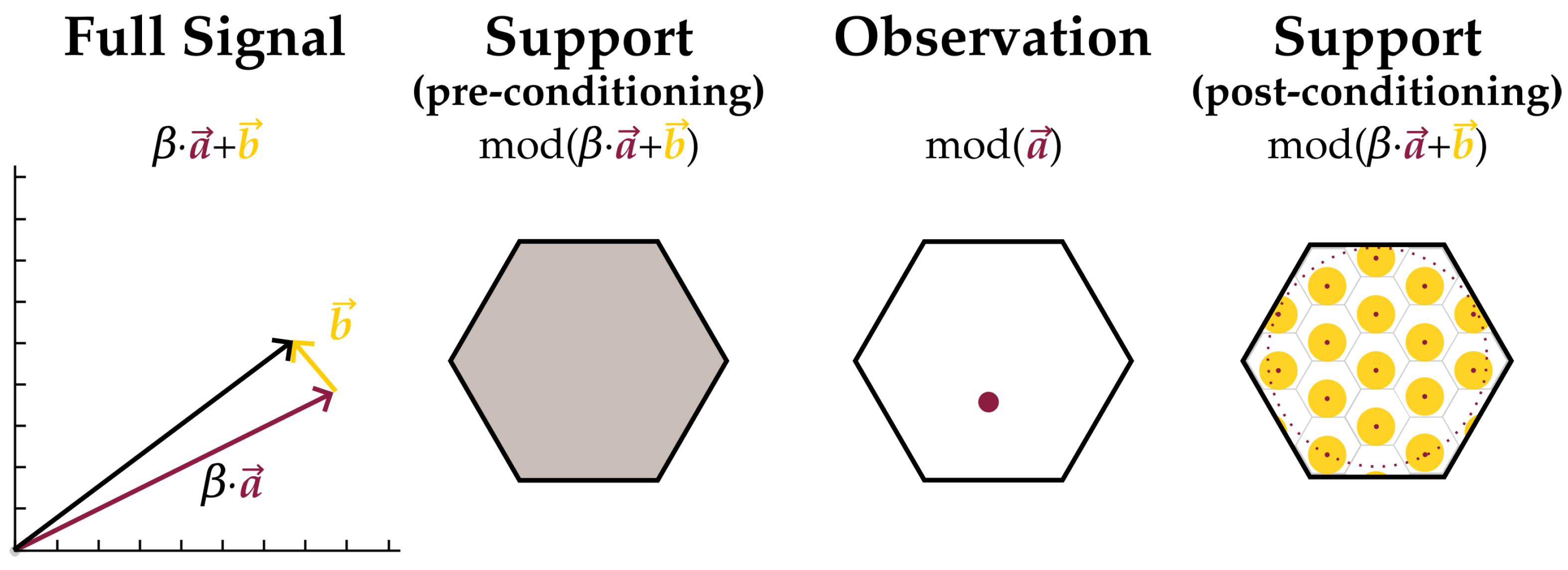
2. Main Results
- Choose some Apply Lemma 1 to . Call a ‘residual.’
- Choose some Apply Lemma 2 to the residual to break the residual up into the sum of a lattice part due to and a new residual, whatever is left over.
- Repeat the previous step until the residual vanishes (up to times). Notice that this process has given several different ways of writing ; by stopping at any amount of steps, is the modulo sum of several lattice components and a residual.
- Design the lattice ensemble for the encoders such that the log-volume contributed to the support of by each component can be estimated. The discrete parts will each contribute log-volume and residuals log-volume
- Recognize the entropy of is no greater than the log-volume of its support. Choose the lowest support log-volume estimate of those just found.
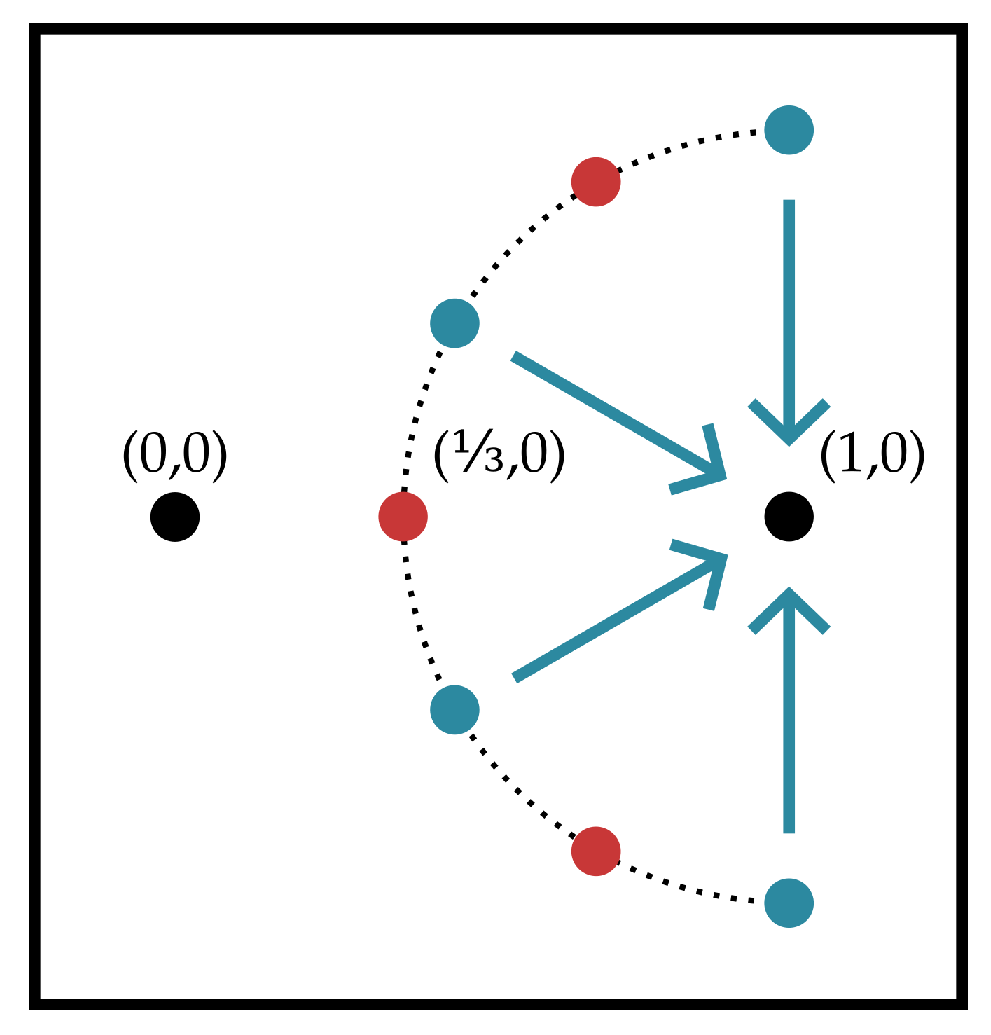
3. Lattice-Based Strategy for Communication via Decentralized Processing
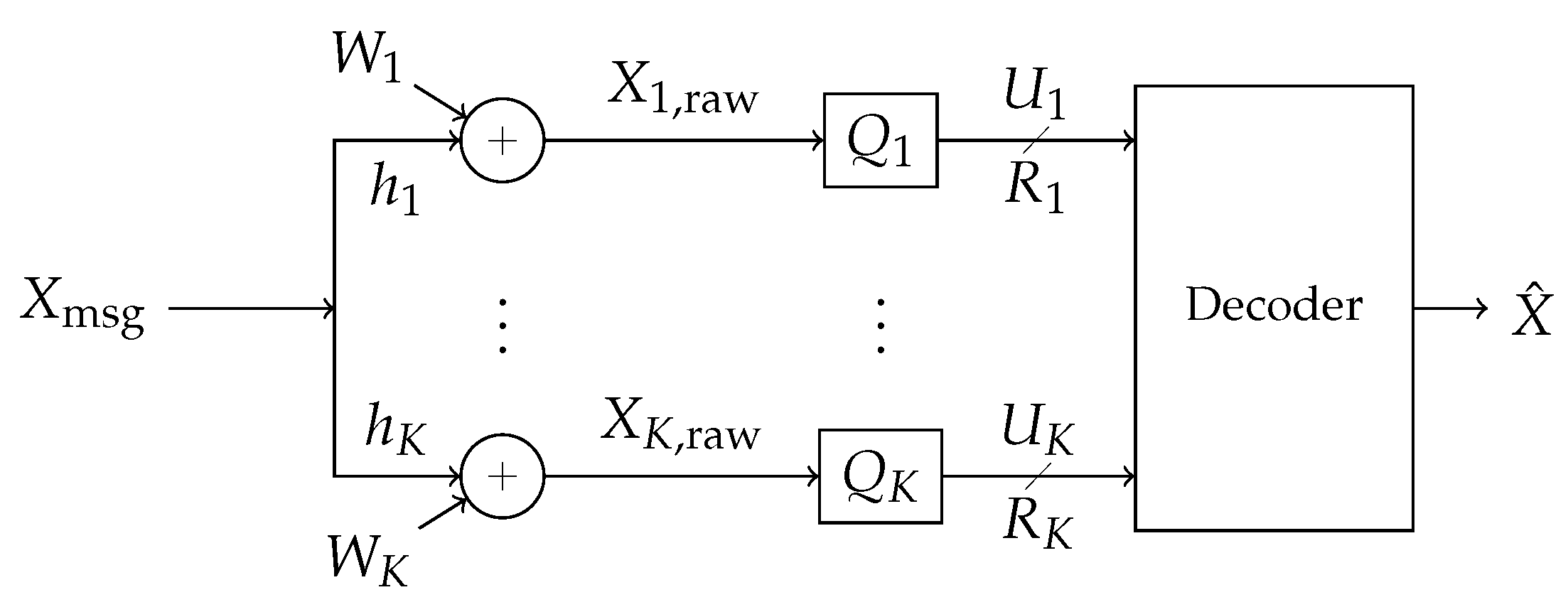
3.1. Description of the Communication Scheme
- is with high probability in the base cell of any lattice good for coding semi norm-ergodic noise up to power.
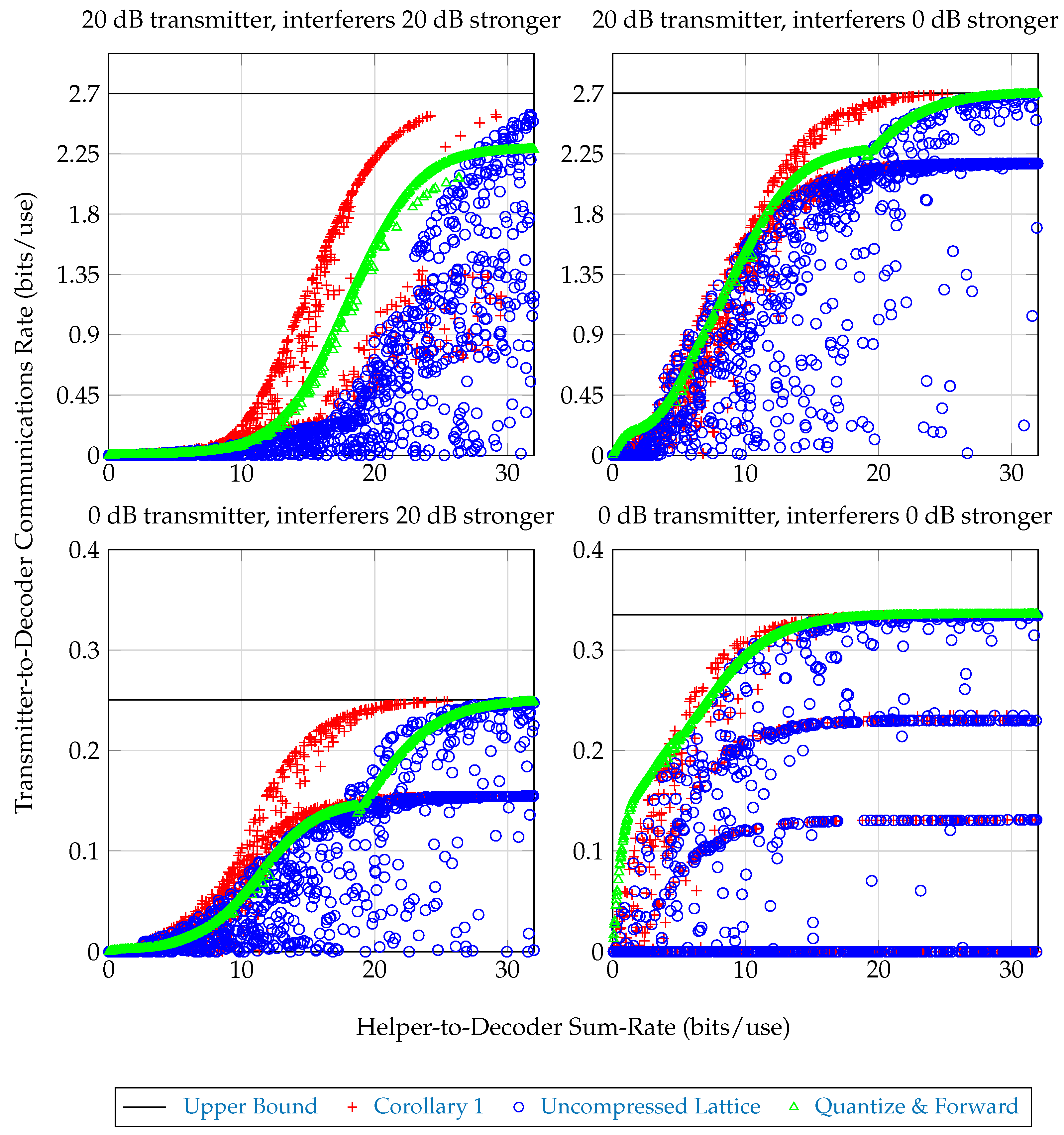
3.2. Numerical Results
3.2.1. Communications Schemes
- Fix some . If helper in the channel from Figure 4 observes , then it encodes a normalized version of the signal:
- Fix equal lattice encoding rates per helper , and take lattice encoders as described in Theorem 1. Note that these rates may be distinct from the helper-to-base rates if post-processing of the encodings is involved.
- Upper Bound: An upper bound on the achievable transmitter-to-decoder communications rate, corresponding to helpers which forward with infinite rate. This bound is given by the formula .
- Corollary 1 The achievable communications rate from Corollary 1, where each helper computes the lattice encoding described above, then employs a joint–compression stage to reduce its messaging rate. The sum-helpers-to-decoder rate for this scheme is given by Equation (2), taking The achieved messaging rate is given by the right-hand-side of Equation (3).
- Uncompressed Lattice: The achievable communications rate from Corollary 1, with each helper forwarding to the decoder its entire lattice encoding without joint–compression. The sum-helpers-to-decoder rate for this scheme is since in this scheme each helper forwards to the base at rate . The achieved messaging rate is given by the right-hand-side of Equation (3).
- Quantize & Forward: An achievable communications rate where helper-to-decoder rates are chosen so that and each helper forwards a rate-distortion-optimal quantization of its observation to the decoder. The decoder processes these quantizations into an estimate of and decodes. This is discussed in more detail in [13]. The sum-helpers-to-decoder rate for this scheme is . The achieved messaging rate is , where .
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Subroutines
- Stages*(·) is a slight modification of an algorithm from [3], reproduced here in Algorithm 1. The original algorithm characterizes the integral combinations which are recoverable with high probability from lattice messages and dithers , excluding those with zero power. The exclusion is due to the algorithm’s use of as just defined. Such linear combinations never arose in the context of [3], although it provides justification for them being recoverable; in the paper, the algorithm’s argument is always full-rank. This is not true in the present context. The version here includes these zero-power subspaces by including a call to before returning.
- , ‘Shortest Lattice Vector Coordinates’ returns the nonzero integer vector which minimizes the norm of while , or the zero vector if no such vector exists. can be implemented using a lattice enumeration algorithm like one in [15] together with the LLL algorithm to convert a set of spanning lattice vectors into a basis [16].
- LatticeKernel(B,A), for returns the integer matrix whose columns span the collection of all where while . In other words, it returns a basis for the integer lattice in whose components are orthogonal to the lattice . This can be implemented using an algorithm for finding ‘simultaneous integer relations’ as described in [17].
- CVarComponents returns certain variables involved in computingwhen has covariance . Write some matrices in block form:Then, taking one can check that:
- CVar computes the conditional covariance matrix of conditioned on for . This is given by the formula:
- in Algorithm 2 implements a strategy for choosing in Theorems 1, 2.
- in Algorithm 3 implements a strategy for choosing in theorems 1, 2.
| Algorithm 1 Compute recoverable linear combinations from modulos of lattice encodings with covariance . |
|
| Algorithm 2 Strategy for choosing for Theorems 1, 2 |
|
| Algorithm 3 Strategy for picking for Theorems 1, 2. |
|
Appendix B. Proof of Lemmas 1, 2, Theorem 1
Appendix B.1. Upper Bound for Singleton S
- Coarse and fine encoding lattices (base regions ) with each k has designed with nesting ratio .
- Discrete part auxiliary lattices (base regions ) with each having nesting ratio .
- Initial residual part auxiliary lattice (base region ) with , nesting ratio
- Residual part auxiliary lattices (base regions ) with each , having nesting ratio .
Appendix C. Sketch of Theorem 2 for Upper Bound on Entropy-Rates of Decentralized Processing Messages
Appendix D. Proof of Lemma 3 for Recombination of Decentralized Processing Lattice Modulos
Appendix E. Proof of Corollary 1 for Achievability of the Decentralized Processing Rate
References
- Zamir, R. Lattice Coding for Signals and Networks: A Structured Coding Approach to Quantization, Modulation, and Multiuser Information Theory; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Ordentlich, O.; Erez, U. A simple proof for the existence of “good” pairs of nested lattices. IEEE Trans. Inf. Theory 2016, 62, 4439–4453. [Google Scholar] [CrossRef]
- Chapman, C.; Kinsinger, M.; Agaskar, A.; Bliss, D.W. Distributed Recovery of a Gaussian Source in Interference with Successive Lattice Processing. Entropy 2019, 21, 845. [Google Scholar] [CrossRef]
- Erez, U.; Zamir, R. Achieving log(1+SNR) on the AWGN Channel With Lattice Encoding and Decoding. IEEE Trans. Inf. Theory 2004, 50, 1. [Google Scholar] [CrossRef]
- Ordentlich, O.; Erez, U.; Nazer, B. Successive integer-forcing and its sum-rate optimality. In Proceedings of the 2013 51st Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–4 October 2013; pp. 282–292. [Google Scholar]
- Ordentlich, O.; Erez, U. Precoded integer-forcing universally achieves the MIMO capacity to within a constant gap. IEEE Trans. Inf. Theory 2014, 61, 323–340. [Google Scholar] [CrossRef]
- Wagner, A.B. On Distributed Compression of Linear Functions. IEEE Trans. Inf. Theory 2011, 57, 79–94. [Google Scholar] [CrossRef]
- Yang, Y.; Xiong, Z. An improved lattice-based scheme for lossy distributed compression of linear functions. In Proceedings of the 2011 Information Theory and Applications Workshop, La Jolla, CA, USA, 6–11 Feburuary 2011. [Google Scholar]
- Yang, Y.; Xiong, Z. Distributed compression of linear functions: Partial sum-rate tightness and gap to optimal sum-rate. IEEE Trans. Inf. Theory 2014, 60, 2835–2855. [Google Scholar] [CrossRef]
- Cheng, H.; Yuan, X.; Tan, Y. Generalized compute-compress-and-forward. IEEE Trans. Inf. Theory 2018, 65, 462–481. [Google Scholar] [CrossRef]
- Saurabha, T.; Viswanath, P.; Wagner, A.B. The Gaussian Many-help-one Distributed Source Coding Problem. IEEE Trans. Inf. Theory 2009, 56, 564–581. [Google Scholar]
- Sanderovich, A.; Shamai, S.; Steinberg, Y.; Kramer, G. Communication via Decentralized Processing. IEEE Trans. Inf. Theory 2008, 54, 3008–3023. [Google Scholar] [CrossRef]
- Chapman, C.D.; Mittelmann, H.; Margetts, A.R.; Bliss, D.W. A Decentralized Receiver in Gaussian Interference. Entropy 2018, 20, 269. [Google Scholar] [CrossRef]
- El Gamal, A.; Kim, Y.H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Schnorr, C.P.; Euchner, M. Lattice Basis Reduction: Improved Practical Algorithms and Solving Subset Sum Problems. Math. Program. 1994, 66, 181–199. [Google Scholar] [CrossRef]
- Buchmann, J.; Pohst, M. Computing a Lattice Basis from a System of Generating Vectors. In Proceedings of the European Conference on Computer Algebra, Leipzig, Germany, 2–5 June 1987; pp. 54–63. [Google Scholar]
- Hastad, J.; Just, B.; Lagarias, J.C.; Schnorr, C.P. Polynomial time algorithms for finding integer relations among real numbers. SIAM J. Comput. 1989, 18, 859–881. [Google Scholar] [CrossRef]
- Ghasemmehdi, A.; Agrell, E. Faster recursions in sphere decoding. IEEE Trans. Inf. Theory 2011, 57, 3530–3536. [Google Scholar] [CrossRef]
- Krithivasan, D.; Pradhan, S.S. Lattices for Distributed Source Coding: Jointly Gaussian Sources and Reconstruction of a Linear Function. In International Symposium on Applied Algebra, Algebraic Algorithms, and Error-Correcting Codes; Springer: Berlin/Heidelberg, Germany, 2007; pp. 178–187. [Google Scholar] [Green Version]
- Erez, U.; Litsyn, S.; Zamir, R. Lattices Which are Good for (Almost) Everything. IEEE Trans. Inf. Theory 2005, 51, 3401–3416. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Define a to equal b | |
| Integers from 1 to n | |
| Matrix, column vector, vector, random vector | |
| Transpose (All matrices involved are real) | |
| Submatrix corresponding to rows S, columns T of | |
| an -vector, the sub-vector of including components with indices in S. If S has order then this vector respects S’s order. | |
| identity matrix | |
| zero vector | |
| Square diagonal matrix with diagonals | |
| Moore-Penrose pseudoinverse | |
| Normal distribution with zero mean, covariance | |
| X is a random variable distributed like f | |
| Vector of n independent trials of a random variable distributed like X, a function whose input is intended to be such a variable | |
| Variance (or covariance matrix) of (components of) a, averaged over time index. | |
| Conditional variance (or covariance matrix) of (components of) a given observation b, averaged over time index. | |
| Covariance between a and , covariance between a and b conditioned on c, averaged over time index. | |
| Linear MMSE estimate of a given observations b | |
| Complement of , i.e., . An important property is that and are uncorrelated. | |
| Lattice round, modulo to a lattice L (when it is clear what base region is associated with L). |
| K | Number of lattice encodings in current context. |
| n | Scheme blocklength |
| Observation at receiver k | |
| Lattice dither k | |
| Lattice encoding k | |
| Quantization of | |
| Ensemble of lattice quantizations, sans modulo | |
| time-averaged covariance between observations | |
| time-averaged covariance between quantizations | |
| Nesting ratios for coarse lattice in the fine lattices , equivalent to the encoding rates of lattice codes when joint compression is not used | |
| Messaging rates for helpers in the Section 3 communications scenario | |
| Nesting ratio for codebook coarse lattice in codebook fine lattice in Section 3, equivalent to codebook rate | |
| Covariance between codeword and quantizations in Section 3 | |
| Integer combination of to analyze in step s of Appendix B | |
| Variance of after removing prior knowledge in Appendix B | |
| Variance of uncorrelated with prior knowledge and in Appendix B | |
| Regression coefficient for in after including prior knowledge at step s in Appendix B |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chapman, C.; Bliss, D.W. Upper Bound on the Joint Entropy of Correlated Sources Encoded by Good Lattices. Entropy 2019, 21, 957. https://doi.org/10.3390/e21100957
Chapman C, Bliss DW. Upper Bound on the Joint Entropy of Correlated Sources Encoded by Good Lattices. Entropy. 2019; 21(10):957. https://doi.org/10.3390/e21100957
Chicago/Turabian StyleChapman, Christian, and Daniel W. Bliss. 2019. "Upper Bound on the Joint Entropy of Correlated Sources Encoded by Good Lattices" Entropy 21, no. 10: 957. https://doi.org/10.3390/e21100957